ChatTTS部署(2025年最新部署)
ubuntu22.04.5(可联网)有一点点linux基础,按照这个办法是绝对可以部署成功的,而且不会报错。
ChatTTS部署(2025最新部署办法)
环境:
ubuntu22.04.5(可联网)
有一点点linux基础,按照这个办法是绝对可以部署成功的,而且不会报错
操作步骤:
Conda安装
安装conda(已安装,或者不想使用conda的可以直接跳过):
安装步骤参考文档:
https://www.anaconda.com/docs/getting-started/miniconda/install#linux-terminal-installer
根据官网给出的一键安装脚本直接wget下来安装运行
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && chmod +x Miniconda3-latest-Linux-x86_64.sh
脚本执行后先回车,然后输入yes接受许可.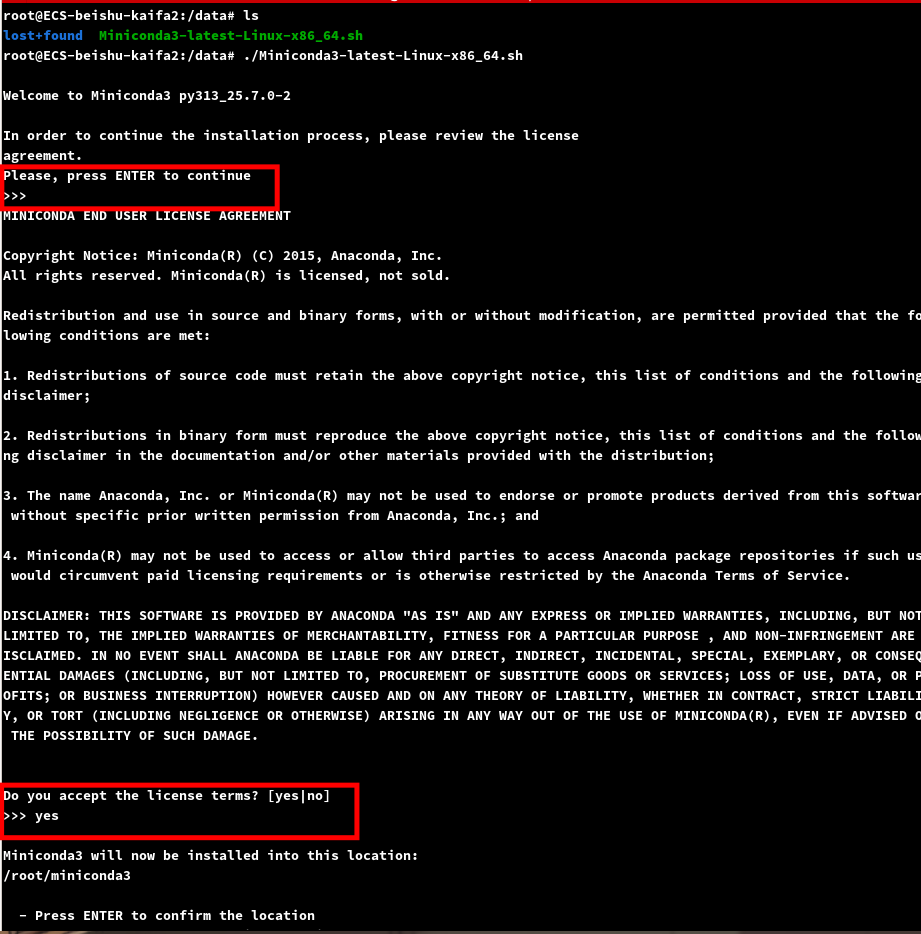
下面有需要的话就指定一下目录,要输入【绝对路径】,如果不要更改直接回车即可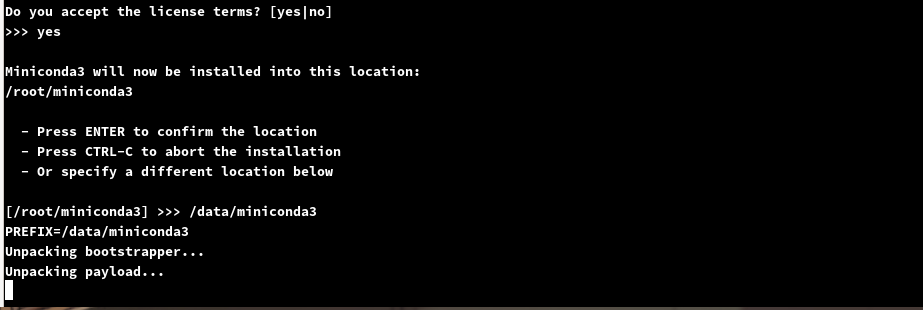
