MultiTalk部署-音频驱动的多人对话视频生成
│├── multitalk_example_1.json# 多人对话配置示例1。│├── multitalk_example_2.json# 多人对话配置示例2。│├── multitalk_example_3.json# 多人对话配置示例3。│├── multitalk_example_tts_1.json # 多人TTS示例。│└── single_example_tts_1.json# 单
MultiTalk 是一个基于音频驱动的多人对话视频生成框架。该项目能够根据输入的音频、参考图像和文本提示,生成包含多人交互的视频,支持唇形同步、单人/多人对话、歌唱、卡通角色等多种场景。
windows11 cuda12.1 GPU: NVIDIA GeForce RTX 4090 24G
git clone https://github.com/MeiGen-AI/MultiTalk.git
conda create -n multitalk python=3.10 -yconda activate multitalk
conda install -c conda-forge librosa ffmpeg
-- 官方基于liunx构建 要求: torch==2.4.1 xformers==0.0.28.post1 没有windows版本
-- 降低版本pip install torch==2.4.0+cu121
torchvision==0.19.0+cu121
torchaudio==2.4.0+cu121
xformers==0.0.27.post2
--index-url https://download.pytorch.org/whl/cu121# windows版本 liunx按官方来
pip install flash_attn == 2.7.4.post1 -i https://mirrors.aliyun.com/pypi/simple
pip install triton-windows == 3.3.1.post19 -i https://mirrors.aliyun.com/pypi/simple
pip install misaki[en] -i https://mirrors.aliyun.com/pypi/simple
pip install ninja -i https://mirrors.aliyun.com/pypi/simple
pip install psutil -i https://mirrors.aliyun.com/pypi/simple
pip install packaging -i https://mirrors.aliyun.com/pypi/simple# 注释以上依赖库后
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
