SAM 3分割一切,支持文本和图像提示
这是一个统一模型,它能基于概念提示 (concept prompts) 在图像和视频中检测、分割和跟踪物体。SA-Co基准包含SA-Co/Gold(由三位标注者标注,用于测量人类表现)、SA-Co/Silver(一位标注者)、SA-Co/Bronze和SA-Co/Bio(现有数据集),以及用于视频的SA-Co/VEval。3. SAM 3 在图像和视频 PCS 任务上取得了显著的性能提升,较现有系

向AI转型的程序员都关注公众号 机器学习AI算法工程
三行摘要
1. SAM 3 提出了一种统一模型,通过名词短语或图像示例等概念提示,实现图像和视频中物体的检测、分割及跟踪,即概念可提示分割 (PCS)任务。
2. 该模型采用了分离识别与定位的“存在头 ”架构,其视觉骨干在图像检测器和基于记忆的视频跟踪器之间共享,并通过一个结合人工与AI的循环数据引擎构建了包含数百万概念标签的高质量数据集。
3. SAM 3 在图像和视频 PCS 任务上取得了显著的性能提升,较现有系统实现了2倍的增益,并改进了SAM系列在交互式视觉分割方面的能力,同时开源了模型及新的SA-Co基准 。
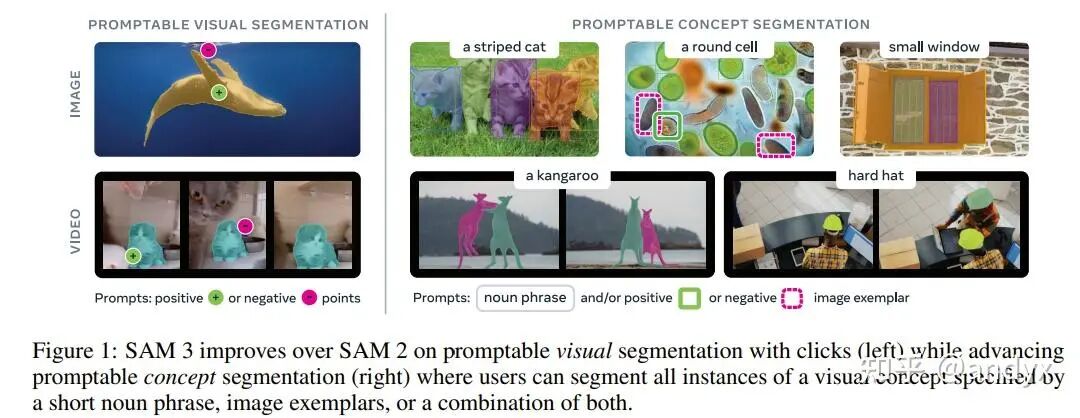
我们提出了 Segment Anything Model (SAM) 3,这是一个统一模型,它能基于概念提示 (concept prompts) 在图像和视频中检测、分割和跟踪物体。概念提示可定义为简短的名词短语 (noun phrases)(例如,“yellow school bus”)、图像示例 (image exemplars),或两者的组合。可提示概念分割 (Promptable Concept Segmentation, PCS) 接受此类提示并返回所有匹配对象实例的分割掩码和唯一身份。为推进 PCS,我们构建了一个可扩展的数据引擎,生成了一个包含 400 万个独特概念标签的高质量数据集,其中包含图像和视频中的困难负例 (hard negatives)。我们的模型由一个视觉主干 (vision backbone) 组成,该主干由图像级检测器 (image-level detector) 和基于记忆的视频跟踪器 (memory-based video tracker) 共享。识别和定位通过一个存在头 (presence head) 解耦,这显著提高了检测准确性。