Mem0实战指南:给你的大模型加上长期记忆
在大语言模型(LLM)迅猛发展的今天,我们已经可以使用 ChatGPT、Claude 等工具完成写作、总结、编程等任务。但这些模型存在一个关键短板:它们没有“长期记忆”。每一次session都是第一次相遇,用户必须反复输入背景信息,这极大地限制了模型在个性化助手、长期交互、用户建模等场景的能力。往深了想,AI没有自己的记忆或者长期叙事,就无法真正拥有“我”的概念,可能永远也谈不上真正意义上的“自主
在大语言模型(LLM)迅猛发展的今天,我们已经可以使用 ChatGPT、Claude 等工具完成写作、总结、编程等任务。但这些模型存在一个关键短板:它们没有“长期记忆”。 每一次session都是第一次相遇,用户必须反复输入背景信息,这极大地限制了模型在个性化助手、长期交互、用户建模等场景的能力。往深了想,AI没有自己的记忆或者长期叙事,就无法真正拥有“我”的概念,可能永远也谈不上真正意义上的“自主决策”。(这部分讨论请看AI是否应该有末那识)
是否有一种快速、简单的方法为我们的模型加上长期记忆呢?
当然有啦~那就是今天给大家介绍的开源项目Mem0
1 什么是Mem0?
Mem0是一个专为 AI 应用设计的开源记忆层,支持长期和短期的上下文存储,可用于增强 LLM 的个性化能力。核心特点包括:
-
多粒度记忆管理(用户 / 会话 / 代理)
-
简洁的 Python SDK 接口
-
与 Chroma 向量数据库集成良好
-
支持自托管与托管两种方式
2 如何使用 Mem0:快速上手实践
2.1 自托管方式
咱们先试一下自托管的方式,核心逻辑是使用本地的Chroma 向量数据库,会在本地自动生成一些.sqlite3文件。
以下是具体代码和用4o生成的详细注释:
# 引入 OpenAI SDK 和 Mem0 的记忆模块from openai import OpenAIfrom mem0 import Memoryimport os# 设置 OpenAI API Key 和自定义的 Base URL(适用于自托管或代理)os.environ["OPENAI_API_KEY"] = "XX"os.environ["OPENAI_BASE_URL"] = "XX"# 定义 Mem0 的配置,包括 LLM 模型信息和向量数据库(使用 Chroma)config = {"llm": {"provider": "openai", # 使用 OpenAI 提供的模型"config": {"model": "gpt-4o-mini", # 模型名称"temperature": 0.2, # 输出的随机程度(越小越稳定)"max_tokens": 2000, # 最大输出长度}},"vector_store": {"provider": "chroma", # 使用 Chroma 作为向量存储"config": {"collection_name": "test", # 数据集合名"path": "db", # Chroma 数据库存储路径}}}# 初始化 OpenAI 客户端openai_client = OpenAI(api_key = "XX",base_url = "XX" # 可选)# 根据上述配置初始化记忆对象memory = Memory.from_config(config)# 核心函数:与 AI 对话,并利用记忆增强响应def chat_with_memories(message: str, user_id: str = "default_user") -> str:# 第一步:从记忆中检索与当前用户输入最相关的记忆内容relevant_memories = memory.search(query=message, user_id=user_id, limit=3)# 将检索到的记忆整理成字符串,作为系统提示输入memories_str = "\n".join(f"- {entry['memory']}" for entry in relevant_memories["results"])# 构建系统提示,告诉 AI 要参考哪些记忆内容system_prompt = ("You are a helpful AI. Answer the question based on query and memories.