RAG检索技术深度解析:从关键词到混合检索的演进之路
本文探讨了RAG系统中的检索技术演进,从传统关键词检索(布尔检索、TF-IDF)到现代向量检索(Embedding技术),再到混合检索与重排序技术。文章指出单一检索方法存在局限性,混合检索结合了语义和关键词优势,而重排序则进一步提升精准度。作者建议RAG项目分阶段实施:从纯向量检索到混合检索,最终引入重排序技术以满足不同场景需求。文章强调检索系统应兼顾语义理解和精确匹配,才能构建真正智能的检索体系
引言
在目前AI人工智能领域中,使用较多的就是RAG(检索增强生成)。无论大小企业都尝试着做私有企业知识库。本文将深入探讨RAG系统的核心技术——检索机制。从传统关键词检索到现代向量检索,再到更先进的混合检索和双路召回,我们将一起探索如何构建一个真正智能的检索系统
1.核心概念阐述
什么是“检索”?简单来说,检索的是在信息空间中快速定位最相关的内容 。其中有三个关键点,
1.表示问题:如何用数学方式表示文档和查询?
2.匹配问题:如何高效计算相似度?
3.排序问题:如何从候选集中选出最优结果?
在这三个问题上,传统检索方法和现代检索方法呈现不同的思路。
2.传统关键词检索技术
1.布尔检索(Boolean Retrieval)是搜索引擎的鼻祖。它的核心是一种极其高效的数据结构——倒排索引(Inverted Index)举个简单的例子来理解“倒排索引”:
文档A: 今天我做了学习了RAG的相关知识,有很多地方不理解。
文档B: RAG技术的核心是的检索增强生成。
布尔检索构建的倒排索引是这样的(下面表格只用了部分词):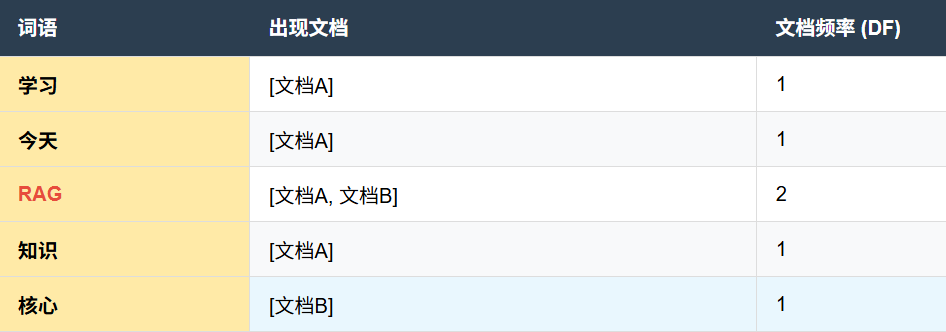
当你查询“RAG知识”时,系统进行的是集合的交集运算:
取出“RAG”的列表[文档A,文档B]
取出“知识”的列表[文档A],取二者的交集也就是[文档A]
从这里可以看出布尔索引检索的局限性,非黑即白。对于一个片段的判断是要么有用要么没用,这会漏掉很多信息,最典型的例子就是无法处理同义词问题,例如检索“手机”就只检索“手机”两个字,“电话”和“手机”意义几乎相同,但它无法理解。
2.TF-IDF 算法:并非所有的词都同样重要。
它的核心思想就是:多个文档中,一个在当前文档的出现频率越高,在别的文档出现的次数越少,该词对于当前文档就越重要。举个例子,假设有三个文档:
1.我爱吃苹果和香蕉 2.我爱吃苹果 3.我爱读书
词频 (TF) :在文档1中,“香蕉”出现了1次,而文档1总共有5个词,所以 TF 较高。
逆文档频率 (IDF) :在所有3个文档中,只有文档1包含了“香蕉”,所以 IDF 非常高。
结果:“香蕉”的 TF 和 IDF 都很高,因此它的 TF-IDF 值很高,这表明它是能将文档1与其他文档区分开来的关键词。相比之下,“我”和“爱”虽然词频高,但它们在所有文档中都出现,IDF极低,因此不重要。
在计算完每个词的重要性后,会将这些片段用向量进行表示,通过余弦相似度计算片段的相关性,大大提升了检索的灵活性。
但它也有缺点,对长文本和语义敏感任务效果有限。
3.稠密向量检索的革命
这是RAG项目的核心,它解决了“语义鸿沟的难题”。
通过一种叫 Embedding(嵌入) 的技术,真正让计算机“听懂”了人话。
例如,国王 - 男人 + 女人 = 女王; 狗 + 弃养 = 流浪狗。
怎么理解 Embedding?想象一下,我们在一个巨大的多维空间里(虽然我们的大脑只能想象三维,但计算机可以处理几百几千维)。在这个空间里,每一个词、每一句话都是一个坐标点。 这个坐标不是随便标的,而是遵循一个原则:意思越像,距离越近。通过计算距离的远近来判断语义的相关性。
这种技术完美吗?并不是。在实际开发中,我发现向量检索也有个巨大的短板,甚至可以说是它的“死穴”。因为它太关注“大概意思”了,导致它在处理精确信息时表现很差。
例如,用户问: “10kV 变压器的绝缘电阻标准是多少?”
