视频质量评价与大模型——VQA2
大型多模态模型(LMM)的出现和扩散为计算机视觉引入了新的范式,将各种任务转变为统一的视觉问答框架,视觉问答(VQA)可以显着增强低水平的视觉质量评估。前言:对于视频质量评价而言,基于LMM方法的探索还是处于一个比较初期的阶段,可能是因为有Q-AlLIGN这个珠玉在前,所以凭借着对图像质量的视觉感知就已经可以对视频质量进行准确的打分了,但是显然这种图像质量模型缺失了对视频时间信息和运动失真的表征,
前言:对于视频质量评价而言,基于LMM方法的探索还是处于一个比较初期的阶段,可能是因为有Q-AlLIGN这个珠玉在前,所以凭借着对图像质量的视觉感知就已经可以对视频质量进行准确的打分了,但是显然这种图像质量模型缺失了对视频时间信息和运动失真的表征,缺乏这一特征无疑是会影响准确率的,因此,本篇文章就建立了一个视频质量的指令微调数据集,并且基于LLaVA-OneVision-Chat-7B微调得到了一个在VQA中性能超过了Q-ALIGN的大模型。
《VQA2: Visual Question Answering for Video Quality Assessment》
0.摘要
大型多模态模型(LMM)的出现和扩散为计算机视觉引入了新的范式,将各种任务转变为统一的视觉问答框架,视觉问答(VQA)可以显着增强低水平的视觉质量评估。引入了 VQA2 指令数据集——第一个专注于视频质量评估的视觉问答指令数据集。该数据集由 3 个子集组成,涵盖各种视频类型,包含 157、755 个指令问答对。然后,利用这个基础,我们推出了VQA2系列模型。
我们的最终模型 VQA2-Assistant 在视觉质量理解任务中超越了著名的 GPT-4o。VQA2-Assistant可以进行精确的视频质量评分,同时展现出强大的视频质量理解和问答能力,标志着该领域的新进展。
- 介绍
我们相信,与传统模型相比,将视觉问答集成到开发视频质量评估模型中可以提供卓越的定量评估和质量理解能力,从而具有更大的广泛应用潜力。该模型可用于视频编码、传输和解码过程[23],提供有效的反馈。此外,它在图像/视频生成领域有望作为细化本地生成细节的有效指导[27]。
我们构建了 VQA2 指令数据集——一个专门用于基于视觉问答的视频质量评估的大规模指令数据集。该数据集为开发具有卓越多功能性的强大视频质量评估模型奠定了坚实的基础。构建流程可分为 3 个阶段及其相应的子集
第一阶段:以模型预训练的失真识别为中心的子集。我们利用来自多个现有数据集的失真信息,开发了用于模型预训练的失真识别指令子集。 •
第2 阶段:以视频质量评分为中心的指令调整子集。我们利用各种现有数据集的平均意见得分(MOS)并将其转换为质量级别标签作为指导数据。
• 第3 阶段:用于理解视频质量的指令调整子集。我们根据人类专家注释整理了由 GPT 扩展的高质量、多样化的数据集
3. 数据集
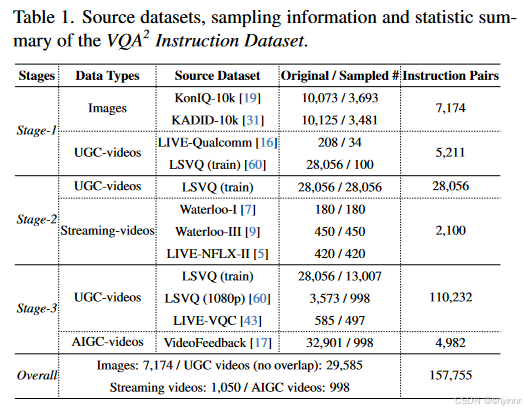
3.1stage1:失真数据集
根据每个数据集的原始质量分布的质量级别确定抽样比例。
