从零开始学 Dify - 一文搞懂 Dify 消息队列与任务调度的设计精髓
Dify 采用事件驱动架构来处理消息和任务,通过多层次的事件系统和任务调度机制,实现了高效、可扩展的异步处理能力。本文档将详细介绍 Dify 中的消息事件和 Task 实现机制,帮助理解系统的核心架构。# 消息事件# 应用事件# 租户事件。
Dify 中消息事件系统和 Task 任务调度机制的实现原理,包括事件定义、事件处理、队列管理和任务调度等核心组件。事件驱动+异步任务,构建高性能、高可用的 AI 应用系统。
目录
-
概述
-
消息事件系统
-
工作流事件系统
-
Task 任务调度机制
-
队列管理机制
-
事件处理流程
-
架构设计图
-
最佳实践
-
消息事件与 Task 任务的区别与联系
-
异常处理和容错机制
-
总结
概述
Dify 采用事件驱动架构来处理消息和任务,通过多层次的事件系统和任务调度机制,实现了高效、可扩展的异步处理能力。本文档将详细介绍 Dify 中的消息事件和 Task 实现机制,帮助理解系统的核心架构。
核心特性
-
事件驱动架构:基于事件的异步通信机制
-
多层次队列管理:支持不同类型的任务队列
-
实时状态同步:通过事件实现实时状态更新
-
可扩展性:支持水平扩展和负载均衡
-
容错机制:完善的错误处理和重试机制
消息事件系统
事件类型定义
Dify 使用 Blinker 库实现信号机制,定义了多种消息事件类型:
# 消息事件
message_was_created = signal("message-was-created")
# 应用事件
app_was_created = signal("app-was-created")
app_model_config_was_updated = signal("app-model-config-was-updated")
app_published_workflow_was_updated = signal("app-published-workflow-was-updated")
app_draft_workflow_was_synced = signal("app-draft-workflow-was-synced")
# 租户事件
tenant_was_created = signal("tenant-was-created")
tenant_was_updated = signal("tenant-was-updated")
事件处理器
事件处理器通过装饰器模式连接到相应的信号:
@message_was_created.connect
def handle(sender, **kwargs):
application_generate_entity = kwargs.get("application_generate_entity")
# 处理消息创建事件
消息事件流程图
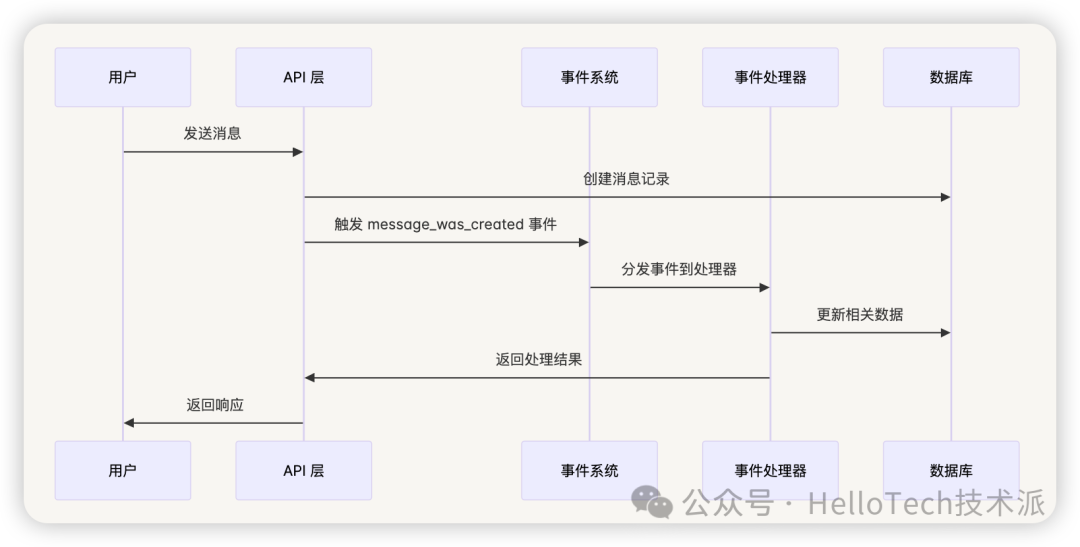
工作流事件系统
事件层次结构
Dify 的工作流事件系统采用分层设计,包含以下主要事件类型:
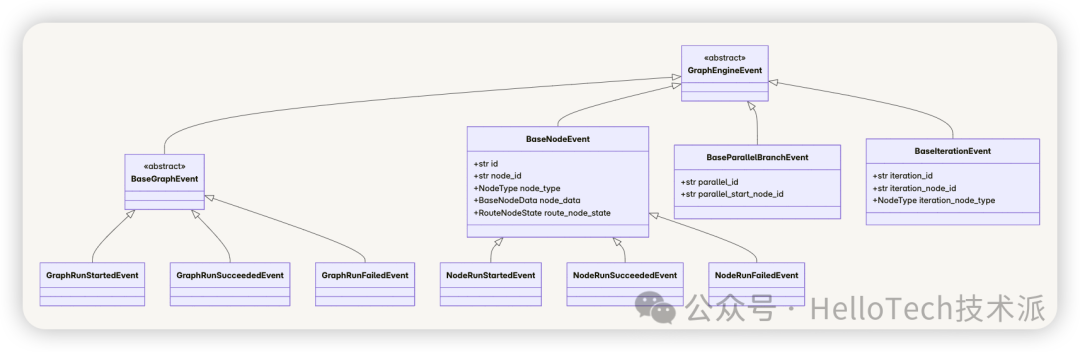
核心事件类型
图级事件(Graph Events)
-
GraphRunStartedEvent:工作流开始执行
-
GraphRunSucceededEvent:工作流成功完成
-
GraphRunFailedEvent:工作流执行失败
-
GraphRunPartialSucceededEvent:工作流部分成功
节点级事件(Node Events)
-
NodeRunStartedEvent:节点开始执行
-
NodeRunStreamChunkEvent:节点产生流式输出
-
NodeRunRetrieverResourceEvent:节点检索到资源
-
NodeRunSucceededEvent:节点成功执行完成
-
NodeRunFailedEvent:节点执行失败
-
NodeRunExceptionEvent:节点执行异常
-
NodeRunRetryEvent:节点重试执行
并行分支事件(Parallel Branch Events)
-
ParallelBranchRunStartedEvent:并行分支开始执行
-
ParallelBranchRunSucceededEvent:并行分支成功完成
-
ParallelBranchRunFailedEvent:并行分支执行失败
迭代事件(Iteration Events)
-
IterationRunStartedEvent:迭代开始执行
-
IterationRunNextEvent:迭代下一步
-
IterationRunSucceededEvent:迭代成功完成
-
IterationRunFailedEvent:迭代执行失败
工作流事件处理流程
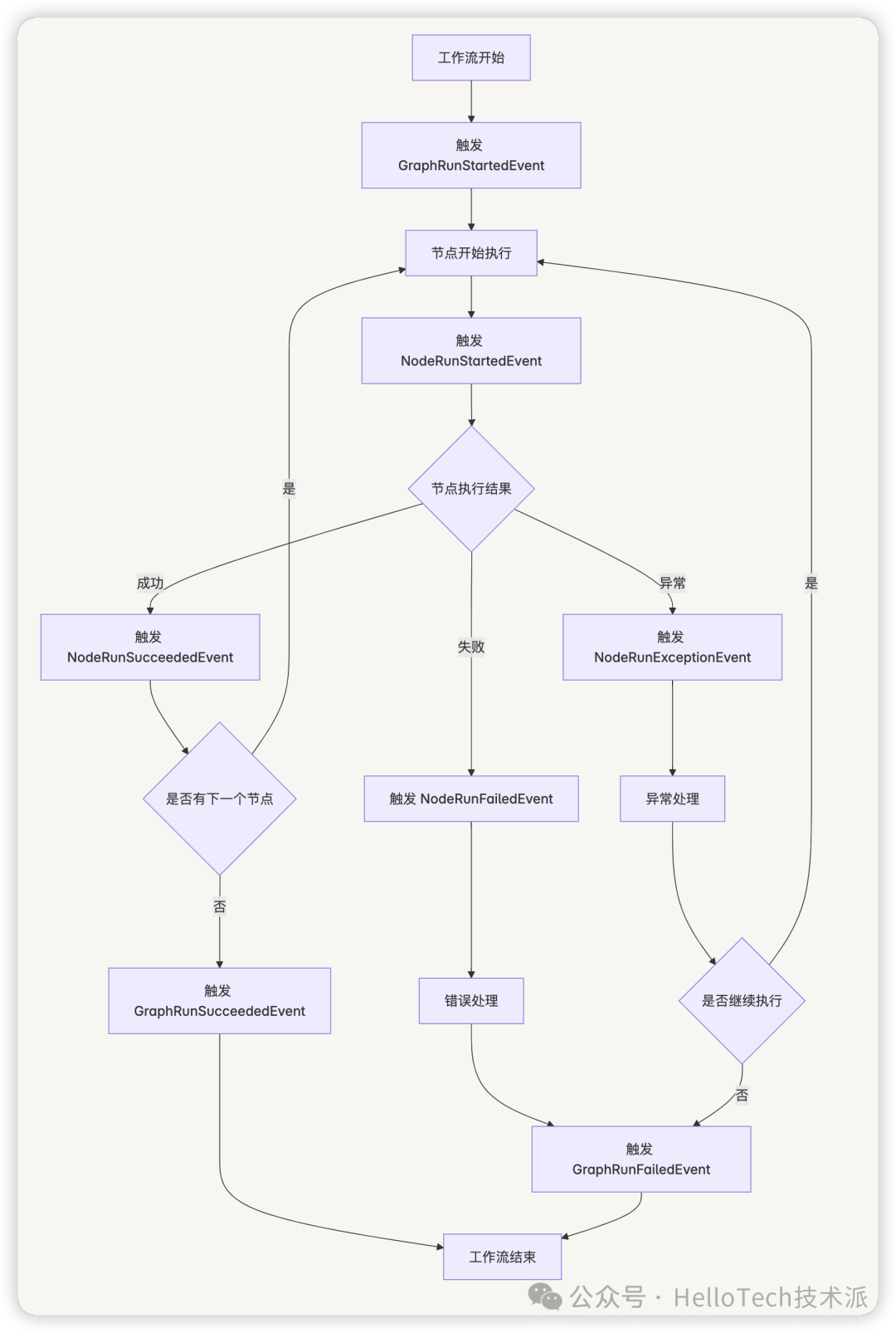
Task 任务调度机制
Celery 任务系统
Dify 使用 Celery 作为分布式任务队列,支持异步任务处理:
class FlaskTask(Task):
def __call__(self, *args: object, **kwargs: object) -> object:
with app.app_context():
return self.run(*args, **kwargs)
任务类型
文档索引任务
@shared_task(queue="dataset")
def document_indexing_task(dataset_id: str, document_ids: list):
"""
Async process document
:param dataset_id:
:param document_ids:
Usage: document_indexing_task.delay(dataset_id, document_ids)
"""
documents = []
start_at = time.perf_counter()
dataset = db.session.query(Dataset).filter(Dataset.id == dataset_id).first()
ifnot dataset:
logging.info(click.style("Dataset is not found: {}".format(dataset_id), fg="yellow"))
db.session.close()
return
# 检查文档限制和配额
features = FeatureService.get_features(dataset.tenant_id)
try:
if features.billing.enabled:
vector_space = features.vector_space
count = len(document_ids)
batch_upload_limit = int(dify_config.BATCH_UPLOAD_LIMIT)
if features.billing.subscription.plan == "sandbox"and count > 1:
raise ValueError("Your current plan does not support batch upload, please upgrade your plan.")
