2025年RAG最佳Reranker模型全景图:从精度到效率的理性选择

前言
在企业大模型落地的实践中,RAG(检索增强生成)已成为绕不开的核心架构。它像一位“外挂大脑”,让大模型能实时调用企业私有知识,避免幻觉、提升准确性。然而,许多团队在部署RAG后发现:即便用了顶尖的嵌入模型和向量数据库,生成结果仍时好时坏。问题往往出在“检索”与“生成”之间的那道缝隙——初始检索返回的文档虽多,却良莠不齐。此时,重排序器(Reranker)便如一位“信息策展人”,从一堆候选中精准挑出最相关的几条,喂给大模型。2025年,Reranker技术已从“可选项”变为“必选项”。本文不堆砌术语,不鼓吹单一模型,而是从工程视角出发,拆解各类Reranker的底层逻辑、实测表现与落地成本,帮助你在精度、速度、预算之间做出理性权衡。无论你是技术负责人、算法工程师,还是正在评估RAG方案的产品经理,这篇文章都将为你提供一份可执行的选型指南。
1. RAG为何需要Reranker:初始检索的天然缺陷
1.1 向量检索的“语义盲区”
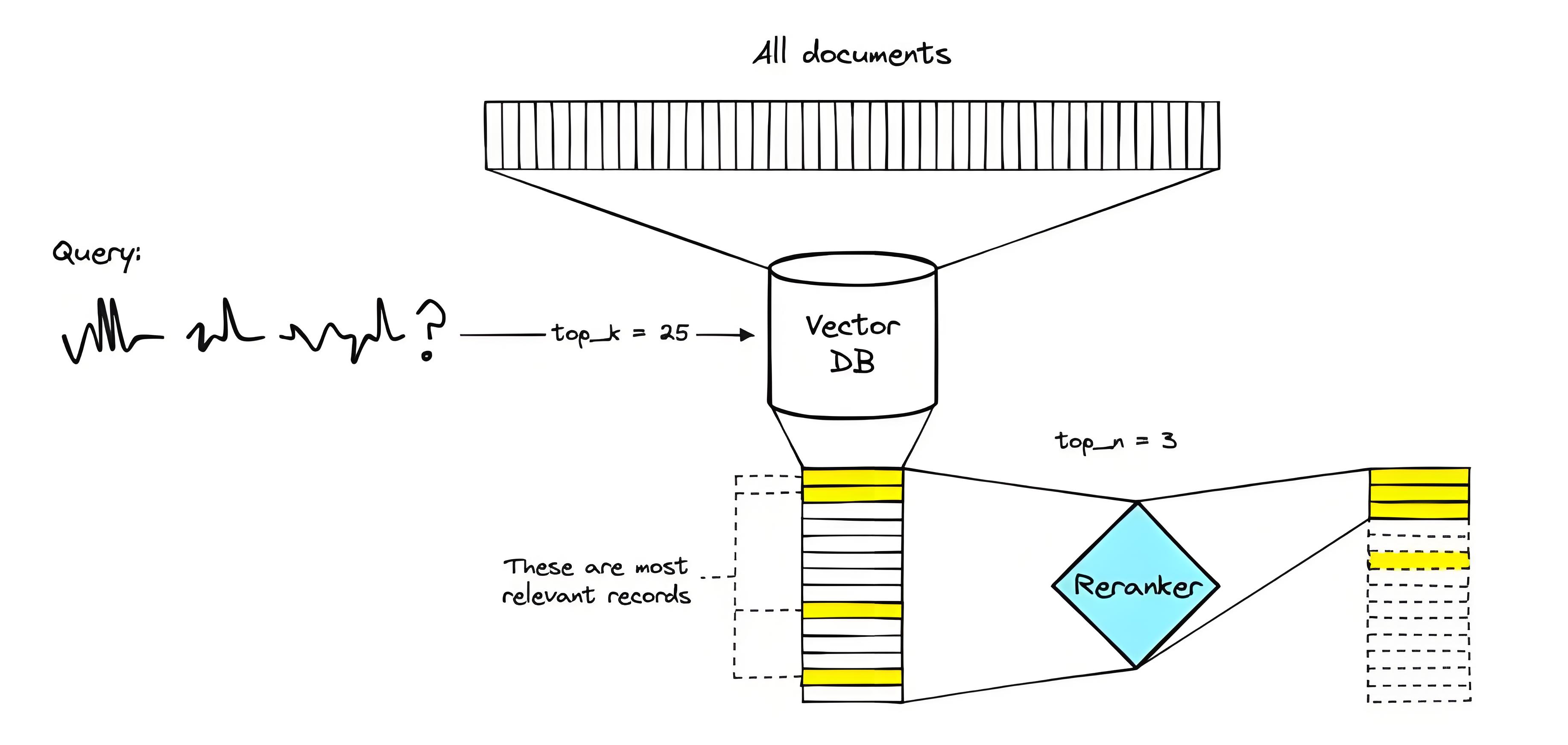
向量数据库通过将文本映射为高维向量,实现语义相似性搜索。这种方法在处理通用语义时表现优异,但面对专业术语、短查询或复杂意图时,往往力不从心。例如,用户提问“如何配置Kubernetes的Pod安全策略?”,初始检索可能返回大量关于“Kubernetes基础架构”或“容器安全”的泛泛文档,却遗漏了真正聚焦“PodSecurityPolicy”或“Pod Security Admission”的技术细节。这种“语义漂移”源于嵌入模型在训练时对长尾领域覆盖不足,导致向量空间中的距离无法准确反映实际相关性。
1.2 上下文窗口的“信息过载”危机
