【论文笔记】【视频异常检测】【CVPR2025】Anomize: Better Open Vocabulary Video Anomaly Detection
这篇论文是第二篇开放词汇视频异常检测(OVVAD)的论文。其实第一篇OVVAD的论文做的方法很简单,但是之所以能投CVPR,是因为提出了OVVAD这个任务。这篇论文没有“第一个提出”这块招牌,也就是说它得在方法上下功夫,才能中CVPR。(就是说检测不到新类)和(就是说无法把新类异常归类),这两个挑战其实也就是OVVAD的两个核心挑战。而论文的创新是引入了“文本增强的双流机制”,我会在后面解释这个机
1. 简介
这篇论文是第二篇开放词汇视频异常检测(OVVAD)的论文。其实第一篇OVVAD的论文做的方法很简单,但是之所以能投CVPR,是因为提出了OVVAD这个任务。这篇论文没有“第一个提出”这块招牌,也就是说它得在方法上下功夫,才能中CVPR。
这篇论文在摘要和引用部分说明了要解决的问题:检测歧义(就是说检测不到新类)和分类混淆(就是说无法把新类异常归类),这两个挑战其实也就是OVVAD的两个核心挑战。
而论文的创新是引入了“文本增强的双流机制”,我会在后面解释这个机制是什么。
2. 方法部分
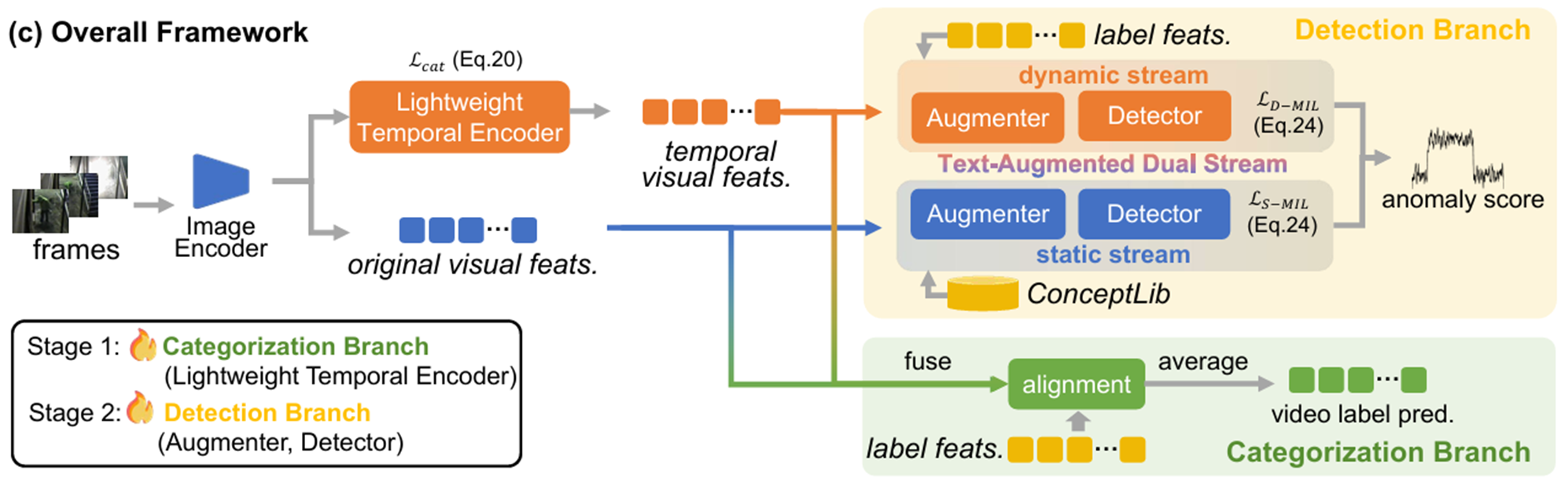
2.1 双流机制
双流指论文提出的两个分支,分别名为:动态流和静态流。
动态流:检测依赖时序动态信息的异常(如尾随行为依赖于时间变化信息)
静态流:检测依赖场景环境线索的异常(如在高速公路上奔跑则更依赖于场景环境线索)
2.2 时序信息的提取
首先用参数冻结的CLIP对每一帧提取特征:
然后分别交予双流处理。
之前第一篇提出OVVAD的论文,在他们的方法中提到:“前人提取时序信息的模块因为参数多,所以会在数据集上过拟合,对于未知类别泛化性弱。”
这篇论文秉承这个思想,在动态流部分,利用一个轻量化的LSTM简单提取了一下时序信息:
而静态流,由于不考虑时序信息,只考虑场景环境信息,所以没有做额外的处理。
可以看到,动态流和静态流,在处理完输入的视频帧之后,接下来的操作就是把处理之后的特征输入到一个增强器(Augmenter)里面。这个增强器就是论文的一大创新,利用文本来增强提取到的特征。
2.3 增强器
