【生物大模型文章精读七】HyenaDNA——Evo模型的主力算子
从最左边的架构图我们可以看到,Hyena是由序列信息经过Hyena Operator和一个MLP形成的,在这个过程中带上Resnet。所以HyenaDNA这个block中最重要的就是Hyena Operator了而对于这个Operator,作者花了大量的笔墨来进行介绍。而最为直接的就是这张Figure3.1了,介绍了对输入x的计算根据作者的描述,和Transformer类似,在序列表示输入之后,先
如果大家仔细地关注过Evo模型的框架,就会发现其中有一个熟悉而陌生的算子:Hyena
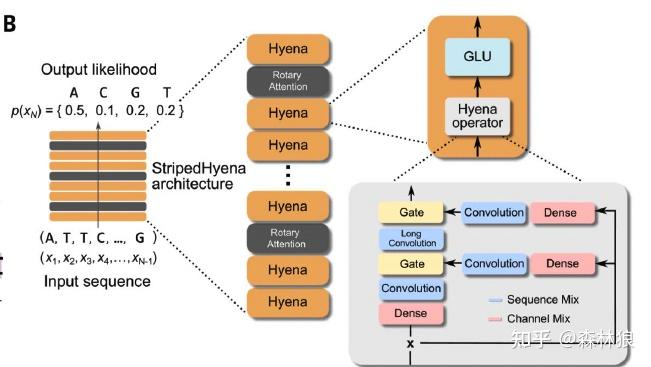
而evo这个大模型,几乎是由hyena加上Rotary attention 2:1堆叠而成的。同样在evo2中,hyena仍然是作为基础框架在发挥作用。而这里的Hyena究竟有什么样的魔力,使得其能够霸榜DNA大模型不倒呢? Hyena,直译是鬣狗的意思,如果大家经常看动物世界,或许有印象,就是和狮子在草原上争霸的这一个族群;而他们虽然单体战斗不如狮子,但是通过灵活的配合和超强的机动性,在与狮子的竞争中不落下风;是一种以先进机制匹敌高数值的典范。

作者以此为模型的名称,是否也是想要说明他们模型胜在机制,而不是大量的算力堆砌呢? 吹牛时间结束,下面我们来关注正式的内容
一、动机与背景(传统序列建模在基因数据长依赖上的挑战)
基因组序列是一种极端长的、层次复杂的生物文本。于是人们理所应当地把DNA作为一种自然语言来进行语言模型的训练,但是与自然语言相比,DNA 的“语言”具有两个显著特点:
- 长度极长
- 局部变异高度敏感。
例如,人类基因组约含有 32 亿个碱基对,其中调控元件间的作用往往跨越十万甚至百万个碱基;而单个核苷酸的改变(如 SNP)即可显著改变基因调控或蛋白功能。
在这两个因素的基础上,由于传统的 Transformer 模型计算复杂度随序列长度平方增长,在显存有限的情况下,在实际中通常只能建模 512–4,096 个碱基的上下文,覆盖人类基因组不到 0.001% 。而为了扩展上下文范围,研究者常采用两种折衷策略:
- 固定 k-mer 分词或 BPE 编码,将若干碱基聚合为“词单元”,以减少序列长度;
- 膨胀卷积(dilation)与下采样,在长序列上跳跃式提取特征
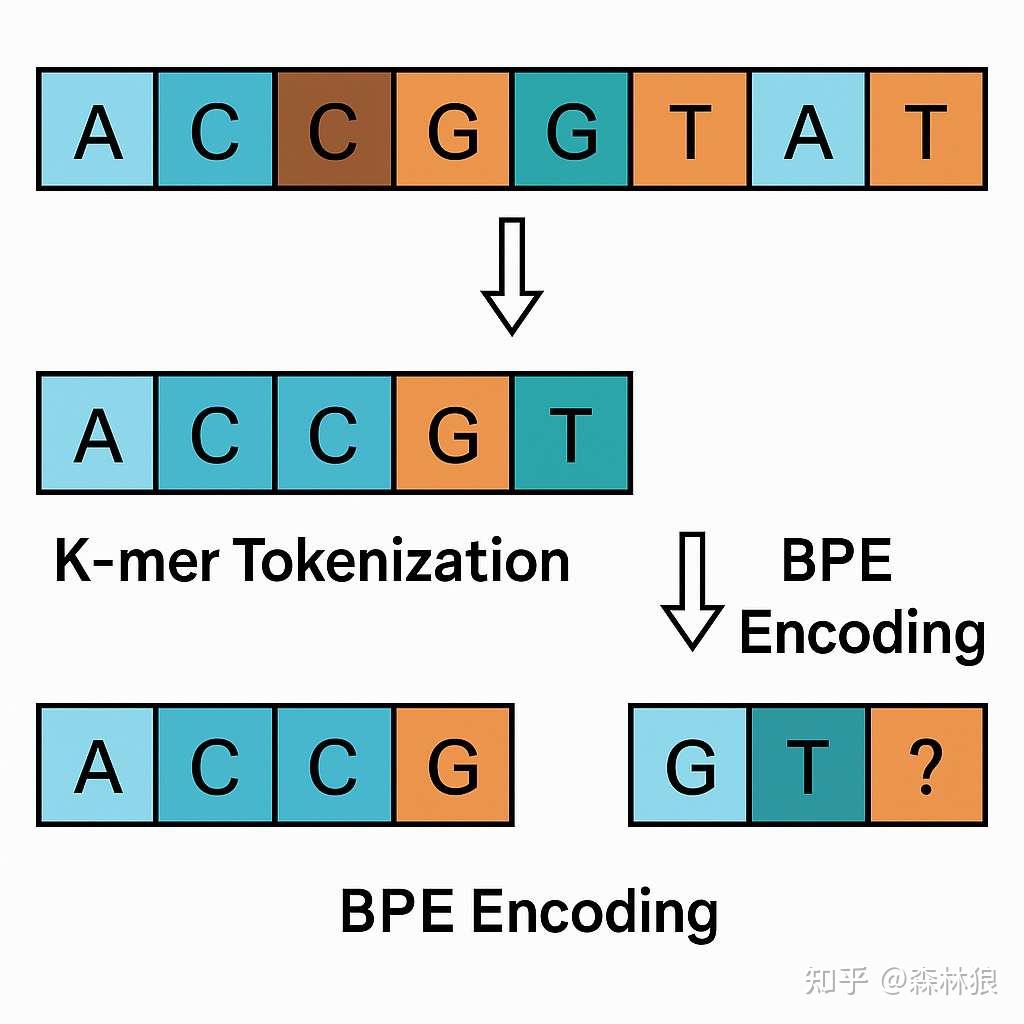
但这两种方法都牺牲了单碱基分辨率,无法捕捉 SNP 等精细突变对功能的影响。此外,基因调控的物理机制往往跨越远距离调控元件和三维染色质折叠层次,要求模型具备全局依赖建模能力与位置敏感的局部表征能力兼备。 因此,如何在可计算的时间复杂度下,同时保持百万级上下文与单碱基精度,成为基因序列建模的核心挑战。
而本文的主角:HyenaDNA 通过长卷积与隐式门控机制,实现亚二次复杂度(O(L log²L))的全局依赖建模,为理解基因组中的远程调控关系与功能语法奠定了基础。
二、HyenaDNA模型架构介绍
1. 整体架构介绍