大语言模型虽强大,但其上下文窗口容量有限。若将初始检索返回的20甚至50个文档全部塞入,不仅浪费计算资源,更会引入大量无关信息,干扰模型判断。实验表明,当输入中混入超过30%的低相关文档时,LLM生成答案的准确率下降超过40%。这种“信息过载”如同让厨师在一堆食材中挑选主料,若配料过多,主味反而被掩盖。Reranker的作用,正是在这堆食材中精准选出最关键的几味,确保大模型“吃得精,做得准”。
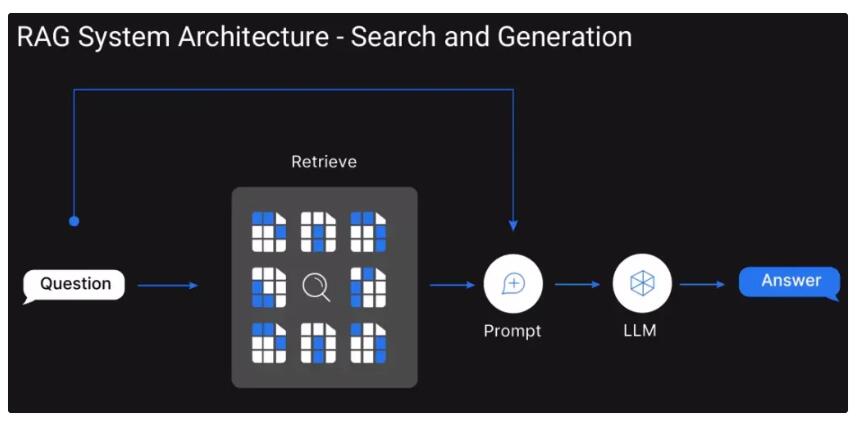
2. Reranker的工作原理:从粗筛到精炼的语义对齐
2.1 交叉编码器:语义匹配的“黄金标准”
交叉编码器(Cross-Encoder)是当前Reranker的主流架构。它将查询(query)与每个候选文档(document)拼接成一个整体输入,通过Transformer模型进行联合编码,输出一个相关性分数。这种方式能捕捉查询与文档之间的细粒度交互,例如代词指代、逻辑关系、隐含前提等。例如,查询“总统对Ketanji Brown Jackson的评价”与文档“她将延续Breyer大法官的卓越传统”之间并无关键词重叠,但交叉编码器能理解“她”指代Jackson,“卓越传统”对应“评价”,从而给出高分。这种深度语义理解使其在精度上远超双编码器(Bi-Encoder)等早期方案。
2.2 多向量与晚期交互:效率与精度的折中
ColBERT等模型采用“多向量+晚期交互”策略。它为文档中的每个词元生成独立向量,并在检索阶段通过MaxSim操作计算查询词元与文档词元的最大相似度之和。这种方式允许文档向量预先计算并索引,大幅降低在线推理延迟。虽然语义深度略逊于交叉编码器,但在处理百万级文档库时,其检索效率优势显著。这种架构适合对响应速度要求极高、且文档集规模庞大的场景,如电商平台的商品搜索或新闻聚合系统。
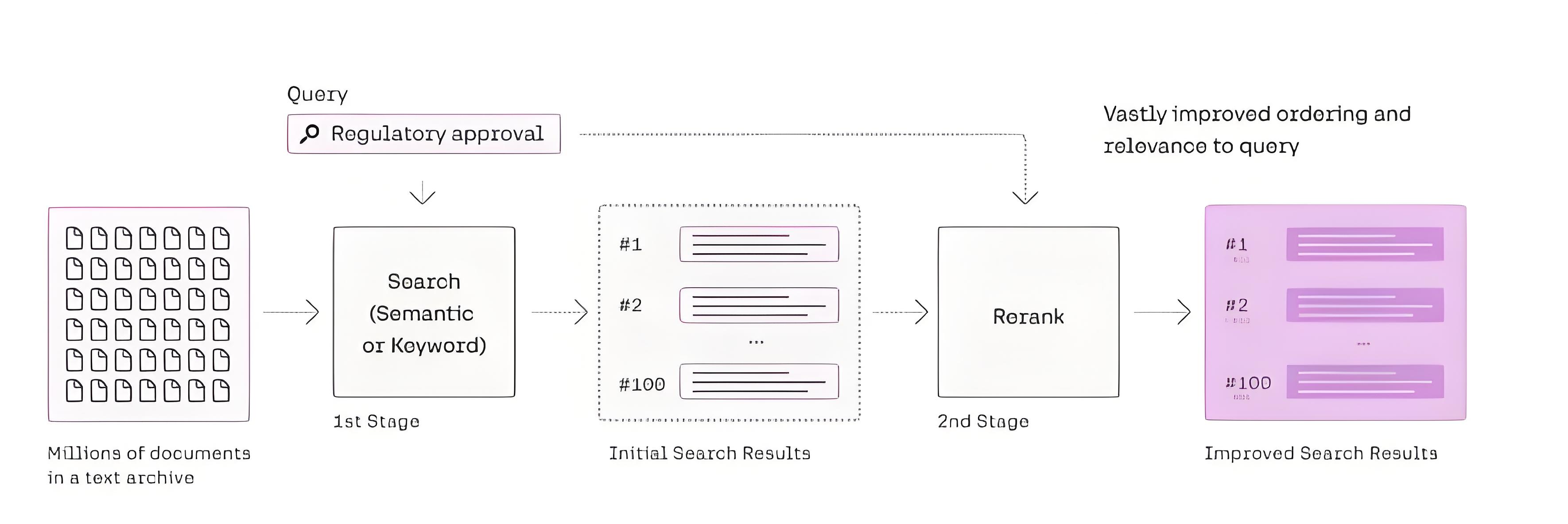
