大规模语言模型时代的自动形式化:综述
自动形式化——将非正式数学命题转化为可验证的形式化表示的过程——是自动化定理证明中的基础任务,为数学在理论和应用领域的使用提供了新的视角。得益于人工智能的快速发展,特别是大规模语言模型(LLMs)的推动,这一领域取得了显著进展,带来了新的机遇和独特挑战。在本综述中,我们从数学和LLM中心视角全面概述了自动形式化的最新进展。我们探讨了自动形式化如何应用于不同数学领域和难度级别,并分析了从数据预处理到
翁柯 1∗{ }^{1 *}1∗, 杜伦 2∗†{ }^{2 * \dagger}2∗†, 李思蕊 Li1\mathbf{L i}^{1}Li1, 吕望月 Lu1\mathbf{L u}^{1}Lu1, 孙浩哲 1{ }^{1}1, 刘恒宇 3{ }^{3}3 和 张天诚 1†{ }^{1 \dagger}1†
1{ }^{1}1 东北大学
2{ }^{2}2 蚂蚁集团蚂蚁研究院
3{ }^{3}3 奥尔堡大学计算机科学系
{2401925, 20226504, 2410827, 20223246}@stu.neu.edu.cn, dulun.dl@antgroup.com, heli@cs.aau.dk, tczhang@mail.neu.edu.cn
摘要
自动形式化——将非正式数学命题转化为可验证的形式化表示的过程——是自动化定理证明中的基础任务,为数学在理论和应用领域的使用提供了新的视角。得益于人工智能的快速发展,特别是大规模语言模型(LLMs)的推动,这一领域取得了显著进展,带来了新的机遇和独特挑战。在本综述中,我们从数学和LLM中心视角全面概述了自动形式化的最新进展。我们探讨了自动形式化如何应用于不同数学领域和难度级别,并分析了从数据预处理到模型设计与评估的端到端工作流。我们进一步探讨了自动形式化在增强LLM生成输出的可验证性方面的作用,强调其对提高LLM的信任度和推理能力的潜力。最后,我们总结了支持当前研究的关键开源模型和数据集,并讨论了开放挑战和有前景的未来方向。
1 引言
历史上,数学家们依赖各种工具——机械或电子——来辅助他们的工作,从早期的算盘到现代计算系统 [Tao, 2024]。近年来,如Lean [Moura and Ullrich, 2021], Coq [Huet et al., 1997], 和 Isabelle [Paulson, 1994] 等形式化证明助手作为构建具有机器可验证正确性的数学严格证明的强大环境出现。与传统编程语言不同,形式化语言并非设计用于执行计算,而是用于编码和验证数学论证在形式系统中的逻辑有效性。
每个证明步骤通常扩展为多行形式化代码,只有当整个脚本符合逻辑规则时,证明才会被接受为正确。
尽管这些工具功能强大,但即使是专家使用证明助手仍然非常耗时,因为将非正式数学推理形式化需要在每一步都保持精确。这一挑战催生了自动形式化,这是一个专注于将非正式数学翻译为形式化语言的研究方向。作为更广泛的数学人工智能领域中的关键组成部分,自动形式化旨在弥合人类直觉和机器可验证推理之间的差距。
大语言模型(LLMs)的最新突破加速了这一方向的发展。值得注意的是,AlphaProof [AlphaProof and AlphaGeometry, 2024] 在国际数学奥林匹克竞赛(IMO)问题上展示了银牌水平的表现,展示了LLMs在解决高级数学推理任务方面的潜力。最近,据报道GPT-o3解决了Frontier Mathematics基准测试中25.2%的问题,显著优于仅能解决约2%问题的早期模型。这些里程碑突显了LLMs生成复杂数学解决方案的能力日益增长,同时也强调了确保正确性所需的正式验证的重要性。
然而,在数学之外,自动形式化的核心思想——将非正式自然语言推理转化为精确、可验证的表示——具有更广泛的意义。在诸如科学假设生成、法律分析甚至多跳问答等领域,确保模型生成推理的内部一致性和正确性变得越来越重要。自动形式化为将LLM推理扎根于形式逻辑提供了一种有希望的机制,使推理步骤能够进行系统检查,从而增强LLM输出的可验证性。随着LLM逐渐转向需要不仅流畅回答还要可靠推理的问题,自动形式化将在弥合语言生成与逻辑严谨性之间的差距方面发挥关键作用。
然而,在数学之外,自动形式化的核心原则——将非正式或半正式语言转化为精确、可验证的表示——具有更广泛的意义。随着LLMs越来越多地应用于算法设计、代码生成和系统规范等任务
∗{ }^{*}∗ 共同贡献
†{ }^{\dagger}† 对应作者
表1:包含链接和简要描述的开源模型或方法。"数据集/基准"列中的上标表示以下内容:^{1} 表示该数据集在论文中用于评估,^{2} 表示用于训练,^{3} 表示该数据集首次在该论文中提出。
| 方法/模型及链接 | 数据集/基准 |
|---|---|
| DeepSeek-Prover-V1 | miniF2F^{1,2} |
| LeanEucIid | LeanEucIid^{2,3}, Elements ^{1}, UniGeo^{1} |
| Isa-AutoFormal | Math^{1}, miniF2F^{1} |
| Retrieval Augmented autoformalization | IsarMathLib^{2} |
| DeepSeekMath | GSM8K^{1}, MATH^{1}, SAT^{1}, OCW Courses^{1}, MGSM-zh^{1}, |
| CMATH^{1}, Gaokao-MathCloze^{1}, Gaokao-MathQA^{1}, miniF2F^{1} | |
| DRAFT, SKETCH, AND PROVE | miniF2F^{1} |
| FORMALALIGN | miniF2F^{1}, FormL4^{1,2}, MMA^{2} |
| GFLEAN | 教科书数学证明^{1} |
| Lean Workbook | miniF2F^{1}, ProofNet^{2} |
| LEAN-GitHub | miniF2F^{1}, ProofNet^{1}, Putnam^{1} |
| LeanDojo | LeanDojo^{1,2,3} |
| LEGO-PROVER | miniF2F^{1,2,3} |
| LLEMMA | Math^{1}, GSM8K^{1}, miniF2F^{1}, ProofFile^{2,3} |
| LYRA | miniF2F^{1,2} |
| MMA | miniF2F^{1}, ProofNet^{1}, MMA^{2,3} |
| Pantograph | miniF2F^{1} |
| PDA | FormL4^{1,2,3} |
| ProofNet | ProofNet^{1,2,3} |
| SubgoalXL | miniF2F^{1,2} |
| Herald | miniF2F^{1},Extract Theorem^{1},College CoT^{1} |
| DeepSeek-Prover-V2 | miniF2F{1},ProofNet{1}, Putnam{1},CombiBench{1},ProverBench^{1,3} |
| Kimina-Prover | miniF2F^{1} |
| Goedel-Prover | miniF2F^{1}, Putnam{1},ProofNet{1},Lean Workbook^{1,2} |
| STP | miniF2F^{1}, Putnam{1},ProofNet{1} |
| Leanabell-Prover | miniF2F^{1} |
| BFS-Prover | miniF2F^{1} |
| InternLM2.5-StepProver | miniF2F{1},Putnam{1},ProofNet{1},LeanWorkbook-Plus{1,3} |
表2:带有代码仓库链接和描述的数据集
| 数据集 | 规模 | 任务 | 描述 |
|---|---|---|---|
| miniF2F | 488 | 定理证明 | 来自奥赛以及高中和本科数学课程的命题 |
| LeanEucIid | 4,71 | 自动形式化 | 用Lean手动形式化的欧几里得几何问题 |
| Math | 12,388 | 数据挖掘 | 12,388道具有挑战性的竞赛数学题 |
| FORMAL4 | 17,137 | 预训练,自动形式化 | 从Mathlib 4提取的有信息量的定理 |
| ProofNet | 374 | 自动形式化,定理证明 | 这些问题来源于流行的本科纯数教材 |
