Milvus混合搜索
需要在 Collections Schema 中定义多个向量字段。目前,每个 Collection 默认最多可包含 4 个向量字段。但也可以根据需要修改的值,在集合中最多包含 10 个向量字段。下面的示例定义了一个 Collection Schema,其中dense和sparseid:该字段是存储文本 ID 的主键。该字段的数据类型为 INT64。text:该字段用于存储文本内容。该字段的数据类型
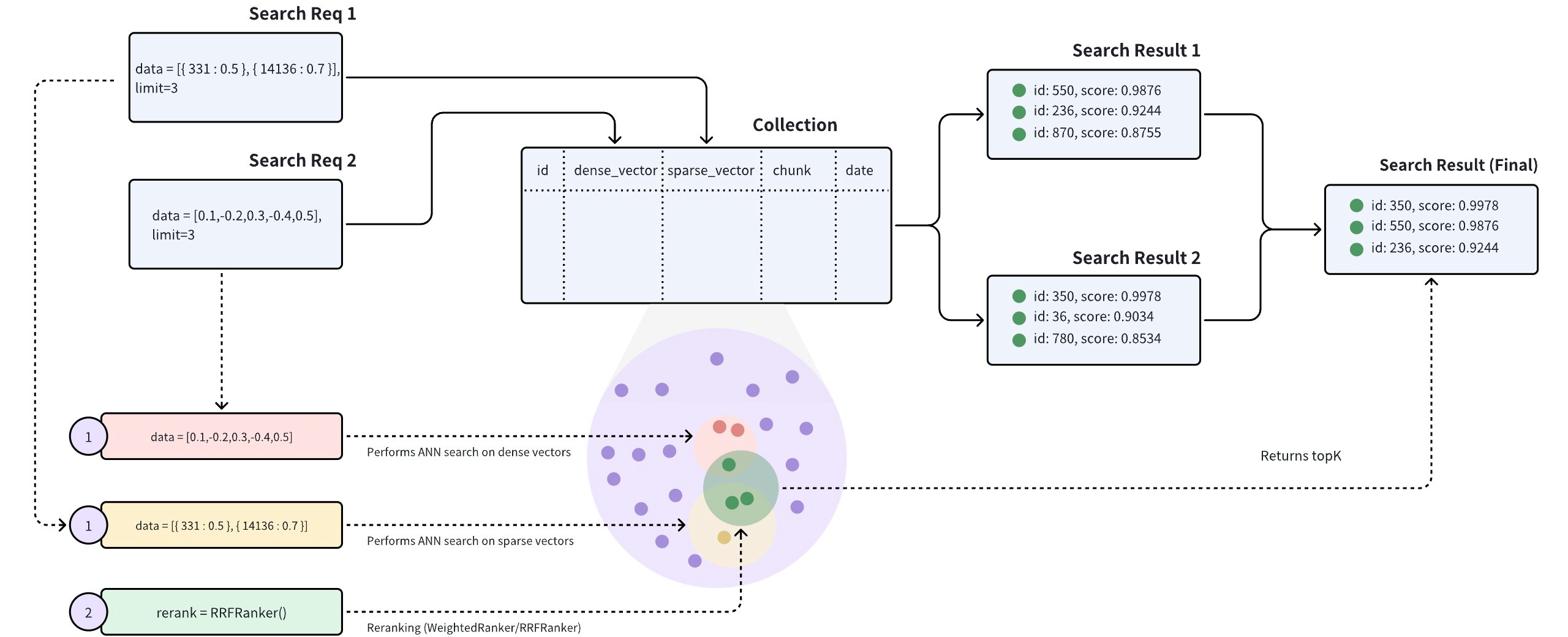
混合搜索指的是一种同时进行多个 ANN 搜索、对这些 ANN 搜索的多组结果进行 Rerankers 并最终返回一组结果的搜索方法。使用混合搜索可以提高搜索的准确性。Milvus 支持在具有多个向量场的 Collections 上进行混合搜索。
混合搜索最常用于稀疏密集向量搜索和多模态搜索等场景。本指南将通过一个具体实例演示如何在 Milvus 中进行混合搜索。
应用场景
混合搜索适用于以下两种情况:
稀疏-密集向量搜索
不同类型的向量可以表示不同的信息,使用不同的嵌入模型可以更全面地表示数据的不同特征和方面。例如,对同一个句子使用不同的 Embeddings 模型,可以生成表示语义的密集向量和表示句子中词频的稀疏向量。
-
稀疏向量:稀疏向量的特点是其向量维度高,存在很少的非零值。这种结构使其特别适合传统的信息检索应用。在大多数情况下,稀疏向量中使用的维数对应于一种或多种语言中的不同词块。每个维度都有一个值,表示该标记在文档中的相对重要性。这种布局对于涉及关键词匹配的任务非常有利。
-
密集向量:密集向量是从神经网络中衍生出来的嵌入。当排列成有序数组时,这些向量能捕捉到输入文本的语义本质。需要注意的是,稠密向量并不局限于文本处理;它们还广泛应用于计算机视觉领域,以表示视觉数据的语义。这些稠密向量通常由文本 Embeddings 模型生成,其特点是大部分或所有元素都非零。因此,密集向量对于语义搜索应用特别有效,因为即使在没有精确关键词匹配的情况下,它们也能根据向量距离返回最相似的结果。这种功能可以获得更细致入微、更能感知上下文的搜索结果,通常可以捕捉到基于关键词的方法可能忽略的概念之间的关系。
多模式搜索
多模态搜索是指跨多种模态(如图像、视频、音频、文本等)对非结构化数据进行相似性搜索。例如,一个人可以用指纹、声纹和面部特征等多种数据模式来表示。混合搜索支持同时进行多种搜索。例如,用相似的指纹和声纹搜索一个人。
工作流程
混合搜索的主要工作流程如下:
-
通过BERT和Transformers 等嵌入模型生成密集向量。
-
在 Milvus 中创建 Collections 并定义 Collections Schema,其中包括密集向量场和稀疏向量场。
-
将稀疏密集向量插入上一步刚刚创建的 Collections 中。
-
进行混合搜索:稠密向量上的 ANN 搜索将返回一组前 K 个最相似的结果,稀疏向量上的文本匹配也将返回一组前 K 个结果。
-
归一化:对两组 K 强结果的得分进行归一化,将得分转换为 [0,1] 之间的范围。
-
选择适当的 Rerankers 策略,对两组 Top-K 结果进行合并和重排,最终返回一组 Top-K 结果。
混合搜索
示例
本节将使用一个具体示例来说明如何在稀疏密集向量上进行混合搜索,以提高文本搜索的准确性。
创建具有多个向量场的 Collections
创建 Collections 的过程包括三个部分:定义 Collections Schema、配置索引参数和创建 Collections。
定义 Schema
在本例中,需要在 Collections Schema 中定义多个向量字段。目前,每个 Collection 默认最多可包含 4 个向量字段。但也可以根据需要修改proxy.maxVectorFieldNum 的值,在集合中最多包含 10 个向量字段。
下面的示例定义了一个 Collection Schema,其中dense 和sparse 是两个向量字段:
-
id:该字段是存储文本 ID 的主键。该字段的数据类型为 INT64。 -
text:该字段用于存储文本内容。该字段的数据类型为 VARCHAR,最大长度为 1000 个字符。 -
dense:该字段用于存储文本的密集向量。该字段的数据类型为 FLOAT_VECTOR,向量维数为 768。 -
sparse:该字段用于存储文本的稀疏向量。该字段的数据类型为 SPARSE_FLOAT_VECTOR。
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("dense")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
在稀疏向量搜索过程中,可以利用全文搜索功能简化生成稀疏嵌入向量的过程。有关详细信息,请参阅全文搜索。
创建索引
定义完 Collections Schema 后,有必要设置向量索引和相似度度量。在本例中,为密集向量场dense 和稀疏向量场sparse 都创建了AUTOINDEX类型的索引。您可以根据需要使用其他索引类型。
import io.milvus.v2.common.IndexParam;
import java.util.*;
