Windows下简易Playwright+MCP Server安装及实现(无ai,单纯理解)
想运行以下代码请先安装vscode以及python。
想运行以下代码请先安装vscode以及python
1.环境安装
首先安装node.js:Node.js — Download Node.js®
安装完成后打开cmd安装所需要的包
mkdir C:\playwright-mcp
cd C:\playwright-mcp
npm init -y
npm install playwright expressnpx playwright install
npm install node-fetch@2
从vscode中打开playwright-mcp文件夹创建mcp-server.js文件,内容如下所示:
const { chromium } = require('playwright');
const express = require('express');
const app = express();
const PORT = 3000;
app.get('/launch', async (req, res) => {
try {
const browserServer = await chromium.launchServer({ headless: true });
const wsEndpoint = browserServer.wsEndpoint();
console.log('Launched browser:', wsEndpoint);
res.send({ wsEndpoint });
} catch (error) {
console.error('Failed to launch:', error);
res.status(500).send('Error launching browser');
}
});
app.listen(PORT, () => {
console.log(`MCP Server running on http://localhost:${PORT}`);
});
创建client.js文件
const { chromium } = require('playwright');
const fetch = require('node-fetch'); // 兼容 Node 18 以下
const fs = require('fs');
const path = require('path');
async function runAutomation(url, filename = 'screenshot.png') {
const response = await fetch('http://localhost:3000/launch');
const { wsEndpoint } = await response.json();
const browser = await chromium.connect({ wsEndpoint });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto(url, { waitUntil: 'domcontentloaded', timeout: 15000 });
const screenshotPath = path.join(__dirname, 'screenshots', filename);
await page.screenshot({ path: screenshotPath });
await browser.close();
return filename; // 返回文件名
}
module.exports = { runAutomation };
创建一个新的API后端server.js
const express = require('express');
const path = require('path');
const { runAutomation } = require('./client');
const app = express();
const PORT = 8080;
app.use(express.static('public')); // 提供前端页面
app.use('/screenshots', express.static(path.join(__dirname, 'screenshots')));
// 简单截图 API:GET /screenshot?url=https://xxx
app.get('/screenshot', async (req, res) => {
const { url } = req.query;
if (!url) return res.status(400).send('Missing URL');
const filename = `screenshot-${Date.now()}.png`;
try {
await runAutomation(url, filename);
res.send(`/screenshots/${filename}`);
} catch (err) {
console.error(err);
res.status(500).send('Failed to capture screenshot');
