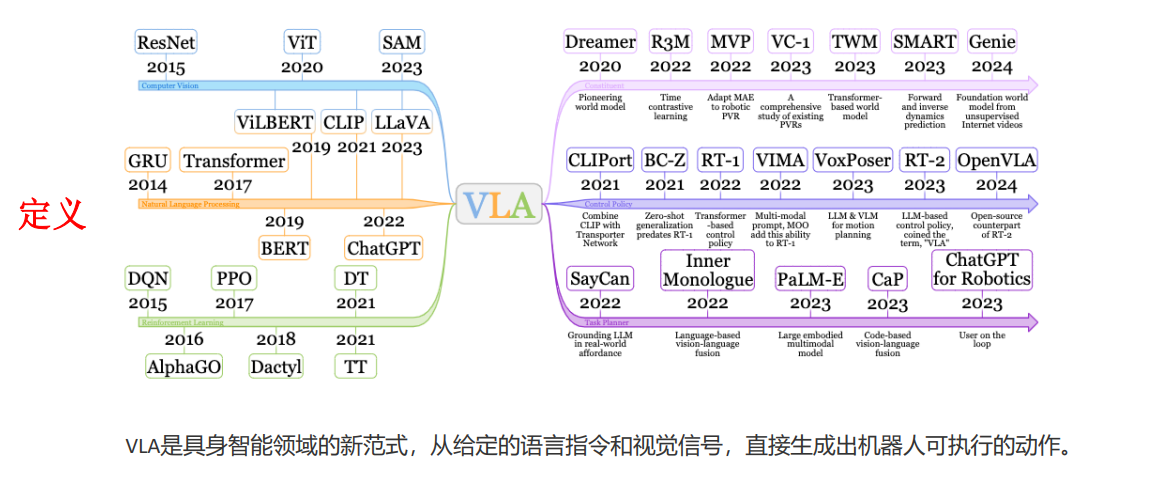
VLA概述
1.传统的机器人决策系统有很强的规则性,没有很好的泛化性。2.VLA就是从给定的视觉和文本信号,去产生相应的动作信号并驱动机器人去执行3.整体流程4.主体要素4.1对于视觉信号而言,最常见的就是ViT4.2对于语言信号而言,最常见的就是基于LLaMA,ChatGPT等大模一些发展。4.3动作模型:Diffusion Policy等6.视觉发展历程6.1Transformer这种模型是具有更强的泛化
一、VLA模型概述
1.传统的机器人决策系统有很强的规则性,没有很好的泛化性。
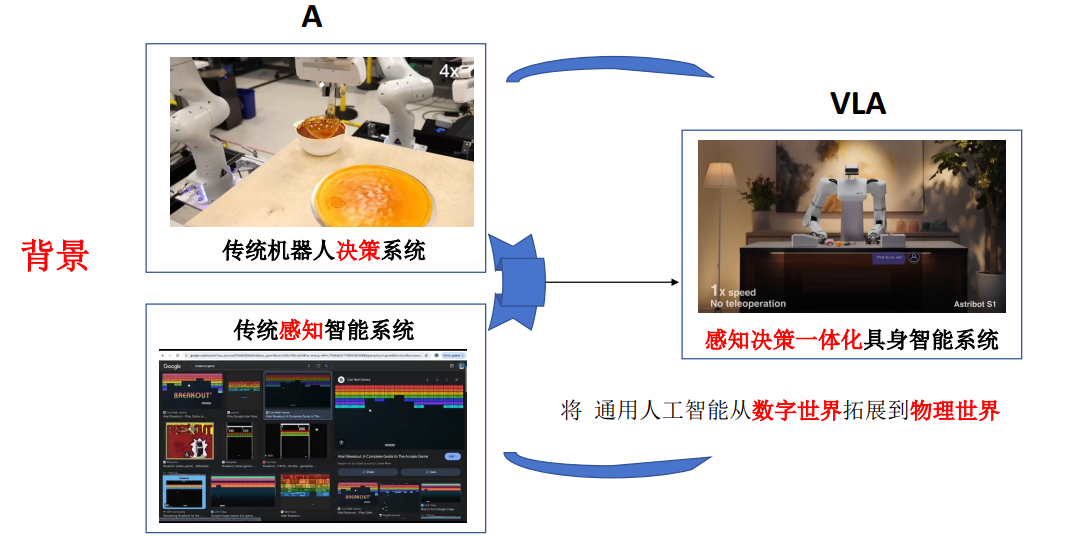