\n"f"User Memories:\n{memories_str}")# 构造对话历史,系统提示 + 当前用户问题messages = [{"role": "system", "content": system_prompt},{"role": "user", "content": message}]# 使用 OpenAI 接口生成对话回复response = openai_client.chat.completions.create(model="gpt-4o-mini",messages=messages)assistant_response = response.choices[0].message.content # 获取回复内容# 将这轮对话(用户和 AI 的发言)添加进记忆库messages.append({"role": "assistant", "content": assistant_response})memory.add(messages, user_id=user_id)return assistant_response # 返回 AI 的回答# 命令行对话主入口def main():print("Chat with AI (type 'exit' to quit)")while True:user_input = input("You: ").strip()if user_input.lower() == 'exit':print("Goodbye!")breakprint(f"AI: {chat_with_memories(message=user_input, user_id='test_1')}")# 程序主执行入口if __name__ == "__main__":main()
不得不说,现在的AI作为效率工具确实厉害,这代码注释写的非常清楚啦~
代码内容就不再赘述了(偷懒ing)。
主要说一下:
-
通过设置不同的user_id,可以保证记忆是隔离的,同一个user_id下的记忆是共享的,也是长期的,即今天运行程序和大模型聊天后关闭程序,明天运行程序时之前的记忆依旧存在;
-
mem0的存储的是通过4o-mini(可以自行设置)进行摘要和信息抽取后的内容;
原始对话输入:
USER:我叫鸣人,来自木叶村,是个火影候选人,喜欢吃一乐拉面,老师是卡卡西,我的梦想是成为最强的火影!Mem0 在会利用模型(如 gpt-4o-mini)对其进行摘要与结构化抽取,生成多条独立的 memory 条目,便于后续精确检索:
[{"memory": "用户叫鸣人"},{"memory": "用户来自木叶村"},{"memory": "用户是火影候选人"},{"memory": "用户喜欢吃一乐拉面"},{"memory": "用户的老师是卡卡西"},{"memory": "用户的梦想是成为最强的火影"}]
这些拆分后的结构化记忆将被向量化并存储在底层向量数据库(如 Chroma)中,以支持模糊语义搜索。当你日后询问类似“我最喜欢吃什么?”或“我的老师是谁?”这类问题时,Mem0 能快速从记忆中找出对应片段,构建上下文响应。
这种摘要+抽取的方式,对于日常的信息量不大的聊天历史来说,非常方便,检索起来也很准确。但是对于做一些deep research等复杂任务,一轮对话会生成非常多的条目,并且有可能丢失某些重要信息(关于信息损失有多大,要看进行信息抽取和摘要的模型的能力)。
这种自托管的方式,好处在于不用掏钱,数据存在本地也安全。坏处在于chroma是轻量级的向量数据库,没有对应的官方前端,要查看数据可中的内容,需要借助一些其他工具,这里推荐SQLite Viewer(VS Code插件),直接在VS Code或者Cursor的插件里搜索安装即可,简单易用。
💬 Mem0 记忆效果展示
Chat with AI (type 'exit' to quit)You: 我叫鸣人,来自木叶村,是个火影候选人,喜欢吃一乐拉面,老师是卡卡西,我的梦想是成为最强的火影!AI: 你好,鸣人!听起来你有一个伟大的梦想,成为最强的火影!我相信你一定能通过坚持和努力实现这个目标。你在追求梦想的过程中有什么有趣的经历吗?还有你对卡卡西老师的看法如何?# 程序重启后,再次对话Chat with AI (type 'exit' to quit)You: 我是谁AI: 你是鸣人,是火影候选人,你的老师是卡卡西。You: 我的梦想是什么AI: 你的梦想是成为最强的火影。You: exitGoodbye!