等待安装完成后会问你要不要初始化,输入yes即可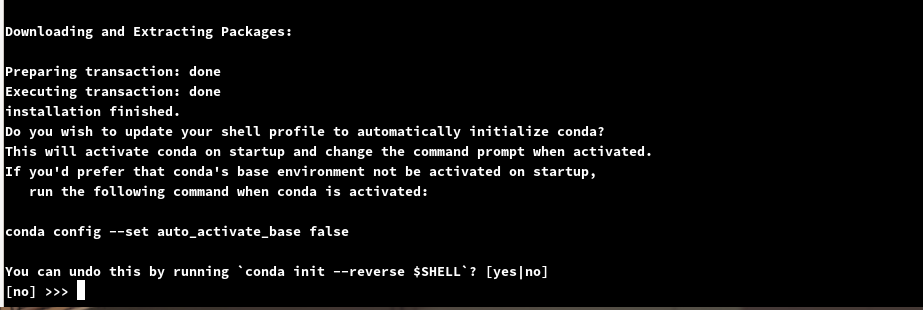
完成安装后,输入source ~/.bashrc命令,导入一下环境变量,现在进入conda的base基础环境中.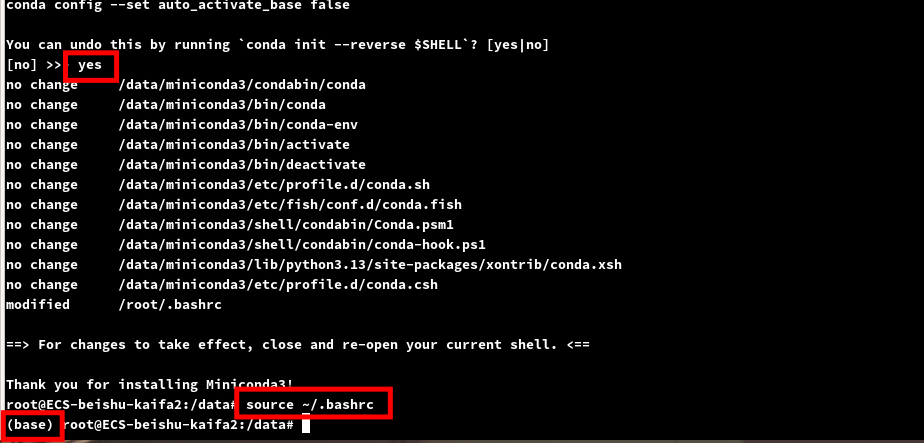
自此conda环境准备完成
ChatTTS部署
这个步骤根据github给出的安装步骤即可:
https://github.com/2noise/ChatTTS/blob/main/docs/cn/README.md
首先克隆文件到本地
git clone https://github.com/2noise/ChatTTS
我这边云主机连不上github,本地下载了然后上传了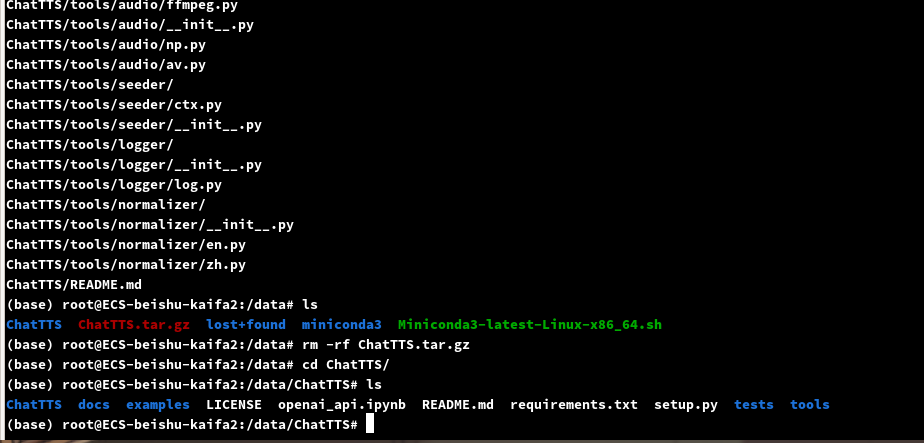
conda创建环境
conda create -n chattts python=3.11
conda activate chattts
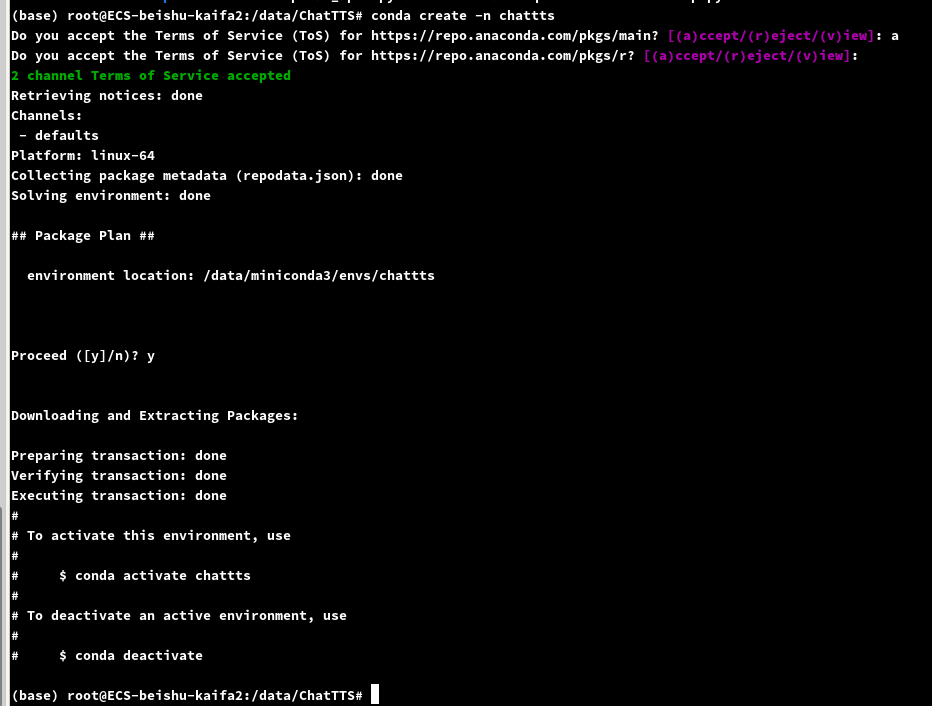
