上下文工程(Context Engineering)综述:大模型的下一个前沿
确立为一门系统化学科,通过对1400+篇文献的整合,构建了“基础组件-系统实现”双层框架,终结了RAG、记忆系统、多智能体等领域的技术碎片化。:将问题分解为中间步骤(如“Let's think step by step”),在数学推理上将准确率从17.7%提升至78.7%。技术演进:ToolFormer(自主API学习)→ ReAct(“思考-行动-观察”循环)→ OpenAI JSON标准化。将
大型语言模型(LLMs)如GPT-4、Claude等的核心性能并非仅取决于模型参数,而关键由推理时提供的上下文信息决定。传统“提示工程”(Prompt Engineering)聚焦于优化单次文本输入,但现代AI系统需处理动态、结构化、多源的信息流(如实时数据、知识图谱、历史对话)。

-
论文:A Survey of Context Engineering for Large Language Models
-
链接:https://arxiv.org/pdf/2507.13334
本文提出“上下文工程”(Context Engineering)作为新兴学科,旨在系统化设计、管理和优化LLMs的信息负载。通过对1400余篇论文的综述,论文首次构建统一框架,将碎片化的技术(如RAG、记忆系统、多智能体协作)整合为“基础组件”与“系统实现”两层体系,并揭示LLMs存在的根本矛盾:在复杂上下文理解上表现卓越,但在长文本生成、逻辑一致性维护上显著受限。这一发现为下一代AI系统的发展指明方向。
核心概念:上下文工程定义
核心问题:如何形式化描述LLM与上下文的交互?
论文突破性地将上下文 ( C ) 定义为动态结构化信息组件的集合,而非静态字符串。其数学形式化包含两个关键层次:
-
组件层:
其中 代表不同信息源(如指令 、外部知识 、记忆 ), 是组装函数(如优先级排序、模板格式化)。这解决了传统提示工程无法灵活整合多源信息的缺陷。
-
优化层:
-
-
:上下文生成函数集(检索/选择/组装)
-
:具体任务实例
-
:输出质量评估函数
意义:将上下文设计转化为系统级优化问题,目标是最大化任务期望收益,而非局部提示调整。
-
关键数学原理:
-
信息论最优性:检索组件需最大化与答案 的互信息 ,确保信息相关性。
-
贝叶斯推理:推断最优上下文后验概率 ,通过似然函数 和先验 处理不确定性,适用于多步推理场景。
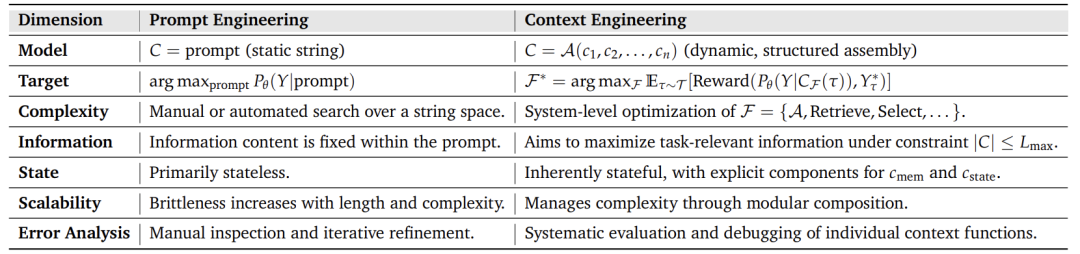
与提示工程的本质区别:
|
维度 |
提示工程 |
上下文工程 |
|---|---|---|
| 模型 |
静态字符串 |
