快速上手PaddleOCR-VL
是百度飞桨团队于 2025 年 10 月开源的轻量化多模态文档解析模型,仅用 0.9 B 参数就在国际权威评测 OmniDocBench V1.5 上以 92.6 分登顶全球第一,超越 GPT-4o 等 70 B+ 级大模型。采用 NaViT 动态高分辨率视觉编码器 + 轻量级 ERNIE-4.5-0.3B 语言模型,兼顾高精度与高效率,在文档元素识别任务中表现卓越,同时显著降低计算资源消耗,适合
1.简介
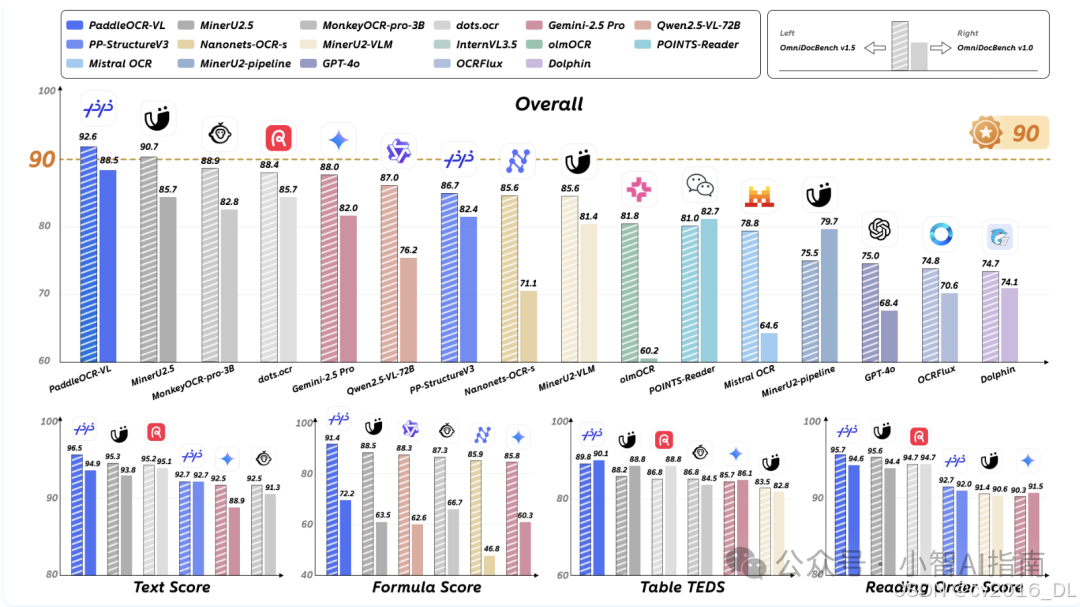
PaddleOCR-VL是百度飞桨团队于 2025 年 10 月开源的轻量化多模态文档解析模型,仅用 0.9 B 参数就在国际权威评测 OmniDocBench V1.5 上以 92.6 分登顶全球第一,超越 GPT-4o 等 70 B+ 级大模型。
2.特性
紧凑而强大的 VLM 架构:
采用 NaViT 动态高分辨率视觉编码器 + 轻量级 ERNIE-4.5-0.3B 语言模型,兼顾高精度与高效率,在文档元素识别任务中表现卓越,同时显著降低计算资源消耗,适合实际部署。
提出了一种新颖的视觉-语言模型(VLM)架构,该模型专为资源高效的推理而设计,并在元素识别任务中实现了卓越的性能。通过将 NaViT 风格的动态高分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型相集成,我们显著提升了模型的识别能力和解码效率。这种集成在保持高精度的同时,有效降低了计算需求,使其非常适合高效、实用的文档处理应用。
文档解析 SOTA 性能
在页面级解析与元素级识别两方面均达到 SOTA,优于传统流水线方案,可高质量识别文本、表格、公式和图表等复杂结构文档,包括手写文本与历史文献。
PaddleOCR-VL 在页面级文档解析和元素级识别两方面均达到了行业领先(SOTA)的性能。它显著优于现有的基于流水线的解决方案,并在文档解析方面展现出与主流视觉-语言模型(VLMs)相比强劲的竞争力。此外,它在识别复杂的文档元素方面表现出色,例如文本、表格、公式和图表,使其能够应对各种具有挑战性的内容类型,包括手写文本和历史文献。这赋予了模型高度的通用性,使其适用于广泛的文档类型和应用场景。
多语言支持(109种)
覆盖中文、英文、日文、韩语、俄语、阿拉伯语等多语种及多书写体系,适用于全球化、多语言文档解析场景。
PaddleOCR-VL 支持 109 种语言,覆盖了全球主要语种,包括但不限于中文、英文、日文、拉丁语、韩语,以及各种拥有不同书写系统和结构的语言,例如俄语(西里尔字母)、阿拉伯语、印地语(天城体)和泰语。这种广泛的语言覆盖,极大地增强了我们的系统在多语言和全球化文档处理场景中的适用性。
3.架构
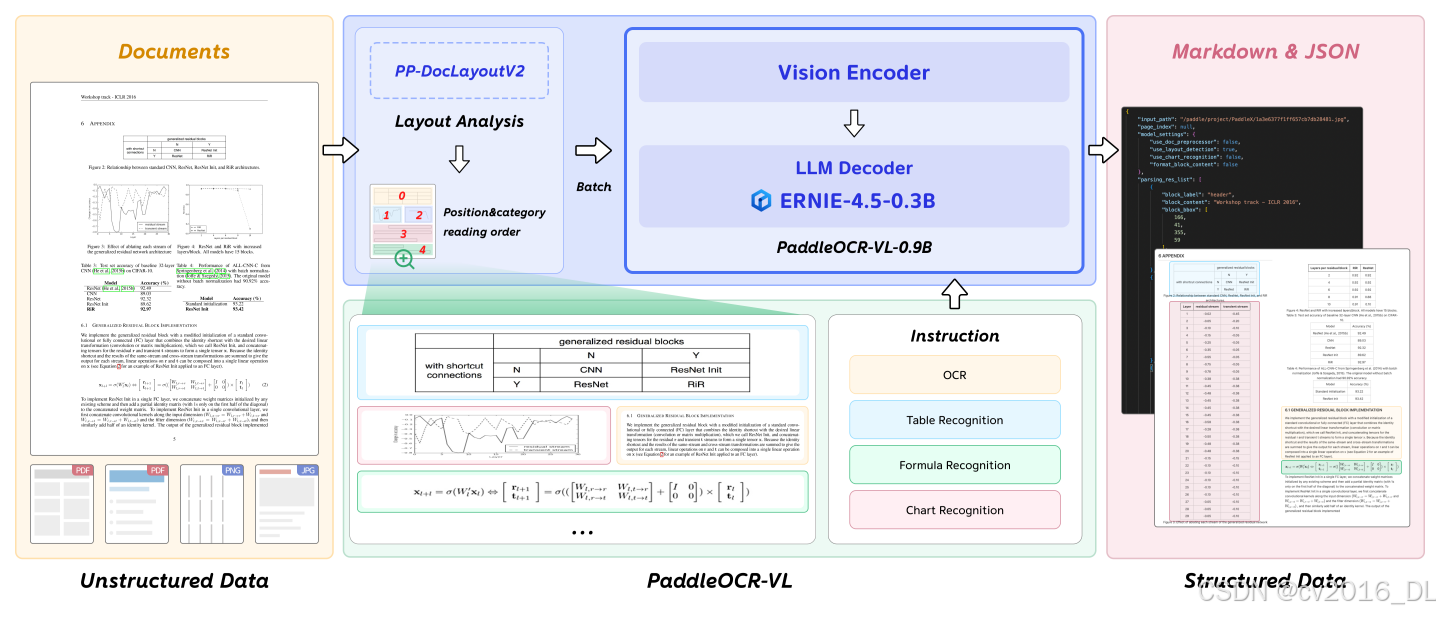
PaddleOCR-VL 将复杂的文档解析任务分解为两个阶段。第一阶段 PP-DocLayoutV2 负责版面分析,定位语义区域并预测其阅读顺序。随后,第二阶段 PaddleOCR-VL-0.9B 基于这些版面预测,对文本、表格、公式和图表等多样化内容进行细粒度识别。最后,轻量级后处理模块聚合两阶段输出,并将最终文档格式化为结构化的 Markdown 和 JSON。
|
阶段 |
模块 |
功能说明 |
输出内容 |
|---|---|---|---|
| 阶段 1 — 版面分析 | PP-DocLayoutV2 |
检测语义区域并预测阅读顺序 |
结构化版面信息 |
| 阶段 2 — 内容识别 | PaddleOCR-VL-0.9B |
识别文本、表格、公式、图表等多类文档元素 |
元素级识别数据 |
| 后处理(聚合阶段) |
轻量后处理模块 |
融合识别内容并生成最终结构化文档 |
