Streamlit使用
提取模型回复的内容(Ollama 响应格式:{'message': {'role': 'assistant', 'content': '回复'}}):param messages: 完整聊天记录,格式为 [{'role': 'assistant/user', 'content': '内容'}, ...]# message的格式是: {'role':'assistant 或者 user', 'con
1. 安装
官方网站
python环境中安装
pip install streamlit==1.32.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装后测试
streamlit hello
2. 基础语法
图片中的分割线应该是divider

streamlit状态记录:Streamlit session_state

标题
使用 st.title() 可以设置标题内容。
st.title('Streamlit教程')
段落write
段落就是 HTML 里的 <p> 元素,在 streamlit 里使用 st.write('内容') 的方式去书写。
import streamlit as st
st.write('Hello')
使用markdown
streamlit 是支持使用 markdown 语法来写页面内容的,只需使用单引号或者双引号的方式将内容包起来,并且使用 markdown 的语法进行书写,页面就会出现对应样式的内容。
import streamlit as st "# 1级标题" "## 2级标题" "### 3级标题" "#### 4级标题" "##### 5级标题" "###### 6级标题"
图片
渲染图片可以使用 st.image() 方法,也可以使用 markdown 的语法。
st.image(图片地址, [图片宽度]) ,其中图片宽度不是必填项。
import streamlit as st
st.image('./avatar.jpg', width=400)
表格
streamlit 有静态表格和可交互表格。表格在数据分析里属于常用组件,所以 streamlit 的表格也支持 pandas 的 DataFrame 。
静态表格 table
静态表格使用 st.table() 渲染,出来的效果就是 HTML 的 <table>。
st.table() 支持传入字典、pandas.DataFrame 等数据。
import streamlit as st
import pandas as pd
st.write('dict字典形式的静态表格')
st.table(data={
'name': ['张三', '李四', '王五'],
'age': [18, 20, 22],
'gender': ['男', '女', '男']
})
st.write('pandas中dataframe形式的静态表格')
df = pd.DataFrame(
{
'name': ['张三', '李四', '王五'],
'age': [18, 20, 22],
'gender': ['男', '女', '男']
}
)
st.table(df)
可交互表格 dataframe
可交互表格使用 st.dataframe() 方法创建,和 st.table() 不同,st.dataframe() 创建出来的表格支持按列排序、搜索、导出等功能。
import streamlit as st
import pandas as pd
st.write('dict字典形式的可交互表格')
st.dataframe(data={
'name': ['张三', '李四', '王五'],
'age': [18, 20, 22],
'gender': ['男', '女', '男']
})
st.write('pandas中dataframe形式的可交互表格')
df = pd.DataFrame(
{
'name': ['张三', '李四', '王五'],
'age': [18, 20, 22],
'gender': ['男', '女', '男']
}
)
st.dataframe(df)
分割线
分隔线就是 HTML 里的 <hr> 。在 streamlit 里使用 st.divider() 方法绘制分隔线。
import streamlit as st st.divider()
输入框
知道怎么声明变量后,可以使用一个变量接收输入框的内容。
