Volcano 进阶实战 (二) - (网络拓扑/负载感知)调度
本篇详细介绍网络拓扑感知调度和负载感知重新调度策略。并利用 8 台节点的 Kubernetes 的环境模拟。网络拓扑结构调度。模拟高负载重新调度
承接前文继续开始进阶调度策略:
四、Volcano 进阶功能实战
在AI大模型训练场景中,模型并行(Model Parallelism)将模型分割到多个节点上,训练过程中这些节点需要频繁进行大量数据交互。此时,节点间的网络传输性能往往成为训练的瓶颈,显著影响训练效率。数据中心的网络类型多样(如IB、RoCE、NVSwitch等),且网络拓扑复杂,通常包含多层交换机。两个节点间跨的交换机越少,通信延迟越低,吞吐量越高。因此,用户希望将工作负载调度到具有最高吞吐量和最低延迟的最佳性能域,尽可能减少跨交换机的通信,以加速数据交换,提升训练效率。
为此,Volcano提出了网络拓扑感知调度(Network Topology Aware Scheduling)策略,通过统一的网络拓扑API和智能调度策略,解决大规模数据中心AI训练任务的网络通信性能问题
4.1 网络拓扑感知调度
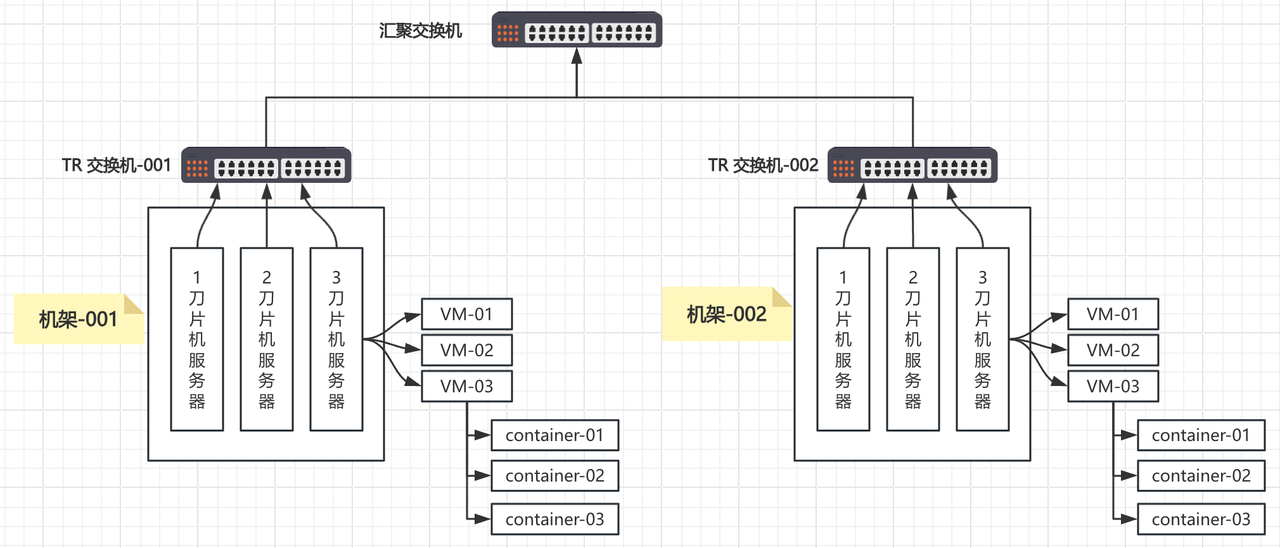
我绘制了一个简易的 IDC 网络拓扑示意图。可以看到实例计算通信速度
-
在本地是最快 -->
-
次之 在同刀片机上 -->
-
次之 在同机架上 -->
-
次之 在同汇聚交换机 -->
-
次之 在同 IDC 机房 -->
-
次之 在同城不同IDC 机房 -->
-
次之 在同国不同城不同IDC 机房 -->
-
次之 跨国不同IDC 机房 (网络联通情况下最慢的网络拓扑)
在大模型训练中海量数据交换通信场景下,是非常需要能优化计算资源,计算任务的网络拓扑优化。
a) 资源准备
k8s / 1 master + 7worker
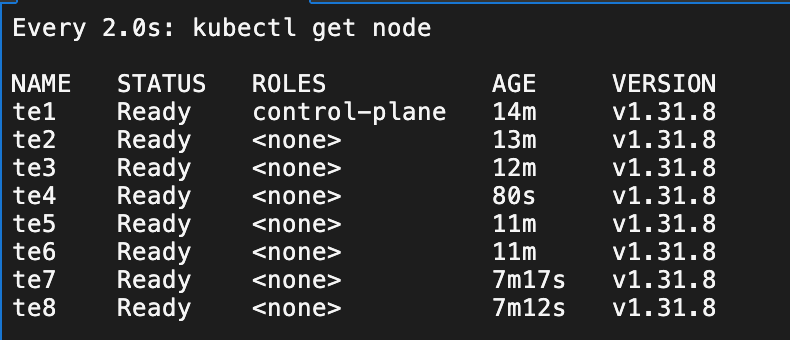
b) 构建HyperNode 拓扑
打标签标记 节点拓扑 模拟网络拓扑(标签在生产环境根据实际情况标记即可)
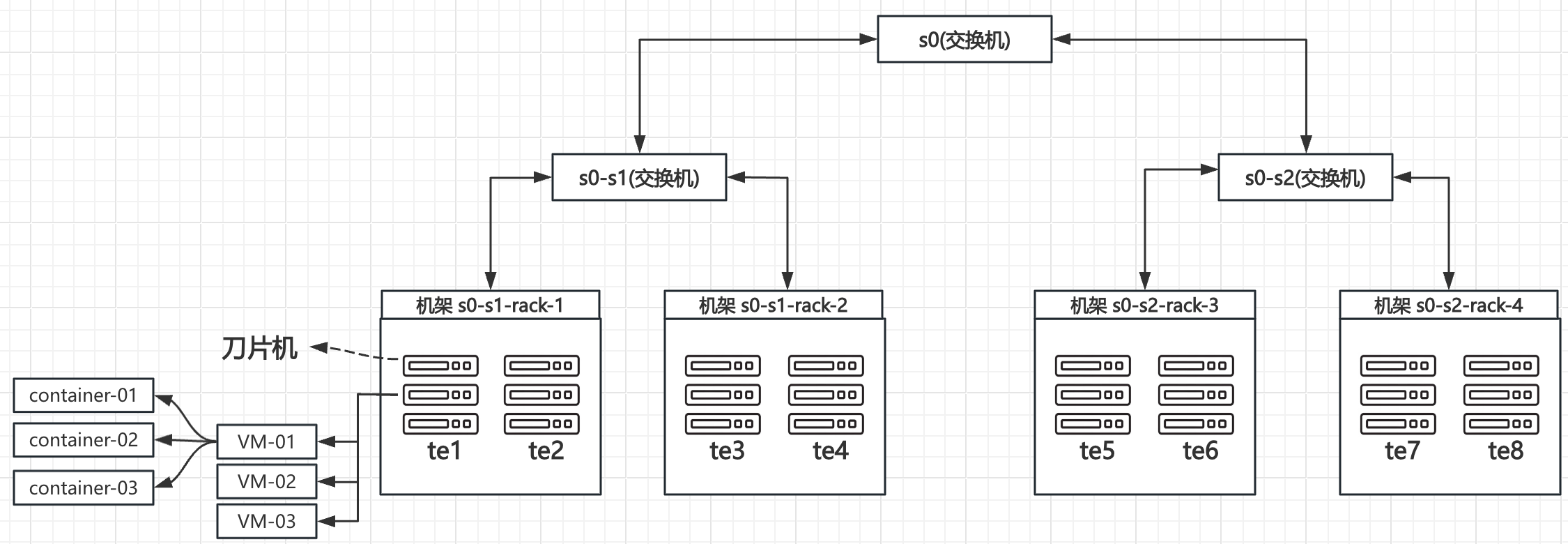
kubectl label node te1 volcano.sh/rack=s0-s1-rack-1 --overwrite
kubectl label node te2 volcano.sh/rack=s0-s1-rack-1 --overwrite
kubectl label node te3 volcano.sh/rack=s0-s1-rack-2 --overwrite
