阿里百炼之模型调优
模型调优包含模型微调(SFT)、继续预训练(CPT)、模型偏好训练(DPO)三种模型训练方式。
一、模型调优简介
模型调优包含模型微调(SFT)、继续预训练(CPT)、模型偏好训练(DPO)三种模型训练方式。
模型调优流程:
二、准备数据集&上传训练数据文件
测试的数据集可以从Hugging Face官网拿;也可以从自己的系统数据拿,来构建数据集文件。
https://huggingface.co/datasets
训练数据文件示例(CPT-文本生成训练集格式示例.jsonl文件):
{"text":"基本竞争战略是由美国哈佛商学院著名的战略管理学家迈克尔·波特提出的,分别为:成本领先战略,差异化战略,集中化战略.企业必须从这三种战略中选择一种,作为其主导战略.要么把成本控制到比竞争者更低的程度;要么在企业产品和服务中形成与众不同的特色,让顾客感觉到你提供了比其他竞争者更多的价值;要么企业致力于服务于某一特定的市场细分,某一特定的产品种类或某一特定的地理范围."}
{"text":"交通运行监测调度中心,简称TOCC(Transportation Operations Coordination Center)TOCC围绕综合交通运输协调体系的构建,实施交通运行的监测,预测和预警,面向公众提供交通信息服务,开展多种运输方式的调度协调,提供交通行政管理和应急处置的信息保障.\nTOCC是综合交通运行监测协调体系的核心组成部分,实现了涵盖城市道路,高速公路,国省干线三大路网,轨道交通,地面公交,出租汽车三大市内交通方式,公路客运,铁路客运,民航客运三大城际交通方式的综合运行监测和协调联动,在综合交通的政府决策,行业监管,企业运营,百姓出行方面发挥了突出的作用."}
{"text":"美国职业摄影师协会(简称PPA)创立于1880年,是一个几乎与摄影术诞生历史一样悠久的享誉世界的非赢利性国际摄影组织,是由世界上54个国家的25000余名职业摄影师个人会员和近二百个附属组织和分支机构共同组成的,是世界上最大的专业摄影师协会.本世纪初PPA创立了美国视觉艺术家联盟及其所隶属的美国国际商业摄影师协会,美国新闻及体育摄影师协会,美国学生摄影联合会等组织.PPA在艺术,商业,纪实,体育等摄影领域一直引领世界潮流,走在世界摄影艺术与技术应用及商业规划管理的最前沿."}
上传训练数据文件到阿里百炼:
curl --location --request POST \
'https://dashscope.aliyuncs.com/api/v1/files' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--form 'files=@"./qwen-fine-tune-sample.jsonl"' \
--form 'purpose="fine-tune"'\
--form 'descriptions="a sample fine-tune data file for qwen"'
返回结果:
{
"request_id":"xx",
"data":{
"uploaded_files":[{
"file_id":"976bd01a-f30b-4414-86fd-50c54486e3ef",
"name":"qwen-fine-tune-sample.jsonl"}],
"failed_uploads":[]}
}
如果您缺乏数据,建议构建智能体应用,使用知识库索引来增强模型能力。当然在很多复杂的业务场景,可以综合采用模型调优和知识库检索结合的技术方案。
数据处理支持用户使用多种模型算子,对模型调优所使用的训练集进行数据清洗和数据增强,从而获得更高质量的训练集。
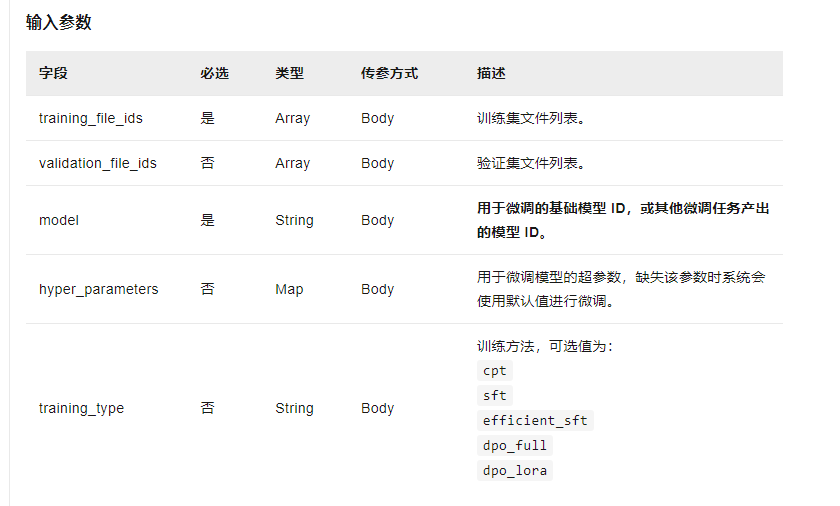
三、创建微调任务
curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' \
--data '{
"model":"qwen-turbo",
"training_file_ids":[
"<替换为训练数据集的file_id1>",
"<替换为训练数据集的file_id2>"
],
"hyper_parameters":{
"n_epochs":1,
"batch_size":16,
"learning_rate":"1.6e-5",
"split":0.9,