输入框又可以设置不同的类型,比如普通的文本输入框、密码输入框。
-
普通输入框
输入框使用 st.text_input() 渲染。
name = st.text_input('请输入你的名字:')
if name:
st.write(f'你好,{name}')
☆ 密码
如果要使用密码框,可以给 st.text_input() 加多个类型 type="password"。
import streamlit as st
pwd = st.text_input('密码是多少?', type='password')
☆ 数字输入框 number_input
数字输入框需要使用 number_input
import streamlit as st
age = st.number_input('年龄:')
st.write(f'你输入的年龄是{age}岁')
众所周知,正常表达年龄是不带小数位的,所以我们可以设置 st.number_input() 的步长为1,参数名叫 step。
# 省略部分代码
st.number_input('年龄:', step=1)
这个步长可以根据你的需求来设置,设置完后,输入框右侧的加减号每点击一次就根据你设置的步长相应的增加或者减少。
还有一点,人年龄不可能是负数,通常也不会大于200。可以通过 min_value 和 max_value 设置最小值和最大值。同时还可以通过 value 设置默认值。
st.number_input('年龄:', value=20, min_value=0, max_value=200, step=1)
多行文本框 text_area
创建多行文本框使用的是 st.text_area(),用法和 st.text_input() 差不多。
import streamlit as st
paragraph = st.text_area("多行内容:")
Chat Elements
-
Chat文本输入框
import streamlit as st prompt = st.chat_input("Say something") if prompt: st.write(f"User has sent the following prompt: {prompt}") -
Chat Message
# 导入 Streamlit 库,Streamlit 是一个用于快速创建数据应用的 Python 库
import streamlit as st
# 使用 st.chat_input 创建一个聊天输入框,提示用户输入问题
prompt = st.chat_input('请输入您的问题: ')
st.write(f'您的问题是: {prompt}')
# 使用 st.chat_message 创建一个用户消息容器,用于显示用户的消息
# 'user' 表示这是用户发送的消息
with st.chat_message('user'):
# 在用户消息容器中显示文本 'Hello '
st.write('Hello ')
# 使用 st.chat_message 创建一个消息容器,用于显示回复消息
message = st.chat_message('assistant')
# 在消息容器中显示文本 'Hello Human',模拟助手的回复
message.write('Hello Human')
小结
-
实现基于Streamlit前端页面开发
-
标题:
-
输入框
-
多行文本框
-
模型调用
import ollama
def get_response(messages):
"""
接收聊天记录列表,调用 Ollama 模型获取响应
:param messages: 完整聊天记录,格式为 [{'role': 'assistant/user', 'content': '内容'}, ...]
:return: 模型回复内容
"""
try:
# 直接将完整聊天记录传给 ollama.chat() 的 messages 参数(保留上下文)
response = ollama.chat(
model='qwen2:0.5b', # 你的本地模型名,确保已通过 ollama pull 下载
messages=messages # 传入完整历史对话,模型会自动关联上下文
)
# 提取模型回复的内容(Ollama 响应格式:{'message': {'role': 'assistant', 'content': '回复'}})
return response['message']['content']