kubectl label node te4 volcano.sh/rack=s0-s1-rack-2 --overwrite
kubectl label node te5 volcano.sh/rack=s0-s2-rack-3 --overwrite
kubectl label node te6 volcano.sh/rack=s0-s2-rack-3 --overwrite
kubectl label node te7 volcano.sh/rack=s0-s2-rack-4 --overwrite
kubectl label node te8 volcano.sh/rack=s0-s2-rack-4 --overwrite构建 valcano 网络拓扑
cat <<EOF | kubectl apply -f -
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0-s1-rack-1
spec:
tier: 1
members:
- type: Node
selector:
exactMatch:
name: "te1"
- type: Node
selector:
exactMatch:
name: "te2"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0-s1-rack-2
spec:
tier: 1
members:
- type: Node
selector:
exactMatch:
name: "te3"
- type: Node
selector:
exactMatch:
name: "te4"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0-s2-rack-3
spec:
tier: 1
members:
- type: Node
selector:
exactMatch:
name: "te5"
- type: Node
selector:
exactMatch:
name: "te6"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0-s2-rack-4
spec:
tier: 1
members:
- type: Node
selector:
exactMatch:
name: "te7"
- type: Node
selector:
exactMatch:
name: "te8"
EOFcat <<EOF | kubectl apply -f -
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0-s1
