论文精读:《MOTR: End-to-End Multiple-Object Tracking with Transformer》
本文提出MOTR,一种基于Transformer的端到端多目标跟踪方法。针对传统方法依赖后处理关联导致的非端到端问题,MOTR创新性地扩展DETR框架,引入可逐帧传递更新的"轨迹查询"(Track Query)机制来建模目标时序信息。通过轨迹感知标签分配(TALA)、时序聚合网络(TAN)和集体平均损失(CAL)三个关键技术,MOTR实现了视频序列的端到端时序建模。
基本概况
- 论文标题:MOTR: End-to-End Multiple-Object Tracking with Transformer
- 来源信息:这是发布在 arXiv 上的计算机视觉(CV)方向论文,最新版本提交于 2022 年 7 月。
- 作者团队:主要作者来自 旷视科技(MEGVII Technology),部分作者来自上海交通大学。通讯作者是旷视的 Tiancai Wang。
- 代码开源:官方代码已在 GitHub 上开源(megvii-research/MOTR),便于社区复现和研究。
Abstract.
第一部分:问题背景与痛点
原文:Temporal modeling of objects is a key challenge in multiple-object tracking (MOT). Existing methods track by associating detections through motion-based and appearance-based similarity heuristics. [cite_start]The post-processing nature of association prevents end-to-end exploitation of temporal variations in video sequence. [cite: 5, 6, 7]
- 翻译:目标的时间建模是多目标跟踪(MOT)中的一个关键挑战。现有方法通过基于运动和外观相似度的启发式规则来关联检测结果以进行跟踪。这种关联操作的“后处理”性质阻碍了对视频序列中时间变化的端到端利用。
- 深度解析:
- 痛点:作者指出了当时主流算法(如 DeepSORT, ByteTrack 等)的通病——Tracking-by-Detection(先检测后跟踪)。这些方法把任务割裂为两步:① 每一帧先用检测器(如 YOLO)把框画出来;② 之后用卡尔曼滤波(Motion)或 Re-ID 特征(Appearance)通过人工设计的规则(Heuristics,例如 IoU 阈值匹配)把框连成线。
- 局限性:这种“后处理”是独立于神经网络训练之外的。也就是说,网络只学会了“找框”,没学会“这个框下一帧去哪了”。这导致网络无法利用视频的时间连贯性进行学习,这就是所谓的“非端到端”。
第二部分:核心方法 (MOTR & Track Query)
原文:In this paper, we propose MOTR, which extends DETR [6] and introduces “track query” to model the tracked instances in the entire video. [cite_start]Track query is transferred and updated frame-by-frame to perform iterative prediction over time. [cite: 8, 9]
- 翻译:在本文中,我们提出了 MOTR,它扩展了 DETR [6] 并引入了“轨迹查询(track query)”来对整个视频中的被跟踪实例进行建模。轨迹查询被逐帧传递和更新,以执行随时间推移的迭代预测。
- 深度解析:
- 理论基石:MOTR 建立在 DETR(Detection Transformer)之上。DETR 用一组固定的 Learnable Queries 去“询问”图像特征图里有没有物体。
- 核心创新——Track Query:
- 在 DETR 中,Query 每张图都是新的。
- 在 MOTR 中,Query 变成了**“接力棒”**。如果在第 t t t 帧,某个 Query 成功检测到了一个物体(比如行人 A),那么这个 Query 会带着行人 A 的特征信息(位置、外观)传递(Transferred) 到第 t + 1 t+1 t+1 帧。
- 在第 t + 1 t+1 t+1 帧,这个“有经验的” Query 会直接去特征图里找“行人 A 跑到哪去了”,而不是重新盲目地搜索。这就是“逐帧更新”和“迭代预测”。
第三部分:三个关键技术组件 (TALA, TAN, CAL)
原文:We propose tracklet-aware label assignment to train track queries and newborn object queries. [cite_start]We further propose temporal aggregation network and collective average loss to enhance temporal relation modeling. [cite: 10, 11]
- 翻译:我们提出了轨迹感知标签分配(TALA)来训练轨迹查询和新生目标查询。我们进一步提出了时序聚合网络(TAN)和集体平均损失(CAL)来增强时间关系建模。
- 深度解析:
这里列出了为了让上述“Track Query”跑通所必须的三个技术:- TALA (Tracklet-Aware Label Assignment):解决“谁是谁”的问题。
- 挑战:Transformer 输出一堆结果,怎么知道哪个是老轨迹,哪个是新出现的物体?
- 方案:TALA 规定,如果是上一帧传下来的 Query,必须负责预测同一个 ID 的物体(强制绑定);如果是专门负责捕捉新物体的 Query(Newborn Object Queries),则通过二分图匹配去找新出现的物体。
