LangGraph+FastAPI+Next.js构建全栈大模型聊天机器人,大模型入门到精通,收藏这篇就足够了!
ai-chatkit是一个开源AI Agent全栈聊天工具,这个项目可以作为一个模板,帮助你使用LangGraph框架快速搭建相关的AI智能体聊天应用,并且支持RAG来增强智能体的知识库问答能力。
一、项目介绍
1. 项目背景
大模型智能体的应用场景一般以聊天机器人为入口,从而构建一个用户端聊天交互界面,用户可以通过界面与智能体进行对话,诸如智能客服、知识问答、知识库问答等等都是基于聊天进行交互的,所以说开发一个智能体应用必然需要一个大模型聊天应用。
ai-chatkit是一个开源AI Agent全栈聊天工具,这个项目可以作为一个模板,帮助你使用LangGraph框架快速搭建相关的AI智能体聊天应用,并且支持RAG来增强智能体的知识库问答能力。
项目技术栈
以下项目主要使用的技术栈:
后端:
- • 语言:Python ,版本:3.13
- • AI应用框架:LangGraph
- • WEB框架:fastApi
- • 向量数据库: chroma
- • 关系数据库: sqlite
- • 包管理工具: uv
前端:
- • 框架:Next.js, React
- • 页面组件:Ant-design, Tailwind CSS
主要特性
1、基于langGraph框架搭建的智能体聊天应用,支持自定义智能体的行为逻辑编排。
2、支持自定义智能体的知识库问答能力,基于ChromaDB来存储和查询知识库。
3、支持自定义智能体的工具调用
4、Python后端接口API,基于FastAPI来实现,支持全异步调用。
5、支持自定义智能体的前端应用,基于NextJS来实现。
6、支持聊天Streaming流输出,前端支持SSE流输出。
7、支持自定义多个智能体
8、支持多智能体协作
9、聊天历史记录保存在本地浏览器缓存中
聊天界面
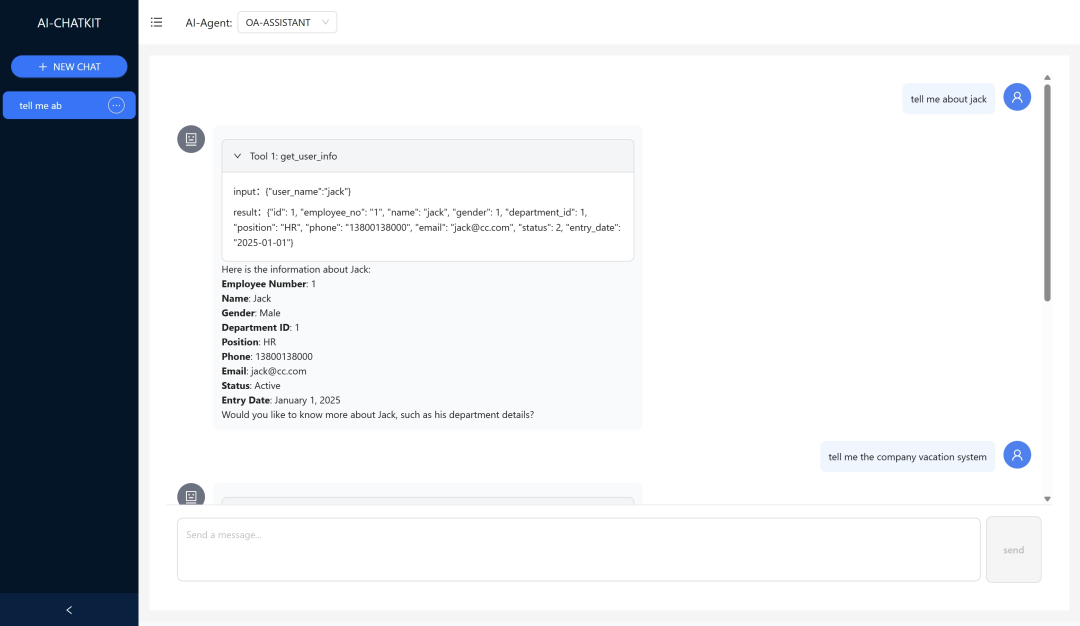
二、主要框架组件介绍
LangGraph
LangGraph 是一个专门用于构建复杂、状态化多智能体(Multi-Agent) AI 应用的开源框架。它由 LangChain 团队开发,核心思想是用“图”(Graph)的结构来设计和编排 AI 工作流,特别擅长处理需要循环、分支、状态持久化和人工干预的复杂任务。
