收藏!从提示工程到上下文工程:零代码实现ACE智能体,打造超智能AI助手
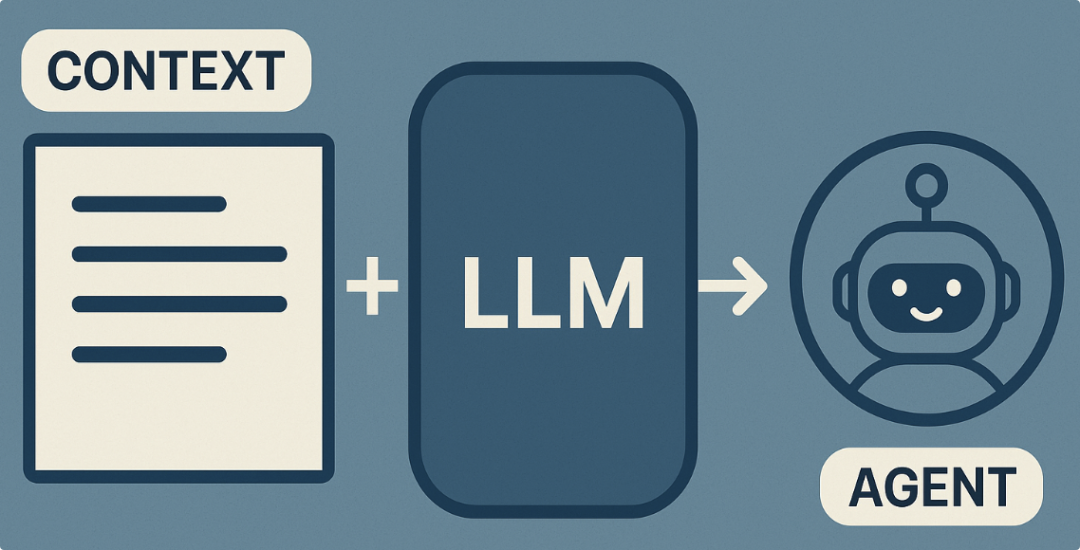
Shopify的CEO Tobi Lutke这样形容上下文工程:为LLM提供所有用于合理解决任务的上下文信息的艺术。如果说上下文是LLM的RAM(来自OpenAI 前研究科学家 Karpathy的比喻),那么上下文工程(Context Engineering)就是 — 设计并实施这块有限 RAM 的管理机制,让信息的组织、输入、更新、淘汰都更有秩序与目的性。上下文工程不是简单的提示模板设计与堆叠(
最近,斯坦福大学等团队联合提出了一种上下文工程方法:Agentic Context Engineering(ACE)。让智能体无需微调,也能通过上下文的不断演化实现自我学习与进化。
1、为什么上下文需要“工程”?
现在的上下文窗口已经普遍达到128K以上甚至1M,这给了智能体勃勃生机的无线可能:你可以把大量智能体需要的东西(指令、知识、工具等)都丢进一次Prompt中,让LLM自由的推理、规划、行动。
但为什么智能体的表现仍然不尽如人意?问题的原因不在于上下文能“装”多少,而在于最终LLM“消化”的是什么。LLM的输出永远存在不确定性——这是架构层面注定的事实。在模型尚未发生质变之前,我们能控制的唯一变量,就是它的输入:上下文(Context)。
而控制上下文,更大的“胃口”(窗口大小)固然重要;但更重要的是“营养”(质量)。大量的测试表明,更长的上下文并不确定会带来更好的结果:其中可能的冗余、冲突、错误(幻觉)信息都会让LLM迷失方向。
即使上下文内容完全正确,当输入规模过大时,LLM的“注意力”也可能会被分散,关键指令或语义线索被淹没,导致模型理解出现偏移与错位,甚至在推理中“跑题”。
更重要的是,在智能体的多轮推理中,微小的偏差会不断“叠加”,最终Agent任务可能完全“南辕北辙”。
这就是为什么需要上下文工程(Context Engineering):
当LLM可以“吞”下更多内容时,你需要确保“营养搭配”:有结构、有逻辑、有重点,而不仅仅是“堆料”。
2、什么是上下文工程?
Shopify的CEO Tobi Lutke这样形容上下文工程:
为LLM提供所有用于合理解决任务的上下文信息的艺术。
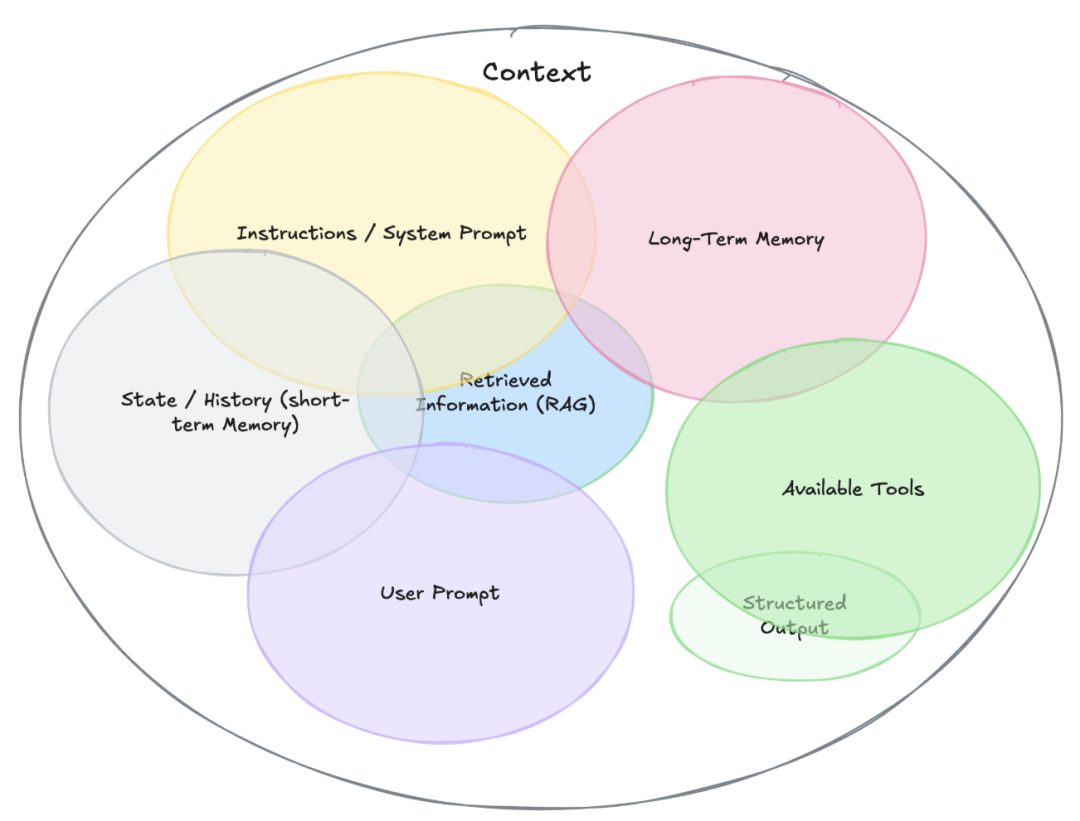
如果说上下文是LLM的RAM(来自OpenAI 前研究科学家 Karpathy的比喻),那么上下文工程(Context Engineering) 就是 — 设计并实施这块有限 RAM 的管理机制,让信息的组织、输入、更新、淘汰都更有秩序与目的性。
上下文工程不是简单的提示模板设计与堆叠(尽管提示模板是它的一角)。它需要关注到更深层次的一系列结构性问题与工程方法:
-
包含哪些信息,如何组织,什么格式?
行业知识或工具指南,或者更多,如何分类排序?