| PutnamBench | 657 | 定理证明 | 来源于William Lowell Putnam数学竞赛的竞赛数学问题 |
| LeanDojo | 122,515 | 定理证明 | 来自mathlib4的定理、证明、策略、首秀 |
| GSM8K | 8,792 | 问答 | 高质量、语言多样化的中小学数学应用题 |
| miniF2N | 261 | 定理证明 | 来源词汇答案和教科书的定理 |
| acoc,Prover | 80 | 自动形式化 | 用Lean形式化的arXiv论文中的定理 |
| DeepSeek-Prover-V1 | 37,503 | 定理证明 | 从高中和本科级数学竞赛问题衍生的Lean4证明数据 |
| Lean Workbook | 13,517 | 自动形式化,定理证明 | 数学问题及其证明信息的集合 |
| Lean-GitHub | 26,446 | 自动形式化,定理证明 | 包含正式证明和策略的2.133个文件中的定理 |
| LeanMats | 565 | 定理证明 | 一种化学发光数学问题及其解法,用Lean 4形式化 |
| Herald | 814,456 | 自动形式化,定理证明 | 由Herald流水线在Mathlib4上生成的数据集,包含50万有效命题和4.4万自然语言形式化证明 |
| ProverBench | 325 | 定理证明 | 包含325个形式化问题的基准数据集,以推进神经定理证明研究,包括来自著名的AIME竞赛(24-25年)的35道题目 |
| CombiBench | 160 | 定理证明 | 手动生成的基准,包括100道不同难度和知识层次的组合数学问题 |
| STP,Lean-0320 | 5,262,558 | 定理证明 | 包括mathlib4例子、LeanWorkbook证明和软玩猜想证明的数据集 |
| Leanabell-Prover-Formal-Statement | 1,133,283 | 定理证明 | 包括现有模型生成的三重编码数据和从非正式数学问题合成的数据的数据集 |
[Shi et al., 2023; Di et al., 2024],确保其输出不仅语法正确而且语义健全变得至关重要。自动形式化提供了一个弥合这一差距的有希望机制:通过将自然语言规范、伪代码甚至非正式正确性声明转换为形式逻辑或可验证代码契约,它使得算法行为能够进行严格的检查。在软件工程、安全审计和科学计算等领域,这种能力可以显著提高LLM生成制品的可信度和可靠性。从这个角度来看,自动形式化不仅仅是一个数学证明工具——它是构建能够集成推理、编码和验证的LLM系统的基石。
本综述提供了关于自动形式化的最新进展的全面和结构化回顾,重点关注其在数学定理证明中的当前应用,以及结合自动形式化与大规模模型形式验证生成完全可信输出的可能性。§2 展示了自动形式化的历史和技术基础的回顾。在 §3 中,我们剖析了自动形式化的工作流程,涵盖了关键组件,如数据预处理、建模策略、后处理技术和评估协议,并剖析了最先进的数学定理证明模型方法。在 §4 中,我们对涉及的数学问题从数学问题领域、数学问题难度级别和数学问题抽象级别进行了深入分析。在 §5 中,我们从多个领域探索了自动形式化与大规模模型输出形式验证之间的联系。我们在 §6 中总结了支持当前研究的显著开源模型和数据集;在 §7 中,我们讨论了主要的开放挑战和有前景的未来研究方向。最后,§8 将我们的综述与现有的相关综述进行比较,阐明其独特的视角和贡献。
2 背景
自动形式化在当代人工智能和数学推理中扮演着双重角色。一方面,它促进了数学知识的形式化,加快了机器验证证明和定理证明系统的发展。另一方面,它为大型语言模型(LLMs)的输出提供了一个基于形式逻辑的框架,实现了可验证性和促进符号与神经方法的更深层次整合[Wu et al., 2022]。这种协同效应创造了一个积极反馈循环:机器学习的进步协助形式化,而形式系统反过来为验证和改进模型输出提供了严格的工具。
在本节中,我们从两个互补的角度介绍了自动形式化的核心概念:它在数学形式化中的基础作用,以及它在LLM生成内容的形式验证中的新兴重要性。
2.1 数学中的自动形式化
近年来,数学家们成功完成了几个标志性定理的形式化,包括四色定理[Gonthier, 2008]和开普勒猜想[Hales et al., 2015]。然而,形式化过程仍然高度耗时且费力。例如,形式化四色定理花费了将近五年的时间,而开普勒猜想则需要超过十年的努力。
自动形式化试图通过将非正式证明自动化转换为可被Coq [Sozeau et al., ]、Lean [de Moura et al., 2015] 和 Isabelle [Mohamed et al., 2008] 等证明助手验证的表示来减轻这一负担。通过减少手动形式化的努力,自动形式化使数学家能够更多地关注概念推理和数学洞察,同时仍能受益于形式验证提供的严谨性和可靠性。
为了更好地理解和系统分析数学领域的自动形式化,我们提出了一个三维框架,如图2所示。此框架捕捉了现有自动形式化研究可以分类和比较的关键轴:
- 数学问题领域:自动形式化任务根据它们针对的子领域差异很大。我们强调代表性的领域,如几何和拓扑、代数和数论,以及通常涉及跨学科推理的复杂系统或前沿问题。
-
- 难度级别:我们进一步根据其内在复杂性和所需抽象级别对问题进行分类——从高中数学到本科和研究生级别的推理。此轴揭示了当前系统如何应对不断增加的证明复杂性和概念深度。
-
- 工作流程:最后,我们分析典型的自动形式化管道,包括数据预处理、建模方法、后处理方法和评估策略。这一维度提供了对不同系统如何构建、训练和评估的见解。
我们采用此框架指导本文的后续部分,沿着这三个维度提供对当前研究工作的结构化讨论。
- 工作流程:最后,我们分析典型的自动形式化管道,包括数据预处理、建模方法、后处理方法和评估策略。这一维度提供了对不同系统如何构建、训练和评估的见解。
2.2 LLM 输出形式验证中的自动形式化
随着像LLaMA [Touvron et al., 2023], Claude [Antropic, 2024], Gemini [Team et al., 2024] 和 GPT-4 [OpenAI, 2024] 等越来越强大的大规模语言模型(LLMs)的出现,由于其广泛的领域知识和强大的少量样本推理能力,已经在广泛的任务上取得了显著进展。然而,尽管它们表达流畅且看似能力强,LLMs 很容易生成错误或逻辑不正确的输出——这种现象被广泛称为幻觉[Sadasivan et al., 2023]。这个问题因模型能够产生有说服力和类似人类的响应而进一步复杂化,使得区分有效推理和细微但关键的错误变得困难。
为了解决这一挑战,近期研究探索了使用自动形式化作为将自然语言输出从LLMs翻译成精确、可验证表示的方法,利用诸如一阶逻辑[Ryu et al., 2024] 或算术系统如皮亚诺算术[Peano, 1889] 等形式系统。在这种背景下,自动形式化充当了自然语言固有的模糊性与形式验证严格要求之间的桥梁。通过启用对LLM输出的符号推理,自动形式化增强了正确性,提高了可靠性,并促进了在需要严格推理和高保证的任务中安全和值得信赖地部署LLMs。
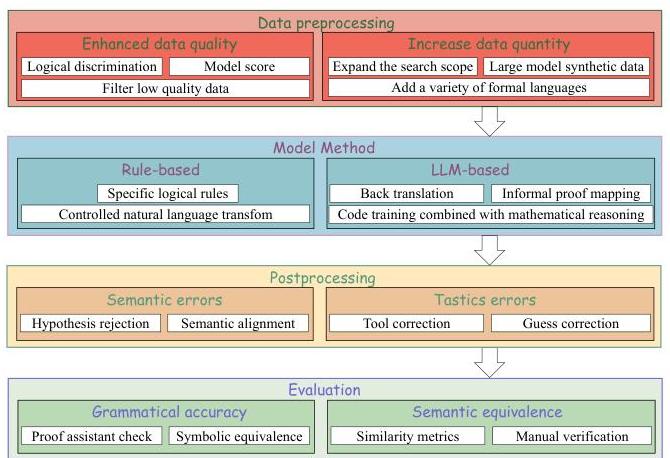
图1:自动形式化的工作流框架
3 自动形式化和定理证明的工作流
基于表1中组织的开源方法模型奠定的坚实基础和自动形式化领域的最新研究进展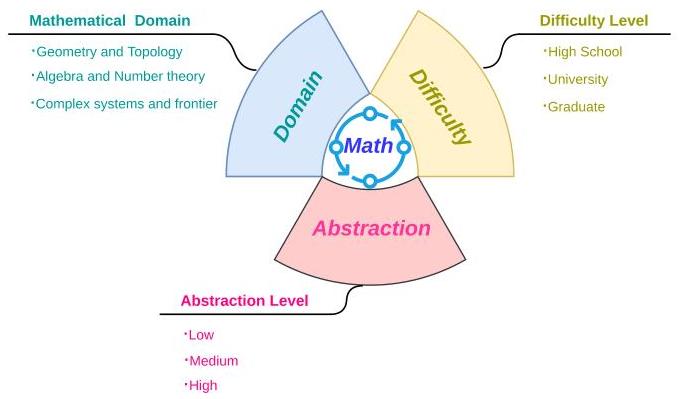 图2:数学中的多维分区自动形式化
图2:数学中的多维分区自动形式化
我们将视角转向工作流的关键维度,深入分析不同环节中的自动形式化机制和关注点,旨在提供一个如图1所示的整体框架,以全面揭示自动形式化的工作流。
3.1 数据预处理
NuminaMath团队指出“优质数据就是你所需要的”[Fleureau et al., 2024] 对于自动形式化很重要,因为数据比其他任务更为稀缺。因此,对数据质量和数量的要求更高,数据预处理部分分为两种方法:提升数据质量和增加数据数量。
提升数据质量
首先,可以通过过滤低质量数据来提升数据质量。[Xin et al., 2024a] 提出了一种新颖的方法,即从高中和本科级别的自然语言数学问题生成有价值的Lean4证明数据,并通过模型评分和假设拒绝方法过滤低质量数据。模型评分中,DeepSeek-Prover对生成的正式陈述进行评分,分为“优秀”、“良好”、“高于平均水平”、“平均水平”或“差”。被评为“公平”或“差”的陈述将被过滤。假设拒绝,即让DeepSeek-Prover尝试证明虚假命题,如果成功证明,则被过滤。这也提醒我们,可以从多个维度限制低质量数据,使非正式陈述尽可能在逻辑上和语义上与相应的正式陈述一致。文章使用了真假命题的逻辑,也可以是其他如理论解析。或许在每个知识领域添加多样性会改善自动形式化的逻辑。