简单来说,它把 AI 应用中的每个步骤(如调用大模型、执行工具函数、人工审核等)抽象为节点(Node),用边(Edge) 来定义节点间的流转逻辑,并通过状态(State) 来管理和持久化整个工作流的数据。这使得开发者能够以更直观、可控的方式构建强大的 AI 应用。
所以LangGraph这种“图”思想特别适合构建和编排各种AI智能体的应用。
FastAPI
FastAPI 是一个基于 Python 的现代、高性能 Web 框架,专为构建高效 API 设计。它结合了 Starlette(异步 Web 框架)和 Pydantic(数据验证库),通过 Python 类型提示实现自动数据校验、文档生成和异步支持,成为开发高性能 API 的热门选择
核心特性
1.高性能与异步支持
- • 基于 ASGI 协议(异步服务器网关接口),原生支持 async/await语法,可轻松处理高并发请求(实测 QPS 达 3000+),性能对标 Go 和 Node.js。
- • 对比传统框架:比 Flask 快 3-5 倍,比 Django 快 4 倍以上。
2.自动化工具链
- • 自动生成交互式文档:集成 Swagger UI 和 ReDoc,访问 /docs或 /redoc即可实时查看、测试 API 接口。
- • 数据验证与序列化:通过 Pydantic 模型自动校验请求/响应数据,类型错误时返回 422 状态码及详细错误信息。
3.开发效率提升
- • 类型提示驱动:结合 Python 类型注解,IDE(如 VSCode)提供自动补全和错误提示,减少 40% 以上编码错误。
- • 依赖注入系统:简化共享资源管理(如数据库连接、身份验证),提升代码复用率。
FastAPI 凭借高性能、开发效率与标准化优势,成为 Python API 开发的标杆框架,尤其适合需要高并发和快速迭代的场景(如 AI 服务、微服务架构)
Next.js
Next.js 是由 Vercel 开发的基于 React 的开源 Web 框架,专为构建高性能、可扩展的现代 Web 应用而设计。它通过提供开箱即用的服务器端渲染(SSR)、静态站点生成(SSG)和全栈开发能力,显著简化了 React 应用的开发流程.