if count > batch_upload_limit:
raise ValueError(f"You have reached the batch upload limit of {batch_upload_limit}.")
except Exception as e:
for document_id in document_ids:
document = db.session.query(Document).filter(
Document.id == document_id, Document.dataset_id == dataset_id
).first()
if document:
document.indexing_status = "error"
document.error = str(e)
document.stopped_at = datetime.datetime.now(datetime.UTC).replace(tzinfo=None)
db.session.add(document)
db.session.commit()
db.session.close()
return
# 处理文档索引
try:
indexing_runner = IndexingRunner()
indexing_runner.run(documents)
end_at = time.perf_counter()
logging.info(click.style("Processed dataset: {} latency: {}".format(dataset_id, end_at - start_at), fg="green"))
except DocumentIsPausedError as ex:
logging.info(click.style(str(ex), fg="yellow"))
except Exception:
logging.exception("Document indexing task failed, dataset_id: {}".format(dataset_id))
finally:
db.session.close()
操作追踪任务
@shared_task(queue="ops_trace")
def process_trace_tasks(file_info):
"""
Async process trace tasks
Usage: process_trace_tasks.delay(tasks_data)
"""
from core.ops.ops_trace_manager import OpsTraceManager
app_id = file_info.get("app_id")
file_id = file_info.get("file_id")
file_path = f"{OPS_FILE_PATH}{app_id}/{file_id}.json"
file_data = json.loads(storage.load(file_path))
trace_info = file_data.get("trace_info")
trace_info_type = file_data.get("trace_info_type")
trace_instance = OpsTraceManager.get_ops_trace_instance(app_id)
# 转换数据模型
if trace_info.get("message_data"):
trace_info["message_data"] = Message.from_dict(data=trace_info["message_data"])
if trace_info.get("workflow_data"):
trace_info["workflow_data"] = WorkflowRun.from_dict(data=trace_info["workflow_data"])
if trace_info.get("documents"):
trace_info["documents"] = [Document(**doc) for doc in trace_info["documents"]]
try:
if trace_instance:
with current_app.app_context():
trace_type = trace_info_info_map.get(trace_info_type)
if trace_type:
trace_info = trace_type(**trace_info)
trace_instance.trace(trace_info)
logging.info(f"Processing trace tasks success, app_id: {app_id}")
except Exception as e:
logging.info(f"error:\n\n\n{e}\n\n\n\n")
failed_key = f"{OPS_TRACE_FAILED_KEY}_{app_id}"
redis_client.incr(failed_key)
logging.info(f"Processing trace tasks failed, app_id: {app_id}")
finally:
storage.delete(file_path)
任务存储模型
class CeleryTask(Base):
"""任务结果/状态"""
__tablename__ = "celery_taskmeta"
id = db.Column(db.Integer, primary_key=True)
task_id = db.Column(db.String(155), unique=True)
status = db.Column(db.String(50), default=states.PENDING)
result = db.Column(db.PickleType, nullable=True)
date_done = db.Column(db.DateTime, nullable=True)
traceback = db.Column(db.Text, nullable=True)
任务调度架构
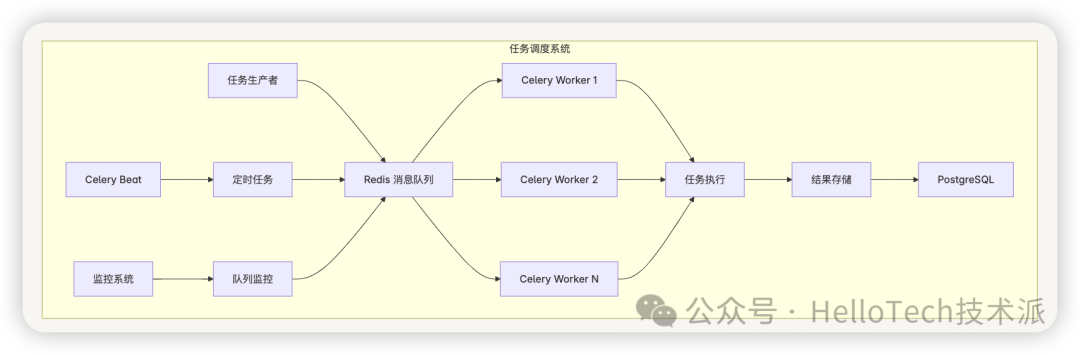
队列管理机制
队列事件类型
Dify 定义了丰富的队列事件类型来处理不同的业务场景:
class QueueEvent(StrEnum):
LLM_CHUNK = "llm_chunk"
TEXT_CHUNK = "text_chunk"
AGENT_MESSAGE = "agent_message"
MESSAGE_REPLACE = "message_replace"
MESSAGE_END = "message_end"
WORKFLOW_STARTED = "workflow_started"
WORKFLOW_SUCCEEDED = "workflow_succeeded"
WORKFLOW_FAILED = "workflow_failed"
NODE_STARTED = "node_started"
NODE_SUCCEEDED = "node_succeeded"
NODE_FAILED = "node_failed"
ERROR = "error"
PING = "ping"
STOP = "stop"
队列管理器
class AppQueueManager:
def __init__(self, task_id: str, user_id: str, invoke_from: InvokeFrom) -> None:
ifnot user_id:
raise ValueError("user is required")
self._task_id = task_id
self._user_id = user_id
self._invoke_from = invoke_from
user_prefix = "account"if self._invoke_from in {InvokeFrom.EXPLORE, InvokeFrom.DEBUGGER} else"end-user"
redis_client.setex(
AppQueueManager._generate_task_belong_cache_key(self._task_id), 1800, f"{user_prefix}-{self._user_id}"
)
q: queue.Queue[WorkflowQueueMessage | MessageQueueMessage | None] = queue.Queue()
self._q = q
def listen(self):
"""
Listen to queue
:return:
"""
# wait for APP_MAX_EXECUTION_TIME seconds to stop listen
listen_timeout = dify_config.APP_MAX_EXECUTION_TIME
start_time = time.time()
last_ping_time: int | float = 0
whileTrue:
try:
message = self._q.get(timeout=1)
if message isNone:
break
yield message
except queue.Empty:
continue
finally:
elapsed_time = time.time() - start_time
if elapsed_time >= listen_timeout or self._is_stopped():
# publish two messages to make sure the client can receive the stop signal
# and stop listening after the stop signal processed
self.publish(
QueueStopEvent(stopped_by=QueueStopEvent.StopBy.USER_MANUAL), PublishFrom.TASK_PIPELINE
)
if elapsed_time // 10 > last_ping_time:
self.publish(QueuePingEvent(), PublishFrom.TASK_PIPELINE)
last_ping_time = elapsed_time // 10
def stop_listen(self) -> None:
"""
Stop listen to queue
:return:
"""
self._q.put(None)
def publish_error(self, e, pub_from: PublishFrom) -> None:
"""
Publish error
:param e: error
:param pub_from: publish from
:return:
"""
self.publish(QueueErrorEvent(error=e), pub_from)
def publish(self, event: AppQueueEvent, pub_from: PublishFrom) -> None:
"""
Publish event to queue
:param event:
:param pub_from:
:return:
"""
self._check_for_sqlalchemy_models(event.model_dump())
self._publish(event, pub_from)
@abstractmethod
def _publish(self, event: AppQueueEvent, pub_from: PublishFrom) -> None:
"""
Publish event to queue
:param event:
:param pub_from:
:return:
"""
raise NotImplementedError
@classmethod
def set_stop_flag(cls, task_id: str, invoke_from: InvokeFrom, user_id: str) -> None:
"""
Set task stop flag
:return:
"""
result: Optional[Any] = redis_client.get(cls._generate_task_belong_cache_key(task_id))
if result isNone:
return
user_prefix = "account"if invoke_from in {InvokeFrom.EXPLORE, InvokeFrom.DEBUGGER} else"end-user"
if result.decode("utf-8") != f"{user_prefix}-{user_id}":
return
stopped_cache_key = cls._generate_stopped_cache_key(task_id)
redis_client.setex(stopped_cache_key, 600, 1)
def _is_stopped(self) -> bool:
"""
Check if task is stopped
:return:
"""
stopped_cache_key = AppQueueManager._generate_stopped_cache_key(self._task_id)
result = redis_client.get(stopped_cache_key)
if result isnotNone:
returnTrue
returnFalse
@classmethod
def _generate_task_belong_cache_key(cls, task_id: str) -> str:
"""
Generate task belong cache key
:param task_id: task id
:return:
"""
returnf"generate_task_belong:{task_id}"
@classmethod
def _generate_stopped_cache_key(cls, task_id: str) -> str:
"""
Generate stopped cache key
:param task_id: task id
:return:
"""
returnf"generate_task_stopped:{task_id}"
def _check_for_sqlalchemy_models(self, data: Any):
# from entity to dict or list
if isinstance(data, dict):
for key, value in data.items():
self._check_for_sqlalchemy_models(value)
elif isinstance(data, list):
for item in data:
self._check_for_sqlalchemy_models(item)
else:
if isinstance(data, DeclarativeMeta) or hasattr(data, "_sa_instance_state"):
raise TypeError(
"Critical Error: Passing SQLAlchemy Model instances that cause thread safety issues is not allowed."
