huggingface模型中各文件详解
Hugging Face模型仓库包含五类核心文件:1) 模型权重文件(如.safetensors分片文件及索引文件);2) 模型配置文件(config.json定义模型架构);3) 分词器文件(tokenizer.json、词汇表等处理文本转换);4) 生成配置文件(generation_config.json设置文本生成参数);5) 其他文件(README说明文档等)。这些文件共同支持trans
文章目录
huggingface/modelscope模型中各文件详解
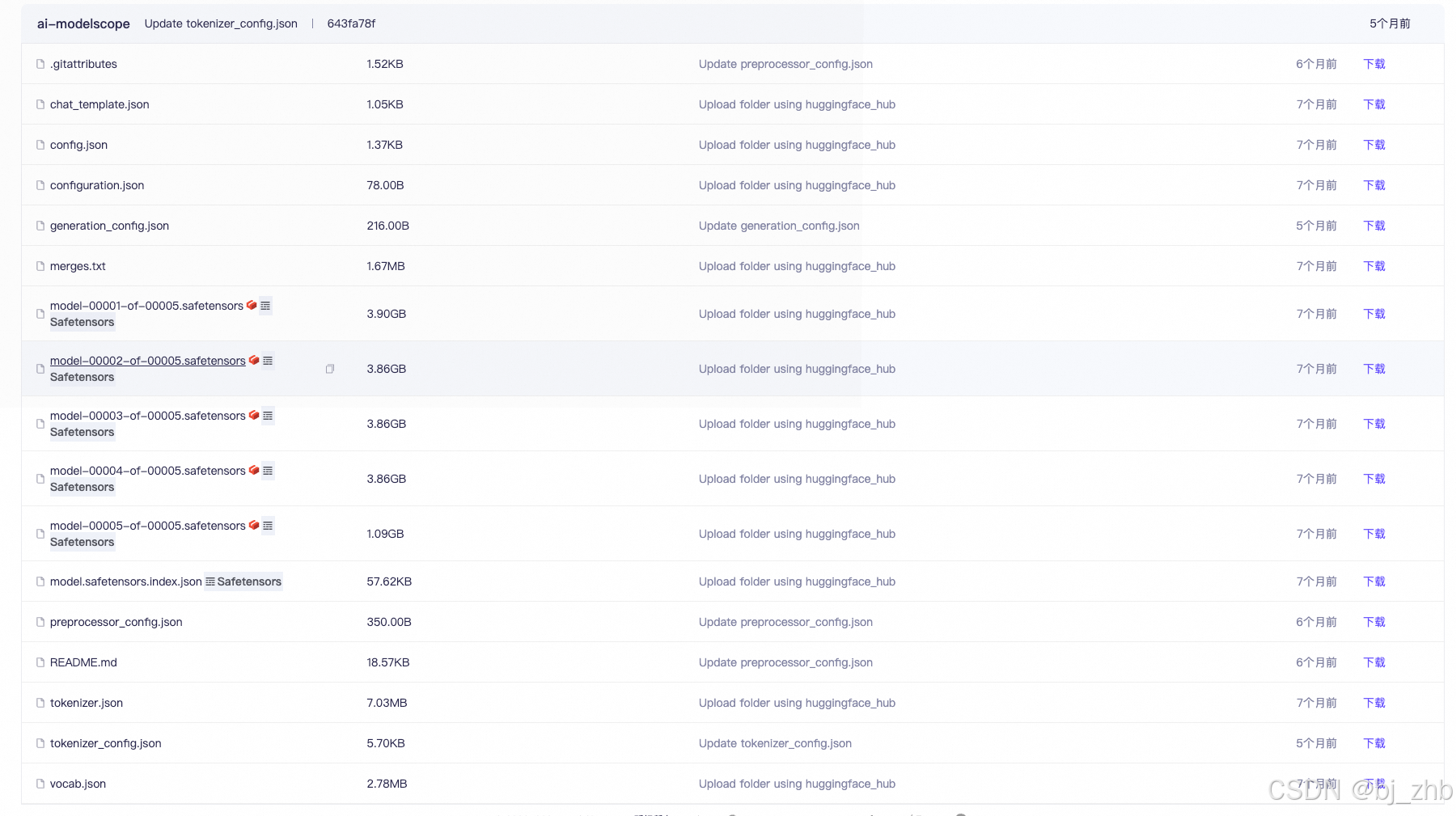
这张图展示了一个典型的 Hugging Face 模型仓库中的文件列表。这些文件共同构成了一个完整的、可直接使用的模型包。下面我将它们分类并逐一解释其作用:
这些文件可以大致分为五类:
- 模型权重文件 (Model Weights)
- 模型配置文件 (Model Configuration)
- 分词器文件 (Tokenizer Files)
- 生成与聊天配置文件 (Generation & Chat Configuration)
- 其他文件 (Miscellaneous)
1. 模型权重文件 (Model Weights)
这是模型最核心的部分,包含了模型经过训练后学到的所有参数(权重和偏置)。
-
model-00001-of-00005.safetensors(以及00002到00005)- 作用:这些是模型权重的分片文件。对于大型模型,单个权重文件可能非常大(几十上百GB),为了方便下载、加载和管理,通常会将它们分割成多个小文件。文件名中的
00001-of-00005表示这是5个分片中的第1个。 - 格式:
.safetensors是一种安全、快速的张量(模型权重)存储格式,是目前Hugging Face推荐的格式,比传统的.bin(PyTorch) 格式更安全(不会执行恶意代码)且加载速度更快。
- 作用:这些是模型权重的分片文件。对于大型模型,单个权重文件可能非常大(几十上百GB),为了方便下载、加载和管理,通常会将它们分割成多个小文件。文件名中的
-
model.safetensors.index.json- 作用:这是一个索引文件或“地图”。当模型权重被分片时,这个文件会告诉Hugging Face的
transformers库,每个具体的权重(比如“第10层注意力头的权重”)存储在哪一个.safetensors分片文件中。没有它,库就不知道如何从这些分片中正确地重组出完整的模型。
- 作用:这是一个索引文件或“地图”。当模型权重被分片时,这个文件会告诉Hugging Face的
2. 模型配置文件 (Model Configuration)
这些文件定义了模型的“蓝图”或“骨架”。
-
config.json- 作用:这是最重要的配置文件,定义了模型的架构。它包含了模型的各种超参数,例如:
- 模型类型 (
architectures, e.g.,LlamaForCausalLM) - 隐藏层大小 (
hidden_size) - 注意力头的数量 (
num_attention_heads) - 网络层数 (
num_hidden_layers) - 词汇表大小 (
vocab_size)
- 模型类型 (
- 当你使用
AutoModel.from_pretrained(...)时,库会首先读取这个文件,以了解应该构建一个什么样的模型结构,然后再将权重加载进去。
- 作用:这是最重要的配置文件,定义了模型的架构。它包含了模型的各种超参数,例如:
-
configuration.json- 作用:通常是
config.json的一个别名或旧版本文件。在现代模型库中,config.json是标准。两者内容基本一致。
- 作用:通常是
3. 分词器文件 (Tokenizer Files)
分词器(Tokenizer)负责将人类的文本语言转换成模型能够理解的数字ID序列,以及反向转换。
-
tokenizer.json- 作用:这是一个由Hugging Face的
tokenizers库生成的“一体化”文件。它包含了分词器所需的所有信息:词汇表、合并规则(merges)、特殊token等。这是一个高效的、独立的配置文件,加载速度非常快。
- 作用:这是一个由Hugging Face的
-
