【弱监督视频异常检测】Learning Event Completeness for Weakly Supervised Video Anomaly Detection
弱监督视频异常检测(WS-VAD)的任务是利用仅包含视频级别标注的数据,在未修剪视频中精确定位包含异常事件的时间区间。然而,由于缺乏密集的帧级别标注,现有WS-VAD方法往往存在定位不完整的问题。针对这一挑战,我们提出了一种新颖的LEC-VAD方法——面向弱监督视频异常检测的事件完整性学习。该方法采用双分支结构,旨在编码视觉与语言之间兼具类别相关性和类别无关性的语义信息。在LEC-VAD框架内,我
Learning Event Completeness for Weakly Supervised Video Anomaly Detection 论文阅读

原文链接:https://arxiv.org/abs/2506.13095
发表于:ICML 2025
Abstract
弱监督视频异常检测(WS-VAD)的任务是利用仅包含视频级别标注的数据,在未修剪视频中精确定位包含异常事件的时间区间。然而,由于缺乏密集的帧级别标注,现有WS-VAD方法往往存在定位不完整的问题。针对这一挑战,我们提出了一种新颖的LEC-VAD方法——面向弱监督视频异常检测的事件完整性学习。该方法采用双分支结构,旨在编码视觉与语言之间兼具类别相关性和类别无关性的语义信息。在LEC-VAD框架内,我们设计了语义正则化机制,通过引入异常感知的高斯混合模型来学习精确的事件边界,从而生成更完整的事件实例。此外,我们开发了基于记忆库的新型原型学习机制,用于丰富与异常事件类别相关的简洁文本描述。这一创新增强了文本表达的丰富性,对推进WS-VAD研究具有重要意义。我们的LEC-VAD方法在XD-Violence和UCF-Crime两个基准数据集上实现了显著突破,性能远超当前最先进方法。
1. Introduction
近年来,视频异常检测(VAD)因其广泛的应用前景而受到越来越多的关注,例如智能监控、多媒体内容审核及智能制造等领域。VAD旨在从任意长度且未修剪的视频中预测异常事件发生的时间区间。然而,该方法面临的主要挑战在于其依赖成本高昂且需要精确标注每个异常事件起止时间的密集注释。为减轻这一依赖,弱监督视频异常检测(WS-VAD)被提出。该范式仅需视频级别标注即可完成模型训练,从而简化标注流程并提升VAD在实际应用中的可行性。