- TAN (Temporal Aggregation Network):解决“记忆”问题。这是一个特殊的模块,帮助 Query 融合历史信息和当前帧信息,增强对长时序的建模能力。
- CAL (Collective Average Loss):解决“训练”问题。不只看单帧的 Loss,而是把一个视频片段(Clip)作为一个整体来计算 Loss,强迫模型学习长期的运动规律。
- TALA (Tracklet-Aware Label Assignment):解决“谁是谁”的问题。
第四部分:实验结果与意义
原文:Experimental results on DanceTrack show that MOTR significantly outperforms state-of-the-art method, ByteTrack [42] by 6.5% on HOTA metric. On MOT17, MOTR outperforms our concurrent works, TrackFormer [18] and TransTrack [29], on association performance. [cite_start]MOTR can serve as a stronger baseline for future research on temporal modeling and Transformer-based trackers. [cite: 12, 13, 14]
- 翻译:在 DanceTrack 上的实验结果表明,MOTR 在 HOTA 指标上显著优于最先进的方法 ByteTrack [42] 6.5%。在 MOT17 上,MOTR 在关联性能上优于我们的同期工作 TrackFormer [18] 和 TransTrack [29]。MOTR 可以作为未来时间建模和基于 Transformer 的跟踪器研究的更强基线。
- 深度解析:
- DanceTrack 的胜利:这是一个非常重要的信号。DanceTrack 数据集的特点是“物体长得像(全是一样的舞者),但动作极其复杂”。ByteTrack 强依赖检测框和简单的运动模型,但在复杂非线性运动下容易跟丢。MOTR 在这里大胜 6.5%,说明端到端的 Transformer 确实学会了复杂的运动模式,而不仅仅是靠外观匹配。
- MOT17 的定位:虽然在 MOT17 上(侧重检测精度)可能不如 ByteTrack(这在后文中会有讨论),但在“关联性能”(即不容易频繁换 ID)上优于同类的 Transformer 方法。
- 地位:作者自信地将其定义为“Future Research”的 Baseline,事实证明确实如此,后来的许多工作(如 MOTRv2, MeMOTR)都基于此架构。
1 Introduction
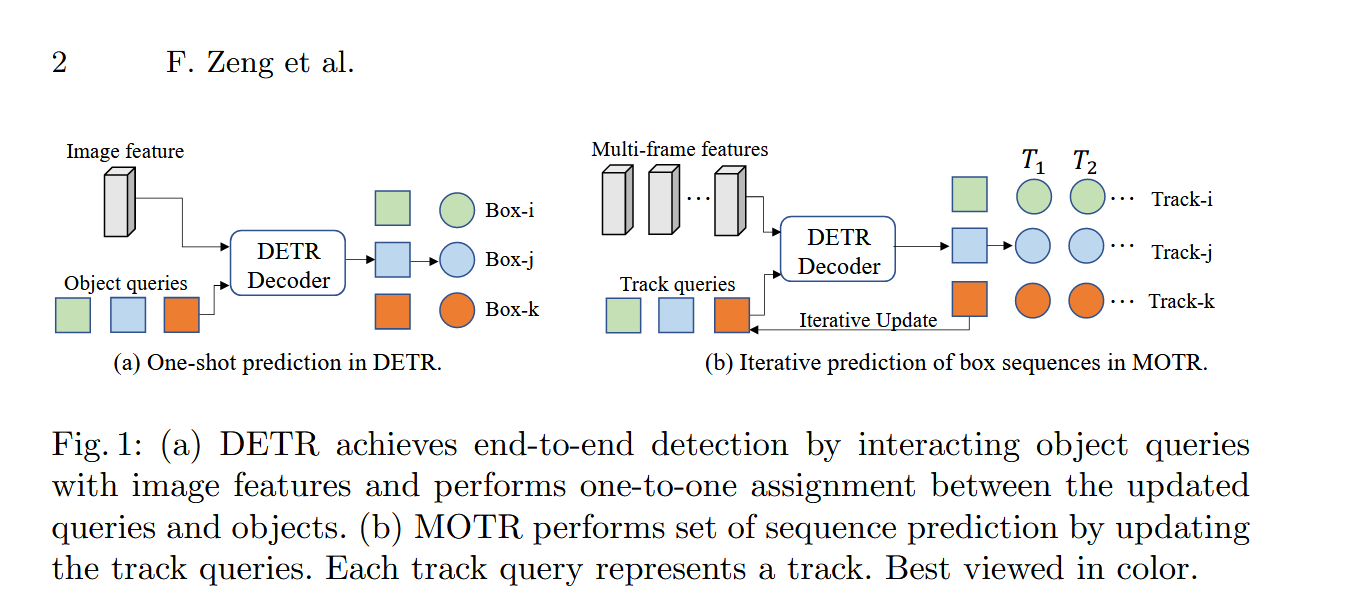
- 痛点分析:传统方法的“伪”端到端
引言开篇直指当时多目标跟踪(MOT)领域的弊端:
- 割裂的建模:传统方法(如 DeepSORT、JDE)通常将跟踪任务生硬地拆解为两部分——外观(靠 Re-ID 特征)和 运动(靠 IoU 或卡尔曼滤波)。
- 后处理瓶颈:这些方法严重依赖人工设计的规则(如匈牙利算法匹配、IoU 阈值筛选)来把检测框连成线。
- 根本缺陷:这种“先检测、后关联”的步骤属于后处理,它切断了神经网络的梯度传播。这意味着网络只学会了“在单张图里找人”,而没有真正学会“在时间轴上跟人”。这就是所谓的“非端到端”。
- 灵感来源:DETR 的集合预测(图 1a 解析)
为了打破上述瓶颈,作者借鉴了目标检测领域的革命性工作——DETR(Detection Transformer)。
- DETR 的核心:它把检测问题定义为集合预测(Set Prediction)。
- 看图 1(a)(One-shot prediction):
- 输入:图像特征 + 一组固定的 Object Queries。
- 过程:Queries 进入 Transformer Decoder,询问图像特征里有没有物体。
- 输出:通过二分图匹配,直接输出最终的检测框(Box-i, Box-j)。
- 局限:DETR 是“一次性”的,处理完当前帧,Queries 就完成了使命,无法传递到下一帧。
- 核心飞跃:MOTR 的迭代序列预测(图 1b 解析)
这是论文最精彩的理论突破。作者提出了一个直观的类比:多目标跟踪(MOT)就像自然语言处理中的“机器翻译”。
- 机器翻译:根据上一个词的隐藏状态,预测下一个词。
- MOTR:根据上一帧的 Track Query,预测当前帧的目标位置。
看图 1(b)(Iterative prediction)——请重点关注底部的循环箭头:
- Track Query(轨迹查询):作者将 DETR 的 Object Query 进化为 Track Query。它不再是每帧重置的,而是承载着物体身份信息的隐藏状态(Hidden State)。
- 传递机制:
- 在 T 1 T_1 T1 时刻,Track-i 预测完位置后,它不会消失。
- 它带着 T 1 T_1 T1 时刻学到的特征,顺着底部的箭头传递(Transfer) 到 T 2 T_2 T2 时刻。
- 在 T 2 T_2 T2 时刻,它直接作为输入,去特征图中寻找同一个目标的新位置。
- 本质变化:从“每帧重新找(Detection)”变成了“带着记忆找(Tracking)”。
- 落地挑战:解决两大技术难题
要让图 1(b) 的构想在数学上成立,必须解决两个现实问题:
-
难题一:如何保证 Query 不“移情别恋”?
- 解法:TALA (轨迹感知标签分配)。传统 DETR 的匹配是随机的,但 MOTR 必须强制约束:如果 Query A 上一帧对应了“张三”,那么这一帧它必须继续预测“张三”,不能去预测“李四”。TALA 策略通过标签分配规则锁定了这种身份对应关系。
-
难题二:新物体进来了、旧物体离开了怎么办?
