YOLOv8检测电动车
本文介绍了电动车目标检测的实现方法。主要介绍了使用labelimg标注数据集和YOLOv8模型的两种训练方式:基于配置文件从头训练和使用预训练模型微调,并提供了详细的训练代码示例。最后提到可以开发包含图片/视频/摄像头检测、日志记录和计数等功能的UI界面来部署训练好的模型。
一、数据集及源码
1、数据集
https://gitcode.com/open-source-toolkit/94dcc这个是网上的一个电动车数据集,其中有近两千张电动车的图片,有标注文件的只有四百张(格式为voc,后缀为.xml),其余都没有标注,需要使用labelimg手动标注。下面简略说一下如何下载并标注(我手中有六百张标注好的图片,需要的话联系我):
1、下载labelimg到环境中,直接在pycharm中的终端输入pip install labelimg ,即可自动下载。如果在Anaconda环境下,可以在Anaconda Prompt输入pip install labelimg下载。
pip install labelimg
2.下载完成后输入labelimg命令,会弹出如下的对话框,首先选择图片和保存标签文件的目录,然后选择标签文件的格式。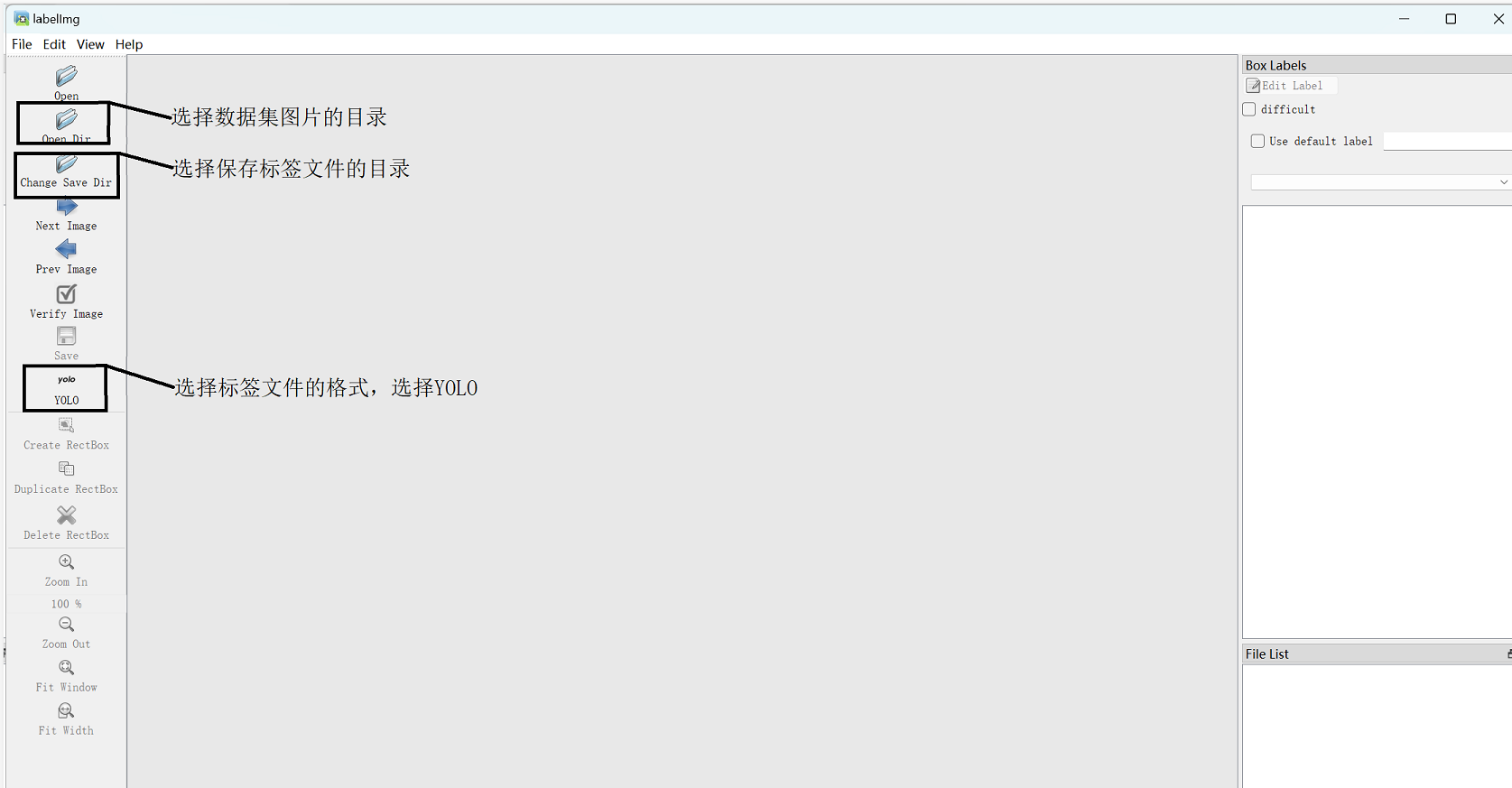
点击View会弹出一些设置,为了方便使用可以自行开启,第一个是自动保存,第二个是标注单标签(标注电动车这种只有一个标签的数据集时可以开启),第三个是显示标签(多标签时需要选择标签名,可以开启)。
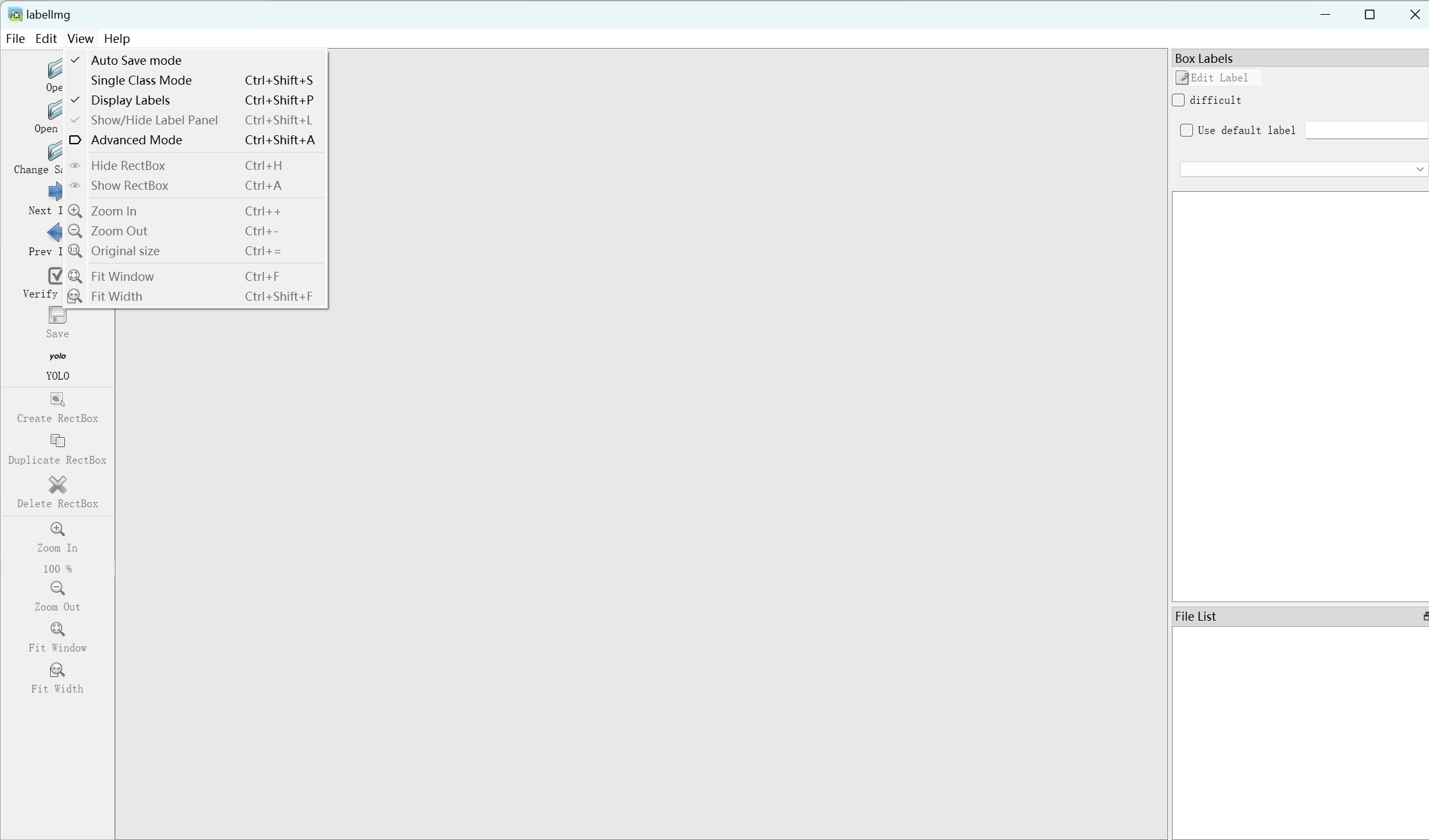