动态结构化组装 |
| 目标 |
优化单次提示 |
系统级函数优化 |
| 状态性 |
无状态 |
显式记忆与状态管理 |
| 扩展性 |
长度增加导致脆弱性 |
模块化组合管理复杂度 |
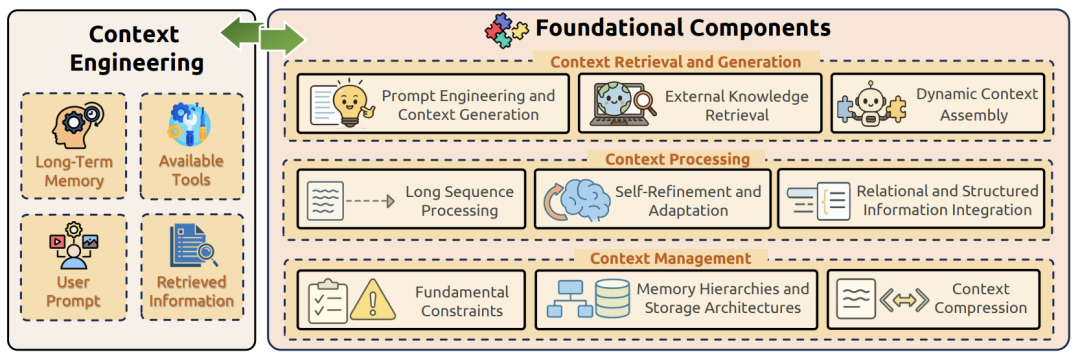
基础组件分解
上下文检索与生成
-
提示工程进阶:
-
-
思维链(CoT):将问题分解为中间步骤(如“Let's think step by step”),在数学推理上将准确率从17.7%提升至78.7%。
-
思维树(ToT):分层探索备选推理路径,24点游戏成功率从4%升至74%。
-
思维图(GoT):以图结构建模推理依赖,较ToT质量提升62%,成本降31%。
-
-
外部知识检索:
-
-
RAG基础架构:融合参数化知识(模型权重)与非参数化知识(外部检索)。
-
知识图谱集成:如KAPING框架通过语义匹配检索相关事实,无需模型重训练。
-
智能体驱动检索:LLM智能体动态分析内容、交叉引用信息(如Agentic RAG)。
-
-
动态上下文组装:
-
-
自动化优化:如Automatic Prompt Engineer (APE) 用搜索算法发现最优提示。
-
多智能体协作:模拟专家团队(分析师/程序员/测试员),代码生成通过率提升29.9-47.1%。
-
上下文处理
-
长上下文处理:
-
-
状态空间模型(SSM):如Mamba实现线性复杂度。
-
位置插值:扩展上下文窗口(如LongRoPE支持2048K token)。
-
稀疏注意力:如S²-Attn保留92%性能,显著节省计算。
-
计算瓶颈:Transformer注意力机制 ( O(n^2) ) 复杂度,序列增至128K token时计算量增122倍。
-
创新架构:
-
-
自优化与元学习:
-
-
自迭代优化:Self-Refine框架让LLM同时担任生成器、反馈提供者、优化器,GPT-4性能提升20%。
-
元学习:SELF框架让LLM通过生成-过滤自有数据持续进化,减少人工监督。
-
-
多模态与结构化整合:
-
-
多模态挑战:模型常偏向文本输入,忽略视觉细节(“模态偏见”)。
-
结构化数据:知识图谱嵌入(如GraphToken)提升图推理任务73个百分点。
-
上下文管理
-
内存架构:
-
-
短时内存:上下文窗口内KV缓存。
-
长时内存:外部存储(如MemGPT模拟操作系统分页)。
-
层次设计:
-
认知启发:MemoryBank基于艾宾浩斯遗忘曲线动态调整记忆强度。
-
-
压缩技术:
-
-
上下文压缩:如QwenLong-CPRS按自然语言指令动态压缩。
-