"warmup_ratio":0.0,
"eval_steps":1
},
"training_type":"sft"
}'
返回样例:
{
"request_id":"8ee17797-028c-43f6-b444-0598d6bfb0f9",
"output":{
"job_id":"ft-202410121111-a590",
"job_name":"ft-202410121111-a590",
"status":"PENDING",
"model":"qwen-turbo",
"base_model":"qwen-turbo",
"training_file_ids":[
"976bd01a-f30b-4414-86fd-50c54486e3ef"],
"validation_file_ids":[],
"hyper_parameters":{
"n_epochs":1,
"batch_size":16,
"learning_rate":"1.6e-5",
"split":0.9,
"warmup_ratio":0.0,
"eval_steps":1},
"training_type":"sft",
"create_time":"2024-10-12 11:55:45",
"user_identity":"1396993924585947",
"modifier":"1396993924585947",
"creator":"1396993924585947",
"group":"llm"
}
}
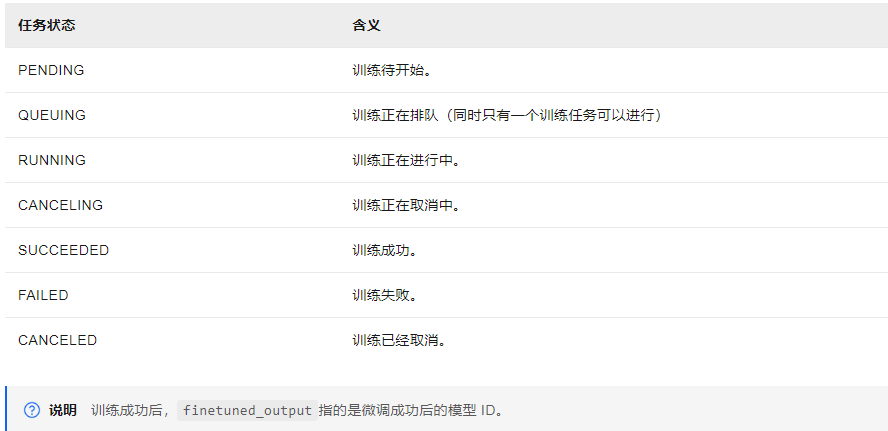
四、查询调优任务详情
在上一步的返回结果中获取到的job_id字段,为本次模型微调任务的ID,您可以使用该ID来查询此模型微调任务的状态。
curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<替换为您的微调任务 id>' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json'
返回成功样例:
{
"request_id":"c8b1d650-498e-432b-9346-c591e34e9622",
"output":{
"job_id":"ft-202410121111-a590",
"job_name":"ft-202410121111-a590",
"status":"SUCCEEDED",
"finetuned_output":"qwen-turbo-ft-202410121111-a590",
"model":"qwen-turbo",
"base_model":"qwen-turbo",
"training_file_ids":[
"976bd01a-f30b-4414-86fd-50c54486e3ef"],
"validation_file_ids":[],
"hyper_parameters":{
"n_epochs":1,
"batch_size":16,
"learning_rate":"1.6e-5",
"split":0.9,
"warmup_ratio":0.0,
"eval_steps":1},
"training_type":"sft",
"create_time":"2024-10-12 11:43:09",
"user_identity":"1396993924585947",
"modifier":"1396993924585947",
"creator":"1396993924585947",
"end_time":"2024-10-12 13:20:33",
"group":"llm",
"usage":3518670
}
}
五、获取调优任务日志
curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<替换为您的微调任务 id>/logs?offset=0&line=1000' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json'
训练成功返回结果:
{
"request_id":"1100d073-4673-47df-aed8-c35b3108e968",
"output":{
"total":57,
"logs":[
"<输出微调日志1>",
"<输出微调日志2>",
...