tokenizer_config.json- 作用:这个文件配置了分词器类的行为。它定义了如何使用其他文件,以及一些特殊token的名称,例如
bos_token(句子开头)、eos_token(句子结尾)、unk_token(未知词) 等。
- 作用:这个文件配置了分词器类的行为。它定义了如何使用其他文件,以及一些特殊token的名称,例如
-
vocab.json- 作用:词汇表文件。它是一个JSON字典,将每个“词元”(token)映射到一个唯一的整数ID。这是分词过程的核心部分。
-
merges.txt- 作用:这是BPE(Byte-Pair Encoding)分词算法的合并规则文件。它按照优先级顺序列出了如何将子词(subword)合并成更大的词元。例如,它可能包含一条规则
e r -> er。
- 作用:这是BPE(Byte-Pair Encoding)分词算法的合并规则文件。它按照优先级顺序列出了如何将子词(subword)合并成更大的词元。例如,它可能包含一条规则
文件关系:AutoTokenizer.from_pretrained(...) 会智能地加载这些文件。如果存在 tokenizer.json,它会优先使用这个文件,因为它最快最全。如果不存在,它会根据 tokenizer_config.json 的指示,组合 vocab.json 和 merges.txt 等文件来构建分词器。
4. 生成与聊天配置文件 (Generation & Chat Configuration)
-
generation_config.json- 作用:这个文件为模型的文本生成过程提供了默认参数。当你调用
.generate()方法时,如果没有指定参数,就会使用这里的配置。常见的参数包括:max_length:生成文本的最大长度。temperature,top_p,top_k:控制生成文本多样性和创造性的参数。do_sample:是否使用采样策略。
- 作用:这个文件为模型的文本生成过程提供了默认参数。当你调用
-
chat_template.json- 作用:对于聊天模型(Chat Model)来说,这是一个非常重要的文件。它定义了如何将多轮对话(包含系统提示、用户输入、模型回复)格式化为模型能够理解的单个字符串。这通常是一个Jinja2模板,确保了角色和特殊token(如
[INST],</s>)被正确地放置。如果格式不对,聊天模型的效果会大打折扣。
- 作用:对于聊天模型(Chat Model)来说,这是一个非常重要的文件。它定义了如何将多轮对话(包含系统提示、用户输入、模型回复)格式化为模型能够理解的单个字符串。这通常是一个Jinja2模板,确保了角色和特殊token(如
5. 其他文件 (Miscellaneous)
-
README.md- 作用:这是一个Markdown格式的说明文件,也就是“模型卡片”(Model Card)。它详细介绍了模型的信息,包括:模型描述、用途、限制、如何使用、训练数据、评测结果等。这是用户了解和使用模型的首要入口。
-
.gitattributes- 作用:这是一个Git的配置文件。它通常与
git-lfs(Large File Storage) 一起使用,告诉Git如何处理大文件。对于像.safetensors这样的GB级大文件,这个文件会指示Git只跟踪文件的指针,而不是文件的完整内容,从而让仓库保持轻量。
- 作用:这是一个Git的配置文件。它通常与
-
preprocessor_config.json- 作用:预处理器配置文件。对于纯文本的语言模型,这个文件可能比较简单或不存在。但在多模态模型(如处理图像或音频)中,它会定义数据预处理的步骤,例如图像缩放尺寸、归一化参数等。
总结
当你执行 AutoModelForCausalLM.from_pretrained("仓库名") 和 AutoTokenizer.from_pretrained("仓库名") 这两行代码时,Hugging Face的 transformers 库会在后台自动下载所有这些必要的文件,并:
- 用
config.json搭建模型框架。 - 用
model...index.json和.safetensors文件填充模型权重。 - 用
tokenizer相关文件构建一个功能完备的分词器。
这样,你就可以用几行代码轻松地加载和使用一个复杂的预训练模型了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)