当前大多数弱监督视频异常检测方法遵循一套系统化流程。首先,利用预训练模型提取帧级特征;随后,将这些特征输入二元分类器并结合多示例学习策略;最终通过分析预测的异常置信度来识别异常事件。尽管取得了显著成果,但此类分类范式仅将视频帧分配至零个或多个异常类别。在推理阶段,其依赖人工设计的后处理步骤将帧级预测聚合为具有明确边界的连续异常片段。然而,如图1所示,这种方法往往导致异常片段识别不完整且呈现碎片化现象。
为解决该范式下异常事件检测不完整的挑战,我们提出LEC-VAD(面向弱监督视频异常检测的事件完整性学习),包含两项创新机制:基于记忆库的原型学习策略和基于高斯混合先验的局部一致性学习。针对前者,我们利用异常类别的文本描述,构建双分支结构以编码视觉与语言间的粗粒度与细粒度语义。在此过程中,异常类别的文本描述通常简洁但表达力有限,因此开发了基于记忆库的创新原型学习策略以增强文本的信息熵。同时,我们还通过集成可学习的文本条件视觉提示来动态增强文本表征。对于后者,由于模型被训练进行逐帧预测,其缺乏对异常事件边界的显式理解,导致基于分类的训练目标与基于定位的推理目标存在偏差。为弥合这一差距,我们提出预测结果应满足局部一致性的假设。为显式注入该先验,我们采用可学习的高斯混合掩码优化异常分数,使其能融合邻近帧的上下文信息,从而提升预测异常片段的平滑度。
本文的主要贡献包含五个方面:
- 我们提出LEC-VAD这一新颖方法,仅需视频级标注即可实现面向事件完整性的视频异常检测;
- 设计双分支结构以挖掘视觉-语言间兼具类别相关性与类别无关性的语义信息;
- 针对异常类别文本描述简洁但表达受限的问题,开发基于记忆库的原型学习机制以增强文本表征;
- 基于预测结果应满足局部一致性的假设,提出先验驱动的事件完整性学习范式,通过可学习高斯混合掩码优化异常分数;
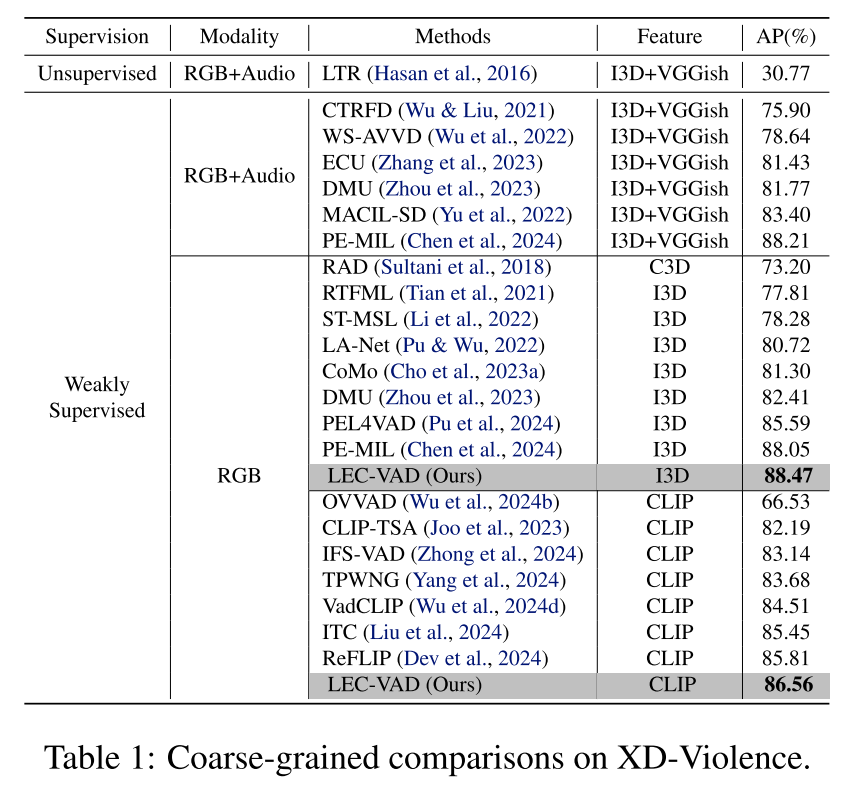
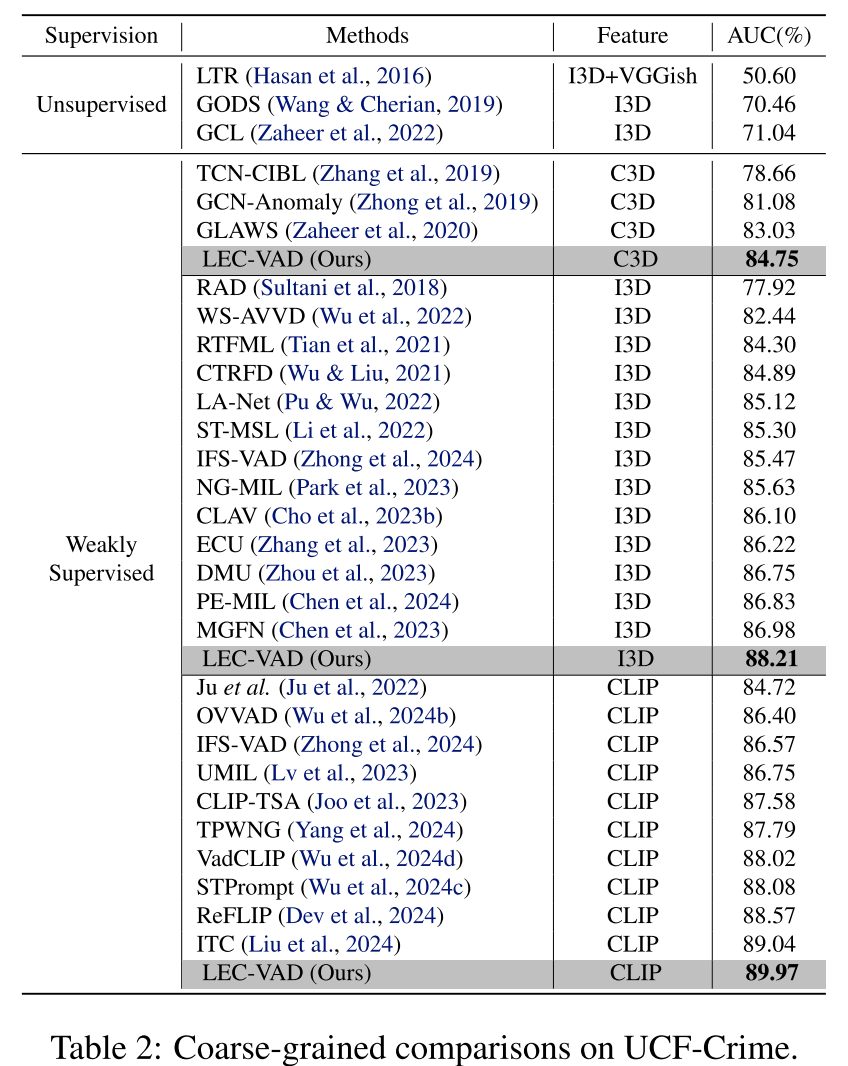
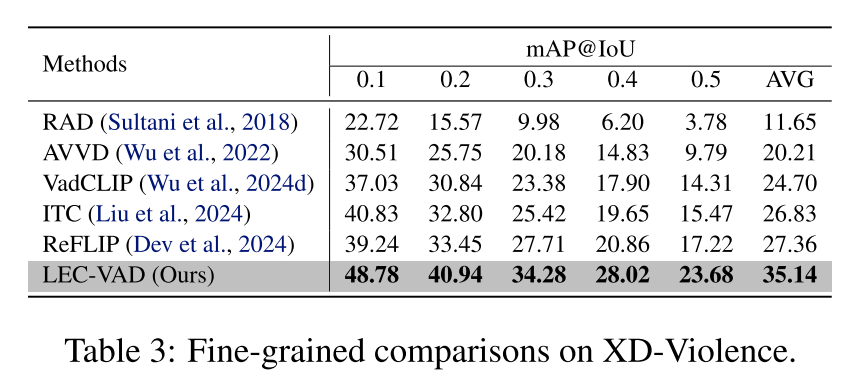
