Time series with LLMs
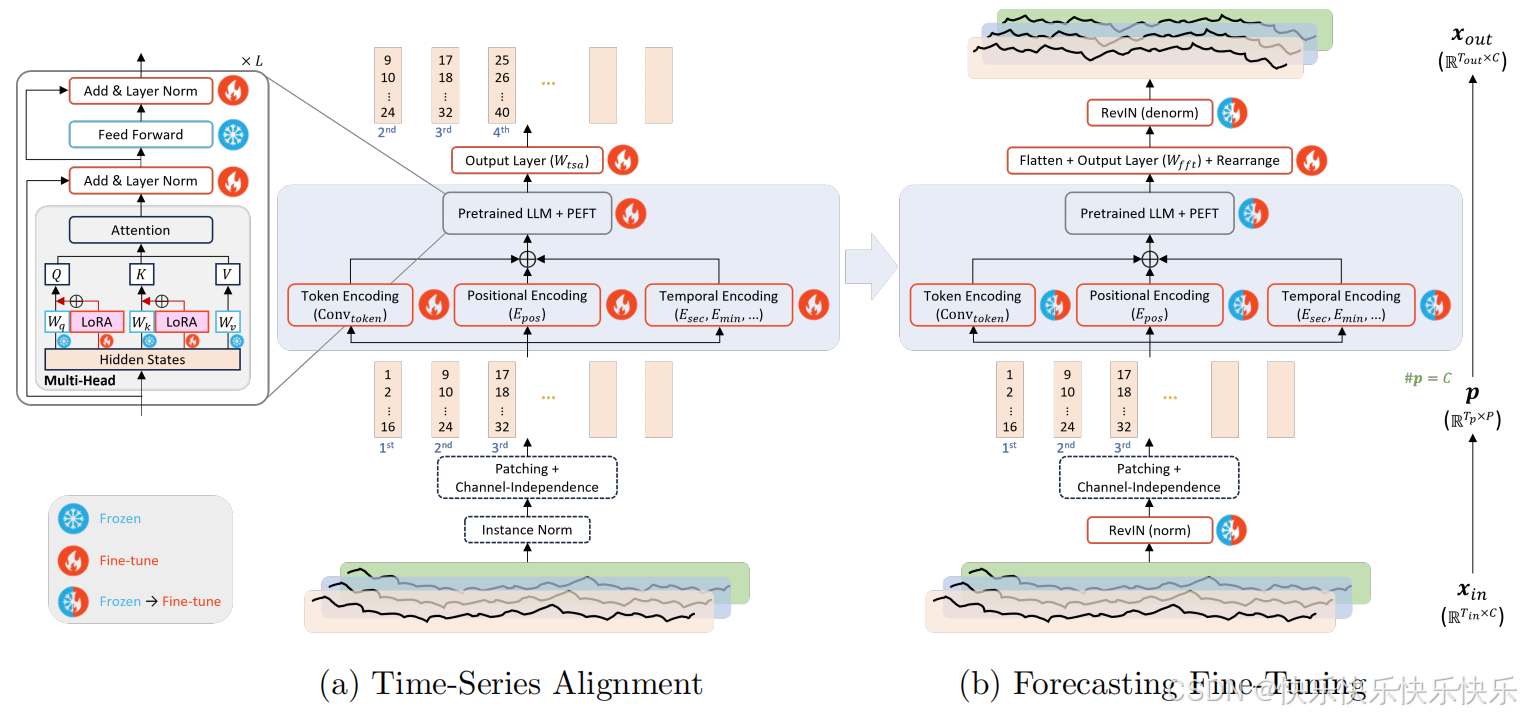
主要工作本篇文章提出了一种两阶段微调方法,首先通过监督微调将模型与时间序列的特性进行对其,引导LLM适应时间序列,接下来以下游预测任务为导向进一步对模型进行微调,从而保障不破坏语言模型固有特性的基础上使得模型能够更好地适配配各类不同域的数据及不同的下游任务。
LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters. TITS 2025.
主要工作
本篇文章提出了一种两阶段微调方法,首先通过监督微调将模型与时间序列的特性进行对其,引导LLM适应时间序列,接下来以下游预测任务为导向进一步对模型进行微调,从而保障不破坏语言模型固有特性的基础上使得模型能够更好地适配配各类不同域的数据及不同的下游任务。
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. ICLR 2024.
