使用Unstructured处理PDF文件的前置安装项
在做RAG开发时,众所周知一个非常关键的步骤就是文档预处理,目前在试用的工具是unstructured。我没有使用langchain的unstructured,而是直接安装了unstructured库。。可以做到本地推理(依赖模型)以及OCR等处理技术。但在运行包含unstructured的程序时发现,直接运行会有诸多报错,基本都是因为一些前置的依赖没有被安装。这篇文章就是来总结一下需要前置安装的
在做RAG开发时,众所周知一个非常关键的步骤就是文档预处理,目前在试用的工具是unstructured。我没有使用langchain的unstructured,而是直接安装了unstructured库。
我在安装unstructured的时候执行的是完整版安装:pip install "unstructured[local-inference]"。可以做到本地推理(依赖模型)以及OCR等处理技术。
但在运行包含unstructured的程序时发现,直接运行会有诸多报错,基本都是因为一些前置的依赖没有被安装。这篇文章就是来总结一下需要前置安装的内容。
提示:本文主要针对Windows环境下的运行。Mac上只需要运行brew install来安装下方依赖项即可。
1. poppler
如果遇到报错pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?,则表明环境中缺少一个名为poppler的依赖库,或者它没有被正确地添加到系统的PATH环境变量中。unstructured库在处理PDF文件时,会依赖pdf2image,而pdf2image则需要poppler来处理 PDF。为了解决安装问题需要执行下面两个步骤:
1.1 安装 poppler
访问此链接下载最新的压缩包,压缩包的名字大概如Release-24.08.0-0.zip。解压后会得到一个poppler-24.08.0的文件夹,将解压后的文件夹放置到一个本地位置,例如C:\根目录。
1.2 配置环境变量
将刚刚解压后的Poppler文件夹中的bin文件夹的完整路径添加到系统环境变量path中。文件夹路径例如:C:\poppler-24.08.0-0\Library\bin。记得一路点击“确定”保存更改。
2. Tesseract
Tesseract 是一个开源的光学字符识别(OCR)引擎。当 unstructured 处理 PDF 文件时(特别是 hi_res 策略),它首先会像人眼一样看PDF 的页面布局(这是由一个叫YOLOX的模型完成的)。然后,对于页面上的图像或者非文本部分,unstructured会使用Tesseract来“读取”这些图像中的文字,将它们转换成可编辑的文本。解决方案与我们处理poppler时如出一辙:我们需要下载、安装 Tesseract,并将其配置到系统路径中。
2.1 安装 Tesseract
-
访问此链接,下载最新的安装程序。通常文件名会是 tesseract-ocr-w64-setup-vX.X.X…exe (适用于64位系统)。
-
运行刚刚下载的安装程序。在安装过程中,会有一个选择组件的步骤,为了以防万一,可以选择安装多种语言的识别包:勾选"Additional language data"。
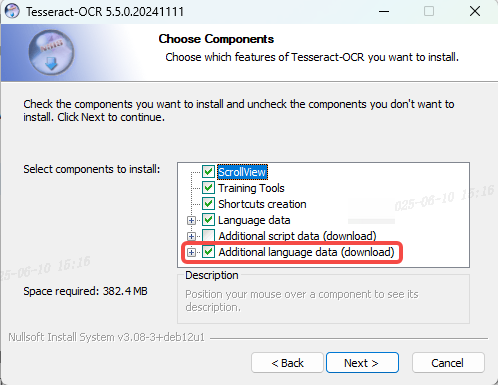
-
记下安装路径,默认路径通常是
C:\Program Files\Tesseract-OCR。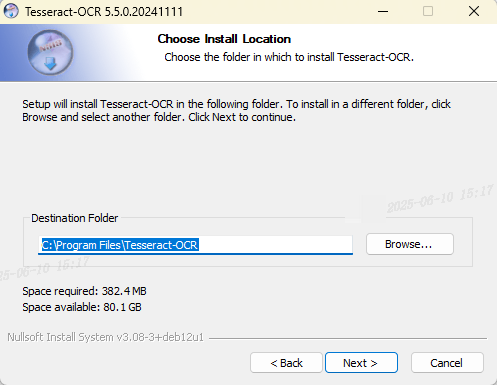
2.2 配置环境变量
在系统环境变量path中添加刚刚记下的安装路径:如C:\Program Files\Tesseract-OCR。
除此之外,推荐再新建一个环境变量来告诉 Tesseract 语言包在哪里。新建如下系统变量:
- 变量名: TESSDATA_PREFIX
- 变量值: C:\Program Files\Tesseract-OCR\tessdata
至此,如果在终端中输入tesseract --version能正常输出版本号,则说明安装成功。
3. yolox模型
由于我在partition的过程中使用了strategy="hi_res"(有关策略可以去unstructured官网手册上看,有关unstructured的几个典型处理过程有空可以再写一篇),unstructured需要下载一个基于YOLOX的版面分析模型(yolox_l0.05.onnx)来获得高质量的解析结果。在运行代码时,模型会自动下载。但是,如果不使用一些特殊的网络连接手段,我们电脑的网络环境很可能限制了对hugging face的访问,导致模型下载失败,程序因此中断。
- 我的实际场景是:生产环境是公司的Windows电脑,我是万万不敢搞事的。于是我在家里电脑正常运行程序从huggingface上下载了模型,然后将模型拷贝到公司的电脑上。方法如下:
huggingface_hub 的默认缓存目录是:C:\Users\<你的用户名>\.cache\huggingface\hub\(Mac也是这个地址),在这个目录中找到名为models--unstructuredio--yolo_x_layout的文件夹,将整个文件夹复制到另一台计算机即可(注意路径也需要是提及的这个,如果目录不存在,请手动创建它)。
我在复制后运行代码出现了一个新的问题(未必所有人都会遇到):ONNX Runtime报错InvalidProtobuf。简单来说,这意味着程序已经成功在本地缓存路径中找到了模型文件yolox_l0.05.onnx,但是当程序尝试读取这个文件时,发现文件内容本身是损坏的、不完整的或格式不正确的。可以先检查一下当前损坏文件的大小:
在Windows中找到这个文件:C:\Users\ThinkPad\.cache\huggingface\hub\models--unstructuredio--yolo_x_layout\snapshots\一个哈希值命名的文件夹\yolox_l0.05.onnx。如果文件大小非常小(例如只有几 KB),说明它可能只是一个文本指针而不是真正的模型文件。
我的解决方案是:直接下载那个onnx模型文件,官方下载地址可以直接从之前的报错日志中找到:https://huggingface.co/unstructuredio/yolo_x_layout/resolve/main/yolox_l0.05.onnx。然后将模型放置到前面提及的路径位置即可。鉴于很多朋友可能没办法访问huggingface,我上传了模型文件,点击这里下载。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)