- 解法:进出机制 (Entrance and Exit Mechanism)。
- 进(Newborn):除了 Track Query,每一帧还会引入一组新的 Detect Query(类似 DETR 的空查询),专门负责捕捉新出现的物体。一旦捕捉到,它们在下一帧就会“晋升”为 Track Query。
- 出(Terminated):如果一个 Track Query 连续几帧都找不到目标(置信度低),它就会被移出查询集合。
- 性能增强与总结
为了进一步强化模型对时间的理解,作者还引入了两个补丁(在后文方法部分会详述):
- CAL (集体平均损失):计算整个视频片段的 Loss,而不是单帧 Loss,强迫模型学习长时序规律。
- TAN (时序聚合网络):给 Track Query 开个“后门”,让它能更高效地聚合历史信息。
2 Related Work
- Transformer 架构的演进 (Transformer-based Architectures)
这一部分简述了 Transformer 是如何从 NLP 跨界统治 CV 领域的,这也正是 MOTR 的技术地基。
- 起源与跨界:Transformer 最初是为了机器翻译引入的,核心是自注意力(Self-attention)和交叉注意力(Cross-attention)机制,用于聚合序列信息。随后,它被广泛应用于语音处理和计算机视觉领域。
- DETR 的出现:这是 MOTR 的直接“父辈”。DETR 结合了 CNN、Transformer 和二分图匹配,实现了端到端的目标检测。
- 技术迭代:为了解决收敛慢的问题,Deformable DETR 引入了可变形注意力模块。
- 图像分类:ViT 构建了纯 Transformer 架构。
- 效率优化:Swin Transformer 通过移动窗口机制提高了效率。
- 视频任务:VisTR 采用并行序列预测框架来处理视频实例分割(Video Instance Segmentation),证明了 Transformer 处理视频序列的能力。
- 多目标跟踪的主流范式 (Multiple-Object Tracking)
作者回顾了 MOT 领域的主流方法,以此反衬出 MOTR “端到端”的独特性。
- 统治地位的范式:Tracking-by-detection(先检测后跟踪) 是主流。
- 基本流程:先用检测器定位每一帧的物体,然后通过关联算法将相邻帧的检测框连起来。
- 关联算法的进化:
- 纯运动模型:SORT 结合了卡尔曼滤波(Kalman Filter)和匈牙利算法(Hungarian Algorithm)进行关联。
- 加入外观模型:DeepSORT 和 Tracktor 引入了余弦距离和外观相似度(Re-ID)来辅助关联,解决物体遮挡或运动突变的问题。
- 联合训练(Joint Training):
- 为了提速,JDE 和 FairMOT 在检测器之上增加了一个 Re-ID 分支,在一个网络里同时学习检测和外观特征。
- TransMOT 则构建了一个时空图 Transformer(Spatial-temporal graph transformer)来进行关联。
- 同期工作(Concurrent Works):
- 作者特意提到了 TransTrack 和 TrackFormer,它们也是基于 Transformer 的 MOT 框架。
- 注:作者在这里埋了个伏笔,表示会在 3.7 节(Discussion) 详细对比 MOTR 与这两者的区别(主要区别在于是否还需要 NMS 或 IoU 匹配等后处理)。
- 迭代序列预测 (Iterative Sequence Prediction)
这一部分揭示了 MOTR 核心机制(Track Query 传递)的理论灵感来源。
- Seq2Seq 框架:在机器翻译和文本识别中,使用编码器-解码器(Encoder-Decoder)架构进行序列到序列(Seq2Seq)的预测非常流行。
- 工作原理:
- 编码器将输入编码为中间表示。
- 引入一个隐藏状态(Hidden State),它携带着特定任务的上下文信息。
- 隐藏状态在解码器中与中间表示进行迭代交互(Iteratively Interacted),逐步生成目标序列。
- 迭代解码:在每次迭代中,隐藏状态负责解码目标序列中的一个元素。
3 Method
3.1 Query in Object Detection
DETR 的查询机制 (The Mechanism)
原文:DETR [6] introduced a fixed-length set of object queries to detect objects. Object queries are fed into the Transformer decoder and interacted with image features, extracted from Transformer encoder to update their representation.
- 深度解析:
- 固定长度 (Fixed-length set):DETR 与传统检测器(如 Faster R-CNN 或 YOLO)最大的不同在于,它不需要生成成千上万个候选框(Anchors)。它预设了一组固定数量的“提问者”(例如 100 个),我们称之为 Object Queries。
- 交互与更新 (Interaction & Update):
- 这些 Object Queries 最初是随机初始化并可学习的向量。
- 它们被输入到 Transformer 的 解码器 (Decoder) 中。
- 在这里,它们通过 交叉注意力机制 (Cross-Attention) 与 编码器 (Encoder) 提取出的图像特征进行“交互”。
- 结果:通过这种交互,Query 吸收了图像信息,其自身的特征表示(Representation)被更新,从而“学会”了它所关注的物体的位置和类别信息。
二分图匹配 (Bipartite Matching)
原文:Bipartite matching is further adopted to achieve one-to-one assignment between the updated object queries and ground-truths.
- 深度解析:
- 一对一分配 (One-to-one assignment):这是 DETR 实现“端到端”的关键。传统方法通常会产生多个框预测同一个物体,需要 NMS(非极大值抑制)来去重。
- 二分图匹配:DETR 强制要求每一个 Ground Truth(真实物体)只能对应唯一的一个 Query 预测结果。这种严格的匹配是通过匈牙利算法(Hungarian Algorithm)在损失计算阶段完成的。这消除了对 NMS 的依赖。
原文:Here, we simply write the object query as “detect query” to specify the query used for object detection.
- 深度解析:
- 这是这一节最关键的一句话。作者在这里做了一个术语重命名。
- 变更:将 DETR 原本的 “Object Query” 改称为 “Detect Query” (检测查询)。
- 目的:这是为了与下一节(3.2节)即将提出的 “Track Query” (轨迹查询) 进行区分。
- Detect Query:只负责“检测”当前帧里新出现的物体(Newborn)。
- Track Query:负责“跟踪”已知的物体。
- 如果不在这里明确定义,后续读者很容易混淆“为什么这里有两种 Query”。
3.2 Detect Query and Track Query
原文:When adapting DETR from object detection to MOT, two main problems arise: 1) how to track one object by one track query; 2) how to handle newborn and terminated objects.
- 深度解析:
- 挑战一:身份绑定(Identity Preservation)。在 DETR 中,Query 是无状态的,每次都是重新匹配。但在 MOT 中,我们必须保证:上一帧跟踪“张三”的那个 Query,下一帧必须继续跟踪“张三”,不能跳去跟踪“李四”。这就是“One object by one track query”。
- 挑战二:动态生灭(Lifecycle Management)。视频里的物体不是固定的,随时有人进画(Newborn),随时有人出画(Terminated)。DETR 的 Query 数量是固定的(例如 100 个),无法直接应对这种动态变化的数量。
Track Query 的引入
原文:We extend detect queries to track queries in this paper. Track query set is updated dynamically, and the length is variable.
