【大模型】一文掌握大模型应用开发全流程指南,值得收藏。
关于大模型的技术演进趋势技术方向代表技术预期影响模型架构MoE混合专家系统同等效果参数减少30%训练范式联邦学习解决数据隐私问题推理部署手机端大模型端侧运行70亿参数模型多模态世界模型实现物理场景模拟HuggingFace → LangChain → 自定义微调我是小鱼CSDN 博客专家;阿里云 专家博主;51CTO博客专家;企业认证金牌面试官;多个名企认证&特邀讲师等;名企签约职场面试培训、职场
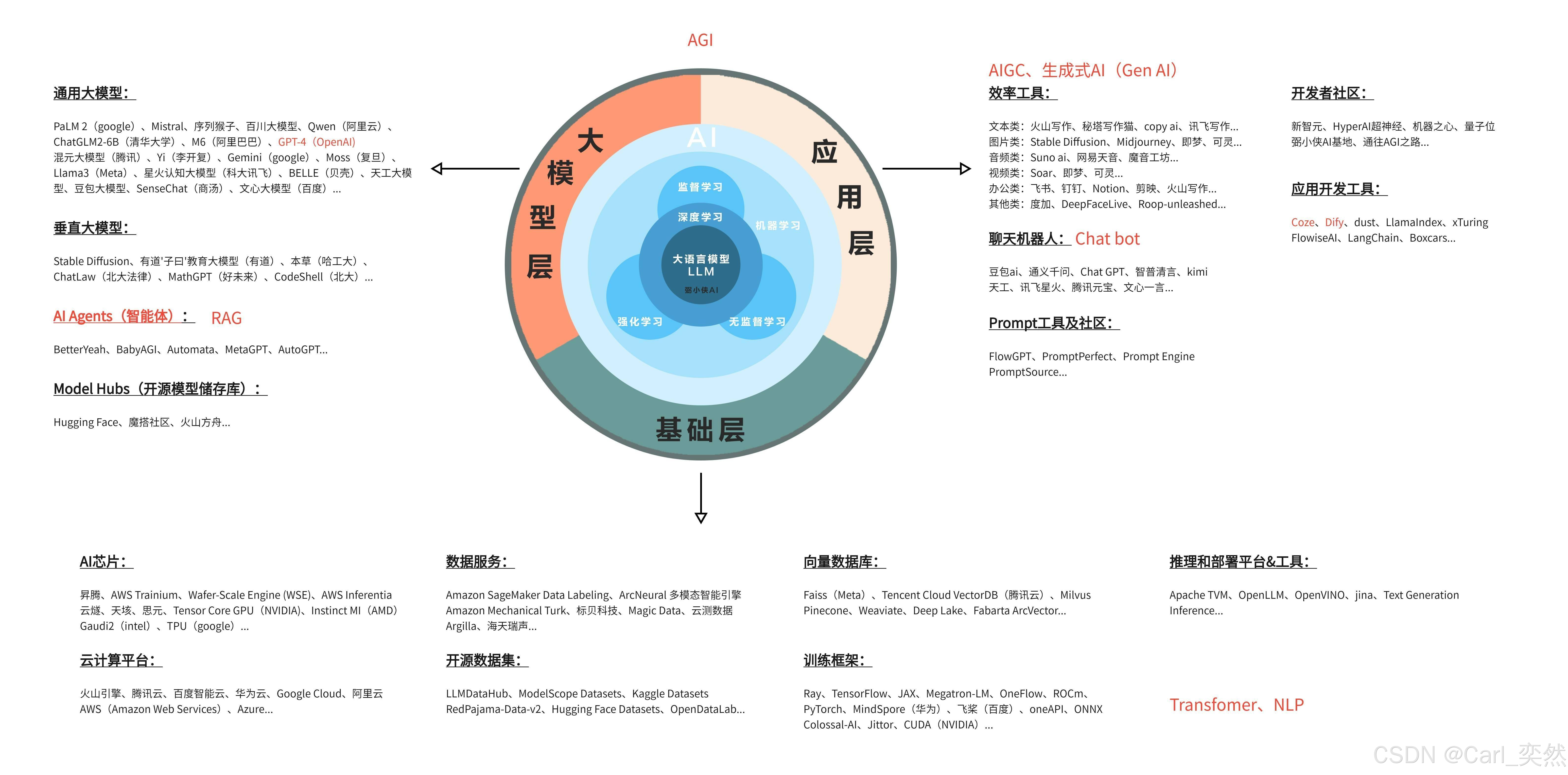
大模型开发全流程
1、 大模型应用开发核心流程
2.2 项目规划阶段
关键步骤:
-
需求分析:明确业务场景(如智能客服、文档摘要)
-
场景定义:确定输入输出形式(文本→文本/多模态→表格)
-
技术选型:7B/13B/70B模型选择(精度 vs 推理成本)
-
资源评估:GPU显存需求估算(模型参数×4~8倍)
1.2 数据处理
数据流水线架构:
# 数据预处理示例
from datasets import load_dataset
dataset = load_dataset("json", data_files="raw_data.json")
dataset = dataset.map(
lambda x: {"text": x["content"].strip()[:2000]}, # 截断处理
remove_columns=["metadata"]
).filter(
lambda x: len(x["text"]) > 50 # 过滤短文本
)
dataset.save_to_disk("processed_data")
数据质量要求:
| 指标 | 建议值 | 检测方法 |
|---|---|---|
| 文本长度 | 平均500字符 | 统计分布直方图 |
| 重复率 | <5% | MinHash LSH检测 |
| 信息密度 | >0.8 | TF-IDF加权计算 |
2、核心技术栈全景解析
2.1 大模型技术栈分层架构
├── 1️⃣ 基础设施层
│ ├── GPU集群:NVIDIA A100/H100
│ ├── 分布式存储:Ceph/GPFS
│ └── 网络:RDMA高速网络
├── 2️⃣ 计算框架层
│ ├── PyTorch + DeepSpeed
│ ├── Megatron-LM
│ └── JAX (Google TPU专属)
├── 3️⃣ 模型架构层
│ ├── 基座模型
│ │ ├── LLaMA-2
│ │ ├── Falcon-40B
│ │ └── ChatGLM3
│ └── 微调方案
│ ├── LoRA/QLoRA
│ └── P-Tuning v2
├── 4️⃣ 推理服务层
│ ├── vLLM(动态批处理)
│ ├── TensorRT-LLM(NVIDIA优化)
│ └── Triton Inference Server
└── 5️⃣ 应用集成层
├── LangChain(应用编排)
├── LlamaIndex(知识库增强)
└── FastAPI/Gradio(服务部署)
2.2 关键技术组件对比
| 技术点 | 推荐方案 | 优势 |
|---|---|---|
| 显存优化 | DeepSpeed ZeRO-3 | 支持千亿级模型训练 |
| 注意力加速 | FlashAttention-2 | 训练速度提升3倍 |
| 量化部署 | GPTQ/AWQ | 4bit量化精度损失<1% |
| 服务框架 | vLLM | 支持动态批处理,吞吐量提升5倍 |
3、场景及代码
3.1 智能文档处理系统
-
流程图:
用户上传PDF → 文本提取 → 大模型摘要 → 结果存储 → API返回 -
代码示例
# 文档摘要流水线
from langchain.document_loaders import PyPDFLoader
from transformers import pipeline
loader = PyPDFLoader("report.pdf")
pages = loader.load_and_split()
summarizer = pipeline("summarization",
model="Falcon-7b-instruct")
summary = []
for page in pages[:3]: # 处理前3页
result = summarizer(page.page_content,
max_length=150,
do_sample=False)
summary.append(result[0]['summary_text'])
print("\n".join(summary))
3.2 多模态商品推荐
代码示例
# 图文跨模态检索
import torch
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(...)
# 图像特征提取
image = Image.open("product.jpg")
inputs = processor(images=image, return_tensors="pt")