主要工作
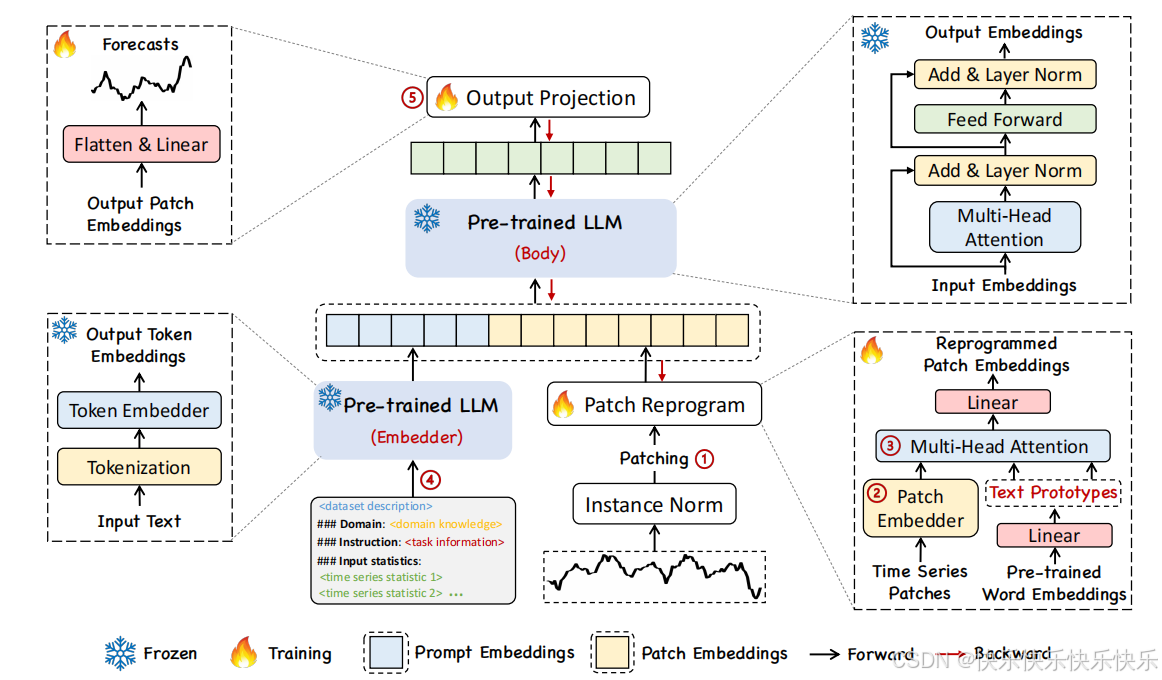
本文提出了一个Time-LLM的模型,它无需微调LLM中的任何层,只需要冻结LLM,然后在其基础上用两个可学习的模块对输入和输出分别进行特殊处理即可。
采用了prompt+patch reprogram的输入形式,LLM本身frozen。
本文也是采用了通道独立的策略,即把多变量预测分解为多个独立的单变量预测。
实验结果
实验部分进行了长期预测,短期预测,零样本预测,少样本预测。
S2IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting. ICML2024.
主要工作
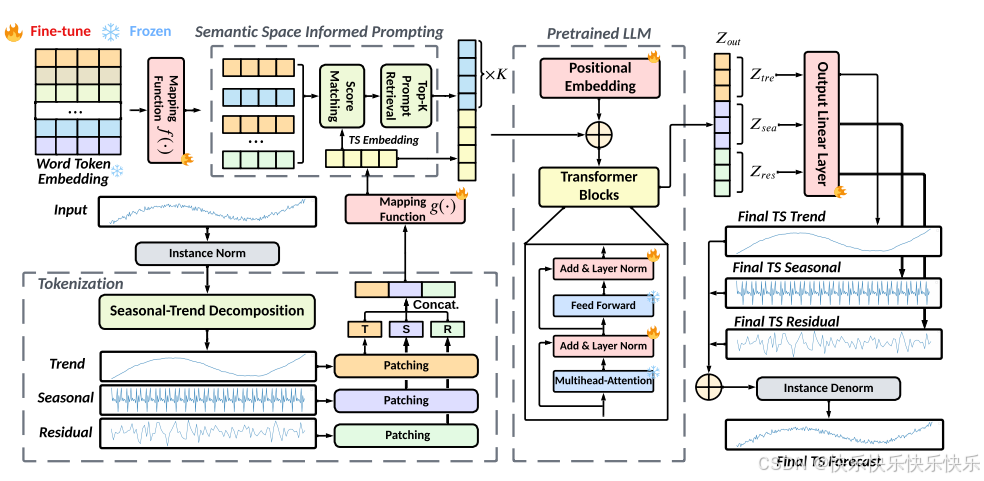
