绝美无痕,比你还会P图的Agent!仅通过自然语言指令,灵活使用数百工具,超越GPT-4o达60%
照片精修是专业摄影的核心环节,但传统工具如Lightroom操作复杂,而AI方案(如GPT-4o)常因。:确保模型精确选择工具(如"曝光补偿"而非"对比度")并设置合理参数值(如曝光+0.5而非+2.0)。:人像(40.8%)、风光(33.3%)、街景(5.7%)、静物(20.2%),通过"AI代理+专业软件"融合实现"人类创意+机器执行"的协作范式。根本原因:缺乏实时视觉反馈的"顿悟时刻"(对比
照片精修是专业摄影的核心环节,但传统工具如Lightroom操作复杂,而AI方案(如GPT-4o)常因过度重生成像素导致细节失真,且缺乏局部精细控制能力。

-
论文:JarvisArt: Liberating Human Artistic Creativity via an Intelligent Photo Retouching Agent
-
链接:https://arxiv.org/pdf/2506.17612
JarvisArt提出一种多模态大模型驱动的智能Agent,通过理解自然语言指令,协调200+个Lightroom工具,实现媲美专业修图师的非破坏性编辑。其突破性在于:
-
精准意图解析:支持文本/框选/笔刷多模态输入
-
透明工作流:生成可解释的编辑决策链
-
任意分辨率支持:突破生成模型的分辨率限制
实验显示,其内容保真度超越GPT-4o达60%,为AI艺术创作开辟新路径。
研究动机与现有方法局限
行业痛点:
-
专业工具门槛高:Lightroom需手动调整数百参数,学习成本陡峭
-
AI方案三大缺陷:
-
内容失真:扩散模型重生成所有像素,破坏原图细节(如人脸特征)
-
局部控制缺失:无法实现"提亮皮肤但保持背景"的精细操作
-
分辨率限制:生成式模型无法处理超高分辨率图像