环境创建完成后激活一下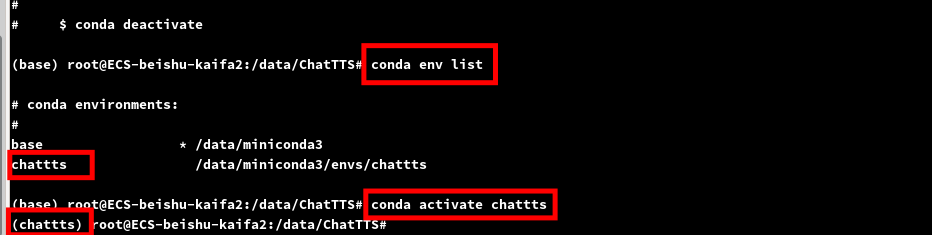
创建完成后,在进行依赖安装前要修改一下依赖文件,不然会有个坑点
修改项目目录下的requirements.txt依赖文件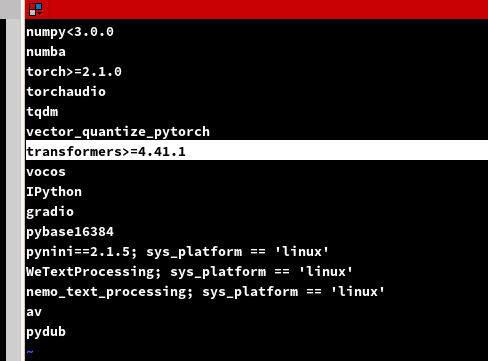
因为transformers版本的需求只是大于4.41.1版本,pip会直接下载最新的版本,就会导致报错:
https://github.com/2noise/ChatTTS/issues/955
如果版本过新,后面模型安装完成在调用的时候,音频生成会报错,输入问题.
解决方式仅需要将transformers版本降级即可
我们就可以在依赖安装的时候就指定好transformers版本,使其不会报错.
修改transformers==4.53.2即可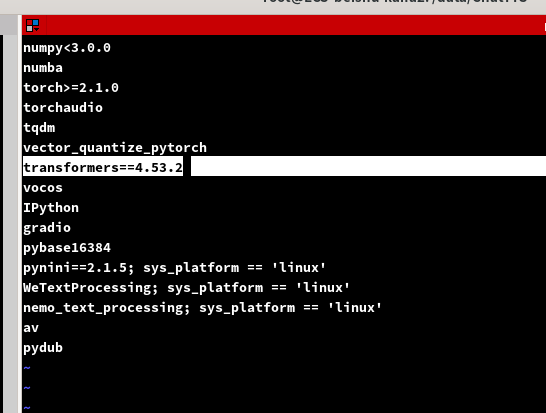
然后就可以开始pip install -r requirements.txt安装依赖了,我这边因为默认缓存的根目录没有空间了,所以指定了别的路径,正常不需要后面的–cache-dir
下载太慢了,临时指定一下清华源