普通文本还是半结构化的JSON、Markdown?
-
信息从哪里,又在什么时候获取?
是来自企业内部数据库还是互联网、或Agent产生?
是原始输入还是通过中间步骤动态注入?
-
信息如何产生,如何存储,又是如何检索?
静态信息、缓存信息、动态生成与检索?
传统索引、向量数据库,还是实时 Web 搜索?
-
信息是否需要清洗、标注、压缩?
是否需要去除冗余、噪音、重复,并标注出重点?
上下文是否需要压缩(如长期记忆)?
-
信息是否需要有生命周期管理?
哪些内容持久存在,哪些随时间与任务衰减?
信息过期机制,滑动窗口、基于使用次数还是LLM判断?
总之,上下文工程更像是为LLM建立一套语义的“供应链”,让LLM得以正确理解和推理 — 从而让Agent做出正确的决策。
3、上下文工程的常见策略
上下文工程涵盖很多不同的方法与技术。在实践中,有一些经过验证、可复用的策略,能帮助我们更好地实施上下文工程,这里为大家总结:
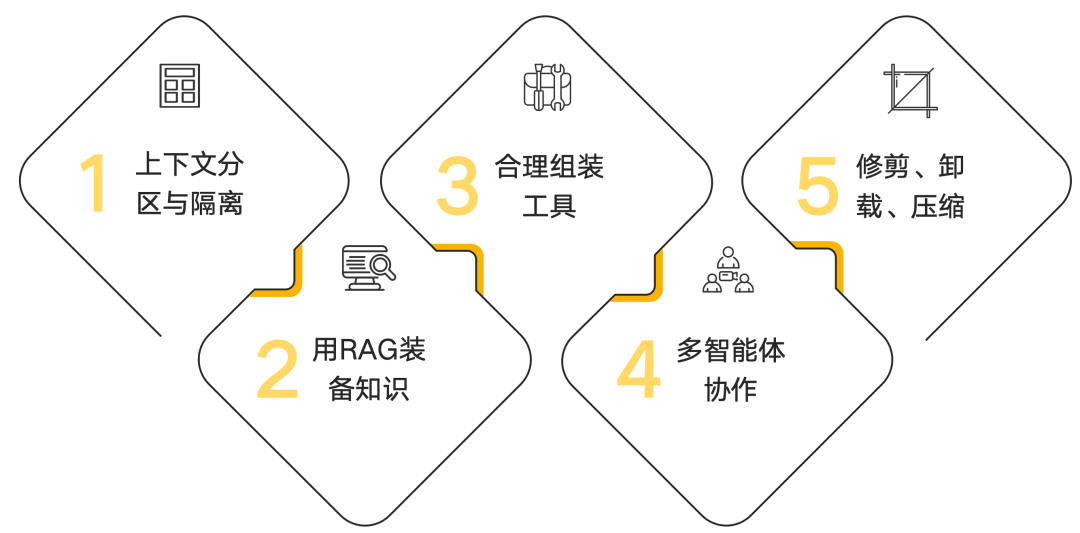
1)上下文分区与隔离
为了让“RAM”中的信息不打架、逻辑不混乱,可以对上下文进行分区:
- 将上下文划分为指令层、目标层、记忆层、知识层、工具层等
- 为每一层分配独立的 Token 预算与出现顺序,确保关键信息始终可见
- 给不同的角色(如规划器、执行器、反思器)分配不同的上下文切片,避免信息冗余与推理“漂移”
2)用RAG装备知识
- 通过检索召回相关的知识,动态注入上下文。
- 不要迷信超大上下文窗口 – “把所有东西都塞进窗口”。太多的垃圾信息,只会让LLM又傻又慢。上下文不是简单的“堆料”,而是“选料”。
3)合理组装工具(Tools)
工具(Tools)是Agent的手脚,上下文工程要教他如何用手脚:
- 给每个工具以清晰、没有歧义的“说明书”(如函数Docstring)
- 仅装载最相关的工具,比如用RAG来筛选工具描述
- 让工具的异常返回具有清晰的“引导性”,而不是简单的“Tool Error”
4)多智能体协作
在大型的Agent任务中,多Agent是一种常见的架构模式:
- 每个子Agent拥有各自独立的上下文窗口与任务焦点,本身就是一种上下文隔离,减少干扰的手段
- 让单Agent推理100个工具,不如让五个Agent各推理20个,再加一个协调者
- 多Agent设计可以遵循模块设计经典原则“高内聚、低耦合”
5)修剪、卸载、压缩
在长程推理任务的Agent中,你需要考虑应对上下文的“滚雪球”式的膨胀:
- 修剪:适时删除不相关的信息。可借助LLM或者规则引擎来判断
- 卸载:让Agent在上下文之外”记笔记”,比如把阶段性结果写入外部存储,必要时再引用(如工具输出、动态规则等)
- 压缩:通过摘要或语义聚合让上下文更紧凑,提高信息密度而不过度冗长。
当然,除了这些重要的上下文策略,传统提示工程中的技巧仍然奏效:比如指令既不能太死板,也不能太空洞;提供少量但多样化的few-shot等。
4、Agentic上下文工程(ACE)是什么?
Agentic上下文工程(Agentic Context Engineering)是由斯坦福大学、SambaNova、UC 伯克利团队提出的一种上下文工程框架,,其核心理念是:
不用微调,不改变模型参数,让智能体自己成长。
换句话说,ACE 的目标不是“训练一个更聪明的LLM”来让Agent更聪明,而是让Agent学会“训练自己” — 通过不断调整和丰富它的上下文,实现一种类似“自我学习”“自我成长”的能力。
ACE采取了怎样的方法呢?