2.VLA就是从给定的视觉和文本信号,去产生相应的动作信号并驱动机器人去执行
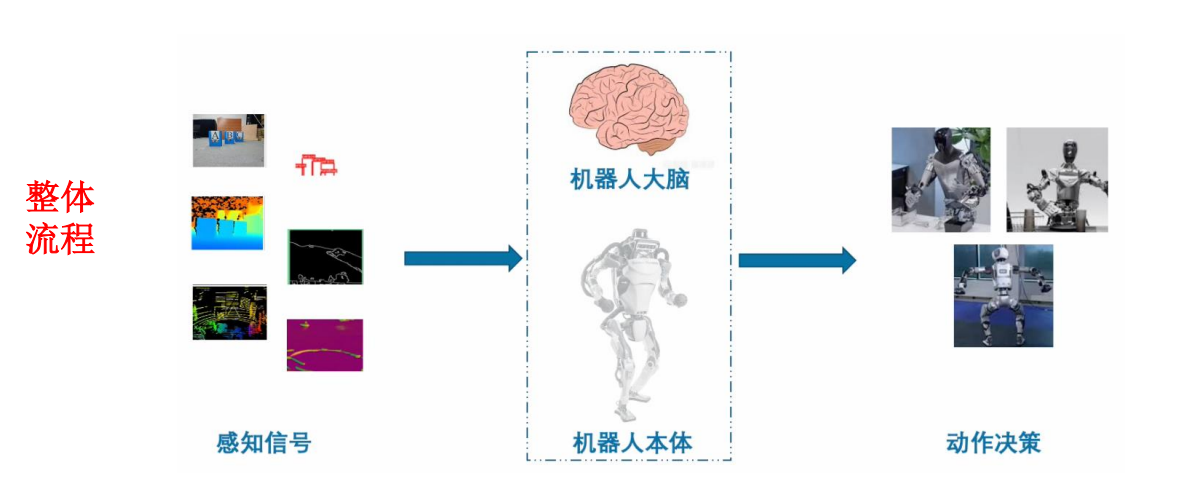
3.整体流程
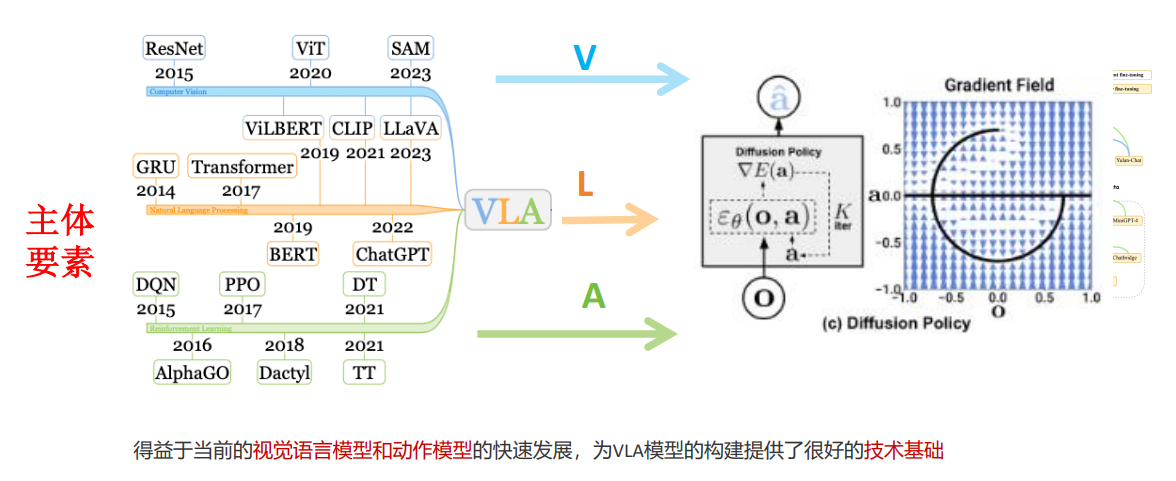
4.主体要素
4.1对于视觉信号而言,最常见的就是ViT
4.2对于语言信号而言,最常见的就是基于LLaMA,ChatGPT等大模一些发展。
4.3动作模型:Diffusion Policy等
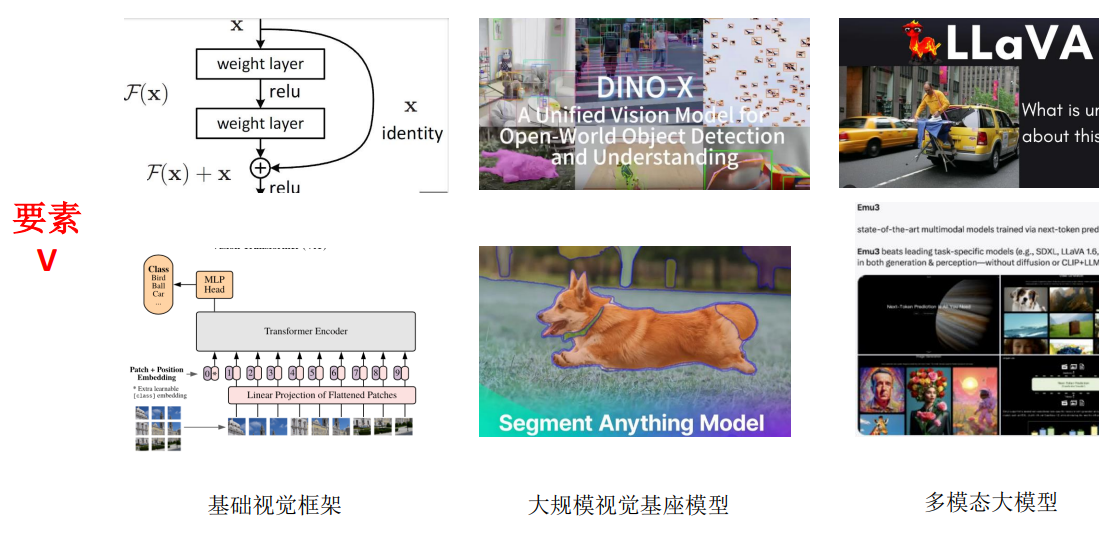
6.视觉发展历程
6.1Transformer这种模型是具有更强的泛化性,并且其skills要高于CNN