- Detect Query ( q d q_d qd):
- 这就是 3.1 节定义的“老 DETR Query”。
- 作用:它的职责被缩减了。在 MOTR 中,它只负责寻找新出现的目标(Newborn)。
- 数量:固定长度(Fixed-length)。
- Track Query ( q t r q_{tr} qtr) - 新概念:
- 定义:这是 MOTR 的创新。它是从 Detect Query“进化”而来的。
- 作用:负责持续跟踪已经出现的目标。
- 本质:它承载了目标的隐藏状态(Hidden State),即包含了目标过去的位置和外观特征。
- 数量:动态变化(Variable Length)。目标多时它就多,目标少时它就少。
生命周期管理:图解 Figure 2 (Lifecycle Management)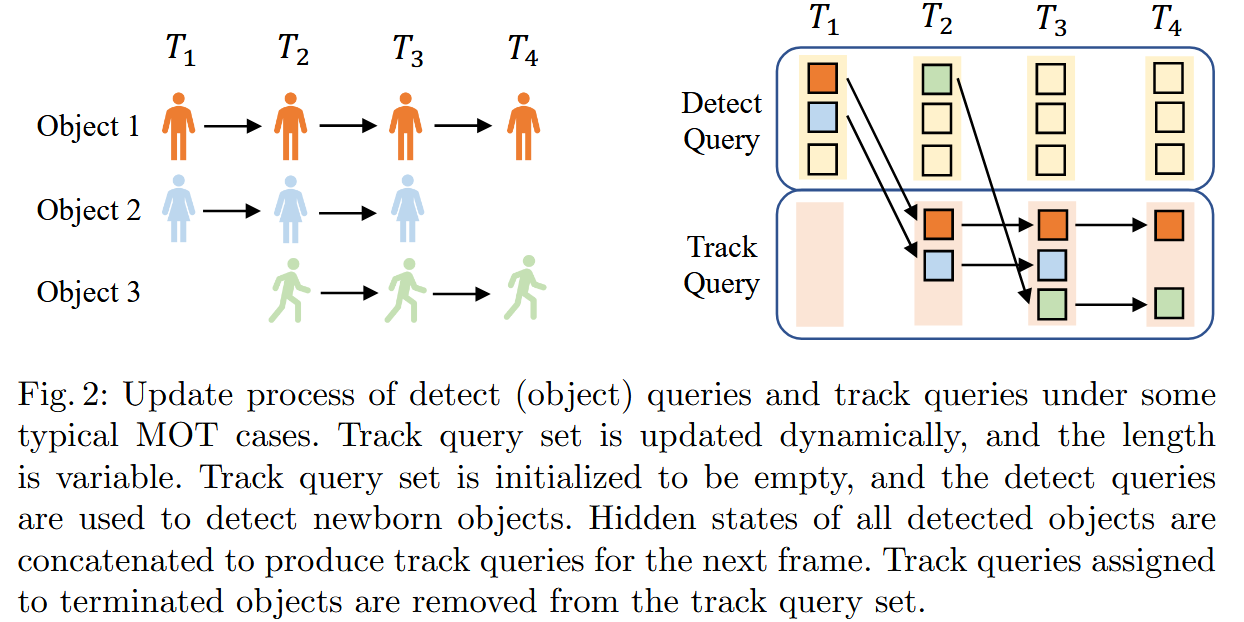
作者通过 Figure 2 极其直观地展示了 Detect Query 如何转化为 Track Query,以及 Track Query 如何消亡。
让我们对着图 2 的时间轴 ( T 1 → T 4 T_1 \rightarrow T_4 T1→T4) 进行逐帧拆解:
-
T 1 T_1 T1:初始状态 (Initialization)
- 状态:Track Query 集合初始化为空。
- 操作:只有 Detect Queries 在工作。它们扫描全图,检测到了 Object 1(橙人)和 Object 2(蓝人)。
- 转化:这两个检测成功的 Detect Queries 提取出的隐藏状态,不会被丢弃,而是被保存下来。
-
T 2 T_2 T2:继承与新生 (Inheritance & Newborn)
- 继承: T 1 T_1 T1 保存的那两个隐藏状态,在 T 2 T_2 T2 变成了 Track Queries。它们直接去预测 Object 1 和 Object 2 的新位置。
- 新生:同时,Detect Queries 继续工作,它们发现了新进画的 Object 3(绿人)。
- 结果:现在我们有 3 个活跃的 Query(2 个 Track + 1 个 Detect)。
-
T 3 T_3 T3:全面跟踪 (Full Tracking)
- 转化: T 2 T_2 T2 发现的 Object 3,其隐藏状态也加入了 Track Query 集合。
- 状态:现在 Track Query 集合里有 3 个 Query,分别负责 Object 1, 2, 3。Detect Queries 在这一帧没有发现新目标(空闲)。
-
T 4 T_4 T4:目标消亡 (Termination)
- 事件:Object 2(蓝人)离开了画面,或者被遮挡严重导致消失。
- 操作:负责跟踪 Object 2 的那个 Track Query 发现自己找不到目标了(置信度低)。
- 结果:该 Track Query 被移除(Removed) 出集合。Track Query 集合长度减 1。
3.3 Tracklet-Aware Label Assignment
- DETR 的做法:在 DETR 中,每一个 Detect Query 都可以被分配给图像中的任何一个物体。这是一种“乱序”匹配,因为它是通过全局二分图匹配(Bipartite Matching)动态决定的。
- MOTR 的需求:MOTR 引入了 Track Query,这些 Query 必须负责预测特定的、已跟踪的对象。
- 冲突:如果不加干预,Detect Query 可能会去抢 Track Query 的目标,或者 Track Query 可能会突然换人跟踪。
- TALA 的作用:制定一套严格的规则,规定“谁该干什么”。
TALA 的两大策略 (Two Strategies)
TALA 将查询分为两类,分别制定了不同的分配规则:
策略一:Detect Queries —— 只抓新人 (Newborn-only)
- 规则:Detect Queries 被禁止参与已跟踪目标的匹配。它们只能去匹配那些新出现的目标 (Newborn Objects)。
- 操作:在计算二分图匹配时,候选项不再是所有 Ground Truth,而仅仅是 Y n e w Y_{new} Ynew (新目标的真值集合)。
策略二:Track Queries —— 从一而终 (Target-consistent)
- 规则:Track Queries 不参与二分图匹配。
- 操作:它们直接继承上一帧的分配结果。
- 如果 Query A 在 T − 1 T-1 T−1 帧负责跟踪目标 ID 1,那么在 T T T 帧,系统强制要求 Query A 继续负责目标 ID 1。
- 这种“硬性指派”保证了轨迹 ID 的一致性,不需要任何后处理关联算法。
数学表达 (Formalization)
作者用两组公式形式化了上述过程:
对于 Detect Queries (公式 1):
ω d e t i = arg min ω d e t i ∈ Ω i L ( Y ^ d e t i ∣ ω d e t i , Y n e w i ) \omega^i_{det} = \arg \min_{\omega^i_{det} \in \Omega_i} \mathcal{L}(\hat{Y}^i_{det}|_{\omega^i_{det}}, Y^i_{new}) ωdeti=argωdeti∈ΩiminL(Y^deti∣ωdeti,Ynewi)
- 含义:在第 i i i 帧,Detect Queries 的分配结果 ω d e t i \omega^i_{det} ωdeti 是通过最小化匹配代价 L \mathcal{L} L 得到的。
- 关键点:注意匹配的目标仅限于 Y n e w i Y^i_{new} Ynewi(新目标集合),而不是所有目标。
对于 Track Queries (公式 2):
ω t r i = ω t r i − 1 ∪ ω d e t i − 1 ( for i > 1 ) \omega^i_{tr} = \omega^{i-1}_{tr} \cup \omega^{i-1}_{det} \quad (\text{for } i > 1) ωtri=ωtri−1∪ωdeti−1(for i>1)
- 含义:第 i i i 帧的 Track Queries 分配结果,等于 “上一帧的老 Track” 加上 “上一帧成功抓到新人的 Detect”。