ACE 给上下文带入一份可以不断演化的**“策略手册(Playbook)”**。每次任务执行,Agent会从自己的表现中总结经验并修正,并带着改进后的“宝典”进入下一轮。如此循环往复,Agent的能力也随之积累与升级。
假设有一个客服智能体,负责回答用户的退换货问题。
-
第一次任务中,它在处理“退款到账时间”的问题时,给出了笼统的回答:“一般需要1–7个工作日。”
-
但用户追问后发现该回答并不准确,因为不同支付方式的退款周期不同。
-
任务结束后,反思器(Reflector)开始分析了这次对话的轨迹与失败原因:
“我没有区分支付渠道(支付宝、微信、信用卡),
导致回答模糊,用户体验不佳。”
- 接着,策划器(Curator) 会把这条经验转化为Playbook中的“经验”。这条经验会被注入到下一次任务的智能体上下文
“当回答退款周期问题时,需根据支付方式提供具体时间范围。”
- 第二次任务,当智能体再次遇到类似问题时,参考这条经验,回答变成:
“若您通过支付宝付款,退款通常在 1–2 个工作日内到账;
若使用信用卡,银行处理可能需要 3–7 个工作日。”
这就是一次完整的“ACE 循环”:
生成 → 反思 → 策划 → 再执行。
智能体没有改模型参数,却通过上下文的演化,
学会了更精准、更符合场景的回答。
5、Agentic上下文工程(ACE)原理与架构
ACE通过四个核心组件的协同工作,实现了 Agent 的持续学习和自我进化。这四个组件形成了一个完整的学习循环,让 Agent 能够从每次执行中积累经验,并将这些经验转化为可复用的策略:
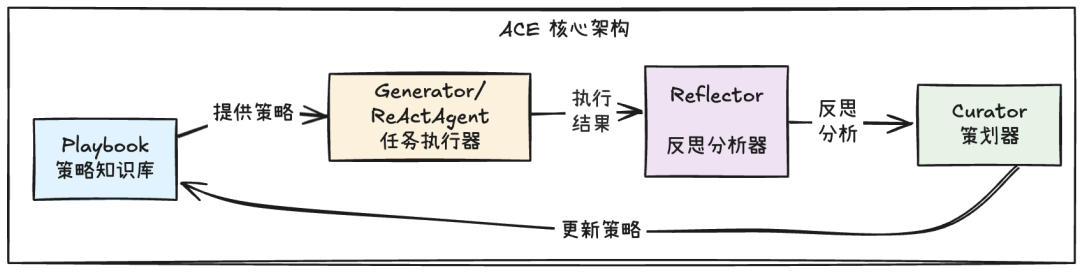
- 策略知识库(Playbook)-- “记忆体”
ACE系统的"记忆中枢",负责存储和管理 Agent 在实践中学到的所有策略。它不是一个简单的数据存储,而是一个智能化的知识管理系统,承担必要的策略维护与生命周期管理等。
- 生成器(Generator)-- “行动者”
承担常规任务执行的角色,基于当前上下文执行任务,产生一系列动作、推理轨迹和结果(如对话和工具使用序列)。在此过程中会暴露出问题:哪些策略是有效的,哪些出现偏差。
- 反思器(Reflector)-- “复盘者”
每轮任务后,对生成器的行为轨迹进行反思 ,提炼出具体的经验教训,如:哪些提示奏效了?哪些推理路径出现失误?哪类信息确实导致错误?你可以理解为一种“工作复盘:这一步我为什么错了?下次我应该注意什么?。
- 策划器(Curator)-- “策略管家”
将反思器给出的教训转化为可以附加在上下文中的可复用的策略,并维护更新Playbook。这里的关键在于:不是简单地插入或覆盖,而需要实现严格的质量控制(去重、修剪、评分等)、优先级决策、生命周期管理等能力。
我们用伪代码来认识工作原理:
# === 一次完整的 ACE 循环 ===
def ace_round(task, playbook):
# 1) 取策略手册生成上下文(可含 RAG/工具说明/约束)
strategies = playbook.query(task)
context = build_context(task, strategies)
# 2) 行动者执行任务,产生轨迹
generator = Generator()
trace = generator.run(task, context)
