使用ollama部署DeepSeek-R1-Distill-Qwen-1.5B
Ollama是一个基于 Go 语言的本地大语言模型运行框架,类 docker 产品(支持 list,pull,push,run 等命令),ollama将类似于镜像的大模型从中央仓库拉取到本地,可以把ollama看作,把ai大模型看作是镜像。DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司。推出国产大模型DeepSeek-V3和DeepSeek-R1。总参数量为671B,激活37B。优
1. 介绍
1.1 ollama
Ollama 是一个基于 Go 语言的本地大语言模型运行框架,类 docker 产品(支持 list,pull,push,run 等命令),ollama将类似于镜像的大模型从中央仓库拉取到本地,可以把ollama看作docker容器,把ai大模型看作是镜像。
如果想使用vllm部署DeepSeek-R1-Distill-Qwen-1.5B,可以看这篇文章:使用vllm部署DeepSeek-R1-Distill-Qwen-1.5B-CSDN博客
1.2 deepseek
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司。推出国产大模型DeepSeek-V3和DeepSeek-R1。总参数量为671B,激活37B。
优势:
(1):开发费用超级低,训练成本约为558万美元,是美国最好的模型openAI o1开发费用的3%;
(2):与openAI o1水平相当,数学、编程和推理任务上,甚至偶尔超过了o1;
也正是因为如此,DeepSeek R1价格非常便宜,每100万个输出tokens 2.19美元,而 OpenAI o1 则需要60美元,DeepSeek R1便宜 96.4%,性能却不相上下,完全就是逆风翻盘。
DeepSeek基于 Llama 和 Qwen 从 DeepSeek-R1 中提炼出六个密集模型。 DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中均优于 OpenAI-o1-mini。