从最左边的架构图我们可以看到,Hyena是由序列信息经过Hyena Operator和一个MLP形成的,在这个过程中带上Resnet。所以HyenaDNA这个block中最重要的就是Hyena Operator了
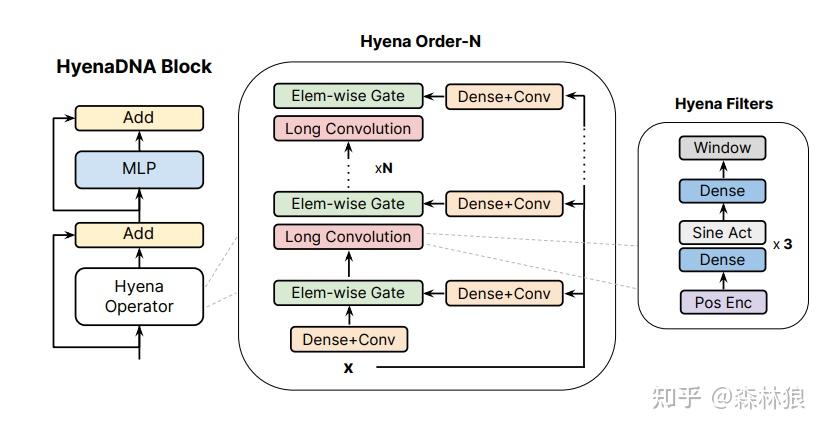
而对于这个Operator,作者花了大量的笔墨来进行介绍。而最为直接的就是这张Figure3.1了,介绍了对输入x的计算
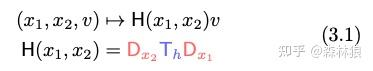

根据作者的描述,和Transformer类似,在序列表示输入之后,先进行线性映射加短卷积计算,然后一气化三清变成
l = u.size(-2)
l_filter = min(l, self.l_max)
u = self.in_proj(u)
u = rearrange(u, 'b l d -> b d l')
uc = self.short_filter(u)[...,:l_filter]
*x, v = uc.split(self.d_model, dim=1)
随后,作者使用了一种learnable long convolution filter 来将输入的过滤为,托普利兹矩阵,原文叫Toeplitz matrix。而这个卷积核非常长,且它的参数是由一个小的神经网络来学习的,这点就很有意思了。这也是Hyena能够节省参数和复杂度的原因,后面我们会着重介绍这个卷积核。这里只是这个卷积核在这里的调用:
self.filter_fn = HyenaFilter(
d_model * (order - 1),
order=filter_order,
seq_len=l_max,
channels=1,
dropout=filter_dropout,
**filter_args
)
k = self.filter_fn.filter(l_filter)[0]
k = rearrange(k, 'l (o d) -> o d l', o=self.order - 1)
bias = rearrange(self.filter_fn.bias, '(o d) -> o d', o=self.order - 1)
OK,明白了这个Hyena卷积核之后,作者在生成了,用这个Hyena长卷积核来对,的长距离特征进行了提取的得到,随后以作为门控,对进行过滤,得到最后再进行Hyena长卷积核提取,用的结果进行门控最终得到输出。这里看着是不是似曾相识?
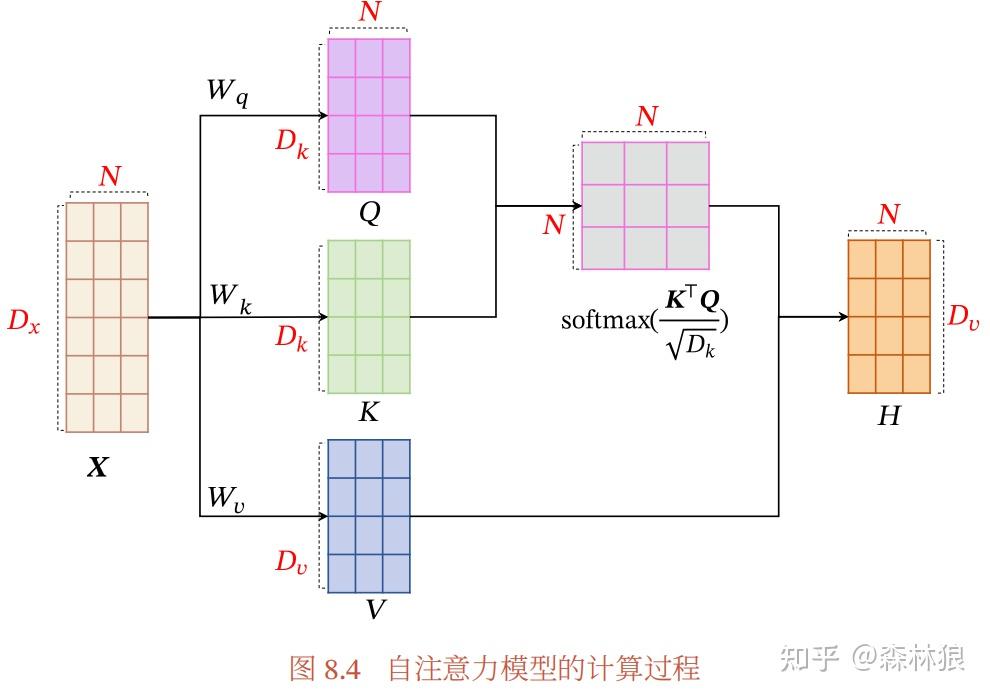
实际上就是transformer的qk做注意力后再来过v的套路。还得是经典老番。
最后让我们来看综合看看这个Operator的模块代码 注意其中的元素:
- x:来自 short_filter 的分块输出(把通道按 d_model 一块一块切)。当 order=3 时通常有 x=[x0, x1],再加一条主支 v,每个都是 B×D×L。
- v:主分支特征,形状 B×D×L(batch×通道×长度)。
- k:长卷积核,经整形后是 k.shape = [order-1, D, L],也就是每一阶 o、每个通道 d 一条长核。
