新手必看| 2025年Deepseek一站式本地配置,直接搭建(Windows11)
Ollama 是一个开源框架,专门设计用于在本地运行大型语言模型(LLMs)。LM Studio 是一款桌面应用程序,专为那些希望拥有图形用户界面(GUI)而非命令行界面(CLI)的用户提供服务。
一、准备工作
了解一下ollama是啥东西,LLMStudio是啥,因为接下来会用到
二、Ollama 和 LM Studio 简介
1.Ollama
Ollama 是一个开源框架,专门设计用于在本地运行大型语言模型(LLMs)。它的主要特点如下:
- 简化部署:Ollama可以个人电脑上部署和运行LLM的过程。它轻量级、易于扩展的框架,能在本机上轻松构建和管理
- 支持多平台:该框架支持macOS、Linux以及Windows(预览版)
- 量化支持:为了降低显存需求,Ollama支持4-bit量化,使得普通家用计算机也能运行大型模型。
2.LM Studio
LM Studio 是一款桌面应用程序,专为那些希望拥有图形用户界面(GUI)而非命令行界面(CLI)的用户提供服务。其关键特性包括:
- 一站式解决方案:LM Studio允许用户直接从Hugging Face等平台发现、下载并运行本地的LLMs,无需编程知识即可操作。
- 用户友好的界面:相比Ollama,LM Studio更加注重用户体验,提供了直观的图形界面,即使是非技术人员也能方便地与AI模型进行交互。