🧠 Mem0 记忆内容展示
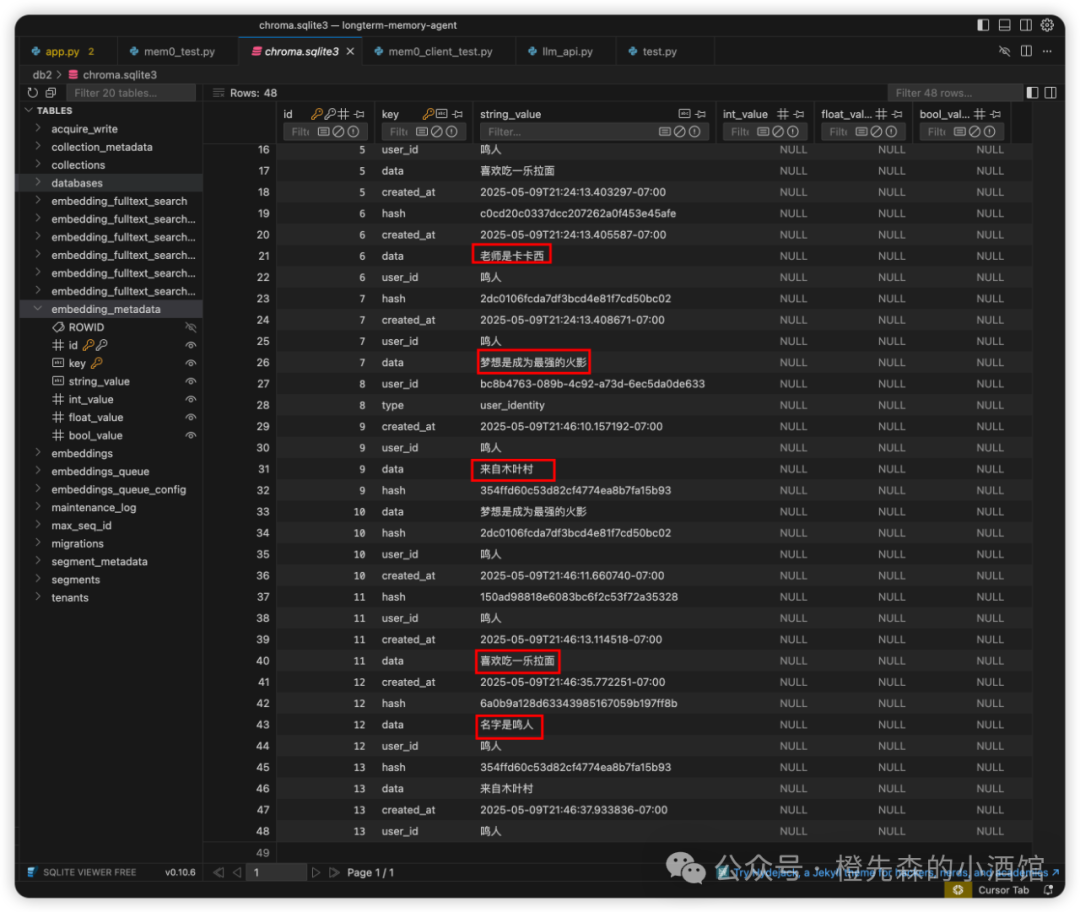
2.2 托管方式
托管方式指的是将记忆的内容托管到mem0的云端,进行记忆摘要和信息抽取的模型mem0也配置好了,使用更方便,并且有漂亮的前端展示,可以让你清晰的看到不同USER_ID下记忆内容。缺点是免费帐户每月存储和检索次数有限,且一些私密数据上传云端可能不是很安全。
以下是具体代码和用4o生成的详细注释:
# 导入 OpenAI SDK 和 Mem0 的托管客户端接口from openai import OpenAIfrom mem0 import MemoryClient# 初始化 OpenAI 客户端(用于调用 LLM 生成回复)openai_client = OpenAI(api_key = "XX", # 替换为你的 OpenAI API 密钥base_url = "XX" # 可选项,若使用代理则指定 base_url)# 初始化 Mem0 托管服务的客户端# 🔐 api_key 获取方式:# 1. 访问官网:https://mem0.ai# 2. 登录后进入 Dashboard 页面# 3. 在「API Key」模块中复制你的专属密钥memory = MemoryClient(api_key='XX') # 替换为你从 mem0.ai 获取的 API 密钥# 核心对话函数:基于记忆检索+模型响应+记忆写入def chat_with_memories(message: str, user_id: str = "default_user") -> str:# 🔎 Step 1:从 Mem0 中搜索与当前问题相关的记忆片段relevant_memories = memory.search(query=message, user_id=user_id, limit=3)print(relevant_memories) # 可用于调试,查看检索结果# 将记忆内容拼接成系统提示内容if relevant_memories:memories_str = "\n".join(f"- {entry['memory']}" for entry in relevant_memories)else:memories_str = "No memories found"# 🧠 Step 2:构造 system prompt,将记忆嵌入模型提示中system_prompt = ("You are a helpful AI. Answer the question based on query and memories.