6.2随着数据集的扩充和学术界的努力慢慢产生了一些视觉基座模型,这些基座模型虽不像大语言模型那样通用,但是在很多场景中的泛化性也是比较好的。eg:Segment Anything Model、DINO-X。
6.3随着视觉模型的发展,慢慢转向了多模态大模型。eg:LLaVA
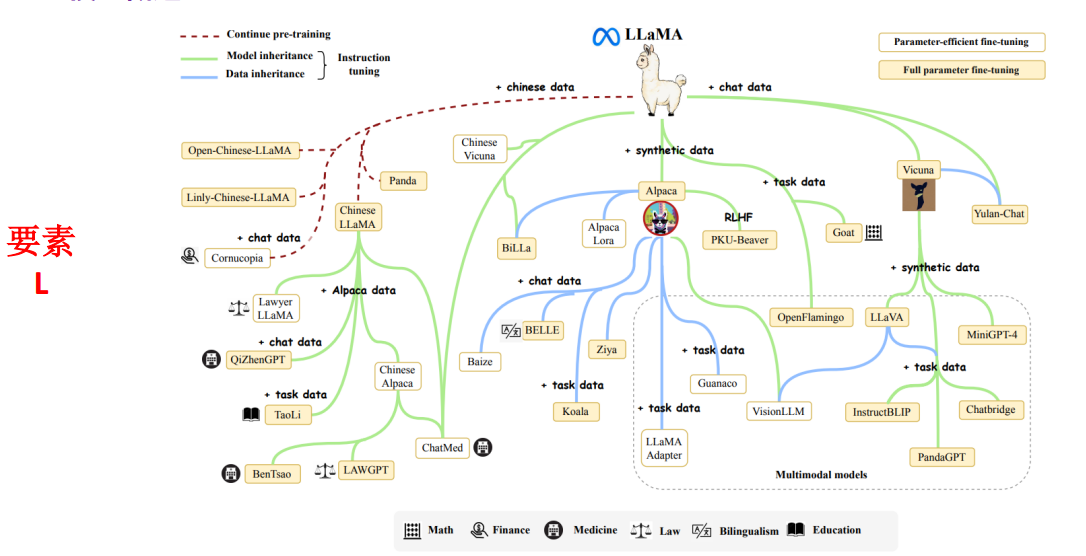
7.大语言模型发展概述
基于LLaMA之后做的相应的改进。
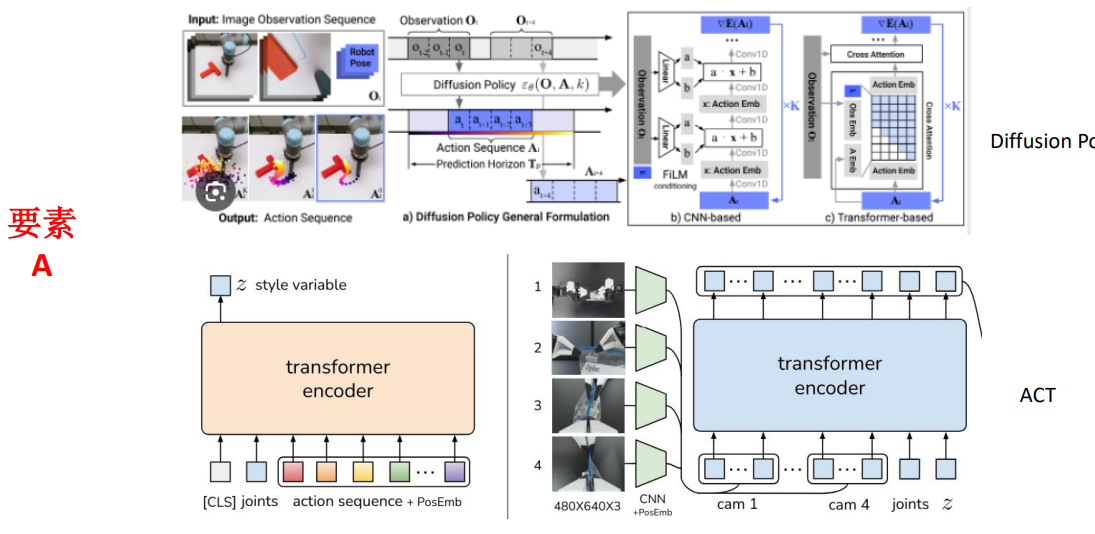
8.动作模型概述
9.VLA模型
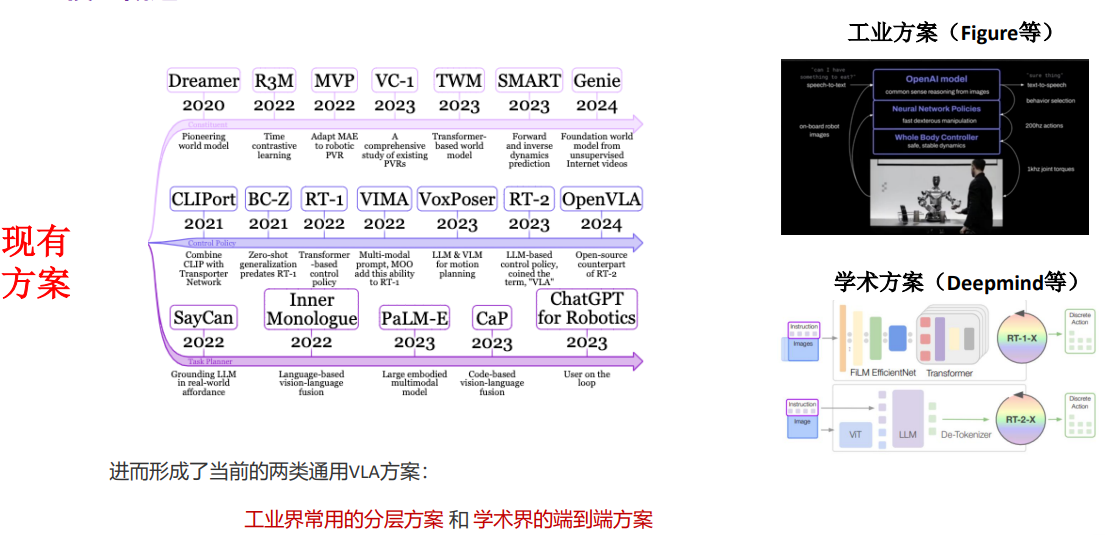