核心特性
1.灵活的渲染模式
- • 服务端渲染(SSR):页面在服务器端动态生成后发送至客户端,提升首屏加载速度与 SEO 效果,适合电商、新闻等动态内容场景。
- • 静态站点生成(SSG):构建时预渲染为静态 HTML,适用于博客、文档站等内容稳定的项目,支持 CDN 加速实现毫秒级加载。
- • 增量静态再生(ISR):按需更新静态页面(如定时刷新部分内容),无需全站重建,平衡性能与内容实时性。
2.零配置路由系统
- • 基于文件系统自动生成路由:pages/about.js→ /about,pages/blog/[slug].js→ /blog/xxx(动态路由),无需手动配置。
- • 支持嵌套布局(Layout):通过 layout.tsx统一管理页面结构,提升组件复用率。
3.内置全栈开发支持
- • API 路由:在 pages/api/下创建 Node.js 风格接口,无缝对接数据库或第三方服务,实现前后端一体化
4.开箱即用
- • 不需要手工配置路由和构建打包,直接可以启动,不需要vite等构建工具
三、快速开始
代码结构
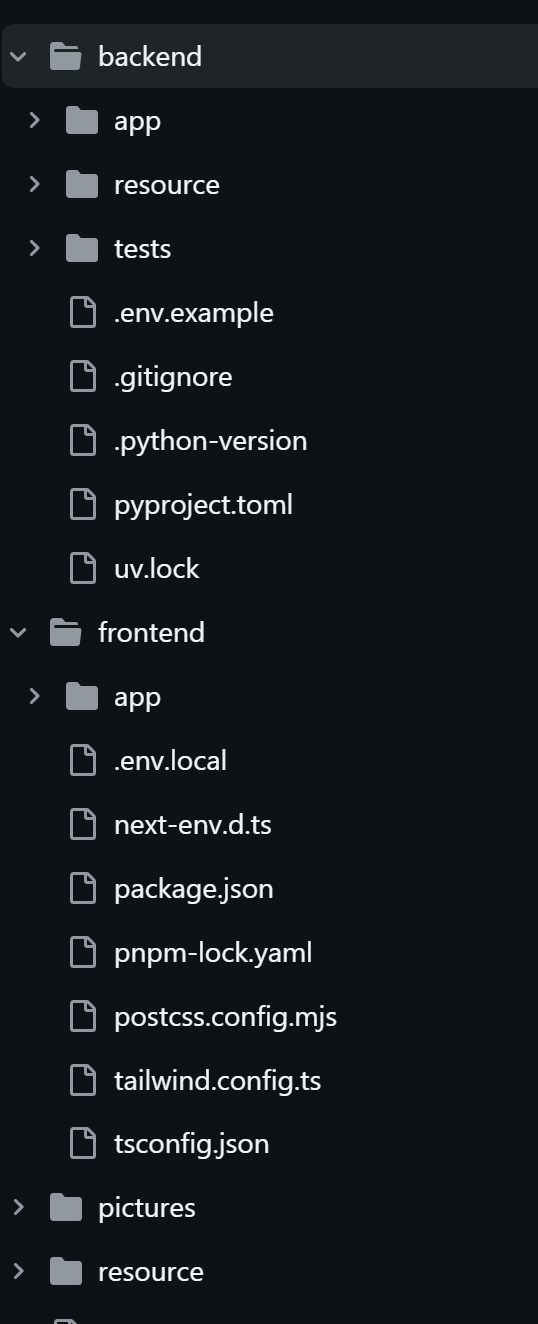
- •
backend: 后端服务代码 - •
frontend: 前端服务代码
后端服务
后端.env文件配置
修改.env.example文件名为.env
# 环境变量配置# 数据库配置#slqlite urlDATABASE_URL=sqlite+aiosqlite:///resource/database.db#mysql # DATABASE_URL=mysql+aiomysql://root:root@localhost/ai-chatkit# 应用配置DEBUG=TrueAPP_NAME=AI ChatKit# openaiOPENAI_API_KEYDEFAULT_MODEL=gpt-4o-mini# 通义千问API,因为deepseek的api响应比较慢,如果用不了openai的api,建议使用阿里百炼的api#DASHSCOPE_API_KEY=#DEFAULT_MODEL=qwen-plus# deepseek api#DEEPSEEK_API_KEY=#DEFAULT_MODEL=deepseek-chat# 使用bge-m3为embedding模型,支持中英双文,需要本地通过ollama部署bge-me模型EMBEDDING_MODEL=bge-m3#chromadb的相对存储路径CHROMA_PATH=resource/chroma_db
启动后端服务:
# Use the uv tool to manage Python dependenciespip install uv# Replace ${workdir} with your own working directorycd ${workdir}/backenduv sync --frozen# 使用python虚拟环境source .venv/bin/activate# 如果是windows系统启动python虚拟环境,请使用以下命令# .venv/Script/active#run serverpython app/run_server.py
RAG 部署
本工程默认访问本地的ollama部署的bge-m3,故如果要在本地访问知识库,则需要本地部署ollama,本地ollama部署bge-m3请参考:https://ollama.com/library/bge-m3
前端应用
# ${workdir}替换为你自己的工作目录cd ${workdir}/frontend# 采用pnpm管理依赖包pnpm install# 启动前端应用pnpm dev
启动成功后则可以,访问地址:http://localhost:3000/,直接可以打开聊天界面了
支持多智能体应用
本项目你可以使用LangGraph扩展创建并编排多个智能体,每个智能体可以都有自己行为逻辑,智能体的编排逻辑可以写在backend/app/ai/agent目录。
在前端你可以切换不同的智能体进行对话,具体如下:
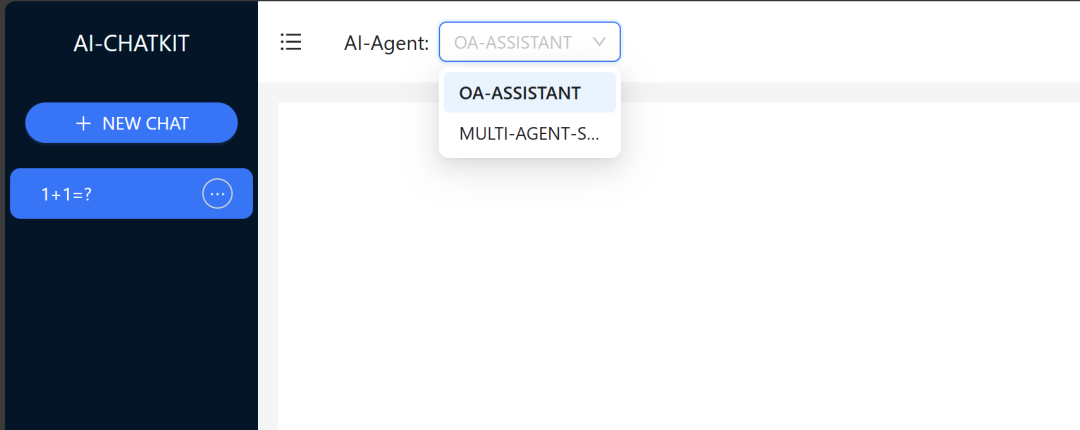
本项目自带以下智能体:
1、OA-ASSISTANT,主要用于演示OA助手智能体,支持员工信息查询和员工手册知识库检索
具体可以参考:backend/app/ai/agent/oa_assistant.py
2、MULTI_AGENT_SUPERVISOR,主要用于演示多智能体协作智能体,支持多个智能体之间的协作,multi_agent包含三个智能体:
1)math_agent :数学智能体, 主要用于处理数学计算
2)code_agent :代码智能体,主要用于处理代码生成
3)general_agent :通用智能体,主要用于处理通用问题
三个智能体通过supervisor进行协作管理:
聊天演示如下:
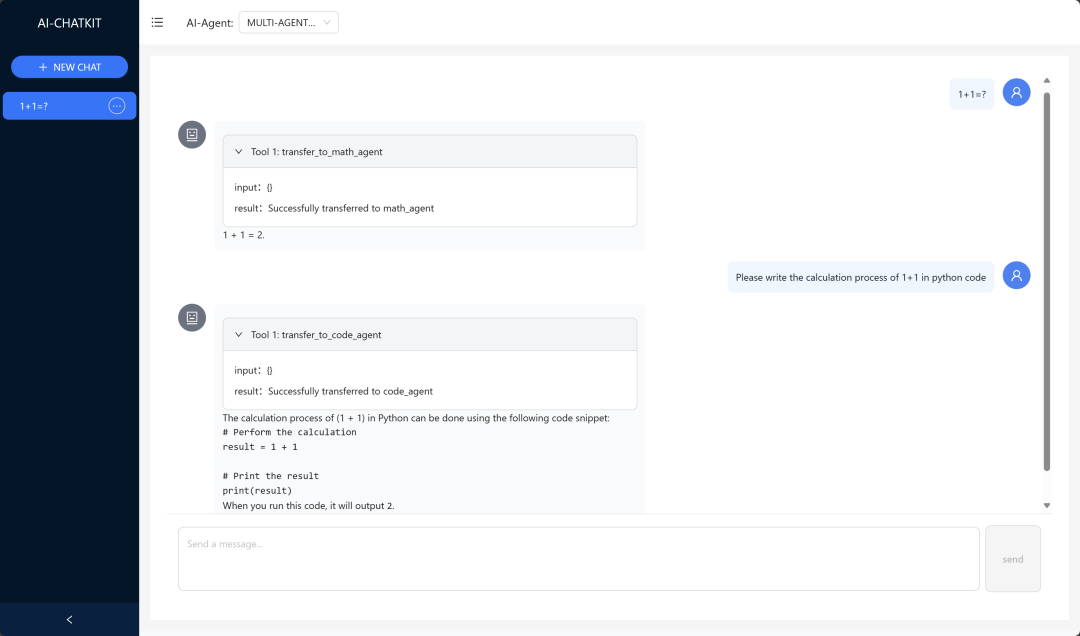
具体可以参考:backend/app/ai/agent/multi_agent.py