)
消息队列架构
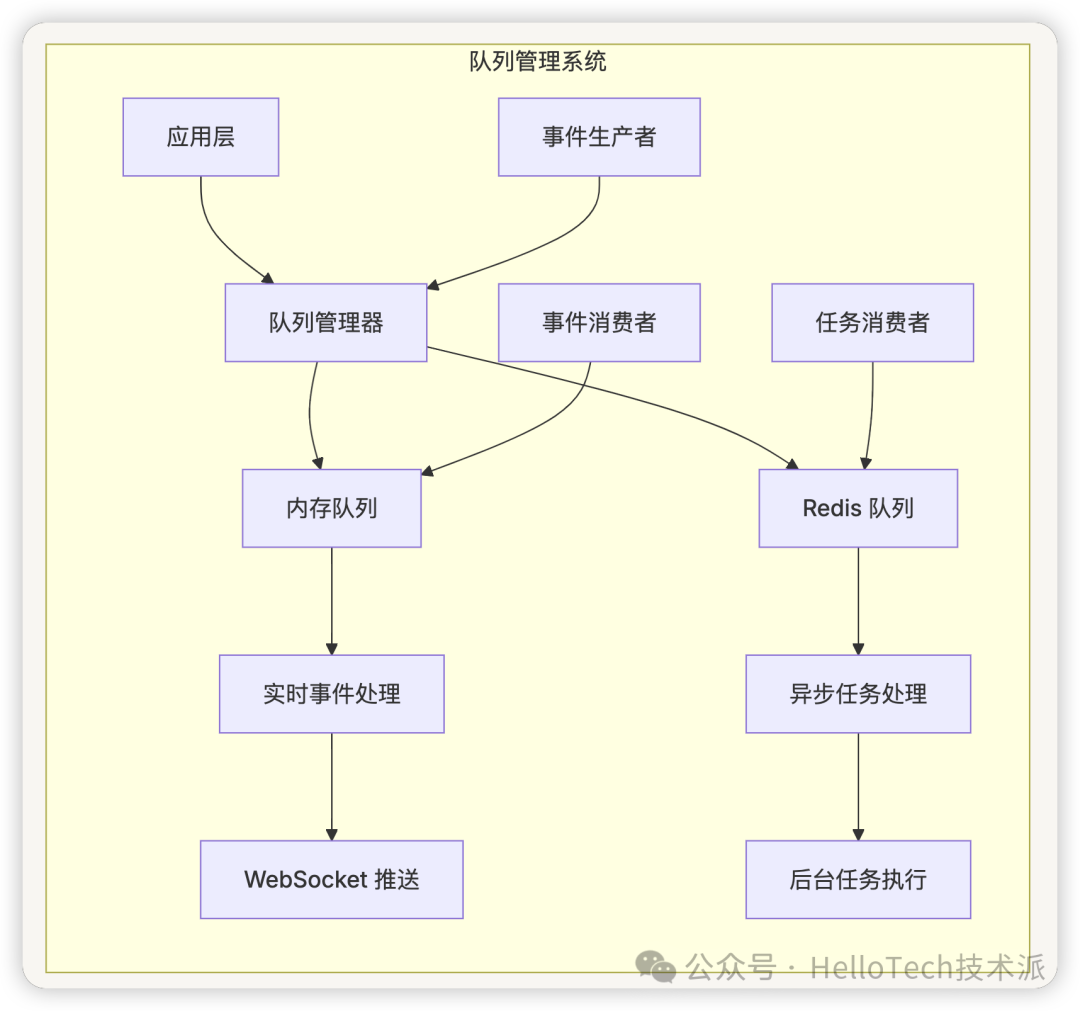
事件处理流程
消息处理完整流程
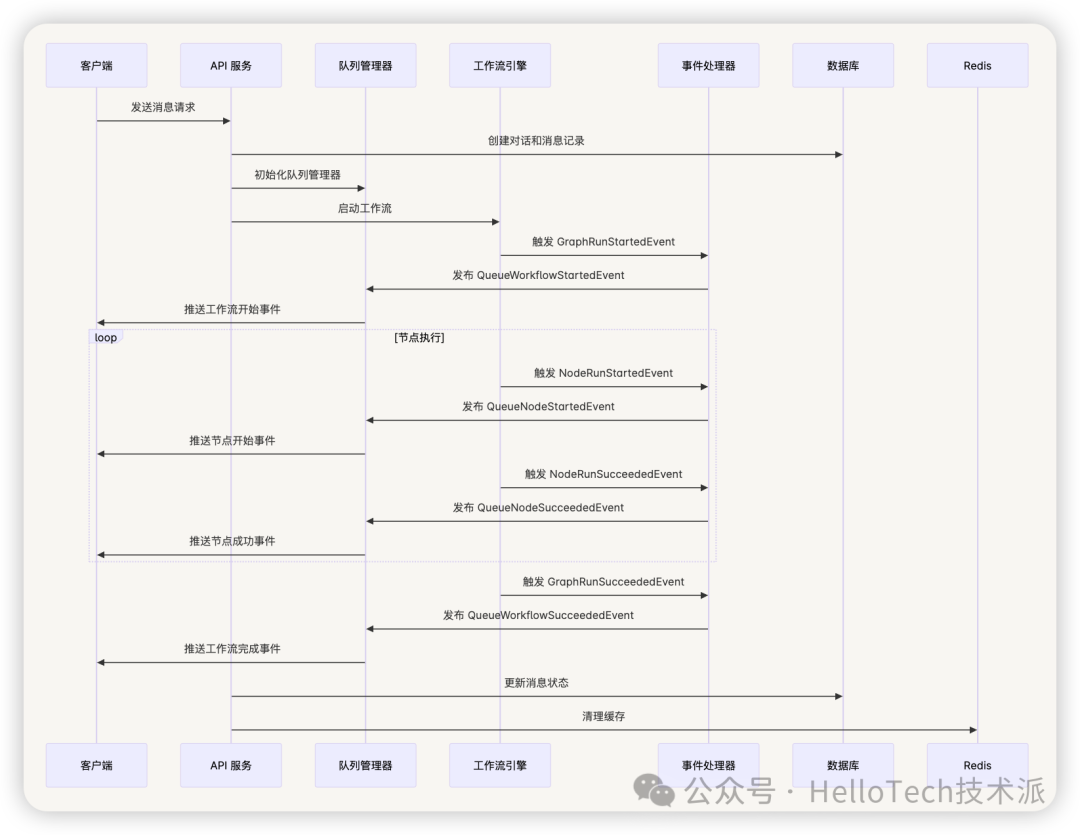
事件转换机制
工作流应用运行器负责将工作流事件转换为应用级别的队列事件:
def _handle_event(self, workflow_entry: WorkflowEntry, event: GraphEngineEvent):
if isinstance(event, GraphRunStartedEvent):
self._publish_event(
QueueWorkflowStartedEvent(
graph_runtime_state=workflow_entry.graph_engine.graph_runtime_state
)
)
elif isinstance(event, NodeRunSucceededEvent):
self._publish_event(
QueueNodeSucceededEvent(
node_execution_id=event.id,
node_id=event.node_id,
node_type=event.node_type,
# ... 其他属性
)
)
架构设计图
整体架构图
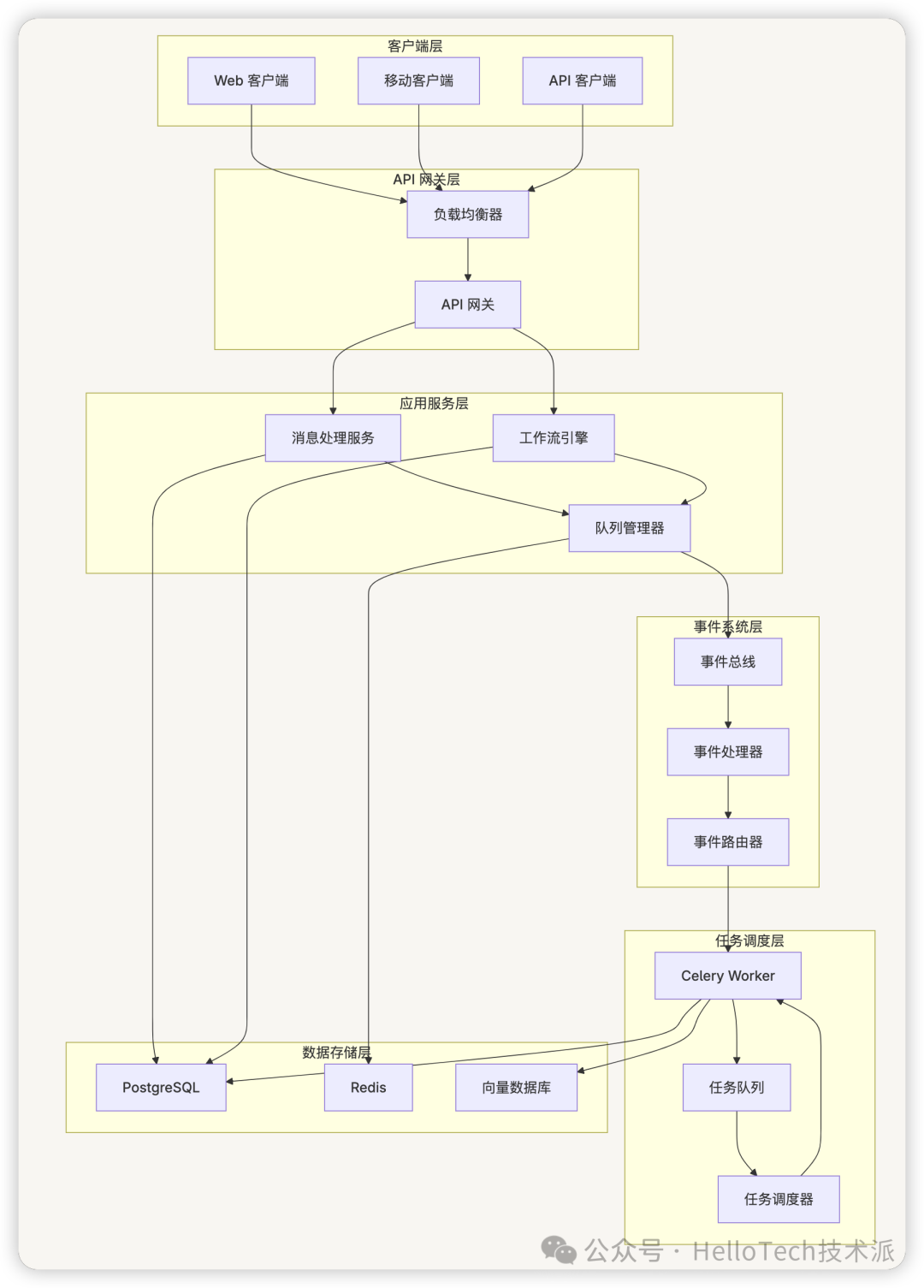
事件流转图
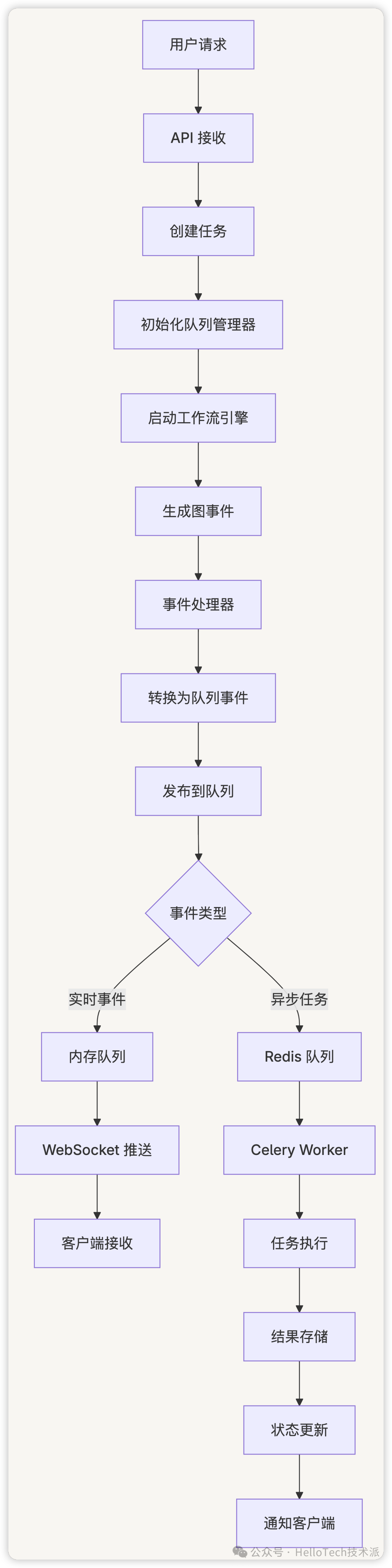
最佳实践
故障处理和恢复最佳实践
1. 设计原则
-
故障隔离:确保单个组件的故障不会影响整个系统
-
快速恢复:设计自动恢复机制,减少人工干预
-
数据一致性:在故障恢复过程中保证数据的一致性
-
监控优先:建立完善的监控体系,及时发现问题
-
渐进式恢复:采用渐进式恢复策略,避免系统过载
2. 实施策略
class FaultToleranceManager:
"""容错管理器"""
def __init__(self):
self.event_recovery = EventRecoveryManager(redis_client)
self.network_resilience = NetworkResilienceManager(redis_client)
self.resource_monitor = ResourceMonitoringManager()
self.health_checker = HealthCheckManager(redis_client, db_session)
self.alert_manager = AlertManager([SlackNotificationChannel(webhook_url)])
def initialize_fault_tolerance(self):
"""初始化容错机制"""
# 1. 启动健康检查定时任务
self._start_health_check_scheduler()
# 2. 恢复应用重启前的未完成事件
self.event_recovery.recover_pending_events()
# 3. 恢复网络异常时缓存的事件
self.network_resilience.recover_cached_events()
# 4. 注册信号处理器
self._register_signal_handlers()
def _start_health_check_scheduler(self):
"""启动健康检查调度器"""
import schedule
# 每分钟执行一次健康检查
schedule.every(1).minutes.do(self._perform_periodic_health_check)
# 每5分钟检查一次资源使用情况
schedule.every(5).minutes.do(self._check_resource_pressure)
def _perform_periodic_health_check(self):
"""执行周期性健康检查"""
try:
health_report = self.health_checker.perform_health_check()
if health_report["overall_status"] != "healthy":
self._handle_health_issues(health_report)
except Exception as e:
logging.error(f"Health check failed: {e}")
self.alert_manager.send_alert(
"health_check_failure",
f"Health check execution failed: {str(e)}",
"error"
)
def _check_resource_pressure(self):
"""检查资源压力"""
try:
resource_status = self.resource_monitor.check_system_resources()
# 检查是否有资源压力
critical_resources = [res for res, info in resource_status.items()
if info["critical"]]
if critical_resources:
self.resource_monitor.handle_resource_pressure(resource_status)
self.alert_manager.send_alert(
"resource_pressure",
f"Critical resource usage detected: {', '.join(critical_resources)}",
"warning"
)
except Exception as e:
logging.error(f"Resource pressure check failed: {e}")
def _handle_health_issues(self, health_report: dict):
"""处理健康问题"""
for component, status in health_report["components"].items():
if status["status"] == "critical":
self._handle_critical_component(component, status)
elif status["status"] == "warning":
self._handle_warning_component(component, status)
def _handle_critical_component(self, component: str, status: dict):
"""处理关键组件故障"""
if component == "redis":
# Redis 连接故障,启动连接恢复
self._recover_redis_connection()
elif component == "database":
# 数据库连接故障,尝试重新连接
self._recover_database_connection()
elif component == "celery":
# Celery 故障,重启 worker
self._restart_celery_workers()
# 发送关键告警
self.alert_manager.send_alert(
f"{component}_critical",
f"Critical failure in {component}: {status.get('error', 'Unknown error')}",
"critical"
)
def _register_signal_handlers(self):
"""注册信号处理器"""
import signal
def graceful_shutdown(signum, frame):
logging.info("Received shutdown signal, performing graceful shutdown...")
self._graceful_shutdown()
signal.signal(signal.SIGTERM, graceful_shutdown)
signal.signal(signal.SIGINT, graceful_shutdown)
def _graceful_shutdown(self):
"""优雅关闭"""
# 1. 停止接收新的事件
self._stop_event_processing()
# 2. 等待当前事件处理完成
self._wait_for_event_completion()
# 3. 持久化未完成的事件
self._persist_pending_events()
# 4. 关闭连接
self._close_connections()
3. 运维建议
-
定期备份:定期备份关键数据和配置
-
容量规划:根据业务增长预测进行容量规划
-
故障演练:定期进行故障恢复演练
-
版本管理:建立完善的版本管理和回滚机制
-
文档维护:维护详细的故障处理文档
事件设计原则
-
单一职责:每个事件只负责一个特定的业务场景
-
幂等性:事件处理应该是幂等的,重复处理不会产生副作用
-
异步处理:耗时操作应该异步处理,避免阻塞主流程
-
错误隔离:事件处理失败不应该影响其他事件的处理
任务设计原则
-
任务分解:将大任务分解为小任务,提高并发性
-
重试机制:实现合理的重试策略,处理临时性错误
-
监控告警:建立完善的监控和告警机制
-
资源控制:合理控制任务的资源使用,避免系统过载
性能优化建议
-
批量处理:对于大量相似任务,采用批量处理提高效率
-
缓存策略:合理使用缓存减少数据库访问
-
连接池:使用连接池管理数据库连接
-
异步 I/O:使用异步 I/O 提高并发处理能力
错误处理策略
-
分级处理:根据错误严重程度采用不同的处理策略
-
日志记录:详细记录错误信息,便于问题排查
-
降级机制:在系统异常时提供降级服务
-
熔断保护:防止级联故障的发生
消息事件与 Task 任务的区别与联系
核心概念对比
消息事件系统
定义:基于信号机制的同步事件处理系统,用于在应用内部进行实时状态同步和业务逻辑触发。
特点:
-
同步执行:事件处理器在当前线程中同步执行
-
实时性强:事件触发后立即处理,延迟极低
-
内存操作:主要在内存中进行数据传递和处理
-
轻量级:适合简单的业务逻辑处理
-
强一致性:事件处理与主流程在同一事务中
Task 任务系统
定义:基于 Celery 的分布式异步任务处理系统,用于处理耗时操作和后台任务。
特点:
-
异步执行:任务在独立的 Worker 进程中异步执行
-
可扩展性:支持多 Worker 并行处理,可水平扩展
-
持久化:任务状态和结果可持久化存储
-
重试机制:支持任务失败重试和错误恢复
-
最终一致性:任务执行与主流程解耦
详细对比分析
|
维度 |
消息事件系统 |
Task 任务系统 |
|---|---|---|
| 执行方式 |
同步执行 |
异步执行 |
| 响应时间 |
毫秒级 |
秒级到分钟级 |
| 资源消耗 |
低(内存操作) |
高(独立进程) |
| 可靠性 |
依赖主进程 |
高可靠性 |
| 扩展性 |
受限于单进程 |
可水平扩展 |
| 事务性 |
强一致性 |
最终一致性 |
| 错误处理 |
简单异常捕获 |
完善的重试机制 |
| 监控能力 |
基础日志 |
丰富的监控指标 |
| 适用场景 |
实时状态同步 |
耗时后台处理 |
适用场景分析
消息事件系统适用场景
1. 实时状态同步
# 示例:消息创建后立即扣除配额
@message_was_created.connect
def handle_quota_deduction(sender, **kwargs):
"""消息创建时立即扣除配额"""
application_generate_entity = kwargs.get("application_generate_entity")