等待依赖下载完成后,暂时先不要启动,因为模型要去huggingface下载,没挂梯子是跑不了的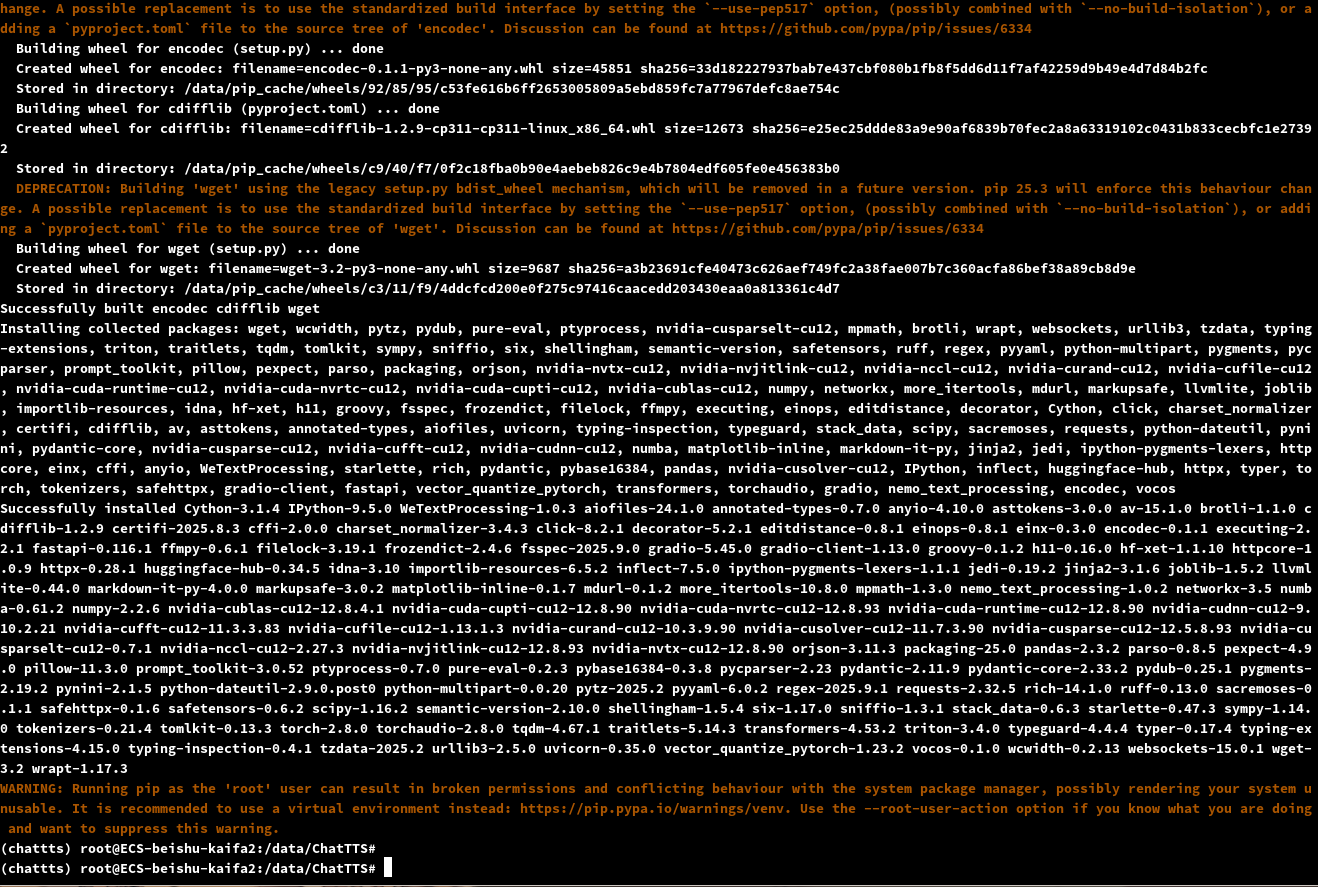
模型下载
使用替代方法,去魔塔社区下载:
https://www.modelscope.cn/models/AI-ModelScope/ChatTTS/files
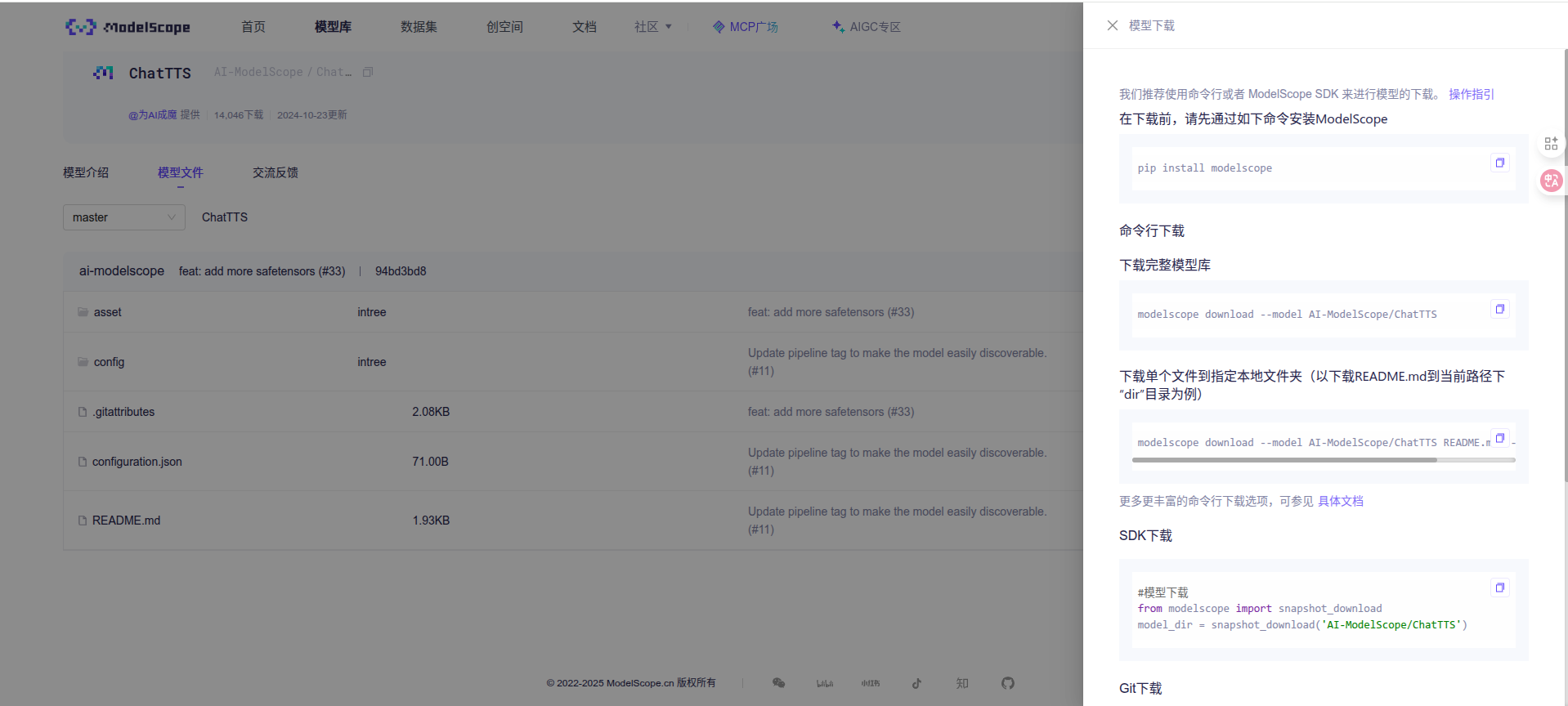
点击模型下载是有给出下载步骤的
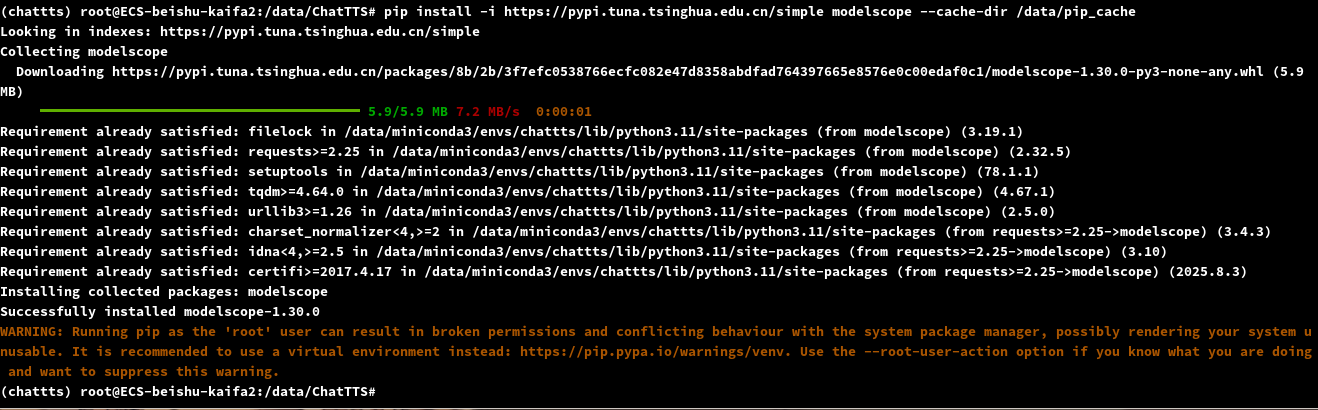
先安装modelscope
pip install modelscope
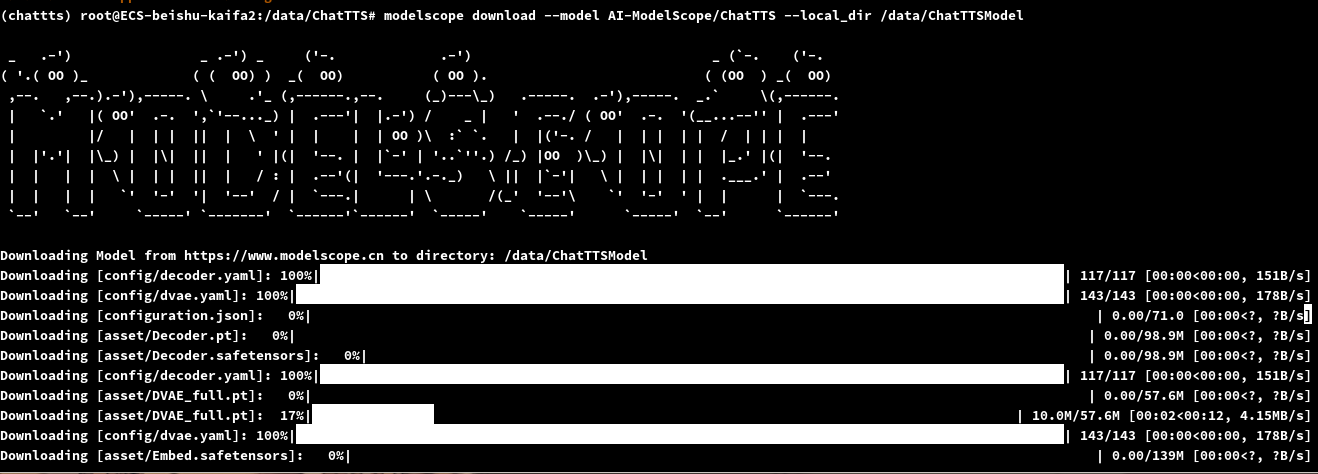
下载模型到指定位置,不指定的话他就下载到root的缓存目录下了
modelscope download --model AI-ModelScope/ChatTTS --local_dir /data/ChatTTSModel
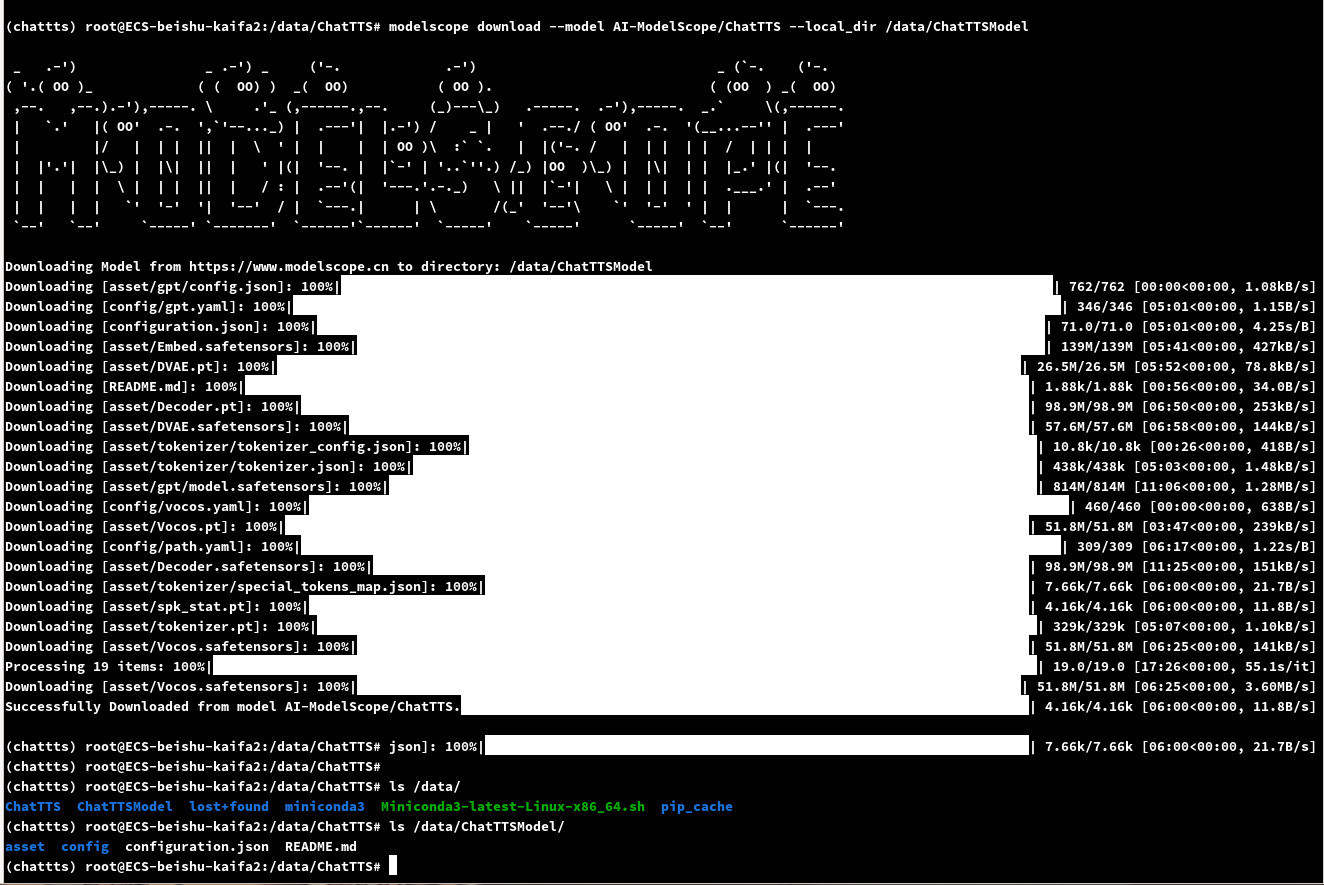
服务启动
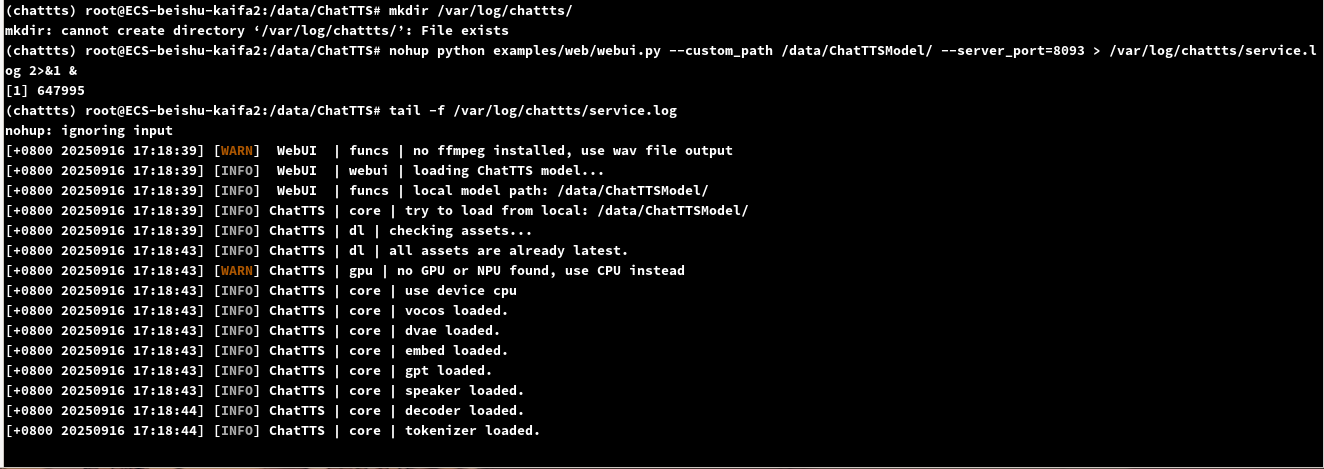