四、主要源码解析
1、定义使用的大模型
backend\app\ai\llm.py
可以在.env文件中配置默认使用的大模型,目前支持以下大模型客户端:
- • openai
- • ollama
- • deepseek
- • 通义千问
...ModelT: TypeAlias = ( ChatOpenAI | ChatOllama | ChatDeepSeek | FakeToolModel | ChatTongyi)@cachedefget_model(model_name: AllModelEnum, /) -> ModelT: """ Get model by model name. Args: model_name: Model name. Returns: Model instance. """ api_model_name = _MODEL_TABLE.get(model_name) ifnot api_model_name: raise ValueError(f"Unsupported model: {model_name}") if model_name in OpenAIModelName: return ChatOpenAI(model=api_model_name, temperature=0.5, streaming=True) if model_name in DeepseekModelName: return ChatDeepSeek( model=api_model_name, temperature=0.5, streaming=True, api_key=settings.DEEPSEEK_API_KEY, ) if model_name in OllamaModelName: if settings.OLLAMA_BASE_URL: chat_ollama = ChatOllama( model=settings.OLLAMA_MODEL, temperature=0.5, base_url=settings.OLLAMA_BASE_URL ) else: chat_ollama = ChatOllama(model=settings.OLLAMA_MODEL, temperature=0.5) return chat_ollama if model_name in FakeModelName: return FakeToolModel(responses=["This is a test response from the fake model."]) if model_name in TongYiModelName: return ChatTongyi(model=api_model_name, temperature=0.5, streaming=True)
2、定义LangGraph 智能体工厂
backend\app\ai\agent\agents.py
项目支持多个智能体,可以在界面选择与哪一个智能体进行对话,以下是根据前端传入的agent_id获取智能体
from dataclasses import dataclassfrom langgraph.graph.state import CompiledStateGraphfrom pydantic import BaseModel, Fieldfrom ai.agent.oa_assistant import oa_assistantfrom ai.agent.multi_agent import supervisor_agentDEFAULT_AGENT = "oa-assistant"classAgentInfo(BaseModel): """Info about an available agent.""" key: str = Field( description="Agent key.", examples=["oa-assistant"], ) description: str = Field( description="Description of the agent.", examples=["A oa assistant for company"], )@dataclassclassAgent: description: str graph: CompiledStateGraphagents: dict[str, Agent] = { "oa-assistant": Agent(description="A oa intelligent assistant.", graph=oa_assistant), "multi-agent-supervisor": Agent(description="A supervisor for multi-agent assistant.", graph=supervisor_agent),}## 根据agent_id获取agentdefget_agent(agent_id: str) -> CompiledStateGraph: return agents[agent_id].graphdefget_all_agent_info() -> list[AgentInfo]: return [ AgentInfo(key=agent_id, description=agent.description) for agent_id, agent in agents.items() ]