- 接力过程:
- ω t r i − 1 \omega^{i-1}_{tr} ωtri−1:上一帧就在跟踪的老查询。
- ω d e t i − 1 \omega^{i-1}_{det} ωdeti−1:上一帧刚发现新目标的查询(在这一帧晋升为 Track Query)。
- 特例:对于第一帧 ( i = 1 i=1 i=1),因为没有历史,所以 Track Query 集合为空 ( ∅ \emptyset ∅)。
作者最后提到了一个非常巧妙的工程实现细节,解释了**“为什么 Detect Query 不会抢 Track Query 的活”**:
- 输入:在 Transformer 解码器中,Detect Queries 和 Track Queries 是拼接 (Concatenated) 在一起输入的。
- 机制:利用 Transformer 的 自注意力机制 (Self-Attention)。
- Track Query 会“告诉”其他 Query:“这个目标我已经覆盖了”。
- Detect Query 接收到这个信息后,会抑制自己对该目标的响应。
- 类比:这就像 DETR 中的“去重”机制。如果一个物体已经被置信度高的 Query 占据,置信度低的 Query 就会自动退出。在 MOTR 中,Track Query 相当于那个“置信度高”的存在,压制了 Detect Query 对同一目标的重复检测。
3.4 MOTR Architecture
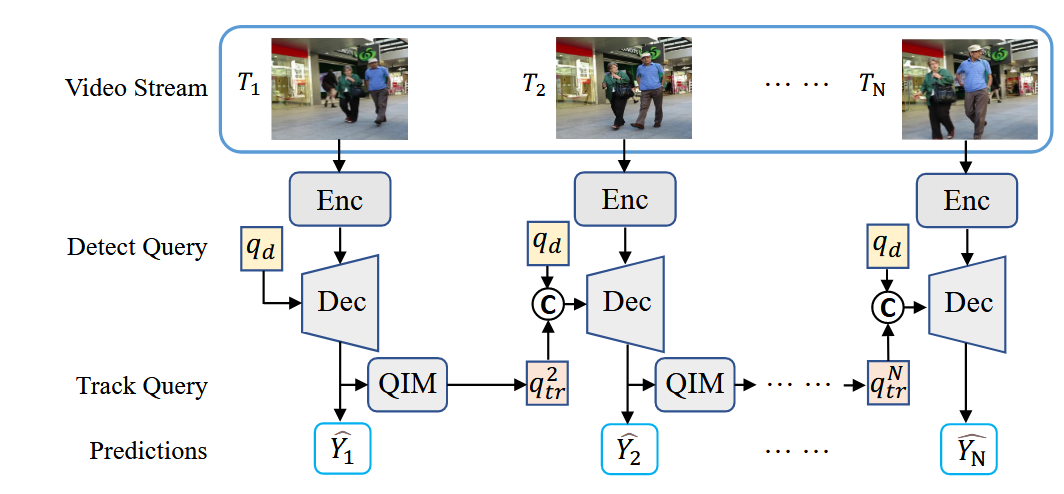
- 特征提取 (Feature Extraction)
- 组件:图中的 “Enc” 模块。
- 组成:包含两个部分。
- CNN Backbone:通常使用 ResNet-50,负责从原始图像中提取基础特征图。
- Transformer Encoder:即 Deformable DETR 的编码器。
- 流程:视频流中的每一帧图像首先经过这个 “Enc” 模块,生成高层的帧特征 (Frame Features),为后续的解码器提供视觉信息。
- 查询流转机制 (The Flow of Queries)
这是架构中最核心的部分,区分了“第一帧”和“后续帧”两种情况:
-
第一帧 ( T 1 T_1 T1) —— 冷启动:
- 状态:此时没有任何历史轨迹,Track Query 为空。
- 输入:解码器只接收一组固定长度的可学习 Detect Queries ( q d q_d qd)。
- 本质:这一步的操作与标准的 DETR 完全一致,纯粹是在做单帧的目标检测,寻找画面中所有感兴趣的物体。
-
后续帧 ( T 2 , … , T N T_2, \dots, T_N T2,…,TN) —— 混合输入:
- 拼接操作 (Concatenation, 图中的 “C”):这是 MOTR 的标志性操作。
- 输入:解码器的输入由两部分拼接而成:
- 上一帧传承下来的 Track Queries ( q t r q_{tr} qtr):携带了老目标的身份和位置信息。
- 固定的 Detect Queries ( q d q_d qd):负责捕捉当前帧可能出现的新目标。
- 目的:这种“新老结合”的输入,保证了模型既能跟踪旧人,又能发现新人。
- 解码与预测 (Decoding & Prediction)
- 交互:在 Deformable DETR 解码器 (Dec) 内部,拼接后的 Queries 与图像特征进行交互(通过自注意力和交叉注意力)。
- 输出:解码器输出更新后的 隐状态 (Hidden States)。
- 双流向:这些隐状态有两个去向:
- 生成预测 ( Y ^ \hat{Y} Y^):直接通过全连接层(FFN)预测当前帧的边界框和类别。
- 生成下一帧查询:输入到 查询交互模块 (QIM)。QIM 处理后,生成下一帧所需的 Track Queries。
- 训练与推理的区别
-
训练阶段 (Training Phase):
- 输入:输入是一整个视频片段(Video Clip)。
- 预测库 (Prediction Bank):模型会收集整个片段中每一帧的预测结果 { Y ^ 1 , Y ^ 2 , … , Y ^ N } \{\hat{Y}_1, \hat{Y}_2, \dots, \hat{Y}_N\} {Y^1,Y^2,…,Y^N}。
- 监管:利用 集体平均损失 (CAL) 对这一组序列预测进行整体监督。这种长时序的训练方式迫使模型学习运动规律,而不仅仅是单帧匹配。
- 标签分配:每一帧都遵循 3.3 节提到的 TALA 策略。
-
推理阶段 (Inference Time):
- 在线处理 (Online):视频流是逐帧进入的。模型实时生成当前帧的预测,并实时更新 Track Query 传递给下一帧,不需要预先知道未来的信息。
3.5 Query Interaction Module
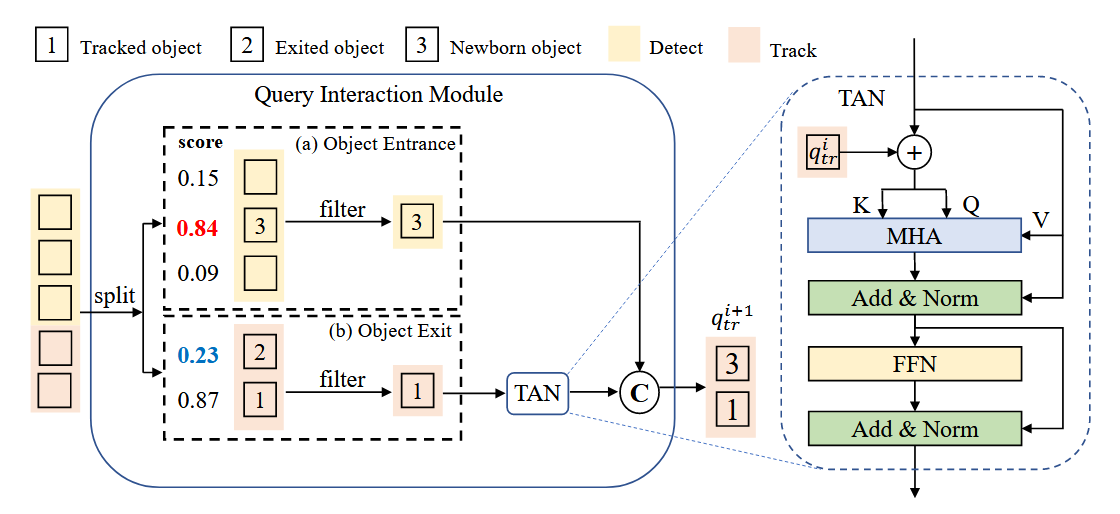
QIM 位于 Transformer 解码器之后,它的核心职责只有两个:管生死(生命周期管理) 和 强记忆(时序增强)。
1. 对象的进出机制 (Object Entrance and Exit)
QIM 的首要任务是决定哪些 Query 应该被保留到下一帧,哪些应该被丢弃。这里分为“训练”和“推理”两种逻辑。
A. 训练阶段 (During Training)
在训练时,因为我们拥有 Ground Truth (GT):
- 处决(Exit):针对 Track Queries。如果对应的目标在 GT 中消失了,或者预测框与 GT 的 IoU 低于 0.5(意味着跟丢了),该 Query 的隐藏状态会被移除。
- 接纳(Entrance):针对 Detect Queries。根据 3.3 节定义的 TALA 分配结果( ω d e t i \omega_{det}^i ωdeti),匹配到新目标的 Query 会被保留。
B. 推理阶段 (For Inference) - 重点看图 4 左侧
在推理时,没有 GT,必须依靠**分类置信度分数(Score)**来判断。请看 Figure 4 左侧的流程:
-
Object Entrance(新目标入场):
- 对象:Detect Queries(图中的黄色方框)。
- 操作:看分数。设定一个进入阈值 τ e n \tau_{en} τen。