3. 2025年主流Reranker模型横向评测
3.1 闭源API阵营:开箱即用的高精度选择
| 模型 | 类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Cohere Rerank | 交叉编码器 | 多语言支持、Nimble版低延迟 | 闭源、按调用付费 | 企业客服、多语言知识库 |
| Voyage Rerank | 交叉编码器 | 基准测试SOTA、法律金融优化 | 高精度版延迟较高 | 法律文书分析、金融研报解读 |
Cohere的“Nimble”版本通过模型蒸馏和量化技术,在保持95%以上精度的同时,将延迟降低60%,特别适合高并发的在线服务。Voyage则在专业领域微调上投入巨大,其法律版模型在判例检索任务中MRR@10达0.89,远超通用模型。
3.2 开源自托管阵营:灵活可控的性价比之选
| 模型 | 类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| bge-reranker | 交叉编码器 | Apache 2.0许可、中等硬件可运行 | 需自运维 | 私有化部署、预算敏感项目 |
| MixedBread (mxbai) | 交叉编码器 | 三阶段RL训练、长上下文、多数据类型支持 | 新模型,社区生态待完善 | 代码/JSON处理、长文档问答 |
| FlashRank | 轻量交叉编码器 | CPU友好、毫秒级响应 | 精度略低 | 边缘设备、实时推荐系统 |
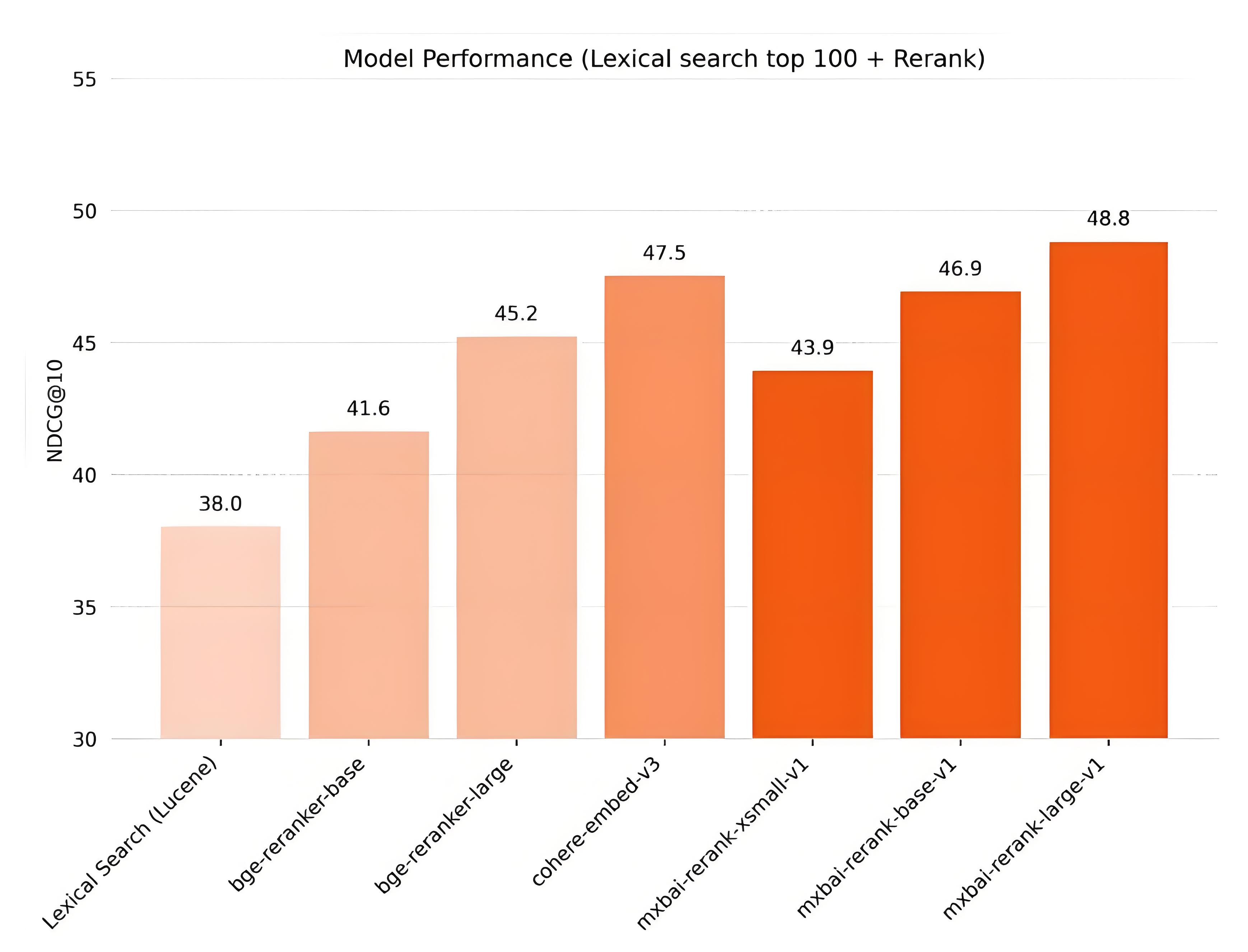
MixedBread的创新在于引入强化学习(RL)进行三阶段训练:先通过GRPO优化基础相关性,再用对比学习拉大正负样本差距,最后用偏好学习对齐人类判断。这种训练范式使其在BEIR基准上超越Cohere Large,且1.5B参数模型推理速度比同类快30%。