增加数据数量
由于自动形式化的数据稀缺,增加数据预处理阶段的数据量也可以帮助提高模型性能。具体来说,这可以通过添加多种形式语言[Jiang et al., 2024];扩大搜索范围[Wu et al., 2024b];合成数据[Azerbayev et al., 2023],如上述方法增加数据量。
来自多种形式语言的数据有助于自动形式化。[Jiang et al., 2024] 将两个最大的语料库:Archive of Formal Proofs (Isabelle) 和 mathlib4 (Lean4) 使用GPT-4翻译成自然语言。这一过程主要基于一个关键观察:非形式化比形式化简单得多,也就是说,从形式语言到非形式语言的数据翻译质量高于从非形式语言到形式语言的翻译质量,而强大的LLMs可以生成不同的自然语言输出。通过消融实验,来自多种形式语言的数据对于自动形式化训练是必不可少的。
由于大量由人类编写的正式语言语料库尚未得到充分利用,为了解决这个问题 [Wu et al., 2024b] 收集了几乎所有的GitHub上的Lean4仓库,并制作了合适的训练数据,增加了数据量,实验证明在如此大规模的数据集上进行训练,模型在多种数学问题领域中的性能得到了提升。
3.2 方法
基于规则的自动形式化
不同于依赖数据驱动的机器学习模型,核心是利用明确的逻辑、句法和语义规则来实现结构转换。为了应对自然语言的灵活性和复杂性,许多系统采用了受控自然语言——允许用户以既自然又正式的方式表达数学证明,从而产生了包括Mizar、NaProche、ForTheL、MathNat和VerboseLean在内的系统。同时,也关注到了GF高级语法编写工具,该工具允许灵活开发定制语法以直接解析数学文本。基于GF的自动形式化代表性工作:[Pathak, 2024] 提出了一个可以使用GF将自然语言翻译成形式语言的框架,算法使用Haskell实现简化ForTheL表达式的抽象语法树,并在GF中实现Lean表达式语法。通过线性化前一步获得的抽象语法树可以获得Lean表达式,从而获得一个符号自然语言理解和处理的框架:GLIF。
基于LLM的自动形式化
与基于规则的方法不同,基于LLM的方法更加灵活,能够捕捉到自然语言中的细节,而这些细节可能是专家在创建规则时遗漏的。像GPT4这样的LLM代表了一种新的机器学习范式。这种自回归模型已经使用大量互联网数据进行了预训练,并可以通过少量样本学习能力快速执行各种下游任务。最近的研究表明,LLM可以在少于5个示例的情况下翻译非正式和正式的数学陈述,这表明我们可能不需要收集大规模的形式语料库来实现自动形式化,尽管大规模训练数据仍然是训练模型时值得关注的问题。值得注意的是,非形式化通常比形式化更容易。在相同的模型下,非正式数学竞赛水平的问题达到了70%的准确率,而正式数学竞赛水平的问题只达到了30%的准确率。利用这一观察结果也促进了随后基于LLM的反向翻译研究。Azerbayev et al. (2024) 建议使用专门设计用于数学的7B和34B参数语言模型LLEMMA,通过LLM的少量样本学习能力在多个基准测试中取得了良好的表现。Xin et al. (2024a) 发布了具有7B参数大小的基础模型DeepSeekMath,其性能与Minerva540B相当,这也表明参数数量不是数学推理能力的唯一关键因素,较小的模型也能表现出强大的性能。
非正式语言和正式语言之间存在一些关键差异:1) 语义差距:非正式语言在不同上下文中具有多义性,而正式语言需要单一定义且无歧义;2) 逻辑差距:非正式语言常常省略隐含知识,而正式语言需要明确填补完整性,也就是说,即使在正式语言中直观的定理也需要分解为原子步骤。Jiang et al. (2023b) 引导自动证明器通过将非正式证明映射到正式证明步骤来完成自动形式化任务。这种引导的目的是填补非正式语言和正式语言之间的语义差距,并间接建立更完整的逻辑链。为了研究代码训练如何影响数学推理,Xin et al. (2024a) 进行了消融实验。结果显示,两阶段训练(代码训练和数学推理)比同时训练代码和数学推理效果更好,后者甚至不如直接训练数学推理。推测DeepSeek-LLM 1.3B太小,无法同时充分同化代码和数学数据,实际上这是更合理的。毕竟,非正式语言和正式语言之间的差距很大,这种差距不能直接完全填补,因此衍生出各种方法来补充它们之间的差距。
在自然语言机器翻译相关工作中,翻译质量很大程度上取决于两种语言之间平行数据的质量。但这种平行数据很少且难以管理,回译是提高翻译质量最有效的方法之一。Azerbayev et al. (2023) 使用OpenAI蒸馏的Codex模型进行回译,以提高模型的自动形式化能力。Jiang et al. (2024) 他们使用GPT-4从现有的形式语言库生成非正式语言数据。他们经验性和分析性地得出结论,非正式比正式简单得多,因此回译是自动形式化的一部分。
后处理
在后处理阶段,一般通过修改机制或解决自动形式化中的陈述语义错觉和证明逻辑错误,确保正式输出对应于非正式输入。陈述的语义错觉是指生成的正式语言陈述与自然语言陈述之间的不匹配。Xin et al. (2024a) 建议使用假设拒绝方法,用于过滤自动形式化后由陈述假设的部分自相矛盾引起的语义错觉。使用矛盾蕴含假命题的原则来过滤掉自相矛盾的假命题。Lu et al. (2024a) 是首个自动评估对齐方法——通过最小化对比损失,使对应的非正式-正式对的余弦相似度高于不对应的对。这样,对齐被正确评估,语义错觉得以缓解。证明的逻辑错误主要指在转换为正式语言证明时使用错误的证明策略导致的证明逻辑中断。Zheng et al. (2024) 建议使用工具校正和猜测校正机制,包括工具校正机制以修正LLM在错误生成的策略中使用的正式证书,避免因大模型错误使用已证明的策略而导致证明逻辑故障。
评估
在自动形式化工作流中,语法准确性和语义等价性在评估层面是确保自动形式化过程成功的关键因素。语法准确性指的是正确翻译成正式语言的能力,即最终的正式结果是否能通过Lean、Coq等环境的类型检查。Lean、Coq等环境的类型检查并不意味着完全正确,因为形式化结果还需要在语义上等价于相应的自然语言版本,因此评估语义等价性同样重要。语法准确性的目的是通过正式语言证明助手的类型检查机制确保自动形式化的结果,主要涉及两个方面:1)在代码生成层面:生成的正式语言代码没有语法错误;2)在数学推理层面:生成的正式语言代码具有正确的逻辑链。最常见的评估准确性方法是比较自动生成的正式表达式与专家手动形式化的结果。这种评估通常依赖召回率指标或人工检查。Wu et al. (2022) Agrawal et al. (2022), Azerbayev et al. (2023), Jiang et al. (2023a) 判断两者在数学内容上的一致性。虽然这种方法是正确的,但它耗时且主观,因此常用于校准自动评估工具。对于数学推理的准确性,例如模型是否对应每个变量的具体含义,或者证明过程中使用的证明策略是否正确,对于前者,Li et al. (2024a) 建议使用符号等价方法。将陈述分成前提和结论(假设前提是自洽的),当待验证的正式结果的前提和结论分别等价于正确的前提和结论并通过ATP证明时,说明模型对应每个变量的具体含义。对于后者 Zheng et al. (2024) 利用反馈评估证明策略是否正确,并使用工具校正机制解决。对于语义等价性,主要判断自动形式化生成的正式表达是否准确反映相应的自然语言表达。常用的相似性指标包括文本相似性(如BLEU、ROUGE等),[Poiroux et al., 2025] 提出了符号计算指数:BEqL和BEq+。正如[Liu et al., 2025]所指出的,BEqL可以指示各种语法变化的准确性。这种方法可以实现各种语法变化的准确性。尽管它的假阴性率较高,但文章认为其简洁性使得这个指标值得使用。BEq+在BEqL的基础上引入了更复杂的策略组合(如simp、ring等),进一步增强了验证深层数学结构(如代数恒等式)准确性的能力。[Lu et al., 2024a] 提到,对于LLM生成的正式结果,即使BLEU指数很高也不能说明正式结果与相应的自然语言表达在语义上等价,因此提出了对齐评分以更好地评估语义等价性。
3.3 定理证明
