rk3588完成mipi摄像头0拷贝传输-0基础 DMA_BUF+CMA
基于RK3588平台的AI项目零拷贝处理流程。通过DMA_BUF+CMA实现MIPI摄像头数据采集后,系统利用RGA进行格式转换(YUV420→RGB565),构建线程池进行NPU并行推理(YOLOv5s),最后通过MPP硬编码和FFmpeg完成RTMP推流。重点解析了两种零拷贝方案:mmap实现内核-用户空间直接访问,DMABUF则通过文件描述符实现跨模块内存共享。同时详细说明了CMA机制如何保
0基础
首先我们来了解一下,使用rk3588完成一个ai项目的流程
DMA_BUF+CMA完成mipi摄像头数据0拷贝采集(YUV420) → RGA预处理(YUV420→RGB565) → 搭建线程池使用安全队列完成NPU推理(YOLOv5s,3核并行) → 将结果opencv处理叠加(可选) → 格式转换(RGB565→YUV420,供编码) → MPP硬编码(H.264) → FFmpeg推流(RTMP等)
如果在不使用usb免驱摄像头情况下,第一步就是使用DMA_BUF+CMA完成mipi摄像头数据0拷贝采集
mipi驱动的部分后面会更新
下面开始介绍知识点了!
在rk3588中数据从硬件(如摄像头)到达应用程序,需要经过多次拷贝。其根本原因在于操作系统对内存的保护机制和硬件对内存的特殊要求。
地址空间隔离:
-
为了安全,操作系统将内存划分为内核空间和用户空间。应用程序运行在用户空间,驱动程序运行在内核空间。它们默认不能直接访问对方的内存。
-
因此,当摄像头把数据采集到内核的缓冲区后,应用程序若想使用,内核必须执行一次拷贝操作,将数据从内核缓冲区复制到用户缓冲区。
硬件访问限制:
-
许多高性能硬件(如摄像头、GPU)内部的DMA控制器(Direct Memory Access Controller)为了性能和设计简洁,要求它操作的内存必须是物理上连续的。
-
而操作系统为应用程序分配的内存,通常只保证虚拟地址连续,物理地址可能是零散的。
这两个限制导致了传统的、低效的数据路径:硬件 -> [DMA拷贝] -> 内核连续内存 -> [CPU拷贝] -> 用户内存。这里的“CPU拷贝”就是我们想要消除的性能瓶颈。
-
解决方案一:mmap 内存映射
V4L2框架提供的第一种零拷贝方式是mmap。它的核心思想是让内核与用户共享同一块内存,从而省去两者之间的CPU拷贝。
工作流程如下:
1、内存由驱动分配:首先,应用程序请求V4L2驱动程序在内核空间分配一组用于视频采集的缓冲区。这些缓冲区通常是由驱动确保的物理连续内存。
2、建立映射:然后,应用程序通过mmap这个系统调用,将驱动在内核中分配好的那组缓冲区,一一“映射”到自己的用户空间虚拟地址中。
3、直接访问:映射建立后,应用程序就获得了一个指向那块内核缓冲区的用户空间地址。当摄像头通过DMA将数据填充到该缓冲区后,应用程序可以通过这个地址直接读取数据,无需内核再进行一次拷贝。
mmap方式的本质:它解决的是“内核空间”与“用户空间”之间的拷贝问题。数据实际上还是从硬件DMA到V4L2驱动管理的内核缓冲区中,只是用户程序通过一个“传送门”(mmap映射)直接进入这块缓冲区拿东西,省去了让内核“搬运”的环节。
局限性:这种方式下,内存的所有权和管理权在V4L2驱动手里。它很适合“摄像头 -> CPU”这种点对点的应用场景。但如果数据处理流程很复杂,比如“摄像头 -> 视频编码器(VPU) -> 网络发送”,数据需要在多个硬件模块间流转,mmap方式就显得力不从心了。因为这块内存不是一个通用的、可以在不同驱动间自由传递的“令牌”。
-
解决方案二:DMABUF —— 一种通用的内存共享契约
为了让不同的模块(如V4L2驱动、GPU驱动、显示驱动)和用户空间能安全、统一地共享内存,Linux内核需要一个标准的“中介”或“契约”。这个角色由 DMABUF 来扮演。
DMABUF的本质不是一种新的内存类型,而是一个内核框架。它的核心思想是
-
将一块连续的物理内存(无论它来自哪里)打包封装。
-
为这个封装好的内存块创建一个 文件描述符(File Descriptor, fd)来作为它的唯一标识。
这个文件描述符就像一个“通行证”。任何一个驱动程序或者应用程序,只要拿到了这个dmabuf_fd,就可以:
传递给其他驱动程序,让其他驱动也能访问这块内存。
通过mmap系统调用,将这块物理内存直接映射到自己的虚拟地址空间,从而实现直接访问。
通过这种方式,dmabuf_fd 成为了跨模块、跨驱动、跨内核与用户空间进行内存共享的标准接口。
小总结:
mmap方式:驱动分配内存,应用映射访问。它实现了“驱动(内核) -> 应用(用户)”的零拷贝,适用于简单的点对点数据流。
dmabuf方式:应用分配内存,通过fd共享给各方。它实现了“驱动A -> 驱动B -> … -> 应用”之间的通用零拷贝,适用于复杂的多设备处理流水线。
-
核心实现:CMA —— 提供硬件所需的特殊内存
现在我们有了DMABUF这个“通行证”机制,但还有一个关键问题没解决:这块被共享的、物理连续的内存从哪里来?