# 3) 反思器复盘轨迹,产出“经验教训”
reflector = Reflector()
lessons = reflector.analyze(task, trace)
# 4) 策划器做质量控制,增量写回 Playbook
curator = Curator()
updates = curator.curate(lessons)
playbook.update(updates)
return trace, updates
# === 主流程(持续的在任务过程中学习) ===
playbook = Playbook()
for task in task_stream():
# 连续的真实任务流
trace, updates = ace_round(task, playbook)
ACE 的创新在于,它建立了一个真正的智能体学习闭环:
生成→反思→策略->再生成
智能体不只是执行任务,而是在不断****学习如何执行得更好 - 每一次任务都在丰富它的上下文,完善它的策略。
这正是“Agentic上下文工程”的真正含义——
让上下文智能进化,进而让Agent自我成长,不断变聪明。
6、整体架构与流程
参考 ACE 论文提出的结构,我们将其应用于一个基于 ReAct 范式 的智能体中。这个智能体具备自我“反思—学习—成长”的能力:
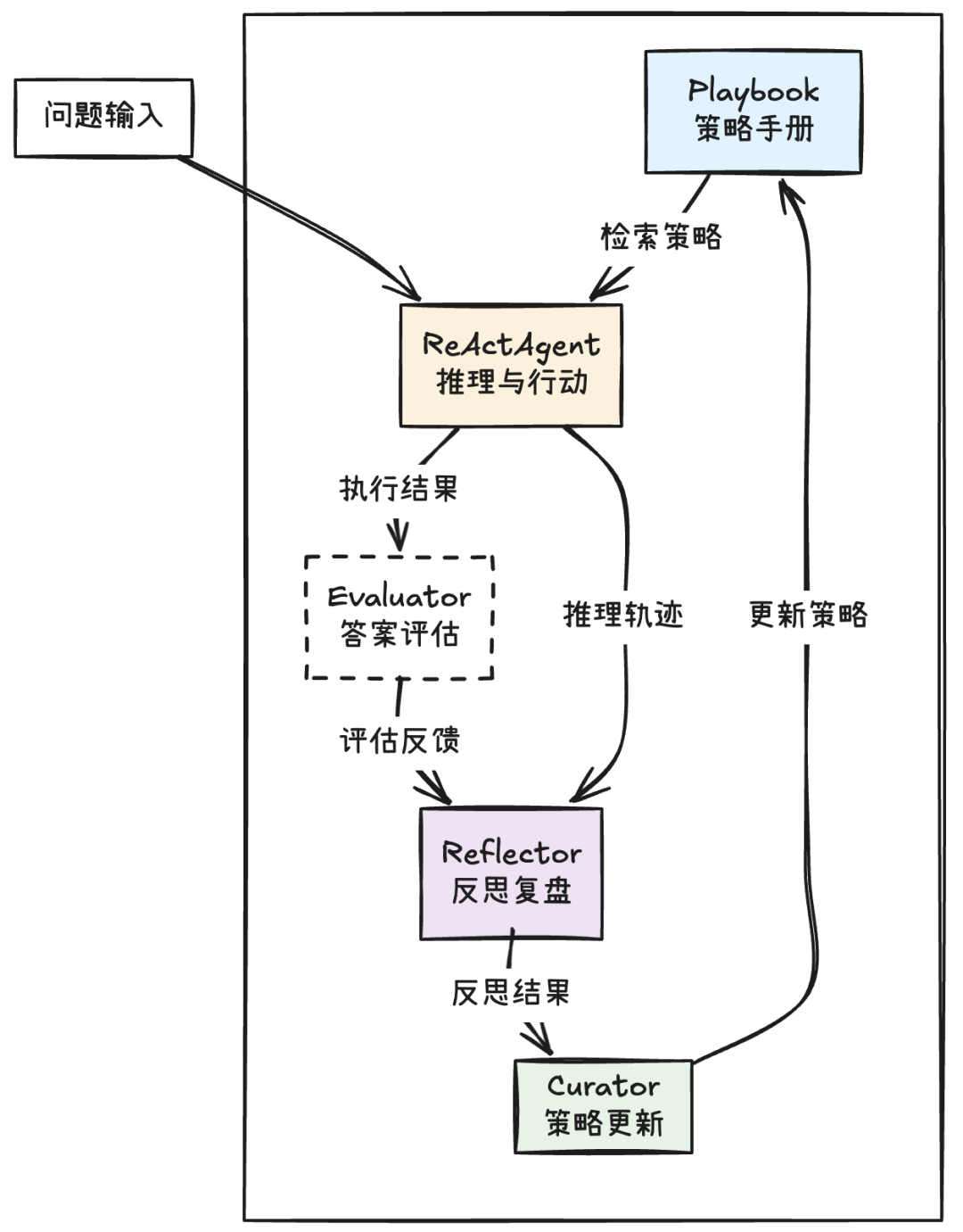
【设计要点】
- 用ReAct Agent代表Generator(行动者)
- 用一个ReAct Agent来承担Generator校色,接受输入任务,输出答案与推理过程。当然,实际应用中可以是任何形态的Agent。
- 离线模式与在线模式
关于ACE论文中的两种典型运行模式:
-
离线模式(Offline Adapter)
即"训练模式",用来在固定的训练数据集上多轮迭代运行ACE流程,每轮处理相同的样本,生成初始的策略库(Playbook)。这类似于学生反复做题,总结规律,积累经验。
-
在线模式(Online Adapter)
即"生产模式":部署到真实业务场景中。此时输入数据不再固定,也不会多次迭代,但智能体会根据新任务实时更新 Playbook。它更像是一个在实战中不断成长的从业者,边工作边学习。
两者间的“协作”大概是这样:
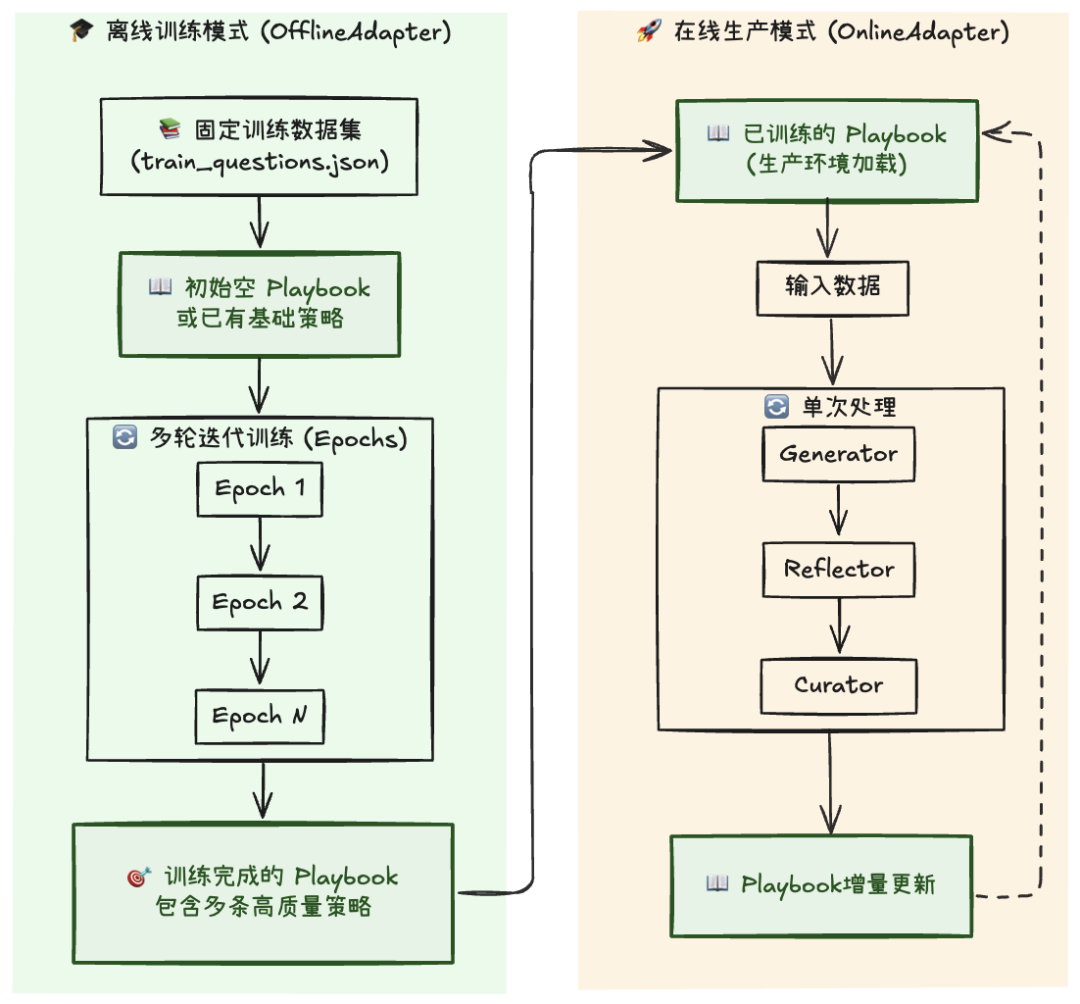
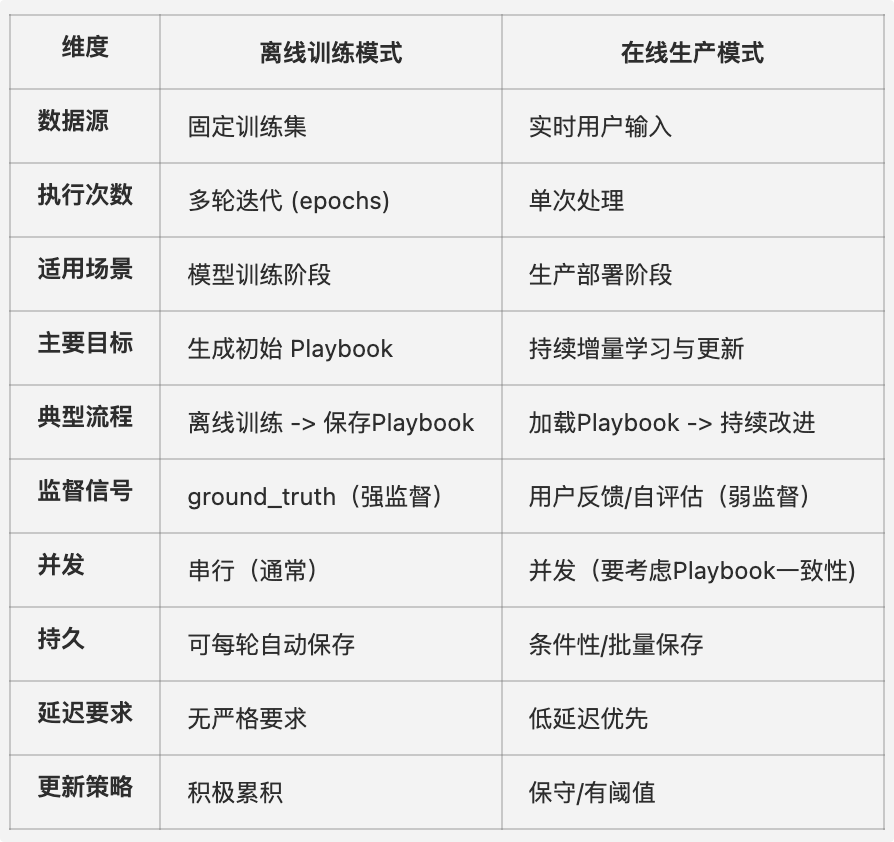
两者间的区别用下表总结:
实际上,对于单次任务输入(迭代次数=1) 的情况,两者在基本流程上并无本质区别。因此我们可以构建一个统一的工作流结构:
- 若需“预训练”,只需在固定数据集上重复运行多轮
- 若直接“生产”,则让工作流持续接收新输入并在线更新策略
接下来,我们将逐步拆解各个模块的实现逻辑,从 Playbook 开始(为了更好地聚焦于 ACE 框架的核心逻辑,原型实现做了很多简化)。
7、实现Playbook – “策略手册”
Playbook 是 ACE 系统的"记忆中枢",负责存储和管理 Agent 在实践中学到的所有策略。不仅记录Agent在不同任务中的“经验与教训”,还通过评分机制和语义检索,让Agent在后续任务中能够主动调用最优策略。
结构如下:
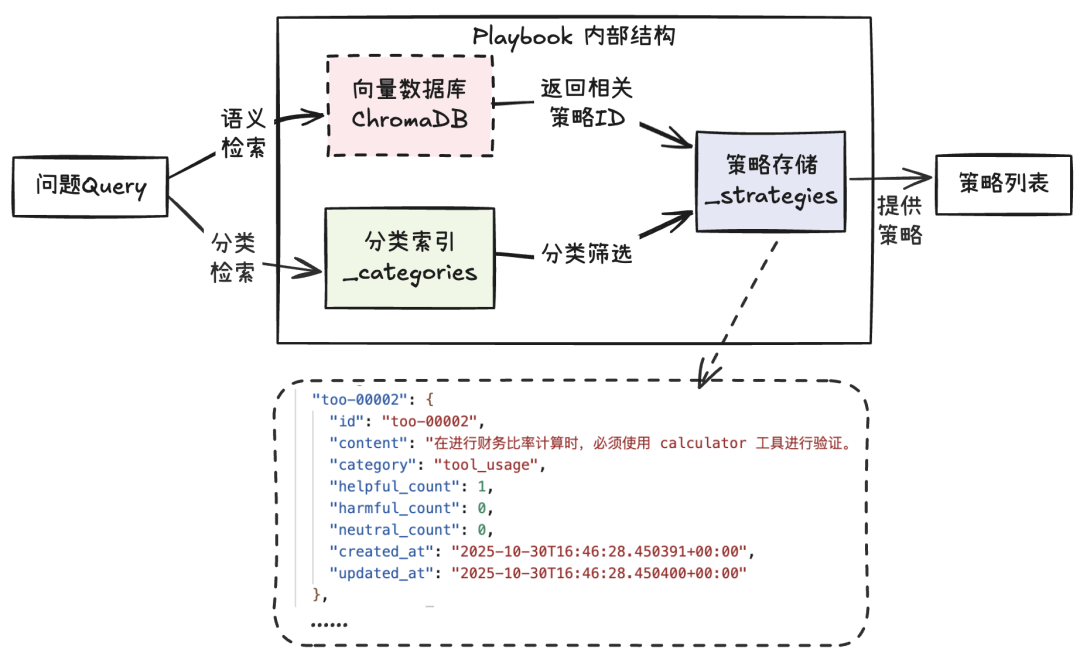
【设计要点】
1. 多样的检索策略
Playbook 提供两种检索方式:
- 基于评分:基于评分优先返回表现好的策略
- 基于语义:借助向量实现语义级检索
2. 动态学习与优胜劣汰
每条策略都会在任务执行后根据反馈被打上标签(helpful / harmful / neutral)。系统根据这些反馈自动计算得分(Score):
score = helpful_count - harmful_count
高分策略在检索时权重更高,而低分策略会逐步被淘汰。这使得智能体的经验体系具备自我优化能力。
3. 策略去重与整合
为避免知识冗余,Playbook 会在新增策略时进行去重检测(基于向量相似度)。当系统检测到已有相似策略时,不会简单新增,而是更新已有策略的统计信息。
4. 持久化与可重建
支持将Playbook持久化(文件或数据库),在系统重启后可快速加载使用,同时在模型或存储结构变化后,也能快速重建语义索引。
【策略结构】
每个策略包含有内容、分类标签、使用反馈与实践信息等。
class Strategy:
id: str # 唯一标识
content: str # 策略内容
category: str # 分类(如 "react", "calculation")
helpful_count: int # 有效次数
harmful_count: int # 有害次数
neutral_count: int # 中性次数
created_at: str # 创建时间
updated_at: str # 更新时间
@property
def score(self):
# 净得分 = 有效次数 - 有害次数
returnself.helpful_count - self.harmful_count
...
【策略样例】
以下是一条典型的策略示例:
"dat-00007": {
"id": "dat-00007",
"content": "信息来源评估原则:在确认信息时,必须对每个信息来源进行权威性评估。步骤:1) 获取多个来源的信息;2) 评估来源的权威性,例如是否为政府机构或知名组织;3) 选择最权威的来源并说明选择理由;4) 若存在差异,需给出合理解释。",
"category": "data_verification",
"helpful_count": 1,
"harmful_count": 0,
"neutral_count": 0,
"created_at": "2025-10-31T04:24:00.338080+00:00",
"updated_at": "2025-10-31T04:24:00.338084+00:00"
}
通过这样的结构,Playbook 在执行阶段能动态调用最优策略,在反思阶段生成并吸收新策略,最终形成一个能够持续自我进化的“知识系统”— 让Agent不仅记得“做过什么”,还知道“怎样可以做得更好”。
8、实现Generator – “行动者”
Generator 是 ACE 框架中的执行者。它可以是一次简单的 LLM 调用。我们采用****ReAct范式的 Agent:根据输入问题生成可验证的答案,并产生可追溯的“推理轨迹”,供后续 Reflector 与 Curator 使用:
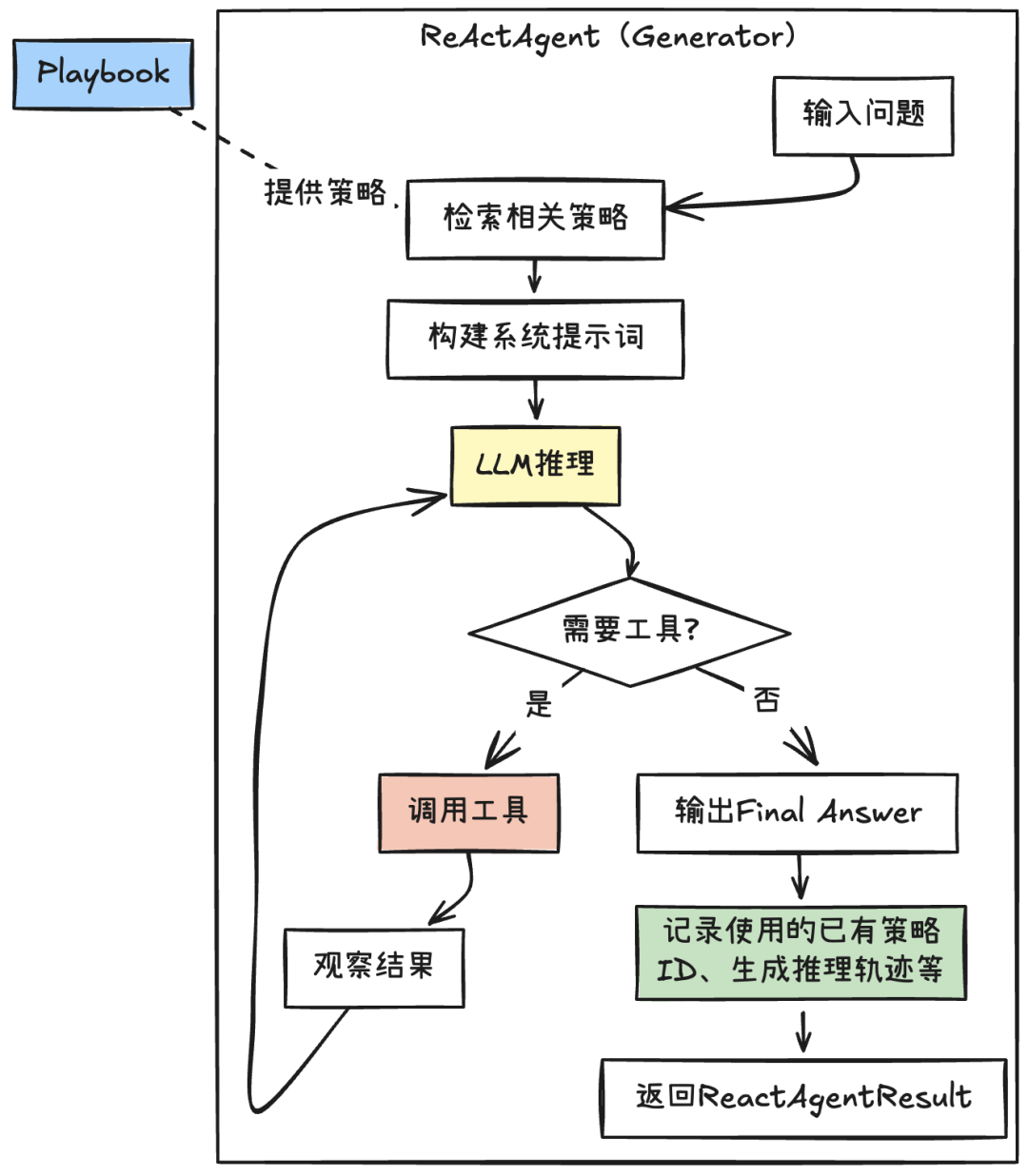
【设计要点】
- 用ReAct驱动任务执行
借助LangChain的create_agent创建,让模型在需要时自动调用工具(通常是通过 Function Calling功能)。