spec:
tier: 2
members:
- type: HyperNode
selector:
exactMatch:
name: "s0-s1-rack-1"
- type: HyperNode
selector:
exactMatch:
name: "s0-s1-rack-2"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0-s2
spec:
tier: 2
members:
- type: HyperNode
selector:
exactMatch:
name: "s0-s2-rack-3"
- type: HyperNode
selector:
exactMatch:
name: "s0-s2-rack-4"
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0
spec:
tier: 3
members:
- type: HyperNode
selector:
exactMatch:
name: "s0-s1"
- type: HyperNode
selector:
exactMatch:
name: "s0-s2"
EOF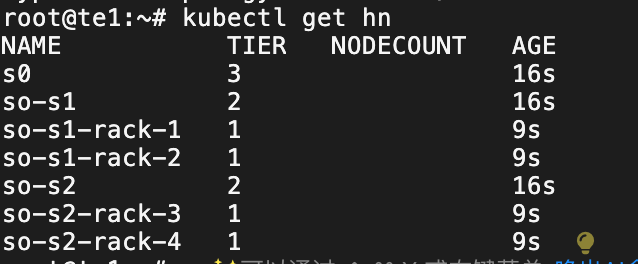
c) 调度测试部署
## hard / soft
cat <<EOF | kubectl apply -f -
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: hello-volcano-job
spec:
schedulerName: volcano
minAvailable: 6
queue: default
networkTopology:
mode: hard
highestTierAllowed: 2
tasks:
- name: mytask
replicas: 10
template:
spec:
containers:
- name: hello-container
image: busybox
command: ["sh", "-c", "echo 'Hello Volcano!' && sleep 30"]
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "100m"
memory: "256Mi"
restartPolicy: Never
EOFhard模式
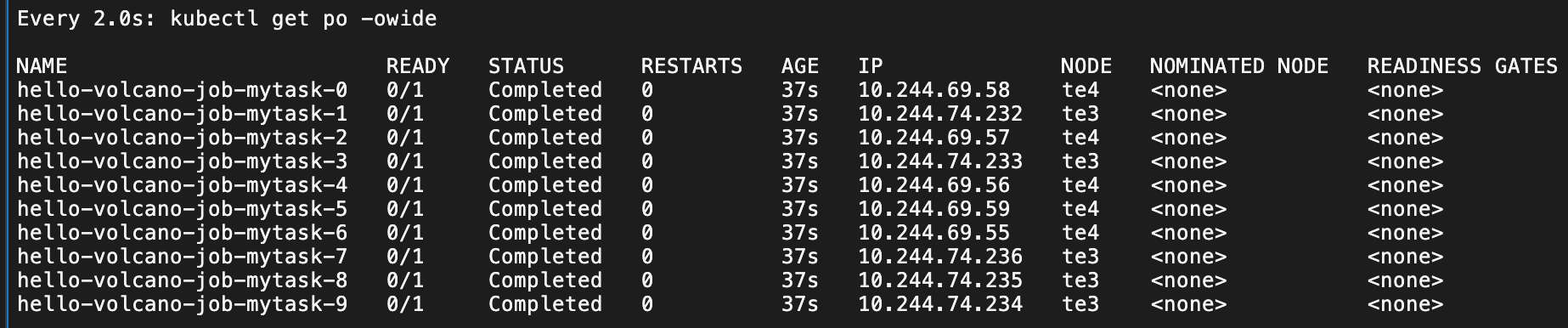