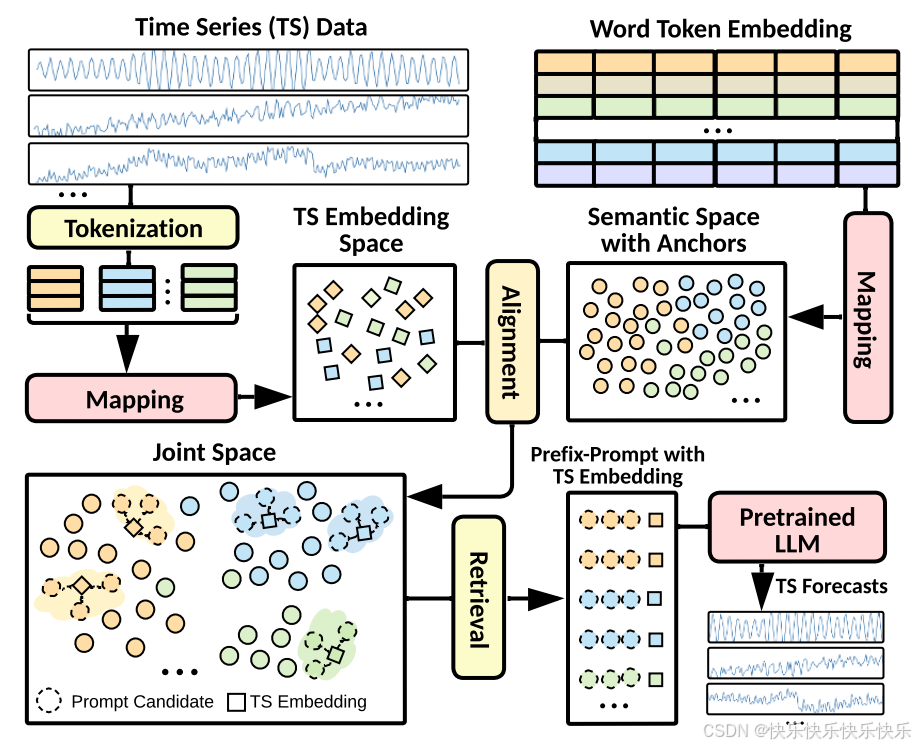
1.本文对输入序列做了一步趋势项季节项分解。每个分解后的时间序列,都单独做标准化,然后分割成有重叠的patch。每一组patch对应趋势项patch、季节项patch、残差patch,将这3组patch拼接到一起,输入到MLP中,得到每组patch的基础embedding表征。
2.将时间序列的patch表征和大模型的word embedding在隐空间对齐,然后检索出topK的word embedding,作为隐式的prompt。
3.使用GPT2作为语言模型部分,除了position embedding和layer normalization部分的参数外,其余的都冻结住。