Map<String, Object> denseParams = new HashMap<>();
IndexParam indexParamForDenseField = IndexParam.builder()
.fieldName("dense")
.indexName("dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
Map<String, Object> sparseParams = new HashMap<>();
sparseParams.put("drop_ratio_build", 0.2);
IndexParam indexParamForSparseField = IndexParam.builder()
.fieldName("sparse")
.indexName("sparse_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.extraParams(sparseParams)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForDenseField);
indexParams.add(indexParamForSparseField);
创建 Collections
使用前两个步骤中配置的集合 Schema 和索引创建名为demo 的 Collection
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(createCollectionReq);
插入数据
将稀疏密集向量插入集合demo
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
JsonObject row1 = new JsonObject();
row1.addProperty("id", 1);
row1.addProperty("text", "Artificial intelligence was founded as an academic discipline in 1956.");
row1.add("dense", gson.toJsonTree(dense1));
row1.add("sparse", gson.toJsonTree(sparse1));
JsonObject row2 = new JsonObject();
row2.addProperty("id", 2);
row2.addProperty("text", "Alan Turing was the first person to conduct substantial research in AI.");
row2.add("dense", gson.toJsonTree(dense2));
row2.add("sparse", gson.toJsonTree(sparse2));
JsonObject row3 = new JsonObject();
row3.addProperty("id", 3);
row3.addProperty("text", "Born in Maida Vale, London, Turing was raised in southern England.");
row3.add("dense", gson.toJsonTree(dense3));
row3.add("sparse", gson.toJsonTree(sparse3));
List<JsonObject> data = Arrays.asList(row1, row2, row3);
InsertReq insertReq = InsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
InsertResp insertResp = client.insert(insertReq);
创建多个 AnnSearchRequest 实例
混合搜索是通过在hybrid_search() 函数中创建多个AnnSearchRequest 来实现的,其中每个AnnSearchRequest 代表一个特定向量场的基本 ANN 搜索请求。因此,在进行混合搜索之前,有必要为每个向量场创建一个AnnSearchRequest 。
通过在AnnSearchRequest 中配置expr 参数,可以为混合搜索设置过滤条件。请参阅过滤搜索和过滤。
在混合搜索中,每个AnnSearchRequest 只支持一个查询向量。
假设查询文本 "谁开始了人工智能研究?"已经被转换成稀疏向量和密集向量。在此基础上,分别针对sparse 和dense 向量字段创建两个AnnSearchRequest 搜索请求,如下例所示。
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.data.BaseVector;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.request.data.SparseFloatVec;
float[] dense = new float[]{-0.0475336798f, 0.0521207601f, 0.0904406682f, ...};