\n"f"User Memories:\n{memories_str}")# 组装对话消息历史(用于发送给 LLM)messages = [{"role": "system", "content": system_prompt},{"role": "user", "content": message}]# 使用 OpenAI 的 chat API 获取模型回复response = openai_client.chat.completions.create(model="gpt-4o-mini",messages=messages)assistant_response = response.choices[0].message.content # 提取回复内容# 🧾 Step 3:将这轮对话(user 和 assistant)添加进 Mem0 的记忆messages.append({"role": "assistant", "content": assistant_response})memory.add(messages, user_id=user_id)return assistant_response # 返回给前端或 CLI 的回答内容# 命令行对话入口函数def main():print("Chat with AI (type 'exit' to quit)")while True:user_input = input("You: ").strip()if user_input.lower() == 'exit':print("Goodbye!")break# 注意此处设置的 user_id,是记忆关联的主键print(f"AI: {chat_with_memories(message=user_input, user_id='test')}")# 启动主程序if __name__ == "__main__":main()
🧠 Mem0 记忆内容展示
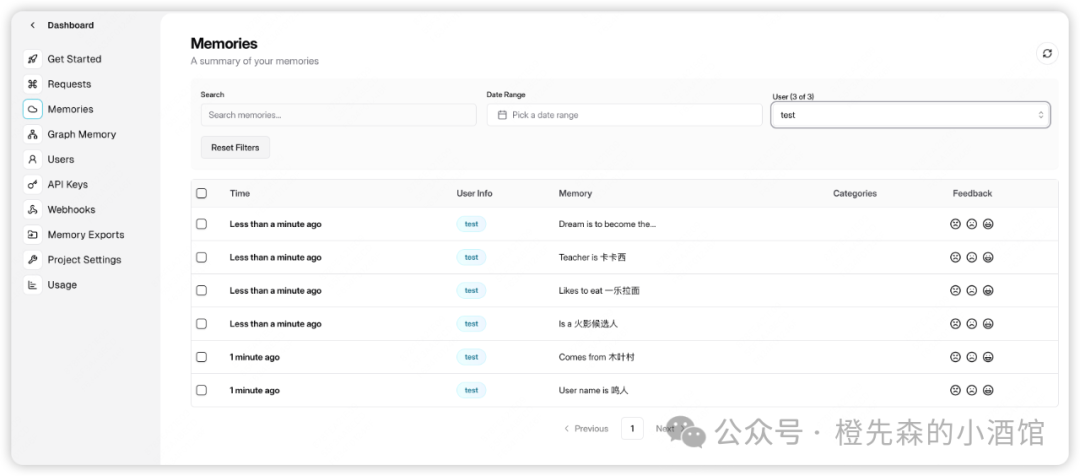
整体而言,mem0简单易用,可以满足咱们的日常需求,可以快速给你的AI加上长期记忆。mem0是一个开源项目,并且有对应的论文(arxiv.org/pdf/2504.19413)。
后续咱们一起解读下这篇paper,然后看看项目源码,争取对该项目的memory实现有更深入的了解~
欢迎大家指正错误,点点关注,一起学习~
参考资料
[1]
Mem0: https://github.com/mem0ai/mem0

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)