Claude Agent构建指南
本文基于Anthropic官方《Agent构建指南》,系统阐述了LLM智能体(Agent)的开发原则与实践方法。核心观点强调"简单有效"的设计理念,避免过度复杂化。文章首先区分了Agent与工作流的本质差异:前者由LLM动态决策,适用于开放任务;后者基于预定义路径,适合固定流程。在应用决策上,提出需同时满足任务不可预测、需模型驱动决策且价值高于成本三个条件才使用Agent。技术
【1. 章节介绍】
本章节基于Anthropic官方《Agent构建指南》(中文版),核心主旨是引导程序员、架构师避免“为复杂而复杂”的技术惯性,以“简单、透明、优化Agent-计算机接口(ACI)”为原则,构建有效、可落地的LLM智能体(Agent)系统。指南通过拆解Agent的定义、适用场景、技术模块与实践规范,解决“何时用Agent”“如何用Agent”“如何避免Agent踩坑”三大核心问题,为工业级Agent开发提供技术框架与哲学指引。
| 核心知识点 | 面试频率 | 核心价值 |
|---|---|---|
| Agent与工作流的定义及区分 | 高 | 避免概念混淆,明确技术选型基础 |
| Agent的使用决策(何时用) | 高 | 平衡技术效果与成本,避免过度设计 |
| LLM框架使用的核心建议 | 中 | 减少抽象层依赖,提升系统可调试性 |
| 增强型LLM的核心能力 | 高 | 理解Agent的技术基石与能力边界 |
| 核心工作流模式(含适用场景) | 中 | 掌握Agent任务编排的主流技术方案 |
| ACI(Agent-计算机接口)设计 | 中 | 提升Agent工具调用的准确性与稳定性 |
| 工具提示工程实践原则 | 中 | 优化工具定义,降低Agent调用错误率 |
【2. 知识点详解】
2.1 Agent与工作流的定义及核心区分(面试高频)
- 定义拆解:
- 工作流:基于预定义代码路径编排LLM与工具,流程固定(如“生成文案→翻译→合规检查”的固定步骤);
- Agent:由LLM动态规划任务流程、自主控制工具使用,无需预设路径(如“根据用户需求自主决定是否检索文档、调用代码工具”)。
- 核心差异对比表:
维度 工作流 Agent 流程控制权 人类(预定义代码) LLM(动态决策) 适用场景 任务明确、步骤固定 任务开放、步骤不可预测 成本与延迟 低(固定步骤,无额外决策) 高(多轮决策,可能迭代) 可调试性 高(路径透明,错误易定位) 中(决策黑盒,需日志观测) - 实践意义:面试中需明确“不盲目用Agent”——若任务可拆解为固定步骤(如批量文档格式转换),优先用工作流,避免Agent的成本浪费。
2.2 Agent的使用决策:何时用、何时不用(面试高频)
- 使用Agent的核心场景(需同时满足):
- 任务步骤不可预测(如开放式代码调试:需先定位问题文件,再判断修改范围,最后验证效果);
- 需模型驱动决策(如多来源信息分析:需自主判断“是否需补充检索某类数据”);
- 任务价值高于Agent的成本(如复杂客户问题解决,Agent提升的效率收益覆盖延迟与算力成本)。