从 KonIQ-10K [19] 和 KADID-10K [31] 数据集中采样了 7, 174 个图像来进行空间失真识别。使用[63]中的失真类型注释,我们选择了11种不同类型的空间失真:“压缩伪影”、“空间模糊”、“运动模糊”、“噪声”、“过度曝光”、“曝光不足”、“低对比度” 、“高对比度”、“过饱和”、“去饱和”和“块效应”。对于运动失真识别,我们重点关注视频失真——“闪烁(相机抖动)”和“卡顿”。我们使用来自 LIVE-Qualcomm [16] 的 34 个具有闪烁失真的视频和 LSVQ(训练)[60] 中具有闪烁和口吃失真的 100 个视频,并通过提取时间和空间剪辑来扩展它们,产生 5, 211 个包含运动的视频剪辑扭曲。指令格式如图2所示。
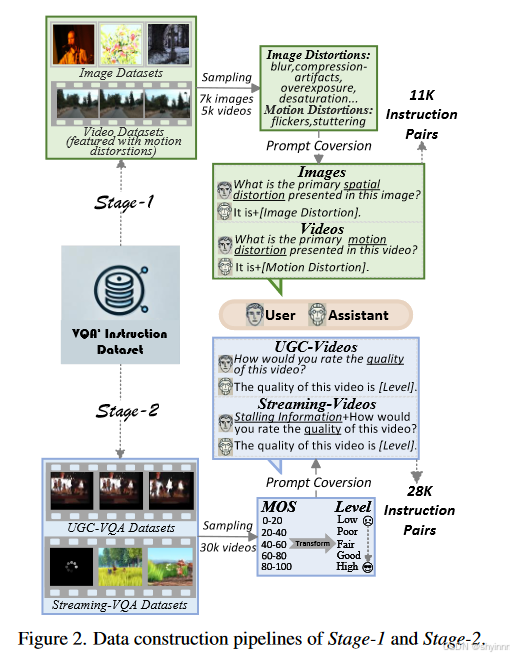
3.2 stage2:对视频质量进行评分的微调子集。
我们使用LSVQ(训练)作为离线UGC视频质量评分任务的视频源,同时使用Waterloo-I [7]、WaterlooIII [7]和LIVE-NFLX-II [5]作为离线UGC视频质量评分任务的视频源。流媒体视频质量评分任务。为了确保所有数据集的主观实验分数处于相同的范围内,我们将每个数据集中的 MOS 标准化为 [0, 100] 范围。缩放后,我们将视频质量分为五个质量等级:“高”、“好”、“一般”、“差”和“低”,每个等级代表20分的区间。这种方法最大限度地减少了数据集中质量分布不一致的影响。
对流视频数据集:在指令集中添加了停顿信息。我们设计了两种格式来呈现停顿信息。第一种格式使用“0/1”序列直接指示每一帧的停顿(“1”表示停顿,“0”表示平滑播放)。在第二种格式中,停顿信息概括如下:停顿事件总数、每个停顿事件的持续时间、停顿事件持续时间占视频总长度的比例、初始缓冲时间以及停顿事件之间经过的时间。最后一次停顿事件的结束和播放的结束。
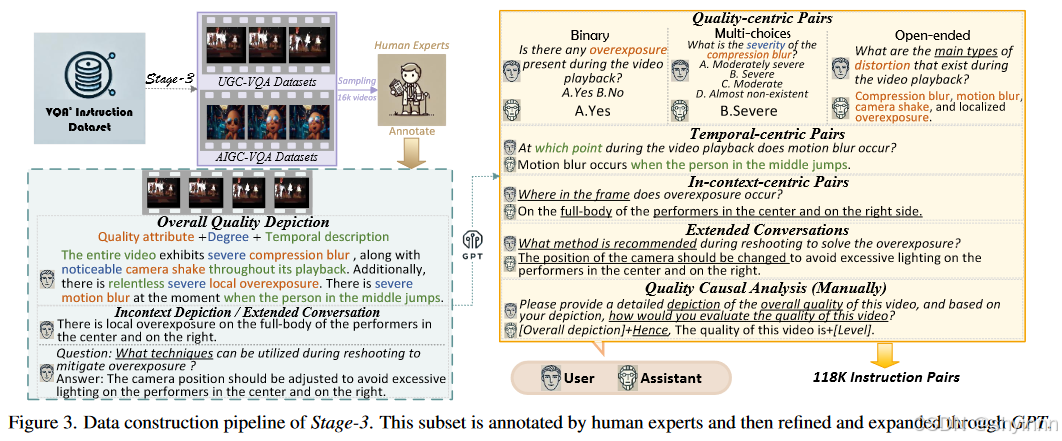
3.3 stage3:质量理解
从 LSVQ (train) 和 LSVQ (1080p) [60] 中选择 14, 005 个视频,从 LIVQ-VQC [43] 中选择 497 个视频,从 AIGC 视频数据集 Videofeedback [17] 中选择 998 个视频。该指令集主要针对视频的低级视觉质量问答,同时还涉及视频审美评估(VAA)和AIGC视频质量分析相关的少量数据。为了构建更多的问答对,我们采用了使用 GPT 扩展人类专家注释的方法。
先,我们需要针对视频质量属性进行全面的整体质量描述。每个描述都包含几个质量属性,用三个关键元素描述:质量属性+程度+时间描述。
在第二部分中,我们要求注释者提供包含上下文(局部)时间或空间质量的简短质量描述。如果找不到这样的描述,可以用扩展对话来代替。
使用 GPT 重写和细化带注释的整体质量描述、上下文描述和扩展对话。
对于每个总体描述,我们指示 GPT 提取信息并将其重新表述为三个以质量(属性)为中心的问答对:二元选择单答案对、多选单答案对和开放式对。要求 GPT 根据原始整体描述生成一对以时间为中心的问答对和另一对扩展对话(人工注释的对话除外)。
对于人工注释的上下文描述和扩展对话,GPT 还将它们重写为正式问答对的格式,其含义不变。