3.3 长文档与大规模场景的特殊选手
Jina-ColBERT支持8,192 token上下文,能直接处理整篇技术白皮书或财报,避免因分块导致的语义断裂。ColBERTv2在MS MARCO数据集上Recall@100达0.92,适合构建企业级知识图谱的底层检索引擎。这类模型虽索引成本高,但一旦部署,后续查询成本极低,适合数据更新频率低、查询量大的场景。
4. 如何评估Reranker的实际效果
4.1 核心指标解析
- MRR@10(平均倒数排名) :衡量首个相关结果的排名位置。若MRR@10从0.5提升至0.7,意味着用户平均在第1.4次点击就能找到答案,而非第2次。
- NDCG@5(归一化折扣累积增益) :综合考虑相关性与排名位置。例如,一个高度相关文档排第1位贡献0.9分,排第5位仅贡献0.2分。
- Precision@3:直接反映喂给LLM的前三文档质量。若该值低于0.6,生成答案大概率包含噪声。
4.2 业务场景驱动的评估策略
在客服场景,更关注首次响应准确率,应优先优化MRR@1;在研究辅助场景,需覆盖多角度信息,Recall@10更为关键。建议构建领域专属测试集,包含典型查询-文档对,并人工标注相关性等级,避免依赖通用基准的“虚高”分数。
5. 选型决策框架:平衡精度、成本与工程复杂度
5.1 闭源 vs 开源:不只是钱的问题
闭源API的优势在于免运维、自动更新,但存在数据隐私风险和长期成本不可控问题。某金融客户测算发现,日均10万次调用下,Cohere年费用超20万美元,而自托管bge-reranker-large仅需2台A10 GPU,年成本不足5万。若业务涉及敏感数据或需深度定制,开源是更可持续的选择。
5.2 精度与延迟的权衡曲线
实验数据显示,在通用问答任务中:
- Voyage Rerank-2 精度最高(NDCG@5=0.85),但P99延迟达420ms;
- MixedBread-Large 精度相近(0.83),延迟降至280ms;
- FlashRank 精度0.72,延迟仅45ms。
若业务容忍度允许精度损失5%,选择FlashRank可将服务器成本降低70%。关键在于明确业务对“准确”的定义——是绝对正确,还是“足够好且快”?
6. 未来趋势:Reranker的演进方向
6.1 多模态与结构化数据支持
下一代Reranker将不再局限于纯文本。MixedBread已支持JSON和代码,能理解“提取用户订单中的product_id”这类指令。未来,模型将融合表格、图表甚至视频帧的语义,实现跨模态重排序。
6.2 动态上下文感知
当前Reranker多为静态打分。前沿研究正探索结合用户历史行为、对话上下文进行动态重排序。例如,同一查询“Python异常处理”,对新手返回基础教程,对专家返回高级调试技巧。这种个性化重排序将极大提升RAG的用户体验。
写在结尾
站在2025年的门槛回望,Reranker已从RAG的“配角”成长为决定系统成败的“核心引擎”。没有放之四海皆准的最优模型,只有最适合业务场景的理性选择。精度、速度、成本、隐私——这些维度交织成一张复杂的决策网。真正的工程智慧,不在于追逐SOTA的光环,而在于看清需求本质,在约束条件下找到那个恰到好处的平衡点。当你在深夜调试RAG pipeline,看着重排序后的上下文精准命中用户意图,那一刻的满足感,或许就是技术落地最美的回响。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 11
11 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)