增强器会将获取到的文本信息和之前两个流提取的视频帧的特征(叫做视觉信息)结合起来。至于这个文本信息是怎么获取的,我会在2.4节介绍。
结合文本信息和视觉信息的方式,就是做一个多头注意力机制:
很明显,这里的多头注意力机制,是为了让文本特征去注意到视觉特征。
以防你不知道 MHA 这个公式是什么意思:
MHA全称是 Multi-Head Attension,也就是多头注意力机制,是17年的那篇 Attension is All You Need 那篇论文提出来的。换句话说,论文里的这个公式,仅仅只是利用了那篇论文的内容,而非自己提出来了一个模块。
总之,对于这个式子:,你就理解为是把 A、B 两个向量点积之后用 softmax 获取权重(除以
防止梯度消失),然后这个权重作用于 C,认为 C 注意了 A 和 B(结合了 A、B 的信息)
将文本特征 用视觉特征
注意之后,将注意后的文本特征
和原来的视觉特征进行拼接,并用一个MLP把俩特征结合起来,得到增强后的特征:
这个增强后的特征就被用于后续的异常检测、异常分类任务中。
2.4 文本特征
论文为动态流和静态流提取的视觉特征都用了增强器来增强。而这两个流增强所用的文本特征则不相同。
2.4.1 动态流文本特征 - 群组引导的文本编码
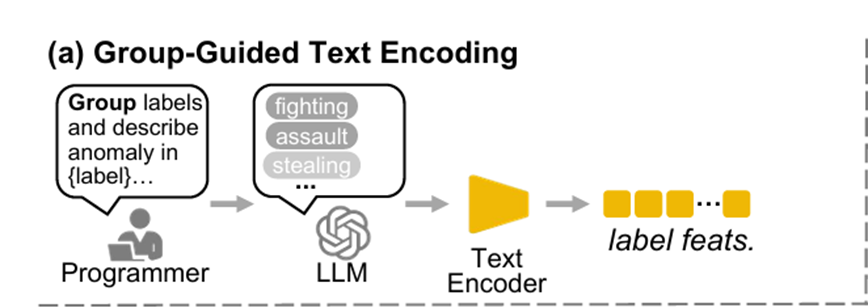
数据集的标签是存在类别标签的(不然怎么做OVVAD任务),所以论文首先使用GPT-4将每个标签按照视觉相似性分类
不过说是按照所谓的“视觉相似性”分类,实则就是在 GPT-4 的 prompt 中加入了 “按照视觉相似去分类”,并不是我一开始以为的 “CLIP文本编码提取特征然后聚类” 这样去分类。以下是这里的 prompt:

随后,对每个分类后的标签进行描述:
每个描述大概50-70词,以下是描述的 prompt

最后把每一条描述都送进CLIP提取特征:
这个特征就被用在增强动态流的视觉特征。
2.4.2 静态流文本特征 - 构建概念库
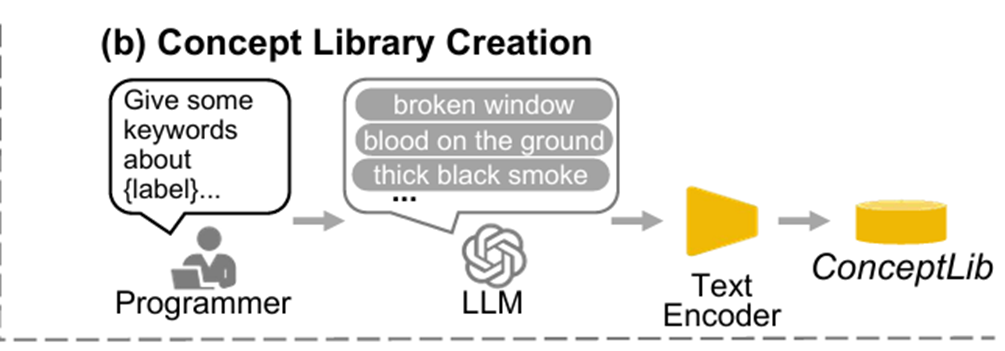
首先让GPT-4对标签中的每个类别标签,都列举出若干个名词短语,然后将每个短语送进CLIP获取特征。所有这些名词短语提取而成的特征,被称之为概念库。
2.4.3 为啥动态流和静态流构建的文本特征不同?他们有啥区别?