SAM 3 在图像和视频 PCS 方面比现有系统实现了 2 倍的增益 (2x gain),并改进了先前 SAM 在交互式视觉分割任务 (interactive visual segmentation tasks) 中的能力。我们开源了 SAM 3 及其新的 Segment Anything with Concepts (SA-Co) 基准 (benchmark)。
核心贡献:
- 提出PCS任务和SA-Co基准:
论文形式化了PCS任务,即输入文本和/或图像示例,预测所有匹配概念的物体实例的分割掩码和唯一身份,并在视频帧中保持物体身份。为此,作者构建了Segment Anything with Concepts (SA-Co) 基准,包含了400万个独特的概念标签和5200万个掩码,规模远超现有数据集。
- 解耦识别与定位的架构:
SAM 3在SAM 2的基础上进行了扩展,支持PCS任务,同时保留了PVS(Promptable Visual Segmentation)能力。其核心架构包括一个共享视觉骨干(Perception Encoder, PE)、一个图像级检测器(Detector)和一个基于内存的视频追踪器(Tracker)。
- 高效高质量的人工-AI协同数据引擎:
论文开发了一个可扩展的数据引擎,能够生成高质量、多样化的图像和视频训练数据。该引擎创新性地体现在三个方面:媒体来源多样化、利用本体和多模态大语言模型(MLLMs)生成名词短语和难负例来丰富标签多样性与难度、通过微调MLLMs作为“AI验证器”将标注吞吐量提高了一倍,使其达到接近人类的性能。
核心方法:
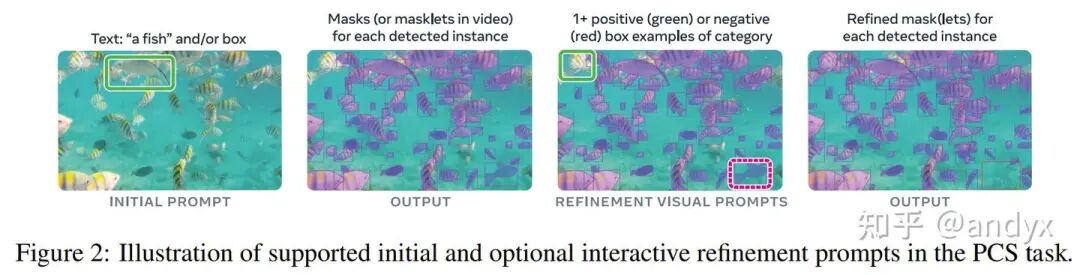
1. PCS任务定义: 任务目标是给定图像或短视频和由短文本短语、图像示例或两者组合指定的视觉概念,检测、分割并追踪该概念的所有实例。文本提示(名词短语)对所有帧全局有效,而图像示例可在单个帧上作为正或负边界框提供,以迭代细化目标掩码。论文特别指出,由于其开放词汇性质,PCS任务本质上是模糊的,模型在数据收集、指标设计和建模阶段都考虑了这些模糊性。
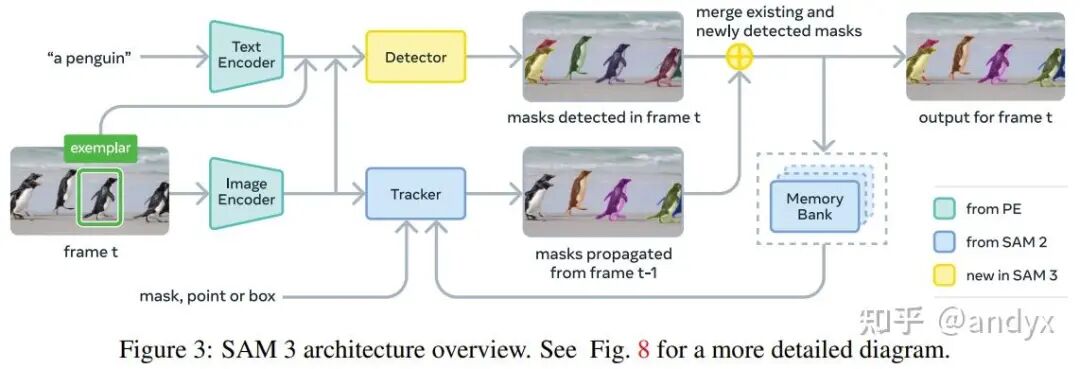
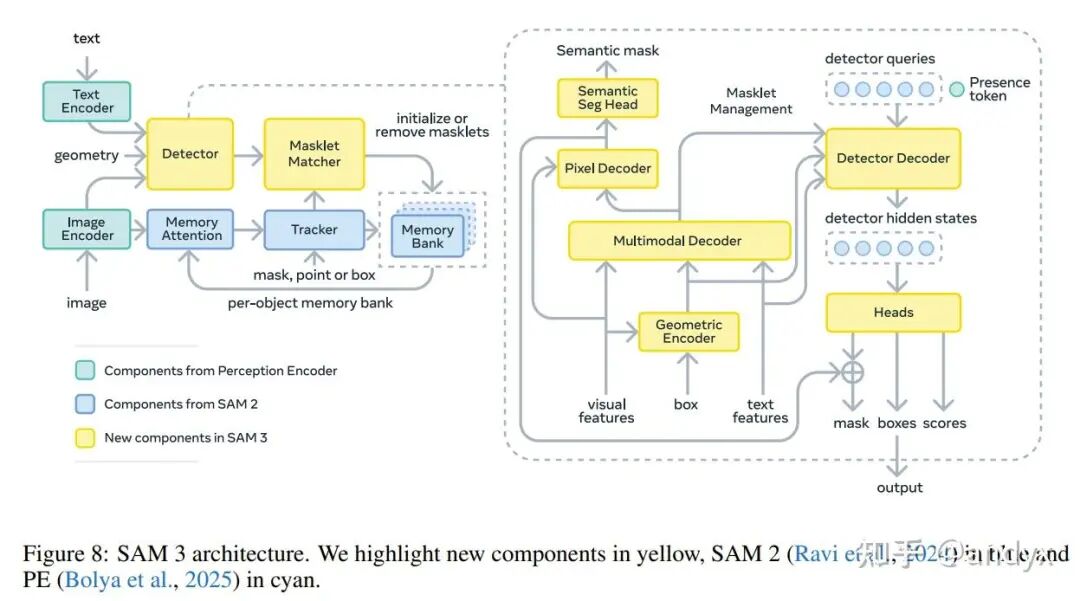
2. 模型架构(SAM 3): SAM 3采用DETR (Detection Transformer)范式,包含一个双编码器-解码器 Transformer。
