Qwen/Qwen3-30B-A3B-Thinking-2507-FP8(简单测试情况,linux,含部署教程,含踩坑)
踩坑:一开始以为是掉驱动,后来是发现一张卡估计压力测试下质量翻车了,不过同时研究了换驱动的方法,对于需要更换显存,建议自己看情况换版本,能够避免切换版本导致。然后安装one-api,方便API管理,可以选择不开端口访问,使用lucky转发还便于套证书(这里就不写教程了,很简单),但是局域网环境就开放就行。token数是干到125t/s,之前测试过gguf的30ba3b,这模型基本逻辑能力是不用怀疑
首先建议使用1panel进行大模型部署,能省去很多小白问题(懂得都懂)。
踩坑:一开始以为是掉驱动,后来是发现一张卡估计压力测试下质量翻车了,不过同时研究了换驱动的方法,对于需要更换显存,建议自己看情况换版本,能够避免切换版本导致NVML问题,所以魔改的4090必须得有店家质保,不然风险还是摆在这里得。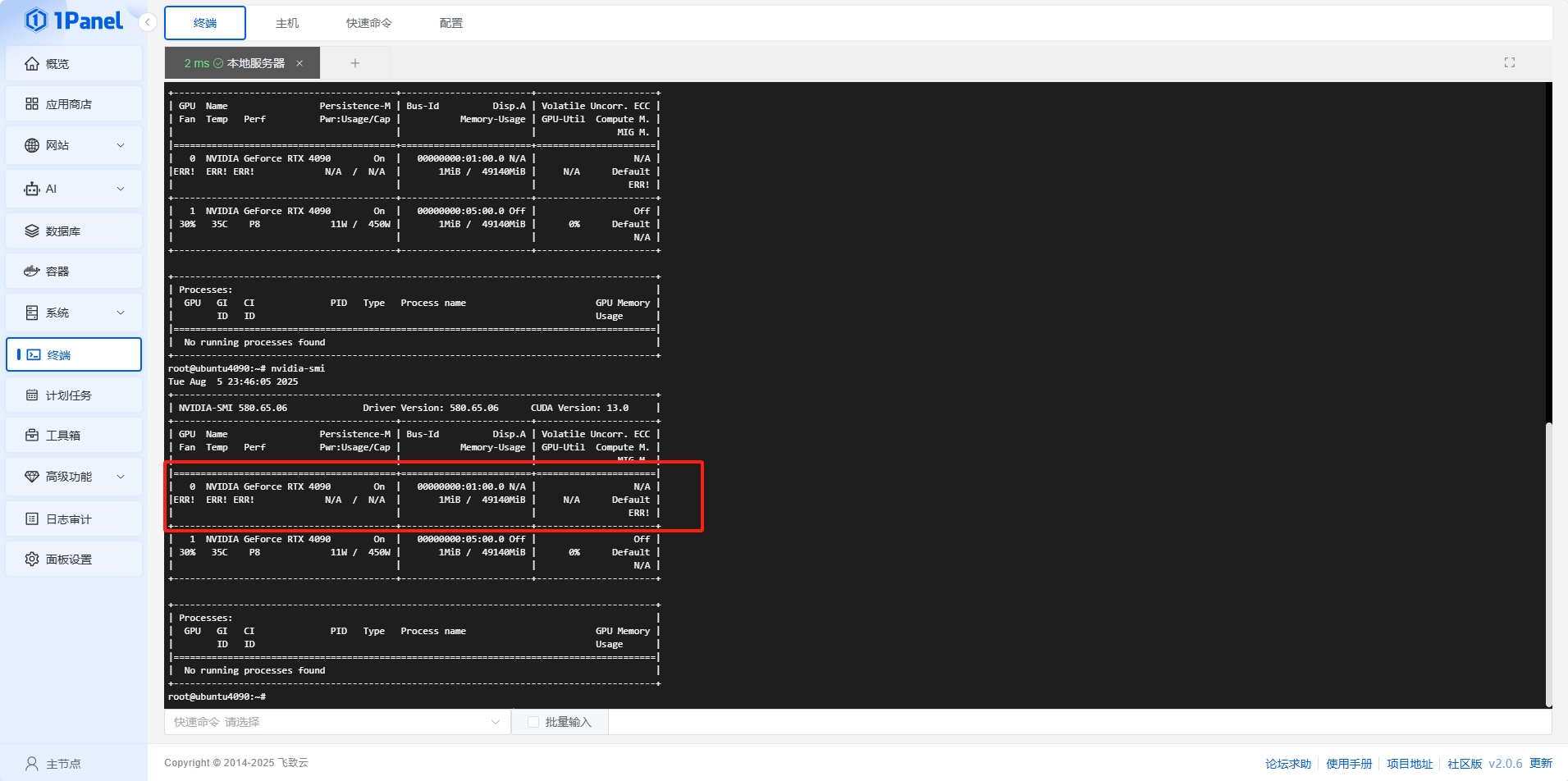
sudo apt-get purge '*nvidia*'
sudo apt autoremove
sudo apt autoclean需要重装tookit
# Check if nvidia-container-toolkit is installed
dpkg -l | grep nvidia-container-toolkit
# If not installed, reinstall it (for Ubuntu/Debian)
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker建议开守护进程