- bias:对应每阶、每通道的偏置,bias.shape=[order-1, D]。
class HyenaOperator(nn.Module):
def __init__(
self,
d_model,
l_max,
order=2,
filter_order=64,
dropout=0.0,
filter_dropout=0.0,
**filter_args,
):
r"""
Hyena operator described in the paper https://arxiv.org/pdf/2302.10866.pdf
Args:
d_model (int): Dimension of the input and output embeddings (width of the layer)
l_max: (int): Maximum input sequence length. Defaults to None
order: (int): Depth of the Hyena recurrence. Defaults to 2
dropout: (float): Dropout probability. Defaults to 0.0
filter_dropout: (float): Dropout probability for the filter. Defaults to 0.0
"""
super().__init__()
self.d_model = d_model
self.l_max = l_max
self.order = order
inner_width = d_model * (order + 1)
self.dropout = nn.Dropout(dropout)
self.in_proj = nn.Linear(d_model, inner_width)
self.out_proj = nn.Linear(d_model, d_model)
self.short_filter = nn.Conv1d(
inner_width,
inner_width,
3,
padding=2,
groups=inner_width
)
self.filter_fn = HyenaFilter(
d_model * (order - 1),
order=filter_order,
seq_len=l_max,
channels=1,
dropout=filter_dropout,
**filter_args
)
def forward(self, u, *args, **kwargs):
l = u.size(-2)
l_filter = min(l, self.l_max)
u = self.in_proj(u)
u = rearrange(u, 'b l d -> b d l')
uc = self.short_filter(u)[...,:l_filter]
*x, v = uc.split(self.d_model, dim=1)
k = self.filter_fn.filter(l_filter)[0]
k = rearrange(k, 'l (o d) -> o d l', o=self.order - 1)
