基于llama.cpp在CPU环境部署Qwen3
开始使用Transformers库能够正常把模型服务进行部署起来,但是通过测试速度比较慢,用户的体验会比较差。
最近两天在研究如何使用小规模参数的模型在CPU环境上进行落地应用,比如模型Qwen3-0.6B。开始使用Transformers库能够正常把模型服务进行部署起来,但是通过测试速度比较慢,用户的体验会比较差。
一、框架对比
因此就调研了能够在CPU环境支持对模型加速的算法框架。比如:onnxruntime、openvino、llama.cpp。
(1)onnxruntime:需要转换为onnx格式的模型, 但是对于Qwen3模型使用的SwiGLU、Rotary Embedding、动态 KV 缓存这些新技术onnx格式支持不是很好,会严重影响模型的推理效果;同时转换后会出现中间层冗余,推理速度很慢,对生成长文本的内容并不友好,同时需要把模型进行量化才可以。
(2)openvino:使用这个框架需要把模型转换成onnx格式,然后再转换为openvino IR格式的模型。转换比较复杂。目前官方未提供Qwen3转换的pipeline,需要多次进行测试验证。推理速度比不上llama.cpp + GGUF。
(3)llama.cpp:该框架原生支持CPU,技术文档相对成熟一些,推理和部署相对比较快些。因此最终选择这个技术方案进行了实验。
二、llama.cpp实验
1. 编译程序
# 克隆代码
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# 编译
cmake -B build # 检查本地环境并确定需要包含的推理后端与特性
cmake --build build --conig Release # 构建实际使用的程序文件
或者
cmake --build build --config Release -j 8 # 使用多个并行编译任务进行构建程序
# 程序目录
./build/bin
2. 获取GGUF
# 从huggingface下载对应的Qwen3 GGUF文件
huggingface-cli download Qwen/Qwen3-8B-GGUF qwen3-0.6b-q8_0.gguf --local-dir .
# 自己转换GGUF文件
在llama.cpp文件中有对应的进行格式转换的程序。
图1 hf2gguf
- 运行模型
3.1 llama-cli
# 查看支持的参数
llama-cli --help
# 运行程序
llama-cli -m Qwen3-0.6B-Q8_0.gguf
启动程序后就可以进行正常对话了,如下图所示:
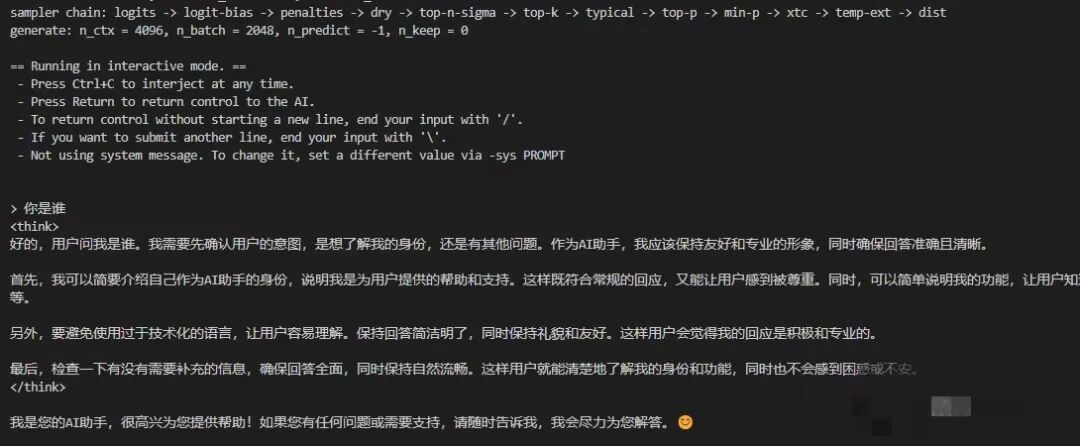
图2 模型推理
还可以配置线程数、模版、生成的最大长度、线程数等参数信息。
3.2 llama-server
如果想封装成http服务,以及openai接口的格式服务,就可以使用llama-server程序进行实现,比如:
llama-server-mmodel.gguf--port8080--hostxx.xx.xx.xx
# openai api
http://localhost:8080/v1/
三、推理速度
针对同样的prompt,让在不同框架下部署的模型进行推理,重复测试N次,计算其平均值。
使用llama.cpp + GGUF框架,模型Qwen3-0.6B(fp16),推理速度大约是20token/s。
使用llama.cpp + GGUF框架,模型Qwen3-0.6B(int8),推理速度大约是31token/s。
单从速度上来看,是能达到落地要求的,用户的体验相比使用tansformers库推理提高了很多。
以上就是在使用llama.cpp + GGUF策略在cpu环境上探索部署Qwen3-0.6B模型的分享,既然速度可以,接下来就可以使用Qwen3-0.6B模型处理具体的下游任务,最终进行落地到实际场景中。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献370条内容
已为社区贡献370条内容

所有评论(0)