Multi-Patch Prediction: Adapting Language Models for Time Series Representation Learning. ICML2024.
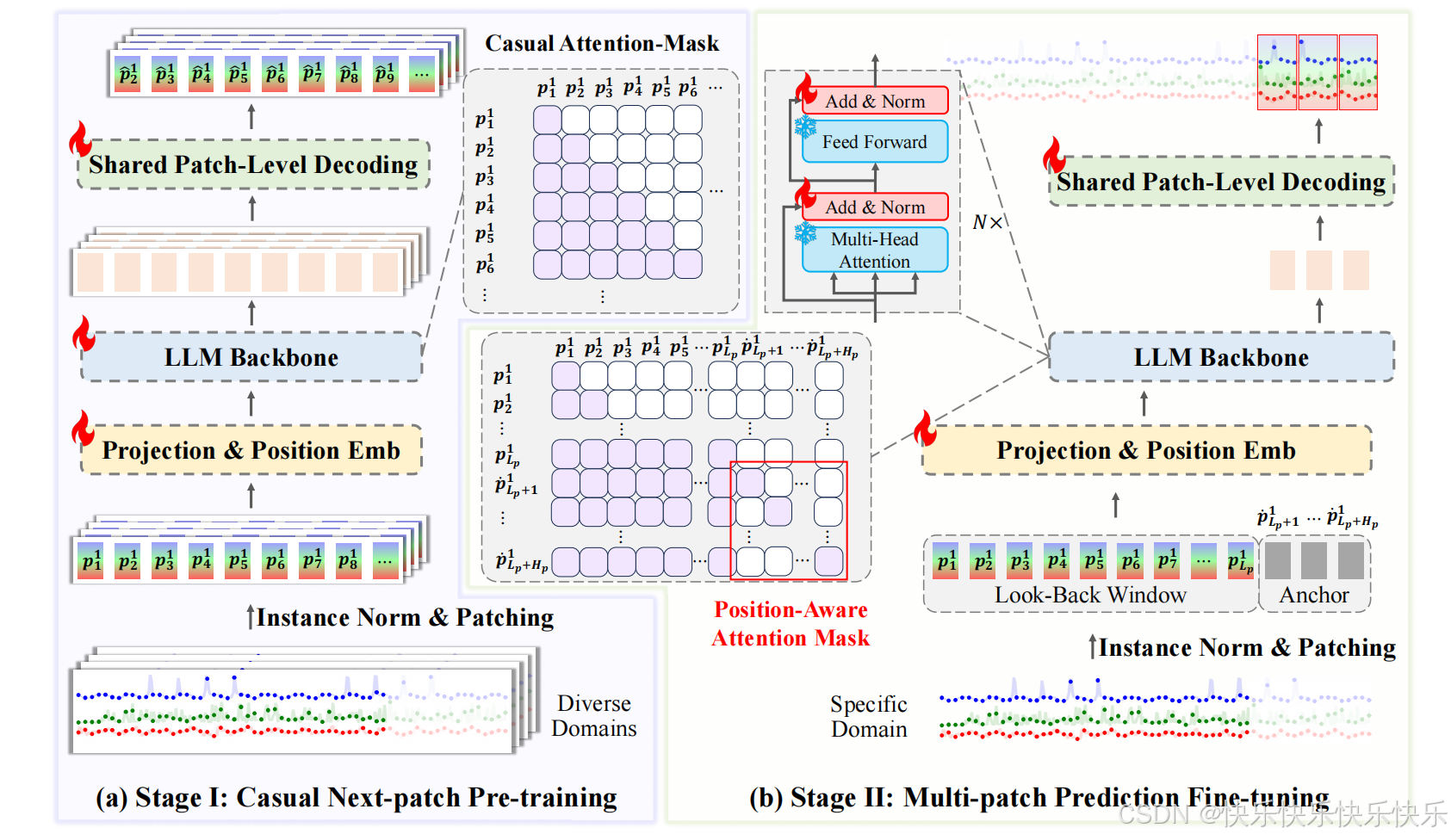
主要工作
将时间序列预测重新视为一种自我监督的多块预测任务,与传统的对比学习或掩模和重建方法相比,它可以更有效地捕获块表示中的时间动态。
对各种时间序列数据集进行因果连续预训练阶段,锚定于下一个patch预测,有效地将 LLM 功能与复杂的时间序列数据同步;在目标时间序列上下文中对multi-patch预测进行微调。
实验结果
实验部分,进行了长短期预测,表征少样本学习,还进行了异常序列检测。
