从数据集准备到大模型(qwen2.5-vl-3B)微调训练完整流程
本文介绍了使用Label Studio和LLaMA-Factory进行图像标注及大模型微调的完整流程。首先通过Label Studio进行图像标注并导出CSV/JSON数据,经格式转换处理后存入指定目录,同时在dataset_info.json中注册新数据集。然后在LLaMA-Factory中选择配置好的数据集、模型及参数进行微调训练。文中提供了详细的工具使用指南,包括数据格式转换、路径设置等关键
目录
json文件放入data/upload中,并在dataset_info.json中加入新加的数据集json文件信息
1.Label studio(准备自己的数据集)
打开web界面
#打开相应env后在anaconda终端输入下面命令(参考下方链接中quick start)
label-studio start对图片打标签导出csv/json

csv转成xlsx格式
excel中点击数据(csv导入)-将空白行删掉并确认-复制表格内容另存为xlsx文件格式
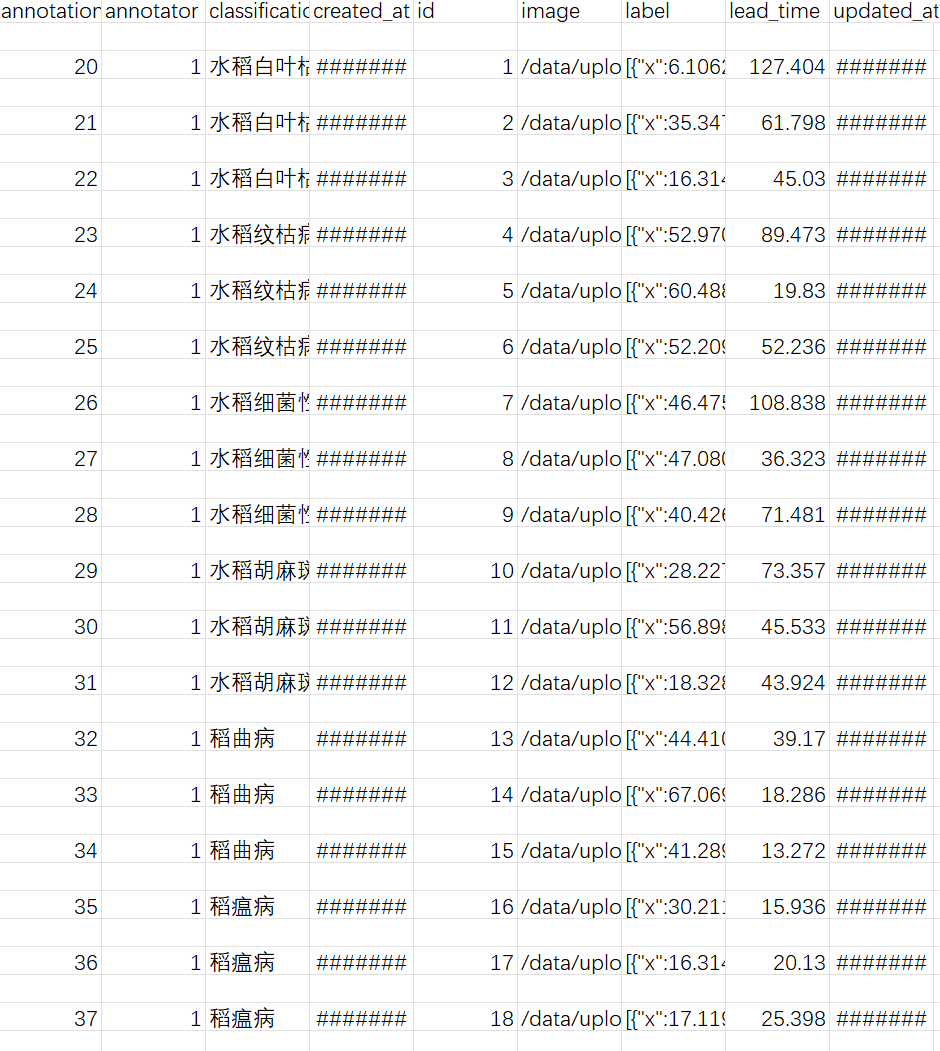