常用快捷键:w:创建一个检测box,就是方框;a:前一张图片;d:下一张图片;Ctrl + s保存结果,先前View中勾选了Auto Save mode后,只需框选,然后下一张,就能自动保存;框选错误时可以选中错误框后,按delete 。
更详细的可以看使用labelimg标注。
注意:数据集格式:
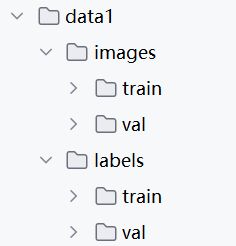
2、YOLOv8源码
可以直接在浏览器搜索YOLOv8源码,也可以点击链接直接跳转至Gitee中直接下载。
二、配置文件准备
1、使用配置文件训练
下图是使用配置文件进行训练的代码,其中注释很明确。
import warnings
from sympy import false
# 忽略警告信息,避免影响训练过程中的输出
warnings.filterwarnings('ignore')
# 导入YOLOv8模型类,用于目标检测模型的训练和推理
from ultralytics import YOLO
if __name__ == '__main__':
# 从YAML配置文件创建新的YOLO模型(注意:这里使用的是自定义的yolo11.yaml配置)
model = YOLO(model=r'ultralytics\cfg\models\11\yolo11.yaml')
# 开始模型训练,配置各项训练参数
model.train(
data=r'data.yaml', # 数据集配置文件路径,定义类别和图像路径
imgsz=640, # 输入图像尺寸,统一调整为640×640像素