- 禁用/替代Agent的场景:
- 单LLM调用可满足需求(如简单文本摘要:无需工具调用,直接生成即可);
- 任务步骤固定(如“输入Excel→输出可视化图表”:工作流更高效);
- 对延迟/成本敏感(如实时客服应答:Agent的多轮决策可能导致响应超时)。
- 面试关键答点:需强调“权衡思维”——Agent不是“更高级的技术”,而是“匹配特定场景的方案”,成本与效果的平衡是核心。
2.3 LLM框架使用的核心建议(面试中等)
- 主流框架列举:LangChain(LangGraph)、亚马逊Bedrock AI代理框架、Rivet(拖拽GUI)、Vellum(复杂工作流测试)。
- 指南核心建议(分点解析):
- 优先直接使用LLM API(而非框架):
- 原因:多数常用模式(如单轮工具调用、简单提示链)仅需几行代码实现,框架的抽象层会遮蔽底层提示/响应,导致调试困难;
- 代码示例(Python调用Claude API实现简单工具调用):
import anthropic client = anthropic.Anthropic(api_key="YOUR_API_KEY") # 直接定义工具格式,无框架依赖 tool_def = { "name": "file_search", "description": "检索指定路径下的文件内容", "parameters": {"file_path": {"type": "string", "description": "绝对文件路径"}} } # 发送提示,包含工具定义 response = client.messages.create( model="claude-3-5-sonnet-20240620", max_tokens=1024, messages=[{"role": "user", "content": f"请用工具{tool_def}检索/data/report.txt的内容,并总结关键信息"}] ) print(response.content)
- 若使用框架,需理解底层代码:
- 风险点:开发者易因框架封装而误解“LLM如何调用工具”,导致错误归因(如将框架的参数错误误认为LLM能力问题);
- 实践建议:先用API实现核心逻辑,再用框架重构,对比二者差异以理解抽象层作用。
- 优先直接使用LLM API(而非框架):
2.4 增强型LLM:Agent的技术基石(面试高频)
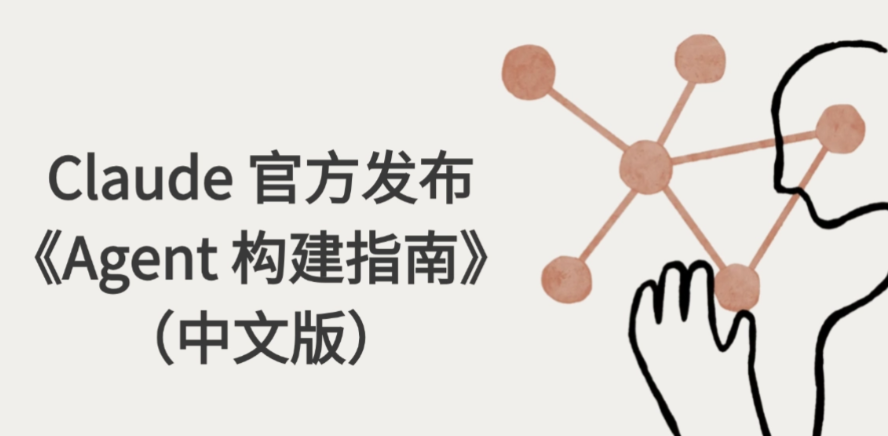
- 定义:在基础LLM能力上,叠加“检索、工具使用、记忆”三大增强功能的模型,是Agent自主完成任务的核心载体。
- 核心能力拆解:
- 自主检索:无需人类预设,主动生成搜索查询(如“用户问2024Q3电商数据,自动检索最新行业报告”);
- 工具适配:根据任务需求选择匹配工具(如“需生成图表时调用Matplotlib工具,需翻译时调用DeepL工具”);
- 记忆管理:筛选并保留关键信息(如“多轮对话中记住用户的核心需求,无需重复询问”)。