- 图例解析:图中三个 Detect Queries 分数分别为 0.15, 0.84, 0.09。假设阈值是 0.5,那么只有 0.84 的那个 Query(对应 Object 3)被保留,其余被过滤掉。
-
Object Exit(旧目标离场):
- 对象:Track Queries(图中的粉色方框)。
- 操作:看分数。设定一个退出阈值 τ e x \tau_{ex} τex。
- 缓冲机制:为了防止误删(比如偶尔一帧被遮挡导致分数低),作者规定必须连续 M 帧分数都低于 τ e x \tau_{ex} τex 才会被移除。
- 图例解析:图中两个 Track Queries 分数分别为 0.23 和 0.87。0.23 的那个(对应 Object 2)被认为是消失或跟丢了,直接被 Filter 移除;0.87 的(对应 Object 1)被保留进入下一步。
2. 时序聚合网络 (TAN) - 重点看图 4 右侧
筛选出幸存的 Track Query(如图中的 Object 1)后,并不是直接传给下一帧,而是要先经过 TAN (Temporal Aggregation Network) 进行“强化”。
- 目的:增强时序关系建模,为跟踪对象提供上下文先验(Contextual Priors)。
- 结构:TAN 本质上是一个修改版的 Transformer Decoder Layer。
让我们聚焦 Figure 4 右侧的虚线框,看看 TAN 内部的数据流是如何设计的:
-
输入来源:
- Current Hidden State:当前帧解码器输出的隐状态(图中 Object 1 的粉色块)。
- Last Frame Query ( q t r i q_{tr}^i qtri):上一帧传递过来的 Query 向量。
-
核心操作:Q, K, V 的分配:
这是 TAN 最精妙的设计。在多头自注意力(MHA)中:- Query (Q) & Key (K):由 “上一帧 Query” + “当前帧 Hidden State” 相加得到。
- 原理:上一帧的 Query 包含了历史的运动/身份倾向,加上当前的观测,构成了更完整的查询意图。
- Value (V):仅由 “当前帧 Hidden State” 构成。
- 原理:Value 代表我们要提取的内容。我们希望提取的是当前这一帧的新鲜信息,而不是历史信息。
- Query (Q) & Key (K):由 “上一帧 Query” + “当前帧 Hidden State” 相加得到。
-
输出 ( q t r i + 1 q_{tr}^{i+1} qtri+1):
经过 MHA 和前馈网络(FFN)处理后,生成的输出就是 下一帧的 Track Query。最后,它会与新诞生的 Object 3 的 Query 拼接(Concatenate ‘C’),组成新的 Query 集合传给下一帧。
3.6 Collective Average Loss
-
痛点:短视的训练
- 现有问题:传统的 MOT 训练策略通常只关注两帧(Training within two frames)。模型只能学到 T T T 到 T + 1 T+1 T+1 的瞬时位移。
- 后果:模型无法理解长距离的运动(Long-range object motion)。例如,一个物体被遮挡后又出现,或者在做复杂的非线性运动,只看两帧是学不会这种规律的。
- 对比:传统的 Kalman Filter 是靠人工设计的物理公式(Heuristics)来处理运动的,而 MOTR 想要从数据中学习(Learn from data) 这种时间方差。
-
解决方案:视频片段输入
- MOTR 不再是一张张图输入,而是直接把一个 Video Clip(视频片段,如 5 帧) 扔进去训练。这就为学习长期依赖提供了数据基础。
-
Collection (收集):
- 在训练时,模型并不会算完一帧的 Loss 就立刻反向传播。
- 相反,它建立了一个 Prediction Bank(预测库),把整个视频片段中每一帧的预测结果 Y ^ = { Y ^ 1 , Y ^ 2 , . . . , Y ^ N } \hat{Y} = \{\hat{Y}_1, \hat{Y}_2, ..., \hat{Y}_N\} Y^={Y^1,Y^2,...,Y^N} 全部收集起来。
-
Calculation (算总账):
- 当 N N N 帧全部跑完后,CAL 会拿出一整套 Ground Truths Y = { Y 1 , . . . , Y N } Y = \{Y_1, ..., Y_N\} Y={Y1,...,YN} 和一整套匹配结果 ω \omega ω,计算整个序列的总损失。
L o ( Y ^ ∣ ω , Y ) = ∑ n = 1 N ( L ( Y ^ t r i ∣ ω t r i , Y t r i ) + L ( Y ^ d e t i ∣ ω d e t i , Y d e t i ) ) ∑ n = 1 N ( V i ) ( 3 ) \mathcal{L}_{o}(\hat{Y}|_{\omega}, Y) = \frac{\sum_{n=1}^{N} (\mathcal{L}(\hat{Y}_{tr}^i | \omega_{tr}^i, Y_{tr}^i) + \mathcal{L}(\hat{Y}_{det}^i | \omega_{det}^i, Y_{det}^i))}{\sum_{n=1}^{N} (V_i)} \quad (3) Lo(Y^∣ω,Y)=∑n=1N(Vi)∑n=1N(L(Y^tri∣ωtri,Ytri)+L(Y^deti∣ωdeti,Ydeti))(3)
这个公式看起来复杂,其实非常直观。我们把它拆开看:
-
分子(总损失):
- ∑ n = 1 N \sum_{n=1}^{N} ∑n=1N:对视频片段中的每一帧(从第 1 帧到第 N 帧)进行累加。
- L ( Y ^ t r i ) \mathcal{L}(\hat{Y}_{tr}^i) L(Y^tri):Track Query 的损失。这是为了监督模型“是否跟准了老目标”。
- L ( Y ^ d e t i ) \mathcal{L}(\hat{Y}_{det}^i) L(Y^deti):Detect Query 的损失。这是为了监督模型“是否发现了新目标”。
- 关键点:这里再次体现了 TALA 的策略——两类 Query 分别计算 Loss,互不干扰。
-
分母(归一化):