}
});
app.listen(PORT, () => {
console.log(`📸 Web server running at http://localhost:${PORT}`);
});
最后写一个前端的页面index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>网页截图演示</title>
</head>
<body>
<h1>Playwright 截图工具</h1>
<input type="text" id="url" placeholder="输入网址" size="50">
<button onclick="takeScreenshot()">截图</button>
<p id="status"></p>
<img id="result" style="max-width: 100%; margin-top: 10px;" />
<script>
async function takeScreenshot() {
const url = document.getElementById('url').value;
if (!url) return alert('请输入网址');
document.getElementById('status').innerText = '正在截图,请稍候...';
try {
const res = await fetch(`/screenshot?url=${encodeURIComponent(url)}`);
if (!res.ok) throw new Error('请求失败');
const imgPath = await res.text();
document.getElementById('result').src = imgPath;
document.getElementById('status').innerText = '截图成功!';
} catch (err) {
console.error(err);
document.getElementById('status').innerText = '截图失败';
}
}
</script>
</body>
</html>
所有文件夹的形式如下所示
playwright-web/
├── mcp-server.js
├── client.js
├── public/
│ └── index.html
├── server.js
├── screenshots/
│ └── *.png
└── package.json
所有代码保存完毕后打开两个cmd窗口分别运行以下两个命令
node mcp-server.js
node server.js
然后你就可以通过http://localhost:8080 访问网站了,网站内部大概长这个样子:
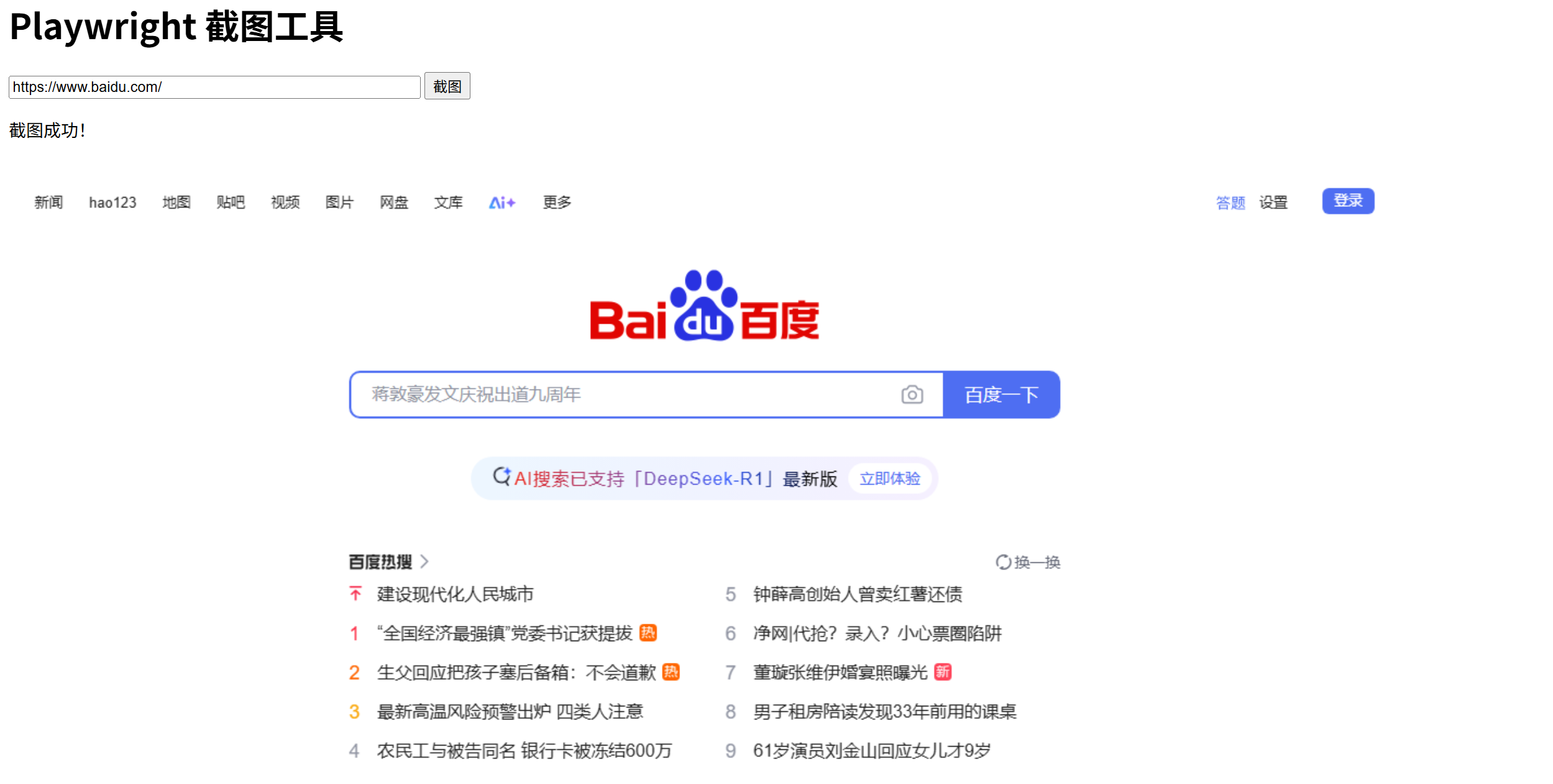
把想要截图的网站输入到对话框里点击截图按钮就可以完成截图操作了,图片保存在当前目录的文件夹里
上述就是整个完整的流程了,可以看到整个了流程是十分简单的,但是当我自己写到这里的时候我就会有一个疑问,就是到底这样的一个MCP架构跟我们平时使用的Flask架构的区别是什么呢?因为同样修改后端我们都是需要进入到代码里面更改,不同的就是可能Flask我修改对应的后端代码,然后MCP就是修改client.js和server.js,那么他们到底有什么区别
针对上述我自己的问题我总结了一下:
最本质的区别就是flask在多用户访问的时候可能会出现问题,而MCP就是每个用户过来访问的不是同一个东西,相当于是server给每一个用户都分配了一个不同的浏览器对象然后进行不同的操作,这样隔离做的更好
具体MCP服务的流程如下:
① 用户 → 在前端页面输入网址,点击按钮
↓
② 前端 → 发 HTTP 请求到 server.js(比如 /screenshot?url=xxx)
↓
③ server.js → 接收到请求,调用 client.js 的函数
↓
④ client.js → 向 MCP Server(mcp-server.js)发请求,让它启动浏览器
↓
⑤ MCP Server → 启动浏览器实例,返回 wsEndpoint 地址
↓
⑥ client.js → 连接 wsEndpoint,开始控制浏览器操作页面
↓
⑦ client.js → 截图 / 抽取数据等操作完成
↓
⑧ server.js → 收到结果,返回前端
↓
⑨ 用户 → 得到截图 / 数据,看到结果
就相当于有个中继站,而且对应的js也可以隔离存储,不像Flask,因为我个人也写过Flask代码,后端所有的代码都放在一起,也就是一整个文件就是Flask后端了
针对具体工程肯定代码量是不止上述这么一点的,上述内容只是对于PlayWright+MCP的一个简要的学习过程记录,整个的思维流程应该是MCP是做什么的,然后到那这样的一个MCP服务跟我们平时熟知的Flask有什么区别,通过以上的流程就能够大致知道PlayWright+MCP具体做了一个什么事儿,然后具体的工程就更改对应的代码就可以了

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)