动态流构建的文本,是对每个类别标签,生成的一条长文本;而静态流构建的文本,是对每个类别标签生成的多条短语。
动态流获取的视觉特征是时序上下文的特征。所以用文本增强的时候,就需要长文本来描述。因为只有一句完整的文本才能描述出时间信息。(比如:A terrorist is breaking a window)
而静态流获取的是场景视觉元素,不包含时序上下文。所以用文本增强的时候,不需要长文本,只需要最小限度能描述场景的文本,也就是短语。(比如:broken window)
2.5 异常分类
OVVAD有两个目标,一个是异常检测,一个是给异常分类。

在给异常分类时,先把之前获取的双流特征进行融合:
然后将融合后的特征,和之前动态流增强用的文本特征做一个余弦相似:
这里为什么要和之前给动态流增强的文本特征做融合呢?因为给动态流增强的这些文本特征,每一条特征其实都对应一个标签。还记得之前是怎么生成这部分文本的吗?是一个标签生成一段文本。所以这里直接对这些文本做余弦相似,和哪个文本相似度高,那就属于哪一类。
然而,数据集的标签是视频级的标签,而我们得到的类别是帧级的类别,那么要怎么计算损失呢?还是用经典的 TOP-K(不过论文这里是 TOP-M)。对每一类别,在当前视频的所有帧中,把余弦相似最高的 M 帧的相似度加起来取平均,随后使用 sigmoid 激活后,选择分数最高的那个作为整个视频的类别:
我举个例子解释一下这部分怎么做的:
假设有 F1、F2、F3 三帧,C1、C2、C3 三类。
先前的计算得出:
F1 对这三类的相似度分别是 [0.1, 0.4, 0.5]
F2 对这三类的相似度分别是 [0.2, 0.8, 0.4]
F3 对这三类的相似度分别是 [0.3, 0.3, 0.1]
这里 TOP-M 的系数 M 取 2,也就是取前 2 个相似度最大的,那么:对于类别 C1,最大的两个相似度为[0.2, 0.3],加起来取平均之后是0.25
对于类别 C2,最大的两个相似度为[0.4, 0.7],加起来取平均之后是0.60
对于类别 C3,最大的两个相似度为[0.5, 0.4],加起来取平均之后是0.45
于是把 [0.25, 0.60, 0.45] 做 sigmoid 激活后,得到 [0.56, 0.64, 0.61] 这个向量。最后选取值最高的那个作为整个视频的类别,也就是 C2
2.6 异常检测
在异常检测的时候,是将动态流的检测分数 和静态流 的检测分数
结合起来。
在计算动态流的异常分数时,首先用文本特征去增强视觉特征:
然后把增强后的视觉特征做一个残差连接之后,用 sigmoid 激活获得异常分数:
至于为什么要残差连接,论文没有说。(这是16年何凯明教授在 ResNet 中提出来的方法)
在计算静态流的异常分数时,同样也需要先用文本特征增强视觉特征。不过用于增强静态流视觉特征的文本是一个概念库,里面有许多文本特征,可不能全部拿来增强,需要挑选。
首先将概念库中的所有文本特征和当前视频帧的视觉特征做余弦相似:( 代表概念库中的特征)
然后去其中 TOP-K 个相似度最高的视觉特征:( 代表余弦相似度的值)
最后把这 K 个视觉特征加权融合为一个特征,权重就是它们和当前视频帧的相似度:
接下来的操作就和动态流一样了:
3. 模型训练
3.1 一阶段训练
本阶段只训练分类任务,检测任务的参数冻结。使用三元组损失和多类交叉熵损失:
将这两个损失相加得到最终损失:
3.2 二阶段训练
本阶段只训练检测任务,分类任务的参数冻结。对每个流使用二元交叉熵损失:
这里的 X-MIL 的意思就是说它既代表动态流的损失 D-MIL 也代表静态流的损失 S-MIL。最终的损失就是它们相加:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)