对于前面提到的带注释的整体描述,为了在训练过程中充分利用信息,我们将它们手动制定为质量因果分析问答对的形式。
3.4主观实验
主观标注实验共有33名参与者,全部是受过良好教育、具有相关专业背景的本科生或研究生。其中,16名参会人员为相关领域的专家。参与者的选择确保了人工注释数据的质量。整个实验持续一个月,期间要求所有参与者在满足正式主观实验要求的环境中观看和注释视频。每个参与者注释的视频数量为100至1, 000个。为防止疲劳,指导参与者均匀分配每日注释任务,每天不少于15个视频,不超过30个视频
4. VQA scorer
4.1 模型结构
选择 LLaVA-OneVision-Chat-7B [26] 作为我们模型的基础。基础模型在多个高级视觉问答基准测试中取得了优异的性能[13, 35],并在视频语义理解和推理方面展现了出色的能力。
模型:由SigLIP[62]构建的视觉塔,用于从关键帧序列中提取特征标记;由用于特征映射的全连接层组成的视觉投影仪;以及 Qwen-2 模型 [57],其标记器充当 LLM 和文本嵌入层。
短时间内发生的视频卡顿或抖动会显着降低视频的感知质量,而这种失真与相邻帧密切相关。因此,以长间隔提取的关键帧序列将完全错过这种失真表示
我们建议该模型应该包含一个视频运动提取模块,用于处理密集输入视频帧中的相邻帧。我们选择 SlowFast-R50 [12] 进行运动提取,在空间预处理后输入整个视频。确保运动标记的数量与运动标记的数量一致。使用与视觉投影仪结构相同的运动投影仪来映射运动标记,确保它们的尺寸与视觉标记和文本标记一致。,我们通过对运动标记和可学习的绝对位置嵌入执行标记加法来应用位置编码。在训练期间,视觉标记序列和运动标记序列以交错的方式输入。
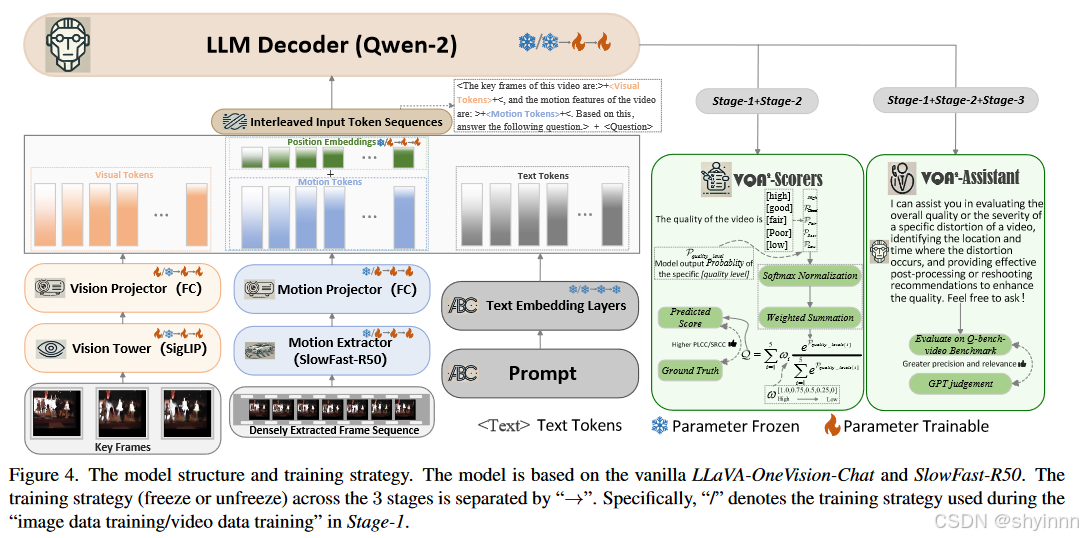
4.2 训练
用第一阶段的数据预训练模型。当使用空间扭曲指令子集进行训练时,我们冻结了 LLM、运动提取器和运动投影仪,只允许训练视觉塔和视觉投影仪。相反,当使用运动失真指令子集时,我们专门训练运动提取器和投影仪。这是因为我们认为预训练数据的格式相对简单。解冻所有模型参数进行训练很容易导致严重的过拟合,从而影响后续的训练过程。
VQA2-UGC-Scorer 在预训练模型上使用来自第 2 阶段 UGC 视频数据部分的指令子集进行训练。随后,基于 VQA2UGC-Scorer,对来自 Stage-2 流视频数据部分的指令集进一步训练 VQA2-StreamingScorer。
最终模型 VQA2-Assistant 旨在掌握更细致的视频质量理解任务和高效的低级视觉问答,同时仍然具备精确的质量评分功能。该模型以 VQA2-UGC-Scorer 为基础,还使用指令子集 Stage-3 进行全面参数调整。
严格遵循 LLaVA-OneVision 项目中提供的训练超参数。所有模型仅在各自的训练数据上训练一个完整的时期。
整个训练过程在8块NVIDIA H800-SXM5-80GB GPU上进行(总共需要约15个小时)。所有评估实验均在 6 个 NVIDIA A6000-48GB GPU 上进行。
