解读 DeepSeek V3.2 稀疏注意力机制(DSA)
详解DeepSeek V3.2新引技术——“DeepSeek Sparse Attention”(DSA)稀疏注意力机制
DeepSeek新放出了DeepSeek-V3.2-Exp模型。
模型的重点,是在 V3.1-Terminus 的基础上引入了DeepSeek稀疏注意力机制(Sparse Attention)DSA。DSA的原理主要是从Query token中筛选出重要的token进行attention注意力计算,即在原有模型架构上再做一次attention score计算,然后选择TopK的token attention score 。这使得模型在处理长上下文文本时,推理成本大大降低,推理效率得到显著提升。

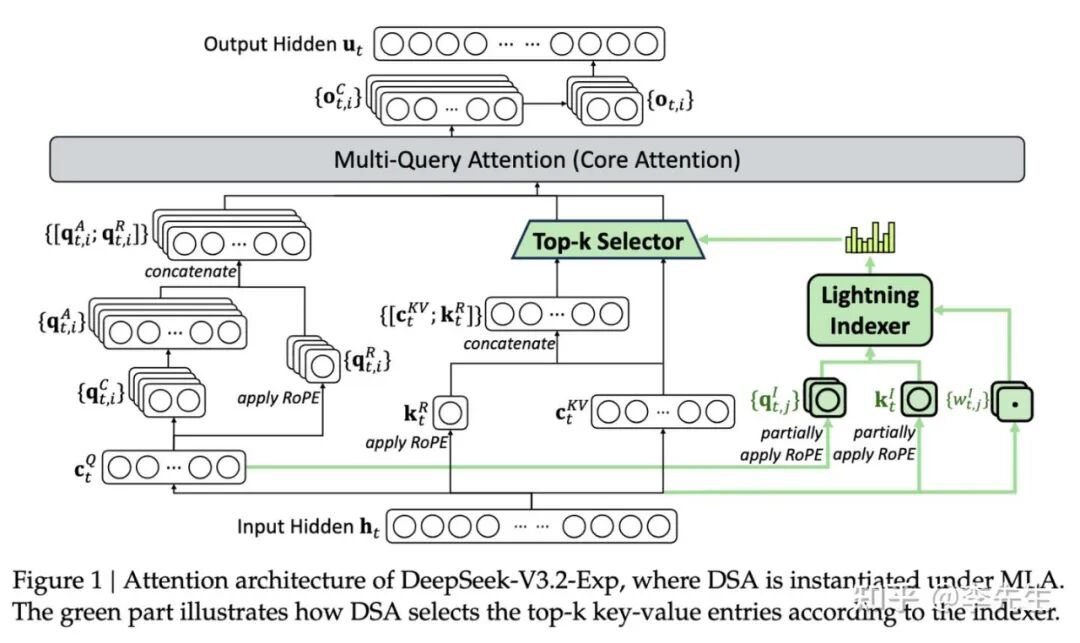
DeepSeek-V3.2模型架构图
从上面文章中可以看出V3.2模型架构中引入了一个可学习模块Lightning Indexer
接下来讲述一下Lightning Indexer的计算过程:
Lightning Indexer的计算过程是DeepSeek V3.2模型实现高效稀疏注意力的核心,通过轻量级架构将原本O(L²)的注意力计算复杂度降至O(L×k)(k通常为2048)。其核心逻辑是对高维输入进行低维投影后快速计算相关性得分,最终筛选出Top-k关键token参与后续精细注意力计算,以下是具体步骤:
1. 输入准备与低维投影
首先,模型将输入的高维隐藏状态(维度通常为7168维)通过线性层投影到低维空间,以降低计算成本:
<1>Query投影:输入token的隐藏状态 Xt 先通过LoRA降维矩阵
![]()
压缩至1536维,再通过
![]()
投影为128维的索引Query向量 。这一过程通过代码中的 wq_a(降维)和 wq_b(升维为多头格式)实现
<2>Key投影:历史token的隐藏状态通过线性层 Wk(7168×128)直接投影为128维的索引Key向量 ,对应代码中的 wk 层
<3>权重投影:通过线性层
![]()
生成每个注意力头的动态权重 ,用于后续得分加权,对应代码中的 weights_proj。
2. 位置编码与量化优化
为保留序列位置信息并进一步提升效率,模型会对投影后的向量进行处理:
<1>旋转位置编码(RoPE):将Query和Key向量的前64维(rope_head_dim)拆分出来,应用旋转位置编码后与剩余维度拼接,确保模型感知token的相对位置。
<2>FP8量化:对Query和Key向量进行FP8精度量化(act_quant函数),并缓存量化后的Key向量(k_cache)及缩放因子(k_scale_cache),显著降低内存占用与计算延迟
3. 相关性得分计算(核心步骤)

<1>点积与激活:每个头的低维Query与Key向量先做点积(q·k),再通过ReLU激活函数过滤负值(选择ReLU是因其计算效率远高于Softmax)
<2>多头加权:用动态权重对多头得分进行加权求和,得到最终相关性得分。代码中通过 fp8_index 函数实现高效的低精度矩阵乘法。