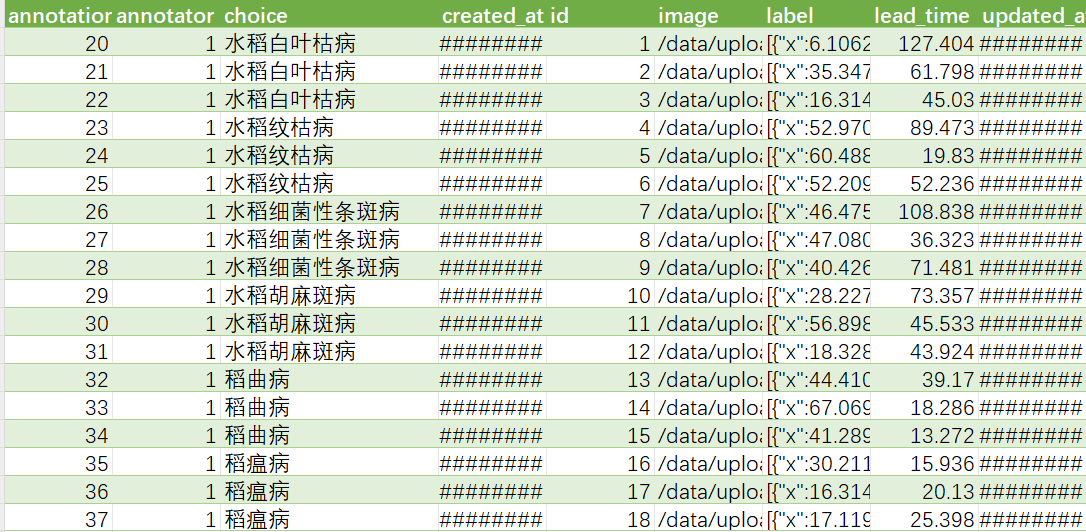
将xlsx文件转成json
(对应模型的json格式,这里的qwen2.5-vl-3B参考mllm_demo_json格式)用excel2json.py文件转(注意表头和.py中对应)注意导出json的image路径
#excel2json.py
import pandas as pd
import json
# 配置参数
input_file = ("D:/Driverless_car/LLM/shuidao.xlsx") # 输入文件名
output_file = "D:/Driverless_car/LLM/shuidao.json" # 输出文件名
all_data = []
selected_columns = ["choice", "image"] # 需要提取的列名
sheet_name = None # 工作表名称(默认第一个表可设为None)
# 定义行处理函数
def process_row(row):
all_data.append(
{
"messages": [
{
"content": "<image>图片中的农作物得了什么病?",
"role": "user",
},
{