SortedMap<Long, Float> sparse = new TreeMap<Long, Float>() {{
put(3573L, 0.34701499f);
put(5263L, 0.263937551f);
...
}};
List<BaseVector> queryDenseVectors = Collections.singletonList(new FloatVec(dense));
List<BaseVector> querySparseVectors = Collections.singletonList(new SparseFloatVec(sparse));
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("dense")
.vectors(queryDenseVectors)
.metricType(IndexParam.MetricType.IP)
.params("{\"nprobe\": 10}")
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("sparse")
.vectors(querySparseVectors)
.metricType(IndexParam.MetricType.IP)
.params("{\"drop_ratio_build\": 0.2}")
.topK(2)
.build());
由于limit 参数设置为 2,因此每个AnnSearchRequest 都会返回 2 个搜索结果。在本例中,创建了 2 个AnnSearchRequest ,因此总共会返回 4 个搜索结果。
配置 Rerankers 策略
要对两组 ANN 搜索结果进行合并和重新排序,有必要选择适当的重新排序策略。Milvus 支持两种重排策略:加权排名策略(WeightedRanker)和重 排序策略(RRFRanker)。在选择重排策略时,需要考虑的一个问题是,是否强调向量场上的一个或多个基本 ANN 搜索。
-
加权排名:如果您要求结果强调特定的向量场,建议使用该策略。通过 WeightedRanker,您可以为某些向量场分配更高的权重,从而更加强调这些向量场。例如,在多模态搜索中,图片的文字描述可能比图片的颜色更重要。
-
RRFRanker(互易排名融合排名器):在没有特定重点的情况下,建议采用这种策略。RRF 可以有效平衡每个向量场的重要性。
有关这两种 Reranking 策略机制的更多详情,请参阅Reranking。
下面两个示例演示了如何使用 WeightedRanker 和 RRFRanker 重排序策略:
-
例 1:使用加权排名策略
使用 WeightedRanker 策略时,需要在
WeightedRanker函数中输入权重值。混合搜索中的基本 ANN 搜索次数与需要输入的值的次数相对应。输入值的范围应为 [0,1],数值越接近 1 表示重要性越高。import io.milvus.v2.service.vector.request.ranker.BaseRanker; import io.milvus.v2.service.vector.request.ranker.WeightedRanker; BaseRanker reranker = new WeightedRanker(Arrays.asList(0.8f, 0.3f)); -
示例 2:使用 RRFRanker
使用 RRFRanker 策略时,需要将参数值
k输入 RRFRanker。k的默认值为 60。该参数有助于确定如何组合来自不同 ANN 搜索的排名,目的是平衡和混合所有搜索的重要性。import io.milvus.v2.service.vector.request.ranker.BaseRanker; import io.milvus.v2.service.vector.request.ranker.RRFRanker; BaseRanker reranker = new RRFRanker(100);
执行混合搜索
在进行混合搜索之前,有必要将 Collections 加载到内存中。如果集合中的任何向量字段没有索引或没有加载,调用 Hybrid Search 方法时就会出错。
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName("my_collection")
.searchRequests(searchRequests)
.ranker(reranker)
.topK(2)
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
输出结果如下:
["['id: 844, distance: 0.006047376897186041, entity: {}', 'id: 876, distance: 0.006422005593776703, entity: {}']"]由于在混合搜索中指定了limit=2 ,Milvus 将对步骤 3 中的 4 个搜索结果进行重新排序,最终只返回最相似的前 2 个搜索结果。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)