先新建一个日志目录
mkdir /var/log/chattts/
启动webui图形界面
nohup python examples/web/webui.py --custom_path /data/ChatTTSModel/ --server_port=8093 > /var/log/chattts/service.log 2>&1 &
完成后访问http://127.0.0.1:8093,就可以看到web页面了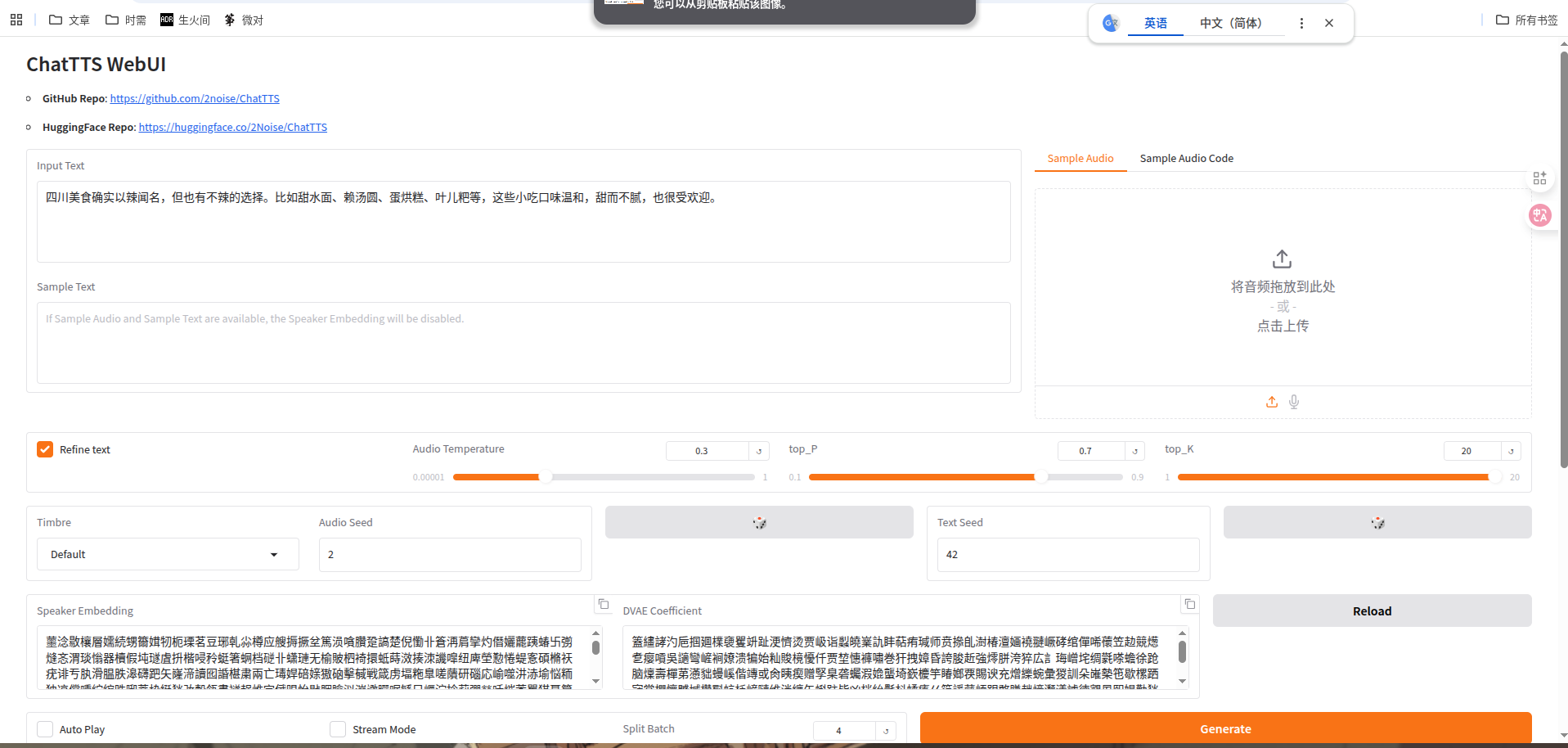
生成一段语音看看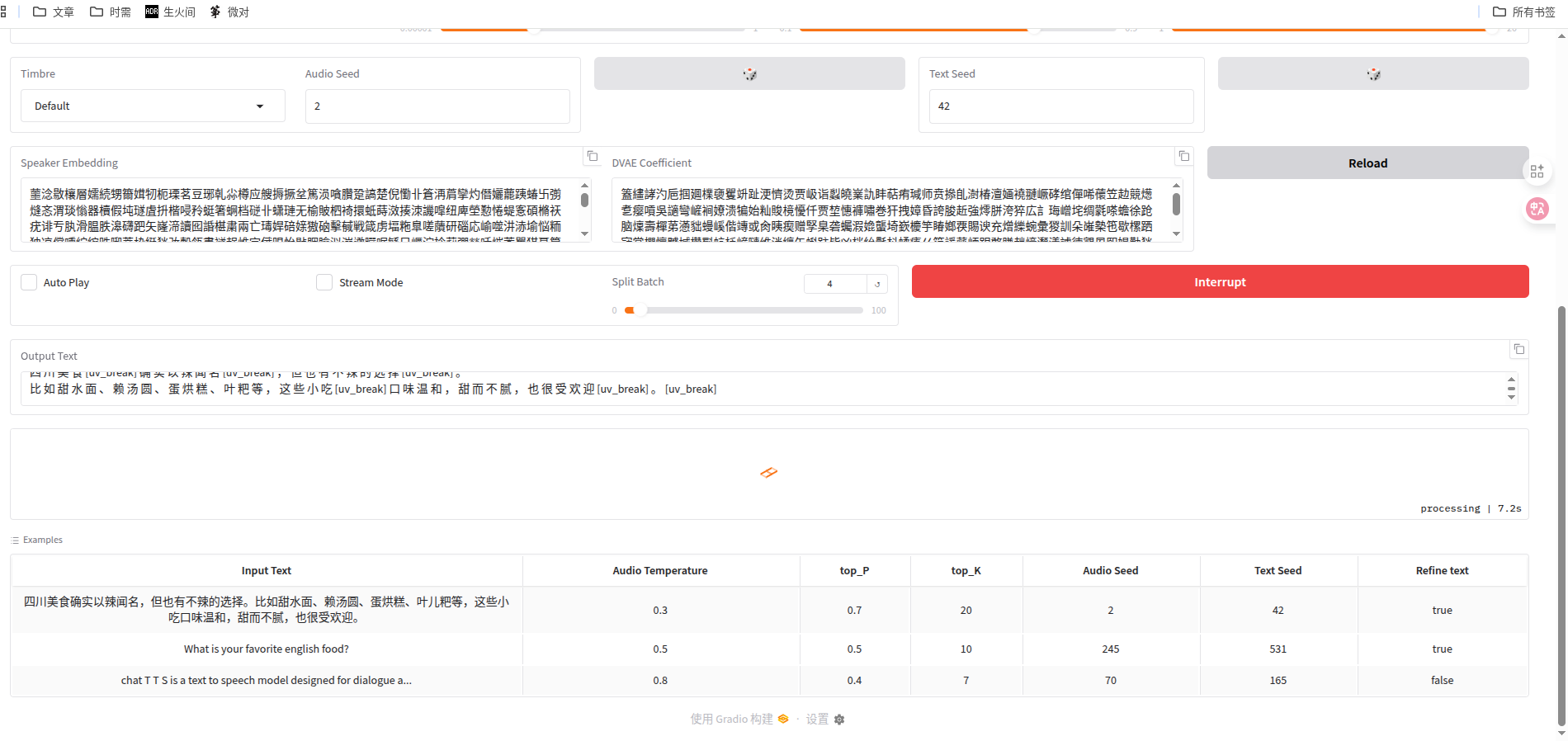
查看日志可以看到是有在跑的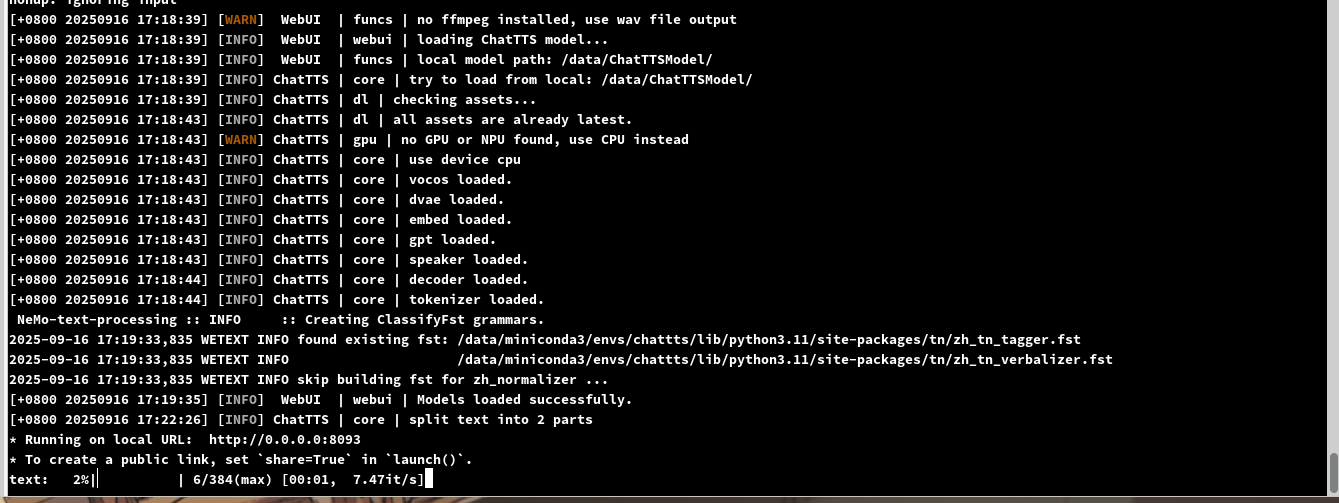
有人给出的按钮提示,下图为参照,不过我现在这个版本看不到有下载的按钮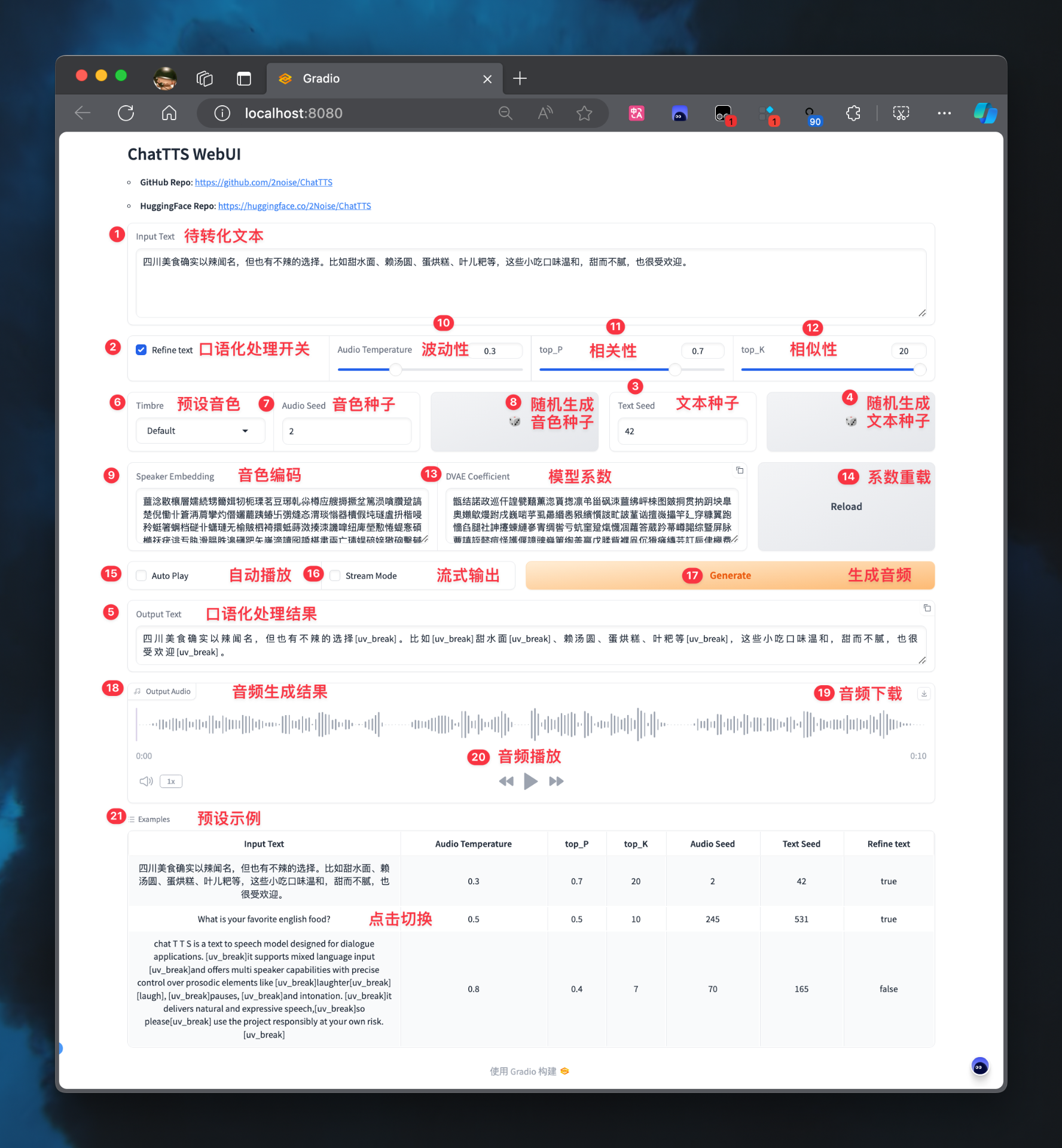
启动api接口
首先修改api的python文件,把模型启动制定到本地模型
找到开始的这段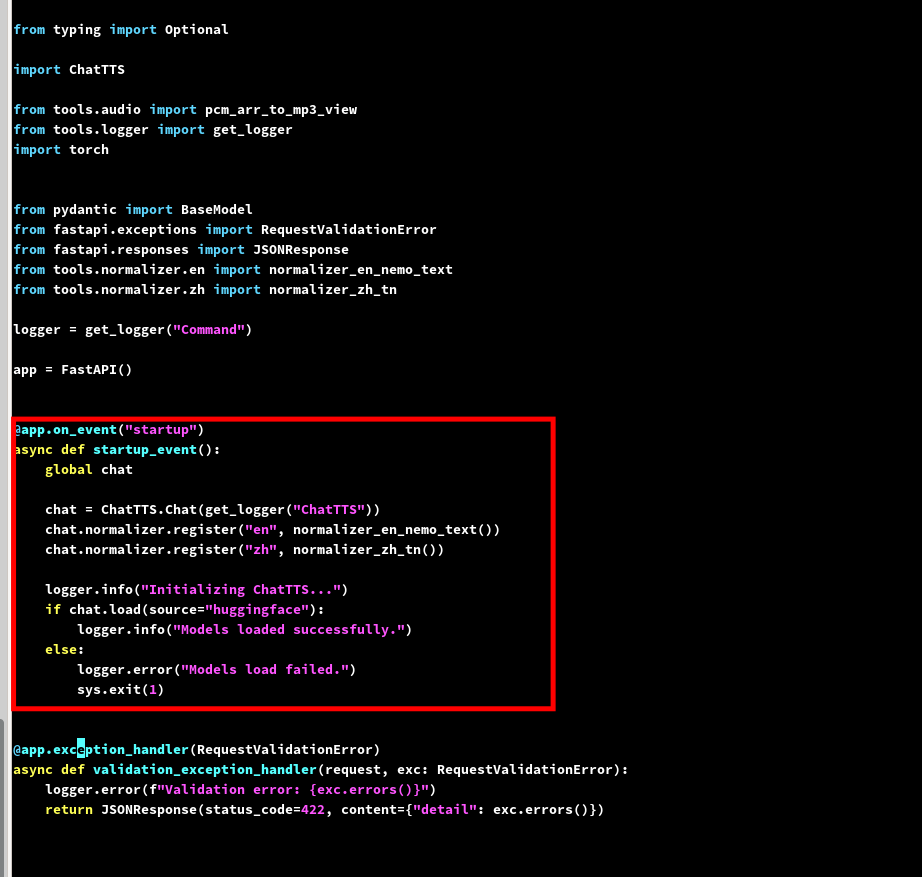