#模型下载
pip install -U huggingface_hub
set HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480Phuggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-basehuggingface-cli download TencentGameMate/chinese-wav2vec2-base model.safetensors --revision refs/pr/1 --local-dir ./weights/chinese-wav2vec2-basehuggingface-cli download hexgrad/Kokoro-82M --local-dir ./weights/Kokoro-82Mhuggingface-cli download MeiGen-AI/MeiGen-MultiTalk --local-dir ./weights/MeiGen-MultiTalk
#复制权重文件
复制2文件:weights/MeiGen-MultiTalk/diffusion_pytorch_model.safetensors.index.json
weights/MeiGen-MultiTalk/multitalk.safetensors
到目录:
weights/Wan2.1-I2V-14B-480P
--部署完成
项目结构说明
```
MultiTalk/
├── app.py # Gradio Web界面应用
├── generate_multitalk.py # 主要生成脚本
├── requirements.txt # 项目依赖
├── README.md # 项目说明文档
├── LICENSE.txt # 许可证文件
├── assets/ # 资源文件
│ ├── efficiency.png # 效率图表
│ ├── logo.png # 项目Logo
│ ├── logo2.jpeg # 项目Logo2
│ ├── none_quant_efficiency.png # 非量化效率图表
│ └── pipe.png # 流程图
├── examples/ # 示例配置文件
│ ├── multi/ # 多人对话示例
│ ├── single/ # 单人示例
│ ├── multitalk_example_1.json # 多人对话配置示例1
│ ├── multitalk_example_2.json # 多人对话配置示例2
│ ├── multitalk_example_3.json # 多人对话配置示例3
│ ├── multitalk_example_tts_1.json # 多人TTS示例
│ ├── single_example_1.json # 单人配置示例
│ └── single_example_tts_1.json # 单人TTS示例