3、创建智能体
backend\app\ai\agent\oa_assistant.py
这里以oa_assistant为例,使用langGraph进行智能体流程编排,支持工具调用和RAG检索
如果扩展更多智能体,可以参考此文件进行添加
class AgentState(MessagesState): """State of the agent."""tools = [get_user_info, get_user_department, search_handbook]defwrap_model(model: BaseChatModel) -> RunnableSerializable[AgentState, AIMessage]: model = model.bind_tools(tools) preprocessor = RunnableLambda( lambda state: [SystemMessage(content=instructions)] + state["messages"], name="StateModifier", ) return preprocessor | modelinstructions = """ You are an assistant of a company's OA system, and your task is to help users query the administrative and personnel information within the company. You need to use tools to query relevant information from the database and knowledge base based on the user's questions and return it to the user. It is not allowed to forge the relevant regulations of the company at will to avoid misleading users out of thin air. You need to answer the users' questions and ensure the accuracy and completeness of the answers. You need to pay attention to the users' questions and avoid answering questions that they don't care about. The current time is:{current_time}"""asyncdefcall_model(state: AgentState, config: RunnableConfig) -> AgentState: """This node is to call llm model""" m = get_model(config["configurable"].get("model", settings.DEFAULT_MODEL)) model_runnable = wrap_model(m) response = await model_runnable.ainvoke(state, config) return {"messages": [response]}# After "model", if there are tool calls, run "tools". Otherwise END.defpending_tool_calls(state: AgentState) -> Literal["tools", "done"]: last_message = state["messages"][-1] ifnotisinstance(last_message, AIMessage): raise TypeError(f"Expected AIMessage, got {type(last_message)}") if last_message.tool_calls: return"tools" return"done"# Define the graphagent = StateGraph(AgentState)agent.add_node("model", call_model)agent.add_node("tools", ToolNode(tools = tools))agent.set_entry_point("model")agent.add_edge("tools", "model")agent.add_conditional_edges("model", pending_tool_calls, {"tools": "tools", "done": END})oa_assistant = agent.compile( checkpointer=MemorySaver(),)oa_assistant.name = "oa_assistant"