...
...
]
}
}
六、模型部署&调用
将微调任务成功后的模型 ID 作为创建模型服务的model_name参数。
curl --location 'https://dashscope.aliyuncs.com/api/v1/deployments' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' \
--data '{ "model_name": "<替换为微调任务成功后的模型 ID>", "capacity":2}'
返回结果:
{
"request_id":"865d7bd0-3f8f-4937-ad40-66361e6bc617",
"output":{
"deployed_model":"qwen-turbo-ft-202410121142-b631",
"gmt_create":"2024-10-12T15:59:55.494",
"gmt_modified":"2024-10-12T15:59:55.494",
"status":"PENDING",
"model_name":"qwen-turbo-ft-202410121142-b631",
"base_model":"qwen-turbo",
"base_capacity":2,
"capacity":2,
"ready_capacity":0,
"workspace_id":"llm-3z7uw7fwz0ve65pt",
"charge_type":"post_paid",
"creator":"1396993924585947",
"modifier":"1396993924585947"
}
}

七、查询模型部署的状态
curl --location 'https://dashscope.aliyuncs.com/api/v1/deployments/<替换为部署任务成功后的模型实例 ID>' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json'
八、模型调用
当模型部署状态为RUNNING时,您可以像调用其他模型一样使用微调后的模型。
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \
--header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \
--header 'Content-Type: application/json' \
--data '{
"model": "<替换为部署任务成功后的模型实例 ID>",
"input":{
"messages":[
{
"role": "user",
"content": "你是谁?"
}
]
},
"parameters": {
"result_format": "message"
}
}'
九、模型测评
阿里云百炼支持以下三种评测方式:人工评测、自动评测和基线评测。
- 人工评测:由您本人或您邀请的业务专家参与,基于选定的评测维度和评测集,对待测模型的输出效果进行人工评价。这种方式的优势在于业务专家能够通过实际操作产品等方式,来验证输出内容中的每个细节及步骤的正确性。但局限性也很明显,即评测成本较高、效率低,并且多人评测时可能会受到主观因素的干扰。
- 自动评测:全过程无需人工参与,阿里云百炼将基于内置的深度学习指标(包括BLEU、ROUGE和F1)和AI评测器,自动对模型的输出效果进行评分。这种方式的优势在于高效率以及评测的公正性。局限性在于AI评测器的评测效果高度依赖于人为初始设定的评分维度、步骤和标准,并且它无法像人工评测那样验证输出内容中每个细节和步骤的正确性。
- 基线评测:基于预置基线评测集(包括C-Eval/CMMLU等主流榜单评测集)对待测模型的各项基础通用能力进行自动评测,适用于对已调优模型的基本效果进行回归评测(虽然调优有可能提升模型在特定任务上的效果,但有时也会降低模型的通用能力),避免模型通用能力的下降和丢失。
通常最佳实践是将上述三种评测方式结合起来。一个可能的场景是:先通过初始的人工评测确定一套评测维度,并形成配套可自动化执行的评分步骤和标准。再将这一整套评分体系应用于自动评测中,让阿里云百炼按照设定进行自动评测,快速从多个候选模型中选出最优者。最后通过人工评测仔细对比模型输出在结构组织、伦理合规等方面的细微差异。如果针对特定领域进行了模型调优,同时希望确保模型的通用能力没有明显下降,则可以进行基线评测。
三合一评测代码示例:
class HybridModelEvaluator:
"""
混合评测系统 - 结合人工、自动化和基线评测
"""
def __init__(self, domain: str):
self.domain = domain
self.results = {}
def run_complete_evaluation(self,
candidate_models: List[str],
test_questions: Dict[str, List[str]],
baseline_datasets: Dict[str, Any]]):
"""执行完整的混合评测流程"""
print("🚀 开始三合一模型评测...")