epochs=150, # 训练总轮次
batch=4, # 每批次处理的图像数量(受GPU内存限制)
workers=0, # 数据加载工作线程数,0表示在主进程中加载
device='', # 自动选择计算设备(GPU优先)
optimizer='SGD', # 使用随机梯度下降作为优化器
close_mosaic=10, # 在最后10个轮次关闭Mosaic数据增强
resume=False, # 不恢复训练,始终从头开始
project='runs/train', # 训练结果保存的项目目录
name='exp', # 实验名称,结果将保存在runs/train/exp目录下
single_cls=True, # 不使用单类别模式
cache=False, # 不缓存图像,节省内存
)下图是源码中模型配置文件的截图,训练之前将nc(数据种类)改为自己数据集对应的个数即可训练。
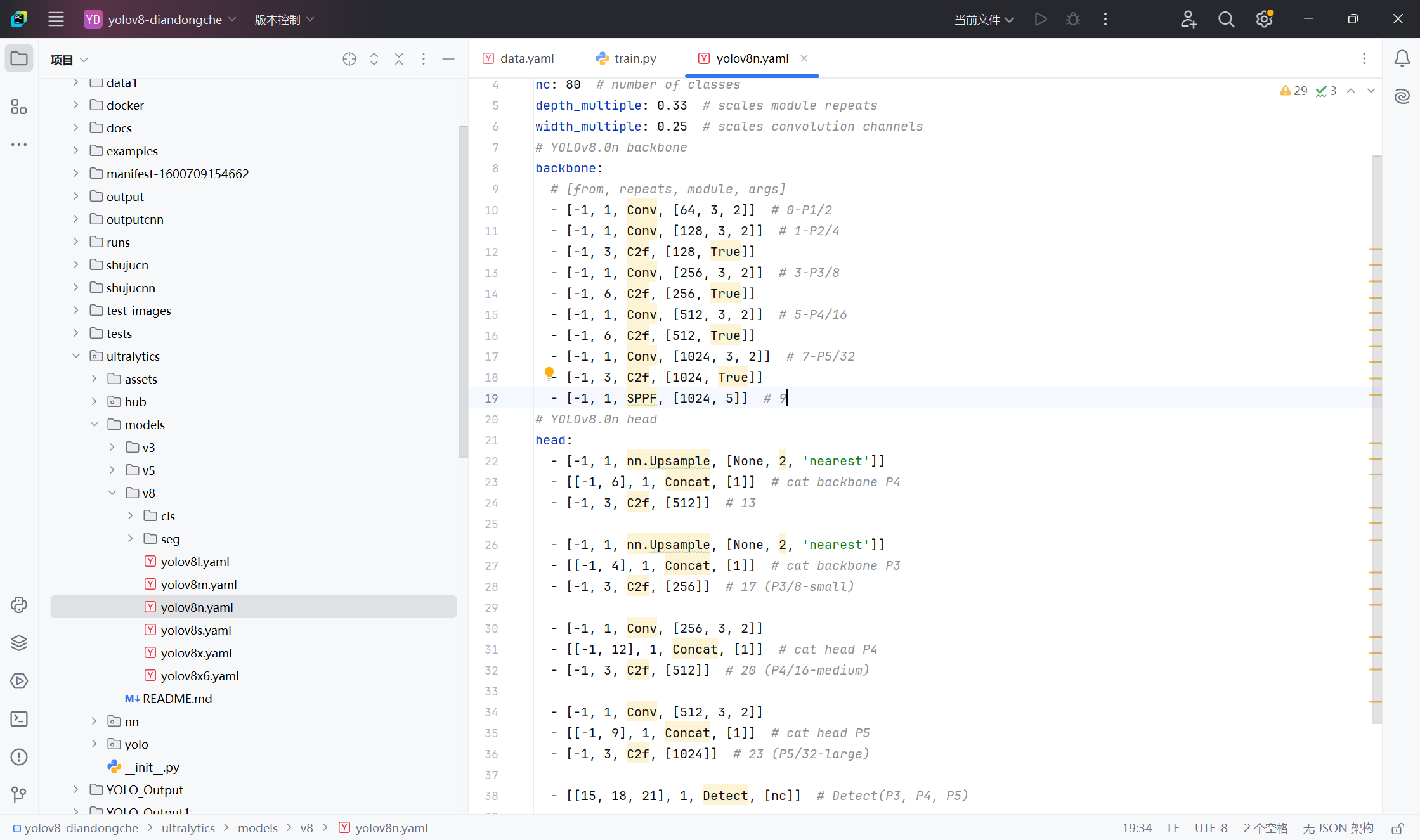
2、使用预训练模型训练
使用预训练模型训练需要先下载预训练的模型文件,点击链接直接跳转到Ultralytics的模型,然后就可以寻找对应的预训练模型。下载后保存到项目中与下面代码同目录中即可。
import warnings
from sympy import false
# 忽略警告信息,避免影响训练过程中的输出
warnings.filterwarnings('ignore')
# 导入YOLOv8模型类,用于目标检测模型的训练和推理
from ultralytics import YOLO
