Meta提出Deep Think with Confidence:几乎啥都不用动,就能提升推理的准确性与效率
近年来,大型语言模型(LLMs)在复杂推理任务上表现惊人,尤其是在测试时生成多条推理链并通过“自一致性”(Self-Consistency)进行多数投票的策略,显著提升了答案的正确率。例如,在AIME25上,GPT-OSS-120B使用尾部置信度+Top10%过滤,达到了惊人的**99.9%**准确率,而普通投票为97.0%。: 对于一个新问题,先正常生成一小部分(如16条)完整的推理路径,计算它
近年来,大型语言模型(LLMs)在复杂推理任务上表现惊人,尤其是在测试时生成多条推理链并通过“自一致性”(Self-Consistency)进行多数投票的策略,显著提升了答案的正确率。然而,这种通常被称为“并行思考”的方法也带来了巨大的计算成本:每道题生成数百甚至上千条推理路径,token消耗量呈线性增长,在实际部署中几乎不可持续。更糟糕的是,随着生成路径的增加,性能提升会逐渐饱和甚至下降,传统投票法却对所有路径一视同仁,无法区分高质量和低质量的推理。

-
论文:Deep Think with Confidence
-
链接:https://arxiv.org/pdf/2508.15260
正是在这样的背景下,Meta AI与UCSD的研究团队提出了Deep Think with Confidence(DeepConf)——一种简单却强大的方法,能够在测试阶段动态识别并过滤低置信度的推理路径,从而在不增加训练成本、不调整超参数的前提下,同时提升推理的准确性与效率。本文将对这一方法进行全面解读,揭示其如何通过“置信度”这一内在信号,实现更智能、更高效的推理聚合。
为什么需要“带置信度的深度思考”?
传统的自一致性方法虽然有效,但有两大痛点:
-
计算开销巨大:例如,在AIME 2025数学竞赛题上,使用Qwen3-8B模型将准确率从68%提升至82%,需要额外生成511条推理路径,消耗上亿token。
-
收益递减:生成更多路径并不总能带来性能提升,有时反而会引入噪声,因为低质量路径也可能“带偏”投票结果。
以往也有一些工作尝试用“全局置信度”(例如整条推理路径的平均置信度)来筛选路径,但这种方法有两个缺陷:
-
掩盖局部错误:整条路径的平均值可能掩盖中间某几步的严重不确定性或错误。
-
无法提前终止:必须生成完整路径才能计算置信度,无法在生成过程中及时止损。
DeepConf的动机正是要解决这些问题:利用更细粒度的、局部的置信度信号,在生成过程中或生成后动态过滤低质量路径,从而实现高效且准确的推理。
DeepConf如何工作?
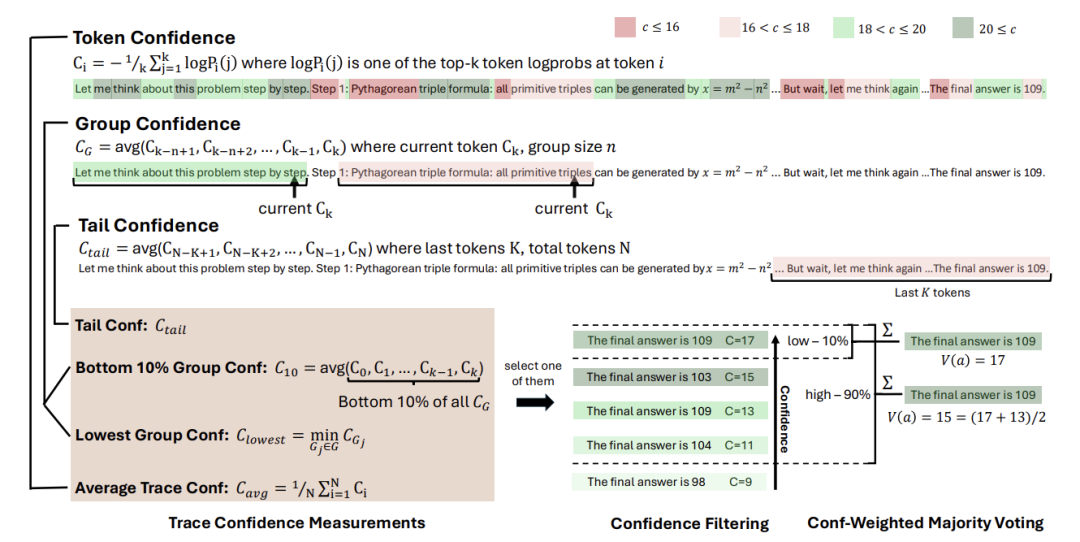
一、置信度指标的设计与理解
DeepConf的核心在于一系列创新的置信度度量方式,它们从不同角度捕捉推理路径的质量。
1. Token级指标:
-
Token熵(Token Entropy):衡量模型对下一个词的不确定性。熵越低,模型越确信。
其中 是第i个位置第j个词的概率。
-
Token置信度(Token Confidence):作者定义为前k个候选词的平均负对数概率:
注意:这里置信度越高,数值反而越低(因为取负号),但论文中实际使用时会更关注相对值——数值低代表置信度高。
2. 轨迹级指标:
-
平均轨迹置信度(Average Trace Confidence):整条路径所有token置信度的平均值。虽然常用,但容易掩盖局部错误。
3. 创新指标(关键贡献):
-
组置信度(Group Confidence):将轨迹分成长度固定的重叠窗口(如每1024个token一组),计算每组内的平均置信度。这提供了更平滑的局部信号。
-
底部10%组置信度(Bottom-10% Group Confidence):取所有组中置信度最低的10%组的平均值。这能捕捉推理中最薄弱、最不确定的环节。
-
最低组置信度(Lowest Group Confidence):所有组中置信度最低的那一组的置信度值。这是最极端的局部质量指标,非常适合在线生成中做提前终止的判断。
-
尾部置信度(Tail Confidence):只计算轨迹最后固定数量token(如2048个)的平均置信度。因为推理的结尾部分(得出答案的关键步骤)的质量至关重要。