KV缓存优化:Heavy Hitter Oracle (H₂O) 通过淘汰低贡献token提升吞吐量29倍。
-
系统实现架构
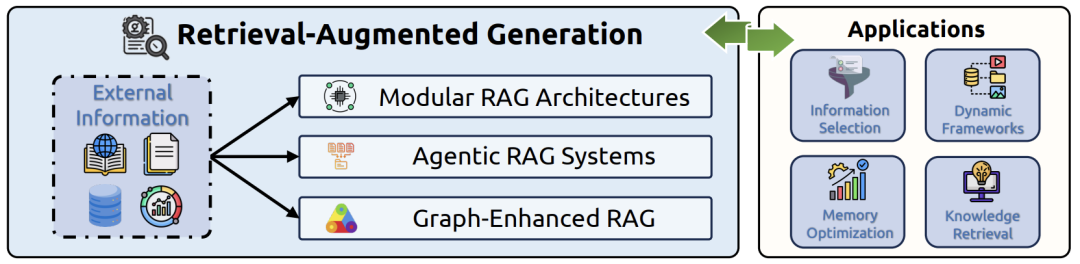
检索增强生成(RAG)
-
模块化RAG:
分层架构(顶层阶段/中间子模块/底层操作单元),支持路由、调度与融合机制。如FlashRAG提供5核心模块灵活组合。 -
智能体驱动RAG:
将检索转化为动态操作(如PlanRAG:先规划后检索),整合任务分解与反思机制。 -
图增强RAG:
用图结构捕获实体关系(如GraphRAG社区检测分层索引),解决传统RAG上下文漂移问题。
实时应用挑战:
-
动态知识更新:增量索引避免全量重训练。
-
低延迟检索:图方法优化速度-精度平衡(如LightRAG双级检索)。
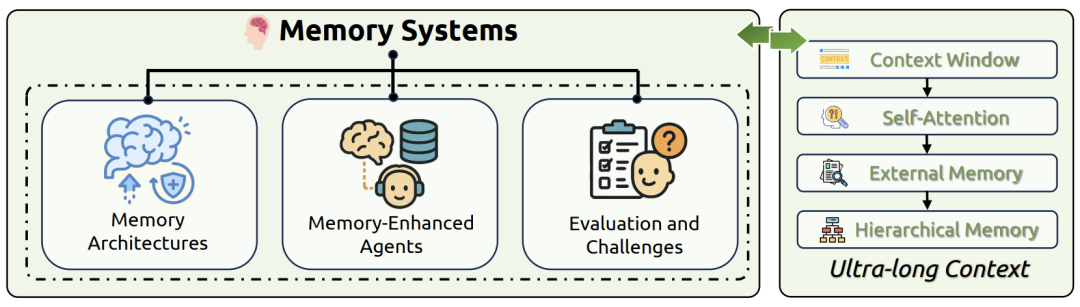
内存系统
-
短时内存:
上下文窗口内KV缓存(如Transformer灵活检索,LSTM侧重早期语义)。 -
长时内存:
-
-
文本存储:完整交互历史。
-
知识表示:摘要/知识三元组/混合形式。
-
操作:编码/检索/反思/遗忘(如Reflective Memory管理冲突消解)。
-
商业应用:
-
Google Gemini:跨生态长时记忆个性化体验。
-
ChatGPT Memory:跨会话对话记忆。
工具集成推理
-
函数调用机制:
-
-
技术演进:ToolFormer(自主API学习)→ ReAct(“思考-行动-观察”循环)→ OpenAI JSON标准化。
-
训练方法:微调(稳定性高) vs. 提示工程(灵活性强)。
-
-
环境交互框架:
-
-
单工具:PAL生成Python代码委派计算。
-
多工具协调:Chameleon组合视觉模型/搜索引擎/Python函数。
-
强化学习:ReTool优化代码解释器使用,数学推理准确率67%。
-
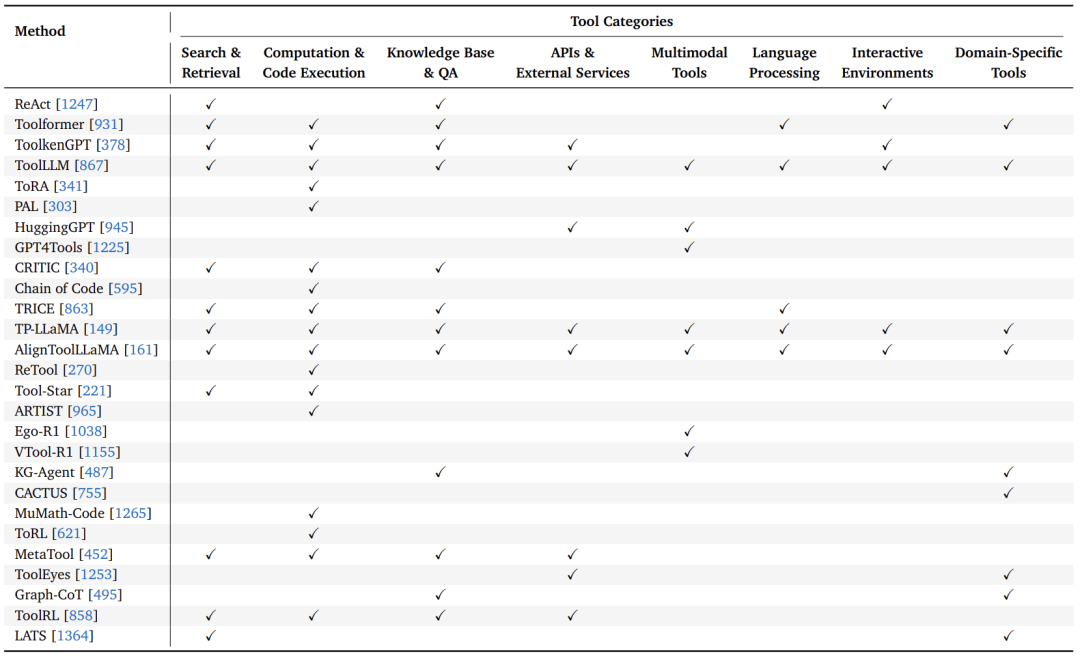
评估瓶颈:
-
GAIA基准测试:人类任务完成率92% vs. GPT-4仅15%。
-
工具选择准确性:嵌套调用错误率显著上升。
多智能体系统
-
通信协议标准化:
-
-
MCP(模型上下文协议):类USB-C的AI交互标准。
-
A2A(智能体间协议):基于能力卡片的安全协作。
-
挑战:协议碎片化与安全漏洞。
-
-
编排机制:
-
-
先验编排:输入预分析选择智能体。
-
后验编排:并行调用+置信度评估(如3S协调器)。
-
核心需求:事务完整性保障(如SagaLLM框架)。
-
应用场景:
-
医疗健康:协调专科智能体处理临床查询。
-
网络管理:上下文感知资源分配。