虽然自动形式化强调将非正式陈述转化为正式表示,但其实用价值最终在于构建完整且可验证的证明的能力。因此,最近在大型语言模型驱动的定理证明方面的进展不仅补充了自动形式化,还扩展了其范围——通过生成验证翻译陈述的形式推导。这些方法可以根据其粒度广泛分类:一些专注于逐步生成策略,实现精确控制和局部推理,而另一些则旨在整体、端到端的证明生成。我们先回顾前者,它围绕策略级推理和搜索展开,并在训练模型有效导航正式证明空间方面起着基础作用。
3.3.1 策略步骤证明方法
最近,许多工作致力于使用策略步骤增强自动定理证明的局部推理能力。例如,[Xin et al., 2025] 提出了一种基于广度优先树搜索的可扩展专家迭代框架。在每次迭代中,该框架筛选问题集,并结合直接偏好优化和长度规范化策略优化语言模型。这使其优先探索有希望的证明路径。Bfs-prover在Lean4 MiniF2F基准测试中达到了72.95%的通过率,显示了在适当缩放条件下简单的BFS搜索具有竞争力。
同样,[Wu et al., 2024a] 在大规模Lean数学问题集上使用了专家迭代策略。我们还训练了一个批评模型,挑选相对简单的练习以指导模型搜索更深的证明。通过优化问题选择和深化探索深度,我们的方法在MiniF2F上达到了65%的通过率,并在Lean-Workbook-Plus数据集上证明了17.0%的问题。这些方法主要集中在加强局部搜索策略,提高模型样本效率,并为更复杂的全局证明生成奠定基础。
[Li et al., 2025] 旨在缓解训练数据稀疏性问题:它通过可扩展的数据合成框架持续生成新的训练样本,并设计了指导树搜索算法以支持高效推理。通过这种数据迭代和搜索方法的结合,[Li et al., 2025] 在MiniF2F等基准测试中达到了68.4%的通过率。此外,[Li et al., 2025] 发布了一个包含30,000个合成证明实例的数据集,每个实例包含一个自然语言问题、一个自动形式化的Lean陈述及其相应的证明。上述策略步骤证明方法不仅优化了局部搜索策略并提高了证明性能,还通过合成自然语言和正式证明对为自动形式化提供了有价值的数据支持。
3.3.2 全证明生成方法
端到端证明生成方法最近也取得了显著突破,特别是在整合自然语言推理和正式证明方面。
[Lin et al., 2025] 采用了另一种端到端训练思路。首先,使用大规模LLM将自然语言数学问题自动翻译成Lean 4正式陈述,并生成包含1.64M正式陈述的Goedel-Pset-v1数据集。然后,我们连续训练一系列Prover模型,使新模型能够证明旧模型未能解决的陈述,不断扩大训练集。基于该数据集,[Xin et al., 2024b] 进行了监督和微调,所得的Goedel-Prover-SFT在MiniF2F上取得了57.6%的成功率,比之前的最优模型高出7.6%。这种方法充分展示了自动生成大规模训练数据并迭代优化模型的有效性。
基于Qwen2.5-72B模型,[Wang et al., 2025] 提出了结合大规模强化学习管道的“形式推理模型”,模仿人类问题解决策略。该模型在MiniF2F基准测试中取得了80.7%的通过率,并在其采样条件极低的情况下展示了强大的能力,显示出其高采样效率。[Wang et al., 2025] 还展示了模型大小与性能之间的明显正相关关系,其独特的推理风格也有助于弥合形式验证和非正式数学之间的差距。
[Zhang et al., 2025] 专注于现有证明模型的后训练扩展:首先在混合数据集上连续训练基础模型,该数据集包含大量的形式陈述-证明对以及模仿人类推理行为的辅助数据,然后利用Lean 4编译器反馈作为强化学习的奖励信号来优化模型。通过这种连续训练和强化学习的结合,[Zhang et al., 2025] 成功提高了[Xin et al., 2024b] 和 [Lin et al., 2025] 等模型的能力,使其在MiniF2F上的通过率达到59.8%。
[Ren et al., 2025] 引入了强化学习和子目标分解技术:在此方法中,首先使用现有模型DeepSeek V3将复杂问题分解为一系列子目标,然后将已解决的子目标的证明过程与原始模型的逐步推理相结合,形成完整的解决方案链以进行冷启动强化学习训练。这种将自然语言推理和正式证明结合起来的方法使[Ren et al., 2025]模型在MiniF2F测试集上达到88.9%的通过率,并在PutnamBench上解决了49个问题。
总之,上述端到端方法不仅极大地提高了自动证明能力,还弥合了自然数学语言和正式数学证明之间的差距。这些进步为自动形式化研究提供了更丰富的训练数据和更强的证明能力,推动自动形式化向前发展。
4 数学问题自动形式化的分类
数学作为一种严谨和系统的学科,其自动形式化具有独特而重要的意义,也是探索LLM完全可靠推理的基础。数学的自动形式化在多个维度上展现出广泛的应用前景和理论价值。接下来,我们将从多个角度详细分析数学领域的自动形式化,包括数学问题领域、数学问题难度以及数学问题的抽象层次分析。
4.1 数学问题领域
为了更好地说明自动形式化在数学各领域的多样性和挑战,我们现在深入探讨最近取得最显著进展的代表性子领域。每个领域都有其独特的特征,例如几何中的图形推理、代数中的符号操作以及对正式系统的不同要求。对这些领域的详细分析有助于更清楚地理解自动形式化如何适应不同的语义结构、输入模式和推理范式。
几何和拓扑问题
这类问题的特征在于问题描述中的大部分信息包含在图中。其与其它问题域的核心区别在于信息复杂性:几何和拓扑问题涉及自然语言描述和图形元素(例如几何、坐标系、拓扑关系)。例如,几何问题中的图形具有隐藏属性,如角度和边长,图形信息需要编码成符号逻辑(例如通过坐标系或几何定理)。难点在于图形特征的提取以及需要对文本和图形的语义进行对齐(例如三角形A、B、C的顶点位置匹配),而大多数其他问题领域仅依赖于自然语言描述。[Murphy et al., 2024] 解决了欧几里得几何自动形式化中的挑战:非正式证明依赖图表,留下难以形式化的缺陷。非正式几何证明中常见的隐式图形推理,例如证明使用图形中两个圆的交点,但未证明其存在性,因此需要模型填补图形推理的缺陷。为了填补这一缺陷,[Murphy et al., 2024] 使用了一个名为E的形式化系统,该系统提取一组图形规则,以便将其建模为逻辑图形推理,从而实现形式化。
代数和数论问题
这类问题的特征在于符号逻辑。这种问题的自动形式化核心是将自然语言描述的变量、方程和运算规则转换为符号逻辑链。例如,线性代数问题(如矩阵运算)需要将自然语言描述的概念如向量空间映射到正式语言如向量空间,其中的难点在于解决嵌套符号结构和隐式运算的优先级。由于数学语言包含自然语言中不常见或不存在的特征,如数字、变量和定义术语,[Cunningham et al., 2023] 提出了一种基于通用变换器的语义解析方法。这包括复制机制,为定理及其证明中的每个唯一数值常量或变量字面量引入不同的通用标签,并通过使用数值、变量和定义的通用标签,只需有限的嵌入集进行训练,模型就能泛化到不可见的数字或变量和定义名称,并在一定程度上支持词汇外的数学术语。与几何和拓扑问题相比,代数和数论问题更注重各种变量间的引用和嵌套关系以及隐式运算逻辑。这是LLM的舒适区,利用LLM强大的逻辑推理能力处理纯文本,可以更好地解决问题而无需跨模态对齐。
复杂系统和前沿问题
这些问题通常直接解决实际挑战,连接理论和现实需求,包括尚未完全形式化的尖端数学。例如,偏微分方程用于描述跨越时间和空间相互作用的复杂系统。例如,受热和机械拉伸影响的杆系统通过热方程和波动方程建模和控制。[Soroco et al., 2025] 使用信号时序逻辑对偏微分方程控制问题中的约束进行形式化,以便清晰准确地将复杂规格约束表达为逻辑公式并消除可能的歧义。然后利用LLM完成自动形式化任务。这种方法对复杂系统问题具有极大的科学和工程应用潜力。前沿数学涵盖了数百个未公开的问题,防止大型模型“记住数据”来解决它们。强大的GPT-O3仅解决了25.2%的问题,而其他LLM仅解决了2%的问题。这揭示了现有大型模型与人类数学专家在创造性推理维度上仍存在较大差距,这也是当前自动形式化领域面临的问题。
4.2 数学问题的难度级别
自动形式化还可以根据语料库的难度级别划分为三个层次:高中、本科和研究生数学问题。不同难度级别的数学问题不仅在语言表达上有所不同,而且在证明的复杂性上也有所不同:例如,证明的长度、使用的策略类型和数量,以及抽象水平都呈现逐步增加的趋势。
高中水平
高中数学问题主要集中在高中数学竞赛问题上,如国际数学奥林匹克(IMO)、美国数学竞赛(AIMC)等其他数学竞赛。问题通常思路清晰,证明过程简短,逻辑结构标准化,一般涉及基础代数、几何和初步数论命题。[Zheng et al., 2022] 提出的一个代表性数据集miniF2F中的问题大多取自高中奥林匹克数学问题,具有清晰的结构和有限的步骤。