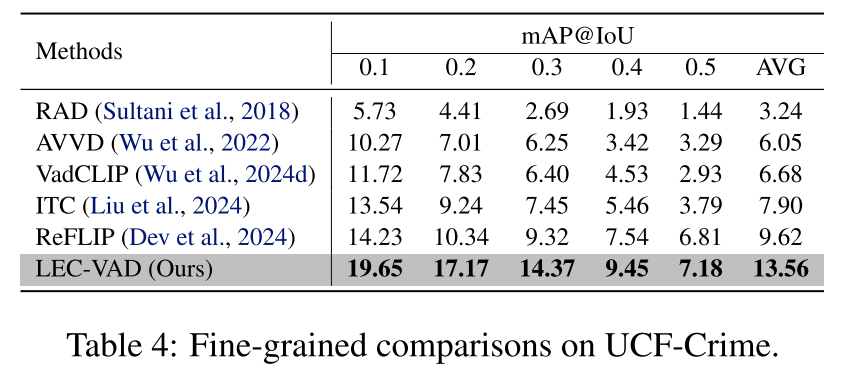
- 在XD-Violence和UCF-Crime数据集上的大量实验表明,LEC-VAD达到最先进性能,尤其在细粒度异常事件检测方面较现有方法展现出显著优势,以较大幅度超越现有方法。
2. Related Work
2.1. Vision-Language Pre-training
2.2. Weakly Supervised Video Anomaly Detection
3. Methodology
在本节中,我们首先介绍所提出的双分支框架LEC-VAD,随后将在3.2节和3.3节分别详细阐述基于记忆库的原型学习机制与基于高斯混合先验的局部一致性学习策略。
3.1. Overview
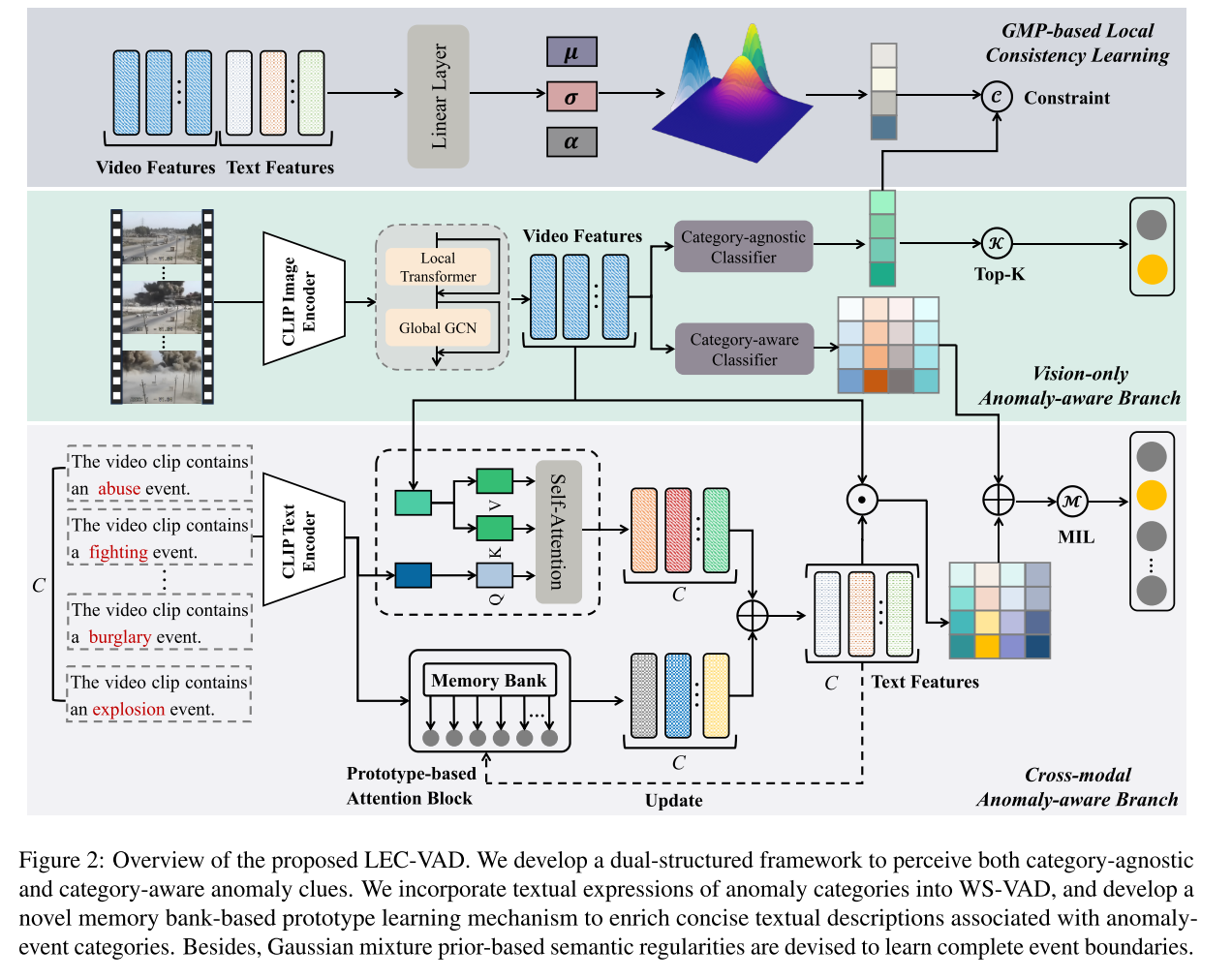
问题定义。给定包含n个视频的数据集 V = { v i } i = 1 n V = \{v_i\}_{i=1}^n V={vi}i=1n,这些视频具有不同粒度的标注。每个视频 v i v_i vi分别标注有粗粒度视频级标签 y i ∈ { 0 , 1 } y_i \in \{0, 1\} yi∈{0,1}和细粒度视频级标签 g i ∈ { 0 , . . . , C } g_i \in \{0, ..., C\} gi∈{0,...,C},其中 C C C表示异常类别数量。若 v i v_i vi被标记为正常视频,则 y i = 0 y_i = 0 yi=0且 g i = 0 g_i = 0 gi=0;反之 y i = 1 y_i = 1 yi=1且 g i g_i gi被赋予特定异常类别。粗粒度弱监督视频异常检测需要预测每个视频片段包含异常的可能性。细粒度弱监督视频异常检测则需预测具体的异常事件实例,表示为 { s j , e j , g j , w j } \{s_j, e_j, g_j, w_j\} {sj,ej,gj,wj},其中 s j s_j sj和 e j e_j ej分别表示第j个异常实例的起始与结束时间戳, g j g_j gj代表异常类别, w j w_j wj表示对该实例的预测置信度。