- 强大的功能集合:除了基本的模型运行外,LM Studio还支持同时运行多个AI模型,并利用“Playground”模式增强性能和输出。
- 高级功能支持:如分布式训练、超参数调整及模型优化等功能,使得LM Studio适合于更复杂的应用场景和技术要求较高的用户群体。
3.两个对比区别
如果你是一位初学者或者非技术背景的用户,寻找一个简单易用、带有可视化界面的工具来运行语言模型,那么LM Studio可能更适合你。而如果你偏好灵活性更高、可通过命令行自定义配置的开源框架,Ollama将是一个不错的选择。
三、硬件要求
1.最低硬件配置
CPU方案
- 处理器 (CPU): 四核八线程往上
- 内存 (RAM): 最低8GB(对于7B模型),推荐32GB+(流畅运行),内存不贵
- 存储: 至少256GB,推荐NVME固态存储,速度超快,读写1GB起步
- 操作系统: Windows 10+/Linux/macOS
在纯CPU环境下运行DeepSeek是可行的,但会显著降低生成文本的速度,并且对内存的需求更高,因为模型权重需要完全加载到内存中。
GPU方案(推荐)
- 图形处理单元 (GPU): NVIDIA GPU配备至少8GB显存;建议使用RTX 3090或更高性能的显卡来加速推理过程。
- 处理器 (CPU): 支持AVX指令集的任意CPU