4、定义LLM工具调用
backend\app\ai\tools\oa_tools.py
这里定义了数据库查询工具,以及用户手册智能库搜索工具
数据库使用FastApi的SQLModel组件操作,基于SQLAlchemy组件,支持异步查询
@toolasyncdefget_user_info(user_name: str) -> dict: """Obtain user information""" asyncwith async_session_maker() as session: employee = await EmployeeRepository.get_employee_by_name(session, name=user_name) ifnot employee: return {"error": "user not found"} return asdict(employee)@toolasyncdefget_user_department(user_name: str) -> dict: """Obtain the information of the user department""" asyncwith async_session_maker() as session: employee = await EmployeeRepository.get_employee_by_name(session, name=user_name) ifnot employee: return {"error": "user not found"} department = await DepartmentRepository.get_department(session, department_id=employee.department_id) ifnot department: return {"error": "department not found"} return asdict(department)@toolasyncdefsearch_handbook(query: str) -> str: """ Check the employee handbook and the internal rules and regulations of the company """ result = hand_book_vector_store.similarity_search(query, k=10) if result.__len__ == 0: return"no result found" return"\n\n".join(doc.page_content for doc in result)
5、定义chroma 客户端和Vector Store
backend\app\ai\rag\chromaClient.py
client = chromadb.PersistentClient(path=settings.CHROMA_PATH,settings=Settings(anonymized_telemetry=False))#embeddings = OllamaEmbeddings( model=settings.EMBEDDING_MODEL,)# collection = client.get_or_create_collection(name="handbook") hand_book_vector_store = Chroma( collection_name="handbook", persist_directory=settings.CHROMA_PATH, # Where to save data locally, remove if not necessary embedding_function=embeddings, client=client, create_collection_if_not_exists=True,)
6、FastAPI聊天接口定义
backend\app\api\chat_routes.py
接口支持Stream流输出
@chat_router.post("/stream", response_class=StreamingResponse, responses=_sse_response_example())async def stream(user_input: StreamInput) -> StreamingResponse: """ 流式传输代理的响应。 """ return StreamingResponse( message_generator(user_input), media_type="text/event-stream", )...