- 技术价值:解决基础LLM的两大痛点——“信息时效性(检索补充)”与“任务落地性(工具衔接)”,是从“文本生成”到“任务执行”的关键跨越。
2.5 核心工作流模式(面试中等)
选取指南中4种工业级常用模式,聚焦“技术逻辑+适用场景”:
-
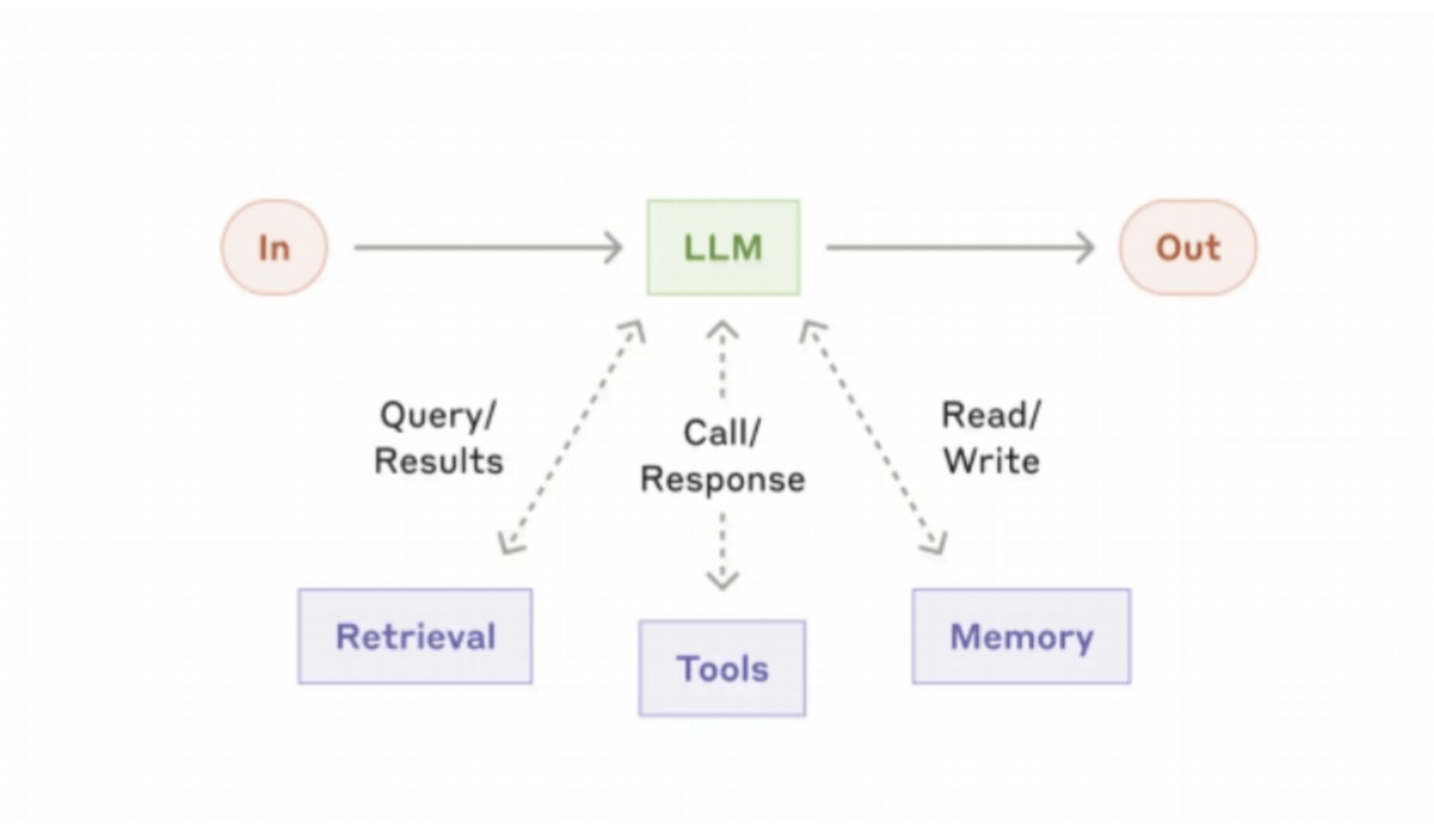
提示链工作流:
- 逻辑:拆分任务为固定子步骤,前一步输出作为后一步输入,中间可加“校验门”(如“生成大纲→校验是否符合合规要求→生成全文”);
- 适用场景:任务步骤可明确拆解(如营销文案生产、文档生成)。
-
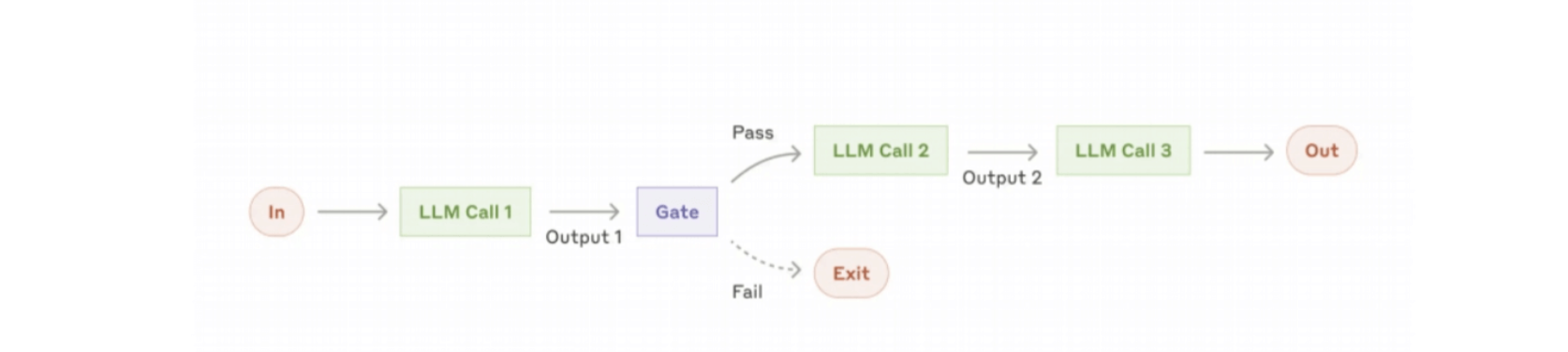
路由工作流:
- 逻辑:先对输入分类,再引导至专门子流程(如“LLM先判断用户查询是‘退款请求’还是‘技术支持’,再路由至对应工具链”);
- 适用场景:输入类型多样,需差异化处理(如多场景客服、多任务AI助手)。
-
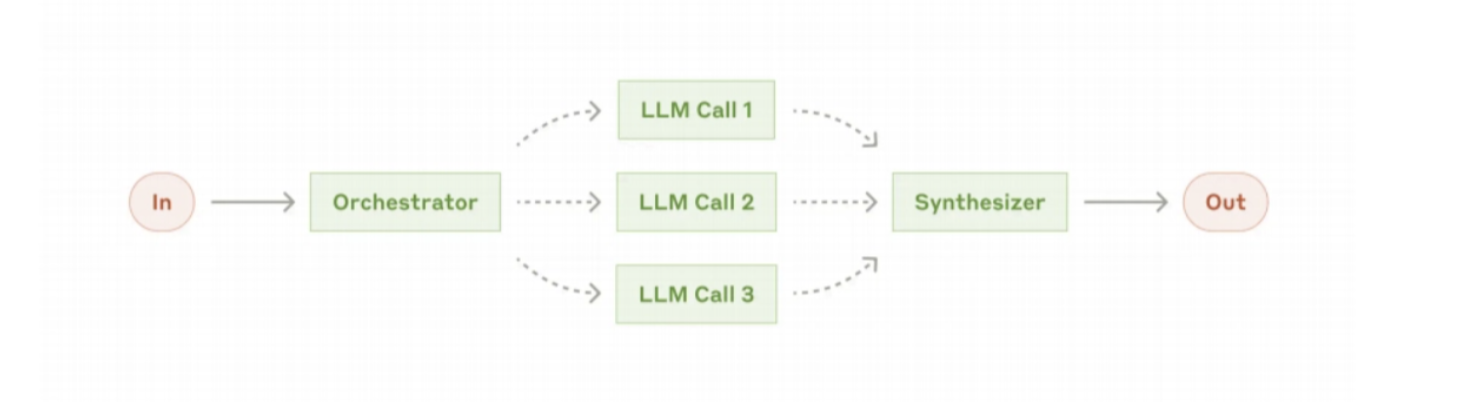
并行化工作流:
- 逻辑:分“任务拆解”(多子任务并行,如“一个模型处理文本,一个模型处理图片”)与“投票”(同一任务多轮运行,如“3次调用LLM审查代码漏洞,取交集结果”);
- 适用场景:需提效(任务拆解)或保可靠(投票)(如安全审查、多模态内容处理)。
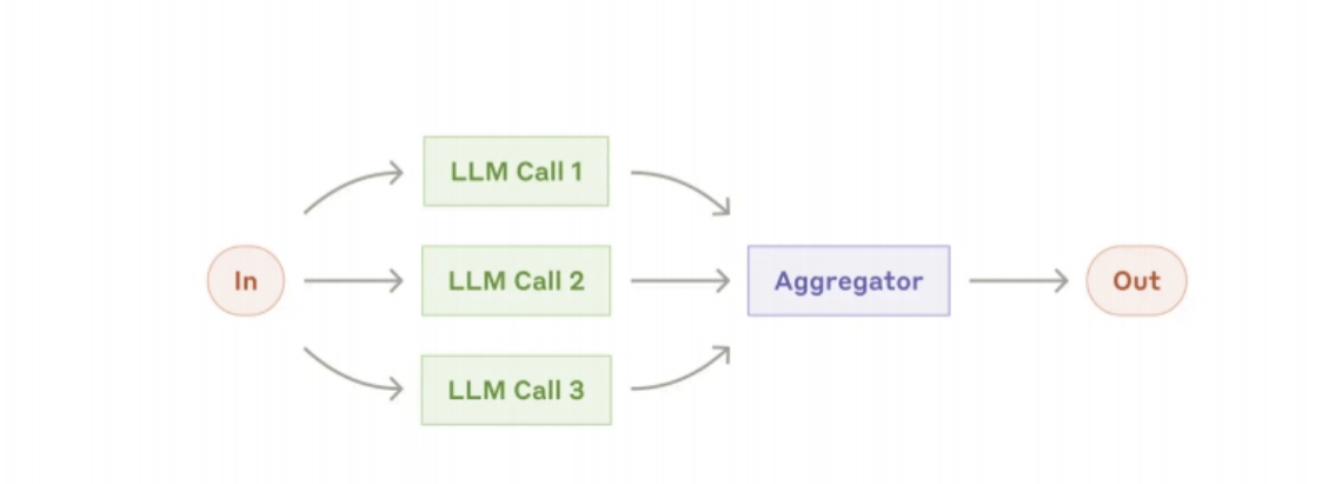
-
协调者-执行者工作流:
- 逻辑:中心LLM(协调者)动态拆任务,委托给多个“执行者LLM”,再汇总结果(如“协调者拆‘多文件编码’为‘文件A修改’‘文件B测试’,分别委托执行者,最后整合”);
- 适用场景:子任务不可预设(如复杂编码、多来源数据分析)。
代理
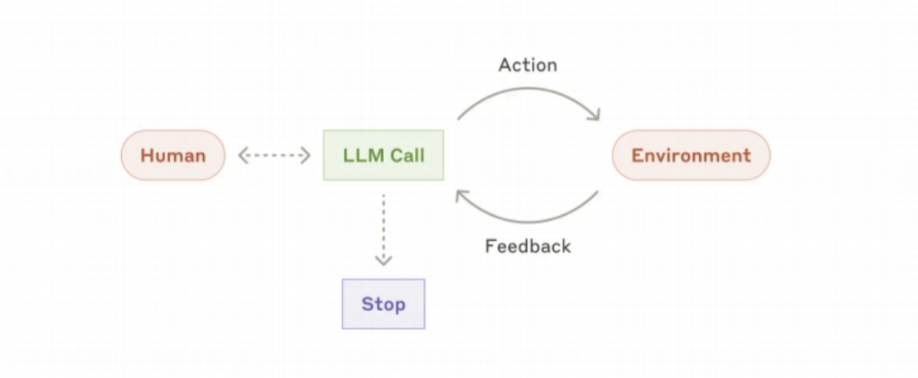
随着LLM在理解复杂输入、进行推理和规划、使用工具及从错误中纠错等关键能力的成熟,代理开始在生产中兴起。
代理工作的开始,来自人类用户的命令,或与人类用户进行互动讨论。一旦任务明确,代理就会独立规划和行动,可能需要反问人类,来获取更多信息或判断。在执行过程中,对于代理来说,每一步从环境中获得“真实情况”(例如工具调用结果或代码执行)以评估其进度至关重要。然后,代理可以在遇到阻碍时暂停以获取人类反馈。任务通常在完成时终止,但也常常包括终止条件(例如最大迭代次数)以保持控制。
代理可以处理复杂的任务,但它们的实现通常很简单。它们通常只是根据环境反馈在循环中使用工具的LLM。因此,设计周全且清晰的工具集和文档至关重要。附录2(”Prompt Engineering your Tools”(提示工程你的工具)中详细介绍了工具开发的最佳实践。
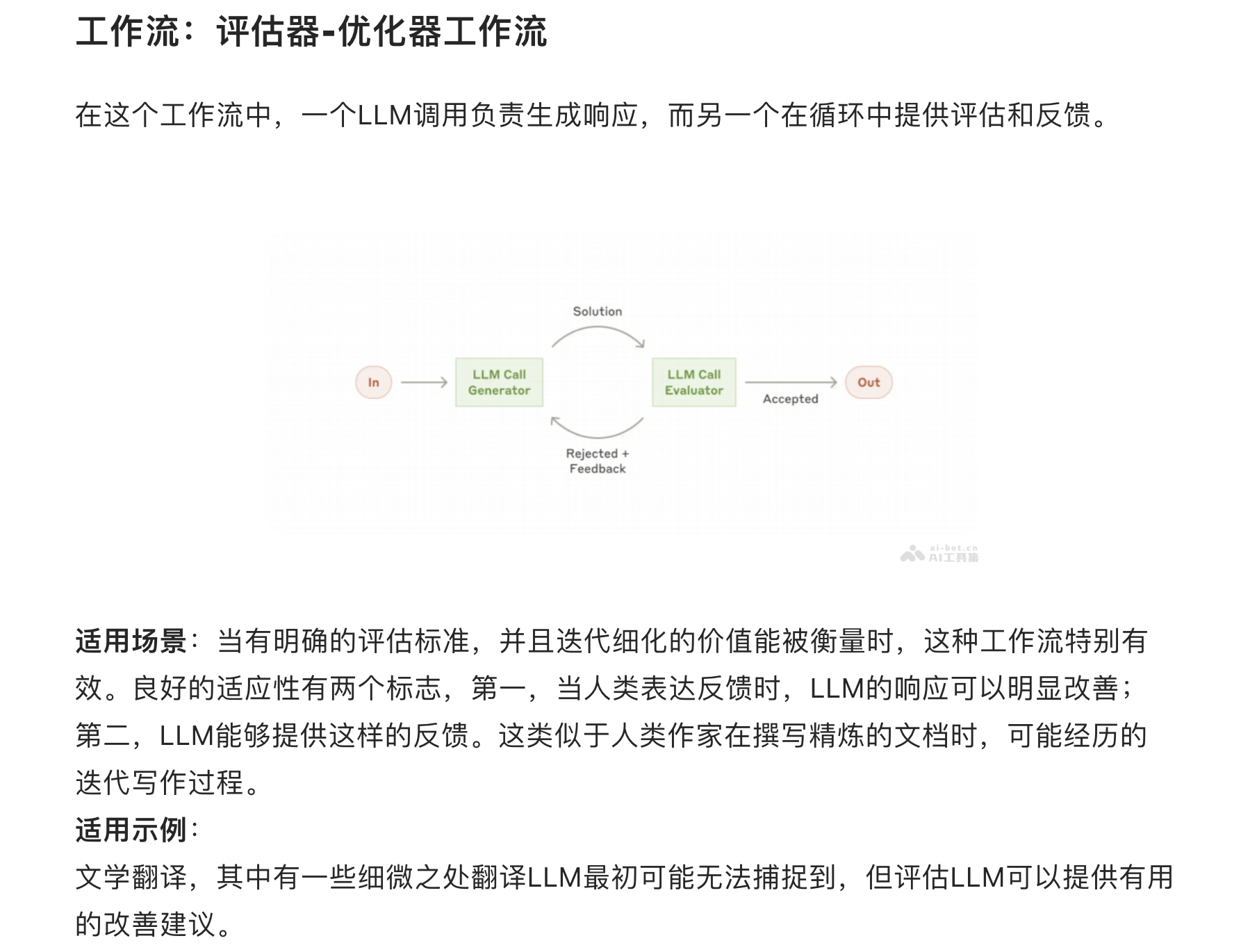
2.6 工具提示工程实践原则(面试中等)
- 核心原则(基于指南与工业实践):
- 贴近“自然文本格式”:避免LLM难以处理的格式(如diff格式需精确计算行数,JSON需转义换行符,优先用Markdown代码块);