Markdown / JSON |
如果对核心特性和架构的描述看起来有些发懵,咱们用大白话解释一下,PaddleOCR就像文档界的“超级翻译官”和“万能扫描仪”,支持 100 多种语言,连手写、竖排、公式、表格这种最棘手的内容都能读得又快又准。
4.快速开始
安装依赖
安装 PaddlePaddle 和 PaddleOCR:
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install -U "paddleocr[doc-parser]"
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install -U "paddleocr[doc-parser]"
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whlpython API:
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")使用 vLLM 加速 VLM;
Start the VLM inference server (the default port is 8080):
docker run \ --rm \ --gpus all \ --network host \ ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server # You can also use ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server for the SGLang server
docker run \
--rm \
--gpus all \
--network host \
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server
# You can also use ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server for the SGLang serverCall the PaddleOCR CLI or Python API:
paddleocr doc_parser \
-i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png \
--vl_rec_backend vllm-server \
--vl_rec_server_url http://127.0.0.1:8080from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL(vl_rec_backend="vllm-server", vl_rec_server_url="http://127.0.0.1:8080")
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_ocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")5.其他链接
官网:
https://ernie.baidu.com/blog/zh/posts/paddleocr-vl/
HuggingFace模型库:
https://huggingface.co/PaddlePaddle/PaddleOCR-VL
arXiv技术论文:
https://arxiv.org/pdf/2510.14528在线体验Demo:
https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)