- ∑ n = 1 N ( V i ) \sum_{n=1}^{N} (V_i) ∑n=1N(Vi):这是整个视频片段中,所有帧里真实物体(Ground Truth Objects)的总数量。
- V i = V t r i + V d e t i V_i = V_{tr}^i + V_{det}^i Vi=Vtri+Vdeti:即第 i i i 帧中“老目标数量”加“新目标数量”之和。
- 为什么要除以它?:这是为了平均化(Normalize)。如果不除以物体总数,长视频或者人多的视频 Loss 就会巨大,导致梯度爆炸;短视频 Loss 就很小。CAL 保证了 Loss 的数值规模只与“预测的准确度”有关,而与视频长度和人数无关。
至于每一帧内部具体怎么算 Loss,MOTR 沿用了标准 DETR 的配方:
L ( Y ^ i ) = λ c l s L c l s + λ l 1 L l 1 + λ g i o u L g i o u ( 4 ) \mathcal{L}(\hat{Y}_i) = \lambda_{cls}\mathcal{L}_{cls} + \lambda_{l1}\mathcal{L}_{l1} + \lambda_{giou}\mathcal{L}_{giou} \quad (4) L(Y^i)=λclsLcls+λl1Ll1+λgiouLgiou(4)
- L c l s \mathcal{L}_{cls} Lcls (Focal Loss):分类损失。判断是人、是车还是背景。
- L l 1 \mathcal{L}_{l1} Ll1 (L1 Loss):位置绝对误差。预测框的中心点偏了多少。
- L g i o u \mathcal{L}_{giou} Lgiou (Generalized IoU Loss):重叠度损失。预测框和真值框的重合程度,这比单纯的 L1 Loss 更能反映框的质量。
3.7 Discussion
TransTrack
- 对手策略:TransTrack 虽然也用了 Transformer,但它本质上还是传统的 Tracking-by-detection 范式。
- 工作流程:
- 检测:在相邻两帧之间检测对象,形成短的“小轨迹(Tracklets)”。
- 关联:通过 IoU 匹配(IoU-matching) 将这些小轨迹连成完整的长轨迹。
- MOTR 的批判:TransTrack 将任务**解耦(Decouples)**成了“检测”和“关联”两步。它依然依赖 IoU 匹配这种人工规则。
- MOTR 的优势:MOTR 是完全端到端的,通过 Track Query 的迭代更新直接输出长轨迹,不需要 IoU 匹配。
TrackFormer (短视的端到端)
- 对手策略:TrackFormer 和 MOTR 很像,也使用了 Track Query 的概念。
- 致命缺陷:短视(Short-range)。
- TrackFormer 的训练只在相邻两帧之间进行。
- 这导致它的时序学习能力相对较弱(Weak temporal learning)。
- 后果:因为学得不够好,TrackFormer 容易产生重复的轨迹。为了修补这个问题,它被迫使用了 Track NMS(非极大值抑制) 和 Re-ID 特征 等启发式规则来过滤垃圾轨迹。
- MOTR 的优势:
- 得益于 CAL(集体平均损失) 和 TAN(时序聚合网络),MOTR 具备强大的**长时序(Long-range)**建模能力。
- 因此,MOTR 不需要 NMS,也不需要 Re-ID。
作者通过 Table 1极其直观地展示了“谁才是真正的 End-to-End”。
| 方法 (Method) | IoU 匹配 (IoU match) | 非极大值抑制 (NMS) | Re-ID 特征 (ReID) |
|---|---|---|---|
| TransTrack | ✅ (需要) | ✅ (需要) | - |
| TrackFormer | - | ✅ (需要) | ✅ (需要) |
| MOTR (Ours) | ❌ (不需要) | ❌ (不需要) | ❌ (不需要) |
- 解读:
- TransTrack 依然活在 IoU 和 NMS 的阴影下。
- TrackFormer 虽然去掉了 IoU,但还得靠 NMS 和 ReID 来“打补丁”。
- MOTR 是唯一一个全空的。这证明了它是一个**纯粹的(Truly)**端到端框架,完全摒弃了所有基于规则的后处理步骤。
4 Experiments
- 实验设置与关键策略
数据集的选择很有讲究
作者并没有只盯着传统的 MOT17,而是引入了 DanceTrack。这非常有深意:
- MOT17:传统数据集,主要看检测器准不准。很多 SOTA 方法(如 ByteTrack)靠超强的检测器就能刷高分。
- DanceTrack:新数据集,特点是**“外观长得都一样(Uniform Appearance),但动作极其复杂(Diverse Motion)”。这种场景下,光靠检测器或者外观 Re-ID 是不行的,必须靠强大的时序运动建模**。
- BDD100k:自动驾驶数据集,用于验证模型处理**多类别(Multi-class)**的能力。
为了让 Track Query 学会处理目标的“生”与“死”,作者在训练中使用了两个特殊技巧:
- 随机擦除 (Query Erasing, p d r o p p_{drop} pdrop):在训练时,故意随机删掉一些正在跟踪的 Track Query。这迫使模型去适应“目标丢失”的情况,并模拟 Detect Query 重新捕捉的过程。
- 虚假插入 (False Positive Inserting, p i n s e r t p_{insert} pinsert):故意把一些错误的预测结果(False Positives)作为上一帧的 Track Query 塞进去。这迫使模型学会识别并剔除这些错误的轨迹(即模拟 Exit 机制)。
此外,Clip Length(视频片段长度) 是渐进式增加的。刚开始只训练 2 帧,然后慢慢增加到 3、4、5 帧。这就像教小孩走路,先教走一步,稳了再教走两步、三步。
MOT17(关联强,检测弱)
- 对比对象:TrackFormer, TransTrack(同类 Transformer 方法)。
- 战况:
- IDF1(身份保持指标):MOTR 显著更高。这意味着 MOTR 很少把“张三”认成“李四”,这是端到端关联的功劳。
- MOTA(检测精度指标):MOTR 不如 TransTrack,也不如非 Transformer 的 ByteTrack。