2. linux环境配置
V100-32GB
PyTorch 2.5.1
Python 3.12(ubuntu22.04)
Cuda 12.4
3. 安装ollama
3.1 linux
参考网址:ollama/docs/linux.md at main · ollama/ollama · GitHub
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
3.2 macOS和windows
参考网址:https://github.com/ollama/ollama
ollama也支持macOS和windows安装,根据自己相应的系统下载安装就行。
启动: ollama serve
3.3 Ollama 添加为自启动服务
3.3.1 首先为Ollama 创建用户
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
3.3.2 然后在该位置:/etc/systemd/system/ollama.service 创建服务文件
[Unit]
Description=Ollama
Service After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
3.3.3 最后启动服务
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama
sudo systemctl status ollama
3.3.4 修改ip和端口也可以在环境变量中修改
export OLLAMA_HOST=0.0.0.0
export OLLAMA_PORT=11434
4. ollama常用命令
ollama启动以后可以运行以下命令和他交互:
ollama list:显示模型列表。
ollama show:显示模型的信息
ollama pull:拉取模型
ollama push:推送模型
ollama cp:拷贝一个模型
ollama rm:删除一个模型
ollama run:运行一个模型
5. 运行deepseek模型
5.1 从https://ollama.com/library中查找你想要运行的模型
5.2 不同类型的模型对应的ollama运行命令如下:

5.3 运行deepseek-r1-qwen-1.5b模型
执行命令ollama run deepseek-r1:1.5b,如果本地没有该模型,则会先下载模型再运行。首次运行启动可能略慢。运行ollama run命令以前,必须先运行ollama serve命令启动ollama。
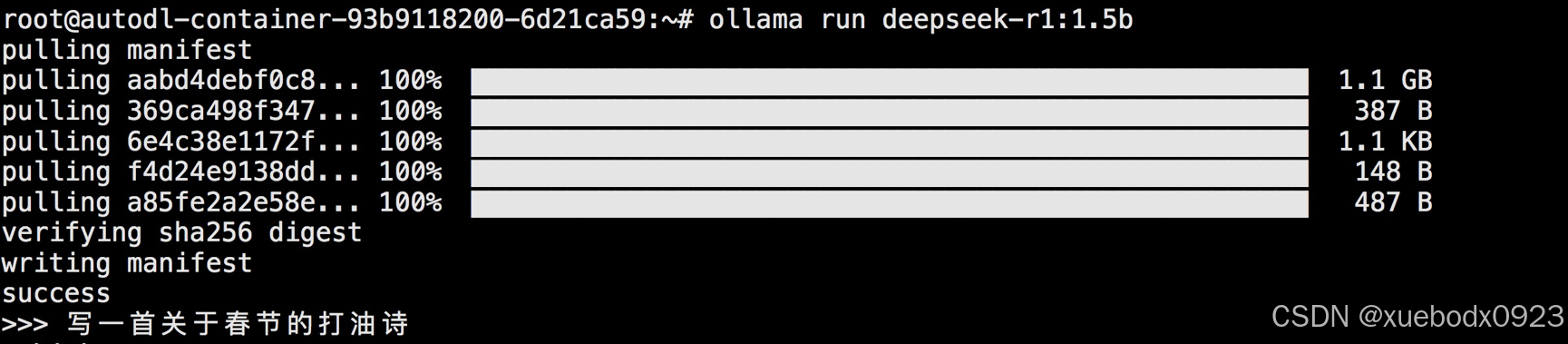
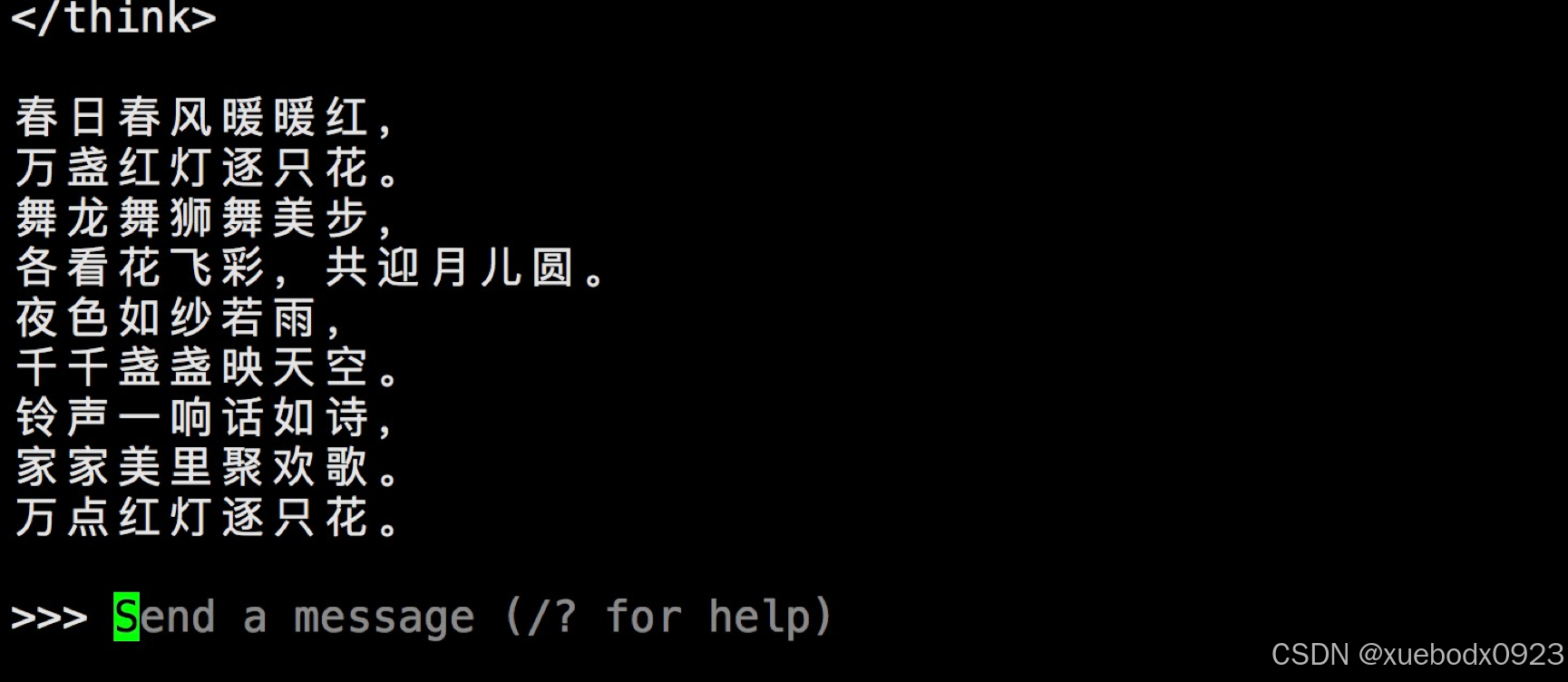
运行成功后可以直接和大模型对话:
1.5b的模型GPU占用不到2G:
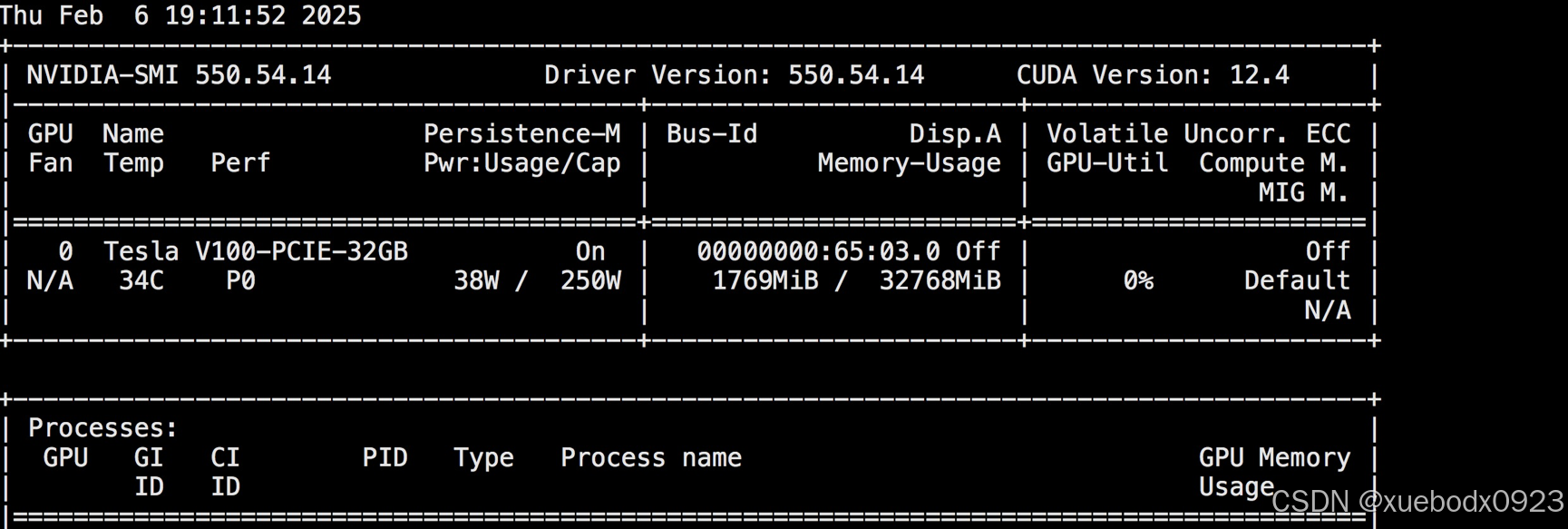
5.4 运行deepseek-r1-qwen-32b模型
ollama run deepseek-r1:32b
查看模型: ollama list

运行成功后可以直接和大模型对话:


32b的模型GPU占用21G:
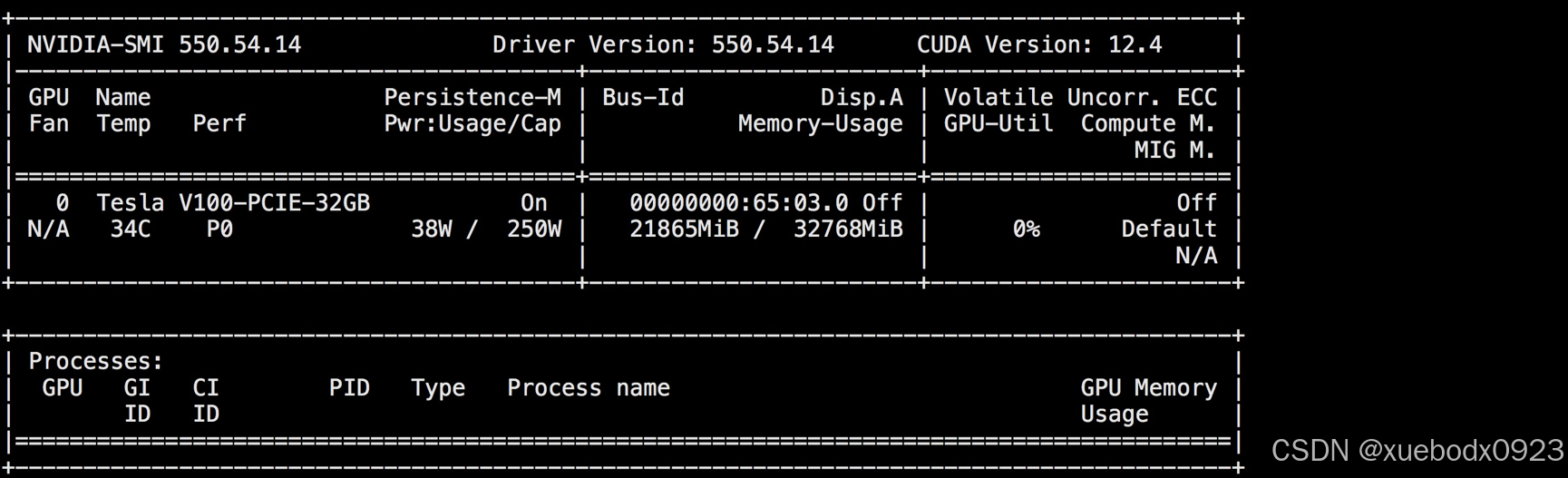
让1.5b的模型和32b的模型同时写一首关于春节的打油诗,可以看到32b的回答要比1.5b的回答好,大家可以按照自己的GPU大小和需求运行对应的deepseek版本;
6. 通过web界面调用大模型

git clone https://github.com/ollama-webui/ollama-webui-lite.git cd ollama-webui-lite npm ci npm run dev 运行之后,你可以对连接信息进行设置,默认是连接本机的 http://localhost:11434/api,如果你也是本机部署,那就不用更改。然后界面选择启动的模型,就可以对话了。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 37
37 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)