二、离线推理模式
离线模式下,所有推理路径均已生成完毕,DeepConf通过以下两种策略提升多数投票的效果:
-
置信度加权投票(Confidence-Weighted Majority Voting): 不再“一人一票”,而是每条路径的投票权重与其置信度成正比。高置信度的路径对最终结果有更大影响力。
-
置信度过滤(Confidence Filtering): 在进行加权投票之前,先根据置信度分数过滤掉一部分路径。论文主要尝试了两种过滤比例:
-
Top 10% :只保留置信度最高的10%的路径。激进策略,力求精度,但若模型对错误答案过于自信,可能翻车。
-
Top 90% :保留置信度最高的90%的路径。保守策略,在保持多样性的同时过滤掉最差的10%,稳定可靠。
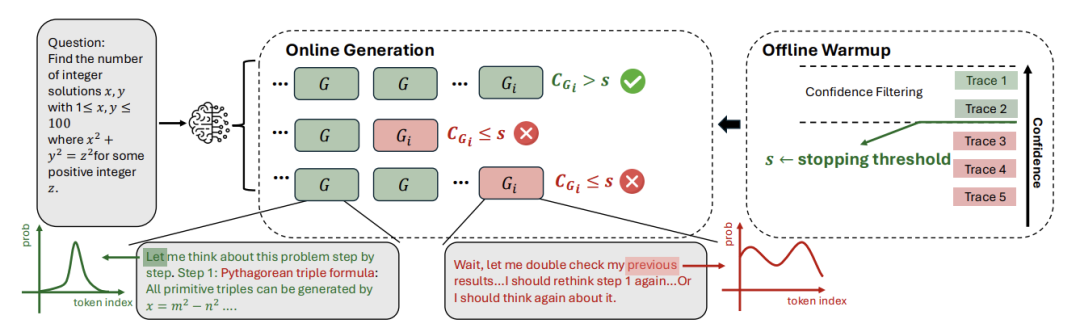
三、在线推理模式
在线模式的目标是在生成过程中实时判断路径质量,并提前终止那些“注定失败”的路径,以节省计算资源。其核心是最低组置信度指标。
在线DeepConf分为两个步骤:
-
离线预热(Offline Warmup): 对于一个新问题,先正常生成一小部分(如16条)完整的推理路径,计算它们的最低组置信度,然后根据设定的保留比例η(10%或90%),确定一个停止阈值s。例如,DeepConf-low(η=10%)会将阈值s设为预热集中置信度前10%的路径的最低值。
-
自适应采样(Adaptive Sampling): 开始大规模生成路径。每生成一个token组(如2048个token),就计算当前组置信度。
-
如果当前值低于阈值s,立即终止该路径。
-
同时,每完成一条路径,就检查当前所有已生成路径的答案共识度是否超过某个阈值τ(如95%)。如果已达成共识,则停止生成,直接输出结果。
这种方法确保了在线过程近似地复现了离线过滤的效果,同时避免了大量不必要的token生成。
DeepConf效果如何?
实验设置
-
模型:涵盖了不同规模的先进开源模型,如DeepSeek-8B, Qwen3-8B/32B, GPT-OSS-20B/120B。
-
基准:多个高难度数学推理数据集,如AIME 2024/2025, HMMT 2025, BRUMO 2025, 以及GPQA-Diamond。
-
基线:标准的自一致性+多数投票(Cons@K)、以及单条路径精度(Pass@1)。
-
评估:所有结果均在64次独立运行上取平均,同时汇报准确率和生成的总token数。
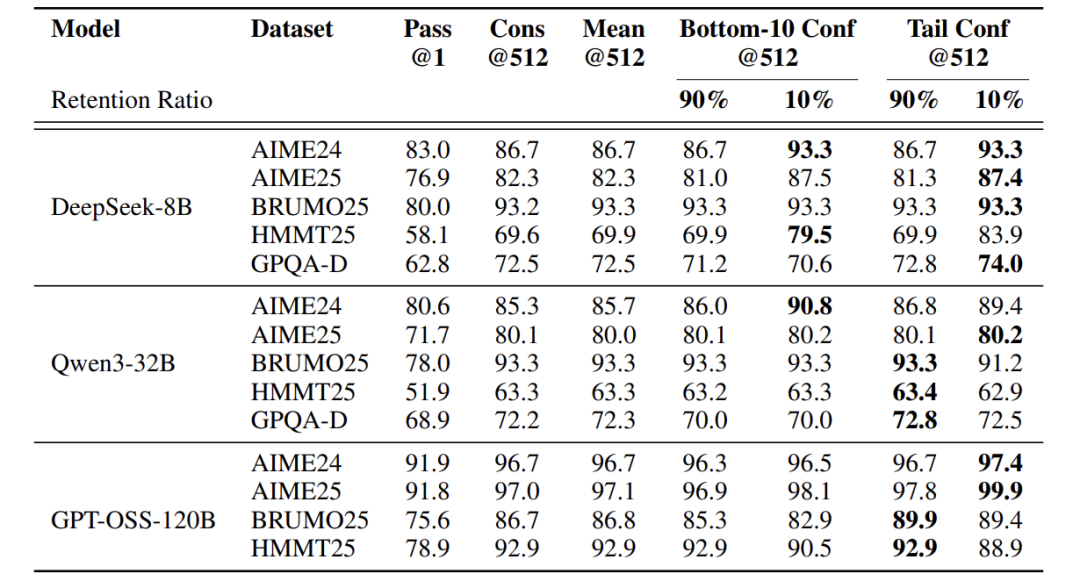
离线评估结果
关键发现:
-
置信度加权+过滤几乎全面优于普通投票。例如,在AIME25上,GPT-OSS-120B使用尾部置信度+Top10%过滤,达到了惊人的**99.9%**准确率,而普通投票为97.0%。
-
Top10%过滤策略通常带来最大提升,但也存在因模型“自信地犯错”而导致性能下降的风险(如GPT-OSS-120B在部分数据集上)。
-
Top90%过滤是一个非常安全的选择,几乎总能匹配或略微超过普通投票的精度,同时为后续过滤奠定了基础。
-
局部置信度信号(尾部和底部)整体表现不逊于甚至优于全局平均信号,证实了关注局部质量的必要性。