这就是CMA(Contiguous Memory Allocator,连续内存分配器)发挥作用的地方。
解决什么问题:正如前面所说,在系统长时间运行后,物理内存会产生大量碎片,此时再想申请一块大的、连续的物理内存会非常困难,甚至失败。
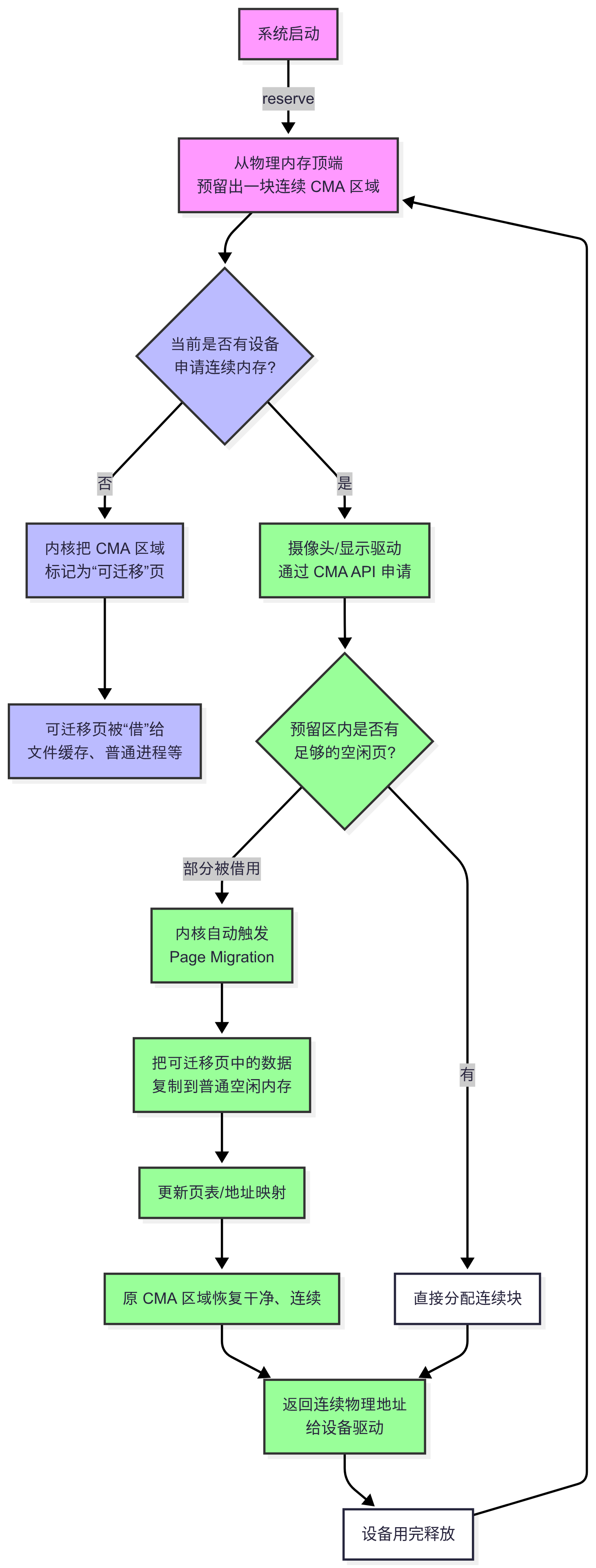
CMA的原理:为了保证总能提供出连续内存,CMA在系统启动时,就从物理内存中预留(reserve)出一大块连续的区域。
-
“预留但不独占”:这块预留的区域并不会被一直闲置浪费。当没有设备(如摄像头)需要使用连续内存时,内核可以将这块CMA区域中的内存页“借”给系统,用于普通用途(例如用作文件缓存、普通进程内存等)。这些被借出去的内存页被标记为“可迁移(movable)”的。
-
按需回收:当一个设备通过驱动程序向CMA请求一块连续内存时,CMA会开始工作。它会检查预留区中是否有足够的空间。如果部分空间已经被“借”出去了,内核会自动地、透明地将这些“可迁移”页上的数据拷贝到其他空闲的普通内存位置,然后更新相关的地址映射。这个过程叫做页面迁移(Page Migration)。当数据迁移完成后,预留区中就腾出了一块干净的、物理连续的内存块,CMA就可以把它分配给提出申请的设备。
如何使用:在Linux系统中,CMA通过/dev/dma_heap/cma这样的设备节点向用户空间提供接口。应用程序可以直接open这个设备,然后通过ioctl命令(如序列图中的DMA_HEAP_IOCTL_ALLOC)来请求分配一块由CMA管理的连续内存。成功后,会返回一个代表这块内存的dmabuf_fd。
-
功能:利用RK3588的VPU(视频处理单元)通过MPP框架进行H.264硬编码,实现1080P@30FPS且CPU占用率仅5%。
-
关键细节:
-
编码输入格式:VPU对YUV420格式处理效率最高,因此需将叠加后的RGB565帧通过RGA转换为YUV420。
-
编码参数:配置码率、I帧间隔、GOP等参数,平衡画质与延迟(如低延迟模式下减小GOP)。
-
-
实现方式:
-
启动编码线程,从 编码输入队列 取帧,通过RGA完成RGB565→YUV420转换。
-
调用MPP编码API(如
mpi_enc_send_frame)将YUV420帧送入VPU编码,输出H.264码流(NALU单元)。 -
将码流存入 推流队列。
-
完整流程
现在,我们用上面建立的知识来完整地走一遍序列图中的流程。
阶段一:初始化和内存分配
1、打开 /dev/video0: 应用程序打开V4L2摄像头设备。
2、VIDIOC_QUERYCAP / VIDIOC_S_FMT: 查询设备能力、设置视频格式。这是标准的V4L2准备工作。