if application_generate_entity:
# 同步扣除配额,确保数据一致性
quota_service.deduct_quota(application_generate_entity)
2. 业务逻辑触发
# 示例:应用配置更新后立即清理缓存
@app_model_config_was_updated.connect
def handle_cache_cleanup(sender, **kwargs):
"""应用配置更新后立即清理相关缓存"""
app = sender
cache_service.clear_app_cache(app.id)
3. 数据验证和校验
# 示例:租户创建时进行数据验证
@tenant_was_created.connect
def handle_tenant_validation(sender, **kwargs):
"""租户创建时进行数据验证"""
tenant = sender
validation_service.validate_tenant_data(tenant)
适用特征:
-
处理时间短(< 100ms)
-
需要强一致性
-
与主流程紧密耦合
-
实时性要求高
-
数据量小
Task 任务系统适用场景
1. 文档处理和索引
# 示例:大文档的异步索引处理
@shared_task(queue="dataset", bind=True, max_retries=3)
def document_indexing_task(self, dataset_id: str, document_ids: list):
"""异步处理文档索引,支持重试"""
try:
# 耗时的文档解析和向量化处理
indexing_runner = IndexingRunner()
indexing_runner.run(dataset_id, document_ids)
except Exception as exc:
# 支持重试机制
if self.request.retries < self.max_retries:
raise self.retry(countdown=60, exc=exc)
raise
2. 批量数据处理
# 示例:批量导入注释数据
@shared_task(queue="dataset")
def batch_import_annotations_task(annotation_data_list: list):
"""批量导入注释数据"""
for annotation_data in annotation_data_list:
# 处理大量数据,避免阻塞主流程
process_annotation(annotation_data)
3. 外部服务调用
# 示例:发送邮件通知
@shared_task(queue="mail")
def send_email_task(email_data: dict):
"""异步发送邮件"""
# 调用外部邮件服务,避免网络延迟影响主流程
email_service.send_email(email_data)
4. 定时任务和清理作业
# 示例:定时清理过期数据
@shared_task
def cleanup_expired_data():
"""定时清理过期的临时数据"""
# 定期执行的维护任务
cleanup_service.remove_expired_files()
cleanup_service.remove_old_logs()
适用特征:
-
处理时间长(> 1s)
-
可以容忍延迟
-
需要重试机制
-
资源消耗大
-
可以异步处理
联系与协作
协作模式
1. 事件触发任务模式
# 消息事件触发异步任务
@message_was_created.connect
def handle_message_analysis(sender, **kwargs):
"""消息创建后触发异步分析任务"""
message = sender
# 立即返回,不阻塞主流程
analyze_message_task.delay(message.id)
@shared_task(queue="analysis")
def analyze_message_task(message_id: str):
"""异步分析消息内容"""
# 耗时的分析处理
message = Message.query.get(message_id)
analysis_result = ai_service.analyze_message(message.content)
# 保存分析结果
save_analysis_result(message_id, analysis_result)
2. 任务完成事件通知模式
# 任务完成后触发事件通知
@shared_task(queue="dataset")
def document_processing_task(document_id: str):
"""文档处理任务"""
try:
# 处理文档
process_document(document_id)
# 任务完成后触发事件
document_processed.send(document_id=document_id, status="success")
except Exception as e:
# 任务失败后触发事件
document_processed.send(document_id=document_id, status="failed", error=str(e))
@document_processed.connect
def handle_document_processed(sender, **kwargs):
"""处理文档处理完成事件"""
document_id = kwargs.get("document_id")
status = kwargs.get("status")
# 立即更新UI状态
update_document_status(document_id, status)
数据流转
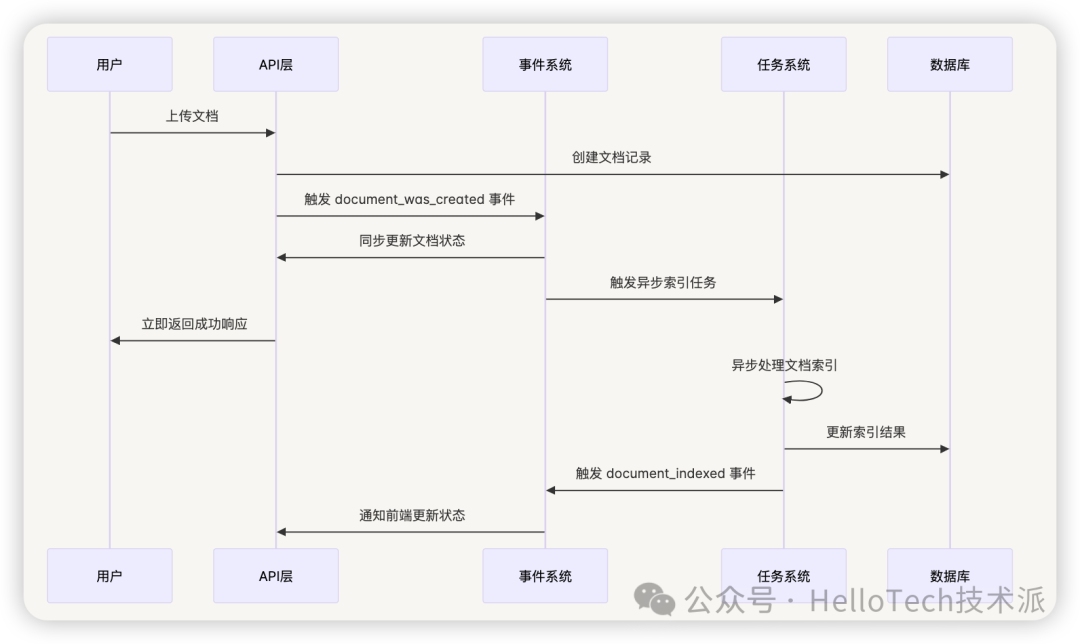
是否可以互相替代?
不可替代的场景
1. 消息事件不可替代 Task 的场景
# ❌ 错误示例:用事件处理耗时任务
@document_was_uploaded.connect
def handle_document_processing(sender, **kwargs):
"""错误:在事件处理器中进行耗时处理"""
document = sender
# 这会阻塞主流程,导致用户等待
large_file_content = extract_text_from_pdf(document.file_path) # 可能需要几分钟
vectorize_content(large_file_content) # 可能需要更长时间
# ✅ 正确示例:事件触发异步任务
@document_was_uploaded.connect
def handle_document_uploaded(sender, **kwargs):
"""正确:事件触发异步处理"""
document = sender
# 立即触发异步任务,不阻塞主流程
process_document_task.delay(document.id)
2. Task 不可替代消息事件的场景
# ❌ 错误示例:用任务处理实时状态更新
@shared_task
def update_user_quota_task(user_id: str, usage: int):
"""错误:用异步任务处理实时配额扣除"""
# 异步处理可能导致配额检查不准确
user = User.query.get(user_id)
user.quota_used += usage
db.session.commit()
# ✅ 正确示例:事件处理实时状态
@message_was_created.connect
def handle_quota_deduction(sender, **kwargs):
"""正确:同步处理配额扣除"""
# 在同一事务中处理,确保数据一致性
application_generate_entity = kwargs.get("application_generate_entity")
quota_service.deduct_quota_immediately(application_generate_entity)
可以替代的场景
1. 非关键性的状态更新
# 方案1:使用事件(适合简单更新)
@app_was_created.connect
def handle_app_created(sender, **kwargs):
"""应用创建后更新统计信息"""
app = sender
statistics_service.increment_app_count(app.tenant_id)
# 方案2:使用任务(适合复杂统计)
@shared_task
def update_app_statistics_task(tenant_id: str, app_id: str):
"""异步更新应用统计信息"""
statistics_service.update_comprehensive_stats(tenant_id, app_id)
2. 日志记录和审计
# 方案1:使用事件(简单日志)
@user_login.connect
def handle_login_log(sender, **kwargs):
"""用户登录时记录简单日志"""
user = sender
logger.info(f"User {user.id} logged in")
# 方案2:使用任务(详细审计)
@shared_task
def create_audit_log_task(user_id: str, action: str, details: dict):
"""异步创建详细的审计日志"""
audit_service.create_detailed_log(user_id, action, details)
选择决策树
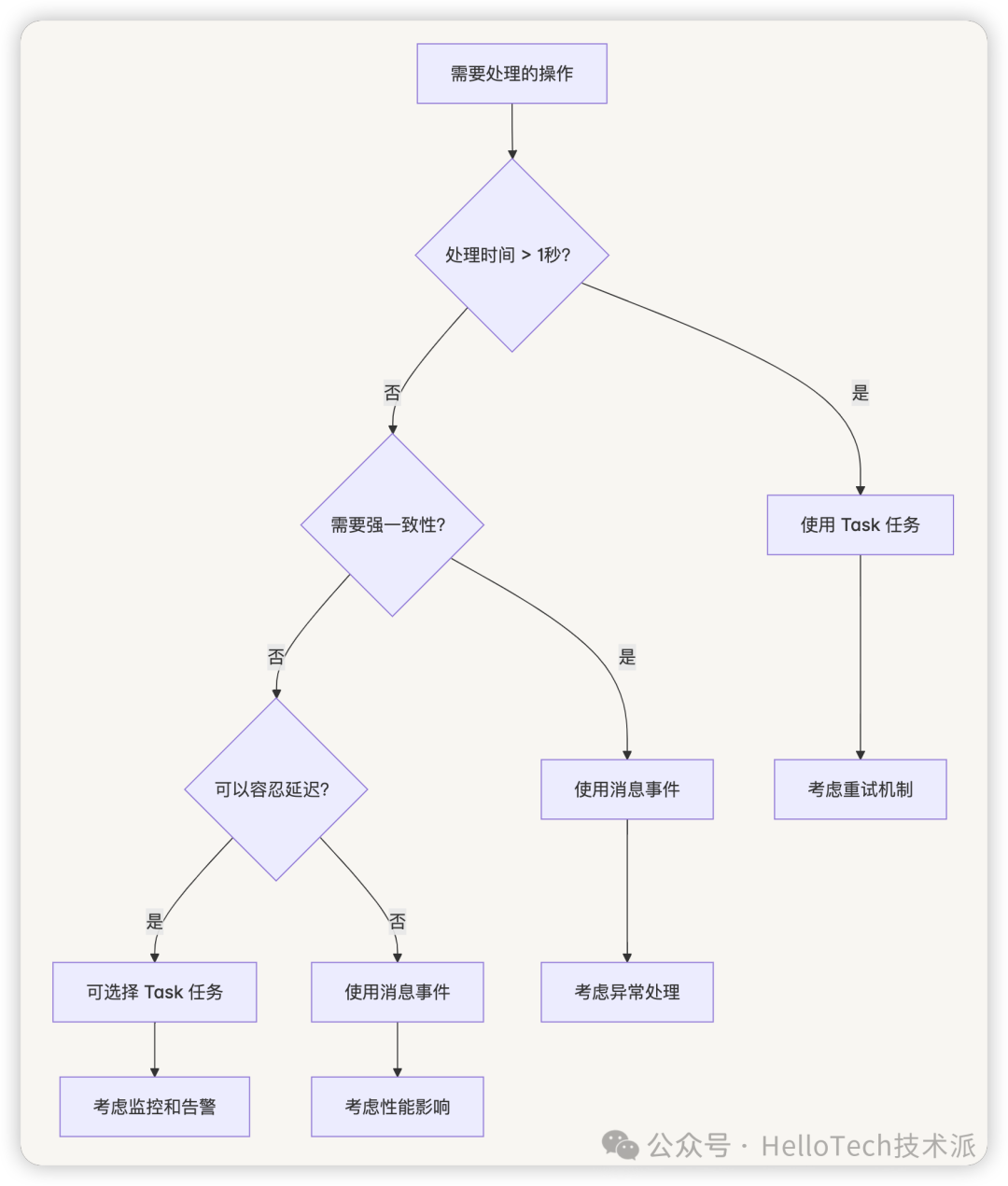
最佳实践建议
设计原则
-
职责分离:事件处理实时同步,任务处理异步计算
-
性能优先:优先考虑用户体验和系统响应时间
-
数据一致性:根据业务需求选择强一致性或最终一致性
-
可维护性:保持代码简洁,避免过度复杂的设计
组合使用策略
class MessageProcessingStrategy:
"""消息处理策略示例"""
def handle_message_created(self, message: Message, **kwargs):
"""消息创建的完整处理流程"""
# 1. 立即处理(事件系统)
self._immediate_processing(message, **kwargs)
# 2. 异步处理(任务系统)
self._async_processing(message)
def _immediate_processing(self, message: Message, **kwargs):
"""立即处理:配额扣除、状态更新等"""
# 扣除配额(必须同步)
quota_service.deduct_quota(kwargs.get("application_generate_entity"))
# 更新统计(可以同步)
statistics_service.increment_message_count(message.app_id)
# 记录基础日志(同步)
logger.info(f"Message {message.id} created")
def _async_processing(self, message: Message):
"""异步处理:内容分析、索引更新等"""
# 内容分析(耗时操作)
analyze_message_content_task.delay(message.id)
# 更新搜索索引(耗时操作)
update_search_index_task.delay(message.id)
# 发送通知(可能失败的操作)
send_notification_task.delay(message.id)