- 内存 (RAM): 推荐16GB RAM(需共享显存时)
- 存储: 至少256GB,推荐NVME固态存储,速度超快,读写1GB起步
- 操作系统: Windows 10+/Linux/macOS
注意事项
- 如果您的硬件条件有限,可以考虑使用更小的模型版本,比如1.5B或8B的蒸馏版本,这些可以在较低配置的硬件上运行。
- 使用量化技术(如4-bit或8-bit量化)也可以减少内存占用,但这可能会牺牲一些模型性能。
- 对于不具备足够硬件资源的情况,还可以考虑通过DeepSeek API进行远程调用,或者利用云服务提供商提供的计算资源。
确保按照实际需求和预算选择合适的硬件配置,以获得最佳的性能和用户体验。
2.本人电脑配置(使用的是笔记本系统Win11)
| 组件 | 本人配置 | 推荐配置 (生产环境) |
|---|---|---|
| CPU | Intel i7-12700H(14核20线程) | Intel i9-13900HX / AMD Ryzen 9 7945HX |
| 内存 | DDR5 32GB(4800MHz) | DDR5 64GB(5600MHz) |
| 存储 | 2TB NVMe SSD(PCIe 4.0) | 4TB NVMe SSD RAID 0(7000MB/s+) |
| GPU | NVIDIA GeForce GTX 4070(8GB GDDR6X) | RTX 4080 16GB / RTX 4090 24GB |