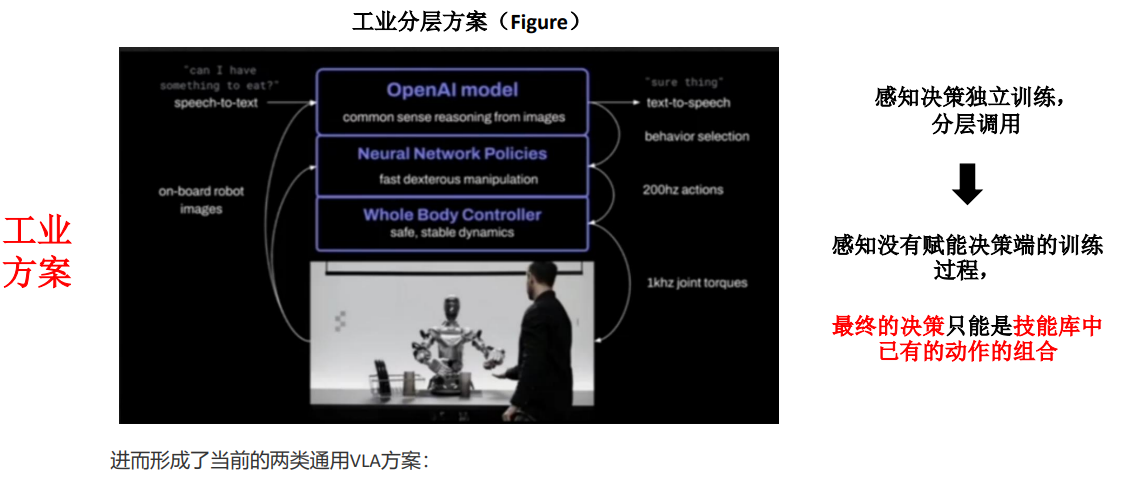
9.1工业界常用的分层方案(Figure)
9.1.1由人工输出语音指令,随后机器人先将语音指令通过speech-to-text模型转化成文字,之后由多模态大模型对文字结合当前的图片情景进行拆解。之后由一个任务拆解成多个子任务,拿着子任务去Neural Network Policies中去做一个检索(预先将下游任务训练成了一个技能库)并生成动作。调用控制器去控制机器人的运动。
9.1.2缺点:技能是有限的,需要预先把技能训练好。从而最后的决策只能是技能库中已有动作的组合。对于陌生的动作执行不好。感知模型是GPT,动作模型是单独训练出来的,造成了感知信号和下游的信号是割裂开来的,多模态的感知性能没有去赋能决策段的训练过程。