highestTierAllowed: 2 严格在同一个网络拓扑节点上
soft模式

允许调度的就比较多了。看起来是比较零散的。可能还需要更多的精细调整。
4.2 负载感知调度
集群中的调度是将pending状态的Pod分配到节点运行的过程,Pod的调度依赖于集群中的调度器。调度器是通过一系列算法计算出Pod运行的最佳节点,但是Kubernetes集群环境是存在动态变化的,例如某一个节点需要维护,这个节点上的所有Pod会被驱逐到其他节点,但是当维护完成后,之前被驱逐的Pod并不会自动回到该节点上来,因为Pod一旦被绑定了节点是不会触发重新调度的。由于这些变化,集群在一段时间之后就可能会出现不均衡的状态。
a) 基础环境配置
## 安装 metrics-server
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
#需要在环境变量中添加如下 配置去掉校验
#- --kubelet-insecure-tls
## 安装 prometheus 相关组件
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm upgrade --install prometheus prometheus-community/prometheus -n kube-system \
--set server.persistentVolume.enabled=false \
--set server.alertmanager.enabled=false
helm install prometheus-adapter prometheus-community/prometheus-adapter -n kube-system
##安装 valcano
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
##安装 valcano-descheduler
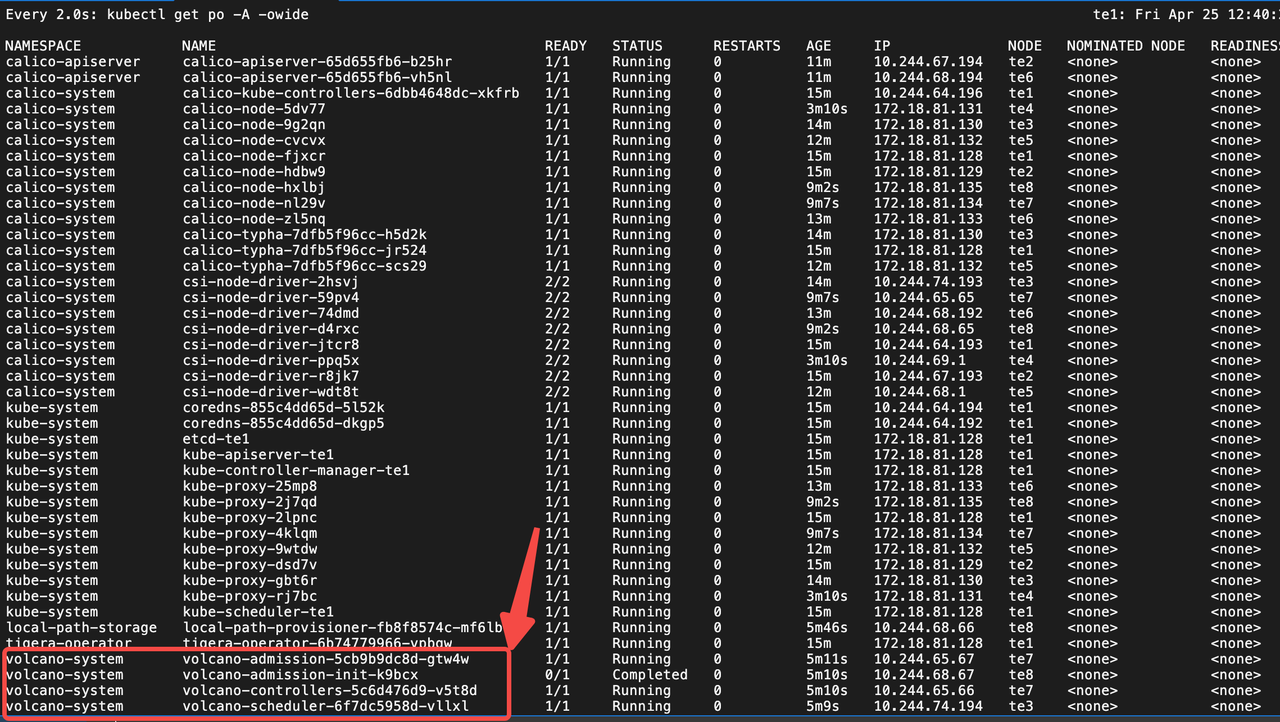
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/descheduler/refs/heads/main/installer/volcano-descheduler-development.yamlmetrics-server 安装成功后会看到如下:
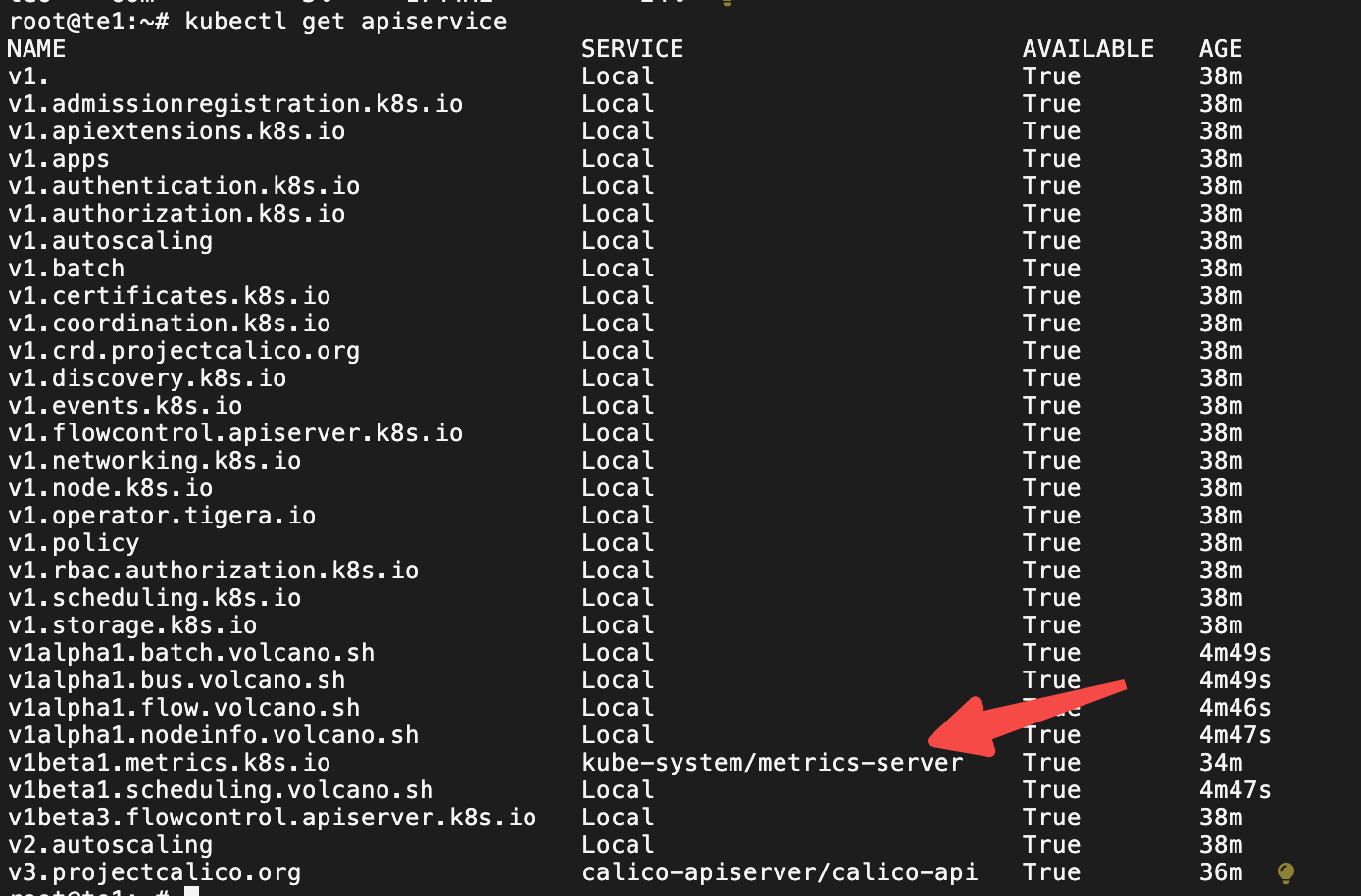
安装 valcano和valcano-descheduler的运行情况

b) descheduler 调度配置