3.📊适配模型清单(实测数据)
| 模型类型 | 推荐版本 | 量化方案 | 性能表现 | 使用场景 |
|---|---|---|---|---|
| Deepseek-7B | v2.1-int4 | 4-bit量化 | 12 tokens/sec | 本地代码生成/文档分析 |
| Deepseek-Math-3B | v1.9-fp16 | 半精度 | 18 tokens/sec | 数学推理/公式处理 |
| Deepseek-Coder-1.3B | v2.0-fp16 | 8-bit量化 | 28 tokens/sec | 实时代码补全 |
| Deepseek-Vision | Lite-4B | 混合精度 | 9 FPS(512x512图像) | 图文理解/OCR增强 |
四、软件环境搭建
1.Ollama安装包下载
官网 https://ollama.com/
百度网盘 https://pan.baidu.com/s/1rKAUm9fyfEOZtr2xvjzBow?pwd=3jvw
CSDNOllama安装包
ollama安装
直接安装就可以了,安装完成后电脑右下角有个猫的图标
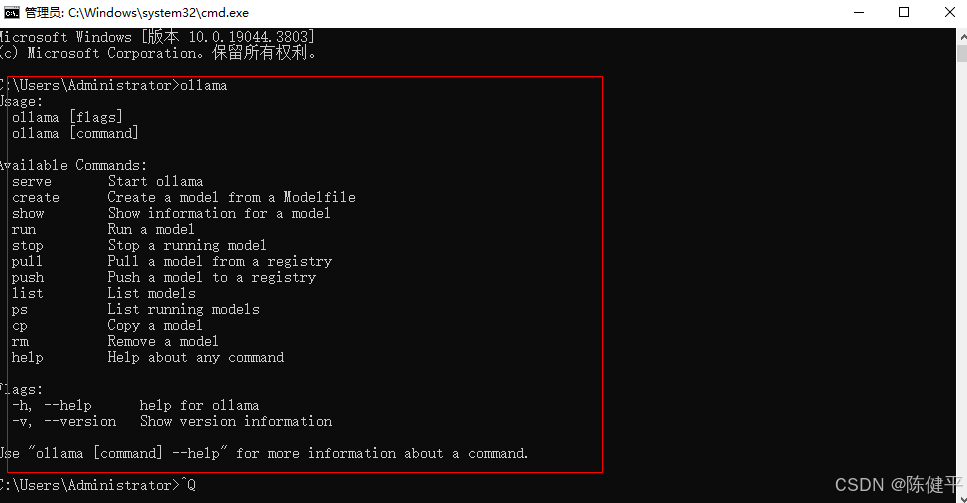
打开电脑终端输入ollama命令查看是否安装成功
2.LLMStudio安装包下载