sudo systemctl enable --now nvidia-persistenced
1panel的安装教程直接从官网来就行
模型下载首先推荐魔塔社区
通义千问3-30B-A3B-Thinking-2507-FP8 · 模型库
推荐使用uv环境进行,方便管理。
随便测了下256k
第一步先安装uv
sudo apt-get update && apt-get install astral uv第二步创建虚拟环境并安装modelscope
cd ~ && uv venv &&uv run modelscope download --model Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --local_dir ./Qwen3-30B-A3B-Thinking-2507-FP8当前版本的直接安装modelscope会出缺少filelock三方库的问题,后续官方可能会修,没遇到就忽略,安装方法如下(阿里镜像加速):
uv pip install filelock -i https://mirrors.aliyun.com/pypi/simple修复完依赖问题可以开始安装
uv run modelscope download --model Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --local_dir ./Qwen3-30B-A3B-Thinking-2507-FP8
等模型下载后,在1panel编排中直接丢如下compose,不映射端口是为了后续使用one-api便于api管理,这里更具自己需求设置。
记得安装toolkit
Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit
同时这里需要根据自己需求设置下tp的显卡数量,我这里是用的两张4090 48G
services:
30ba3b2507:
image: lmsysorg/sglang:v0.4.10.post2-cu126
ipc: host
environment:
- TZ=Asia/Shanghai
volumes:
- '$HOME/Qwen3-30B-A3B-Thinking-2507-FP8:/Qwen3-30B-A3B-Thinking-2507-FP8'
container_name: 30ba3b2507
tty: true
entrypoint: python3 -m sglang.launch_server
command: >
--model-path /Qwen3-30B-A3B-Thinking-2507-FP8
--api-key abc123
--context-length 262144
--reasoning-parser deepseek-r1
--tensor-parallel-size 2
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- 1panel-network
networks:
1panel-network:
external: true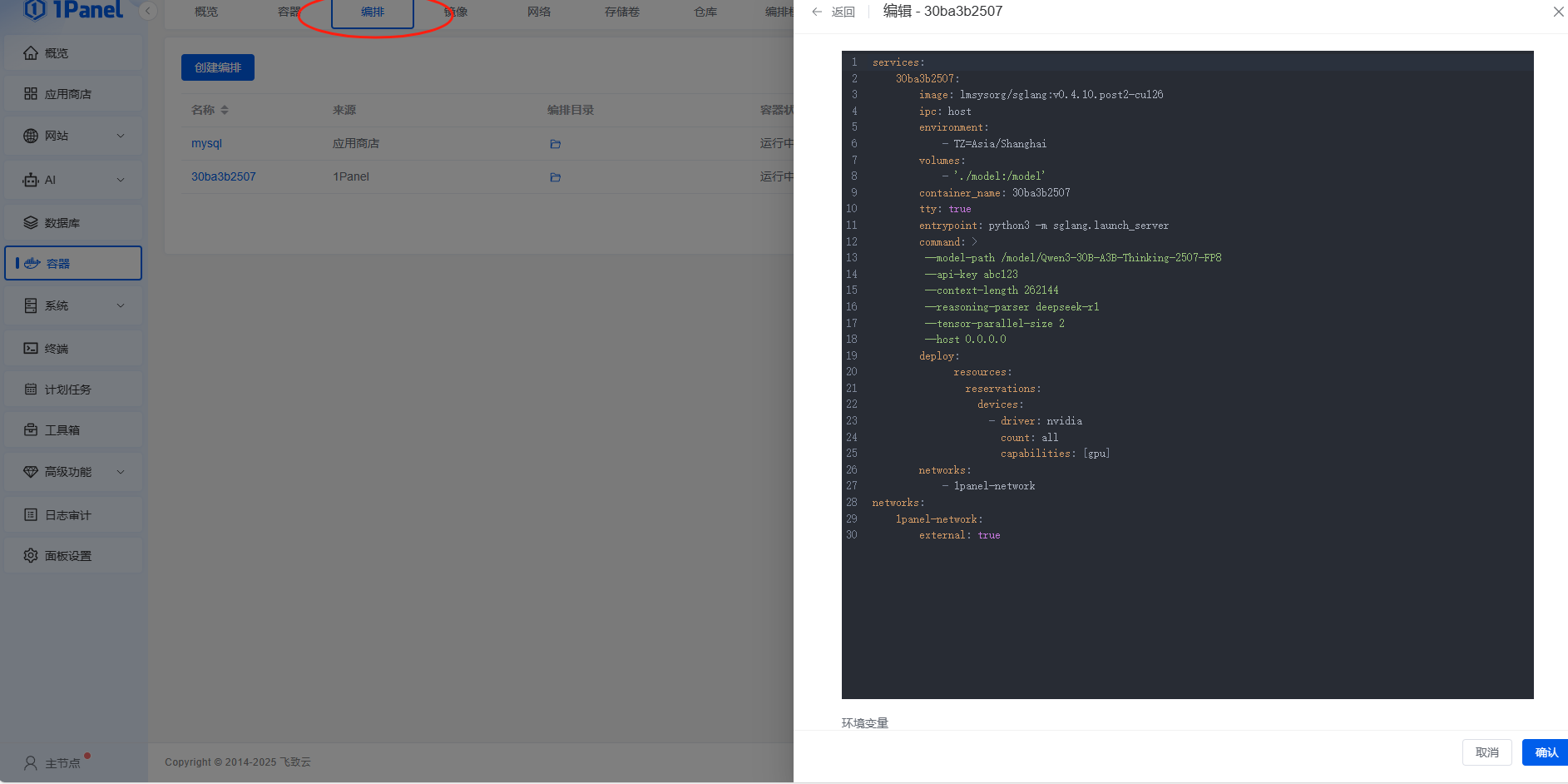
显存占用情况如下,256k上下文大概占用84G: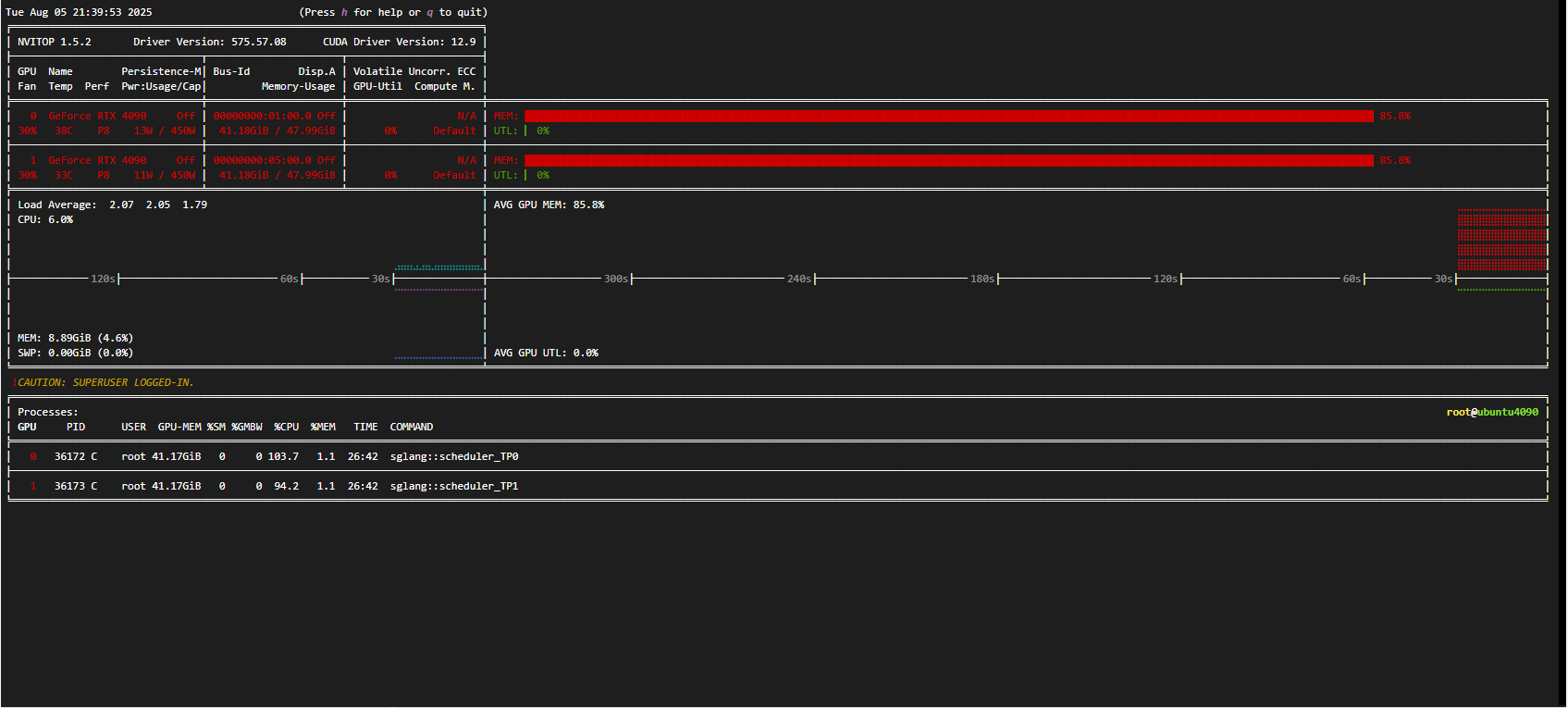
然后是1panel应用商店安装mysql,建议不开端口外部访问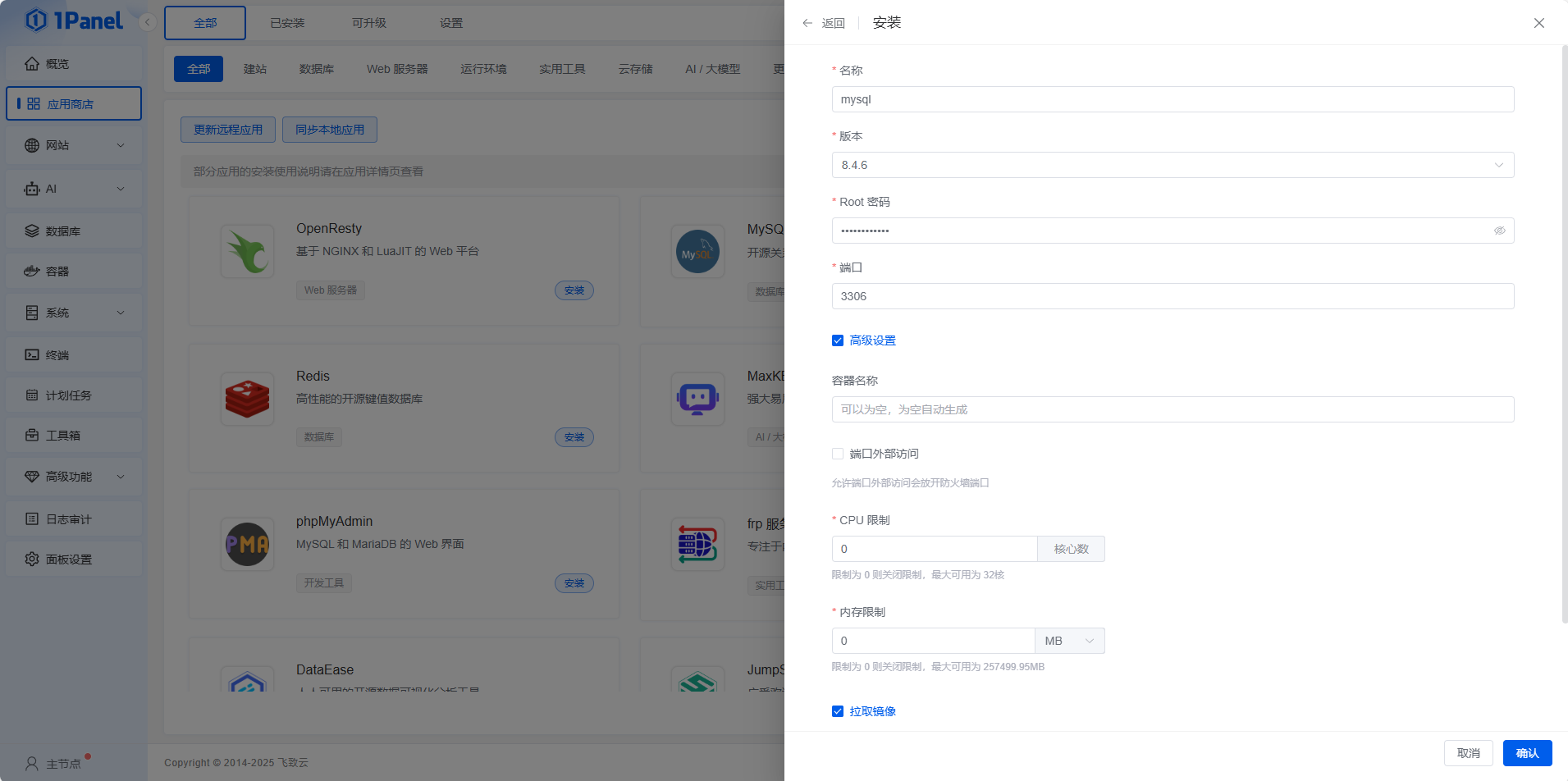
然后安装one-api,方便API管理,可以选择不开端口访问,使用lucky转发还便于套证书(这里就不写教程了,很简单),但是局域网环境就开放就行。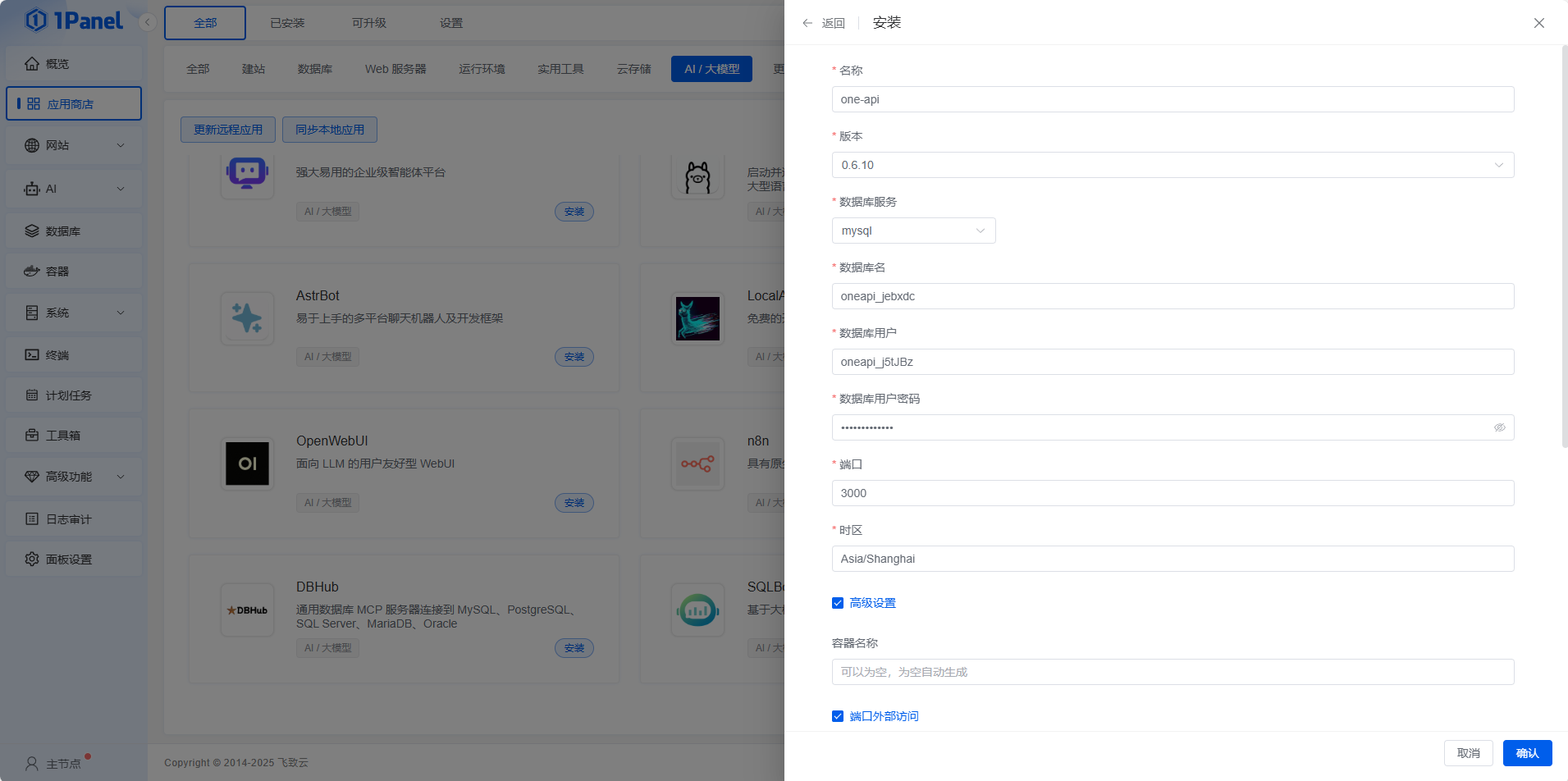