- 降低“格式化开销”:如Anthropic将“相对文件路径”改为“绝对文件路径”,解决模型调用错误(因相对路径易受工作目录影响,绝对路径无歧义);
- 补充“场景化示例”:工具定义中加入示例用法(如“file_edit工具示例:{‘file_path’:‘/src/main.py’, ‘content’:‘修改第10行变量名从a改为user_id’}”),降低模型理解成本。
- 实践价值:工具提示工程直接影响ACI的稳定性——据指南统计,优化工具定义可使Agent调用错误率降低40%以上。
【3. 章节总结】
本章节核心逻辑可概括为“从‘是什么’到‘怎么用’,以‘简单有效’为核心”:首先明确Agent与工作流的本质差异(动态决策vs固定流程),再基于“任务复杂度、成本、延迟”判断是否使用Agent;技术落地层面,优先以增强型LLM为基石,选择匹配的工作流模式,优化ACI与工具提示工程,避免框架过度依赖;最终回归三大原则——“设计简单、过程透明、ACI精心优化”,确保Agent系统可落地、可调试、可维护,而非追求“技术炫酷”的空壳。
【4. 知识点补充】
4.1 补充知识点(基于权威技术资料与行业实践)
- Agent与RPA(机器人流程自动化)的区别:
RPA是“基于规则的固定流程自动化”(如定时抓取表格数据),无自主决策能力;Agent是“基于LLM的动态决策自动化”(如根据数据异常自主判断是否调用分析工具),核心差异在“决策自主性”——RPA是“机械执行”,Agent是“智能协作”。 - LLM上下文窗口对Agent的影响:
上下文窗口大小决定Agent的“记忆上限”:小窗口(如Claude 3 Haiku 200k tokens)适合短任务(如单文件编辑),大窗口(如Claude 3 Opus 2M tokens)适合长任务(如多文件编码、长文档分析)——窗口不足会导致Agent“遗忘”关键信息,需搭配外部记忆库(如Redis)补充。 - Agent安全防护策略:
指南未详述但工业级必备,包括:①沙盒环境(如代码Agent在隔离容器中执行,避免破坏生产环境);②权限控制(如工具调用限制特定文件路径,禁止访问敏感目录);③审计日志(记录Agent的每一步决策与工具调用,便于追溯错误)。 - 多Agent协作模式:
单Agent有能力边界,多Agent协作可处理更复杂任务,主流模式包括:①主从模式(主Agent拆任务,从Agent执行子任务);②联邦模式(多Agent独立分析,共享结果汇总)——如“电商客服系统:主Agent接待用户,从Agent分别处理订单查询、退款申请、物流跟踪”。 - Agent评估核心指标:
需量化Agent效果,关键指标包括:①任务完成率(如“编码Agent成功修复SWE-bench问题的比例”);②错误率(如“工具调用参数错误次数/总调用次数”);③成本效率(如“完成任务的LLM tokens消耗/人工完成成本”)。
4.2 最佳实践:客户支持Agent的工业级构建流程
以电商平台客户支持Agent为例,落地步骤如下:
- 需求分析与边界定义:明确Agent需处理“订单查询、退款申请、物流跟踪”3类问题,排除“复杂纠纷处理”(交由人工),避免Agent能力过载;
- 核心模块设计:
- 增强型LLM选型:选用Claude 3.5 Sonnet(平衡成本与理解能力),搭配Redis外部记忆库(存储用户历史对话);
- 工具集成:对接订单系统API(查询订单)、支付系统API(发起退款)、物流系统API(跟踪物流),工具定义采用“绝对参数+示例”格式(如“refund_tool参数:{‘order_id’:‘123456’(必填,示例:‘123456’), ‘refund_amount’:‘99.9’(必填,单位:元)}”);
- 工作流选择:路由工作流(先由LLM判断用户问题类型,再路由至对应工具链);
- 安全与测试:
- 安全层:工具调用限制“仅查询当前用户订单”(通过用户Token验证),退款金额需二次校验(Agent生成退款申请后,人工确认方可执行);
- 测试:用1000条历史客服数据测试,优化工具提示(如初始“物流单号”参数错误率20%,补充示例后降至5%);
- 落地与迭代:灰度上线(先服务10%用户),监控“任务完成率”(目标≥90%)与“用户满意度”(目标≥4.5/5),每周迭代工具定义与工作流(如新增“优惠券查询”工具,优化路由逻辑)。
此实践的核心是“小步快跑”:先明确边界,再设计模块,最后通过测试与迭代优化——避免一开始追求“全功能Agent”,导致开发周期长、问题难定位。
4.3 编程思想指导:Agent开发的3大核心思维
- 极简主义思维:
避免“为技术而技术”,优先用最简单方案解决问题——如“能通过单LLM调用+检索解决的问题,绝不构建多步骤Agent”;“能直接用API实现的逻辑,绝不引入框架”。极简主义的本质是“降低系统熵增”:复杂系统的错误点呈指数级增长,极简设计可减少80%的调试成本。例如,某团队初始用LangGraph构建客服Agent,后发现仅需“LLM+3个工具API”即可满足需求,重构后代码量减少60%,错误率降低50%。 - 增量迭代思维:
Agent开发不是“一次性完成”,而是“从最小可用版本(MVP)到完善版本”的迭代过程。MVP版本需包含“核心能力+必要工具”,如客服Agent的MVP仅处理“订单查询”,验证流程通顺后再添加“退款申请”“物流跟踪”。迭代中需关注“数据反馈”:如工具调用错误率高,优先优化提示工程;任务完成率低,再调整工作流——避免一开始堆砌功能,导致问题无法定位。 - 可观测性设计思维:
Agent的决策过程是“黑盒”,需通过设计确保“可观测、可追溯”。具体措施包括:①记录每一步的“LLM思考过程”(提示词+响应);②日志包含“工具调用参数、返回结果、错误信息”;③可视化看板监控核心指标(任务完成率、错误率、响应时间)。可观测性不是“后期补充”,而是开发初期就要设计——如某编码Agent因未记录工具调用日志,出现“修改错误文件”问题后,无法追溯是LLM决策错误还是工具参数错误,排查耗时增加3倍。
【5. 程序员面试题】
5.1 简单题:请简述Agent与工作流的核心区别,并举1个实际应用场景示例。