现有技术对比:
|
方法类型 |
代表模型 |
核心局限 |
|---|---|---|
|
优化算法 |
3DLUT/RSFNet |
依赖预训练代理,泛化性差 |
|
强化学习 |
RL-based |
缺乏艺术审美判断 |
|
扩散模型 |
MagicBrush |
静态提示,多轮推理能力弱 |
|
多模态模型 |
GPT-4o/Gemini |
局部控制弱,像素级保真度低 |
JarvisArt的定位:兼具自动化与可控性,通过"AI代理+专业软件"融合实现"人类创意+机器执行"的协作范式。
JarvisArt系统设计
工作流程
用户输入 → 多模态理解 → 艺术推理 → 工具协调 → Lightroom执行

关键技术
-
链式思维监督微调(CoT SFT):
使用50K链式思维样本训练模型分步推理能力:"理解用户意图 → 分析美学缺陷 → 选择工具 → 设置参数"
例如:
"用户需提升夜景霓虹灯对比度:先调白平衡至3200K冷调,再用线性蒙版提亮灯牌,最后增加锐化..." -
GRPO-R强化学习:
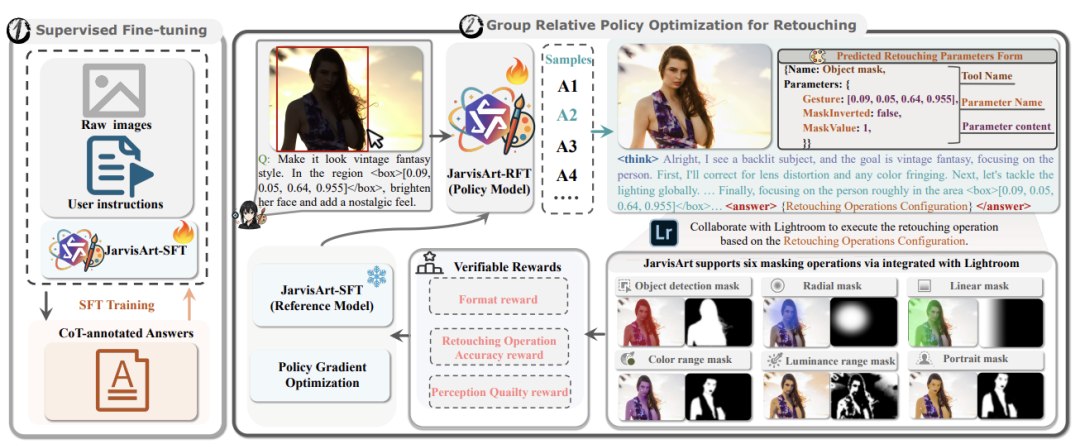
核心创新:三维奖励函数驱动模型进化:
-
格式奖励(Rf):强制结构化输出(思考过程/工具调用分离)
-
操作精度奖励(Rroa):量化工具选择与参数匹配度
-
感知质量奖励(Rpq):评估修图后视觉保真度
A2L协议
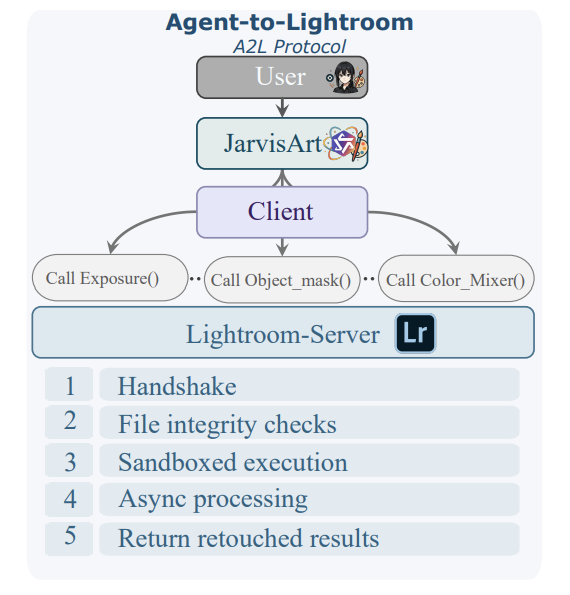
-
五大阶段:握手 → 文件验证 → 沙箱执行 → 异步处理 → 结果返回
-
核心价值:将ROC文件转为Lightroom可执行的Lua脚本,支持非破坏性编辑流程闭环。
MMArt数据集构建
三层数据生成流水线:

-
图像对与配置生成:
-
使用Grounding DINO定位兴趣区域(置信度>0.8)