"content": row["choice"], # 从数据集中获取的标题
"role": "assistant",
},
],
"images": row["image"], # 图像文件路径
}
)
# 读取Excel文件
df = pd.read_excel(input_file)
# dfframe = pd.DataFrame.from_dict(df, orient='index')
print("开始处理数据...")
for index, row in df.iterrows():
processed_row = process_row(row)
# print(f"处理第{index+1}行:{processed_row['姓名']}")
# 写入JSON文件
with open(output_file, "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=4)
# print(f"转换完成!共处理了{len(data)}条记录")
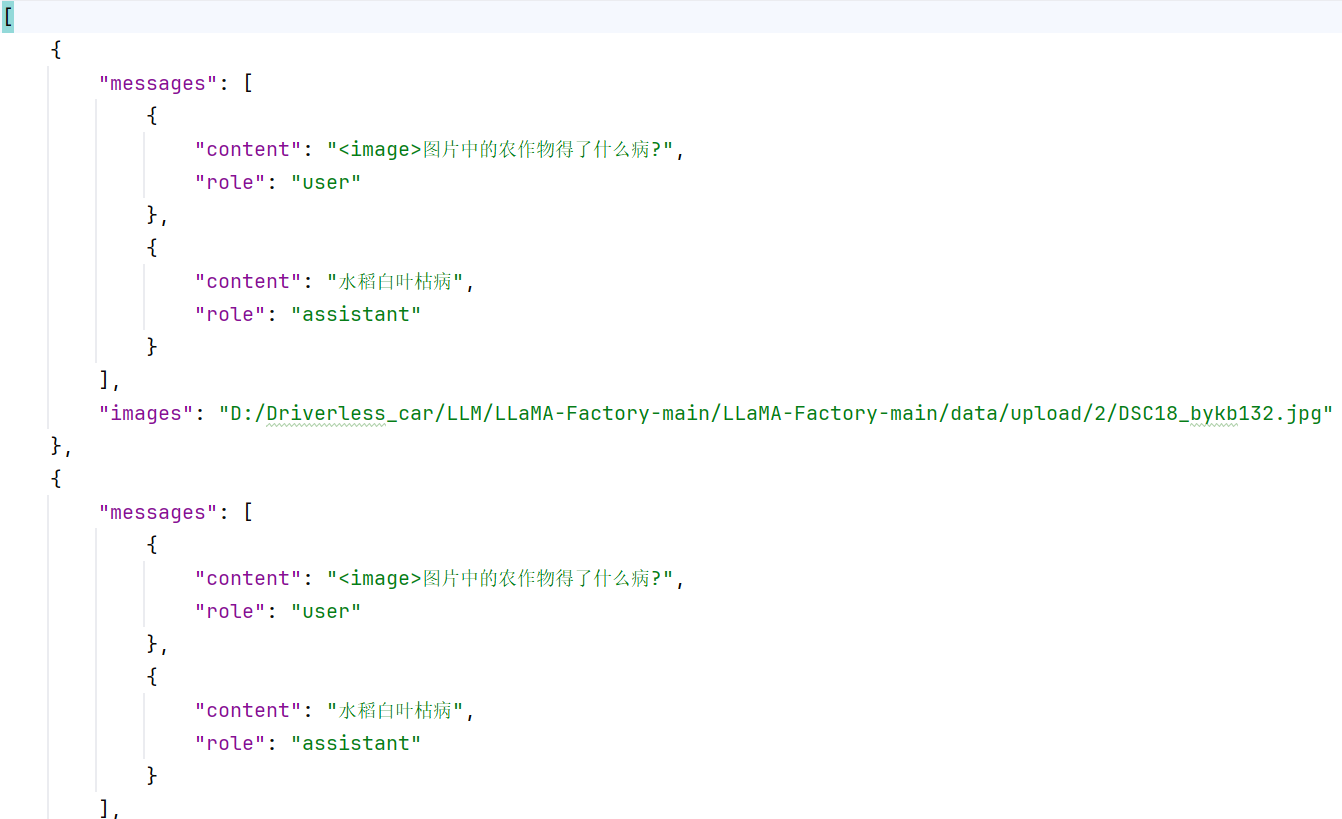
json文件放入data/upload中,并在dataset_info.json中加入新加的数据集json文件信息