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: volcano-descheduler
namespace: volcano-system
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: kube-system
pluginConfig:
- args:
ignorePvcPods: true
nodeFit: true
priorityThreshold:
value: 10000
name: DefaultEvictor
- args:
evictableNamespaces:
exclude:
- default
metrics:
address: "http://prometheus-server.kube-system.svc.cluster.local:80"
type: Prometheus
targetThresholds:
cpu: 80
memory: 85
thresholds:
cpu: 30
memory: 30
name: LoadAware
plugins:
balance:
enabled:
- LoadAware
EOFpriorityThreshol注意测试的 Job 的 Pod 优先级需要符合这个配置才能观测到重新调度现象,要不然直接就略过了
metrics我填的是 prometheus 的 service 的标准地址
metrics:
address: "http://prometheus-server.kube-system.svc.cluster.local:80"
type: Prometheusc) descheduler 源码修改适配
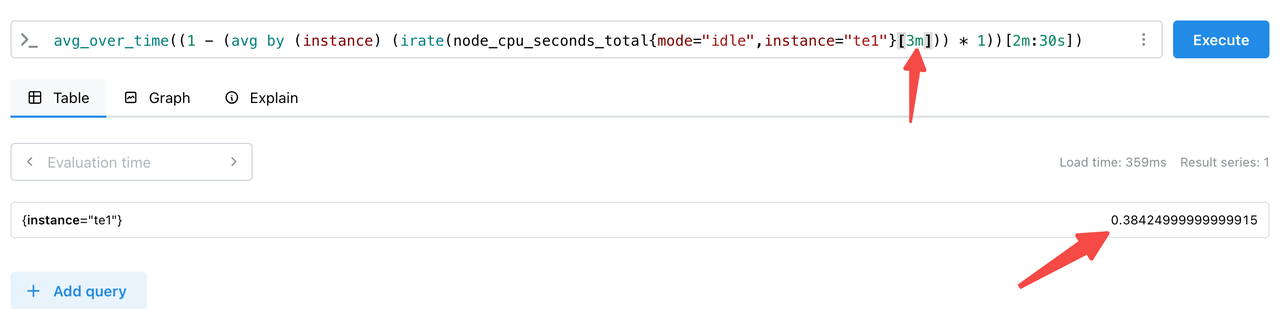
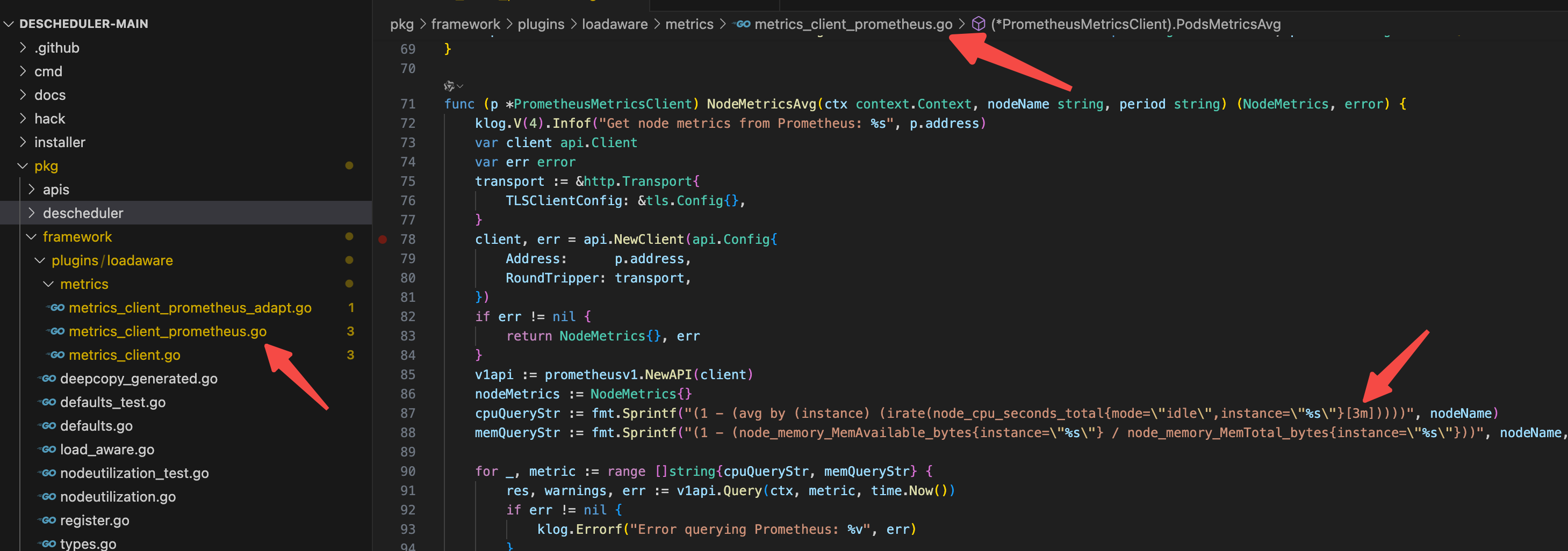
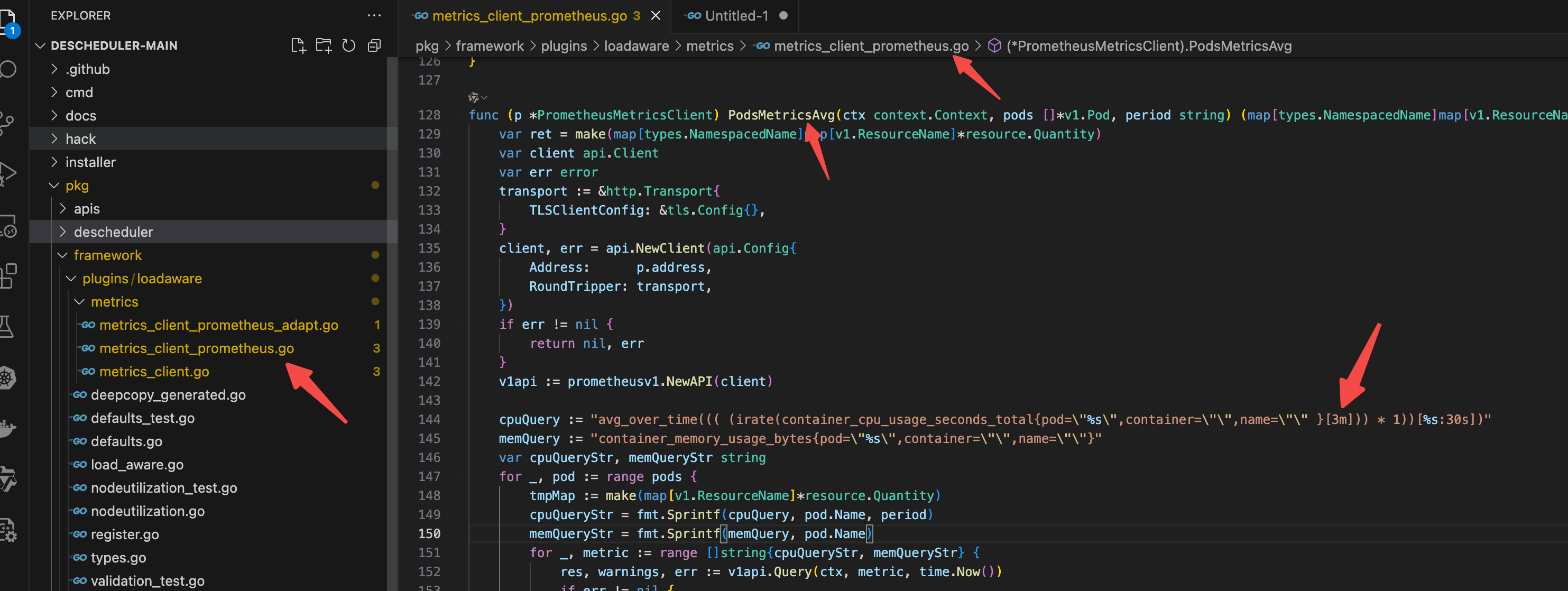
查询语句 不兼容 需要 将 3s 修改成 3m 改大一些。这个没办法语句硬编码到源代码里面了。无法通过配置修改
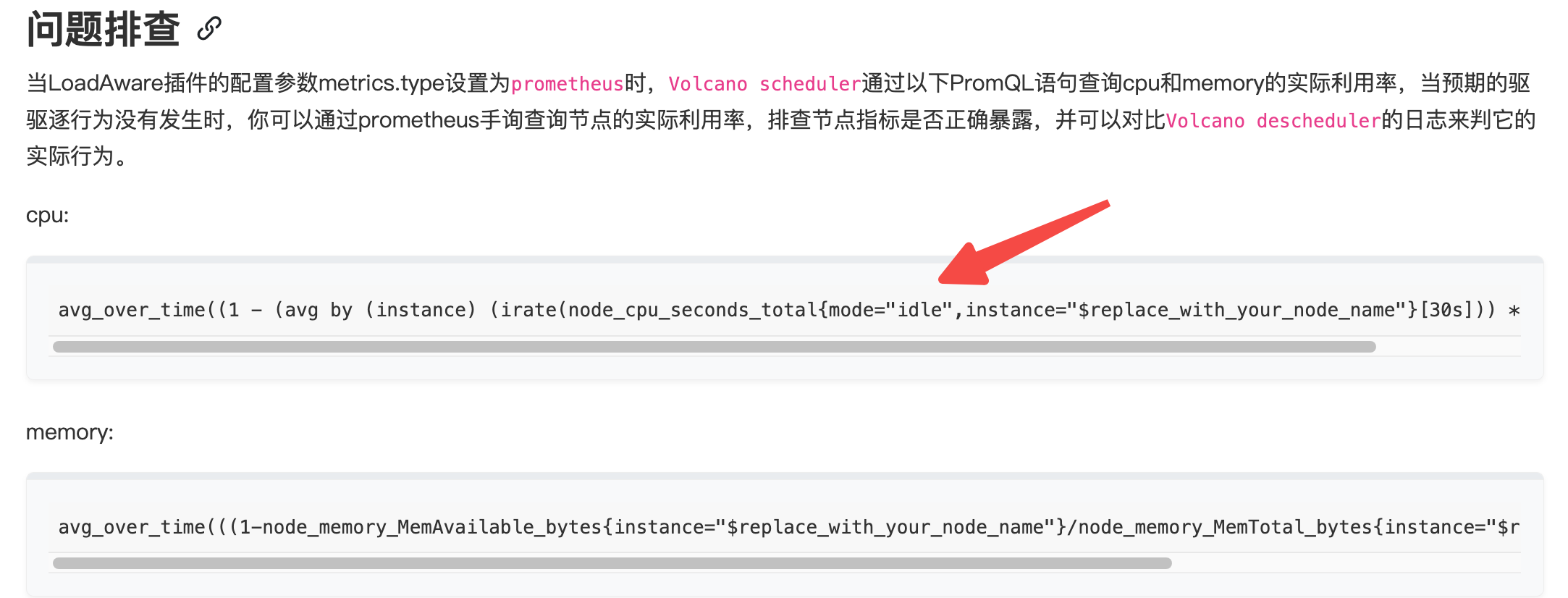
## 查询语句 不兼容 需要 将 3s 修改成 3m 改大一些
avg_over_time((1 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle",instance="$replace_with_your_node_name"}[30s])) * 1))[2m:30s])