通过合理的设计和选择,消息事件系统和 Task 任务系统可以协同工作,构建高效、可靠的分布式应用架构。
异常处理和容错机制
消息事件丢失处理方案
常见原因分析
系统层面原因:
-
Redis 连接断开:网络异常或 Redis 服务重启
-
应用重启:服务重启导致内存中的事件丢失
-
网络异常:网络延迟或丢包导致事件传输失败
-
资源不足:内存或 CPU 资源不足导致事件处理失败
代码层面原因:
-
事件处理器异常:处理器代码抛出未捕获的异常
-
SQLAlchemy 模型传递:在多线程环境中传递模型实例
-
队列满载:队列容量达到上限,新事件被丢弃
预防措施
1. 事件处理器异常保护
# 推荐的事件处理器实现模式
from functools import wraps
import logging
def safe_event_handler(func):
"""事件处理器安全装饰器"""
@wraps(func)
def wrapper(sender, **kwargs):
try:
return func(sender, **kwargs)
except Exception as e:
logging.error(f"Event handler {func.__name__} failed: {str(e)}", exc_info=True)
# 可选:发送告警通知
# send_alert(f"Event handler error: {func.__name__}")
return wrapper
@message_was_created.connect
@safe_event_handler
def handle_message_created(sender, **kwargs):
"""安全的消息创建事件处理器"""
message = sender
application_generate_entity = kwargs.get("application_generate_entity")
# 验证必要参数
ifnot application_generate_entity:
logging.warning("Missing application_generate_entity in message_was_created event")
return
# 业务逻辑处理
# ...
2. Celery 任务重试机制
from celery import shared_task
from celery.exceptions import Retry
import logging
import time
@shared_task(bind=True, max_retries=3, default_retry_delay=60)
def robust_processing_task(self, data_id: str):
"""具有重试机制的任务"""
try:
# 任务执行逻辑
process_data(data_id)
logging.info(f"Task completed successfully for data_id: {data_id}")
except ConnectionError as exc:
# 网络连接错误,可重试
logging.warning(f"Connection error in task {self.request.id}: {exc}")
if self.request.retries < self.max_retries:
# 指数退避重试
countdown = 2 ** self.request.retries
raise self.retry(countdown=countdown, exc=exc)
else:
logging.error(f"Task {self.request.id} failed after {self.max_retries} retries")
raise
except ValueError as exc:
# 数据错误,不可重试
logging.error(f"Data validation error in task {self.request.id}: {exc}")
raise
except Exception as exc:
# 其他异常,记录并重试
logging.error(f"Unexpected error in task {self.request.id}: {exc}", exc_info=True)
if self.request.retries < self.max_retries:
raise self.retry(countdown=60, exc=exc)
else:
# 发送告警
send_task_failure_alert(self.request.id, str(exc))
raise
恢复机制
1. 应用重启导致的事件丢失处理
class EventRecoveryManager:
"""事件恢复管理器,提供事件持久化和恢复功能"""
def __init__(self, redis_client):
self.redis_client = redis_client
self.recovery_key_prefix = "event_recovery:"
def persist_event_before_processing(self, event_id: str, event_data: dict):
"""在处理事件前持久化事件数据"""
recovery_key = f"{self.recovery_key_prefix}{event_id}"
event_payload = {
"event_data": event_data,
"timestamp": time.time(),
"status": "pending",
"retry_count": 0
}
# 设置过期时间为24小时
self.redis_client.setex(recovery_key, 86400, json.dumps(event_payload))
def mark_event_completed(self, event_id: str):
"""标记事件处理完成"""
recovery_key = f"{self.recovery_key_prefix}{event_id}"
self.redis_client.delete(recovery_key)
def recover_pending_events(self):
"""应用重启后恢复未完成的事件"""
pattern = f"{self.recovery_key_prefix}*"
pending_keys = self.redis_client.keys(pattern)
for key in pending_keys:
try:
event_payload = json.loads(self.redis_client.get(key))
if event_payload["status"] == "pending":
# 检查事件是否超时
if time.time() - event_payload["timestamp"] > 3600: # 1小时超时
logging.warning(f"Event {key} timeout, moving to dead letter queue")
self._move_to_dead_letter_queue(key, event_payload)
continue
# 重新处理事件
self._reprocess_event(key, event_payload)
except Exception as e:
logging.error(f"Failed to recover event {key}: {e}")
def _reprocess_event(self, key: str, event_payload: dict):
"""重新处理事件"""
try:
event_data = event_payload["event_data"]
# 增加重试计数
event_payload["retry_count"] += 1
if event_payload["retry_count"] > 3:
logging.error(f"Event {key} exceeded max retry count")
self._move_to_dead_letter_queue(key, event_payload)
return
# 更新状态为处理中
event_payload["status"] = "processing"
self.redis_client.setex(key, 86400, json.dumps(event_payload))
# 重新触发事件处理
self._trigger_event_processing(event_data)
except Exception as e:
logging.error(f"Failed to reprocess event {key}: {e}")
self._move_to_dead_letter_queue(key, event_payload)
2. 网络异常导致的事件丢失处理
class NetworkResilienceManager:
"""网络弹性管理器,支持带重试的事件发布和本地缓存"""
def __init__(self, redis_client):
self.redis_client = redis_client
self.circuit_breaker = CircuitBreaker()
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def publish_event_with_retry(self, event: AppQueueEvent):
"""带重试的事件发布"""
try:
with self.circuit_breaker:
return self._publish_event(event)
except CircuitBreakerOpenException:
logging.error("Circuit breaker is open, event publishing failed")
# 将事件存储到本地缓存,等待网络恢复
self._cache_event_locally(event)
raise
except Exception as e:
logging.error(f"Failed to publish event: {e}")
raise
def _cache_event_locally(self, event: AppQueueEvent):
"""本地缓存事件"""
cache_key = f"local_event_cache:{uuid.uuid4()}"
event_data = {
"event": event.model_dump(),
"timestamp": time.time(),
"retry_count": 0
}
# 使用本地文件系统缓存
cache_file = f"/tmp/dify_events/{cache_key}.json"
os.makedirs(os.path.dirname(cache_file), exist_ok=True)
with open(cache_file, 'w') as f:
json.dump(event_data, f)
def recover_cached_events(self):
"""恢复本地缓存的事件"""
cache_dir = "/tmp/dify_events/"
ifnot os.path.exists(cache_dir):
return
for filename in os.listdir(cache_dir):
if filename.endswith('.json'):
file_path = os.path.join(cache_dir, filename)
try:
with open(file_path, 'r') as f:
event_data = json.load(f)
# 检查事件是否过期
if time.time() - event_data["timestamp"] > 3600: # 1小时过期
os.remove(file_path)
continue
# 重新发布事件
event = AppQueueEvent.model_validate(event_data["event"])
self.publish_event_with_retry(event)
# 删除缓存文件
os.remove(file_path)
except Exception as e:
logging.error(f"Failed to recover cached event {filename}: {e}")
3. 资源不足导致的事件丢失处理
class ResourceMonitoringManager:
"""资源监控管理器,包含内存、CPU、磁盘压力处理机制"""
def __init__(self):
self.memory_threshold = 0.85# 85% 内存使用率阈值
self.cpu_threshold = 0.90 # 90% CPU 使用率阈值
self.disk_threshold = 0.90 # 90% 磁盘使用率阈值
def check_system_resources(self) -> dict:
"""检查系统资源状态"""
import psutil
memory_usage = psutil.virtual_memory().percent / 100
cpu_usage = psutil.cpu_percent(interval=1) / 100
disk_usage = psutil.disk_usage('/').percent / 100
return {
"memory": {
"usage": memory_usage,
"critical": memory_usage > self.memory_threshold
},
"cpu": {
"usage": cpu_usage,
"critical": cpu_usage > self.cpu_threshold
},
"disk": {
"usage": disk_usage,
"critical": disk_usage > self.disk_threshold
}
}
def handle_resource_pressure(self, resource_status: dict):
"""处理资源压力"""
if resource_status["memory"]["critical"]:
logging.warning("High memory usage detected, implementing memory pressure handling")
self._handle_memory_pressure()
if resource_status["cpu"]["critical"]:
logging.warning("High CPU usage detected, implementing CPU pressure handling")
self._handle_cpu_pressure()
if resource_status["disk"]["critical"]:
logging.warning("High disk usage detected, implementing disk pressure handling")
self._handle_disk_pressure()
def _handle_memory_pressure(self):
"""处理内存压力"""
# 1. 减少队列大小
self._reduce_queue_size()
# 2. 触发垃圾回收
import gc
gc.collect()
# 3. 暂停非关键任务
self._pause_non_critical_tasks()
# 4. 启用事件持久化到磁盘
self._enable_event_persistence()
def _handle_cpu_pressure(self):
"""处理 CPU 压力"""
# 1. 降低任务并发度
self._reduce_task_concurrency()
# 2. 延迟非紧急事件处理
self._delay_non_urgent_events()
# 3. 启用任务优先级调度
self._enable_priority_scheduling()
def _handle_disk_pressure(self):
"""处理磁盘压力"""
# 1. 清理临时文件
self._cleanup_temp_files()
# 2. 压缩日志文件
self._compress_log_files()
# 3. 将事件缓存到内存
self._cache_events_in_memory()
def _reduce_queue_size(self):
"""减少队列大小"""
# 暂停低优先级的 Celery 任务
from celery import current_app
current_app.control.cancel_consumer('low_priority')
def _pause_non_critical_tasks(self):
"""暂停非关键任务"""
# 暂停低优先级的 Celery 任务
from celery import current_app
current_app.control.cancel_consumer('low_priority')
def _enable_event_persistence(self):
"""启用事件持久化"""
# 将内存中的事件持久化到磁盘
self._persist_memory_events_to_disk()
def _reduce_task_concurrency(self):
"""降低任务并发度"""
from celery import current_app
# 动态调整 worker 并发数
current_app.control.pool_shrink(n=2)
def _delay_non_urgent_events(self):
"""延迟非紧急事件处理"""
# 将非紧急事件移到延迟队列
delayed_queue_key = "delayed_events"
# 实现延迟队列逻辑
pass
def _enable_priority_scheduling(self):
"""启用任务优先级调度"""
# 启用基于优先级的任务调度
from celery import current_app
current_app.control.add_consumer('high_priority', reply=True)
def _cleanup_temp_files(self):
"""清理临时文件"""
import shutil
temp_dirs = ['/tmp/dify_temp', '/tmp/dify_events']
for temp_dir in temp_dirs:
if os.path.exists(temp_dir):
# 保留最近1小时的文件
cutoff_time = time.time() - 3600
for filename in os.listdir(temp_dir):
file_path = os.path.join(temp_dir, filename)
if os.path.getmtime(file_path) < cutoff_time:
os.remove(file_path)
def _compress_log_files(self):
"""压缩日志文件"""
import gzip
log_dir = '/var/log/dify'
if os.path.exists(log_dir):
for filename in os.listdir(log_dir):
if filename.endswith('.log'):
file_path = os.path.join(log_dir, filename)
if os.path.getsize(file_path) > 100 * 1024 * 1024: # 100MB
self._compress_file(file_path)
def _cache_events_in_memory(self):
"""将事件缓存到内存"""
# 使用内存缓存替代磁盘存储
import redis
redis_client = redis.Redis()
# 设置内存缓存策略
redis_client.config_set('maxmemory-policy', 'allkeys-lru')
def _compress_file(self, file_path: str):
"""压缩文件"""
import gzip
compressed_path = f"{file_path}.gz"
with open(file_path, 'rb') as f_in:
with gzip.open(compressed_path, 'wb') as f_out:
f_out.writelines(f_in)
os.remove(file_path)
def _persist_memory_events_to_disk(self):
"""将内存事件持久化到磁盘"""
# 实现内存事件持久化逻辑
pass
4. Redis 连接恢复
class RedisConnectionManager:
"""Redis 连接管理器"""
def __init__(self, redis_config):
self.redis_config = redis_config
self.connection_pool = None
self.reconnect_attempts = 0
self.max_reconnect_attempts = 5
def get_connection(self):
"""获取 Redis 连接,支持自动重连"""
try:
ifnot self.connection_pool:
self.connection_pool = redis.ConnectionPool(**self.redis_config)
return redis.Redis(connection_pool=self.connection_pool)
except redis.ConnectionError as e:
logging.error(f"Redis connection failed: {e}")
return self._handle_connection_failure()
def _handle_connection_failure(self):
"""处理连接失败"""
if self.reconnect_attempts < self.max_reconnect_attempts:
self.reconnect_attempts += 1
wait_time = 2 ** self.reconnect_attempts # 指数退避
logging.info(f"Attempting to reconnect to Redis in {wait_time} seconds...")
time.sleep(wait_time)
return self.get_connection()
else:
logging.error("Max reconnection attempts reached")
raise redis.ConnectionError("Unable to connect to Redis after multiple attempts")
监控和告警机制
1. 事件流监控
class EventFlowMonitor:
"""事件流监控器"""
def __init__(self, redis_client):
self.redis_client = redis_client
self.metrics_key_prefix = "event_metrics:"