# 1. 人工评测建立标准
print("\n=== Phase 1: 人工评测建立标准 ===")
human_standards = self._human_evaluation_phase(candidate_models[0], test_questions))
# 2. 自动化评测快速筛选
print("\n=== Phase 2: 自动化评测筛选 ===")
automated_scores = self._automated_evaluation_phase(candidate_models, test_questions)))
# 3. 基线评测验证稳定性
print("\n=== Phase 3: 基线评测验证 ===")
baseline_results = self._baseline_evaluation_phase(candidate_models[0],
candidate_models[1],
baseline_datasets))
# 综合评分
final_scores = self._calculate_hybrid_scores(human_standards, automated_scores, baseline_results))
return final_scores
def _human_evaluation_phase(self, reference_model: str, test_questions: Dict):
"""人工评测阶段 - 建立质量标准"""
# 选择代表性样本进行深度评测
representative_samples = self._select_representative_samples(test_questions)))
human_scores = {}
for category, questions in test_questions.items():
print(f"\n📝 人工评测类别: {category}")
evaluation_results = []
for q_idx, question in enumerate(questions[:10]): # 精选10个问题进行深度评测
reference_answer = get_model_response(reference_model, question))
# 邀请专家团队进行评分
expert_scores = self._conduct_expert_evaluation(question, reference_answer))
evaluation_results.append({
"question": question,
"reference_answer": reference_answer,
"expert_scores": expert_scores
})
return evaluation_results
def _automated_evaluation_phase(self, models: List[str], test_questions: Dict):
"""自动化评测阶段 - 快速筛选"""
# 实现前面提到的 automated_evaluation_pipeline
return automated_scores
def _baseline_evaluation_phase(self, base_model: str, tuned_model: str, datasets: Dict)):
# 实现前面提到的 baseline_comparison_evaluation
return baseline_results
def _calculate_hybrid_scores(self, human_scores, auto_scores, baseline_scores):
"""综合计算混合评分"""
hybrid_scores = {}
for model_name in models:
# 权重分配:人工40% + 自动30% + 基线30%
human_weight = 0.4
auto_weight = 0.3
baseline_weight = 0.3
weighted_score = (
human_scores.get(model_name, {}).get('average', 3) * human_weight +
auto_scores.get(model_name, {}).get('overall', 3) * auto_weight +
baseline_scores.get(model_name, {}).get('performance', 3) * baseline_weight
)
hybrid_scores[model_name] = {
"weighted_score": round(weighted_score, 2),
"human_score": human_scores.get(model_name, {}),
"auto_score": auto_scores.get(model_name, {}),
"baseline_score": baseline_scores.get(model_name, {}),
"ranking": None
}
# 排名
ranked_models = sorted(hybrid_scores.items(), key=lambda x: x[1]['weighted_score'], reverse=True))
for rank, (model, scores) in enumerate(ranked_models):
hybrid_scores[model]["ranking"] = rank + 1
return hybrid_scores

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)