本文提出了一种新颖的双分支框架LEC-VAD用于弱监督视频异常检测,其结构如图2所示。核心思想是在缺乏密集标注的情况下学习异常事件的完整性。为实现该目标,我们通过双分支结构同时捕捉类别相关和类别无关的异常知识,避免细微线索被显著特征淹没,从而使模型能够全面理解事件概念。此外,为确保预测结果的局部一致性,我们开发了可学习的高斯混合掩码以提升异常片段预测的平滑度。具体而言,我们首先采用预训练图像编码器提取视觉特征 X v i d e o ∈ R T × d X_{video} \in \mathbb{R}^{T \times d} Xvideo∈RT×d,其中 T T T表示视频片段数量,d为特征维度。参照(Wu et al., 2024d)的方法,为捕捉局部时序依赖关系,我们将帧级特征划分为等长的重叠窗口,随后应用具有受限注意力范围的局部Transformer层,确保窗口间无信息交互,最终得到增强特征 X l ∈ R T × d X_l \in \mathbb{R}^{T \times d} Xl∈RT×d。接着,为捕获全局时序依赖,我们在 X l X_l Xl上应用图卷积网络模块。具体而言,沿用(Wu et al., 2024d)的设置,基于特征相似度建模全局时序关联,该过程可概括为:
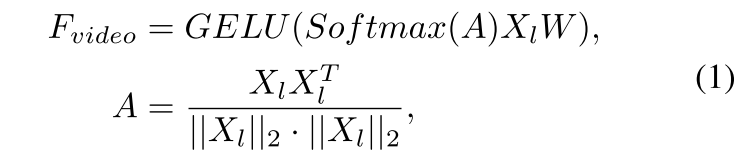
其中A为邻接矩阵,Softmax操作确保每行元素之和为1,W为可学习权重, F v i d e o F_{video} Fvideo为增强后的视频特征。此外,采用预训练文本编码器提取所有异常事件类别的语言特征 F t e x t ∈ R ( C + 1 ) × d F_{text} \in \mathbb{R}^{(C+1) \times d} Ftext∈R(C+1)×d。随后对 F v i d e o F_{video} Fvideo应用全连接层及softmax操作,分别进行类别无关异常的二元分类和类别感知异常的多类别分类,得到预测结果 s b ∈ R T × 2 与 s m ∈ R T × C s_b \in \mathbb{R}^{T \times 2}与s_m \in \mathbb{R}^{T \times C} sb∈RT×2与sm∈RT×C。对于 s b s_b sb,我们沿时间维度计算top-K分数的平均值(针对第c个类别,c属于{0,1}),具体计算如下:
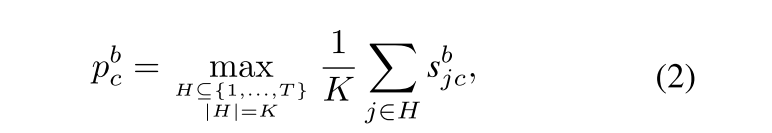
其中 H H H表示 K K K个视频片段的索引集合, p b c p_b^c pbc为类别无关预测结果。随后对预测值 p b p_b pb与真实标签 y y y施加二元交叉熵损失函数:
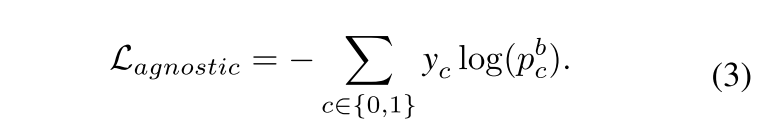
此外,虽然 s m s_m sm包含类别感知的异常信息,但其缺乏与文本描述的关联。为此,我们通过交叉注意力操作建模跨模态交互。此处文本特征 F t e x t F_{text} Ftext作为查询向量,视频特征 F v i d e o F_{video} Fvideo作为键向量和值向量,最终得到增强的跨模态表示 F t v ∈ R ( C + 1 ) × d F_{tv} \in \mathbb{R}^{(C+1) \times d} Ftv∈R(C+1)×d。具体计算过程如下:
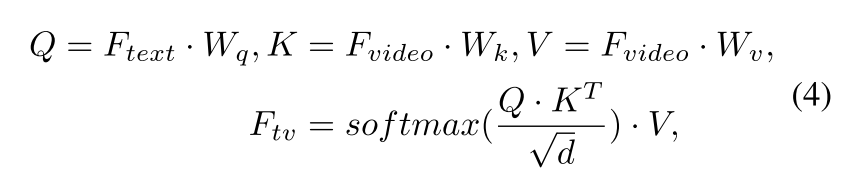
其中 W q W_q Wq、 W k W_k Wk和 W v W_v Wv是 d × d d \times d d×d维的可学习投影矩阵。鉴于异常事件类别的文本描述存在表达简洁有限的特点,我们开发了基于记忆库的机制来存储类别原型。这些原型被用于获取增强的文本描述 F a u g F_{aug} Faug。最终的文本表征 F c t g F_{ctg} Fctg是 F t v F_{tv} Ftv与 F a u g F_{aug} Faug的融合结果,计算公式为 F c t g = F t v + F a u g F_{ctg} = F_{tv} + F_{aug} Fctg=Ftv+Faug。通过利用外部记忆库增强文本表达能力获得 F a u g F_{aug} Faug后,我们通过 F c t g F_{ctg} Fctg与视频特征 F v i d e o F_{video} Fvideo的点积进行类别感知检测,计算过程如下:
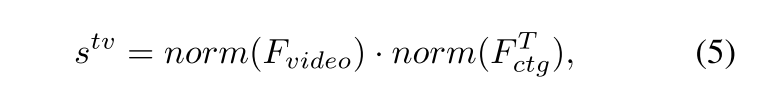