A decoder-only foundation model for time-series forecasting.ICML 2024.
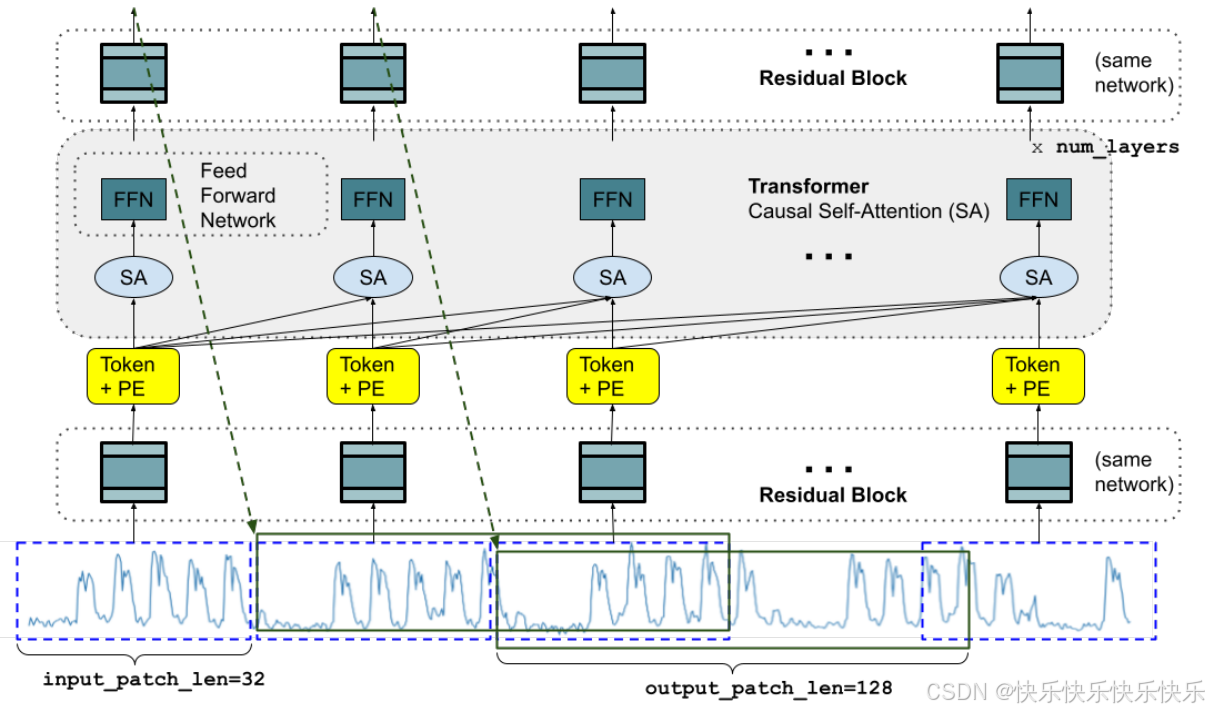
主要工作
本模型在一个包含真实世界和合成数据集的大型时间序列语料库上进行预训练,输入也采用了patch模型。
实验结果
实验部分主要探究了该预训练模型在zero-shot任务上的性能。
Autotimes: Autoregressive time series forecasters via large language models. NeurIPS 2024.
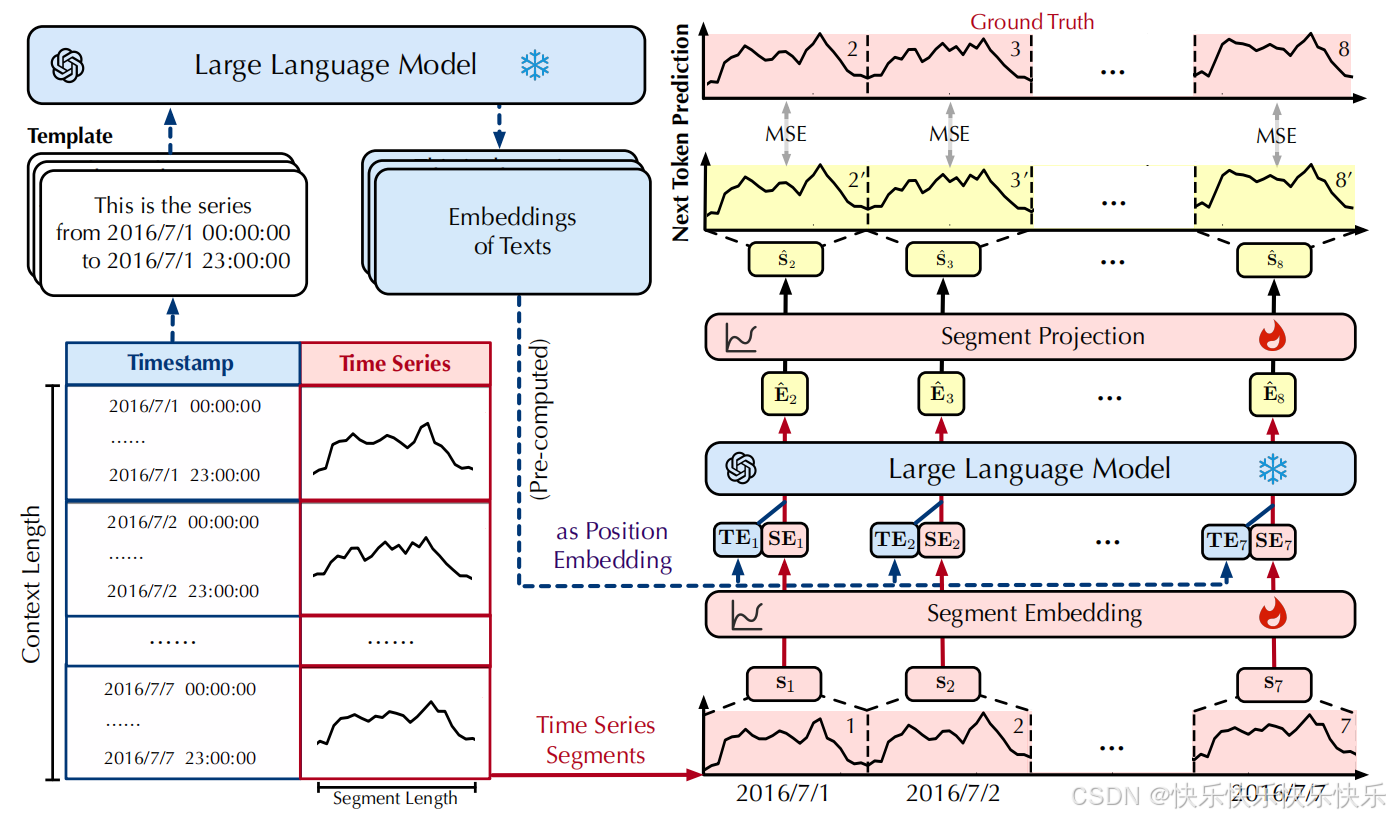
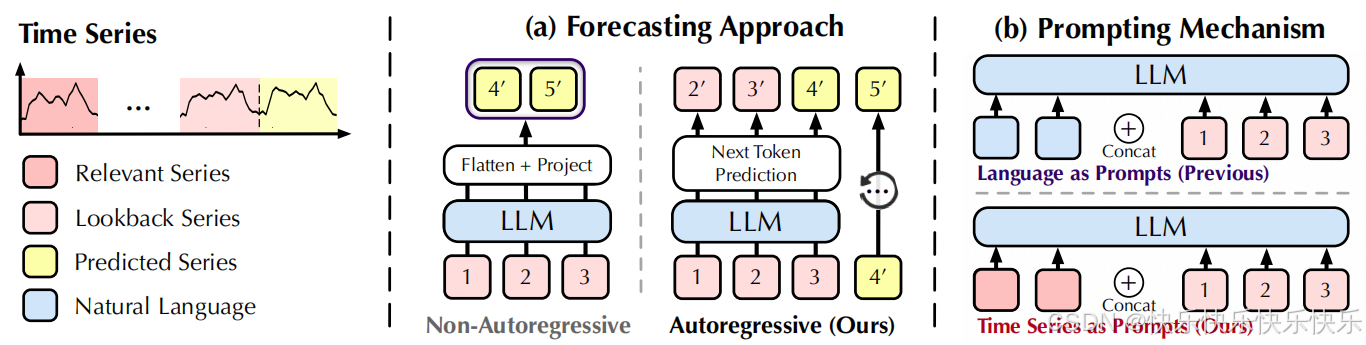