image_features = model.vision_model(**inputs).last_hidden_state
# 文本特征比对
text_inputs = processor(text=["时尚手提包", "运动双肩包"],
return_tensors="pt", padding=True)
text_features = model.text_model(**text_inputs).last_hidden_state
# 计算相似度
similarity = torch.matmul(image_features, text_features.T)
print(f"匹配度:{similarity.softmax(dim=-1).tolist()}")
4、模型开发全流程代码示例
4.1 LoRA微调实战
# 使用QLoRA微调Llama2
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import AutoModelForCausalLM, TrainingArguments
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
load_in_4bit=True,
device_map="auto"
)
# 准备模型
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none"
)
model.add_adapter(peft_config)
# 配置训练参数
args = TrainingArguments(
output_dir="output",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
fp16=True,
optim="paged_adamw_8bit"
)
# 开始训练(伪代码)
trainer = CustomTrainer(model, args, train_dataset=dataset)
trainer.train()
4.2 RAG增强问答系统
# 基于LangChain实现
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
# 构建知识库
embedder = HuggingFaceEmbeddings("sentence-transformers/all-mpnet-base-v2")
documents = load_company_docs() # 自定义文档加载
vector_db = FAISS.from_documents(documents, embedder)
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llama2_7b,
retriever=vector_db.as_retriever(search_kwargs={"k":3}),
chain_type="stuff"
)
# 执行查询
response = qa_chain.run("我司的售后服务政策包含哪些内容?")
print(response)
五、性能优化关键策略
5.1 训练加速方案
3D并行配置示例:
# DeepSpeed配置模板
{
"train_batch_size": 256,
"fp16": {"enabled": true},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu"
}
},
"pipeline": {
"stages": 4,
"activation_checkpoint_interval": 1
}
}
5.2 推理优化技术
vLLM服务部署:
# 启动API服务
python -m vllm.entrypoints.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.9
量化推理示例:
# 使用AutoGPTQ加载4bit模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Llama-2-7B-GPTQ",
device_map="auto",
revision="gptq-4bit-32g-actorder_True"
)
6、总结
关于大模型的技术演进趋势
| 技术方向 | 代表技术 | 预期影响 |
|---|---|---|
| 模型架构 | MoE混合专家系统 | 同等效果参数减少30% |
| 训练范式 | 联邦学习 | 解决数据隐私问题 |
| 推理部署 | 手机端大模型 | 端侧运行70亿参数模型 |
| 多模态 | 世界模型 | 实现物理场景模拟 |
如果要入门, 那必须要学的路线:HuggingFace → LangChain → 自定义微调
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【机器视觉与目标检测】 和【人工智能与大模型】最新最全的领域知识。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)