3、VIDIOC_REQBUFS(DMABUF, 3): 关键步骤。应用程序告诉V4L2驱动,它需要3个缓冲区,并且缓冲区的类型是DMABUF。这表示应用程序会自己从外部提供内存,而不是让V4L2驱动自己去分配。
4、打开 /dev/dma_heap/cma: 应用程序打开CMA堆设备,准备申请物理连续内存。
5、循环分配缓冲区 [loop]:
-
DMA_HEAP_IOCTL_ALLOC: 应用程序通过ioctl向CMA请求分配一块内存。CMA执行我们上面讲的“页面迁移”等操作,准备好一块物理连续内存,并返回一个dmabuf_fd来代表它。
-
mmap(mapped_addr): 应用程序调用mmap,将刚刚得到的dmabuf_fd所代表的物理内存,映射到自己的虚拟地址空间。这样,CPU就可以通过mapped_addr这个虚拟地址直接读写这块内存了。
阶段二:视频采集
-
VIDIOC_QBUF(dmabuf_fd): 关键步骤。应用程序将包含dmabuf_fd的缓冲区“入队”(Queue)给V4L2驱动。V4L2驱动从dmabuf_fd中解析出这块内存的物理地址。
-
VIDIOC_STREAMON: 启动视频流。此时,摄像头的DMA控制器被配置为:当捕获到一帧图像后,直接将图像数据写入到VIDIOC_QBUF传入的那个dmabuf_fd所对应的物理地址上。
-
poll(): 应用程序等待,直到驱动通知有数据准备好。
-
VIDIOC_DQBUF: 应用程序将填满数据的缓冲区“出队”(Dequeue)。它拿到的是缓冲区的索引等信息,但数据本身已经在之前mmap好的mapped_addr里了。
-
DMA_BUF_IOCTL_SYNC (START): 重要同步步骤。因为数据是硬件(DMA)写入的,可能还停留在高速缓存(Cache)中而没有完全写到主内存,或者CPU的缓存不是最新的。此操作确保CPU访问时能看到硬件写入的最新数据。
-
write(image_data): 应用程序通过mapped_addr直接访问数据(例如保存成文件)。注意,这里没有发生内核到用户的拷贝。
-
DMA_BUF_IOCTL_SYNC (END): 如果CPU修改了数据,此操作确保修改后的数据对硬件可见
-
VIDIOC_QBUF: 应用程序将处理完的缓冲区再次入队,循环使用

后续操作
-
对接 RGA 预处理:可将
dmabuf_fd直接传递给 RGA 接口(如importbuffer_fd),实现硬件加速格式转换(YUV420→RGB565),无需数据拷贝。 -
对接 VPU 编码:处理后的 DMABUF 可直接送入 MPP 硬编码模块,RGA 处理后的缓冲区仍以
dmabuf_fd形式存在。实现 “采集→预处理→编码” 全链路零拷贝。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)