GPU性能参数看不懂?我来帮你搞定 NVIDIA H200
本指南详细介绍了GPU计算中的核心性能指标和数据类型规格。文档涵盖了TFLOPS、TOPS、PFLOPS等关键计算单位的定义,深入分析了FP64、FP32、FP16、FP8等不同精度浮点数格式的特性差异。重点对比了BF16、TF32、FP32三种主流浮点格式在位宽、精度、存储占用和应用场景方面的优劣势。此外,还详细比较了NVIDIA H200 SXM与NVL两种不同形态因子的技术规格,包括连接接口
·
计算单位解释
TFLOPS = 每秒万亿次浮点运算
TOPS = 每秒万亿次整数运算
PFLOPS = 每秒千万亿次浮点运算
数据类型解释
- FP64双精度浮点数、FP32单精度浮点数、FP16半精度浮点数、FP8 8位浮点数、INT8 8位整数。
- Tensor Core:使用专门的Tensor Core单元,矩阵运算,并行处理大块数据。
| 特性 | BF16 (BFLOAT16) | TF32 (TensorFloat-32) | FP32 (IEEE 754) |
|---|---|---|---|
| 位宽 | 16位 | 19位 (计算时) | 32位 |
| 位分布 | 1符号+8指数+7尾数 | 1符号+8指数+10尾数 | 1符号+8指数+23尾数 |
| 数值范围 | ≈ FP32范围 (±10⁻³⁸~10³⁸) | 完全继承FP32范围 | 标准范围 (±10⁻³⁸~10³⁸) |
| 精度 (尾数位) | 低 (7位) → 误差~10⁻³ | 中 (10位) → 误差~10⁻⁵ | 高 (23位) → 误差~10⁻⁷ |
| 存储占用 | 16位/数 (显存减半) | 计算19位,存储32位 (兼容FP32) | 32位/数 |
| 硬件需求 | Ampere架构及以上 (A100/H100) | Ampere架构及以上 (A100/H100) | 所有CUDA GPU |
| 设计目标 | 训练稳定性 (大范围防溢出) | 训练速度 (平衡范围与效率) | 计算精度 (通用高精度) |
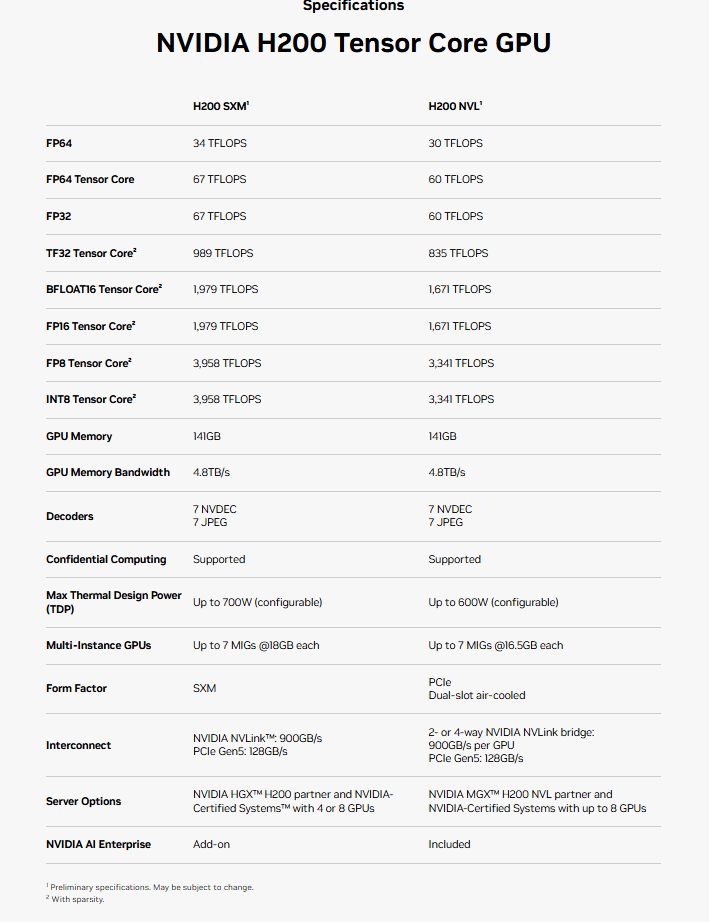
H200 SXM vs NVL
H200 SXM:
- 模块化设计,直接插入专用的SXM插槽
- 主要用于NVIDIA HGX系统架构
- 内置高速NVLink接口
- 支持更高带宽的GPU间通信
- 适合大规模GPU集群
- 最大功耗700W (可配置)
H200 NVL:
- 采用PCIe形态因子
- 标准的PCIe接口,兼容性更好
- 适用于传统的x86服务器架构
- 需要外部NVLink桥接器
- 支持2-4路GPU互连
- PCIe Gen5 128GB/s带宽
- 最大功耗600W (可配置)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)