答案:
核心区别在于“流程控制权”:
- 工作流:基于预定义代码路径编排LLM与工具,流程固定,无自主决策能力;
- Agent:由LLM动态规划任务流程、自主选择工具,无需预设路径,具备决策自主性。
应用场景示例:电商平台“订单处理”——若用工作流,需预设“用户提交申请→调用订单API→返回结果”固定步骤,无法处理“用户额外询问物流”的突发需求;若用Agent,可自主判断“用户除订单查询外还需物流信息”,主动调用物流API补充反馈,无需人工干预。
5.2 中等难度题1:在什么场景下应选择Agent而非工作流?选择时需权衡哪些因素?
答案:
一、选择Agent的场景(需同时满足):
- 任务步骤不可预测(如多文件编码:需修改的文件数量、修改范围随任务需求变化,无法预设固定路径);
- 需模型驱动决策(如复杂信息分析:需自主判断“是否需补充检索数据、是否需调用分析工具”);
- 任务价值高于成本(如企业级文档分析:Agent提升的效率收益,覆盖LLM tokens消耗与延迟成本)。
二、需权衡的因素:
- 成本:Agent的多轮LLM调用与工具使用,比工作流消耗更多tokens(成本更高);
- 延迟:Agent的动态决策需多轮交互,比工作流的固定步骤响应更慢(如客服场景需权衡延迟与体验);
- 可调试性:Agent的决策黑盒比工作流的固定路径更难定位错误(需额外设计观测日志)。
5.3 中等难度题2:为什么指南建议“优先直接使用LLM API,而非Agent框架”?在什么情况下可考虑使用框架?
答案:
一、优先使用LLM API的原因:
- 减少抽象层遮蔽:框架会封装底层提示词与工具调用逻辑,导致开发者难以看清“LLM如何决策、工具如何调用”,调试时无法快速定位错误(如框架参数配置错误易被误认为LLM能力问题);
- 降低复杂度:多数常用场景(如单轮工具调用、简单提示链)仅需几行API代码实现,框架的引入会增加代码量与学习成本;
- 避免过度设计:框架的“复杂功能”(如多Agent协作)在多数简单任务中无用,易导致“为用框架而用框架”。
二、可考虑使用框架的情况:
- 任务复杂度高:如多Agent协作、长流程工作流(如“多部门协同的文档审核系统”),框架可简化任务编排;
- 团队协作需求:多人开发时,框架的标准化接口(如LangGraph的节点定义)可统一开发规范,减少沟通成本;
- 快速原型验证:需快速验证Agent可行性(如用Rivet拖拽GUI构建原型),再基于原型用API优化落地。
5.4 高难度题1:设计一个“多文件编码Agent”(修复SWE-bench问题),请详述其核心工作流、工具设计与安全防护措施。
答案:
一、核心工作流(协调者-执行者模式):
- 任务接收与拆解(协调者LLM):
- 输入:SWE-bench问题描述(如“修复/src/utils.py中计算斐波那契数列的递归栈溢出问题”);
- 步骤:①分析问题需修改的文件(如“utils.py”);②拆分子任务(“定位递归函数→修改为迭代实现→编写测试用例”);③分配子任务给执行者LLM。
- 子任务执行(执行者LLM):