LLMStudio官网https://lmstudio.ai/
百度网盘https://pan.baidu.com/s/1_mK1qUQmdE-cnjdPUxA9eQ?pwd=whtn
CSDNLLMStudio安装包

五、DeepSeek模型下载与部署(看重点,可直接跳转到这)
1.ollama模型的Deepseek
1.直接打开ollama官网
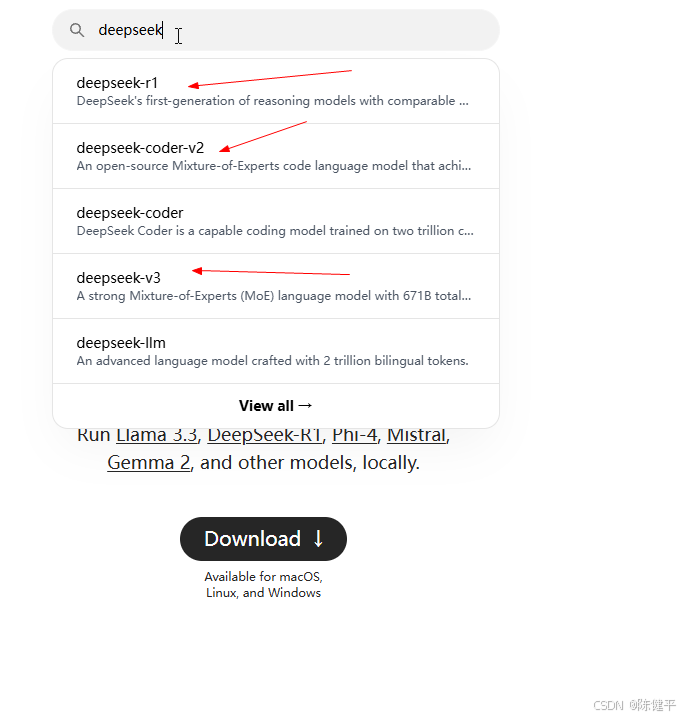
2.点击进入对应的模型
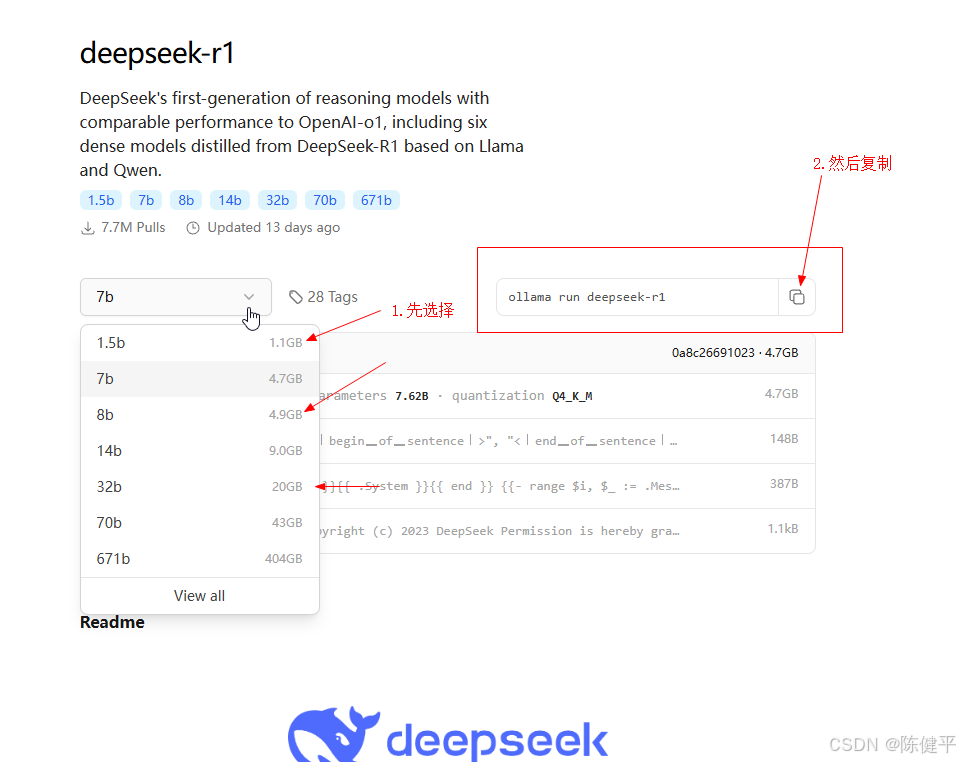
3.选择对应模型的大小,我本地选的是8B的,32B也下载了
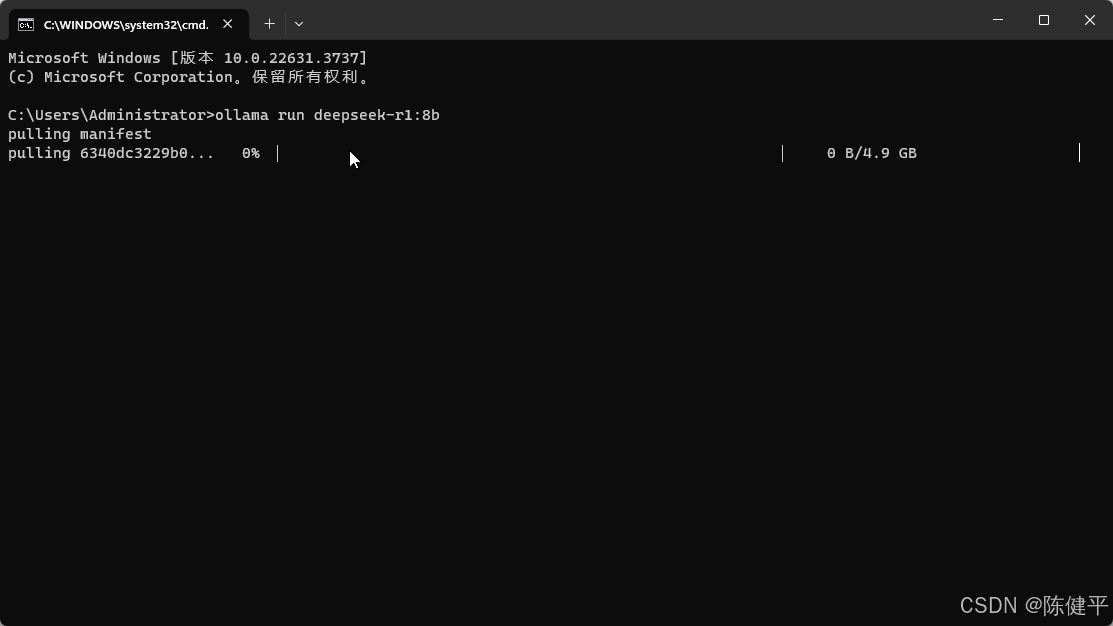
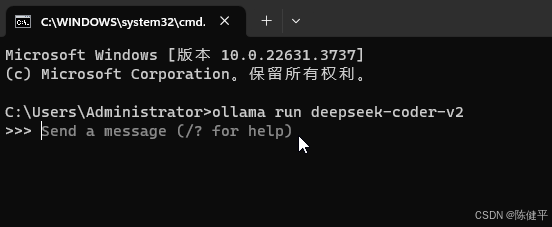
4.直接复制命令打开终端就可以进行下载了输入ollama run deepseek-r1:8b
5.可以直接对话

6.使用VSCode编辑器进行绑定使用DeepSeek模型(这里使用DeepSeek Code V2为例,离线代码提示大模型),首先进入插件库(ctrl+shift+x)搜索Continue进行下载
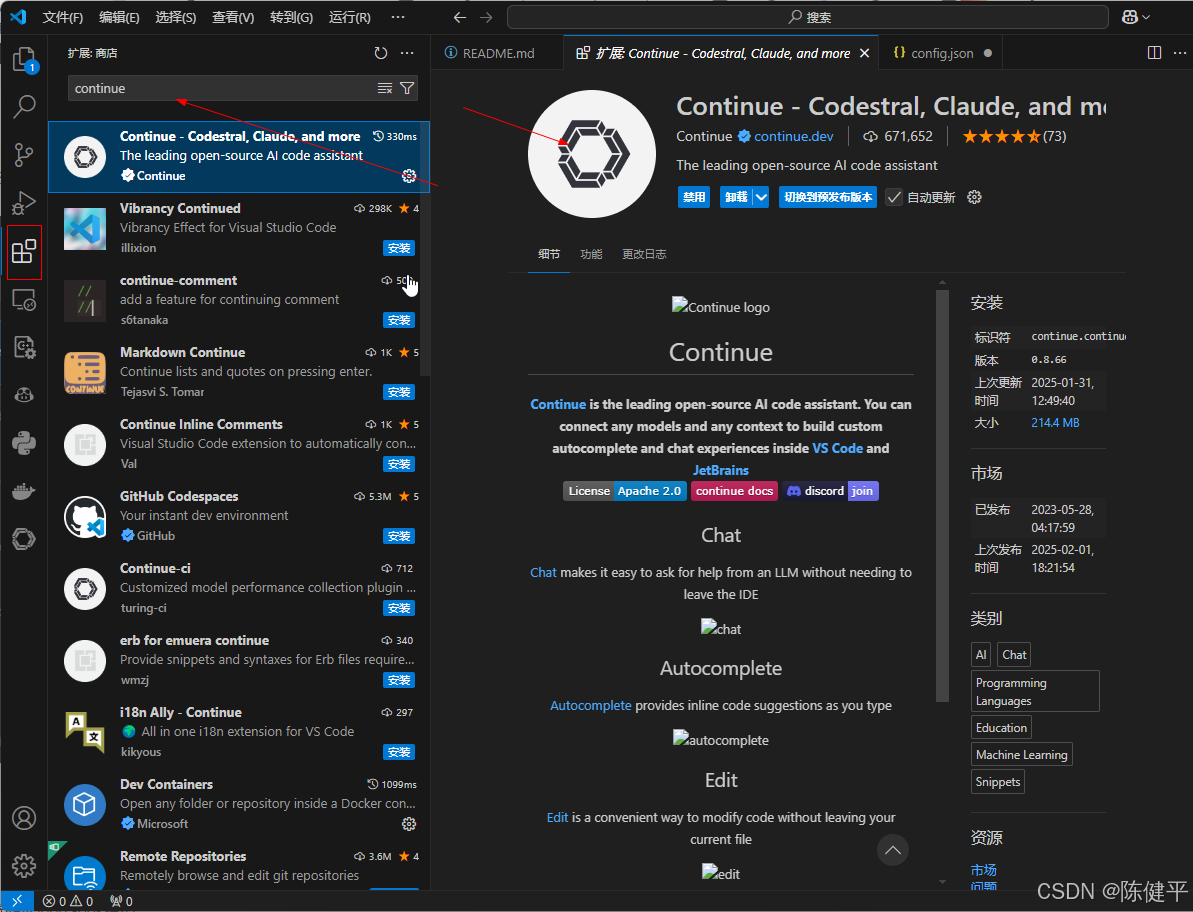
7.进行配置,点击Add ChatModel