其中norm表示 ℓ 2 \ell_2 ℓ2归一化操作。最终,我们通过整合 s t v s^{tv} stv和 s m s^m sm得到类别感知异常检测逻辑值,计算公式为 s a w a r e = s m + s t v s^{aware} = s^m + s^{tv} saware=sm+stv。该逻辑值随后通过多示例学习原则生成视频级分类结果。具体而言,对于第 c c c个异常类别,其逻辑值 p m c p_m^c pmc计算如下:
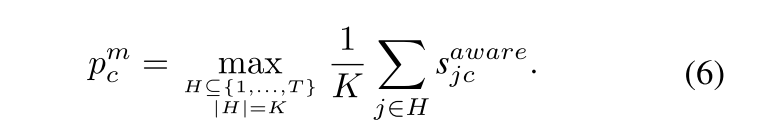
随后,施加交叉熵约束来监督细粒度异常分类过程:
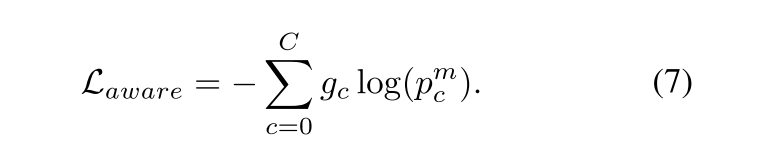
为学习完整的异常事件并提升片段预测的平滑度,我们提出预测分数应满足局部一致性的假设。基于该假设,我们设计了基于高斯混合先验的局部一致性学习机制,将多个异常类别编码为高斯混合模型的分量,从而生成异常约束分数 s g m m ∈ R T s_{gmm} \in \mathbb{R}^T sgmm∈RT。随后采用 s g m m s_{gmm} sgmm对预测异常分数 s b s_b sb进行正则化处理,计算方式如下:
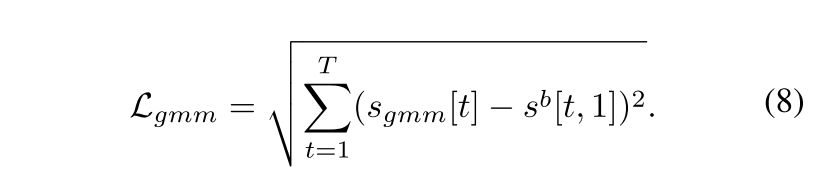
此外,为确保每个视频片段的类别无关异常分数(即 1 − s m [ t , 0 ] 1 - s_m[t, 0] 1−sm[t,0])与类别感知异常分数(即 s b [ t , 1 ] s_b[t, 1] sb[t,1])的一致性,我们引入 ℓ 1 \ell_1 ℓ1正则化损失函数,其计算公式如下:
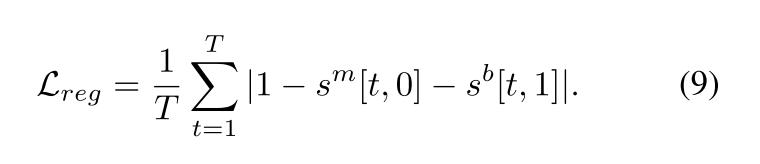
总体而言,建议的LEC-VAD的优化损失总结如下:
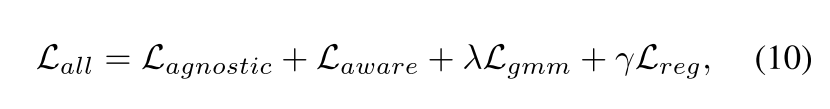
其中,λ和γ是平衡权重。
3.2. Memory Bank-based Prototype Learning