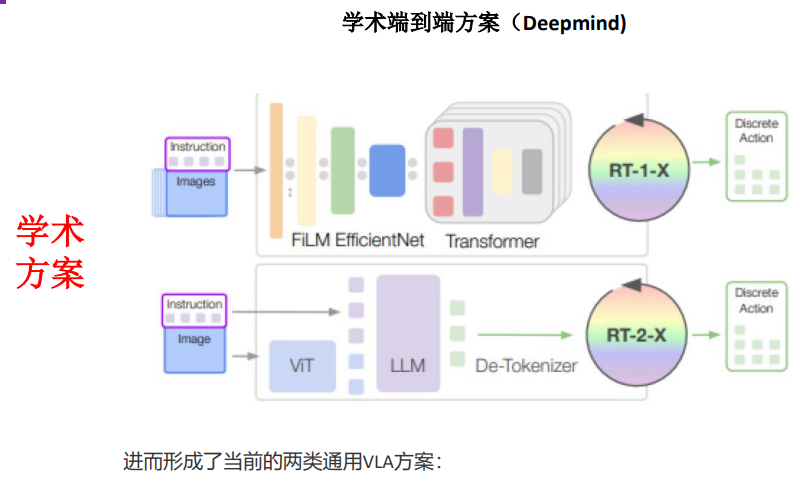
9.2端到端方案(Deepmind)
可以充分利用语言和图像的先验知识去赋能动作的生成。
10.端到端VLA方案分类:从有没有显式地将未来的状态建模出来去区分。
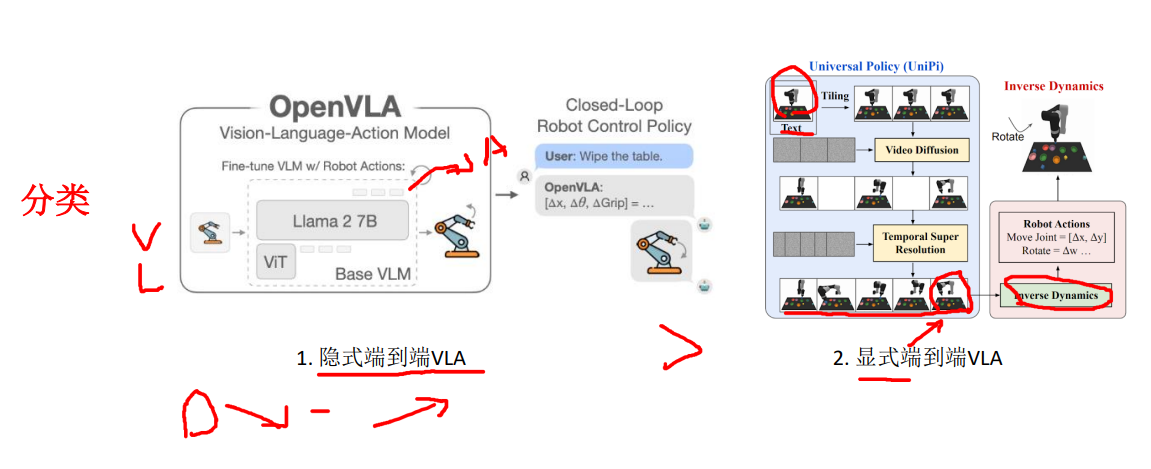 10.1隐式端到端VLA:当视觉信息和语言信息输入之后进行压缩成更加稠密的向量,然后根据生成的向量去remap到对应的action上去。在这个过程中假定动作和语言学到的embedding和action是一一对应的。