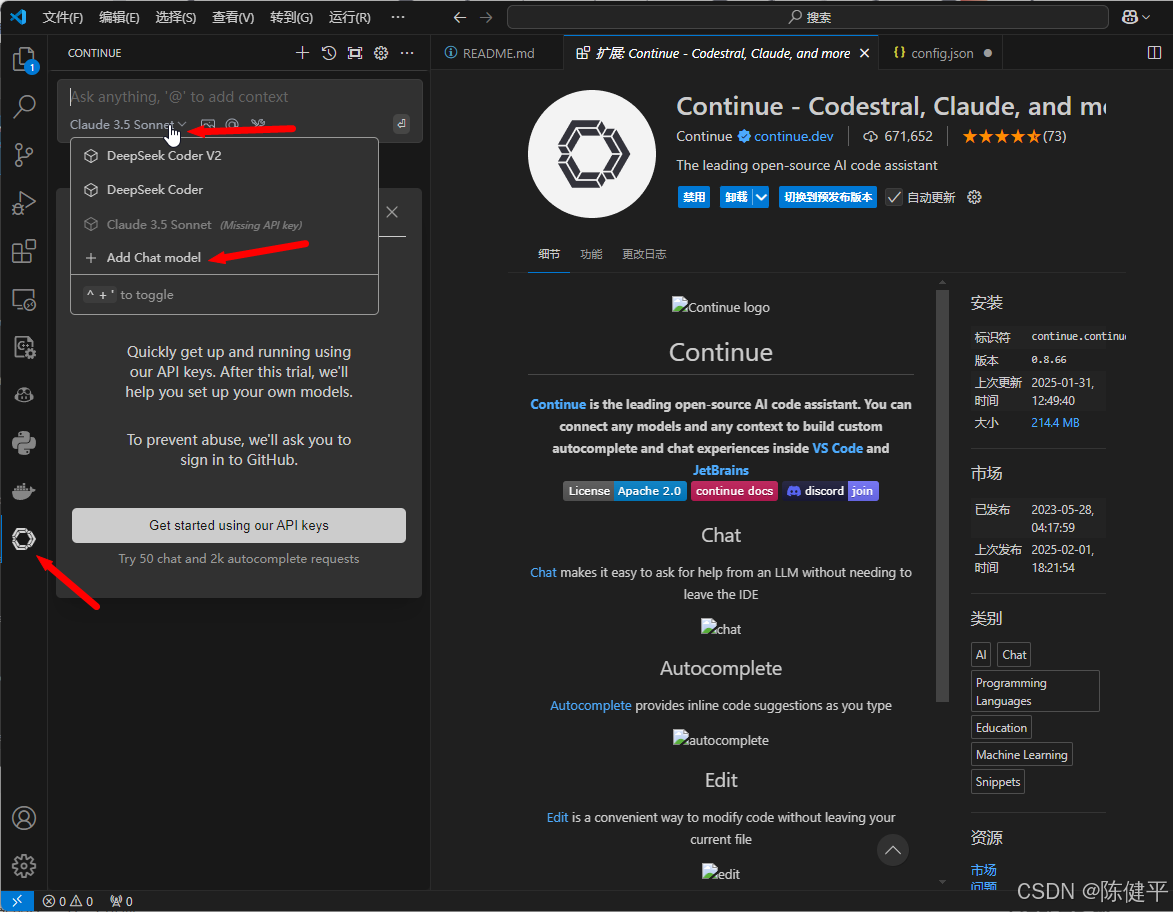
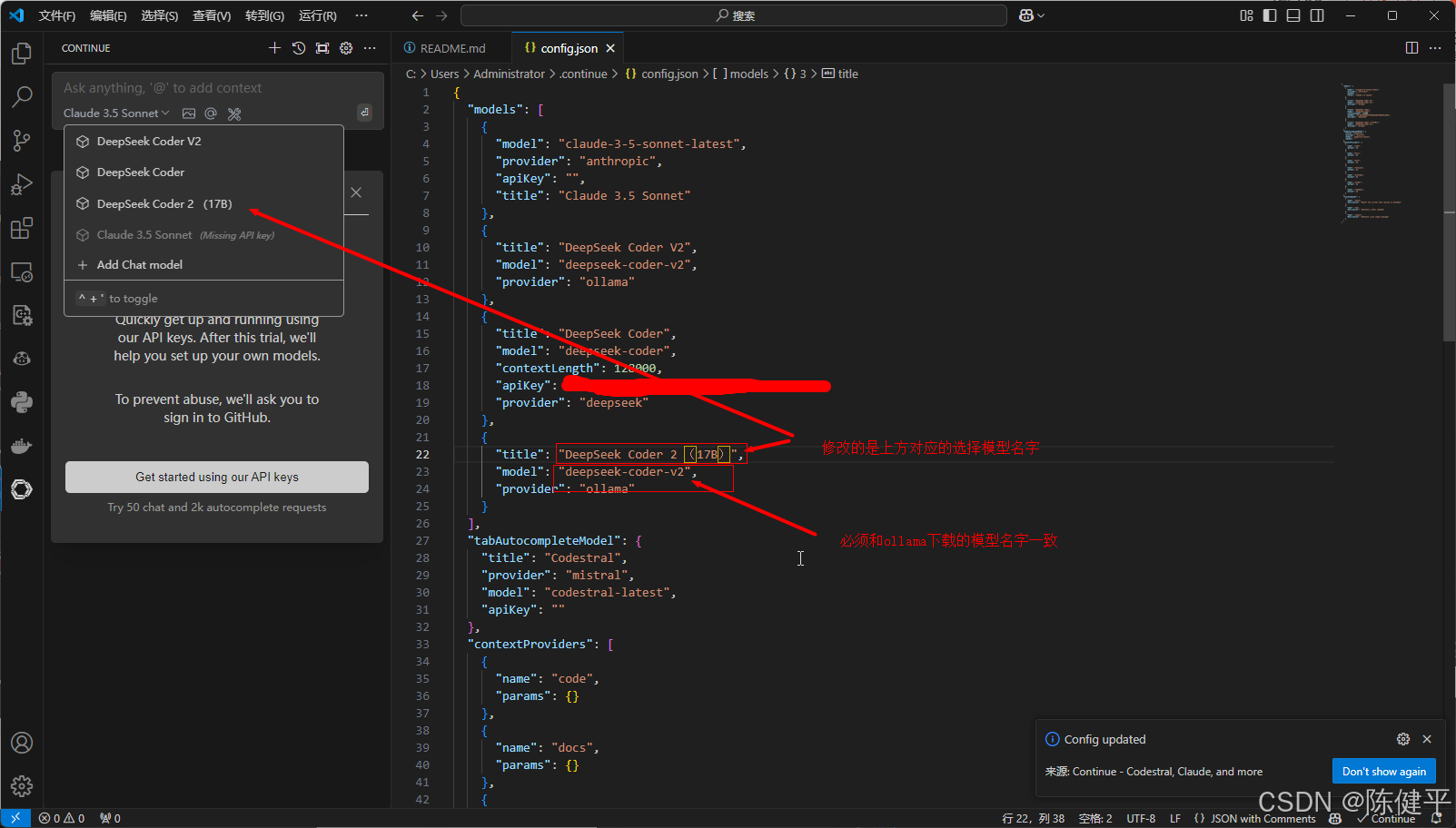
8.选择ollama,和对应的模型版本
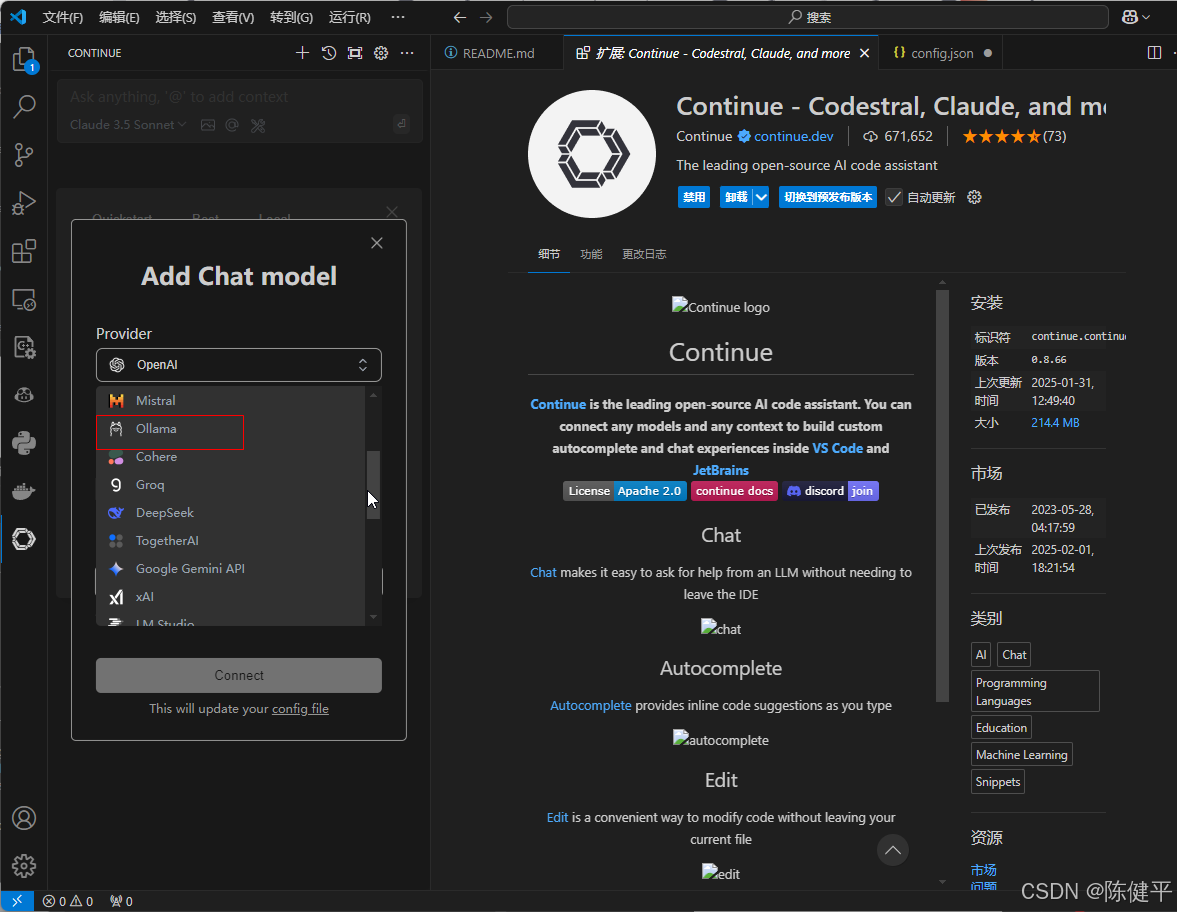
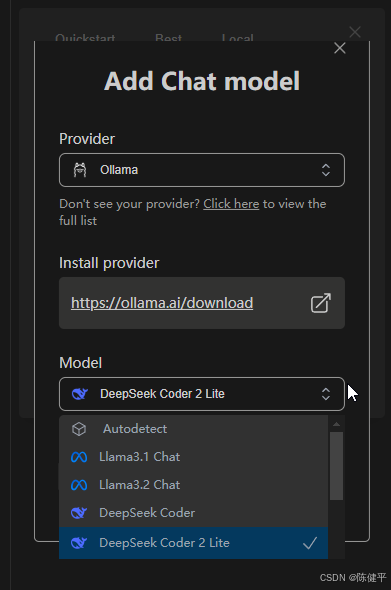
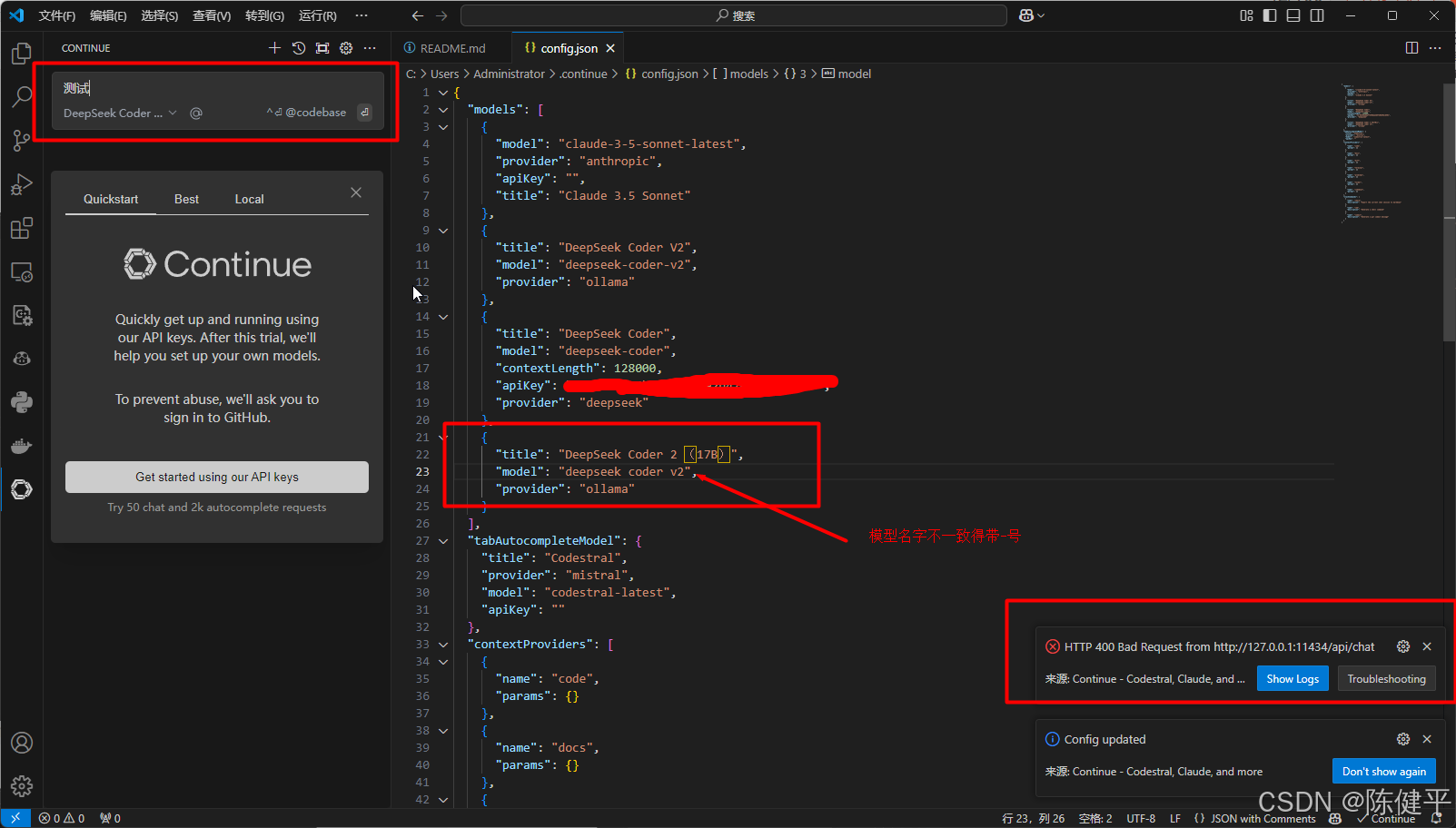
9.修改对应模型名字,得和ollama下载的模型名字一致才有用,这个config.json文件在第8步选完后会自动打开,或者点击右上角设置

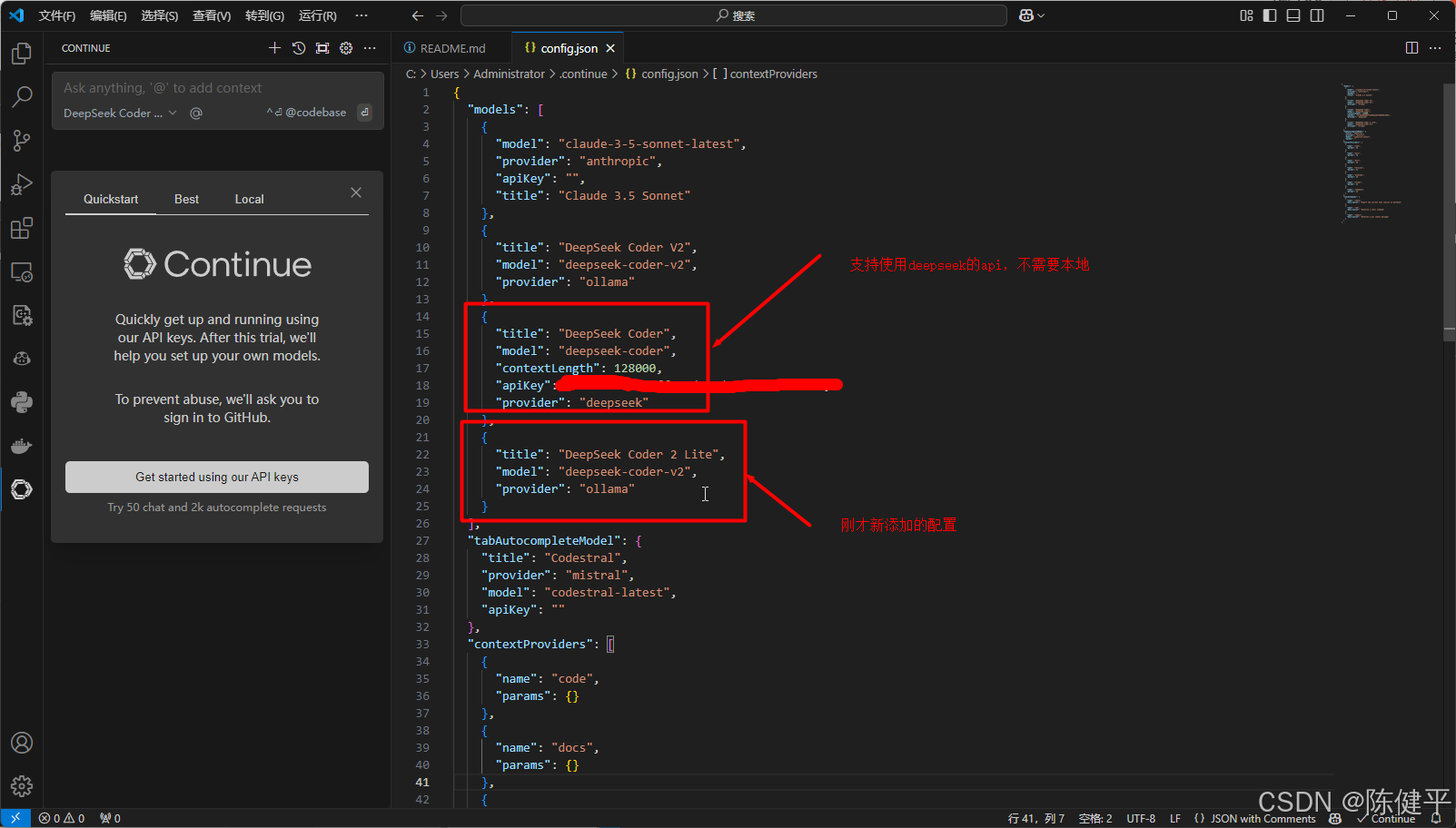
10.修改模型名字,我这是deepseek-coder-v2(16B),https://ollama.com/library/deepseek-coder-v2
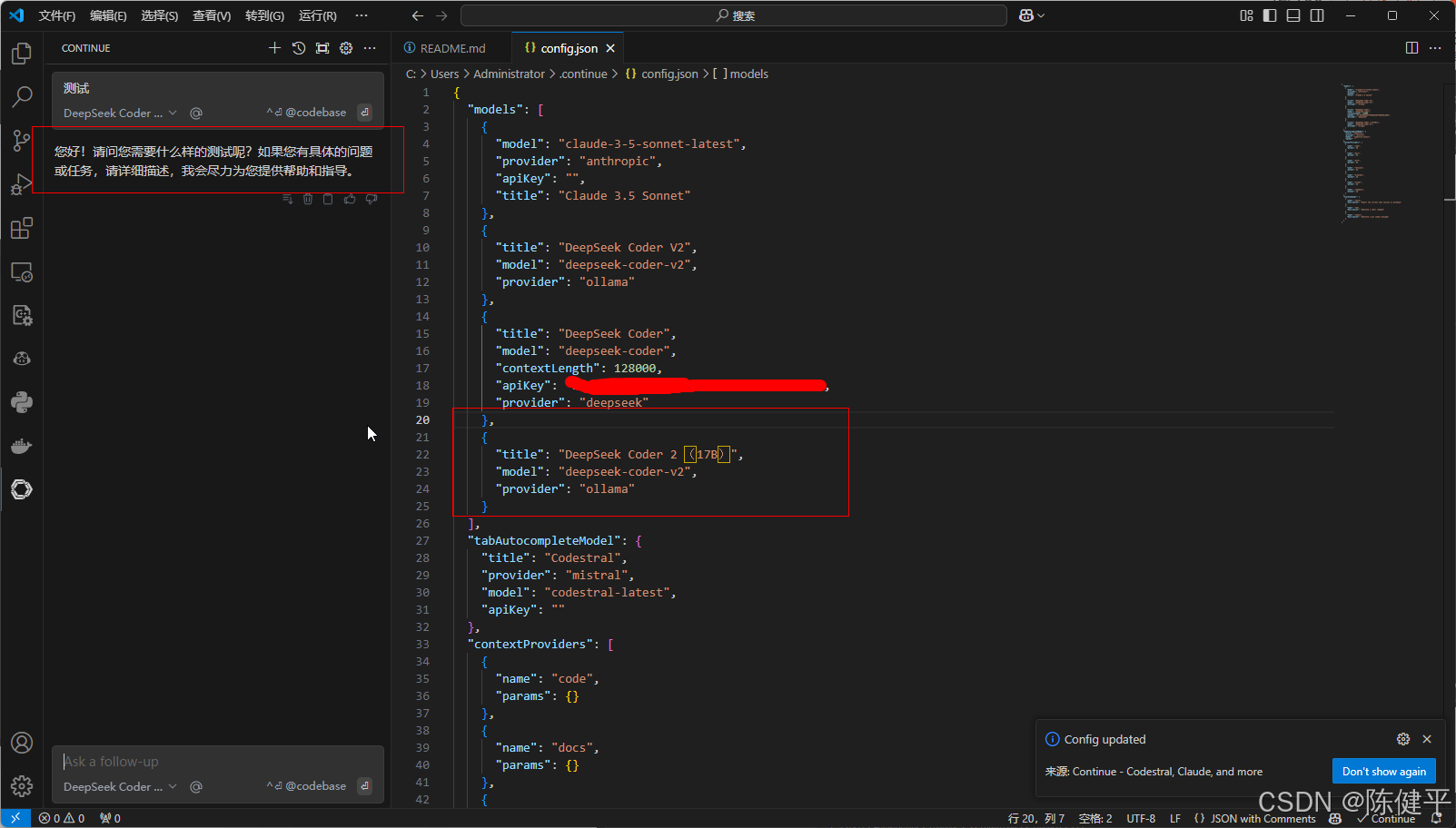
11.模型设置好了就可以进行对话了
12.对话创建一个贪吃蛇前端页面(这个是离线创建的,不需要网络)
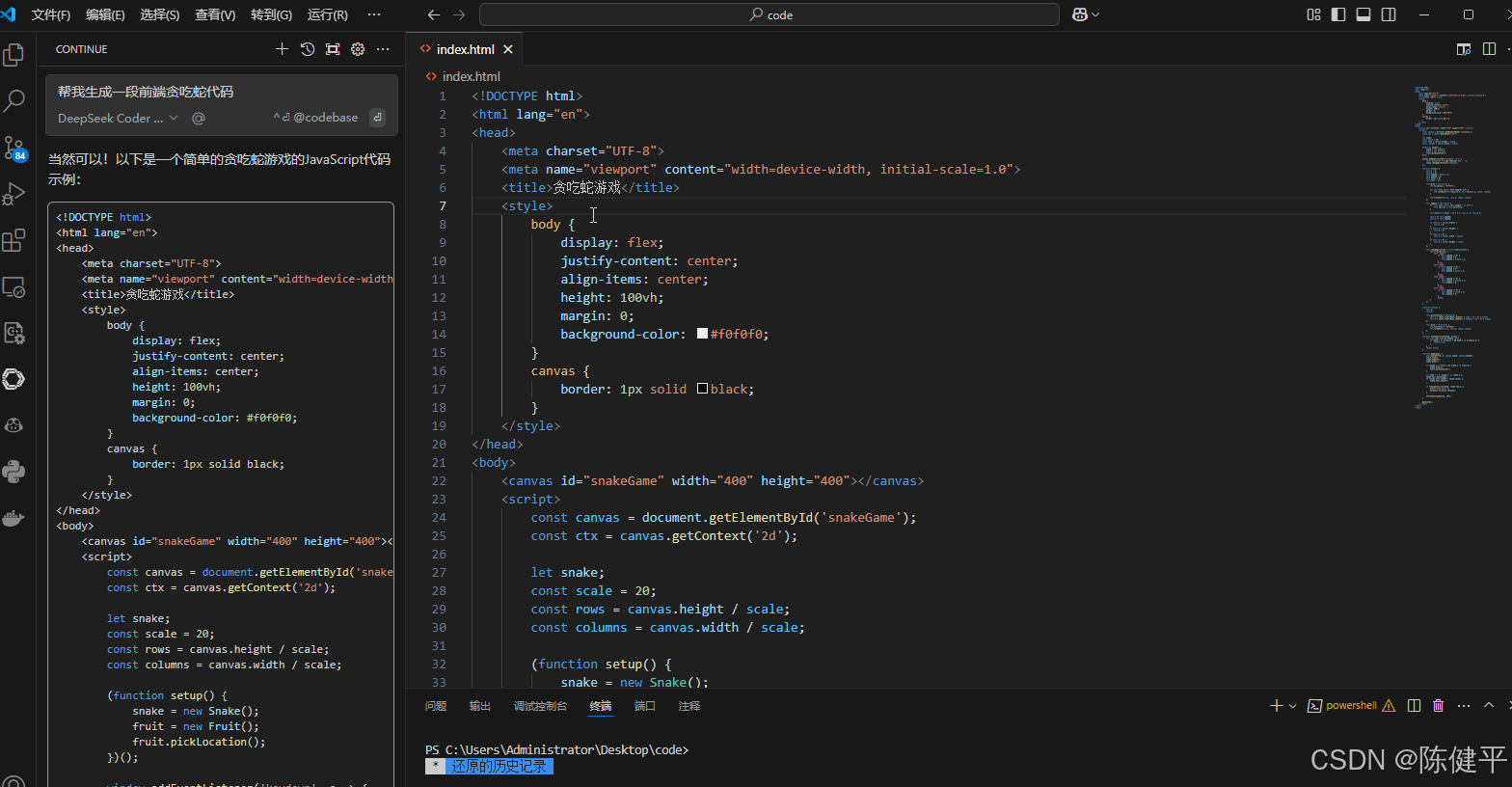
13.跑代码所占CPU和显卡的资源
13.页面展示

提示(对话连接失败)
如果模型名字不对是访问不到的,进行对话会报右下角提示的错误