向量检索召回: 可能会给你找出 35kV 或 110kV 的标准。
原因: 在向量空间里,“10kV”和“35kV”在语义上极度接近(都是“电压等级”),向量模型认为它们是相似的,却忽略了那个具体的数字才是关键。
从这引出了本文的重点,混合检索(我既要大概意思相近,也要关键词相同,双重保障)
4.混合检索的必然性
为什么需要混合检索?因为单一检索方法都有明显的适用边界:
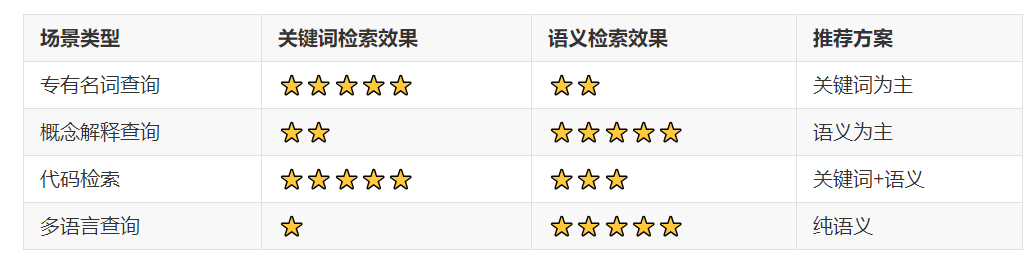
通过同时进行关键词检索和语义检索,大幅提高检索的精准性。
语义检索用的是上述的稠密向量,关键词检索用的是BM-25,它是IT-IDF的优化版(也是根据词的重要性来进行检索的)
检索完毕则需要对结果进行融合,目前有两种主流方案:
1. 简单粗暴的线性加权
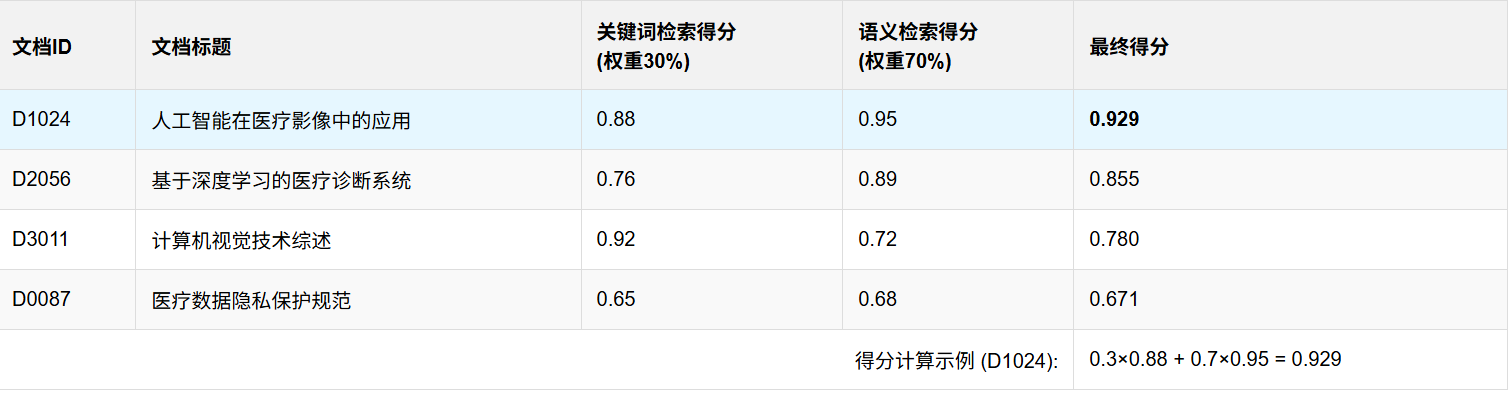
这是最直观的方法。我们人为地给两个分数定权重。
比如:最终得分 = 0.7 * 向量分数 + 0.3 * 关键词分数。
优点:计算快,逻辑简单。
缺点:极其难调参! 哪怕你归一化了,不同问题的分布也不一样。有时候你需要语义占主导,有时候你需要关键词占主导,写死权重往往会导致“两头不讨好”。
2.RRF(倒数排名融合)
这是目前 RAG 界的“版本答案”。RRF(Reciprocal Rank Fusion)不看具体分数,只看排名。 它的逻辑是:不管你考了多少分,我只看你在全班排第几。
-
如果文档 A 在关键词检索排第 1,在向量检索也排第 1,那它肯定是最好的。
-
如果文档 B 在关键词排第 50,向量排第 2,那它的综合排名也会很高。
这个算法最大的魅力在于它不需要任何参数调整。它平滑了不同检索器的分数差异,在大量的实战测试中,RRF 的稳定性远超线性加权。
3.核心杀手锏:重排序(Re-ranking)
讲到混合检索,就绝对绕不开重排序(Re-ranker)。如果说混合检索是“海选”,把几千个文档筛选出前 50 个;那重排序就是“决赛”,用一个更精细的模型,把这 50 个文档仔仔细细读一遍,排定最终座次。
不夸张地说,混合检索 + 重排序 已经成为企业级 RAG 系统的标配架构。