except Exception as e:
return f"模型调用失败:{str(e)}(请确保 Ollama 服务已启动,且模型已下载)"
# 4. 测试自定义的 工具函数.
if __name__ == '__main__':
messages = [{'role': 'user', 'content': '王者荣耀中的孙悟空英雄, 有哪些操作技巧'}]
response = get_response(messages)
print(response)
前端实现
# 1. 导包
import streamlit as st # streamlit库: Python代码实现搭建前端页面 并 部署
from langchain.memory import ConversationBufferMemory # langchain库: 聊天机器人核心模块, ConversationBufferMemory: 聊天记录存储器(存储所有聊天信息的)
from chat_utils import get_response # 自定义模块: 封装了模型处理函数, 获取模型处理结果
# 2. 标题.
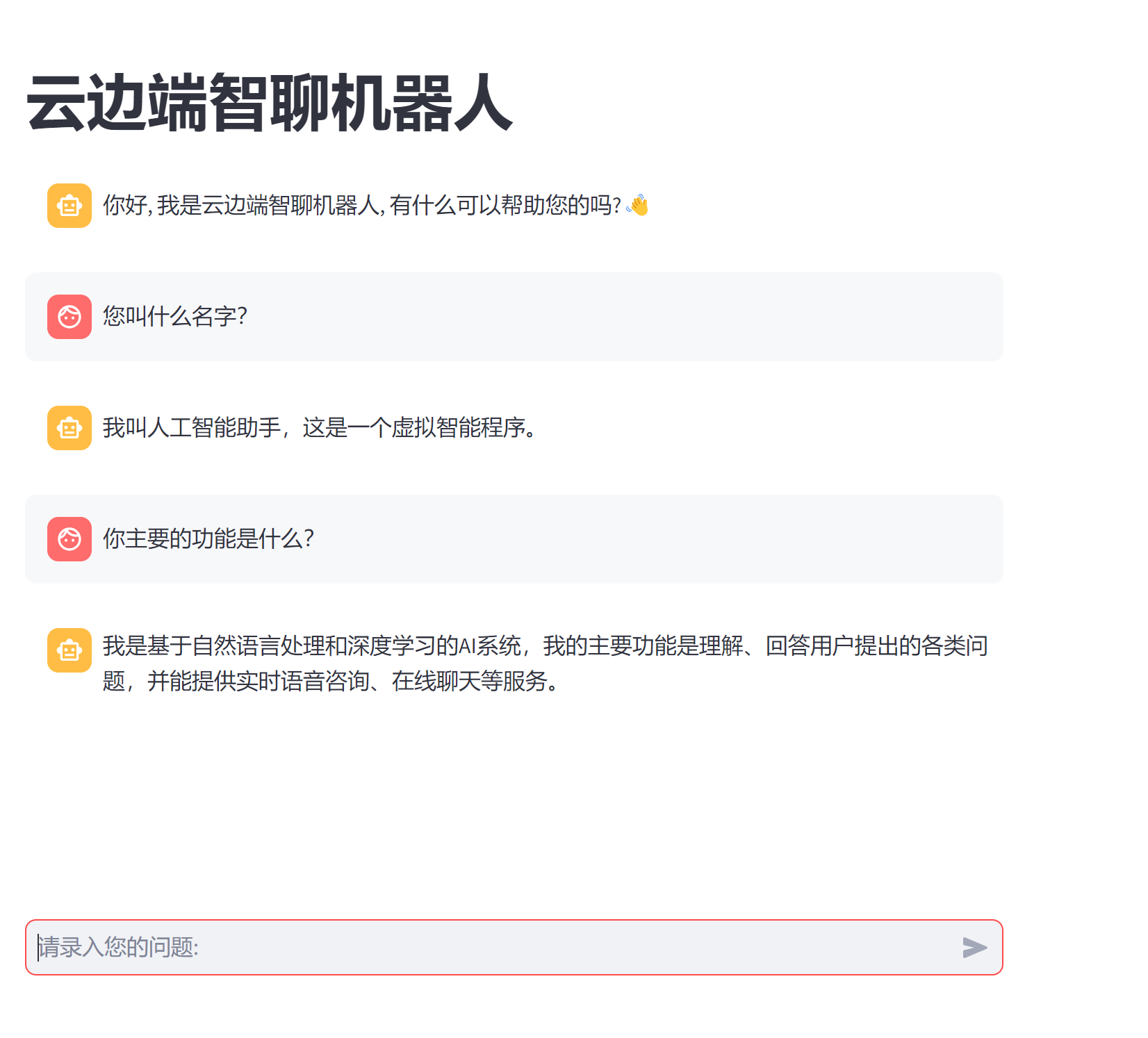
st.title('云边端智聊机器人')
# 3. 判断是否有 历史消息记录对象, 如果没有就创建, 并存储所有的消息记录.
if 'memory' not in st.session_state: # session_state: 存储会话状态数据的字典, 用于存储会话数据.
# 3.1 创建 ConversationBufferMemory 对象, 并存储到 session_state 中.
st.session_state.memory = ConversationBufferMemory()
# 3.2 添加 机器人欢迎语.
st.session_state.messages = [{'role':'assistant', 'content': '你好, 我是云边端智聊机器人, 有什么可以帮助您的吗?👋'}]
# 4.遍历 session_state.messages, 显示所有消息记录.
for message in st.session_state.messages:
# message的格式是: {'role':'assistant 或者 user', 'content': '内容'}
# 4.1 通过 聊天消息容器, 用于显示 当前角色的内容.
with st.chat_message(message['role']):
# 4.2 显示当前角色的内容.
st.markdown(message['content'])
# st.session_state.messages.append({'role':'user', 'content': '你认识夯哥嘛?'})
# st.session_state.messages.append({'role':'assistant', 'content': '认识, 云边端最纯洁的老师!'})
# 5. 接收用户录入的问题.
prompt = st.chat_input('请录入您的问题: ')
# 6. 判断用户用户录入的问题不为空, 我们就继续向下执行.
if prompt:
# 7. 把用户的信息添加到 历史消息记录中, 并展示到前端页面.
st.session_state.messages.append({'role':'user', 'content': prompt})
st.chat_message('user').markdown(prompt)
# 8. (细节: 加入延时等待提示组件) 调用自定义的 chat_util模块中的 get_response()函数, 获取模型的处理结果.
with st.spinner('AI小助理正在思考中...'):
response = get_response(st.session_state.messages)
# 9. 把模型的处理结果添加到 历史消息记录中, 并展示到前端页面.
st.session_state.messages.append({'role': 'assistant', 'content': response})
st.chat_message('assistant').markdown(response)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)