2.LLMStudio模型的Deepseek
1.LLMStudio支持的模型格式为GGUF,所以需要去https://huggingface.co下载对应的DeepSeep模型版本
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF/tree/main
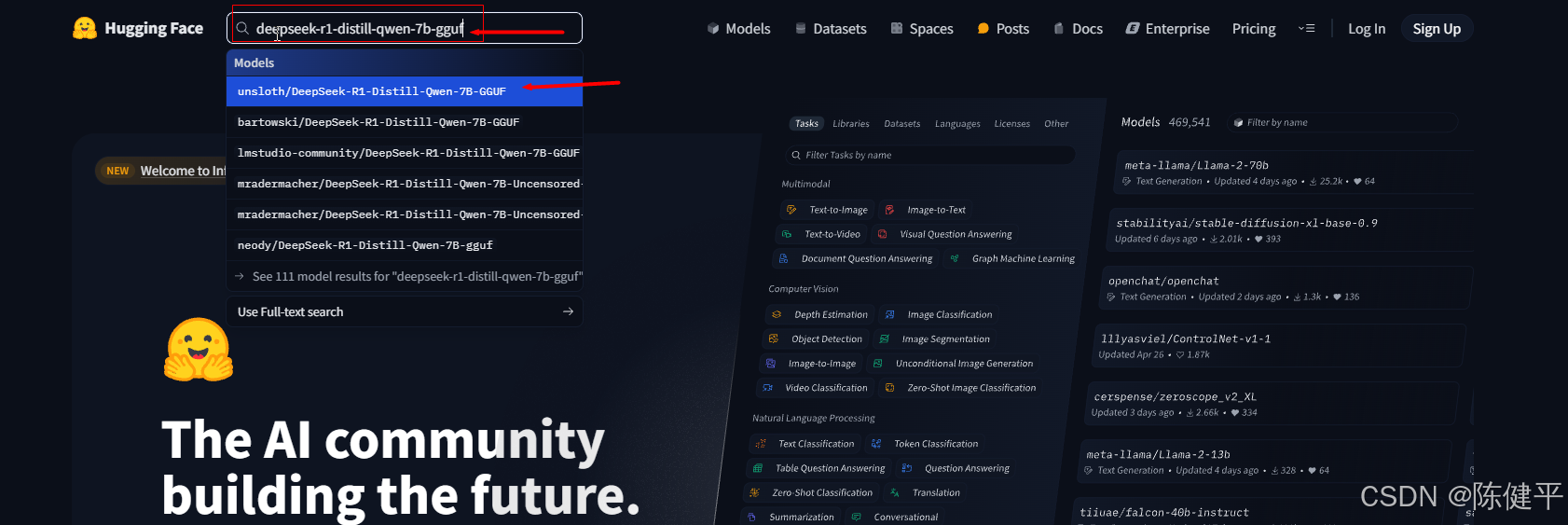
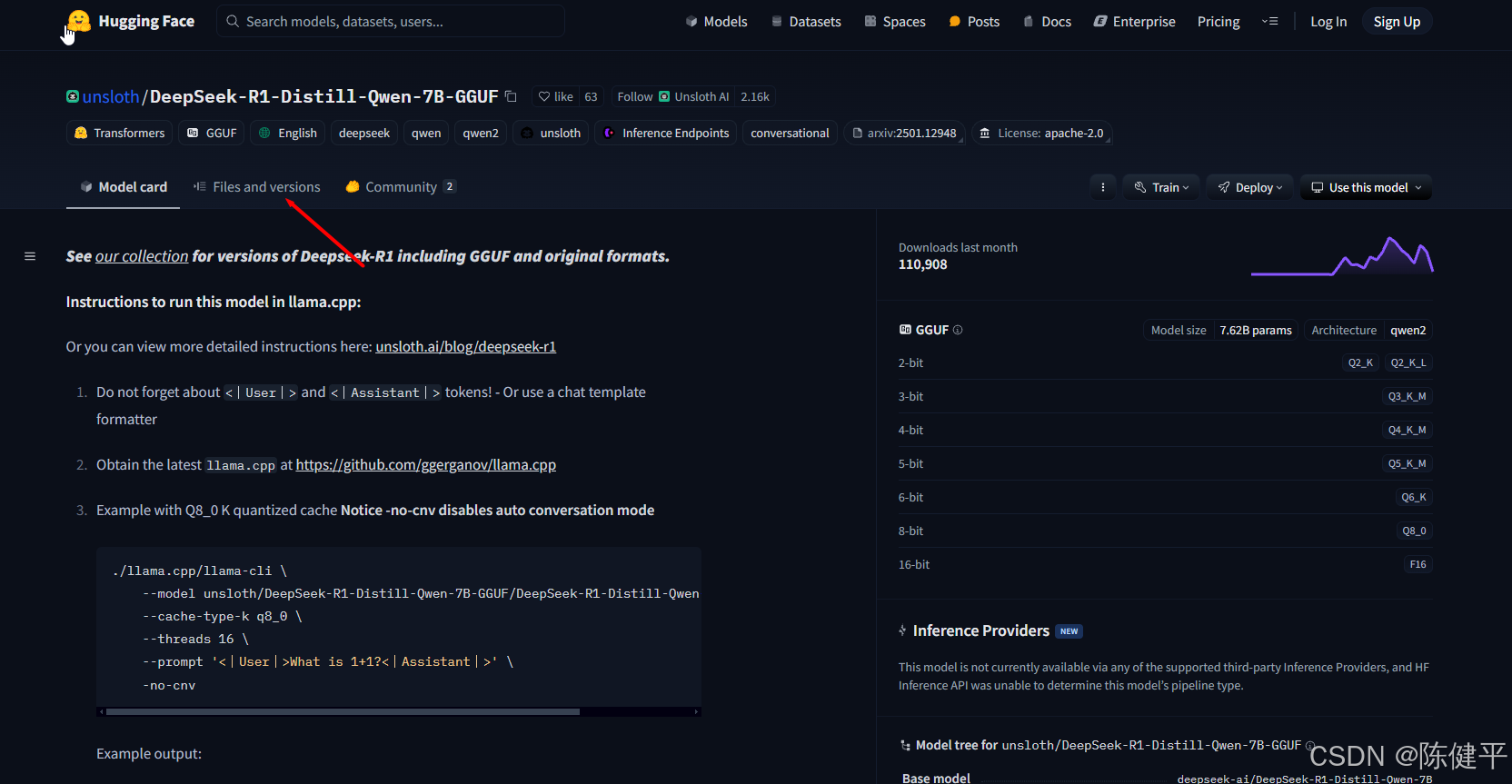
2.对应的版本介绍 文件名中包含了
Distill-Qwen(蒸馏版本,阉割版为了配置低的电脑也可以运行大模型)和不同的后缀,如F16、Q2、Q3等。这些后缀通常与模型的量化级别相关。具体解释如下:
文件名解析
- DeepSeek-R1-Distill-Qwen-7B-F16.gguf:这表示使用 FP16(半精度浮点数)量化的模型。
- DeepSeek-R1-Distill-Qwen-7B-Q2_K.gguf:这表示使用 Q2_K 量化的模型。
- DeepSeek-R1-Distill-Qwen-7B-Q3_K_M.gguf:这表示使用 Q3_K_M 量化的模型。
- DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf:这表示使用 Q4_K_M 量化的模型。