7、前端处理SSE流
frontend\app\chat\hooks\useStreamChat.ts
支持SSE流打印输出,并在聊天界面中显示工具的调用
export constuseStreamChat = ({ currentThreadId, agentId, setMessages, isStreaming, setIsStreaming,}: UseStreamChatProps) => {consthandleStream = async (input: string) => { if (!input.trim() || isStreaming) return; setIsStreaming(true); constnewUserMessage: Message = { id: `user_${Date.now()}`, type: "user", content: input, }; constnewAiMessage: Message = { id: `ai_${Date.now()}`, type: "ai", content: "", }; setMessages((prev: Message[]) => [...prev, newUserMessage, newAiMessage]); try { const requestMsg = { thread_id: currentThreadId, role: "user", message: input, agent_id: agentId, }; const response = awaitfetch(`${process.env.NEXT_PUBLIC_API_BASE_URL}/chat/stream`, { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify(requestMsg), }); const reader = response.body?.getReader(); const decoder = newTextDecoder(); while (reader) { const { done, value } = await reader.read(); if (done) break; const dataChunk = decoder.decode(value, { stream: true }); dataChunk.split("\n").forEach((line) => { if (line.startsWith("data: ")) { const data = JSON.parse(line.replace("data: ", "")); switch (data.type) { case"message": handleMessageData(data.content); break; case"token": handleTokenData(data.content); break; case"end": setIsStreaming(false); reader.cancel(); break; } } }); } } catch (error) { console.error(" Request Failed:", error); message.error(" Request Failed, Please try again later."); setIsStreaming(false); } };consthandleMessageData = (content: any) => { if (content.type === "ai" && content.tool_calls.length > 0) { setMessages((prev) =>{ var addCalls = [] const calls = prev[prev.length - 1].toolCall?.calls || [] const toolCalls = content.tool_calls; if(calls.length === 0){ addCalls = toolCalls; }else{ calls.map((call) => { for (const toolCall of toolCalls) { if (call.id != toolCall.id) { if(addCalls.find((c) => c.id === toolCall.id) == null){ addCalls.push(toolCall); } } } }); } return prev.map((msg, i) => i === prev.length - 1 ? { ...msg, toolCall: { ...msg.toolCall, calls: [...(msg?.toolCall?.calls || []), ...addCalls] }, } : msg ) } ); }elseif (content.type === "ai" && content.content) { setMessages((prev) => prev.map((msg, i) => i === prev.length - 1 ? { ...msg, content: content.content } : msg ) ); } if (content.type === "tool") { setMessages((prev) => { const updatedCalls = prev[prev.length - 1].toolCall.calls.map((call) => call.id === content.tool_call_id ? { ...call, result: content.content } : call ); return prev.map((msg, i) => i === prev.length - 1 ? { ...msg, toolCall: { ...msg.toolCall, calls: [...updatedCalls] }, } : msg ); }); } };consthandleTokenData = (token: string) => { setMessages((prev) => prev.map((msg, i) => i === prev.length - 1 ? { ...msg, content: msg.content + token } : msg ) ); };return { handleStream };};
五、最后
本项目所有源码已经发布到GitHub: https://github.com/pasonk/ai-chatkit
有兴趣的同学自取,顺手Star一下_,,也欢迎指正与交流学习
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献476条内容
已为社区贡献476条内容

所有评论(0)