这样才能在llama_factory的web界面选中自己要微调的数据集

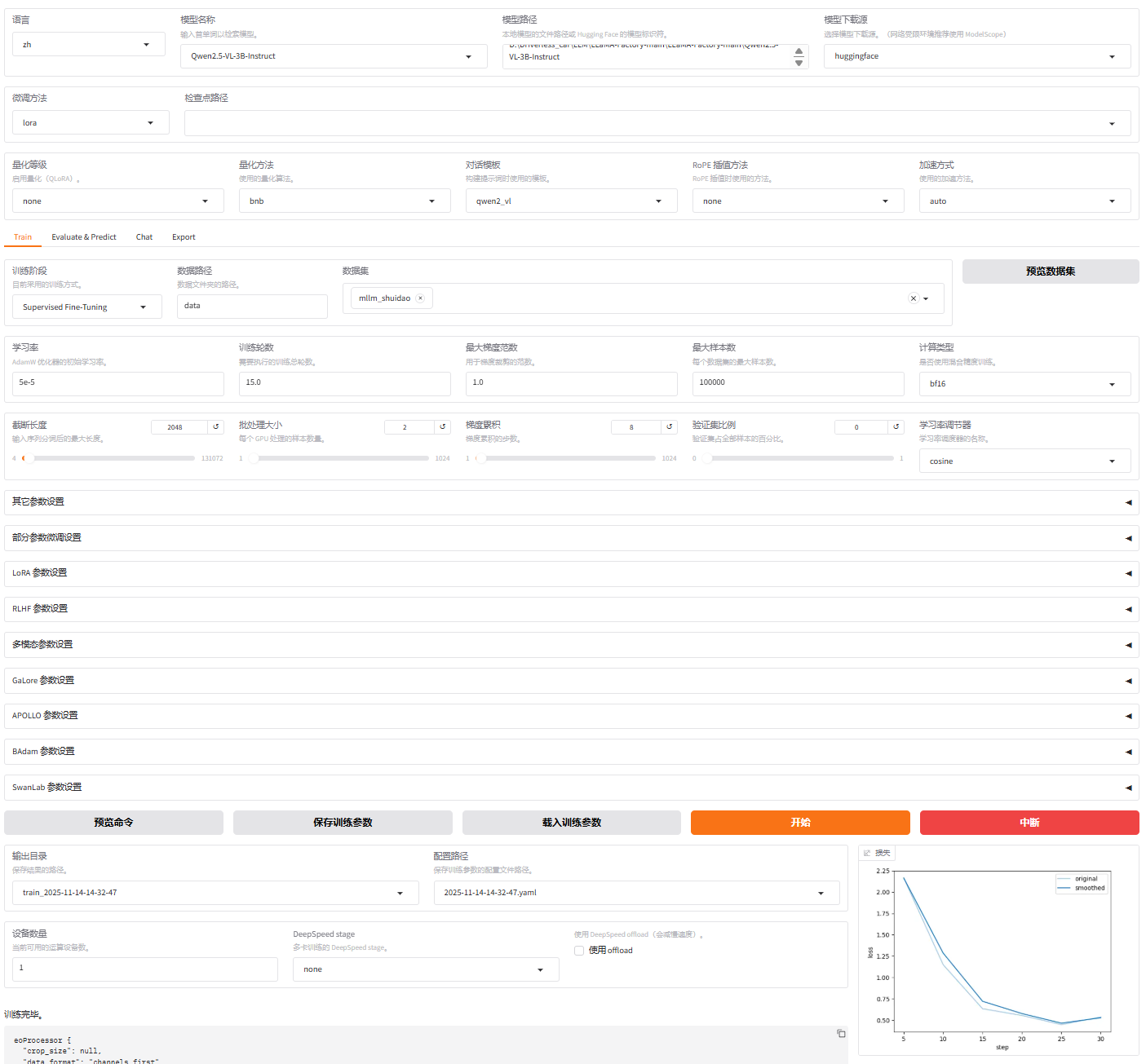
2.llama-factory(实现模型微调)
anaconda终端(参考下方csdn和github链接)
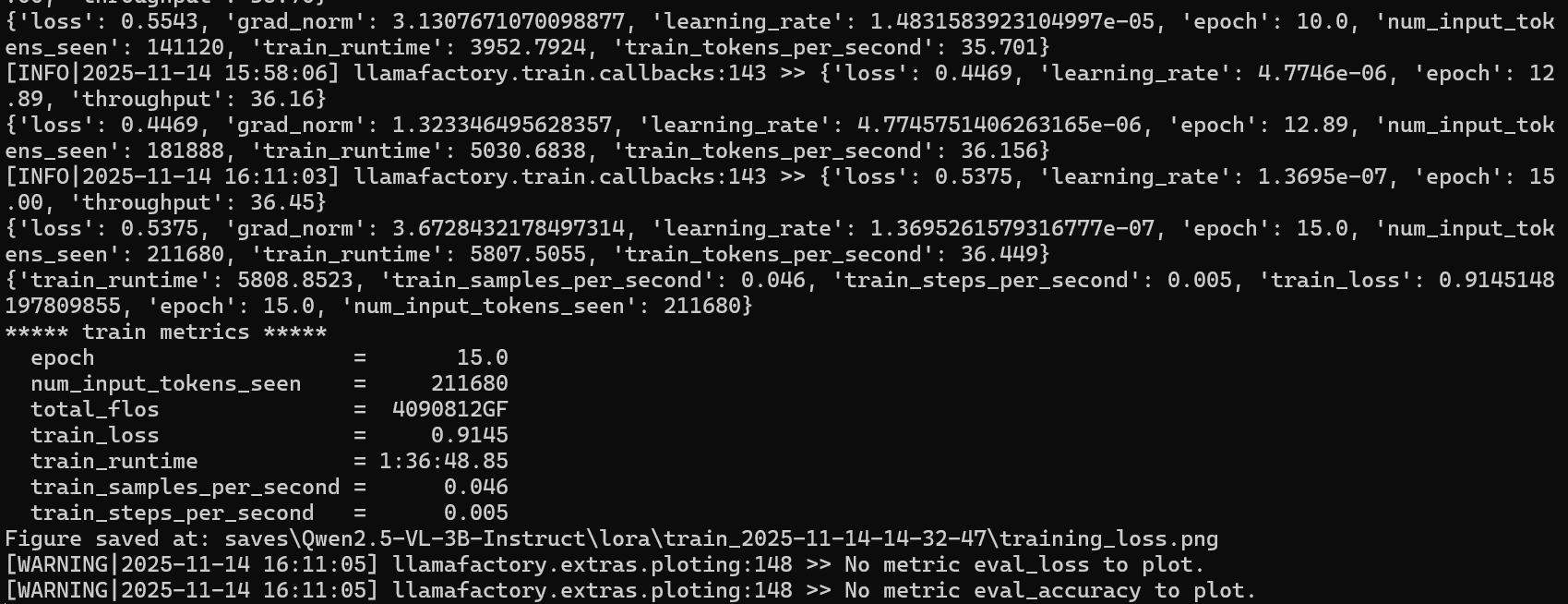
打开对应env,打开llamafactory界面,选中相应模型、data、参数开始训练
llamafactory-cli webui
参考链接:
从数据集准备到大模型(qwen2.5-vl:3B)训练完整流程 Label studio到LLama-Factory_哔哩哔哩_bilibili
Label Studio Documentation — Quick start guide for Label Studio
微调神器LLaMA-Factory官方保姆级教程来了,从环境搭建到模型训练评估全覆盖_llamafactory教程-CSDN博客

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)