本科水平
本科水平的数学问题大多来自经典数学教材,涵盖实分析、线性代数、抽象代数、拓扑等领域。代表性的数据集是[Azerbayev et al., 2023] 中提出的ProofNet,其中包含371个示例,每个示例由Lean 3中的正式定理、自然语言定理陈述和证明组成。它涵盖了实分析、复分析、线性代数、抽象代数和拓扑。[Lu et al., 2024b] 提出的FormL4数据集从Mathlib4中提取定理,并通过大规模语言模型生成相应的非正式描述,反映了大学数学定理从基础到复杂证明的逐步进展。问题涉及更高层次的抽象,证明过程长且严谨,模型需要理解高层次的数学概念。
研究生水平
研究生及以上水平的问题通常来源于最新的学术论文或高级数学专著,涉及比本科水平更高的定理背景、证明策略和概念抽象。[Patel et al., 2024] 提出了一个名为arXiv2Formal的代表性数据集,采样自arXiv上的数学论文,包含50个研究级别的定理,重点在于“无链接形式化”,即在形式化过程中缺少必要的背景定义时,模型需要进行“无链接形式化”,即在缺乏完整上下文的情况下完成定义、引理和定理之间的连接。模型需要处理高度抽象的数学概念,理解复杂的证明策略,并在缺乏完整上下文的情况下进行推理和链接;[Gao et al., 2025] 提出的Herald数据集提供了由Mathlib4在Lean 4中生成的自然语言注释和正式证明对,旨在为自动形式系统提供细粒度的高级数学证明语料库。它主要面向研究生及以上的数学研究,包含高水平的数学语言和证明策略,适合训练模型以处理复杂的数学证明任务。
4.3 数学问题的抽象层次
证明长度和使用的策略数量为上述三个教育层次的数据集提供了可见的难度指示。大多数问题与提出的难度分类一致。本节进一步考察抽象层次作为区分问题难度的补充维度。许多数学家将抽象视为一种概括形式。例如,Luigi将其定义如下:“概念CCC的抽象是一个概念C′C^{\prime}C′,它包括所有CCC的实例,通过将对所有CCC的实例普遍成立的陈述作为公理来构造。”一个经典的例子是群的概念,它抽象了对象的所有对称性集合。当二元运算被解释为对称组合时,群公理捕捉了所有此类变换的共享结构。例如,正多边形的对称性,如旋转和反射,可以组合成一个满足群公理的集合。因此,群的概念通过将这些共享规律抽象成一个通用概念而产生。为了进一步说明抽象层次如何随着教育阶段的变化而演变,我们分析了“函数”这一概念在高中、大学和研究生数学问题中的处理方式。
高中数学中的程序抽象
根据《高级数学思维》,高中水平对函数的理解通常停留在程序抽象阶段——其特征是对技术的依赖而非形式化的公理推理。高中的数学抽象程度较低,内容紧密围绕具体例子和直观解释组织。例如,求解二次函数的零点通常涉及应用诸如计算判别式或分析函数图的技术方法。函数性质如单调性和偶性通过直接代数操作验证,对数值的依赖性强而非逻辑形式主义。例如,为了证明f(x)=exf(x)=e^{x}f(x)=ex的单调性,通常计算其导数——这种方法基于具体的计算而非抽象推理。
大学数学中的逻辑抽象
虽然抽象存在于所有阶段的数学思维中,但大学水平的问题通常要求更高程度的概念和逻辑抽象。一个典型例子是极限的概念。在高中,极限通常通过数值逼近引入,而大学数学则使用符号逻辑对其进行形式化,完全脱离具体的数值值。这种转变反映了一个根本变化:数学对象现在通过逻辑关系接近,具体的上下文示例被抽象掉。重点在于严格的定义和逻辑推导,这需要比高中问题中的程序推理更深的认知参与。
结构抽象在研究生数学中
在研究生水平,数学问题达到更高层次的抽象——强调数学空间的结构。函数不再仅仅被视为计算对象或可绘制表达式;它们被视为由满足属性定义的抽象空间元素。例如,(Lp)(L^{p})(Lp)空间由ppp-可积函数组成,而ℓp\ell^{p}ℓp空间由ppp-可和序列组成。数学焦点从分析具体函数转移到理解其所处空间的属性——如完备性、紧致性或对偶性。在这个阶段,解决问题往往涉及对这些函数空间内部结构的推理,构建它们之间的映射,或证明结构属性。这种抽象层次要求对数学系统及其相互关系有高度 sophisticated 的理解。
5 LLMs与形式验证的连接
自动形式化在大型模型输出的形式验证中起着至关重要的作用。尽管LLMs具有强大的性能,但它们也遭受严重的“幻觉”问题,使得LLMs的输出无法完全信任。因此,大型模型输出的形式验证已成为一个热门的研究方向。然而,为了获得完全可信的输出,LLMs需要进行完全正确的推理,这本质上是一个数学问题,可以使用各种形式验证方法,如一阶逻辑、高阶逻辑、形式语言等。无论使用何种形式验证方法,共同的问题是如何将输出自动形式化为该方法制定的相应“规则”。在推动LLMs进一步发展的方向上,自动形式化是LLMs与形式验证技术之间的桥梁。使两者优势互补并使LLMs生成完全可信的输出成为下一阶段研究的目标。
5.1 代码验证
在形式验证LLMs输出的领域中,传统研究内容是代码验证。大模型生成的代码是否正确直接影响代码能否运行。在代码生成领域,仅在美国,软件故障的成本估计每年高达数万亿美元 Krasner (2022)。自从LLMs问世以来,人们对其生成代码的强大能力寄予厚望。然而,目前生成代码的可验证性较差,因此确保生成代码的正确性至关重要。
非交互式验证
静态分析是一种无需执行程序并与其他验证器交互即可分析程序代码的技术。其目的是检测程序中的错误、验证程序的属性或提取程序的结构信息。静态分析在形式验证中起着重要作用。它提供了一种系统的方式来确保程序的正确性和可靠性。
依赖图
Liao et al. (2025) 根据静态分析的结果设计并构建依赖图,旨在捕获反编译代码中的关键语义信息以验证语义一致性。依赖图是一个三元组 DG=(V,E,L),其中 V 表示节点集,包含反编译代码中的所有变量及相关表达式。E 表示边集,包括控制流依赖边、状态依赖边和类型依赖边。L 是用于将边映射到三种依赖关系的标记函数。
断言生成
在代码验证领域,断言生成是自动化测试的关键方法,用于确保代码单元按预期行为。此过程主要围绕测试用例的编写和执行。测试用例通常由两部分组成:测试前缀(设置测试环境并调用待测函数的代码)和断言(用于验证函数输出或程序状态是否正确)。断言生成的目标是自动生成断言代码以减少手动编写测试用例的工作量并提高测试效率。在代码验证中,这一步骤至关重要,因为它直接决定了测试用例的有效性和准确性。
规范生成
规范在代码验证中常用于描述函数、模块或整个系统的预期行为,确保开发者理解需求并按预期实现功能。Ma et al. (2024) 通过两个阶段有效解决了传统方法的不足:对话驱动和变异驱动。对话驱动阶段通过使用验证器的反馈信息逐步引导模型生成准确的规范,从而提高规范的质量和准确性。在变异驱动阶段,对于LLM生成失败的规范,应用变异算子对其进行修改,并通过启发式选择策略筛选出最可能的规范,以进一步提高规范生成的成功率。
循环不变式生成
循环不变式生成描述了循环在每次迭代中必须满足的属性。目标是为程序中的循环找到一组在每次循环迭代中都成立的逻辑命题。这些不变式对于形式验证至关重要,因为它们允许验证工具在不考虑程序其余部分的情况下局部检查循环的正确性。Kamath et al. (2023) 提出了Loopy,它包含两个主要阶段。首先,使用LLM生成候选循环不变式。其次,使用符号工具(如Frama-C)验证这些候选不变式的正确性。如果LLM生成的不变式不正确,Loopy 使用修复过程调整这些不变式以使其正确。这种方法有效地利用了LLM的强大生成能力和符号工具的精确验证能力。
LLM交互验证
通过使用基于一阶/高阶逻辑和类型系统的交互式定理证明器,结合代码和LLMs进行验证。LLMs可以利用形式验证器的反馈过滤出正确的程序。
LLM生成 [Aggarwal et al., 2024] 使用大规模语言模型将高资源Dafny代码翻译成低资源Verus代码,解决数据稀缺问题,并生成候选程序。然后,使用树搜索算法和验证器的反馈交互信息优化生成的代码,使其正确。
LLM判断 [Liao et al., 2025] 使用LLM通过补充上下文信息的静态分析推断变量的正确类型,并通过推理链提示指导优化过程。SmartHalo会将静态分析中得出的依赖关系转换为自然语言描述(如“变量A的类型取决于表达式B”)并作为提示输入给LLM。这些提示帮助LLMS理解优化目标的静态约束,从而做出更准确的预测。
5.2 医疗领域