然后one-api中设置如下(默认3000端口,root/123456),填写容器名称即可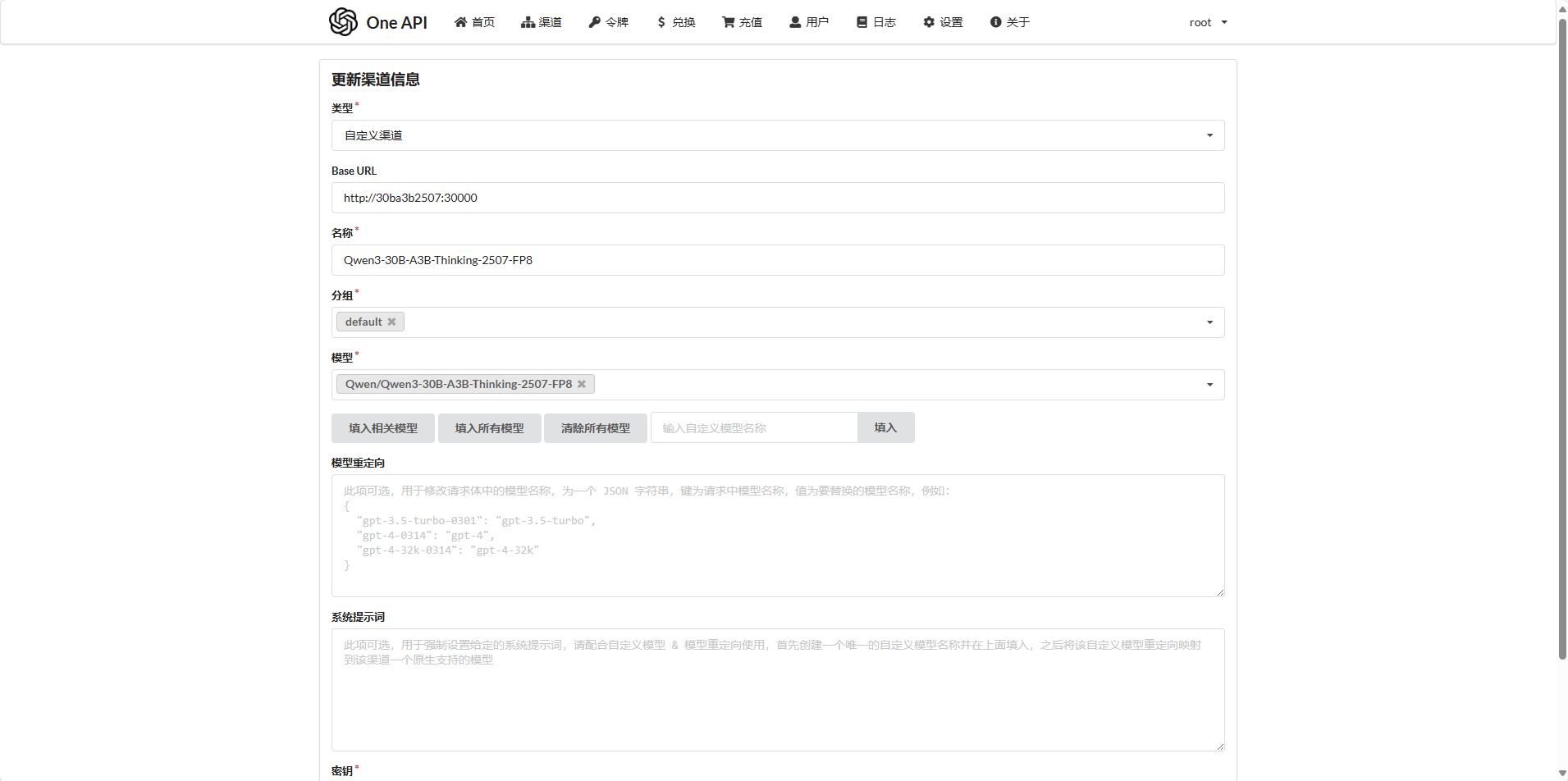
这里就不跑测试了,偷个懒,依旧是老朋友cherry,让直接写5000字小说。
token数是干到125t/s,之前测试过gguf的30ba3b,这模型基本逻辑能力是不用怀疑得,基本够用,最求轻量速度得可以考虑这个模型。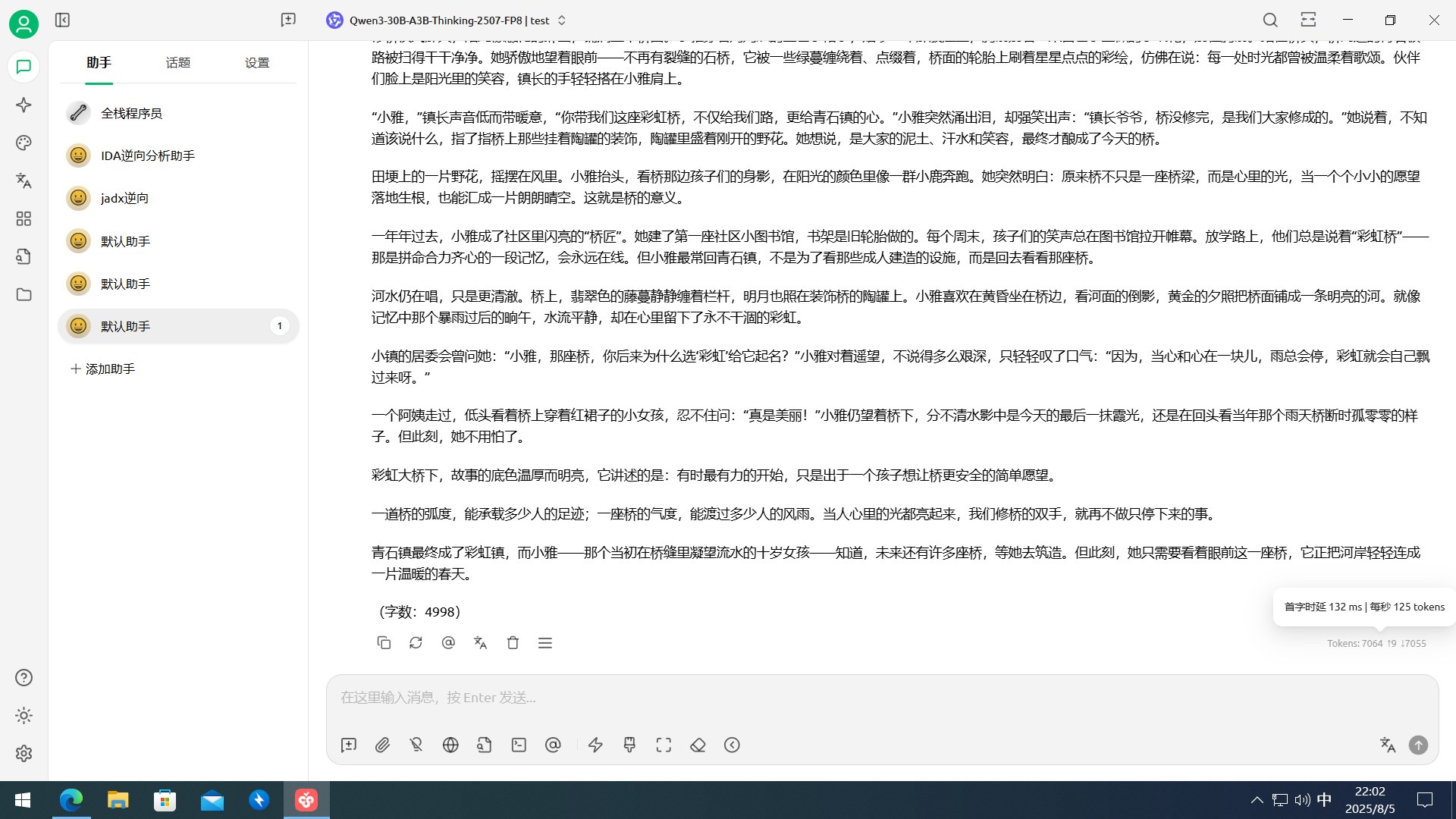
暴力使用情况下还是能稳定在88t/s左右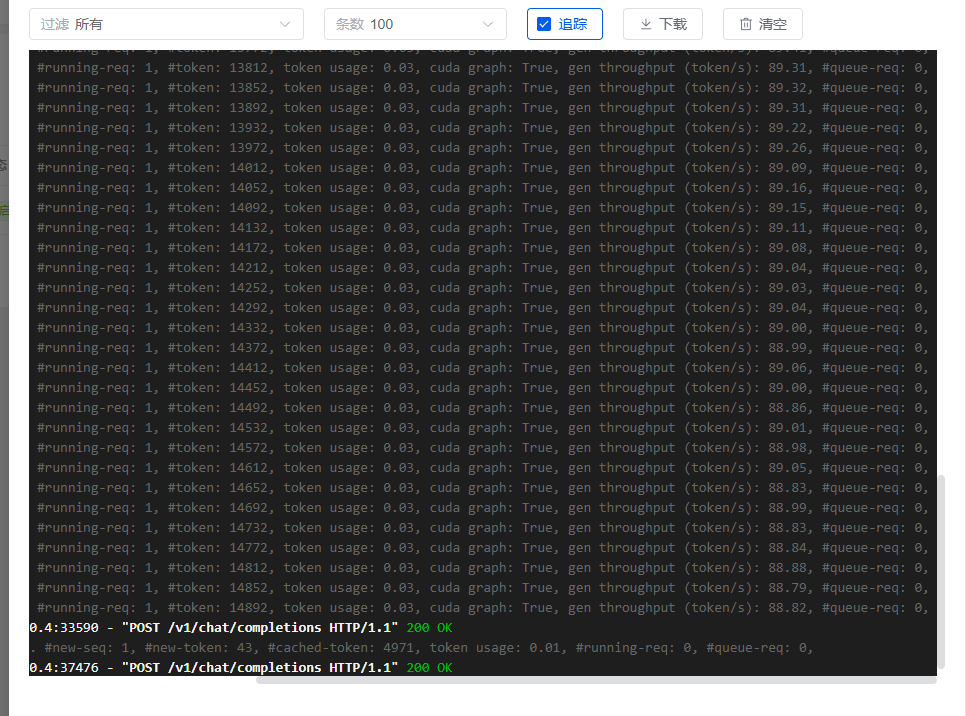

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)