基于FunASR实现的可区分说话人的录音转写系统
摘要:本文介绍了一个基于FunASR开发的智能语音转写系统,能够同时实现语音识别和说话人区分功能。系统支持在有无显卡环境下部署(推荐NVIDIA显卡),具备用户隔离、声纹注册、热词自定义、结果修正等特性,其中声纹注册和管理员审批确保了系统安全性。测试显示在3090Ti显卡上19分钟音频处理时间不足1分钟。系统适用于会议录音、访谈等场景,结合大模型还能实现内容摘要功能。项目已在B站发布演示视频,支持
1. 研究背景
在电话录音,会议录音,访谈录音等情景中都需要把语音信号转为文本文字,也就是使用ASR技术。但是我在对电话录音,会议录音,访谈录音处理的时候我们还需要明确哪句话是谁将的,这就需要使用声纹比对技术,同时结合这两个技术,就可以很好的解决目前中存在的录音转写不知道谁说话的问题,同时还可以结合当下流行的大模型对每个讲话人讲的内容进行概要总结。因此,很有必要写一个可以区分说话人和语音识别的系统。
2. 搭建环境
该项目支持在有显卡或者无显卡的机器上搭建,推荐使用带显卡的机器,这里的机器可以是普通的PC电脑,也可以是Linux服务器,不过这里演示,我使用的是Linux。显卡只能使用英伟达的显卡,至于是否可以使用国产显卡,可以到FunASR代码仓库中查阅资料。我这里使用的是3090Ti显卡,显存24GB,推理速度很快,这里使用19分半的音频测试,不到1分钟就可以返回结果。
3. 项目功能
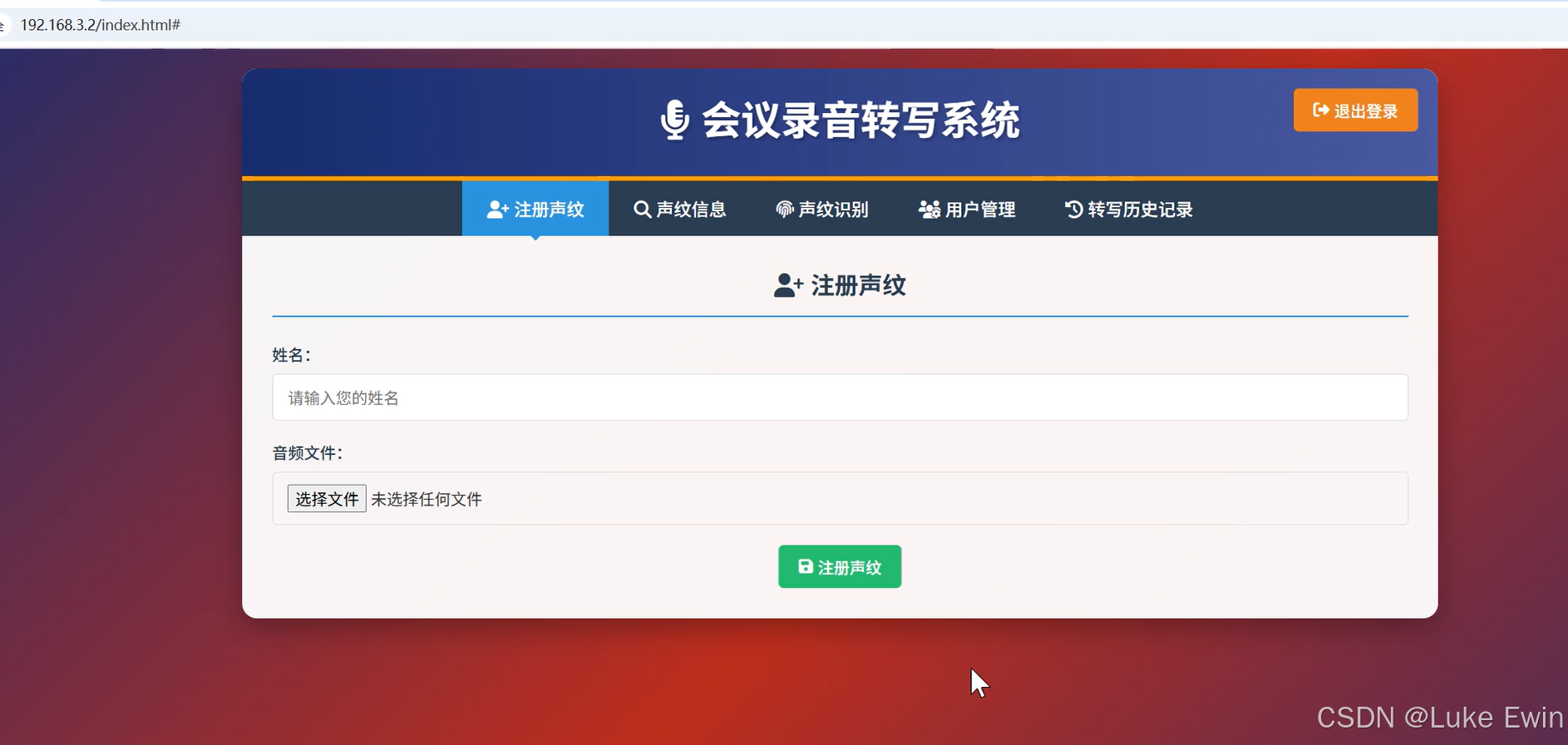
- 支持区分用户,不同的用户登录进来,每个用户的转写记录是相互隔离的;
- 支持注册声纹,可以先把要识别的人物的声纹注册到系统中,并且只能由管理员注册,普通用户,只能使用已注册的声纹信息。
- 支持自定义热词,包含客户端热词和服务端热词,其中服务端热词是全部用户共享的,而客户端热词只针对当前请求有效,每个客户端热词通过“|”进行分隔开,服务端中的每个热词通过写入到一个hotwords.txt文件中,每个热词一行。
- 支持修正模型结果,其中对于说话人的结果,可以开启全局替换来替换全局中的当前说话人标识,也可以只替换当前说话人,还可以修正文字。
- 支持管理员对普通用户的管理,当新用户注册进来时,先要经过管理员的同意才能登录到系统中。
4. 视频演示
具体动态效果,可以看我的下面录制的视频
基于FunASR开发的会议录音转写系统 | 可区分说话人的录音转写系统 | 可内网部署的录音转写系统
5. 联系
博客
公众号:编程分享录
B站:编程分享录

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)