├── kokoro/ # TTS语音合成模块
│ ├── __init__.py # 模块初始化
│ ├── pipeline.py # TTS流水线
│ ├── model.py # TTS模型
│ ├── modules.py # TTS模块组件
│ ├── custom_stft.py # 自定义STFT
│ └── istftnet.py # 逆STFT网络
├── src/ # 源代码模块
│ ├── audio_analysis/ # 音频分析模块
│ ├── vram_management/ # 显存管理模块
│ └── utils.py # 工具函数
├── wan/ # 核心视频生成模块
│ ├── __init__.py # 模块初始化
│ ├── multitalk.py # MultiTalk核心流水线
│ ├── image2video.py # 图像到视频转换
│ ├── text2video.py # 文本到视频转换
│ ├── first_last_frame2video.py # 首末帧到视频转换
│ ├── vace.py # VACE模块
│ ├── wan_lora.py # LoRA适配器
│ ├── configs/ # 配置文件
│ ├── distributed/ # 分布式训练支持
│ ├── modules/ # 核心模块组件
│ └── utils/ # 工具函数
└── weights/ # 模型权重目录
├── chinese-wav2vec2-base/ # 中文Wav2Vec2模型
├── Kokoro-82M/ # TTS模型权重
├── MeiGen-MultiTalk/ # MultiTalk模型权重
├── Wan2.1-I2V-14B-480P/ # Wan基础模型权重
└── weight.txt # 权重说明文件
```
Web界面使用
```
# 基础启动(低显存模式)
python app.py --num_persistent_param_in_dit 0 --quant int8
# 推荐启动(RTX 4090 )
python app.py --num_persistent_param_in_dit 800000 --use_teacache --teacache_thresh 0.3 --size multitalk-480
```
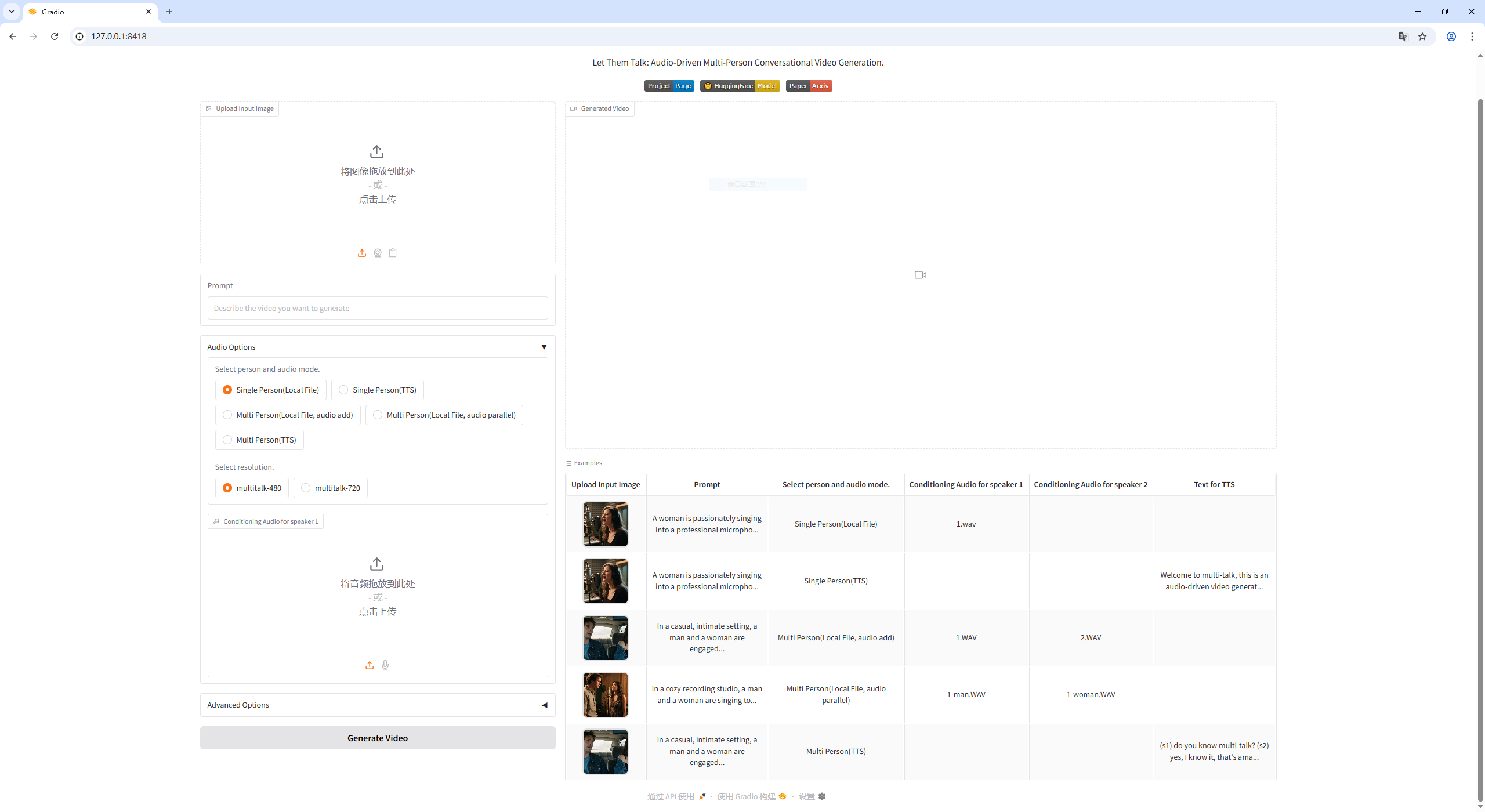
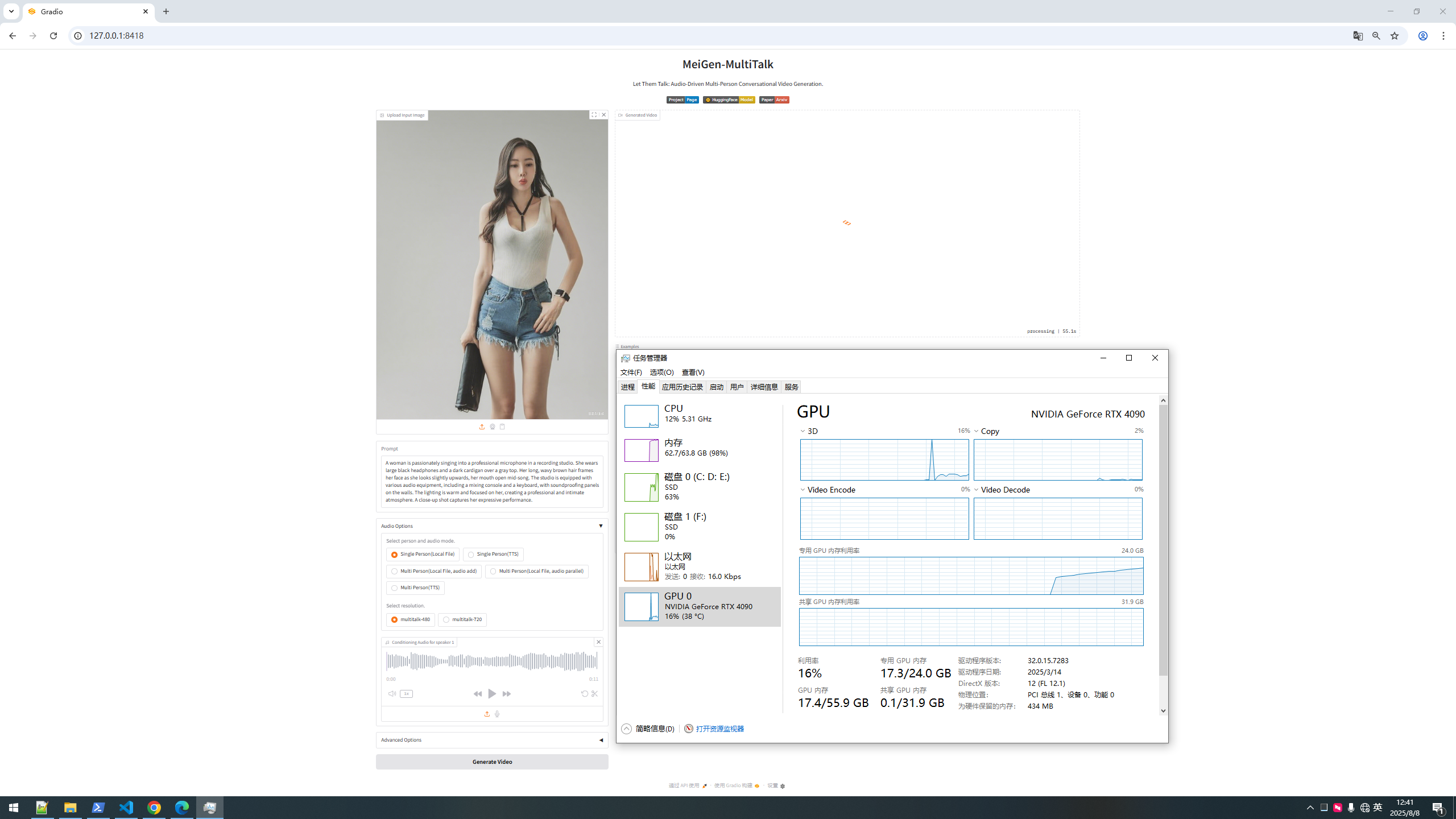
亲测: 一张图片 + 一段音频 + 一段提示词( 英文, 写明场景 动作 最终效果等)
即可生成一段真实视频 480P
4090显卡约10 - 15分钟左右 显存跑满

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)