开始改代码重新打包:
## 制作镜像
cd descheduler
make image

## 重新标记 然后推到阿里云个人仓库
docker tag volcanosh/vc-descheduler:393a2d822ce3946642e76a0e1b27539012280e32 \
registry.ap-southeast-5.aliyuncs.com/xxxx/vc-descheduler:v1.0.0
docker push registry.ap-southeast-5.aliyuncs.com/xxxx/vc-descheduler:v1.0.0
## 然后需要将个人仓库公开
修改descheduler的 deployment 的镜像到阿里云私有仓库地址重启就完事了
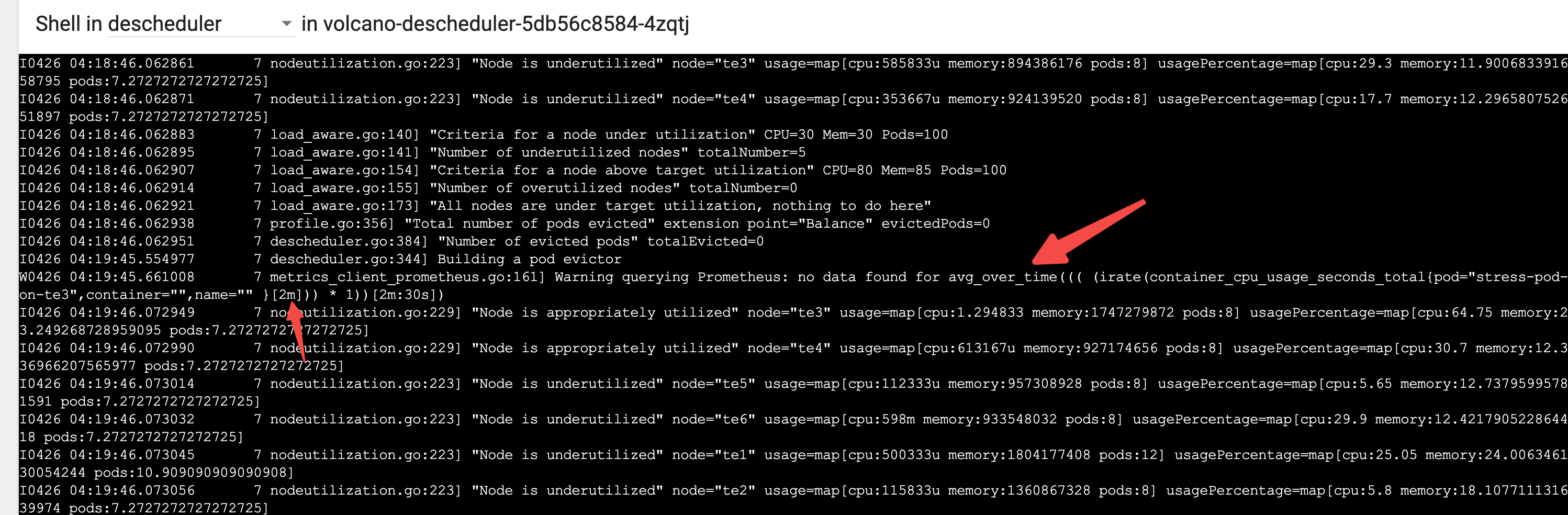
查看日志可以观察到确实生效了 修改的代码
d) 开始测试
注意先修改一下descheduler deployment 的 --descheduling-interval=10m。
方便观测默认值是 10 分钟重新调度一次。可以改成 1 分钟检测一次。
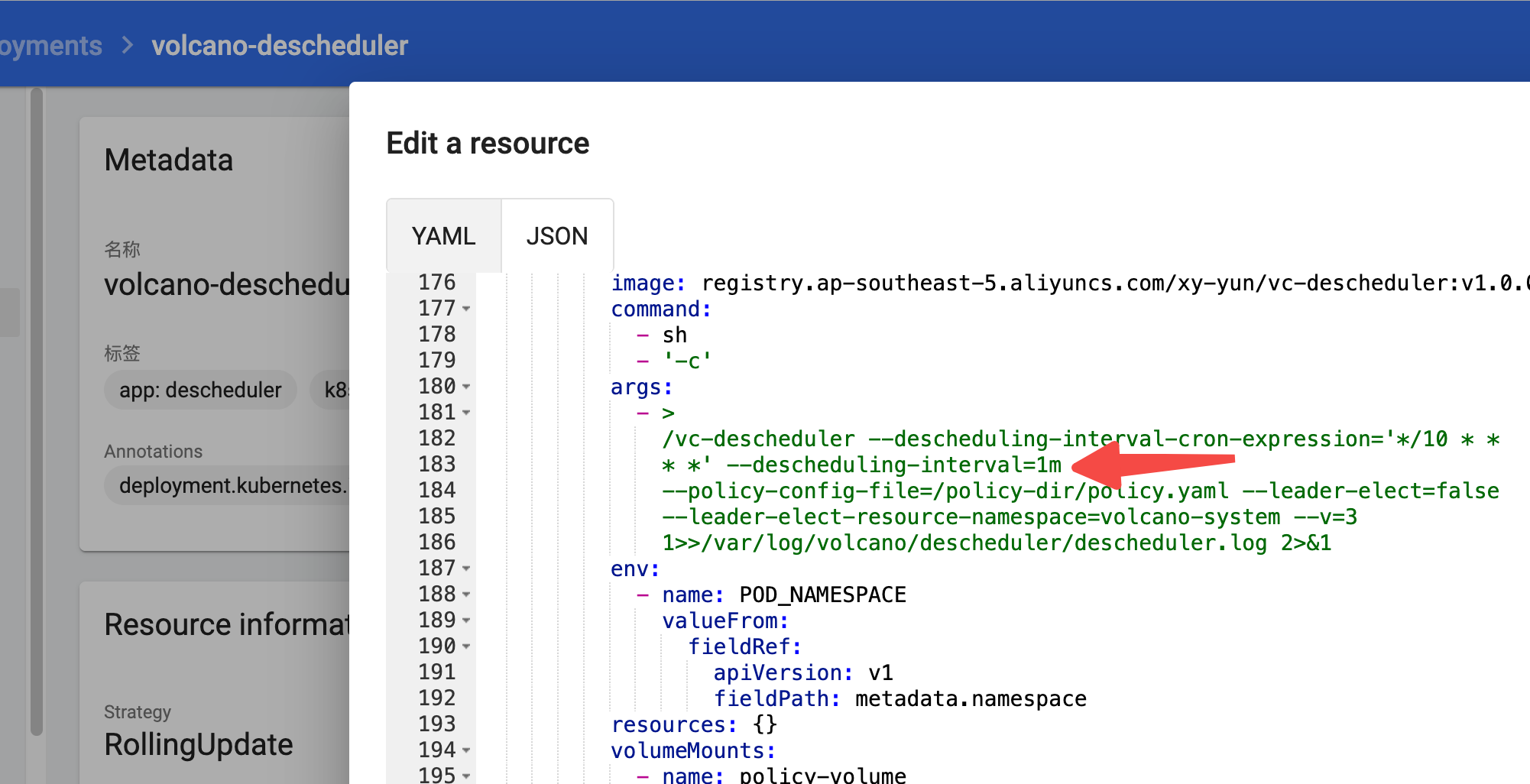
创建自定义优先级资源对象。千万注意要和前文priorityThreshol这个相符合。满足条件才会触发重新调度
cat <<EOF | kubectl apply -f -
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 1000
globalDefault: false
description: "Low priority tasks"
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "High priority tasks, can preempt low priority"
EOF创建低优先级Pod
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: low-priority-workload
annotations:
volcano.sh/preemptable: "true"
spec:
replicas: 3
selector:
matchLabels:
app: low-priority-app
template:
metadata:
labels:
app: low-priority-app
spec:
schedulerName: volcano
priorityClassName: low-priority