-
Qwen2.5-VL模拟专家推荐预设(如"人像-胶片模拟")
-
人工筛选最佳效果,记录Lightroom操作配置(ROC文件)
-
用户指令合成:
-
-
区分普通用户("让天空更蓝")和专业用户("降低高光-0.3,HSL增加蓝色饱和度")
-
覆盖全局调整与局部优化需求
-
-
推理链标注:
-
-
首先生成详细技术步骤(如"用径向蒙版提亮眼部")
-
经Qwen2.5-VL精炼为人类可读的决策逻辑
数据集特性:
-
55K样本(5K标准指令+50K CoT增强)
-
四类场景:人像(40.8%)、风光(33.3%)、街景(5.7%)、静物(20.2%)
-
唯一支持:任意分辨率图像+Lightroom操作记录+链式思维标注

对比:MMArt在真实性、分辨率支持、标注丰富度上显著优于MagicBrush等数据集 核心创新:GRPO-R强化学习
三维奖励函数设计
(1)操作精度奖励(Rroa)
评估预测工具 与目标 的匹配度:关键作用:确保模型精确选择工具(如"曝光补偿"而非"对比度")并设置合理参数值(如曝光+0.5而非+2.0)。
(2)感知质量奖励(Rpq)
解决"不同参数可能视觉相似"问题:-
CD() :CIELAB色彩分布相似度(权重γ=0.4)
-
L() :像素级L1/L2距离
核心思想:平衡全局色调一致性与局部细节保真度。
实验验证
定量对比(MMArt-Bench)
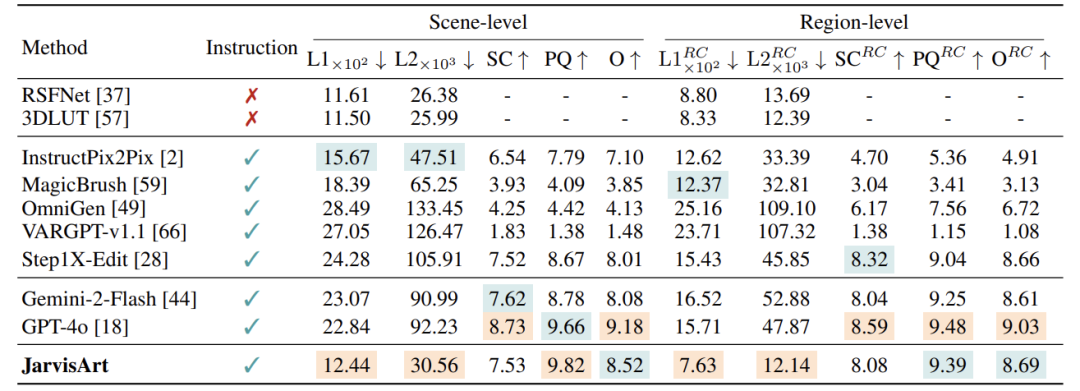
数据:JarvisArt在L1/L2等像素指标显著领先,指令跟随性媲美GPT-4o
-
内容保真度:
-
-
场景级L1:12.44 (vs. GPT-4o的22.84,提升45.6%)
-
区域级L1:7.63 (vs. GPT-4o的15.71,提升51.4%)
-
-
指令跟随性:
-
-