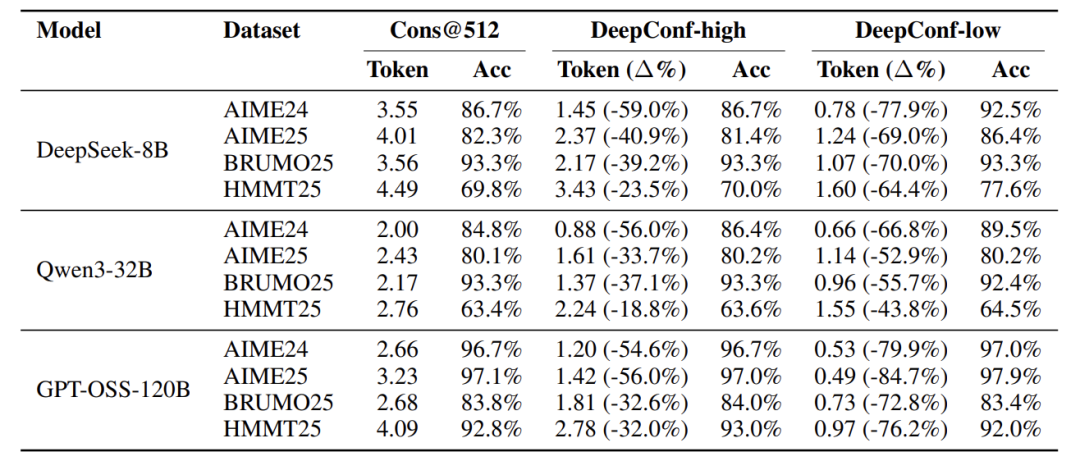
在线评估结果
关键发现:
-
惊人的效率提升:DeepConf-low平均减少了**43-84%的token消耗,最高可达84.7%**(GPT-OSS-120B on AIME25)。
-
精度保持甚至提升:在大多数情况下,DeepConf在大幅节省token的同时,准确率与基线相当或更高。例如,DeepSeek-8B在AIME24上节省77.9%的token,准确率反而提升了5.8%。
-
两种模式的权衡:DeepConf-low(η=10%)追求极致效率,但偶尔会因过滤过于激进导致精度小幅下降;DeepConf-high(η=90%)则更为稳健,以较小的效率提升(节省18-59%token)牢牢守住精度底线。


结论
DeepConf通过巧妙地利用大语言模型内部的置信度信号,为解决测试时推理的“成本-收益”难题提供了一个优雅而有效的解决方案。它证明了并非所有生成路径都是平等的,也证明了关注推理过程的局部质量远比只关注最终答案更重要。这项研究不仅显著提升了先进模型的推理效率,更重要的是,它为未来构建更加“自知之明”、资源高效的人工智能系统指明了方向——让AI学会在思考时衡量自己的把握,从而更聪明地分配计算资源。



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)