bias = rearrange(self.filter_fn.bias, '(o d) -> o d', o=self.order - 1)
for o, x_i in enumerate(reversed(x[1:])):
v = self.dropout(v * x_i)
v = self.filter_fn(v, l_filter, k=k[o], bias=bias[o])
y = rearrange(v * x[0], 'b d l -> b l d')
y = self.out_proj(y)
return y
注意这里的这部分代码
for o, x_i in enumerate(reversed(x[1:])):
v = self.dropout(v * x_i) # 1) 门控:逐时刻逐通道点乘
v = self.filter_fn(v, l_filter,
k=k[o], bias=bias[o]) # 2) 长卷积:depthwise 1D + 偏置
这里作者通过短卷积生成的x_i来对主value进行门控过滤,实际上是把门控信号 x_i 作为时变系数,调制主分支的每个通道。随后对每个通道做一维长卷积。
OK,明确了卷Operator的架构后,让我们来看里面的这个特色长卷积核是怎么设计的吧。
2. 核心卷积核HyenaFilter介绍
所以让我们来看看这个HyenaFilter到底是什么吧
| 类型 | 卷积核参数 | 计算方式 | 参数增长 |
|---|---|---|---|
| 普通卷积 (CNN) | 固定可训练权重矩阵 | h_{i-j} 由直接训练得到 | 随卷积长度 L 线性增长 |
| Hyena 卷积 (Implicit Filter) | 动态生成权重 | h_t = \gamma_\theta(t) | 与序列长度无关 |
所以,这里Hyena卷积的核心思想是:
- 传统卷积需要显式保存 的所有元素,计算复杂度 。
- Hyena 用 直接生成 ,可以在时间维上用 FFT 快速计算:
这就允许卷积核长度远大于模型参数量,从而实现长依赖。 来看看hyena卷积的代码:
class HyenaFilter(OptimModule):
def __init__(
self,
d_model,
emb_dim=3, # dim of input to MLP, augments with positional encoding
order=16, # width of the implicit MLP
fused_fft_conv=False,
seq_len=1024,
lr=1e-3,
lr_pos_emb=1e-5,
dropout=0.0,
w=1, # frequency of periodic activations
wd=0, # weight decay of kernel parameters
bias=True,
num_inner_mlps=2,
normalized=False,
**kwargs
):
"""
Implicit long filter with modulation.