主要工作
在不更新参数的情况下,将 LLM 重新用作自回归时间序列预测器。此外,提出了token-wise prompting,利用相应的时间戳使该方法适用于多模态场景。
Gpt4mts: Prompt-based large language model for multimodal time-series forecasting. AAAI 2024.
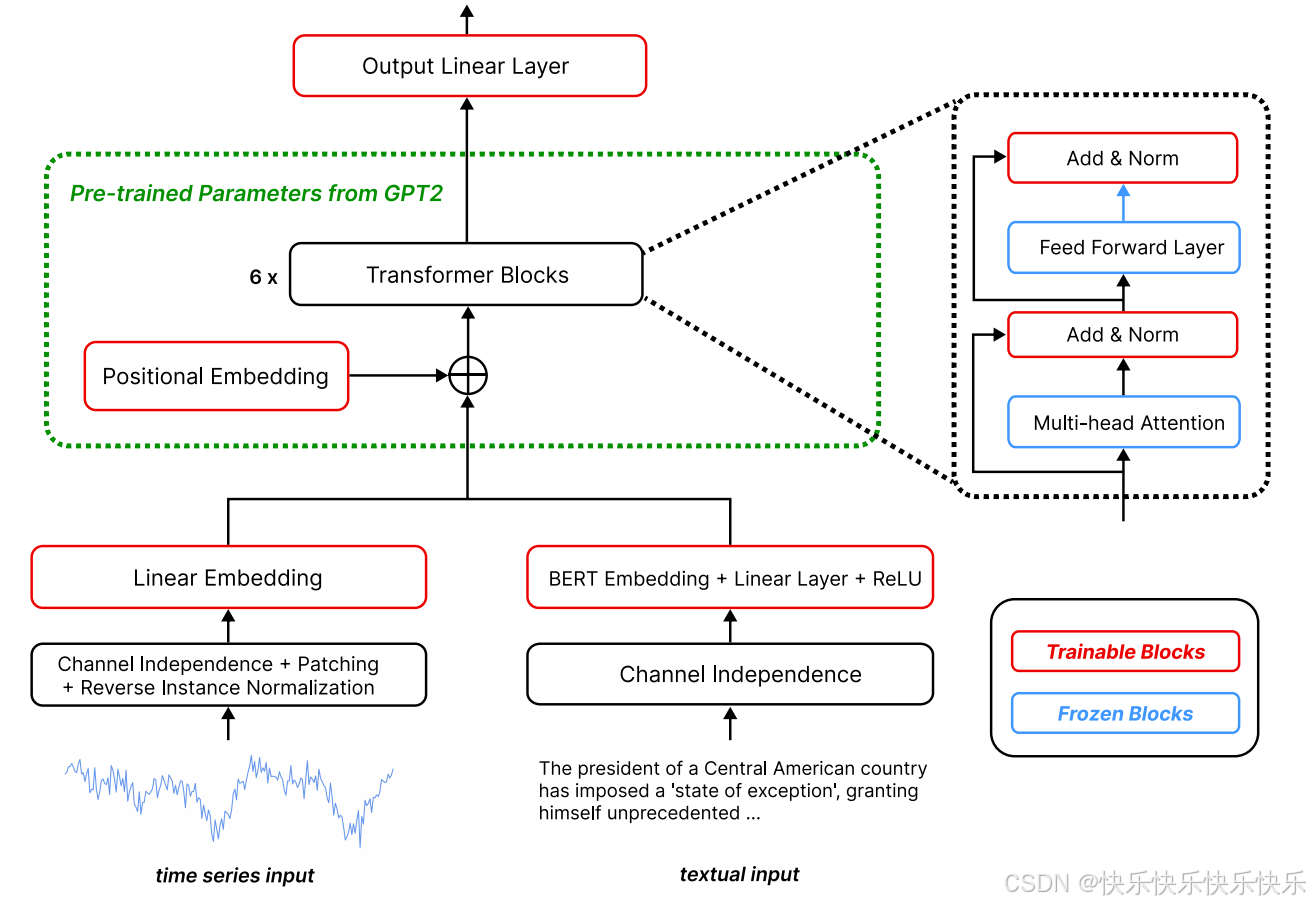
主要工作
1.提出了一个基于提示的LLM框架,可以同时利用数值数据和文本信息
2.提出了一个基于GDELT的多模态时间序列数据集,用于新闻影响力预测。
Chronos: Learning the language of time series