在医疗领域,大语言模型(LLMs)的应用潜力巨大,能够为医疗诊断、药物开发和患者护理等方面提供支持。然而,由于医疗领域的特殊性,它对可靠性和准确性有着极高的要求。医疗决策往往直接关系到患者的健康和安全。因此,使用形式验证确保基于LLMs的系统输出的准确性和可靠性已成为一项关键任务。[Hamed et al., 2025] 运用非交互式验证方法,使用简单的二元关系关联验证来验证LLMS生成的关联的可靠性。这种形式表示提供了一种建模不同类别术语之间关联的结构化方法。验证大模型在疾病、基因和药物本体数据集中生成的术语的语义准确性和可靠性。正确性验证:使用GO、DOID、ChEBI和症状本体等生物医学本体作为真实标准,验证术语的身份。当某个术语未在本体中找到时,称为“未验证”。可靠性验证:以二元关系表示。例如,疾病与基因的关联可以表示为RDG⊆D×G\operatorname{RDG} \subseteq \mathrm{D} \times \mathrm{G}RDG⊆D×G,其中D是疾病术语的集合,G是基因术语的集合。一对(d,g)∈RDG(\mathrm{d}, \mathrm{g}) \in \mathrm{RDG}(d,g)∈RDG表示特定基因ggg与特定疾病ddd相关联。这种形式表示提供了一种建模不同类别术语之间关联的结构化方法。
5.3 LLM输出验证
[Song et al., 2025] 探索了一种框架,在该框架中模型验证其自身的输出。基于此验证,过滤或重新加权数据并提取过滤后的数据。并启动了全面、模块化和受控的LLM自我改进研究。本文为自我改进提供了一个数学公式,主要由形式生成验证差距(GV-Gap)控制。[Hennigen et al., 2023] 提出的SymGen方法使用“符号引用”建立自然语言文本和结构化数据之间的关联。符号引用通过在文本中嵌入特定数据字段(如文件名)的参考标识符,为自动形式化提供明确的数据源参考。这种参考机制类似于形式方法中的模型注释或标记,可以帮助形式工具快速定位文本内容所依赖的数据元素,从而实现更高效的数据驱动形式转换。它不仅有助于确保文本生成阶段的内容准确性和可追溯性,还在后续的形式验证和维护过程中发挥关键作用。
6 进步的基础:技术和语料库
为了系统地研究自动形式化领域,我们收集了现有工作的开源代码、模型参数和数据集,如表1和表2所示。表1描述了现有工作及其开源代码的链接供使用。我们还总结了每种方法/模型使用的基准以及这些基准在相应方法/模型中的作用。顶角标记1{ }^{1}1 表示性能评估,顶角标记2{ }^{2}2 表示作为数据集训练模型,顶角标记+{ }^{+}+ 表示论文提出的基准。我们还总结了每种方法/模型的任务如下:
-
自动形式化证明:利用LLMs的推理能力,自动生成可验证的正式证明,对应给定的自然语言数学问题陈述。
-
- 数据构建:通过大规模合成和生成增强或过滤数据等方法突破数据稀缺瓶颈,提高模型性能。
-
- 评估自动形式化:编制形式证明助手并不意味着自动形式化完全正确。为了更好地验证自动形式化的正确性,提出了新方法或性能指标。
-
- 非形式化:形式陈述中的信息总是足够推断非形式陈述,但反之则不然。从分析经验来看,非形式化比形式化更容易。非形式化是指通过研究从形式语言到非形式语言的转换来增强自动形式化能力的过程。
-
- 检索增强:鉴于当前证明的状态,增强检索潜在前提的能力,并在它们之间建立反射。在证明定理时,模型在每一步生成多个候选策略,通过优先搜索算法找到证明,从而建立正确的证明。
-
- DSP:通过LLM将非正式证明映射到正式证明草图,并使用映射的草图帮助自动证明者搜索比完整问题更简单的子问题以完成证明。
-
- AST简化和转换:基于规则的自动形式化方法通常创建语法规则,生成相应的AST树,然后通过线性化方法将其转换为形式语言。
表2 对定理证明和自动形式化的数据集进行了全面概述。数据集按照数学难度级别(如奥赛级、本科数学)、规模(问题/定理数量)、主要任务和简要描述分类。了解这些数据集的数学难度级别至关重要,因为它直接影响模型评估:低级别问题(如小学数学)测试基本推理,而高级数据集(如研究级形式化)评估模型处理抽象和复杂依赖关系的能力。主要任务是概括数据集支持的任务类别,包括定理证明、自动形式化等。表格中的任务列解释如下:
- AST简化和转换:基于规则的自动形式化方法通常创建语法规则,生成相应的AST树,然后通过线性化方法将其转换为形式语言。
-
定理证明:从给定的命题生成或验证机器可检查的形式证明,通常使用预定义的策略或证明步骤。
-
- 自动形式化:将非正式数学命题翻译成形式代码,同时保持语义等价。
-
- 微调:使用较小的任务特定数据集(如Math(12.5k问题))适配预训练模型到特定领域。
-
- 预训练:在大规模语料库上训练基础模型以学习一般的数学推理模式。
-
- 问答:解决数学问题并生成分步的自然语言或形式化答案。
7 开放挑战与未来方向
尽管自动形式化近年来取得了令人鼓舞的进展,但仍需解决几个关键挑战,以充分释放其潜力——特别是在迈向大规模、值得信赖的AI系统进行数学推理的过程中。
最紧迫的问题之一是数据稀缺。尽管大规模语言模型(LLMs)受益于大量的开放域文本数据,但自动形式化需要高质量的平行语料库,包括对齐的非正式和正式数学陈述。由于生成正式证明所需的复杂性和专业知识,此类数据在规模和多样性方面仍然有限。当前资源——例如LeanWorkbook数据集(4.8MB)——代表了重要进展,但与用于训练其他领域LLMs的海量数据集相比仍然很小。解决这一差距需要开发更可扩展的数据收集管道、改进合成数据生成技术,或许还需要人机协作系统,以最少的专家干预逐步完善正式注释。
展望未来,能够在更大和更抽象的理论中进行形式化而不需广泛微调将是关键。正如[Wu et al., 2022] 所强调的,依赖完全重新训练在计算上昂贵且在大规模下不可行。相反,我们设想自动形式化系统能够组合式泛化、以最少监督适应新领域,并紧密集成到形式验证框架中。
另一个重要方向是改善自动形式化系统的交互性和模块化。与其将形式化视为纯粹的端到端任务,未来的系统可能会从结合LLMs与符号推理引擎、证明助手和基于逻辑的验证器中受益。这种混合方法可以提供更可控和可解释的输出,允许用户根据需要引导或验证过程的部分。
最后,自动形式化的长期愿景与AI研究的更广泛目标一致:创建能够进行创造性数学推理的系统。这样的系统不仅会验证现有的证明,还会提出猜想、探索新想法,并协助人类数学家发现新的研究方向[Tao, 2024]。实现这一点需要在自然语言理解、形式逻辑、数学建模和人机协作的交叉领域取得进展。
8 与其他综述的不同之处
现有研究如[Yang et al., 2024], [Li et al., 2024b], 和[Blaauwbroek et al., 2024] 均聚焦于人工智能时代形式化定理证明的发展,概述了各种形式化定理证明的研究方法。此外,[Yang et al., 2024] 和 [Li et al., 2024b] 还总结和描述了自动形式化的模型方法。其中,[Yang et al., 2024] 将自动形式化模型方法分为基于规则的自动形式化和基于神经网络和LLMs的自动形式化。本文的自动形式化模型方法借鉴了这种分类方法,并在此基础上进一步扩展了前沿研究。
然而,本文不限于模型方法本身,而是深入探讨了整个自动形式化的工作流程,并在更细微的层面上进行了分析。与[Yang et al., 2024] 和 [Li et al., 2024b] 仅对模型方法进行分类和描述不同,本文在此基础上更进一步。它不仅对模型方法进行了详细解读和分析,还对自动形式化工作流程中的每一部分进行了深入研究。包括数据预处理、模型方法、后处理技术和结果验证,从更细致的角度揭示了自动形式化的内部机制。
此外,本文还结合当前热点探讨了LLMs的形式验证自动形式化,并特别强调了
自动形式化在提升大规模语言模型的可信度和推理能力方面的关键意义。不同于[Blaauwbroek et al., 2024]专注于形式化定理证明的发展,本文从两个独特视角出发:形式验证和数学问题,深入探讨了自动形式化在LLMs中的应用和价值,为提升LLMs的性能提供了新的思路和方法。
参考文献
[Aggarwal et al., 2024] Pranjal Aggarwal, Bryan Parno, and Sean Welleck. Alphaverus: Bootstrapping formally verified code generation through self-improving translation and treefinement. arXiv preprint arXiv:2412.06176, 2024.