containers:
- name: workload-container
image: polinux/stress
command: ["stress"]
args:
- "--cpu"
- "1"
- "--timeout"
- "3600s"
resources:
requests:
cpu: "300m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
EOF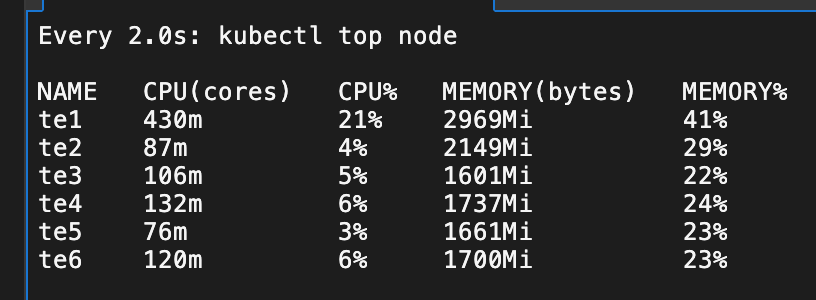

创建压测 Pod
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: stress-pod-on-te3
spec:
nodeSelector:
kubernetes.io/hostname: te3
containers:
- name: stress-container
image: polinux/stress
command: ["stress"]
args: ["--cpu", "2", "--vm", "1", "--vm-bytes", "1G", "--timeout", "600s"]
resources:
requests: { cpu: "1500m", memory: "1Gi" }
limits: { cpu: "2000m", memory: "1.5Gi" }
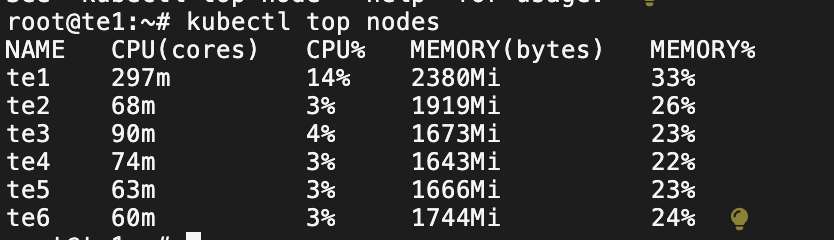
EOF可以观察到压力 Pod 和普通 Pod 都在 te3 上了

可以观察到压力 Pod开始发力,促使 te3 的负载非常高
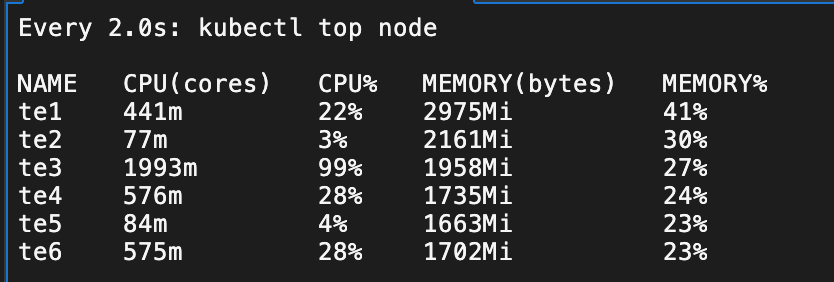
e) 观测结果
valcano-descheduler的日志显示 已经触发驱逐了 平衡了。
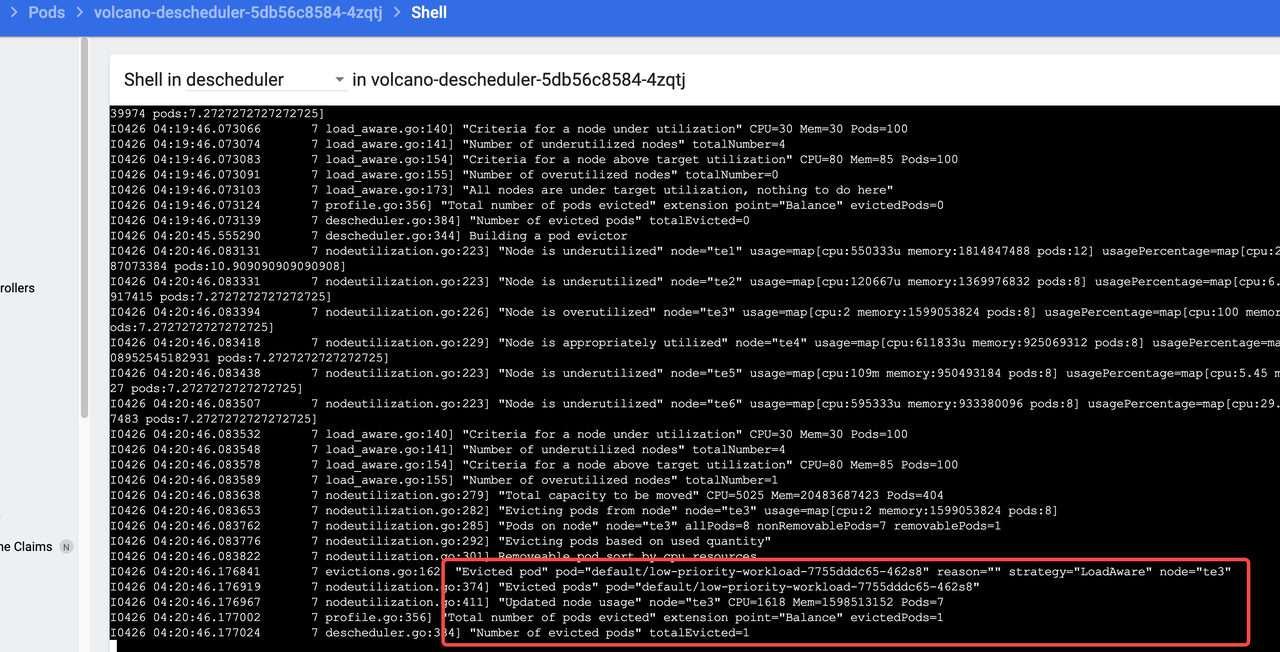
观察 te3 上的普通 Pod 被重新调度到 te5 了


4.3 多集群调度
4.4 离线混部调度
参考:
网络拓扑感知调度 | Volcano背景 在AI大模型训练场景中,模型并行(Model Parallelism)将模型分割到多个节点上,训练过程中这些节点需要频繁进行大量数据交互。![]() https://volcano.sh/zh/docs/network_topology_aware_scheduling/负载感知重调度 | Volcano背景 集群中的调度是将pending状态的Pod分配到节点运行的过程,Pod的调度依赖于集群中的调度器。调度器是通过一系列算法计算出Pod运行