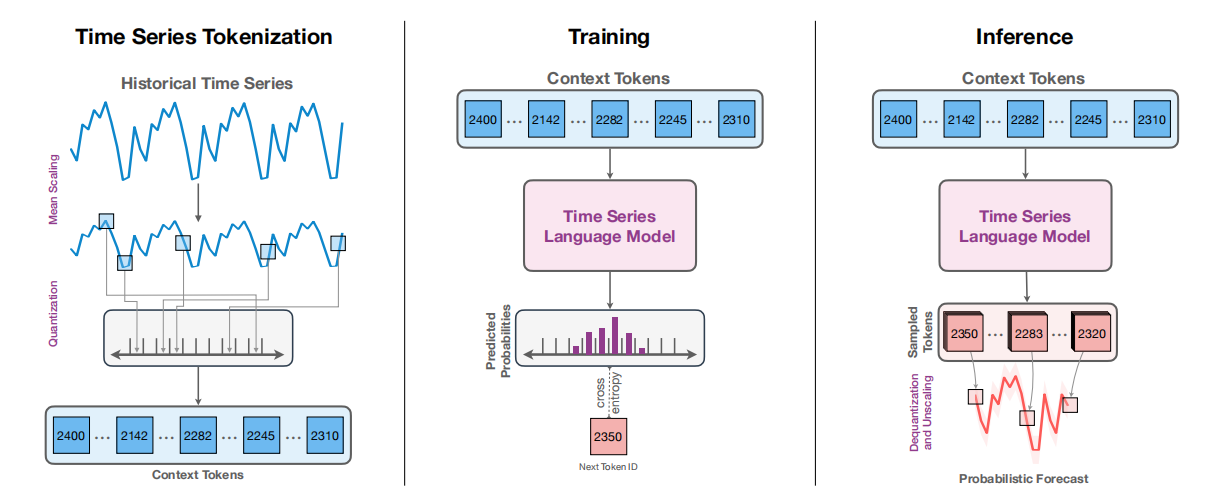
主要工作
Chronos使用缩放(scaling)和量化(quantization)技术将时间序列标记为固定词汇,并通过交叉熵损失在这些标记化(tokenized)的时间序列上训练基于Transformer的语言模型架构。
本文的工作很巧妙,将时间序列分为一个小块一个小块,然后把context tokens放入经典的TSLM在进行训练,损失为交叉熵。推理的时候,先预测出tokens,然后再逆过程恢复出序列。
Context-Alignment: Activating and Enhancing LLM Capabilities in Time Series. ICLR 2025.