[Agrawal et al., 2022] Ayush Agrawal, Siddhartha Gadgil, Navin Goyal, Ashvni Narayanan, and Anand Tadipatri. Towards a mathematics formalisation assistant using large language models, 2022.
[AlphaProof and AlphaGeometry, 2024] Team AlphaProof and Team AlphaGeometry. Ai achieves silver-medal standard solving international 178 mathematical olympiad problems. DeepMind blog, 179:45, 2024.
[Antropic, 2024] Antropic. Claude 3 haiku: Our fastest model yet. 2024.
[Azerbayev et al., 2023] Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics, 2023.
[Azerbayev et al., 2024] Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics, 2024.
[Blaauwbroek et al., 2024] Lasse Blaauwbroek, David M Cerna, Thibault Gauthier, Jan Jakubův, Cezary Kaliszyk, Martin Suda, and Josef Urban. Learning guided automated reasoning: a brief survey. Logics and Type Systems in Theory and Practice: Essays Dedicated to Herman Geuvers on The Occasion of His 60th Birthday, pages 54-83, 2024.
[Cunningham et al., 2023] Garett Cunningham, Razvan C. Bunescu, and David Juedes. Towards autoformalization of mathematics and code correctness: Experiments with elementary proofs. CoRR, abs/2301.02195, 2023.
[de Moura et al., 2015] Leonardo de Moura, Soonho Kong, Jeremy Avigad, Floris van Doorn, and Jakob von Raumer. The lean theorem prover (system description). In Amy P. Felty and Aart Middeldorp, editors, Automated Deduction - CADE-25, pages 378-388, Cham, 2015. Springer International Publishing.
[Di et al., 2024] Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, et al. Codefuse-13b: A pretrained multi-lingual code large language model. In Proceedings of the 46th International Conference on Software
Engineering: Software Engineering in Practice, pages 418-429, 2024.
[Fleureau et al., 2024] Yann Fleureau, Edward Beeching Jia Li, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, and Kashif Rasul. How numinamath won the 1st aimo progress prize. 2024.
[Gao et al., 2025] Guoxiong Gao, Yutong Wang, Jiedong Jiang, Qi Gao, Zihan Qin, Tianyi Xu, and Bin Dong. Herald: A natural language annotated lean 4 dataset, 2025.
[Gonthier, 2008] Georges Gonthier. Formal proof-the fourcolor theorem. 2008.
[Hales et al., 2015] Thomas Hales, Mark Adams, Gertrud Bauer, Dat Tat Dang, John Harrison, Truong Le Hoang, Cezary Kaliszyk, Victor Magron, Sean McLaughlin, Thang Tat Nguyen, Truong Quang Nguyen, Tobias Nipkow, Steven Obua, Joseph Pleso, Jason Rute, Alexey Solovyev, An Hoai Thi Ta, Trung Nam Tran, Diep Thi Trieu, Josef Urban, Ky Khac Vu, and Roland Zumkeller. A formal proof of the kepler conjecture, 2015.
[Hamed et al., 2025] Ahmed Abdeen Hamed, Alessandro Crimi, Magdalena M Misiak, and Byung Suk Lee. From knowledge generation to knowledge verification: Examining the biomedical generative capabilities of chatgpt. arXiv preprint arXiv:2502.14714, 2025.
[Hennigen et al., 2023] Lucas Torroba Hennigen, Shannon Shen, Aniruddha Nrusimha, Bernhard Gapp, David Sontag, and Yoon Kim. Towards verifiable text generation with symbolic references. arXiv preprint arXiv:2311.09188, 2023.
[Huet et al., 1997] Gérard Huet, Gilles Kahn, and Christine Paulin-Mohring. The coq proof assistant a tutorial. Rapport Technique, 178:113, 1997.
[Jiang et al., 2023a] Albert Q. Jiang, Wenda Li, and Mateja Jamnik. Multilingual mathematical autoformalization, 2023.
[Jiang et al., 2023b] Albert Qiaochu Jiang, Sean Welleck, Jin Peng Zhou, Timothée Lacroix, Jiacheng Liu, Wenda Li, Mateja Jamnik, Guillaume Lample, and Yuhuai Wu. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
[Jiang et al., 2024] Albert Q. Jiang, Wenda Li, and Mateja Jamnik. Multi-language diversity benefits autoformalization. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 83600-83626. Curran Associates, Inc., 2024.