10.1隐式端到端VLA:当视觉信息和语言信息输入之后进行压缩成更加稠密的向量,然后根据生成的向量去remap到对应的action上去。在这个过程中假定动作和语言学到的embedding和action是一一对应的。
10.2显式端到端VLA:给定当前的语言指令和场景,根据Video Diffusion模型生成根据这个场景的动作。得到动作之后,再把这些信息作为goal放到Inverse Dynamic中直接生成机器人能够执行的动作。
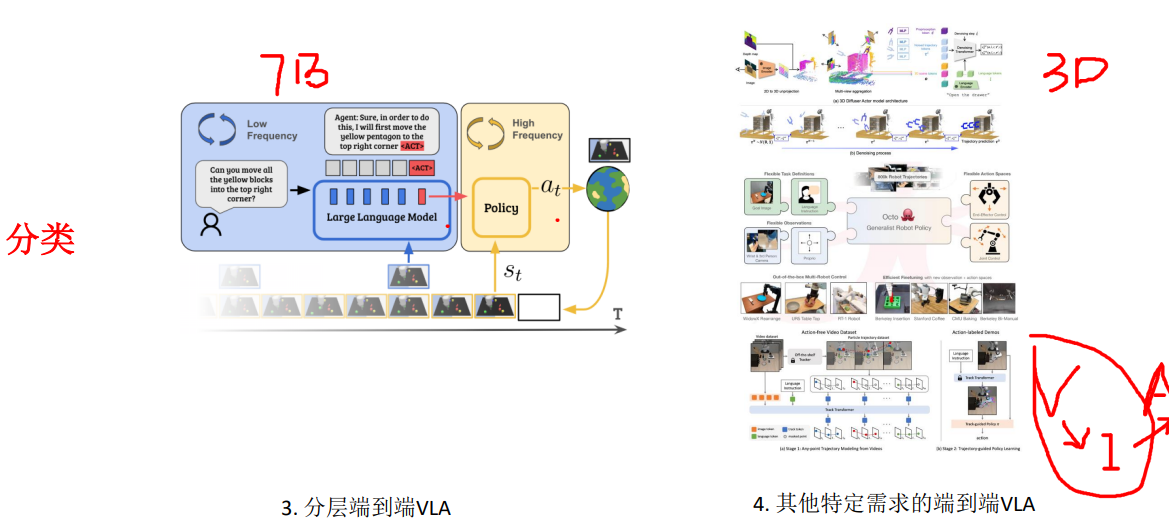
11.分层端到端VLA和其他特定需求的端到端VLA
为了解决大模型速度低,小模型泛化性不够好。通过媒介将大模型和小模型结合起来,形成上下游端到端的网络。