- 原因深度剖析:
- TransTrack 是把检测和跟踪解耦的,检测头可以专心做检测。
- MOTR 是共享解码器。Track Query 会抑制 Detect Query,导致对新目标的检测能力受到一定限制(Detect Query 不敢随便报目标,怕和 Track Query 冲突)。
DanceTrack(MOTR 的主场)
这是论文最亮眼的成绩。
- 战况:MOTR 在 HOTA 指标上比 ByteTrack 高出 6.5%。
- 意义:DanceTrack 的难点在于物体外观极其相似(都是穿一样衣服的舞者),传统的 Re-ID 方法基本失效。MOTR 能赢这么多,说明它真正学会了复杂的运动规律,仅靠位置和运动趋势就能把人跟住。这证明了 CAL 和 TAN 的强大作用。
消融实验:拆解组件,探究“为什么行”
作者通过 Table 6 的一系列实验,像剥洋葱一样展示了每个组件的贡献。
A. 核心组件的贡献 (Table 6a)
- Baseline(只有 Detect Query):效果极差,全是碎片化的框。
- + Track Query:IDF1 从 1.2 飙升到 49.8。这证明了**“轨迹传递”**是实现跟踪的根本。
- + TAN:MOTA 提升 7.8%,IDF1 提升 13.6%。证明了**“聚合历史记忆”**能大幅增强跟踪的稳定性。
- + CAL:在 TAN 基础上再提升 8.3% MOTA。证明了**“看长视频训练”**能让模型学会处理遮挡和复杂运动。
B. 视频长度的影响 (Table 6b)
- 训练时的 Clip 长度从 2 帧增加到 5 帧,性能稳步提升。
- 图 5 (Fig. 5) 可视化:作者展示了由短到长的效果。如果不使用 CAL(短时序),遇到遮挡或交叉时,模型容易产生重复框(Duplicated boxes)或 ID 切换(ID Switch)。用了 CAL 后,模型能“脑补”出遮挡期间的轨迹。
C. 采样间隔 (Sampling Interval)
- 训练时,如果帧与帧之间采样间隔太小(比如间隔 1 帧),模型容易陷入局部最优,学不到大幅度的运动。
- 实验发现,间隔 10 帧左右采样效果最好。这模拟了真实场景中的快速运动或低帧率情况,增强了模型的鲁棒性。
5 Limitations
- 局限一:新生目标检测的“内耗” (The Conflict of Newborn Detection)
原文核心:First, the performance of detecting newborn objects is far from satisfactory… detect queries are suppressed on detecting tracked objects, which may go against the nature of object query…
-
现象:
- MOTR 在 MOTA(多目标跟踪精度) 指标上表现不够好。
- 具体来说,就是**“抓新人的能力不行”**。
-
深度归因(为什么不行?):
这要回溯到 3.3 节的 TALA 和 3.4 节的架构设计。- 资源抢占:在 MOTR 中,Detect Query 和 Track Query 共享同一个 Transformer Decoder。
- 机制冲突:为了保证跟踪的一致性,我们通过注意力机制强制让 Track Query 抑制 Detect Query。也就是说,Detect Query 被训练成:“只要是 Track Query 看到的东西,我就装作没看见”。
- 违背天性:DETR 的 Object Query 天性是“看到什么检什么”。但 MOTR 强行压抑了它的这种天性,让它变得“畏手畏脚”。这导致它在寻找真正的新目标(Newborn)时,敏感度下降,容易漏检。
-
后果:如果一个新物体进来了,Detect Query 第一时间没抓到,那么它永远不会变成 Track Query,后续的跟踪也就无从谈起。这就是所谓的“一步跟不上,步步跟不上”。
- 局限二:串行计算的低效 (Inefficiency of Sequential Processing)
原文核心:Second, the query passing in MOTR is performed frame-by-frame, limiting the efficiency of model learning during training.
-
现象:
- MOTR 的训练和推理必须是 逐帧(Frame-by-frame) 进行的。
- 你必须先算完 T 1 T_1 T1,拿到 Hidden State,才能算 T 2 T_2 T2。这就像 RNN(循环神经网络)。
-
对比(VisTR 的失败):
- 作者提到了 VisTR(Video Instance Segmentation Transformer)。VisTR 是一种**并行(Parallel)**解码的方法,它一次性把整个视频的所有帧扔进去,同时输出所有结果,效率极高。
- 为什么 MOTR 不用并行? 作者尝试过,但在复杂的 MOT 场景下失败了。因为 MOT 涉及严重的遮挡和长距离运动,如果缺乏这种“上一帧传给下一帧”的显式状态传递,模型很难处理复杂的时空逻辑。
-
代价:为了追求跟踪的准确性(尤其是复杂运动下的准确性),MOTR 牺牲了 Transformer 最引以为傲的“并行计算”能力,导致训练效率受限。
- 总结与展望
这一节其实指明了 Transformer-based MOT 未来的两条进化路线:
- 解决检测瓶颈:如何既保留 Track Query 的跟踪能力,又不牺牲 Detect Query 的检测精度?
- 后世解法(如 MOTRv2):引入一个额外的、强力的预训练检测器(如 YOLOX)来生成 Proposal Query,不再让 Detect Query 盲目地从零学起。
- 解决效率瓶颈:如何在保持高精度的同时,实现更高效的时序建模?
- 后世解法:探索更高效的 Attention 机制,或者在局部窗口内进行并行处理。
至此,MOTR 这篇论文的精读就全部结束了。它从 DETR 出发,通过引入 Track Query、TALA、CAL 等机制,成功构建了第一个真正意义上的端到端多目标跟踪框架,虽然有检测性能和效率上的遗憾,但其历史地位不可动摇。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)