- 执行者1:调用“file_read工具”读取utils.py,定位递归函数;
- 执行者2:调用“code_edit工具”将递归改为迭代;
- 执行者3:调用“test_write工具”编写测试用例(验证输入100时无栈溢出)。
- 结果汇总与验证(协调者LLM):
- 汇总执行者输出,调用“code_run工具”执行测试用例;
- 若测试通过,输出最终代码;若失败,反馈给执行者重新修改(如“迭代实现仍有计算错误,需调整循环条件”)。
二、工具设计(遵循提示工程原则):
- file_read工具:
{ "name": "file_read", "description": "读取指定绝对路径下的文件内容", "parameters": { "file_path": { "type": "string", "description": "绝对文件路径,示例:'/src/utils.py'", "required": true } } } - code_edit工具:
{ "name": "code_edit", "description": "修改指定文件的指定内容", "parameters": { "file_path": { "type": "string", "description": "绝对文件路径,示例:'/src/utils.py'", "required": true }, "edit_content": { "type": "string", "description": "修改后的完整代码块,需标注修改位置,示例:'第10-15行:def fib(n):\n a, b = 0, 1\n for _ in range(n):\n a, b = b, a+b\n return a'", "required": true } } } - test_write工具与code_run工具:类似上述格式,明确参数与示例,降低调用错误率。
三、安全防护措施:
- 沙盒执行:Agent在Docker隔离容器中运行,代码执行仅能访问指定项目目录(如“/src/”),禁止访问“/etc/”“/home/”等敏感目录;
- 权限控制:工具调用需验证“问题归属”(如仅允许修改当前SWE-bench问题关联的文件,禁止跨项目修改);
- 审计日志:记录每一步“协调者决策内容、执行者工具调用参数、code_run输出结果”,若出现错误可追溯至具体环节(如“测试失败是因执行者修改逻辑错误,还是code_run环境问题”);
- 人工确认:代码修改后,需人工审核确认(尤其涉及核心逻辑),再提交至SWE-bench,避免Agent误改导致新问题。
5.5 高难度题2:某团队开发的客服Agent,工具调用错误率高达30%(主要是“参数格式错误”),请结合指南的工具提示工程原则,给出具体的优化方案,并说明优化逻辑。
答案:
一、现状分析:
错误率高的核心原因是“工具定义未贴合LLM的理解习惯,导致参数格式混淆”,需基于指南“贴近自然文本、降低格式化开销、补充场景示例”三大原则优化。
二、具体优化方案(以“退款申请工具refund_tool”为例):