def record_event_metrics(self, event_type: str, status: str, processing_time: float = None):
"""记录事件指标"""
timestamp = int(time.time())
metrics_key = f"{self.metrics_key_prefix}{event_type}:{timestamp // 60}"# 按分钟聚合
# 记录事件计数
self.redis_client.hincrby(metrics_key, f"count_{status}", 1)
# 记录处理时间
if processing_time:
self.redis_client.hincrbyfloat(metrics_key, f"total_time_{status}", processing_time)
# 设置过期时间为24小时
self.redis_client.expire(metrics_key, 86400)
def get_event_metrics(self, event_type: str, time_range: int = 3600) -> dict:
"""获取事件指标"""
current_time = int(time.time())
start_time = current_time - time_range
metrics = {
"success_count": 0,
"failure_count": 0,
"avg_processing_time": 0,
"error_rate": 0
}
for minute in range(start_time // 60, current_time // 60 + 1):
metrics_key = f"{self.metrics_key_prefix}{event_type}:{minute}"
minute_metrics = self.redis_client.hgetall(metrics_key)
if minute_metrics:
metrics["success_count"] += int(minute_metrics.get(b"count_success", 0))
metrics["failure_count"] += int(minute_metrics.get(b"count_failure", 0))
total_count = metrics["success_count"] + metrics["failure_count"]
if total_count > 0:
metrics["error_rate"] = metrics["failure_count"] / total_count
return metrics
def check_event_health(self, event_type: str) -> dict:
"""检查事件健康状态"""
metrics = self.get_event_metrics(event_type)
health_status = {
"status": "healthy",
"alerts": []
}
# 检查错误率
if metrics["error_rate"] > 0.1: # 10% 错误率阈值
health_status["status"] = "unhealthy"
health_status["alerts"].append(f"High error rate: {metrics['error_rate']:.2%}")
# 检查事件处理量
total_events = metrics["success_count"] + metrics["failure_count"]
if total_events == 0:
health_status["status"] = "warning"
health_status["alerts"].append("No events processed in the last hour")
return health_status
2. 实时健康检查
class HealthCheckManager:
"""健康检查管理器"""
def __init__(self, redis_client, db_session):
self.redis_client = redis_client
self.db_session = db_session
self.event_monitor = EventFlowMonitor(redis_client)
self.resource_monitor = ResourceMonitoringManager()
def perform_health_check(self) -> dict:
"""执行全面健康检查"""
health_report = {
"timestamp": time.time(),
"overall_status": "healthy",
"components": {}
}
# 检查 Redis 连接
health_report["components"]["redis"] = self._check_redis_health()
# 检查数据库连接
health_report["components"]["database"] = self._check_database_health()
# 检查系统资源
health_report["components"]["resources"] = self._check_resource_health()
# 检查事件流
health_report["components"]["events"] = self._check_event_flow_health()
# 检查 Celery 任务队列
health_report["components"]["celery"] = self._check_celery_health()
# 计算整体状态
unhealthy_components = [comp for comp, status in health_report["components"].items()
if status["status"] != "healthy"]
if unhealthy_components:
if any(health_report["components"][comp]["status"] == "critical"
for comp in unhealthy_components):
health_report["overall_status"] = "critical"
else:
health_report["overall_status"] = "warning"
return health_report
def _check_redis_health(self) -> dict:
"""检查 Redis 健康状态"""
try:
# 测试 Redis 连接
self.redis_client.ping()
# 检查内存使用
info = self.redis_client.info('memory')
memory_usage = info['used_memory'] / info['maxmemory'] if info.get('maxmemory') else0
status = "healthy"
alerts = []
if memory_usage > 0.9:
status = "critical"
alerts.append(f"Redis memory usage critical: {memory_usage:.1%}")
elif memory_usage > 0.8:
status = "warning"
alerts.append(f"Redis memory usage high: {memory_usage:.1%}")
return {
"status": status,
"memory_usage": memory_usage,
"alerts": alerts
}
except Exception as e:
return {
"status": "critical",
"error": str(e),
"alerts": ["Redis connection failed"]
}
def _check_database_health(self) -> dict:
"""检查数据库健康状态"""
try:
# 测试数据库连接
self.db_session.execute("SELECT 1")
return {
"status": "healthy",
"alerts": []
}
except Exception as e:
return {
"status": "critical",
"error": str(e),
"alerts": ["Database connection failed"]
}
def _check_resource_health(self) -> dict:
"""检查系统资源健康状态"""
resource_status = self.resource_monitor.check_system_resources()
status = "healthy"
alerts = []
for resource_type, resource_info in resource_status.items():
if resource_info["critical"]:
status = "warning"if status == "healthy"else status
alerts.append(f"{resource_type.title()} usage critical: {resource_info['usage']:.1%}")
return {
"status": status,
"resource_usage": resource_status,
"alerts": alerts
}
def _check_event_flow_health(self) -> dict:
"""检查事件流健康状态"""
event_types = ["message_created", "workflow_started", "node_executed"]
overall_status = "healthy"
all_alerts = []
for event_type in event_types:
event_health = self.event_monitor.check_event_health(event_type)
if event_health["status"] != "healthy":
overall_status = "warning"if overall_status == "healthy"else overall_status
all_alerts.extend([f"{event_type}: {alert}"for alert in event_health["alerts"]])
return {
"status": overall_status,
"alerts": all_alerts
}
def _check_celery_health(self) -> dict:
"""检查 Celery 健康状态"""
try:
from celery import current_app
# 检查活跃的 worker
inspect = current_app.control.inspect()
active_workers = inspect.active()
ifnot active_workers:
return {
"status": "critical",
"alerts": ["No active Celery workers found"]
}
# 检查队列长度
queue_lengths = {}
for worker, tasks in active_workers.items():