[Kamath et al., 2023] Adharsh Kamath, Aditya Senthilnathan, Saikat Chakraborty, Pantazis Deligiannis, Shuvendu K Lahiri, Akash Lal, Aseem Rastogi, Subhajit Roy, and Rahul Sharma. Finding inductive loop invariants using large language models. arXiv preprint arXiv:2311.07948, 2023.
[Krasner, 2022] Herb Krasner. The cost of poor software quality in the us: A 2022 report. Proc.Consortium Inf. Softw. QualityTM (CISQTM), 2022.
[Li et al., 2024a] Zenan Li, Yifan Wu, Zhaoyu Li, Xinming Wei, Xian Zhang, Fan Yang, and Xiaoxing Ma. Autoformalize mathematical statements by symbolic equivalence and semantic consistency, 2024.
[Li et al., 2024b] Zhaoyu Li, Jialiang Sun, Logan Murphy, Qidong Su, Zenan Li, Xian Zhang, Kaiyu Yang, and Xujie Si. A survey on deep learning for theorem proving. arXiv preprint arXiv:2404.09939, 2024.
[Li et al., 2025] Yang Li, Dong Du, Linfeng Song, Chen Li, Weikang Wang, Tao Yang, and Haitao Mi. Hunyuanprover: A scalable data synthesis framework and guided tree search for automated theorem proving, 2025.
[Liao et al., 2025] Zeqin Liao, Yuhong Nan, Zixu Gao, Henglong Liang, Sicheng Hao, Peifan Reng, and Zibin Zheng. Augmenting smart contract decompiler output through fine-grained dependency analysis and llm-facilitated semantic recovery. arXiv preprint arXiv:2501.08670, 2025.
[Lin et al., 2025] Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedelprover: A frontier model for open-source automated theorem proving, 2025.
[Liu et al., 2025] Qi Liu, Xinhao Zheng, Xudong Lu, Qinxiang Cao, and Junchi Yan. Rethinking and improving autoformalization: Towards a faithful metric and a dependency retrieval-based approach. In The Thirteenth International Conference on Learning Representations, 2025.
[Lu et al., 2024a] Jianqiao Lu, Yingjia Wan, Yinya Huang, Jing Xiong, Zhengying Liu, and Zhijiang Guo. Formalalign: Automated alignment evaluation for autoformalization, 2024.
[Lu et al., 2024b] Jianqiao Lu, Yingjia Wan, Zhengying Liu, Yinya Huang, Jing Xiong, Chengwu Liu, Jianhao Shen, Hui Jin, Jipeng Zhang, Haiming Wang, Zhicheng Yang, Jing Tang, and Zhijiang Guo. Process-driven autoformalization in lean 4, 2024.
[Luigi, 2003] Ferrari Pier Luigi. Abstraction in mathematics. 2003.
[Ma et al., 2024] Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. Specgen: Automated generation of formal program specifications via large language models. corr abs/2401.08807 (2024), 2024.
[Mohamed et al., 2008] Otmane Ait Mohamed, César Muñoz, and Sofiène Tahar. Theorem Proving in Higher Order Logics: 21st International Conference, TPHOLs 2008, Montreal, Canada, August 18-21, 2008, Proceedings, volume 5170. Springer Science & Business Media, 2008.
[Moura and Ullrich, 2021] Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. In Automated Deduction-CADE 28: 28th International Conference on Automated Deduction, Virtual
Event, July 12-15, 2021, Proceedings 28, pages 625-635. Springer, 2021.
[Murphy et al., 2024] Logan Murphy, Kaiyu Yang, Jialiang Sun, Zhaoyu Li, Anima Anandkumar, and Xujie Si. Autoformalizing euclidean geometry, 2024.
[OpenAI, 2024] OpenAI. Gpt-4 technical report, 2024.
[Patel et al., 2024] Nilay Patel, Rahul Saha, and Jeffrey Flanigan. A new approach towards autoformalization, 2024.
[Pathak, 2024] Shashank Pathak. Gflean: An autoformalisation framework for lean via gf, 2024.
[Paulson, 1994] Lawrence C Paulson. Isabelle: A generic theorem prover. Springer, 1994.
[Peano, 1889] Giuseppe Peano. 1889.
[Poiroux et al., 2025] Auguste Poiroux, Gail Weiss, Viktor Kunčak, and Antoine Bosselut. Improving autoformalization using type checking, 2025.
[Ren et al., 2025] Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition, 2025.
[Ryu et al., 2024] Hyun Ryu, Gyeongman Kim, Hyemin S Lee, and Eunho Yang. Divide and translate: Compositional first-order logic translation and verification for complex logical reasoning. arXiv preprint arXiv:2410.08047, 2024.
[Sadasivan et al., 2023] Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can ai-generated text be reliably detected? arXiv preprint arXiv:2303.11156, 2023.
[Shi et al., 2023] Ensheng Shi, Fengji Zhang, Yanlin Wang, Bei Chen, Lun Du, Hongyu Zhang, Shi Han, Dongmei Zhang, and Hongbin Sun. Sotana: The opensource software development assistant. arXiv preprint arXiv:2308.13416, 2023.
[Song et al., 2025] Yuda Song, Hanlin Zhang, Carson Eisenach, Sham Kakade, Dean Foster, and Udaya Ghai. Mind the gap: Examining the self-improvement capabilities of large language models, 2025.
[Soroco et al., 2025] Mauricio Soroco, Jialin Song, Mengzhou Xia, Kye Emond, Weiran Sun, and Wuyang Chen. Pde-controller: Llms for autoformalization and reasoning of pdes, 2025.
[Sozeau et al., ] Matthieu Sozeau, Guillaume Melquiond, and Pierre Roux. The coq proof assistant.
[Tao, 2024] Terence Tao. Machine-assisted proof. Notices of the American Mathematical Society, to appear, 2024.
[Team et al., 2024] Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, and Katie
Millican. Gemini: A family of highly capable multimodal models, 2024.
[Touvron et al., 2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023.
[Wang et al., 2025] Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Pagani, Moreira Machado, Pauline Bourigault, Ran Wang, Stanislas Polu, Thibaut Barroyer, Wen-Ding Li, Yazhe Niu, Yanlin Hu, Zhouliang Yu, Zihan Wang, Zhilin Yang, Zhengying Liu, and Jia Li. Kimina-prover preview: Towards large formal reasoning models with reinforcement learning, 2025.
[Wu et al., 2022] Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. Autoformalization with large language models, 2022.
[Wu et al., 2024a] Zijian Wu, Suozhi Huang, Zhejian Zhou, Huaiyuan Ying, Jiayu Wang, Dahua Lin, and Kai Chen. InternLM2.5-StepProver: Advancing automated theorem proving via expert iteration on large-scale Lean problems, 2024.
[Wu et al., 2024b] Zijian Wu, Jiayu Wang, Dahua Lin, and Kai Chen. Lean-GitHub: Compiling GitHub Lean repositories for a versatile Lean prover, 2024.
[Xin et al., 2024a] Huajian Xin, Daya Guo, Zhihong Shao, Z.Z. Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. Advancing theorem proving in LLMs through large-scale synthetic data. In The 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024.
[Xin et al., 2024b] Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and Monte Carlo tree search, 2024.
[Xin et al., 2025] Ran Xin, Chenguang Xi, Jie Yang, Feng Chen, Hang Wu, Xia Xiao, Yifan Sun, Shen Zheng, and Kai Shen. BFS-prover: Scalable best-first tree search for LLM-based automatic theorem proving, 2025.
[Yang et al., 2024] Kaiyu Yang, Gabriel Poesia, Jingxuan He, Wenda Li, Kristin Lauter, Swarat Chaudhuri, and Dawn Song. Formal mathematical reasoning: A new frontier in AI. arXiv preprint arXiv:2412.16075, 2024.
[Zhang et al., 2025] Jingyuan Zhang, Qi Wang, Xingguang Ji, Yahui Liu, Yang Yue, Fuzheng Zhang, Di Zhang, Guorui Zhou, and Kun Gai. Leanabell-prover: Posttraining scaling in formal reasoning, 2025.
[Zheng et al., 2022] Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. MiniF2F: A cross-system benchmark for formal olympiad-level mathematics, 2022.
[Zheng et al., 2024] Chuanyang Zheng, Haiming Wang, Enze Xie, Zhengying Liu, Jiankai Sun, Huajian Xin, Jianhao Shen, Zhenguo Li, and Yu Li. Lyra: Orchestrating dual correction in automated theorem proving, 2024.
参考论文:https://arxiv.org/pdf/2505.23486

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)