【AI+医疗】MedicalGPT医疗大模型全流程实战:从零基础到专业训练指南
MedicalGPT是专为医疗行业打造的大语言模型训练项目,支持增量预训练、指令微调、RLHF、DPO、ORPO及最新GRPO全流程。项目兼容主流大模型,提供丰富训练脚本和数据集,支持从环境部署到模型推理的全流程操作。无论是医疗AI专业人士还是对大模型感兴趣的开发者,都能通过此项目快速构建医疗领域的专用大语言模型,实现从零基础到专业训练的进阶学习。
简介
MedicalGPT是专为医疗行业打造的大语言模型训练项目,支持增量预训练、指令微调、RLHF、DPO、ORPO及最新GRPO全流程。项目兼容主流大模型,提供丰富训练脚本和数据集,支持从环境部署到模型推理的全流程操作。无论是医疗AI专业人士还是对大模型感兴趣的开发者,都能通过此项目快速构建医疗领域的专用大语言模型,实现从零基础到专业训练的进阶学习。
摘要:
MedicalGPT 是一款专为医疗行业打造的大语言模型训练项目,支持增量预训练、指令微调、人类反馈强化学习(RLHF)、直接偏好优化(DPO)、ORPO 及最新 GRPO 全流程。项目兼容主流大模型,配套丰富训练脚本和数据集,为行业用户量身定制。本文将带你全面了解 MedicalGPT 的架构、特性、训练流程、数据集与推理部署实践,适合医疗AI、数据科学、自然语言处理等专业人士参考和实践。
https://github.com/shibing624/MedicalGPT
MedicalGPT:医疗GPT大模型全流程训练实践指引
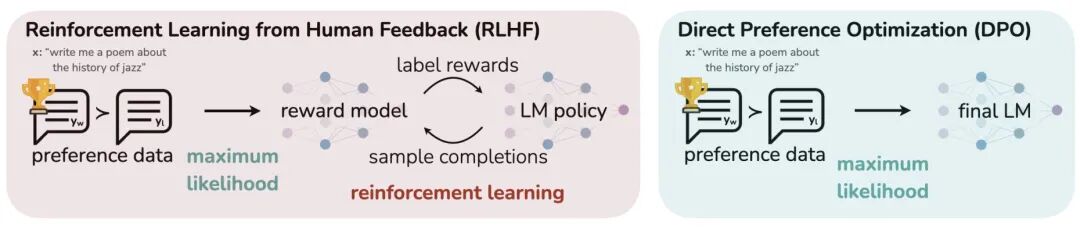 图1. MedicalGPT 项目Logo(仅示意,文章内所有图表建议读者在原项目release页查阅)
图1. MedicalGPT 项目Logo(仅示意,文章内所有图表建议读者在原项目release页查阅)
一、项目简介
MedicalGPT 致力于打造医疗领域的专用大语言模型,完整复现了跨语种、跨场景的ChatGPT训练流程,覆盖增量预训练(PT)、有监督微调(SFT)、人类反馈强化学习(RLHF)、奖励模型建模(RM)以及直接偏好优化(DPO)、单步多偏好融合优化(ORPO)、全新生成式偏好优化(GRPO)等核心环节。通过自有大数据和全流程脚本,助推医学AI与行业大模型落地创新。
主要训练流程图及重要功能进阶表请参考原项目release文档。
1.1 医疗专属强化流程
-
PT:增量预训练,大规模行业文档,适配领域分布(可选)
-
SFT
:有监督指令微调,注入多类医学知识
-
RLHF
:奖励模型+强化步步相扣
-
RM
:奖励打分,建模人类“有帮助、诚实、无伤害”偏好
-
RL
:SFT模型经RM打分用奖励/惩罚反向更新逐步对齐
-
DPO
:直接偏好优化,不经复杂RL,优化行为精确、高效易用
-
ORPO
:单步多偏好融合,无需参考模型,SFT与对齐一体,无灾难遗忘
-
GRPO
:2025年最新,支持LoRA/全参,用原生RL方法巧获 “aha moment”
二、快速上手与环境部署
2.1 安装和依赖
shellCopy code
git clone https://github.com/shibing624/MedicalGPT
cd MedicalGPT
pip install -r requirements.txt --upgrade
图2. requirements.txt 部分依赖包列表
2.2 硬件需求简表
| 训练方式 | 精度 | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| 全参数 | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| LoRA | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA(4bit) | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
三、训练主流程与核心脚本
-
增量预训练
python pretraining.py
或 sh run_pt.sh
-
有监督微调
python supervised_finetuning.py
或 sh run_sft.sh
-
奖励模型建模
python reward_modeling.py
或 sh run_rm.sh
-
直接偏好优化
python dpo_training.py
或 sh run_dpo.sh
-
强化学习(PPO)
python ppo_training.py
或 sh run_ppo.sh
-
单步融合优化(ORPO)
python orpo_training.py
或 sh run_orpo.sh
-
GRPO训练/脚本
支持LoRA+全参 QLoRA混合(推荐高端硬件环境执行)
-
全流程训练pipeline
run_training_dpo_pipeline.ipynb
(DPO训练全流程,15分钟可跑通)
run_training_ppo_pipeline.ipynb(RLHF全流程,约20分钟)
详细训练流程及各参数说明见官方Wiki
流程示意图(请在原项目文档中查阅各阶段pipeline示意图及代码示意说明)
四、模型兼容性与模板支持
支持市面绝大多数主流大模型(含国产大模型)及其指令模板结构:
| 模型名称 | 支持参数量 | 适配模板 | 标的模块 |
|---|---|---|---|
| Baichuan/Baichuan2 | 7B/13B | baichuan/baichuan2 | W_pack |
| BLOOMZ | 560M-176B | vicuna | query_key_value |
| LLaMA/LLaMA2/LLaMA3 | 7B-70B | alpaca/llama2/llama3 | q_proj,v_proj |
| Qwen/Qwen1.5/2/2.5 | 1.8B-110B | qwen | q_proj,v_proj |
| Mistral/InternLM2/Yi/Cohere等 | … | … | … |
T4. 主要模型与适配模块、模板布局表(完整支持列表和模板见README Supported Models小节)
五、核心数据集汇总
| 分类 | 数据集名称 | 内容和规模 | 来源 |
|---|---|---|---|
| 医疗SFT/奖励数据 | shibing624/medical | 240万条中英文医疗数据 | 官方自建 |
| 多轮医疗QA | shibing624/huatuo_medical_qa_sharegpt | 22万条 | 华佗项目 |
| 多语言对话 | shibing624/sharegpt_gpt4 | 10万条 GPT4对话 | 官方 |
| 中文Alpaca | shibing624/alpaca-zh | 2万条 | 官方 |
| 偏好数据集 | shibing624/DPO-En-Zh-20k-Preference | 2万对中英偏好 | 官方 |
| 指令/Guanaco/Belle/moss等 | 见下表 | 百万级 | BelleGroup、Chinese-Vicuna等 |
更多多轮、偏好/奖励、Alpaca等公开数据都已整理为支持格式,一键接入
六、推理部署与API调用
-
本地推理(Gradio Web交互)
shellCopy code CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir启动后浏览器访问,输入问题即得答案
-
命令行推理(单轮/多卡/数据批量预测)
shellCopy code CUDA_VISIBLE_DEVICES=0 python inference.py --base_model path_to_model --lora_model path_to_lora --interactive # 多卡推理 CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 inference_multigpu_demo.py --base_model shibing624/vicuna-baichuan-13b-chat -
vLLM加速多卡部署
sh vllm_deployment.sh -
模型推理结果展示(部分真实Case)
图6. 医疗健康咨询模型实际推理结果片段(如: 儿童发烧、肛门病变、白带异常、皮肤痤疮、科普答疑等)
-
详见README中的Inference Examples部分,内容涵盖常见病症问诊、科普、健康管理等,均来自模型实测输出。
七、典型发布版本与特性演进
| 版本号 | 发布时间 | 重大更新 |
|---|---|---|
| v2.4 | 2025.4 | 支持LoRA+全参GRPO训练, RL体验优化 |
| v2.3 | 2024.9 | 适配Qwen-2.5系列模型 |
| v2.2 | 2024.8 | 新增医患角色扮演数据生成与训练 |
| v2.1 | 2024.6 | 支持Qwen-2系列 |
| v1.9 | 2024.4 | 首发ORPO方法,专项脚本支持 |
T5. 历史版本特性演化表与功能概述(详情见各Release实录)
八、贡献、授权与社区合作
-
项目授权
:Apache-2.0,代码可商用,模型和数据仅限研究。
-
贡献指南
:通过PR、单元测试,遵循标准CI流程参与共建。
-
致谢与引用
:
项目广泛借鉴 DPO 原始论文、Alpaca-Lora、Chinese-LLaMA-Alpaca、LongLoRA 等社区杰作,如在论文及研究中引用请参照如下:bibCopy code @misc {MedicalGPT, title={MedicalGPT: Training Medical GPT Model}, author={Ming Xu}, year={ 2023 }, howpublished={\url{https://github.com/shibing624/MedicalGPT}} }
九、结语与应用前瞻
MedicalGPT 提供了标准化、易扩展的行业大模型全流程训练范式,对于医疗AI领域的大模型定制研发、自主可控与知识能力强泛化具备重要参考价值。无论是作为企业级大模型基座还是学术研究,均可快速复用与拓展。未来版本将持续适配新模型,丰富行业任务类型扩展,并优化性能表现。
十、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 46
46 0
0- 0



 已为社区贡献350条内容
已为社区贡献350条内容

所有评论(0)