二、仿真环境
1.仿真环境

2.渲染引擎与仿真环境

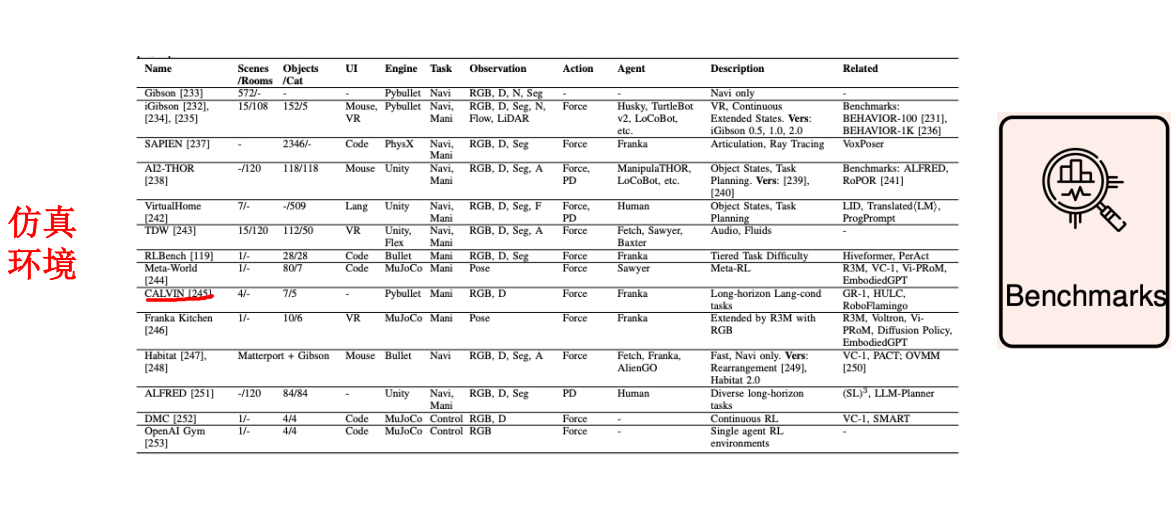
2.1渲染引擎和其对应的仿真环境
仿真环境和渲染引擎是紧密关联但功能不同的两个核心组件,二者共同构成机器人算法开发与测试的基础设施,其关系可概括为仿真环境提供底层运行框架,渲染引擎负责可视化呈现,二者协同工作以支持机器人学习任务。





三、数据构成
1.数据集
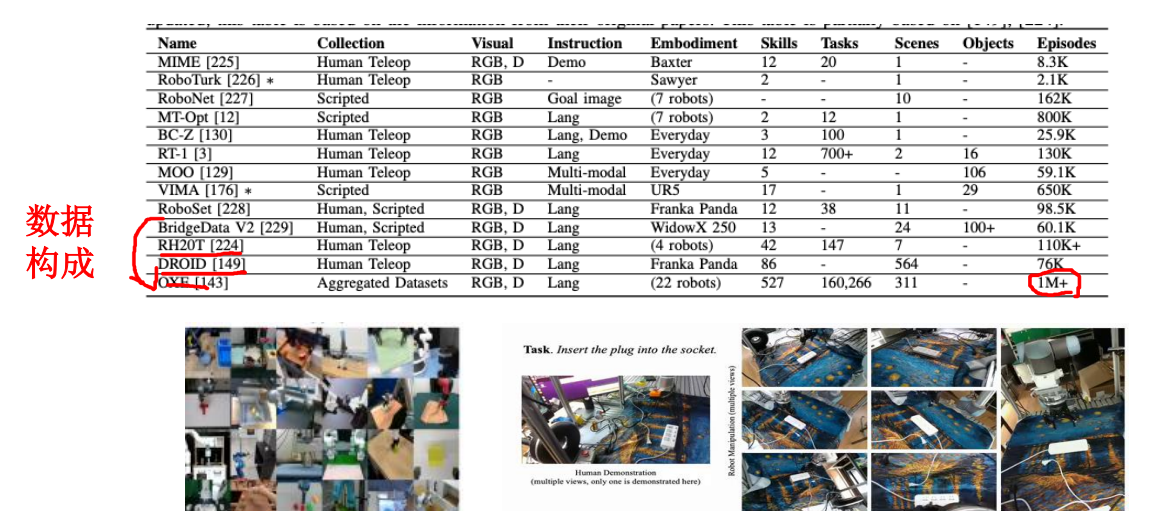
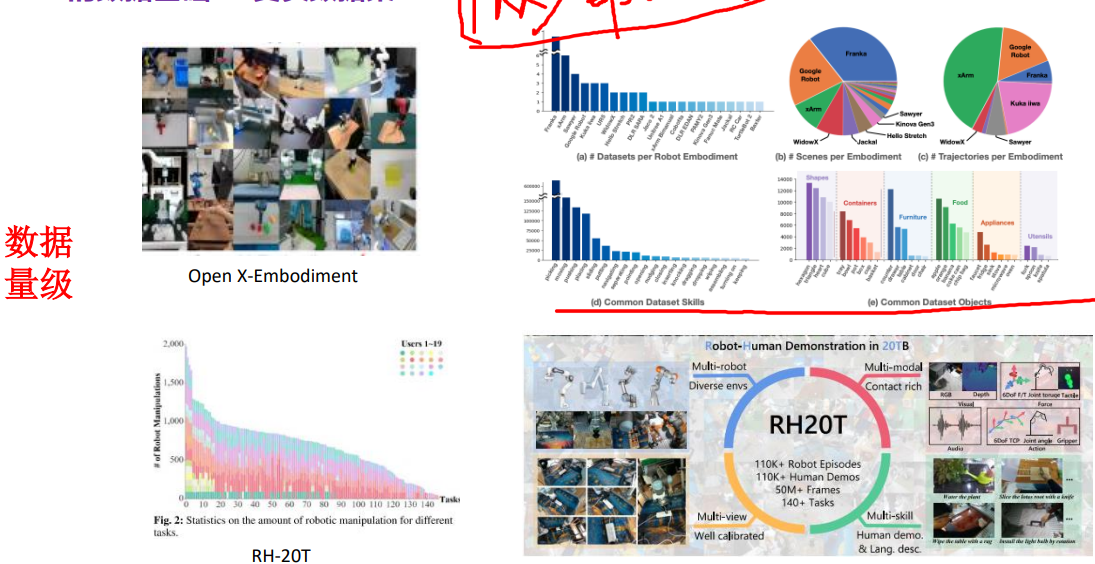
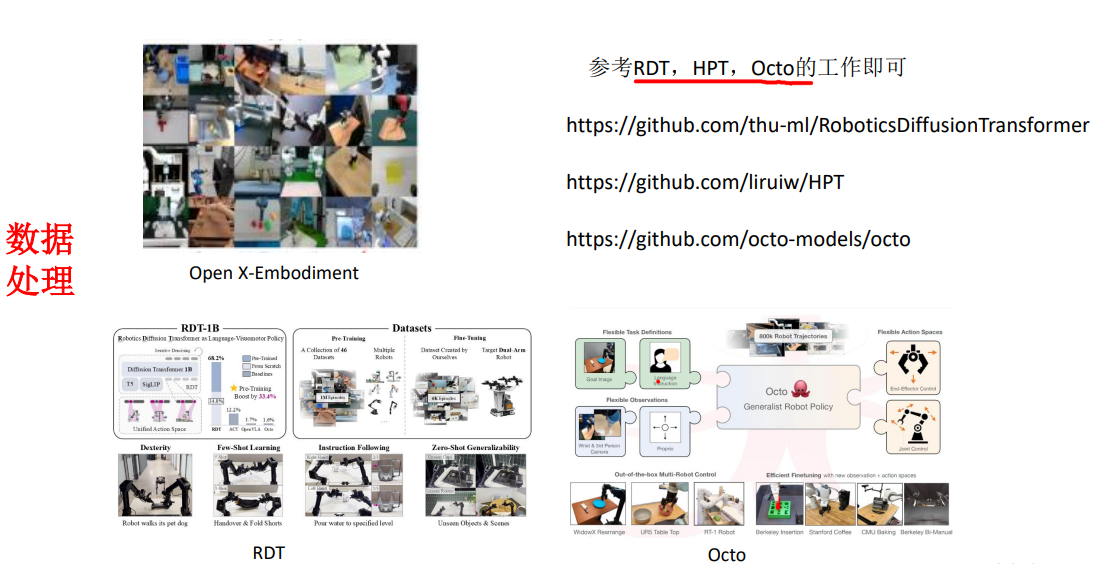