- 共享视觉骨干 (PE):
图像和文本编码器是基于Perception Encoder (PE) 训练的Transformer,PE通过对比视觉语言训练在大规模图像-文本对上进行预训练。视觉编码器采用分窗注意力(windowed attention)和局部层中的全局注意力,并结合RoPE(Rotary Positional Embedding)和分窗绝对位置嵌入。
- 检测器 (Detector):
-
- 输入编码:
图像和文本提示由PE编码。图像示例(如果有)由一个单独的示例编码器(exemplar encoder)编码,它将位置、标签嵌入和ROI池化后的视觉特征进行处理。这些共同构成“提示tokens”。
- 融合编码器 (Fusion Encoder):
接收来自图像编码器的未条件化嵌入,并通过对提示tokens进行交叉注意力来对其进行条件化。
- 解码器 (Decoder):
DETR-like的解码器包含学习到的物体查询(object queries),它们对提示tokens和条件化后的图像嵌入进行交叉注意力。每个物体查询预测一个分类logit(指示是否匹配提示)和边界框偏移量,并使用Box-region-positional bias辅助注意力。
- 存在头 (Presence Head):
这是论文引入的关键组件,用于解耦识别(what)和定位(where)。它引入一个学习到的全局“存在token”(presence token),专门预测目标概念是否存在于图像/帧中,即 。每个物体查询 只需解决定位问题 。最终的物体得分是其自身得分与存在得分的乘积。
- 掩码头 (Mask Head) 和语义分割头:
掩码头改编自MaskFormer ,用于实例分割。另外还有一个语义分割头,预测每个像素是否对应提示的二值标签。
- 歧义头 (Ambiguity Head):
为解决开放词汇概念固有的多重解释问题,模型增加了一个歧义头。它是一个专家混合(mixture of experts)模型,并行训练K个专家,并采用winner-takes-all的方式,只对产生最低损失的专家进行监督,从而使每个专家专注于一种解释。推理时,一个分类头预测哪个专家最可能正确。
- 输入编码:
- 追踪器 (Tracker) 和视频架构:
-
-