在我的项目中,加上 Re-ranker 后,RAG 的准确率(Hit Rate)通常能从 60% 直接飙升到 85% 以上。
为什么它这么强?你可以这样理解, 因为前面的向量检索(Bi-Encoder)为了快,是把问题和文档分开计算的,它们之间没有直接的交互。而 Re-ranker(Cross-Encoder)是把“问题”和“文档”拼在一起扔进模型里,让模型逐字逐句地分析它们的相关性。
虽然它慢,但因为它只处理前 50 条数据,所以延迟完全可控(通常在 ms 级别)。
在目前开源模型中,bge-reranker-v2-m3是优质的重排序模型,它和通常bge-m3(词嵌入)组合成为rag检索的搭档,对于项目初期需要快速搭建项目的场景,它们通常是比较好的选择。
5. 总结与展望:构建高可用的检索系统
回顾这一路的技术演进,从死板但精确的关键词检索,到灵活但偶尔“幻觉”的向量检索,再到集大成者的混合检索+重排序,我们其实是在不断逼近人类处理信息的方式:既要有模糊的联想能力(语义),又要有严谨的查证能力(关键词)。
项目建议,在实际落地 RAG 项目时,不要一上来就追求最复杂的架构。根据我的实战经验,建议按以下阶段演进:
-
阶段一:快速验证期 (MVP)
-
架构:纯向量检索 (IVF_FLAT )。
-
适用:内部Demo、对精度要求不高的闲聊助手。
-
评价:搭建最快,成本最低,能解决80%的语义问题。
-
-
阶段二:生产上路期
-
架构:混合检索 (Vector + BM25) + RRF融合。
-
适用:企业知识库、合同检索、法规查询。
-
评价:解决了专有名词和精确数字查不到的问题,系统鲁棒性大幅提升。
-
-
阶段三:极致体验期
-
架构:混合检索 + 重排序 (Re-ranker)。
-
适用:智能客服、金融投研、医疗问诊等对准确率有苛刻要求的场景。
-
评价:虽然增加了几十毫秒的延迟和算力成本,但能换来召回率质的飞跃。这也是目前 SOTA的标准解法。
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 41
41 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)