这种基于FunctionCalling的Agent在输出“推理轨迹”时不太友好。详见最后一节“问题”部分。
- 工具集成
配备简单的计算器与搜索引擎用于测试。
- 策略注入
- 每次任务开始前,从 Playbook 检索问题相关的Top-K策略(基于分数或语义,注意不是所有策略都适合语义检索)。
- 将这些策略以“片段/指南”的形式动态注入系统提示,作为经验性先验,引导 ReAct 的思考与工具选择。
def_get_or_create_agent(self, question: str = "", context: str = ""):
"""
根据当前问题动态创建 agent,以便使用最相关的策略。
参数:
question: 当前问题
context: 额外的上下文信息
"""
return create_agent(
model=f"openai:{self.model_name}",
tools=self.tools,
system_prompt=self._get_system_prompt(question, context)
)
- 动态系统提示(上下文)
系统提示词动态组装,包含内容有:
- Top-K 相关策略(含策略 ID,便于追溯)
- 工作原则与关键指令(如:必须逐步输出、遇到不确定先验证等)
- 工具使用说明(可选,FunctionCalling不需要)
- 任务上下文与边界(输入背景、约束、期望输出格式)
- 结构化与可审计输出
为了方便后续Reflector的“复盘”,要求ReAct在每轮:
- 输出简明的“思考”过程(Reasoning)
- 明确所引用的Playbook策略ID
- 清晰标准工具调用相关信息
执行结束整理为统一的数据结构,至少包括:
- 最终答案(Final Answer)
- 推理轨迹(每轮Reasoning/Action序列)
- 使用的策略ID列表(用于之后的策略评估与计分)
总之,Agent的“思考”过程越详细,越有利于后续Reflector的“复盘”;这和做数学题一样:过程越详细,越有利于“复查”发现问题。
9、实现Reflector – “复盘者”
它对 Generator(行动者)的推理链与执行轨迹进行系统化复盘,围绕三个关键问题给出结构化结论:
「哪里做得好?哪里出了错?下一次该怎么做得更好?」
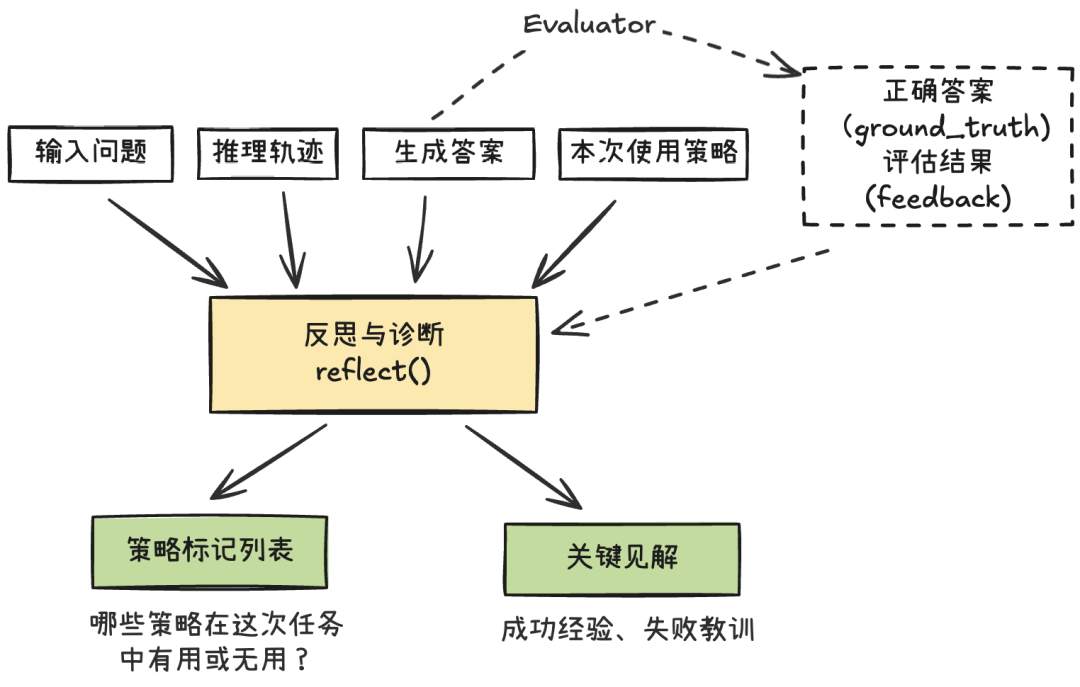
【设计要点】
- 适应有无ground_truth两种模式
- 有ground_truth:先用评估器对最终答案与标准答案进行比对,生成客观评估信号(正确/错误、评估反馈、置信度)。Reflector 将该评估作为附加证据纳入分析,给出更精确的复盘结论。
- 无ground_truth:采用自我审查策略,基于推理链一致性检查、工具调用合理性、来源可靠性等信号,评估结果可信度并提出改进建议。
类比:一种是“做作业时有参考答案的反思”;另外一种则是考试时无答案的复查。
- 多维度诊断(通过Prompt)
Reflector 从多个维度分析Agent的表现,而不是只判断对错。:
- 成功模式:哪些策略、方法和推理链起到了正面作用?能否泛化?
- 策略问题模式:哪些策略选择不当、理解偏差或逻辑跳跃?
- 工具使用错误:是否调用了错误工具、参数是否合理?
- 数据源问题:检索来源是否权威?信息是否一致?