修改为下面这样,gpu加速选项可选,前面两个该了就行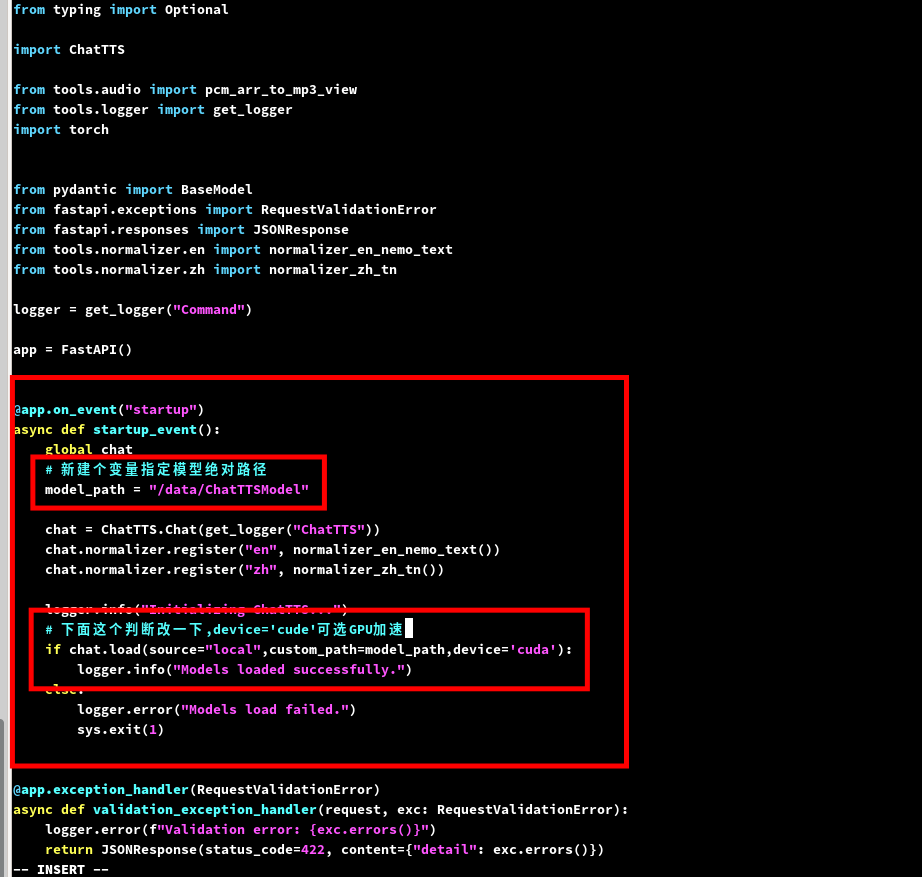
启动api接口文件
uvicorn examples.api.main:app --host 0.0.0.0 --port 8094 --reload > /var/log/chattts/api_service.log 2>&1 &
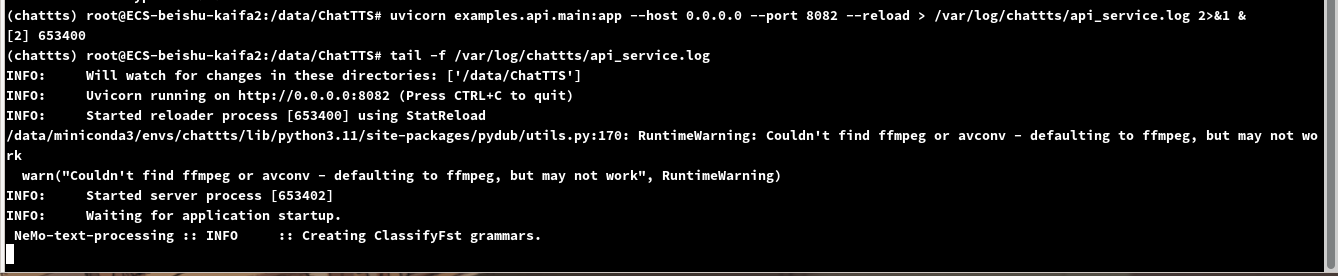
可以看到起来了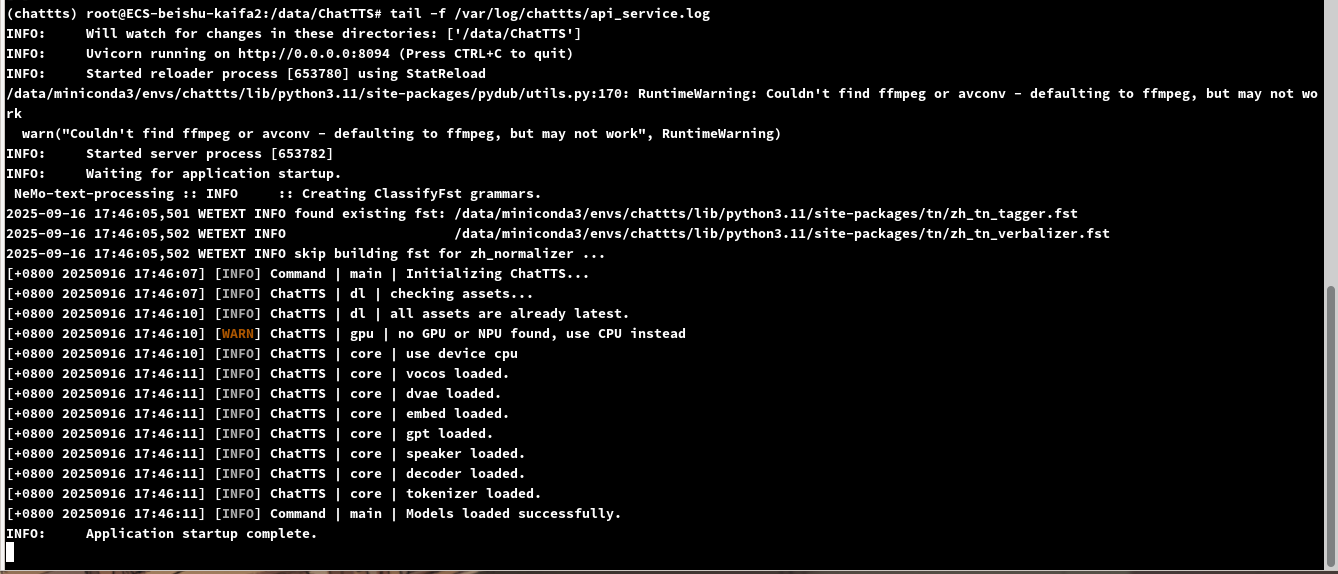
测试一下
curl -X POST http://127.0.0.1:8094/generate_voice --header 'Content-Type: application/json' --data-raw '{"text":"你好"}'

使用curl生成一个,下面为参考
curl -X POST "http://localhost:8094/generate_voice" \
-H "Content-Type: application/json" \
-d '{
"text": [