追踪器利用检测器在视频中检测并追踪与提示对应的物体。在每帧,检测器发现新物体 ,追踪器将前一帧的掩码 传播到当前帧的 。
- SAM 2风格的传播:
对第一帧检测到的每个物体初始化一个掩码。后续帧中,追踪器模块基于前一帧位置预测已追踪物体的新掩码位置,这类似于SAM 2中的视频物体分割任务。追踪器共享检测器的PE骨干,并包含提示编码器、掩码解码器、内存编码器和内存库。
- 匹配与更新:
传播后的掩码 与当前帧的检测 通过简单的IoU匹配函数进行关联,并加入到当前帧的 中。未匹配的新检测物体会生成新的掩码。
- 时间消歧策略:
引入掩码检测得分(Masklet Detection Score, MDS)来衡量掩码在时间窗口内与检测结果匹配的一致性,低于阈值则抑制。此外,通过定期使用高置信度的检测掩码 重新提示追踪器,以解决遮挡或干扰物导致的追踪失败,确保内存库具有最新可靠的参考。
-
- 实例细化:
SAM 3允许用户通过正负点击来细化单个掩码,调整后的掩码随后传播到整个视频。
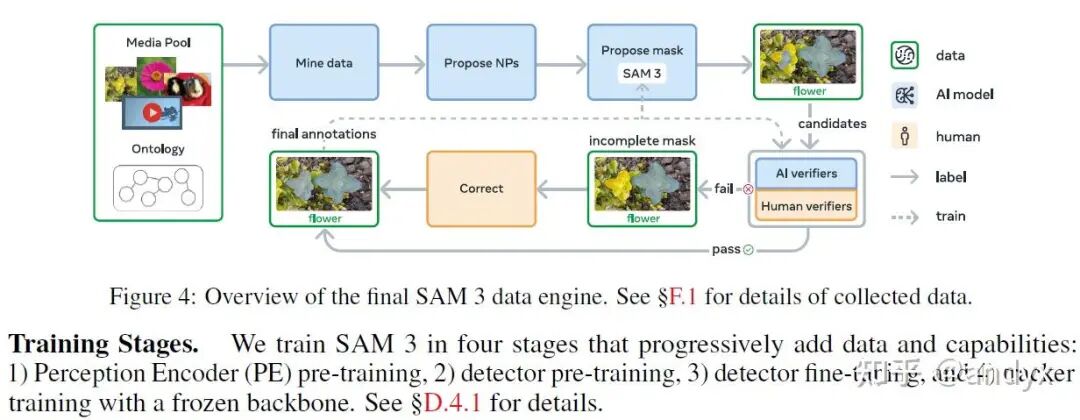

3. 数据引擎: 数据引擎通过SAM 3、人工标注者和AI标注者之间的反馈循环,迭代生成标注数据。
- 组件:
媒体(图像或视频)通过精心策划的本体(ontology)从大型媒体池中挖掘。AI模型提出描述视觉概念的名词短语,SAM 3生成候选实例掩码。
- 验证流程:
提议的掩码经过两步验证:
-
- 掩码验证 (Mask Verification, MV):
标注者根据掩码质量和与名词短语的相关性接受或拒绝掩码。
- 穷尽性验证 (Exhaustivity Verification, EV):
标注者检查输入中是否所有概念实例都已被掩码。 未通过穷尽性检查的媒体-名词短语对会被送往人工修正阶段。
- 掩码验证 (Mask Verification, MV):
- 分阶段发展:
-
- 阶段1 (人工验证):
随机采样图像,简单描述器生成NP,SAM 2生成初始掩码。所有验证均由人工完成,生成SA-Co/HQ 的初始数据集。
- 阶段2 (人工+AI验证):
利用阶段1的人工标签微调Llama 3.2 作为AI验证器(MV和EV),将人工精力集中于最具挑战性的案例,使数据引擎吞吐量翻倍。Llama也用于生成难负例NP。
- 阶段3 (扩展和领域拓展):
AI模型用于挖掘更具挑战性的案例,将SA-Co/HQ的领域扩展到15个数据集,并利用alt-text和SA-Co本体来扩大长尾、细粒度概念的覆盖范围。