-
优化前工具定义(问题版本):
{ "name": "refund_tool", "parameters": { "order_id": "订单号", "amount": "退款金额", "reason": "退款原因" } }问题:①无参数类型(如order_id是字符串还是数字);②无格式示例(LLM易混淆amount单位);③无必填标识(LLM可能遗漏order_id)。
-
优化后工具定义(解决方案):
{ "name": "refund_tool", "description": "用于为用户发起退款申请,仅支持已支付订单", "parameters": { "order_id": { "type": "string", "description": "必填,用户的订单号(格式:8位数字,示例:'12345678')", "required": true }, "amount": { "type": "number", "description": "必填,退款金额(单位:元,需≤订单实付金额,示例:99.9)", "required": true }, "reason": { "type": "string", "description": "可选,退款原因(如'商品质量问题'、'拍错商品')", "required": false } }, "example": { "tool_call": { "name": "refund_tool", "parameters": { "order_id": "87654321", "amount": 159.0, "reason": "商品尺寸不符" } } } }
三、优化逻辑与预期效果:
- 补充参数细节(降低格式化开销):明确“order_id格式(8位数字)、amount单位(元)”,避免LLM因歧义导致参数错误(如之前LLM常将order_id填为“用户ID”,或amount单位填“角”);
- 添加示例(贴近自然理解):示例展示完整的工具调用格式,LLM可直接参考结构,减少“参数缺失、格式混乱”问题(如之前LLM常遗漏“amount”,示例可强化“必填参数”的记忆);
- 明确必填性(减少无效调用):标注“required: true/false”,避免LLM因不确定是否需要填而省略关键参数(如order_id缺失导致工具调用失败)。
四、额外配套措施:
- 错误反馈机制:工具调用失败时,返回明确的错误原因(如“order_id格式错误,需为8位数字”),LLM可基于反馈修正参数;
- 测试迭代:用历史错误案例(如“order_id非8位”“amount单位错误”)测试优化后的工具,持续调整描述与示例,直至错误率降至5%以下。
预期效果:优化后工具调用错误率可从30%降至10%以内,核心是通过“清晰定义+示例引导”,让LLM“一看就懂、一用就对”,本质是优化Agent-计算机接口(ACI)的“沟通效率”。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)