苍穹外卖day09-问题与解决办法
过程:通过mapper找到的page,**能用page.getResult()得到数据order(list类型的),**然后再一个个提取出来,通过BeanUtils装到OrderVO里,再一个个add到orderVO的list里。细节:如果 id 是主键或具有唯一约束,通常不会有 NULL 值,因此 COUNT(id) 会统计所有符合条件的行。解决思路:对订单进行查询,分页查询也是查询,需要框定很
问题1:写用户端历史订单分页查询时,由于忽略了Api文档中,返回结果中包含OrderDetail这一项,将record中只包含了Order,缺少了OrderDetail,前端没有数据显示
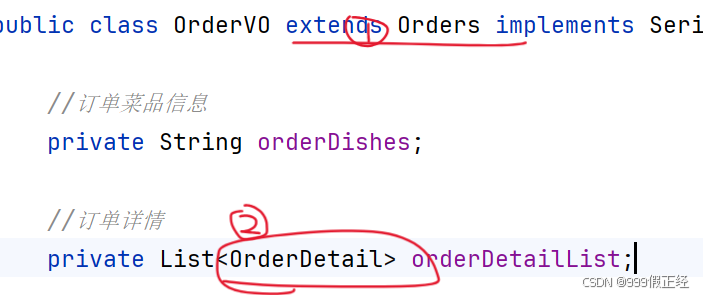
上述OrderVO不但包含了Order这一项,还包含了OrderDetail这一项.因此前端能够有数据显示
总结:注意返回数据的完整性,不要返回少的数据,影响前端正确显示
问题2:接口文档中只写了根据状态查,但标准答案的Mapper中写的查询条件多了很多
解决思路:对订单进行查询,分页查询也是查询,需要框定很多限制条件
比如1.要查找当前用户的订单
2.根据状态找,
3.根据电话号码模糊找,
4.根据订单号模糊找,
5.根据下单时间范围找
所以pageQuery中要传入一个OrdersDTO对象,这个对象中封装了这些限制条件
OrdersDTO ordersDTO = new OrdersDTO();
ordersDTO.setUserId(BaseContext.getCurrentId());
ordersDTO.setStatus(status);
Page<Orders> pageResult = ordersMapper.pageQuery(ordersDTO);
//确定的查询条件,放到ordersDTO中,模糊查询都是前端输入获得到的,这里不用传
问题3:先把查到的Order数据放到OrderVO中,再把查到的OrderDetail数据放到OrderVO中,再把完整的OrderVO数据放到List中.顺序要清晰
Order ----BeanUtils.copyProperties---->OrderVO
orderDetailList ----set---->OrderVO
OrderVO -----add------> List<OrderVO
BeanUtils.copyProperties(order,orderVO);
orderVO.setOrderDetailList(orderDetailList);
//用一个list把查到的一堆数据(OrderVO)装起来,要用add
records.add(orderVO);
4. Mapper.xml中 >= 和 <= 是什么
<!--<if test="beginTime != null">
and order_time >= #{beginTime}
</if>
<if test="endTime != null">
and order_time <= #{endTime}
</if>-->
/*'>':代表大于>*/
/*'<':代表小于*/
/*在XML文档里,大于号和小于号需要用转义符(就上面两个)代替*/
总结: 第一个是>= 第二个是<=
在XML文档里,大于号和小于号需要用转义符(就上面两个)代替
问题5:微信开发者工具,打开小程序之后一片空白
原因:微信开发者工具自动更新,导致基础库和不校验都被更改了,
解决方法:改成下图就能正确显示了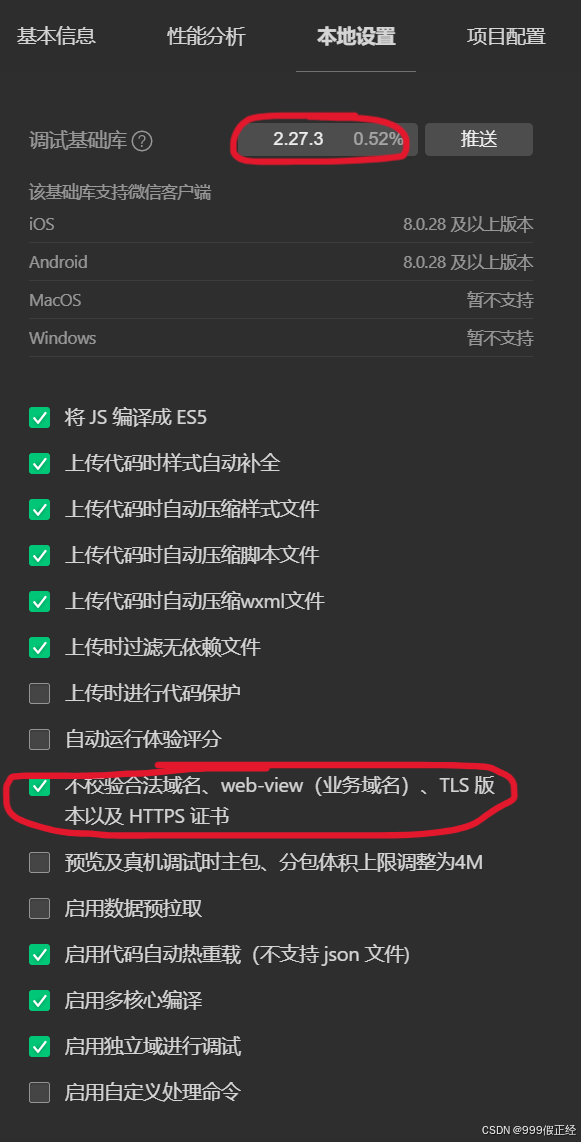
问题6:OrderVO需要分页查找找到的Order,还需要从OrderDetail表里找到订单里有哪些菜
List<Orders> ordersList = page.getResult();
for (Orders orders : ordersList) {
OrderVO orderVO = new OrderVO();
BeanUtils.copyProperties(orders,orderVO);
orderVO.setOrderDishes(getOrderDishes(orders.getId()));
result.add(orderVO);
过程:通过mapper找到的page,**能用page.getResult()得到数据order(list类型的),**然后再一个个提取出来,通过BeanUtils装到OrderVO里,再一个个add到orderVO的list里
问题7:SELECT COUNT(id) 和 SELECT COUNT(*) 有什么区别
在大多数情况下结果是相同的,但它们有一些细微的区别。以下是两者的具体区别:
- COUNT(id)
作用:统计 id 列中不为 NULL 的行数。
细节:如果 id 是主键或具有唯一约束,通常不会有 NULL 值,因此 COUNT(id) 会统计所有符合条件的行。如果 id 列允许 NULL 值,则 COUNT(id) 会忽略 NULL 值,只统计非 NULL 的行。
- COUNT(*)
作用:统计表中所有行的数量,无论列的值是否为 NULL。
细节:COUNT() 直接统计表中的行数,不关心具体列的值。即使某些列是 NULL,COUNT() 仍然会将这些行计入总数。
问题8:报错:Unknown column ‘rejectionReason’ in ‘field list’
<if test="cancelTime != null">
cancel_time = #{cancelTime},
</if>
<if test="rejectionReason != null">
rejectionReason = #{rejectionReason},错的
rejection_reason = #{rejectionReason},
</if>
解决方法:上方代码rejection_reason不能写成rejectionReason

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)