鉴于异常事件类别的文本描述通常简洁且表达力有限,我们构建外部记忆库以保存一组文本原型,记为 M ∈ R ( C + 1 ) × d M \in \mathbb{R}^{(C+1) \times d} M∈R(C+1)×d。这些原型随后被用于增强文本表征。具体而言,我们使用异常事件类别对应的原始CLIP特征初始化M。训练过程中,将增强后的文本特征 F t v F_{tv} Ftv与记忆库内容M拼接,生成上下文感知特征 F c t e ∈ R ( 2 C + 2 ) × d F_{cte} \in \mathbb{R}^{(2C+2) \times d} Fcte∈R(2C+2)×d。随后对 F c t e F_{cte} Fcte施加m个自注意力块以吸收原型特征M中的语义知识,从而获得增强表征 F c t e ′ ∈ R ( 2 C + 2 ) × d F'_{cte} \in \mathbb{R}^{(2C+2) \times d} Fcte′∈R(2C+2)×d。从 F c t e ′ F'_{cte} Fcte′的第一个维度提取前C+1个表征作为精炼文本表示 F a u g ∈ R ( T + 1 ) × d F_{aug} \in \mathbb{R}^{(T+1) \times d} Faug∈R(T+1)×d。同时,记忆库中的原型特征采用动量更新策略,具体更新方式如下:
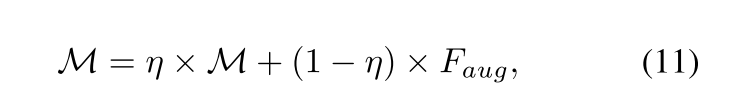
其中,η表示更新的动量系数。
3.3. Gaussian Mixture Prior-based (GMP-based) Local Consistency Learning
本文提出预测分数应满足局部一致性的假设。为显式注入该先验并学习完整实例,我们采用可学习高斯混合模型对每个时间位置t的异常分数建模,其中GMM的每个分量专门用于编码特定类别的异常掩码。具体而言,首先通过Python广播机制将 F a u g F_{aug} Faug与每个片段的视觉特征 F v i d e o F_{video} Fvideo拼接,获得融合多模态表征 F m ∈ R T × C × d F_m \in \mathbb{R}^{T \times C \times d} Fm∈RT×C×d。基于 F m F_m Fm,利用共享全连接层预测各类别高斯掩码的高斯核参数 { σ t c , μ t c } t = 1 T \{\sigma_t^c, \mu_t^c\}_{t=1}^T {σtc,μtc}t=1T。最终通过第 t t t个高斯混合掩码生成第 t t t个时间位置的异常分数 s g a u s s ( t ) s_{gauss}(t) sgauss(t),具体计算流程如下:
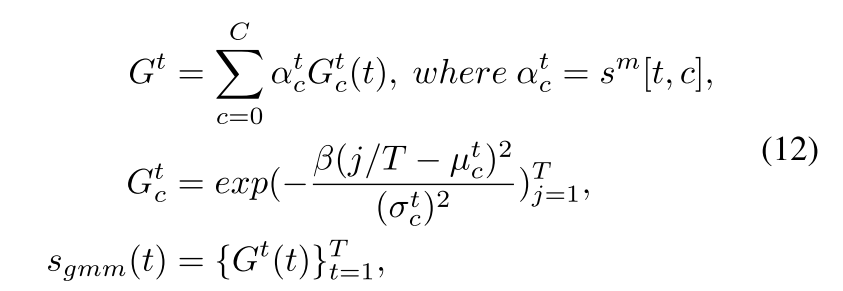
其中 α t c \alpha_t^c αtc表示每个异常事件发生的概率,其值取自 s m [ t , c ] s_m[t, c] sm[t,c]。 β \beta β用于控制高斯掩码 G t c G_t^c Gtc的方差。通过这种方式,这些掩码呈现出局部平滑特性,使其适用于对异常分数 s b s_b sb进行约束,如公式(8)所定义。
3.4. Inference
在推理阶段,针对粗粒度弱监督视频异常检测,我们计算 1 − s m [ t , 0 ] 1-s_m[t, 0] 1−sm[t,0]与 s b [ t , 1 ] s_b[t, 1] sb[t,1]的平均值作为第t帧的异常置信度。对于细粒度弱监督视频异常检测,采用双阈值策略生成异常实例:首先保留视频级激活值超过预设阈值 r c l s r_{cls} rcls的异常类别;随后对每个保留类别,筛选细粒度匹配分数 s m s_m sm超过阈值 r a n o r_{ano} rano的片段作为候选段。将时间连续的候选段合并形成异常实例,并参照AutoLoc方法,基于 s m s_m sm计算每个实例的外内比分作为置信度分数,最后应用非极大值抑制消除冗余提案。
4. Experiments
5. Conclusion
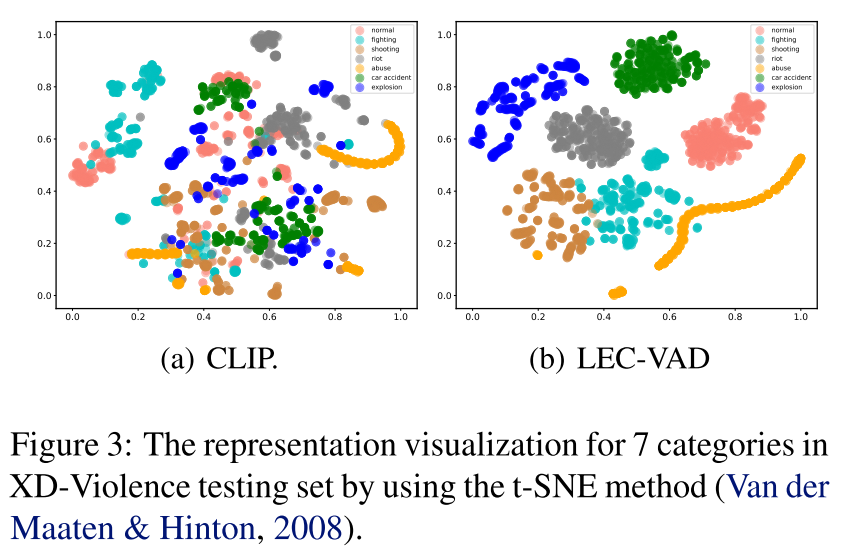
本文提出了一种新颖的弱监督视频异常检测方法LEC-VAD,通过双分支结构编码异常事件的类别相关与类别无关语义。基于预测结果具有局部一致性的假设,我们开发了基于可学习高斯掩码的先验驱动学习机制。同时,提出基于记忆库的原型学习机制以增强文本特征表征能力。在XD-Violence和UCF-Crime数据集上的实验表明,LEC-VAD实现了显著性能提升

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)