- 计算错误:检测到LLM不擅长的数值推理等。
通过这种方式产出根因分析、改进建议、关键洞察等高价值输出。
- 策略使用评估
Reflector不仅要发现新的可用策略,更要对旧的策略使用进行评估:
-
helpful:明确帮助了任务推进或提高了答案质量;
-
harmful:误导了推理或导致错误;
-
neutral:影响不大或无关。
并给出简短理由,作为 Curator 更新 Playbook 计数与内容的依据。
【输出结构(建议)】
from dataclasses import dataclass
from typing import List
@dataclass
class StrategyTag:
id: str # 策略ID
tag: str # "helpful" | "harmful" | "neutral"
justification: str # 标记理由(引用具体证据点)
@dataclass
classReflectionResult:
reasoning: str # 系统化分析(精炼、可读)
error_identification: str # 错误识别(发生了什么问题)
error_location: str # 错误位置(哪一步/哪条消息/哪次工具调用)
root_cause_analysis: str # 根因分析(为什么会错)
correct_approach: str # 正确方法(可操作的改进建议)
key_insight: str # 关键见解(可沉淀为策略的抽象经验)
confidence_in_analysis: float # 置信度(0~1)
strategy_tags: List[StrategyTag] # 对已用策略的评估标签
总之,Reflector 的价值在于从任务过程中提炼可执行的改进与可复用的经验。
10、实现Curator – “策略管家”
Curator 是 ACE 框架的“知识管理者”,它负责把 Reflector 的复盘结果转译为对 Playbook 的具体操作,让“经验教训”沉淀为可复用的策略,确保策略库持续进化且质量可控。
Curator有点像Text2SQL:把反思的结果转化成对Playbook的“SQL”操作
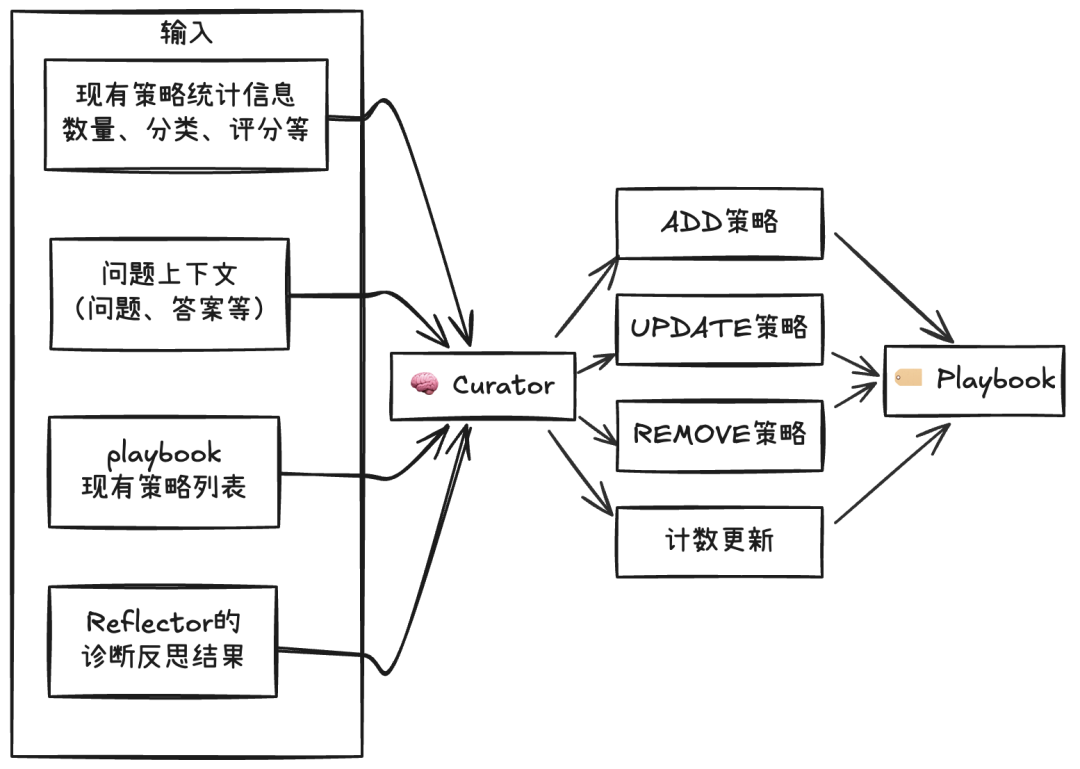
【设计要点】
- 策略操作类型
支持Playbook的多种操作类型,用于不同的策略更新场景:
* ADD:新增具体可执行且可泛化的策略(附简短示例/适用边界)
* UPDATE:对既有策略做增量补充(边界、例外、参数约束、误用警示)
* REMOVE:移除持续有害/过时/与事实冲突的策略
* 有效性计数更新:根据Reflector的输出,更新策略的有效性计数
- 质量控制
在Curator执行的过程加入质量控制是有必要的。其中最重要的是排重与合并(否则可能导致无限制的上下文增长),除了前面Playbook本身具备的基于向量的重复检查外,可以在Curator的提示中加入对现有策略的相似度判断(比如相似度较高,则使用UPDATE而不是ADD)。
输出结构(建议)
from dataclasses import dataclass
from typing import List, Dict, Any
@dataclass
class CurateOperation:
operation: str # "ADD" | "UPDATE" | "REMOVE" | "MARK"
strategy_id: str = ""# 适用于 UPDATE / REMOVE / MARK
content: str = "" # 适用于 ADD / UPDATE(增量内容或补充要点)
category: str = "" # 新增/调整的分类
reason: str = "" # 操作原因(关联反思的证据/根因)
priority: int = 3 # 1~5,数值越小优先级越高
tags: Dict[str, Any] = None# 可选:delta/edge_cases/examples 等
@dataclass
class CurateResult:
operations: List[CurateOperation]
added_count: int
updated_count: int
removed_count: int
marked_count: int
总之,Curator 的职责不是“把反思照抄进库”,而是把反思变成策略学到库里。
11、工作流组装与测试
各模块就位后,我们用 LangGraph 把它们串成一个最小可用的工作流。目标很简单:把已有的 ReAct Agent“包一层”,让它具备执行 → 评估(可选)→ 反思 → 策展的闭环能力(你完全可以自行用代码实现这个流程)。
【工作流编排】
大致的编排直接看编排代码更清晰:
def_build_graph(self) -> StateGraph:
"""
构建 LangGraph 工作流
"""
workflow = StateGraph(ACEReActState)
# 添加所有节点
workflow.add_node("react_agent", self._react_agent_node)
workflow.add_node("evaluator", self._evaluator_node)
workflow.add_node("reflector", self._reflector_node)
workflow.add_node("curator", self._curator_node)
# 设置入口
workflow.set_entry_point("react_agent")
# 使用条件边:react_agent 后根据是否有 ground_truth 决定路由
workflow.add_conditional_edges(
"react_agent",
lambda state: "evaluator"if state["react_question"].ground_truth else"reflector",
{"evaluator": "evaluator", "reflector": "reflector"}
)
# evaluator 后续路径
workflow.add_edge("evaluator", "reflector")