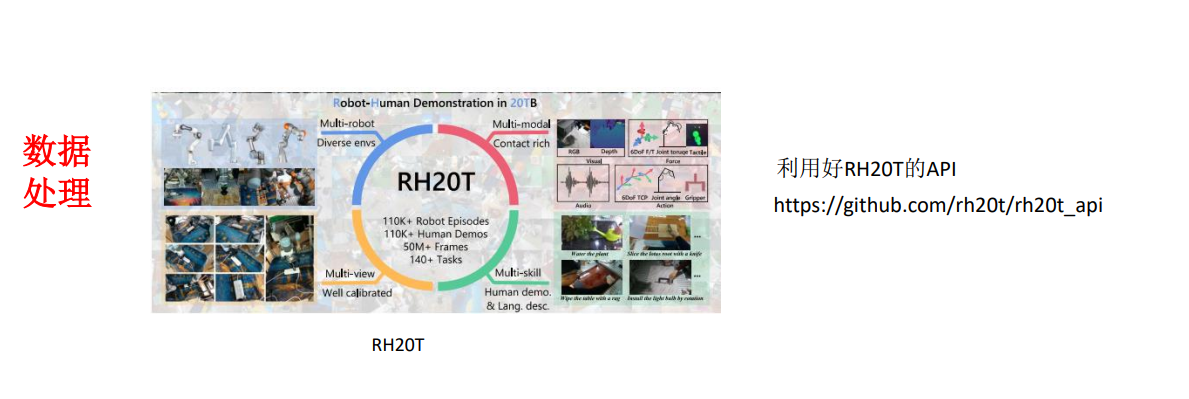
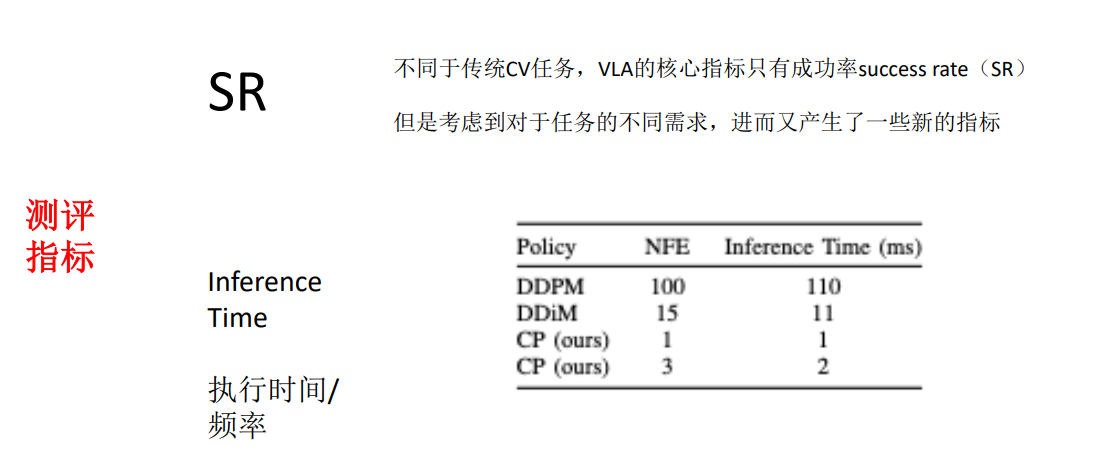
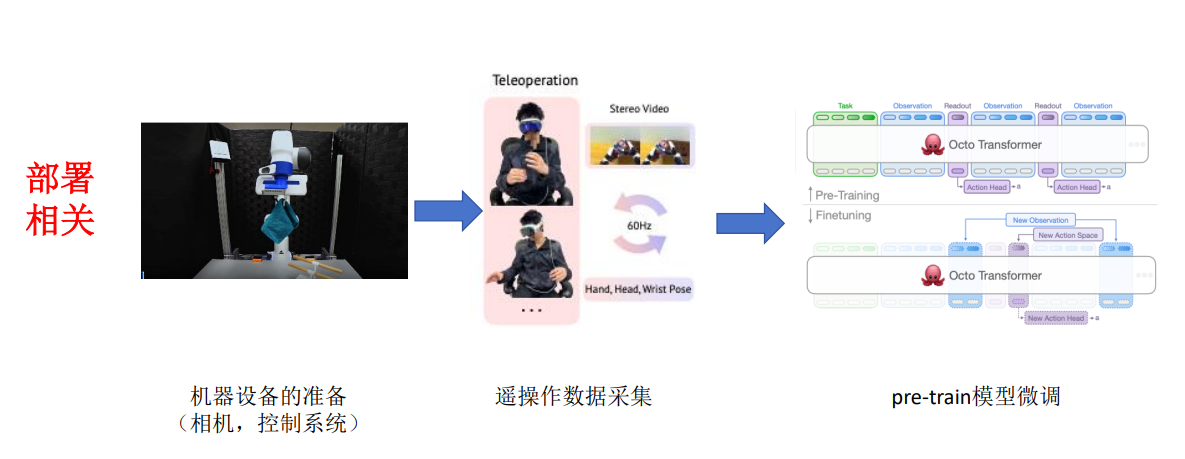
2.VLA的评测指标和部署相关
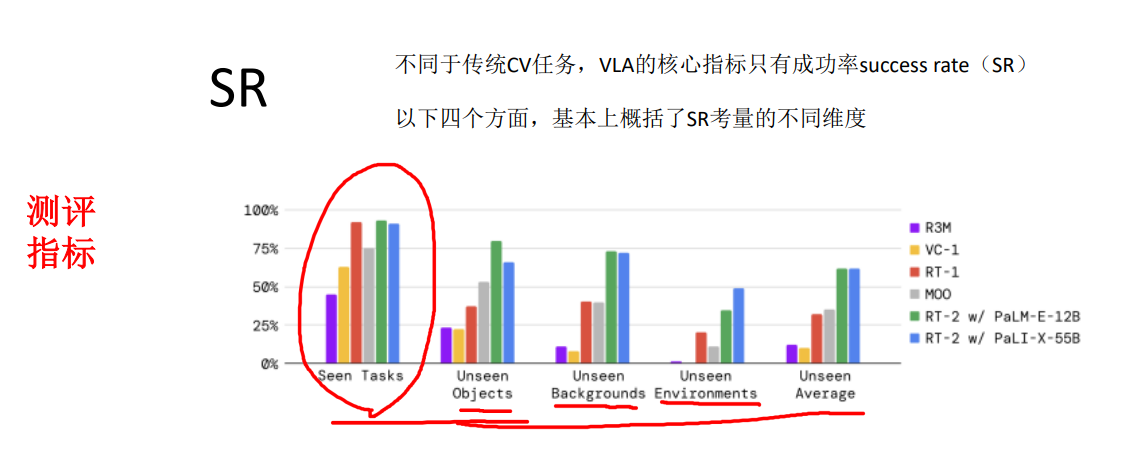
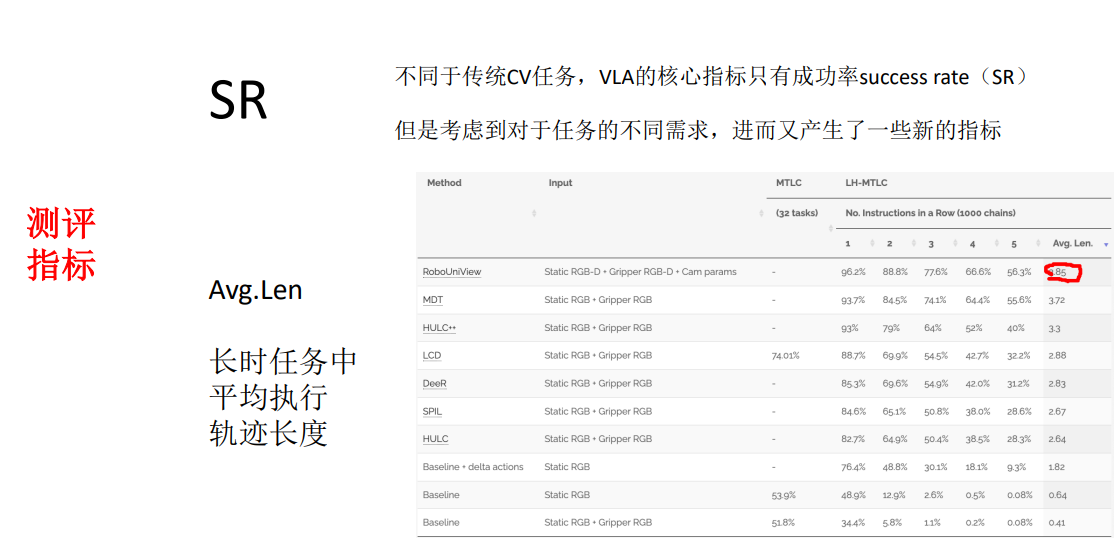
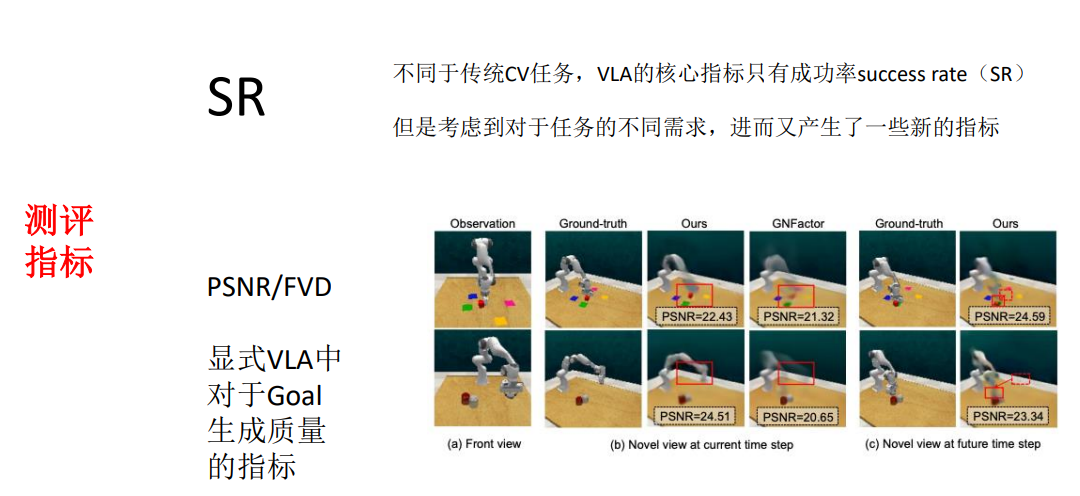

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)