- 阶段4 (视频标注):
将数据引擎扩展到视频,利用成熟的SAM 3收集视频特有挑战的标注,并通过场景/运动过滤器、内容平衡等方式筛选视频。
- 阶段1 (人工验证):
4. SA-Co数据集与评估基准:
- 训练数据:
SA-Co/HQ(高质量人工和AI辅助标注的图像数据)、SA-Co/SYN (AI全自动生成的合成图像数据)、SA-Co/EXT (外部实例掩码数据集)。SA-Co/VIDEO (视频数据集)。
- 评估基准:
SA-Co基准包含SA-Co/Gold(由三位标注者标注,用于测量人类表现)、SA-Co/Silver(一位标注者)、SA-Co/Bronze和SA-Co/Bio(现有数据集),以及用于视频的SA-Co/VEval。
- 评估指标:
引入Classification-gated F1 (CGF1) = 。其中,pmF1(positive macro F1)衡量定位性能,IL MCC(image-level Matthews Correlation Coefficient)衡量图像级别分类性能。
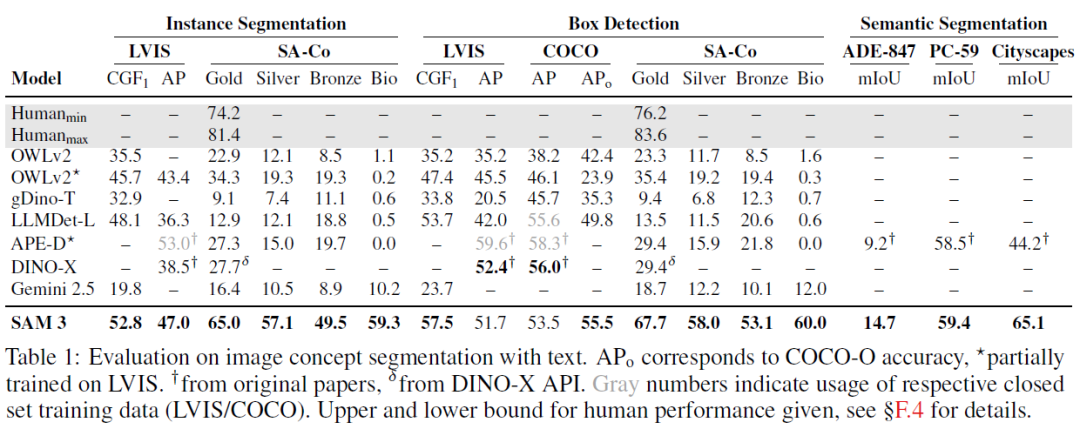
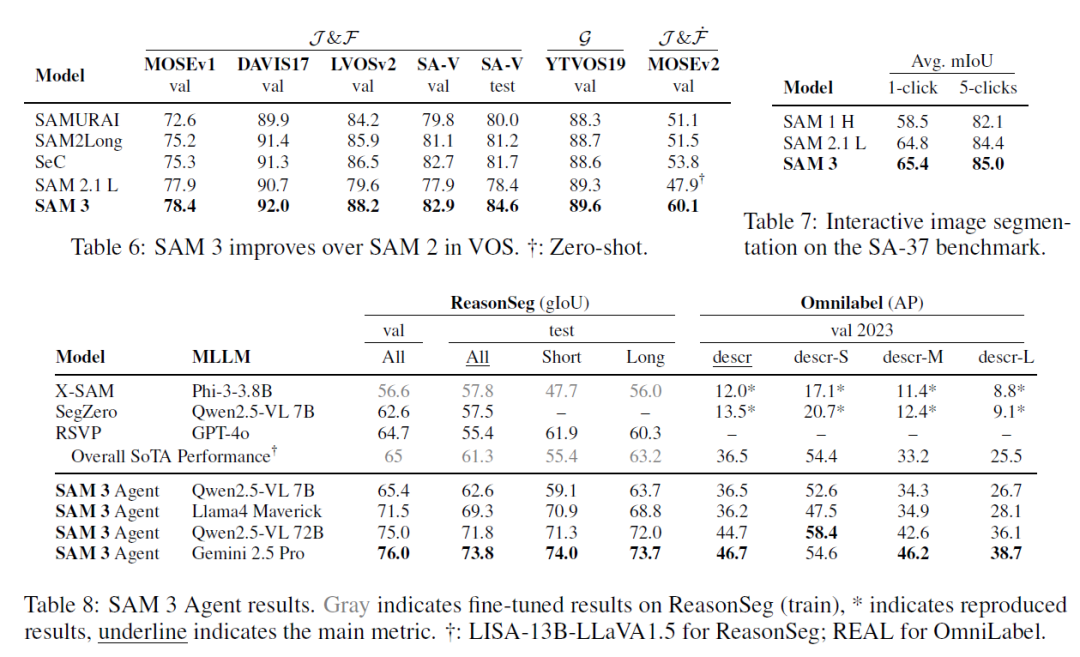
实验结果: SAM 3在图像和视频PCS任务上均取得了最先进的成果,在SA-Co基准上比现有系统性能提升两倍。例如,在LVIS数据集上,其零样本掩码AP达到47.0,超过最佳基线38.5。在SA-Co/Gold上,CGF1得分是OWLv2*的两倍。在Few-Shot Adaptation任务中,SAM 3在10-shot性能上超越了Gemini和现有物体检测专家。与MLLMs相比,SAM 3在物体计数任务上不仅准确率高,还能提供物体分割。在视频PCS任务中,SAM 3在SA-Co/VEval和公共基准上表现显著优于基线模型。SAM 3还提升了SAM 2在交互式视觉分割任务(PVS)上的表现。此外,SAM 3可以作为工具与MLLM结合,形成SAM 3 Agent,处理更复杂的语言查询,在ReasonSeg和OmniLabel等基准上零样本超越了现有工作。消融实验证明了存在头、难负例以及高质量训练数据的有效性。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)