4. Top-k筛选与结果输出
![]()
<1>Top-k选择:通过 topk 函数选取得分最高的 index_topk(通常设为2048)个token,生成其位置索引 topk_indices。
<2>分布式同步:在多GPU环境下,通过 dist.broadcast 确保各设备间的索引一致性,避免计算偏差。
关键设计亮点
轻量级架构:通过低维投影(128维)和少量索引头(如64头),将计算成本压缩至主注意力模块的1/10以下。
硬件适配:全程采用FP8精度和自研DeepGEMM算子,充分利用GPU的低精度计算单元,吞吐量较FP16提升3倍以上
动态稀疏性:不同于固定窗口机制,索引器根据输入内容动态选择关键token,在128K长文本中仅需关注2048个核心token,实现效率与精度的平衡
这一过程为后续的细粒度注意力计算(MLA模块)提供精准输入,使DeepSeek V3.2在处理超长文本时,既能保持精度又能将计算量降低60%以上。如何在低维投影中保留关键语义信息,仍是此类稀疏注意力机制未来优化的核心方向。
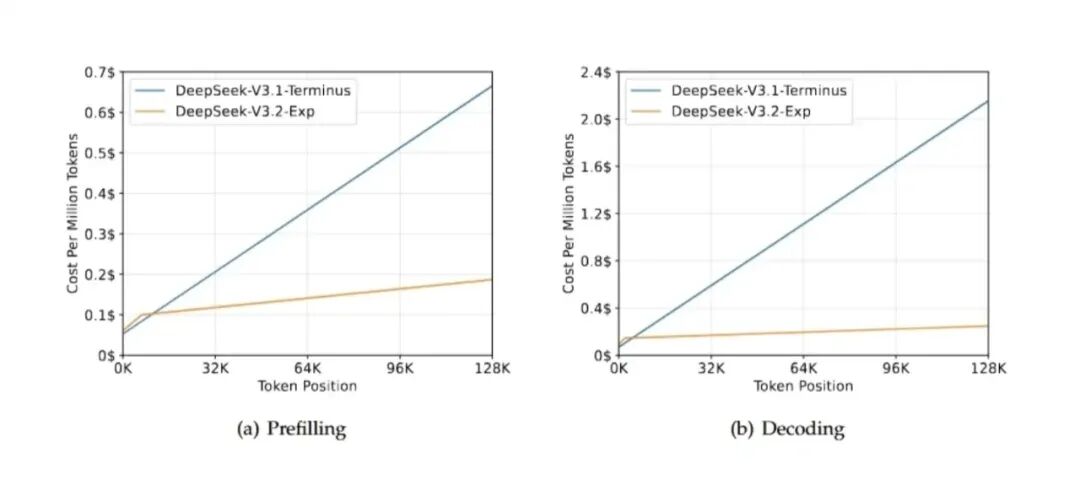
图片是 DeepSeek-V3.1-Terminus 与 DeepSeek-V3.2-Exp 在 128K 长上下文 场景下的 KV-cache 显存占用 对比曲线,分为两个阶段:
(a) Prefilling(预填充阶段)
(b) Decoding(解码阶段)
横轴:Token Position(已处理的 token 位置,0 → 128K)
纵轴:Memory Cost(显存开销,$ 符号只作单位标记,数值越低越好)
(a) Prefilling阶段 两条曲线几乎重合,线性缓慢上升,V3.2-Exp 仅低 ≈0.1$,优势极小;说明在长序列一次性编码阶段,两代压缩率基本一致。
(b) Decoding阶段 差距迅速拉开,V3.2-Exp 显存爬坡更缓,到 128K 时 V3.2-Exp 节省 33% 显存;曲线斜率更小,意味着每新增 1K token 额外开销更低,长对话推理性价比更高。
一句话总结:
V3.2-Exp 引入DSA(稀疏注意力机制)后,在解码阶段通过更高效的 KV-cache 压缩,把长文本推理的显存开销砍了三分之一,而预填充阶段几乎不增加额外工程复杂度,是面向“超长上下文、低成本部署”的关键升级。
实际意义:
1.更长对话:在同样 80G GPU 上,V3.2-Exp 可比 V3.1 多支撑 ≈50% 的上下文长度,或把 batch size 放大近一倍,显著降低线上推理成本。
2.边缘部署:对显存受限的推理终端,33% 的节省可直接决定能否跑 128K 模型。
3.性能 trade-off:图中未给出吞吐量或 PPL 变化,但官方敢把实验版放进对比,通常意味着压缩带来的精度损失已控制在 1–2% 以内,属于“可接受”区间。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)