Args:
d_model: number of channels in the input
emb_dim: dimension of the positional encoding (`emb_dim` - 1) // 2 is the number of bands
order: width of the FFN
num_inner_mlps: number of inner linear layers inside filter MLP
Note:
filter_dropout is not implemented
"""
super().__init__()
self.d_model = d_model
self.use_bias = bias
self.fused_fft_conv = fused_fft_conv
self.bias = nn.Parameter(torch.randn(self.d_model))
self.dropout = nn.Dropout(dropout)
act = Sin(dim=order, w=w)
self.emb_dim = emb_dim
assert emb_dim % 2 != 0 and emb_dim >= 3, "emb_dim must be odd and greater or equal to 3 (time, sine and cosine)"
self.seq_len = seq_len
self.pos_emb = PositionalEmbedding(emb_dim, seq_len, lr_pos_emb)
self.implicit_filter = nn.Sequential(
nn.Linear(emb_dim, order),
act,
)
for i in range(num_inner_mlps):
self.implicit_filter.append(nn.Linear(order, order))
self.implicit_filter.append(act)
self.implicit_filter.append(nn.Linear(order, d_model, bias=False))
self.modulation = ExponentialModulation(d_model, **kwargs)
self.normalized = normalized
for c in self.implicit_filter.children():
for name, v in c.state_dict().items():
optim = {"weight_decay": wd, "lr": lr}
setattr(getattr(c, name), "_optim", optim)
def filter(self, L, *args, **kwargs):
z, t = self.pos_emb(L)
h = self.implicit_filter(z)
h = self.modulation(t, h)
return h
def forward(self, x, L, k=None, bias=None, *args, **kwargs):
if k is None: k = self.filter(L)
# Ensure compatibility with filters that return a tuple
k = k[0] if type(k) is tuple else k
y = fftconv(x, k, bias)
return y
这其中有几个参数解释一下:
| 参数 | 类型 | 作用 | 解释 |
|---|---|---|---|
| w | float | Sin 激活的频率参数 | 决定生成核中正弦波的振荡频率——越大频率越高。 |
| ExponentialModulation | 模块 | 指数调制层 | 把生成的核再乘上一个指数衰减或增长函数,让核更像自然信号(例如随时间衰减)。 |
| PositionalEmbedding | 模块 | 位置编码生成器 | 给每个时间步添加 sin/cos + 线性时间项,让 MLP 感知序列的“位置”。 |
这个过程中,implicit_filter(z)(线性 → Sin 激活 → 多层线性+Sin)输出 h ∈ ℝ^{L×d_model}。 与CNN学一个固定的小核相比,这里学一个“生成核的函数”,给定长度就能吐出一条很长的、通道专属的卷积核,并用 FFT 高效卷积;再配合外层门控实现时变行为。
随后就把filter定义为,先位置编码、再implicit_filter,再是modulation
def filter(self, L, *args, **kwargs):
z, t = self.pos_emb(L)
h = self.implicit_filter(z)
h = self.modulation(t, h)
return h
pos_emb → implicit_filter(MLP + Sin) → ExponentialModulation → k(L,d) 其中最为核心的设计就是implicit_filter了,可以看到
self.implicit_filter = nn.Sequential(
nn.Linear(emb_dim, order),
act,
)
for i in range(num_inner_mlps):
self.implicit_filter.append(nn.Linear(order, order))
self.implicit_filter.append(act)
self.implicit_filter.append(nn.Linear(order, d_model, bias=False))
for c in self.implicit_filter.children():
for name, v in c.state_dict().items():
optim = {"weight_decay": wd, "lr": lr}
setattr(getattr(c, name), "_optim", optim)
作者叠加了多层线性层,而这些线性层,会对HyenaOperator中的k进行生成卷积核:
if k is None:
k = self.filter(L)
y = fftconv(x, k, bias)
先生成卷积核self.filter(L),再使用 快速傅里叶卷积 (FFT convolution),等价于 Conv1d(x, k),但能处理上千长度的核,效率更高。 这样我们就可以看懂operator里面的k是怎么来的了:
- 先“生成”一条长核 k(来自 HyenaFilter)
k = self.filter_fn.filter(l_filter)[0]
- 重排成「阶 × 通道 × 长度」
k = rearrange(k, 'l (o d) -> o d l', o=self.order - 1)
- 逐“阶”使用:门控 → 长卷积
for o, x_i in enumerate(reversed(x[1:])):
v = self.dropout(v * x_i)
v = self.filter_fn(v, l_filter, k=k[o], bias=bias[o])
而后面的ExponentialModulation,是在卷积核上加一个随时间渐变的控制,让模型能控制过去的信息影响多大、持续多久。就是在生成的卷积核上乘上一个调制
其中 α 是可学习的参数。
好的,弄清楚这个算子就花了很多笔墨了,下一节来尝试一下用hyena自回归预训练试试,是骡子是马拉出来溜溜。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)