https://volcano.sh/zh/docs/network_topology_aware_scheduling/负载感知重调度 | Volcano背景 集群中的调度是将pending状态的Pod分配到节点运行的过程,Pod的调度依赖于集群中的调度器。调度器是通过一系列算法计算出Pod运行![]() https://volcano.sh/zh/docs/descheduler/云原生混部 | Volcano背景 随着云原生技术的快速发展,越来越多的业务已逐渐迁移到Kubernetes,使用云原生化的方式进行开发维护,极大地简化了应用程序的部署、编
https://volcano.sh/zh/docs/descheduler/云原生混部 | Volcano背景 随着云原生技术的快速发展,越来越多的业务已逐渐迁移到Kubernetes,使用云原生化的方式进行开发维护,极大地简化了应用程序的部署、编![]() https://volcano.sh/zh/docs/colocation/队列资源管理 | Volcano功能概述 队列是Volcano的核心概念之一,用于支持多租户场景下的资源分配与任务调度。通过队列,用户可以实现多租资源分配、任务优先级控制、资
https://volcano.sh/zh/docs/colocation/队列资源管理 | Volcano功能概述 队列是Volcano的核心概念之一,用于支持多租户场景下的资源分配与任务调度。通过队列,用户可以实现多租资源分配、任务优先级控制、资![]() https://volcano.sh/zh/docs/queue_resource_management/多集群AI作业调度 | Volcano背景 随着企业业务的快速增长,单一Kubernetes集群往往无法满足大规模AI训练和推理任务的需求。用户通常需要管理多个Kubernetes
https://volcano.sh/zh/docs/queue_resource_management/多集群AI作业调度 | Volcano背景 随着企业业务的快速增长,单一Kubernetes集群往往无法满足大规模AI训练和推理任务的需求。用户通常需要管理多个Kubernetes![]() https://volcano.sh/zh/docs/multi_cluster_scheduling/
https://volcano.sh/zh/docs/multi_cluster_scheduling/

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)