整体得分O:8.52 (vs. GPT-4o的9.18,差距<8%)
-
用户偏好研究
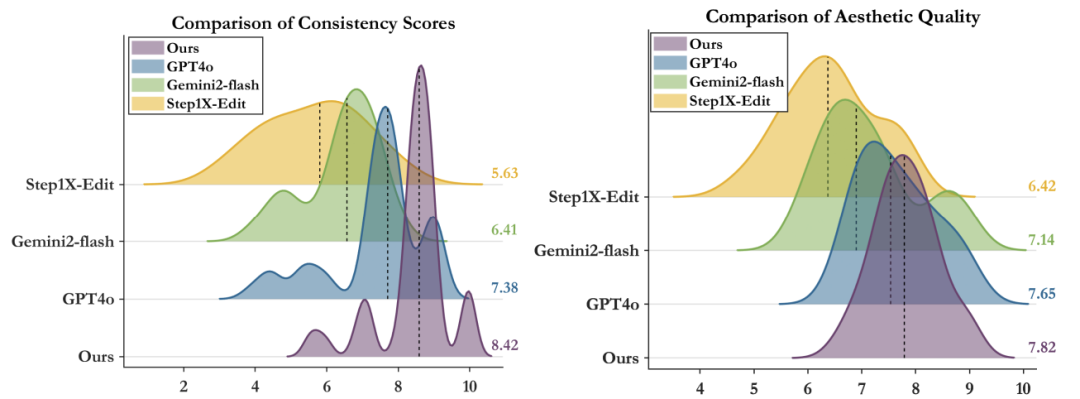
80名参与者对美学质量/内容一致性的评分 -
JarvisArt获最高偏好率:
-
-
美学质量:38.7% (vs. GPT-4o的29.1%)
-
内容一致:42.5% (vs. GPT-4o的24.3%)
-
系统易用性验证
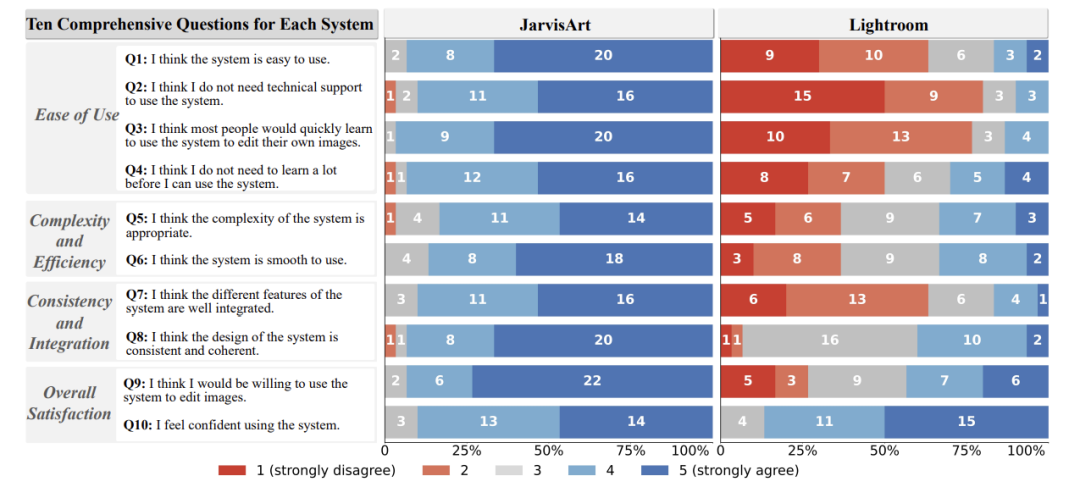
问卷:30名用户对比JarvisArt与Lightroom -
易学性:93.3%用户可在无指导下独立操作
-
效率:86.7%认为工作流更流畅
-
关键优势:降低认知负荷,避免参数迷宫
泛化能力测试(MIT-FiveK)
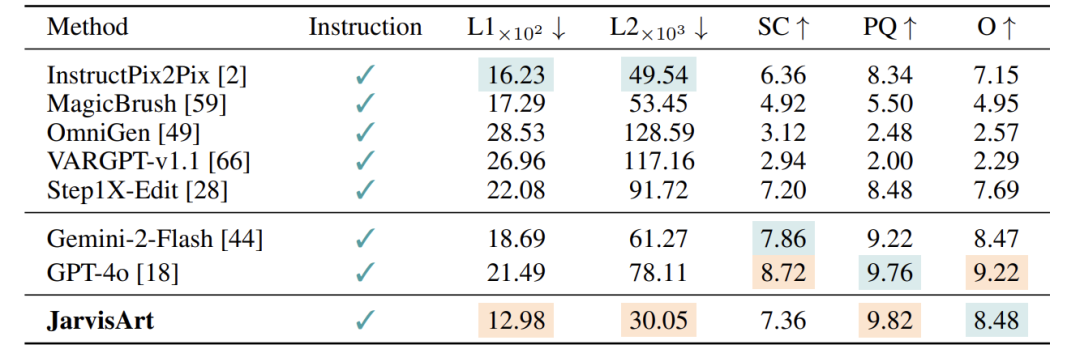
数据:跨数据集性能保持领先 -
L1:12.98 (vs. GPT-4o的21.49)
-
指令跟随得分O:8.48 (vs. GPT-4o的9.22)
典型失败案例
-
复杂光影场景:模型可能过度提亮阴影区域
-
抽象指令:"营造梦幻感"需多次迭代调整
根本原因:缺乏实时视觉反馈的"顿悟时刻"(对比数学推理的逐步验证)
结论与未来方向
核心贡献:
-
首创艺术家代理范式:实现人类创意与专业工具的无缝协作
-
三维奖励强化学习:解决工具调用决策的稀疏奖励问题
-
A2L工业协议:为AI+专业软件集成设立标准
应用价值:
-
摄影爱好者:低成本获得专业级修图效果
-
设计行业:加速商业图片后期流程
-
技术启示:为AI代理操作复杂软件(如CAD/3D建模)提供蓝图
愿景:让AI成为人类创造力的"加速器",而非替代者。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)