queue_lengths[worker] = len(tasks)
max_queue_length = max(queue_lengths.values()) if queue_lengths else0
status = "healthy"
alerts = []
if max_queue_length > 1000:
status = "warning"
alerts.append(f"High queue length detected: {max_queue_length}")
return {
"status": status,
"active_workers": len(active_workers),
"max_queue_length": max_queue_length,
"alerts": alerts
}
except Exception as e:
return {
"status": "critical",
"error": str(e),
"alerts": ["Celery health check failed"]
}
3. 告警通知系统
class AlertManager:
"""告警管理器"""
def __init__(self, notification_channels: list):
self.notification_channels = notification_channels
self.alert_history = {}
def send_alert(self, alert_type: str, message: str, severity: str = "warning"):
"""发送告警"""
alert_key = f"{alert_type}:{hash(message)}"
current_time = time.time()
# 防止重复告警(5分钟内相同告警只发送一次)
if alert_key in self.alert_history:
if current_time - self.alert_history[alert_key] < 300:
return
self.alert_history[alert_key] = current_time
alert_data = {
"type": alert_type,
"message": message,
"severity": severity,
"timestamp": current_time,
"hostname": socket.gethostname()
}
for channel in self.notification_channels:
try:
channel.send_notification(alert_data)
except Exception as e:
logging.error(f"Failed to send alert via {channel.__class__.__name__}: {e}")
class SlackNotificationChannel:
"""Slack 通知渠道"""
def __init__(self, webhook_url: str):
self.webhook_url = webhook_url
def send_notification(self, alert_data: dict):
"""发送 Slack 通知"""
import requests
color_map = {
"info": "good",
"warning": "warning",
"error": "danger",
"critical": "danger"
}
payload = {
"attachments": [{
"color": color_map.get(alert_data["severity"], "warning"),
"title": f"Dify Alert: {alert_data['type']}",
"text": alert_data["message"],
"fields": [
{"title": "Severity", "value": alert_data["severity"], "short": True},
{"title": "Host", "value": alert_data["hostname"], "short": True},
{"title": "Time", "value": time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(alert_data["timestamp"])), "short": True}
]
}]
}
response = requests.post(self.webhook_url, json=payload)
response.raise_for_status()
故障处理流程
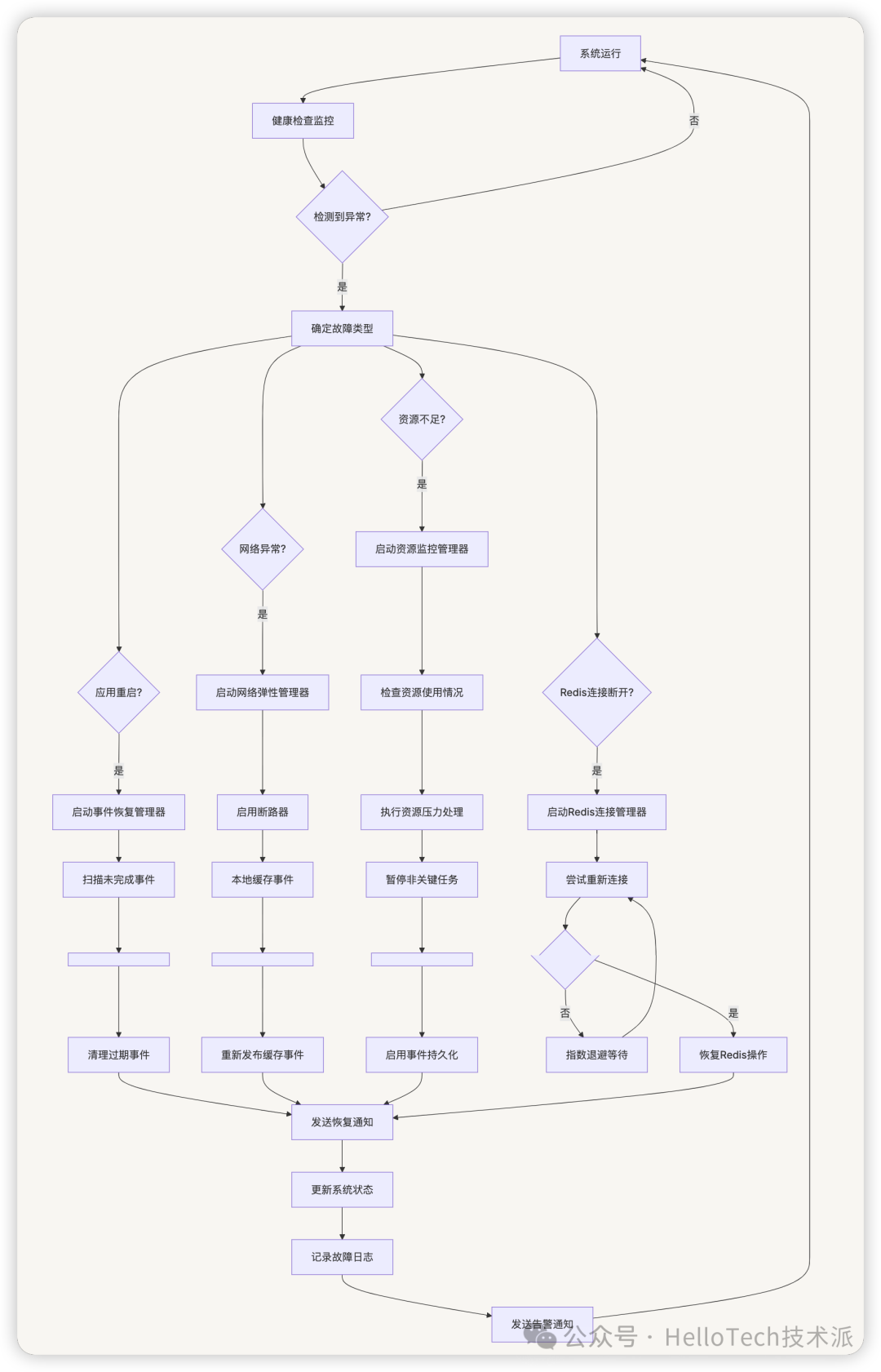
Task 任务执行异常处理
异常分类和处理策略
1. 可重试异常
-
网络连接错误
-
临时资源不足
-
外部服务暂时不可用
-
数据库连接超时
2. 不可重试异常
-
数据验证错误
-
权限不足
-
资源不存在
-
业务逻辑错误
3. 需要人工干预的异常
-
系统配置错误
-
第三方服务长期不可用
-
数据损坏
具体实现方案
class TaskException(Exception):
"""任务异常基类"""
def __init__(self, message: str, retryable: bool = True, alert_level: str = 'warning'):
super().__init__(message)
self.retryable = retryable
self.alert_level = alert_level
class RetryableTaskException(TaskException):
"""可重试的任务异常"""
def __init__(self, message: str, retry_delay: int = 60):
super().__init__(message, retryable=True)
self.retry_delay = retry_delay
class FatalTaskException(TaskException):
"""致命任务异常,不可重试"""
def __init__(self, message: str):
super().__init__(message, retryable=False, alert_level='error')
@shared_task(bind=True, max_retries=3)
def enhanced_document_indexing_task(self, dataset_id: str, document_ids: list):
"""增强的文档索引任务"""
try:
# 参数验证
ifnot dataset_id ornot document_ids:
raise FatalTaskException("Invalid parameters: dataset_id or document_ids missing")
# 获取数据集
dataset = db.session.query(Dataset).filter(Dataset.id == dataset_id).first()
ifnot dataset:
raise FatalTaskException(f"Dataset not found: {dataset_id}")
# 执行索引任务
for document_id in document_ids:
try:
process_single_document(dataset_id, document_id)
except ConnectionError as e:
raise RetryableTaskException(f"Connection error processing document {document_id}: {str(e)}")
except Exception as e:
logging.error(f"Error processing document {document_id}: {str(e)}")
mark_document_failed(document_id, str(e))
logging.info(f"Document indexing completed for dataset: {dataset_id}")
except RetryableTaskException as exc:
if self.request.retries < self.max_retries:
logging.warning(f"Retrying task {self.request.id}: {exc}")
raise self.retry(countdown=exc.retry_delay, exc=exc)
else:
logging.error(f"Task {self.request.id} failed after max retries: {exc}")
send_task_failure_alert(self.request.id, str(exc), 'max_retries_exceeded')
raise
except FatalTaskException as exc:
logging.error(f"Fatal error in task {self.request.id}: {exc}")
send_task_failure_alert(self.request.id, str(exc), 'fatal_error')
raise
except Exception as exc:
logging.error(f"Unexpected error in task {self.request.id}: {exc}", exc_info=True)
if self.request.retries < self.max_retries:
raise self.retry(countdown=120, exc=exc)
else:
send_task_failure_alert(self.request.id, str(exc), 'unexpected_error')
raise
finally:
db.session.close()
总结
Dify 的消息事件和 Task 实现机制体现了分布式系统的设计理念:
核心优势
-
高可扩展性:通过事件驱动架构和分布式任务队列,系统可以水平扩展
-
高可用性:完善的错误处理和重试机制保证系统稳定运行
-
实时性:通过 WebSocket 和事件推送实现实时状态同步
-
灵活性:模块化设计使得系统易于扩展和维护
-
容错性:多层次的异常处理和恢复机制确保系统稳定性
技术特点
-
事件驱动:基于事件的异步通信机制
-
分层设计:清晰的分层架构便于理解和维护
-
类型安全:使用 Pydantic 进行数据验证和类型检查
-
监控完善:内置监控和追踪机制
-
异常处理:完善的异常分类和处理策略
应用场景
-
聊天应用:实时消息处理和状态同步
-
工作流引擎:复杂业务流程的编排和执行
-
文档处理:大规模文档的异步处理和索引
-
数据分析:大数据的批量处理和分析
-
通知系统:实时通知和消息推送
-
AI 应用:AI 模型的调用和结果处理
通过深入理解 Dify 的消息事件和 Task 实现机制,可以更好地利用这些特性构建高性能、高可用的 AI 应用系统。
如何学习AI大模型 ?
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
(👆👆👆安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
(👆👆👆安全链接,放心点击)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)