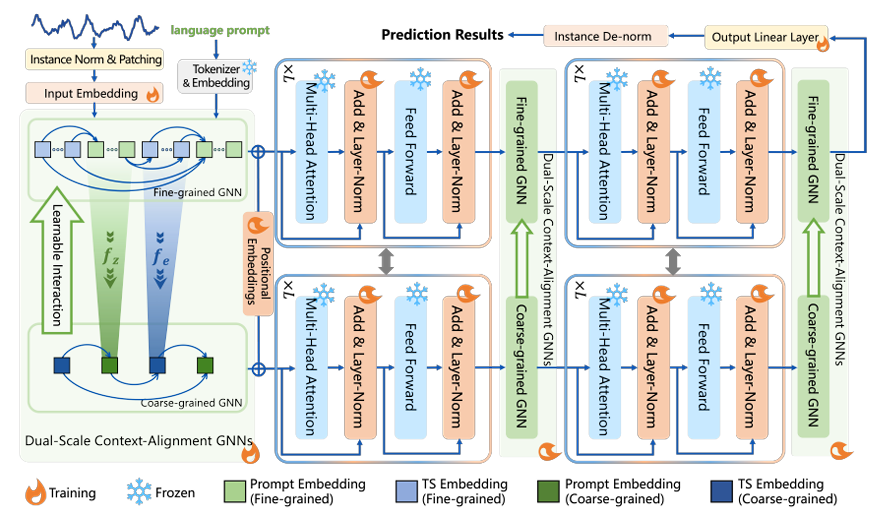
主要工作
本文希望将时间序列数据融入自然语言的语境中,使大语言模型能够将时序数据整体视为一个语言成分,并通过上下文自主地理解时间序列。
VCA 和 FSCA
由于不同的 prompt 内容对应不同的逻辑结构关系,因此双尺度语境对齐图结构依赖于具体的 prompt 内容。作者提出了两种使用双尺度语境对齐图结构的具体方法。
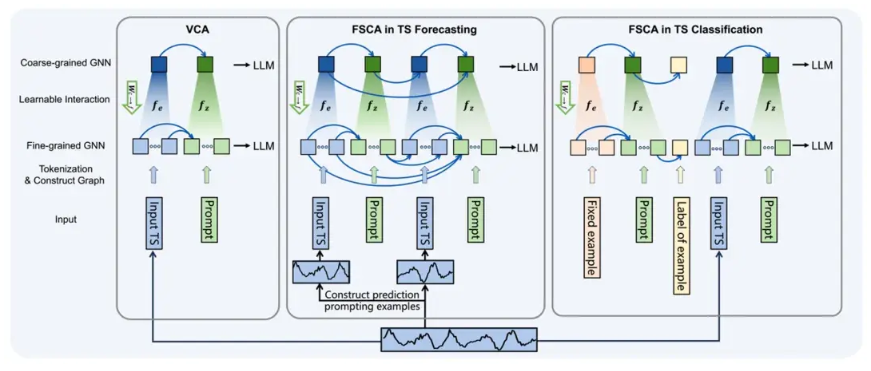
1. Vanilla Context-Alignment(VCA)
VCA 是最直接的实现方式,其输入模式为时序数据 + prompt。例如,在预测任务中,prompt 为「predict future sequences using previous data」,其图结构如图 1 中的 VCA 所示。在分类任务中,输入为「时序数据 + Predict category using previous data」,其图结构与预测任务相同。VCA 利用最简单直接的 prompt,通过双尺度图结构实现语境对齐。
2. Few-Shot Context-Alignment(FSCA)
FSCA 是 VCA 的进阶版本,结合了 Few-Shot prompting 技术以进一步提升性能。该方法的输入包括例子 + 时序数据 + prompt。在预测任务中,prompt 依然为「predict future sequences using previous data」,但需要将原始历史时序数据分成两部分构建一个例子:前半段数据作为后半段数据的历史输入,后半段数据作为利用前半段数据预测的 ground truth。这一示例有助于大语言模型更好地理解预测任务。其图结构如图 1 中的「FSCA in TS Forecasting」所示。
- 细粒度图结构将每个 token 视为一个节点,强调 token 之间的相互独立性,保留时序的具体信息。
- 粗粒度图结构将连续的、模态一致的 tokens 映射为一个节点,表示了模态的整体性。
实验结果
该研究展示了长期预测、短期预测、Few-Shot 预测、Zero-Shot 预测以及分类任务的实验结果。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)