# reflector 和 curator 的路径
workflow.add_edge("reflector", "curator")
workflow.add_edge("curator", END)
return workflow.compile()
使用LangGraph的好处是把已有的ReAct Agent再编排成一个“具有自主学习能力”的Workflow;并获得流式输出、checkpoint、异步等特性。
【测试流程】
我们用一个简洁的主程序跑通闭环:先离线“预热”出初始 Playbook,再在线测试与继续学习。为方便演示,epoch=1。
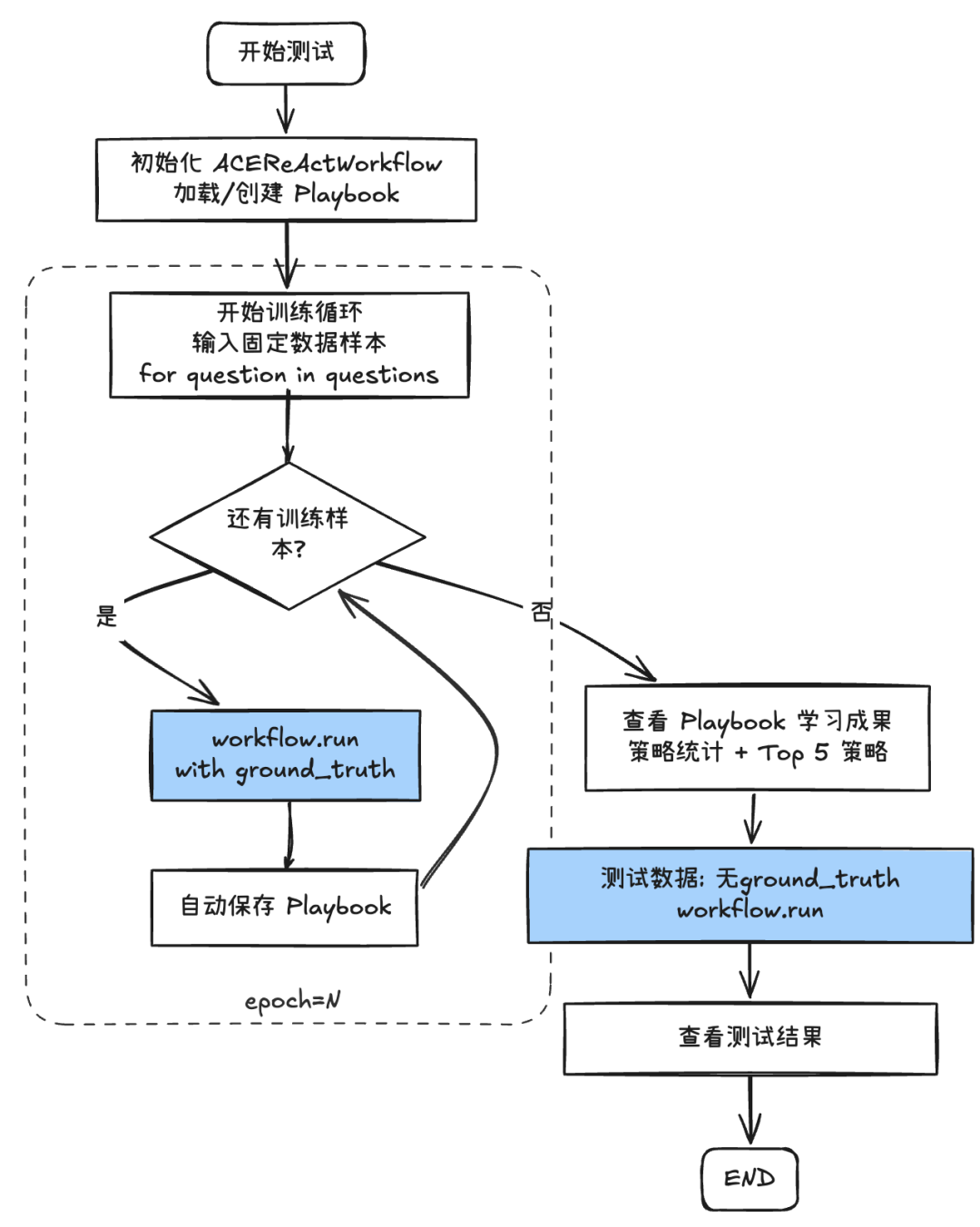
【观察与产出】
首先是几个固定数据集的训练过程:
# 训练问题
questions = [
ReactQuestion(
question="计算 (25 + 17) * 3 - 8 的结果,并验证答案是否为偶数",
ground_truth="118,是偶数",
context=""
),
ReactQuestion(
question="搜索 Python 语言的创建者,并说明他创建 Python 的年份",
ground_truth="Guido van Rossum,1991年",
context=""
),
ReactQuestion(
question="搜索世界上最高的山峰名称和海拔高度,然后计算如果一个人每天爬升500米,需要多少天才能到达顶峰",
ground_truth="珠穆朗玛峰,8849米,需要约18天",
context=""
)
]
我们在流程的每一步观察输出结果。
- Generator输出
可以看到除了最终答案外,需要看到逐步 Reasoning / 工具调用 / 观察的完整轨迹。

- Reflector输出
基于Generator的输出,结合答案的评估结果(Evaluator),进行诊断与反思,并将此轮的“经验教训”输出。

- Curator输出
Curator根据Reflector的反思结果对Playbook增量更新,并输出本次迭代的“成果”统计(包括操作明细与摘要)。

- 第一轮训练完成后的成果
在第一轮训练完成后可以得到一个可用的初始Playbook:

这个Playbook会用在后续的样本上:复用现有策略或者精炼已有策略。
比如你可能会在下一轮训练中看到对之前“策略”的引用:

也可能在下一轮训练中看到对现有策略的完善:

这正是ACE的意义:不是“每次从零做题”,而是“做一次、学一点,下次更好”。
- 排重
在Playbook增量更新中,我们也观察到重复策略的排除:

- 无监督场景测试
现在,初始的Playbook可以用于新的无监督(无ground_truth)测试样本:

而测试样本在执行过程中,也可能产生新的策略并更新Playbook。
问题与改进方向
现在总结下我们是如何把 Agent 放进一个会“学习”的流程里:
- LangGraph 负责编排
- ReAct 负责生成与输出推理轨迹
- Reflector 负责把执行过程转化成“经验”
- Curator 负责把“经验”变成资产(Playbook)
周而复始,你会发现:同一个 Agent,做第二次同类任务,已经更“聪明”了。
【问题与限制】
尽管 ACE 的原型验证取得了一定效果,但目前仍存在若干关键问题:
1. LLM 表现波动大
- Generator 与 Reflector 都严重依赖LLM与提示设计
- 即便相同的模型与提示,不同样本上的输出也可能不一致。特别是在基于 Function Calling 的 ReAct Agent 中,模型会在输出tool_calls后抑制本轮文本输出(content字段),导致“思考过程”或“策略引用”信息缺失
2. 策略增量更新的判定困难
Curator 在执行增量更新时,LLM 对“新增”与“更新”的边界判断并不稳定。常见问题包括:
- 倾向于新增相似策略,而非更新原策略
- 无法可靠检测重复或冲突策略
- 更新内容缺乏上下文一致性
需要引入向量检索 + 相似度阈值(如 0.7)的排重逻辑辅助。
3. 同步反思导致性能瓶颈
Reflector/Curator的同步执行会显著拖慢主流程。在生产场景中,这种“实时复盘”模式并不现实,可以采取异步或延迟执行机制。
【改进方向思考】
1. 异步反思与批量学习
让 Reflector/Curator 异步运行,定期汇总反思结果并统一更新 Playbook,从而提升在线响应速度,同时保持学习闭环。
2. 领域化与定制化调优
ACE 不是一个“固定模板”,而是一种可演化的工程思想。在不同场景中,它的重心也会不同。比如,不同类型的智能体需要不同的反思与策略重点:
- 工具型智能体:更关注工具调用逻辑、参数安全、错误恢复
- 知识型智能体: 更注重专业知识积累、对话一致性与合规性
因此,实际落地时需根据业务场景、模型能力与目标指标进行调优。
3. Playbook 的生命周期管理
未来的策略库应支持:
- 更完善的质量评分与退化淘汰机制
- 版本管理与回滚(方便做 A/B 测试)
- 并发一致性控制(多任务下策略更新冲突)
- 检索优化(如何更好的选择最相关的策略)
5. 扩展性与组件化设计
- 可扩展/插拔的 Evaluator/Reflector 等模块
- 可替换的 Prompt 模板与策略过滤器
- 面向不同领域的 Playbook 预设(如财务、科研、客服等)
ACE提出了一种创新思想,它不再依赖模型的训练,而是让Agent自我”训练“,通过不断迭代更新的上下文实现自我提升。这篇原型实现只是一个起点,我们还是期待在更多真正的生产应用里看到其实际的运行效果。
本文源码:
https://github.com/pingcy/ace-langgraph
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
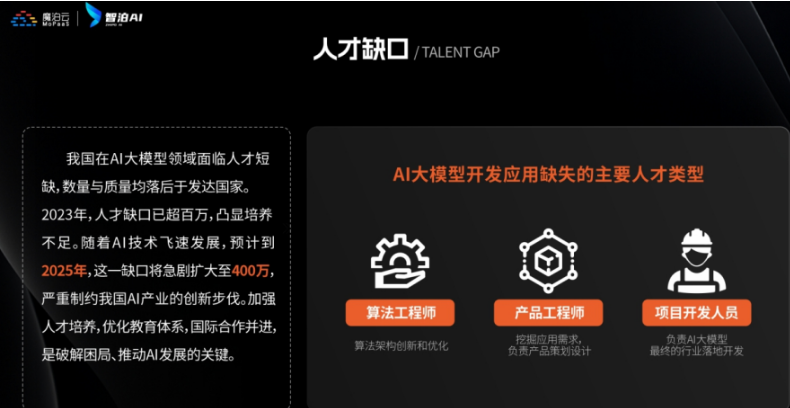
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 34
34 0
0- 0



 已为社区贡献272条内容
已为社区贡献272条内容

所有评论(0)