"75年前,中国人民志愿军肩负着人民的重托、民族的期望,高举保卫和平、反抗侵略的正义旗帜,雄赳赳、气昂昂,跨过鸭绿江,同朝鲜军民一道浴血奋战,历经2年零9个月取得了抗美援朝战争的伟大胜利。祖国和人民不会忘记,19万7千多名中华英雄儿女献出了宝贵生命,他们永远是最可爱的人。"
],
"stream": false,
"lang": null,
"skip_refine_text": true,
"refine_text_only": false,
"use_decoder": true,
"audio_seed": 12345678,
"text_seed": 87654321,
"do_text_normalization": true,
"do_homophone_replacement": false,
"params_refine_text": {
"prompt": "",
"top_P": 0.7,
"top_K": 20,
"temperature": 0.7,
"repetition_penalty": 1,
"max_new_token": 384,
"min_new_token": 0,
"show_tqdm": true,
"ensure_non_empty": true,
"stream_batch": 24
},
"params_infer_code": {
"prompt": "[speed_5]",
"top_P": 0.1,
"top_K": 20,
"temperature": 0.3,
"repetition_penalty": 1.05,
"max_new_token": 2048,
"min_new_token": 0,
"show_tqdm": true,
"ensure_non_empty": true,
"stream_batch": true,
"spk_emb": null
}
}' --output 1.mp3
需要等待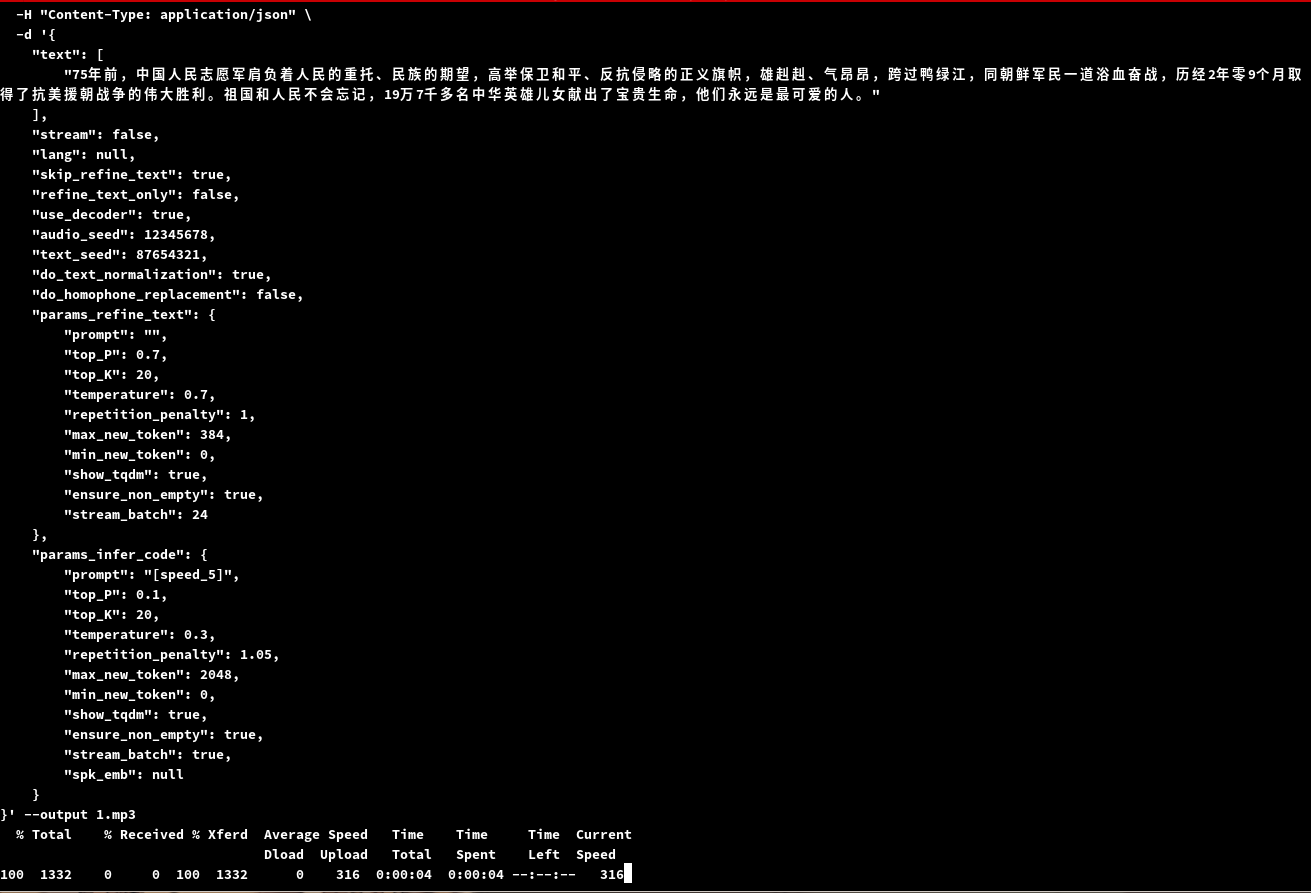
这边我就不听了,已经实验过好几次了,自己验证即可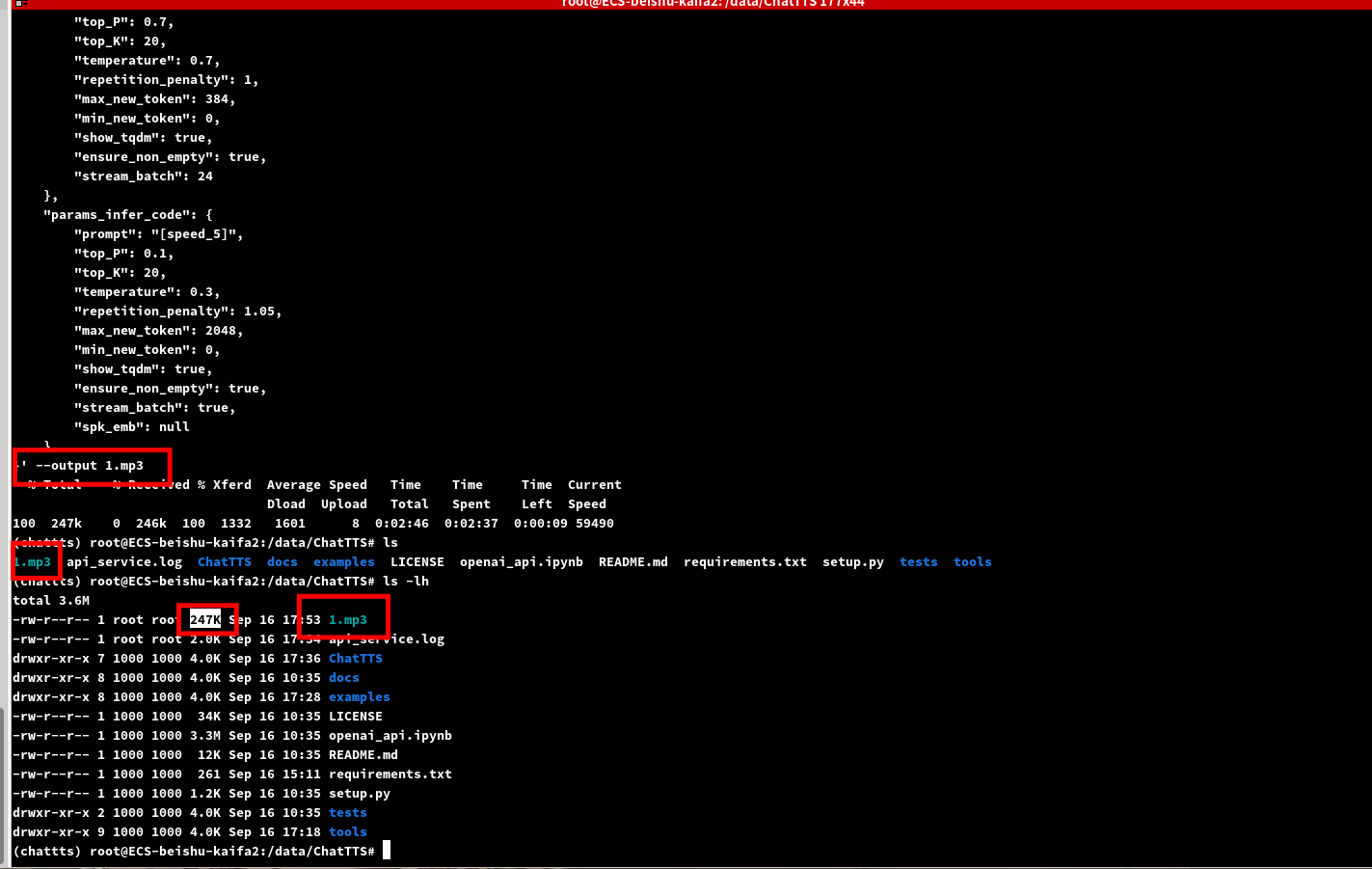
也可以根据官方自己的api目录下的client.py文件来作为参考,修改地址和端口,直接python执行就行了,就不做实验了,自己去代码调用吧。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)