关键发现与挑战
核心不对称性(Core Asymmetry)
问题本质:
LLMs在上下文理解(如复杂文档分析、多源信息整合)上表现卓越,但在长文本生成(如报告撰写、多步规划)中暴露出三大缺陷:
-
逻辑连贯性断裂
-
事实一致性下降(如早期结论被遗忘)
-
规划深度不足
实验证据:
-
延伸思维链任务中,性能因“中间信息丢失”下降多达73%。
-
自动评估显示,生成质量随长度增加呈指数级衰减。
评估困境
-
组件级评估:
-
-
传统指标(BLEU/ROUGE)无法捕捉推理链质量。
-
长上下文测试依赖“大海捞针”(Needle-in-Haystack)范式,缺乏系统性。
-
-
系统级评估:
-
-
多智能体协作缺乏事务完整性验证(如LangGraph无原子性保证)。
-
商业助手在长交互中准确率下降30%(LongMemEval基准)。
-
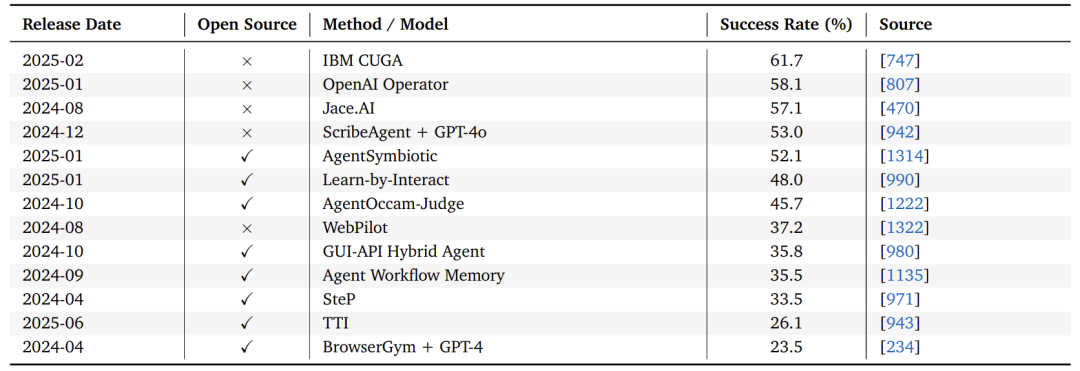
案例:WebAgent评测
|
模型 |
开源 |
成功率 |
|---|---|---|
|
IBM CUGA |
× |
61.7% |
|
OpenAI Operator |
× |
58.1% |
|
GPT-4 + 浏览器 |
✓ |
23.5% |
| 说明:复杂网页交互任务中,现有模型远未达实用水平。 |
技术瓶颈
-
长度扩展:
注意力机制 ( O(n^2) ) 复杂度使百万级token处理成本过高。 -
内存管理:
KV缓存随序列增长成瓶颈(如128K请求需16GB内存)。
结论
本文首次将上下文工程确立为一门系统化学科,通过对1400+篇文献的整合,构建了“基础组件-系统实现”双层框架,终结了RAG、记忆系统、多智能体等领域的技术碎片化。其核心贡献在于:
-
形式化定义:将上下文建模为动态优化问题,奠定数学基础(信息论/贝叶斯推理)。
-
关键技术图谱:
-
基础层:检索/处理/管理组件的创新(如SSM长文处理、自迭代优化)。
-
系统层:四类实现架构的演进(模块化RAG→工具集成智能体)。
-
关键洞见:揭示LLMs理解强于生成的根本不对称性,为未来研究指明优先级。
-
评估与挑战:指出系统级评测的缺失(如事务完整性)、长度扩展的计算瓶颈。
-
未来研究需聚焦三大方向:
-
理论:建立上下文组合的数学规范。
-
技术:突破长文本生成瓶颈,实现多模态/图结构深度融合。
-
伦理:设计内存隐私保护与多智能体责任机制。
此框架不仅为研究者提供技术路线图,更推动AI从“静态提示”迈向“动态上下文感知”的新范式。


-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)