if __name__ == '__main__':
# 使用预训练模型进行训练,是需要更改这一处就行
model = YOLO('yolov8n.pt')
# 开始模型训练,配置各项训练参数
model.train(
data=r'data.yaml', # 数据集配置文件路径,定义类别和图像路径
imgsz=640, # 输入图像尺寸,统一调整为640×640像素
epochs=150, # 训练总轮次
batch=4, # 每批次处理的图像数量(受GPU内存限制)
workers=0, # 数据加载工作线程数,0表示在主进程中加载
device='', # 自动选择计算设备(GPU优先)
optimizer='SGD', # 使用随机梯度下降作为优化器
close_mosaic=10, # 在最后10个轮次关闭Mosaic数据增强
resume=False, # 不恢复训练,始终从头开始
project='runs/train', # 训练结果保存的项目目录
name='exp', # 实验名称,结果将保存在runs/train/exp目录下
single_cls=True, # 不使用单类别模式
cache=False, # 不缓存图像,节省内存
)3、两者区别
|
模型配置文件训练 |
预训练模型训练 |
|
|
训练方式 |
从头开始构建和训练模型。模型配置文件(如:yolov8n.yaml)定义了网络结构、层数、滤波器数量等超参数。训练过程不依赖预训练权重,所有参数随机初始化。 |
预训练模型训练利用在大规模数据集(如COCO)上训练过的权重作为初始参数。只需加载预训练权重(如yolov8n.pt),模型已具备基础特征提取能力。 |