4.3 指令设置
在训练和评估阶段,系统会在数据集中的所有指令之前添加系统提示。我们设计的系统提示在训练的各个阶段都是相同的。在评估过程中,我们根据具体任务采用专门设计的系统提示。为了彻底验证模型在视频质量评分任务中的端到端性能,我们不会在系统提示中提供任何可能需要额外提取测试视频的时间信息(如长度、帧速率和停顿信息)。
系统提示:
System Prompt: Now you will receive one video. This video is [length] seconds long, and you will see a sequence of keyframes generated by uniformly sampling 1 frame per second from the video. The keyframe sequence follows the original order of the video. After uniform sampling, there are a total of [length] images: [image]. In addition, you will also obtain motion features extracted from all [num frames] frames of the entire video: [motion]. The temporal motion features also follow the original frame order of the video. Please watch this video carefully, and then answer the following question.
质量评价的提示:
System Prompt: The key frames of this video are: [image]. And the motion feature of the video is [motion]. Please watch this video carefully, and then answer the following question.
- 实验结果
5.1 UGC质量评价
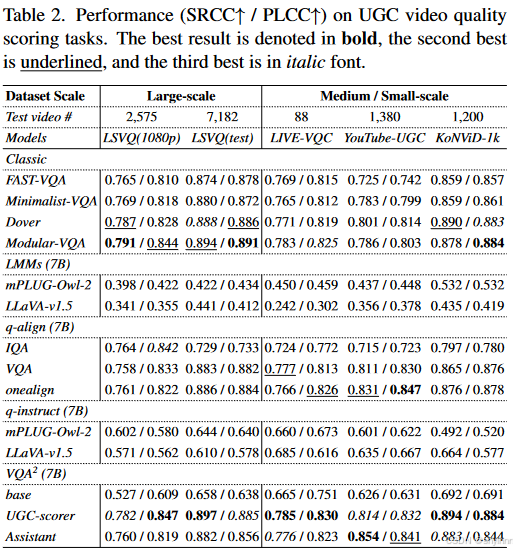
虽然Assistant在性能上稍微落后于UGC-Scorer,但它仍然提供了相对较强的评分性能。这证实了主要用于视频质量理解和问答的助手仍然可以有效地处理质量评分任务,展示了其多功能性
5.2在Q-video-bench上的比较结果
笔者很想知道LLaVA-3的效果会怎么样?发现Q-video-bench是开源的,接下来将会测试一下
5.3消融实验
发现他对于不加入stage-1的预训练的结果,也就是只进行第二步的score的训练的话,泛化性能是没有超过LMM-VQA的,所以对于传统的视频打分的任务,还是要依靠第二个stage的训练,也就是还是需要分数指令的微调。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)