|
训练时间 |
时间长 |
时间短 |
|
数据要求 |
数据量大 |
数据量小 |
|
性能起点 |
随机初始化开始 |
初始性能较高 |
|
适用场景 |
适合研究新架构或特殊任务 |
适合大多数实际应用 |
三、训练模型
1、新建.py文件训练
两种方法训练模型的代码已经在配置文件准备中给出,直接复制并准备相关文件进行训练。注意修改路径。
2、使用命令进行训练
这个命令是使用预训练模型进行训练的命令,具体超参数根据情况自行更改。
python train.py --img 320 --batch 2 --epochs 20 --data ImageNet100.yaml --weights yolov8n.pt --cache disk
这个命令是使用模型配置文件进行训练的命令,具体超参数根据情况自行更改。仅改变weights部分。
python train.py --img 320 --batch 2 --epochs 20 --data ImageNet100.yaml --weights yolov8n.yaml --cache disk
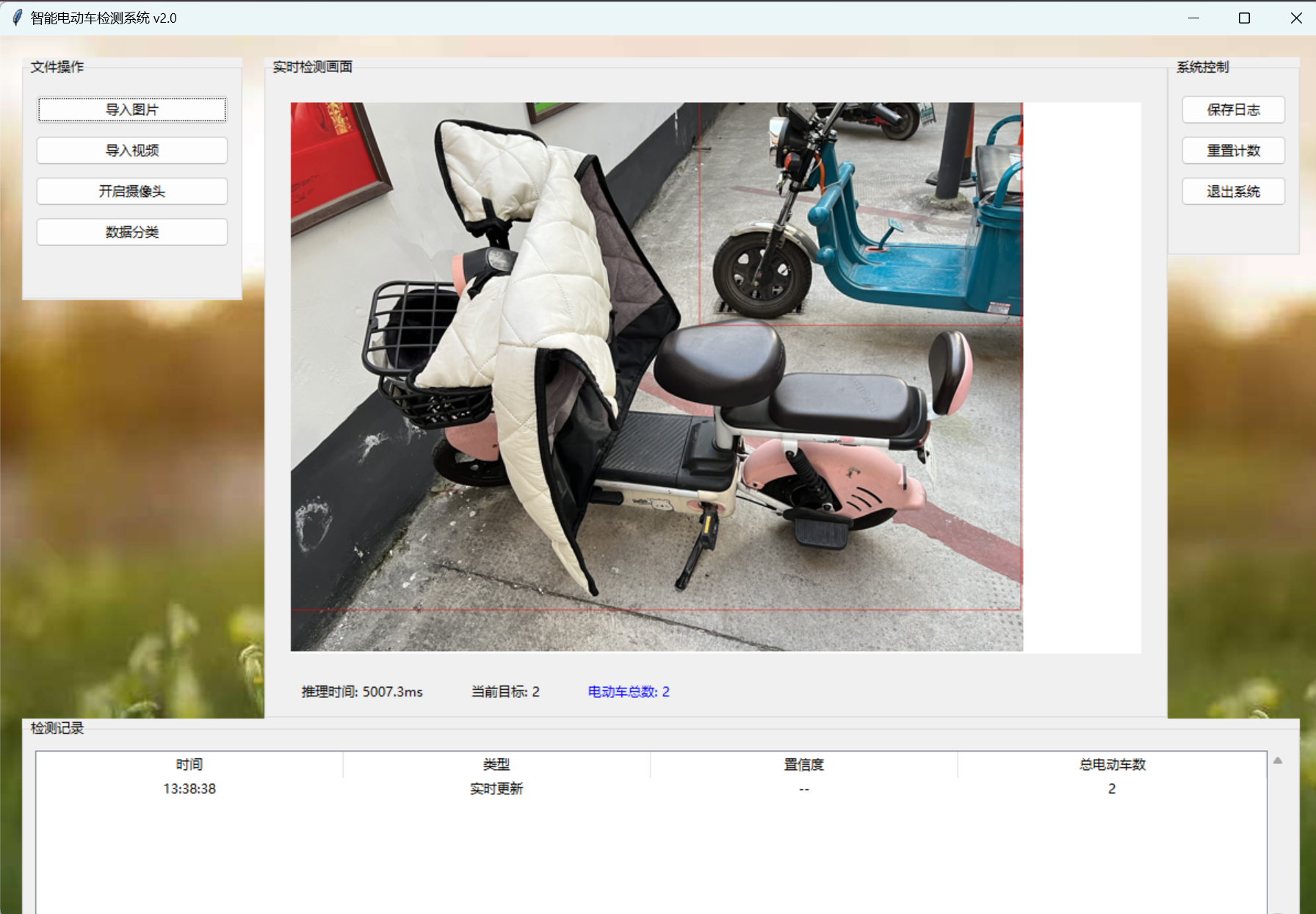
四、UI界面
训练好模型得需要一个简单的UI界面来使用它,如下是电动车检测的界面,功能包括:图片、视频和摄像头检测,也可以对多图片进行检测,还有日志、计数等功能。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)