- DeepSeek-R1-Distill-Qwen-7B-Q5_K_M.gguf:这表示使用 Q5_K_M 量化的模型。
- DeepSeek-R1-Distill-Qwen-7B-Q6_K.gguf:这表示使用 Q6_K 量化的模型。
- DeepSeek-R1-Distill-Qwen-7B-Q8_0.gguf:这表示使用 Q8_0 量化的模型。
量化级别解释
- FP16 (F16):半精度浮点数,通常用于加速推理和训练,减少内存占用。
- Q2_K:2位量化,K 表示特定的量化方式。
- Q3_K_M:3位量化,M 表示混合量化。
- Q4_K_M:4位量化,M 表示混合量化。
- Q5_K_M:5位量化,M 表示混合量化。
- Q6_K:6位量化。
- Q8_0:8位量化,0 表示特定的量化方式。
gguf文件详细总结
这些文件名中的后缀表示了不同级别的量化处理,量化可以显著减少模型的大小和内存占用,同时在一定程度上保持模型的性能。具体的量化级别(如 Q2、Q3、Q4 等)决定了模型参数的比特数,从而影响模型的精度和运行速度。电脑配置低选Q2,Q3,Q4这种,配置好选最高的QN版本
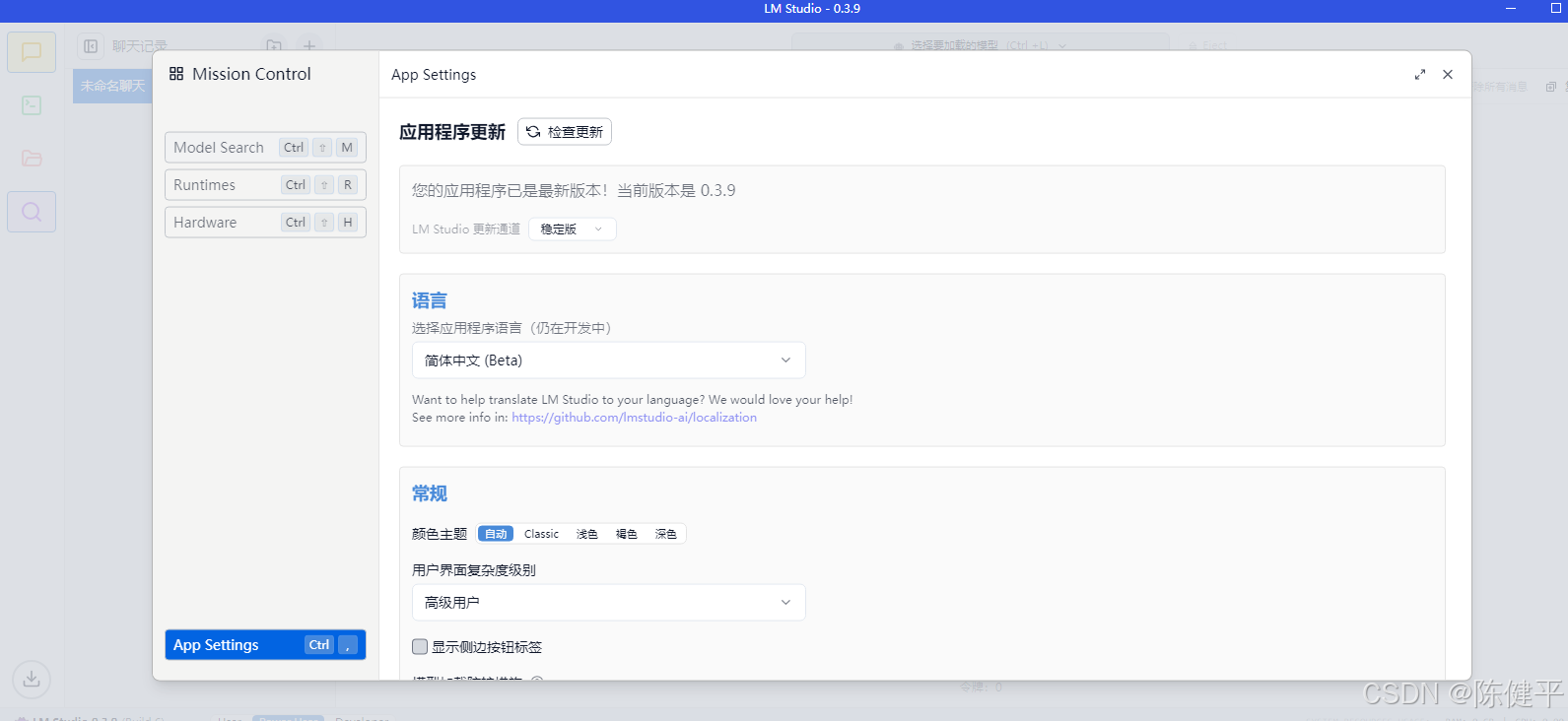
3.打开LLMStudio编辑器,设置中文

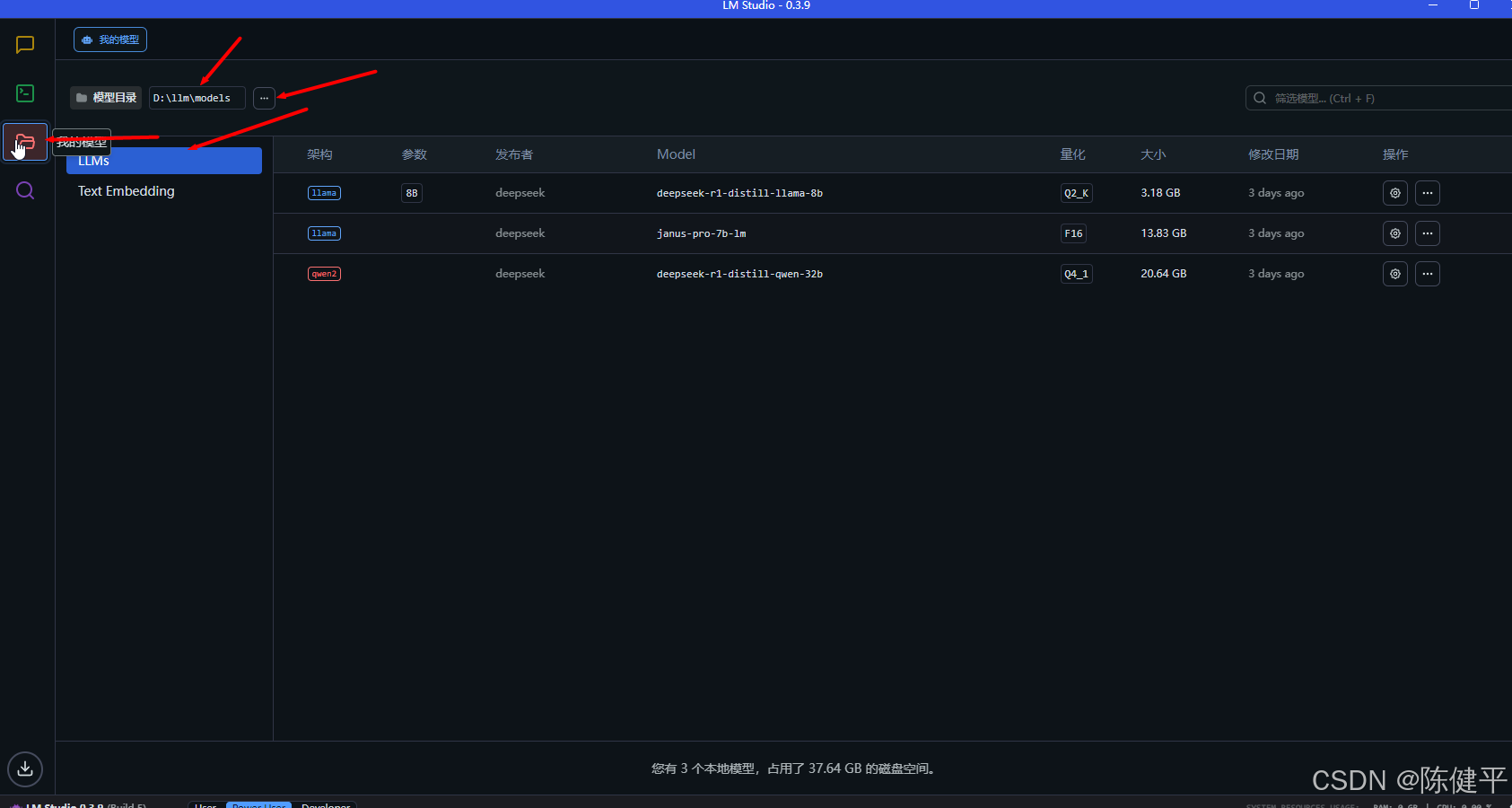
4.设置模型位置文件
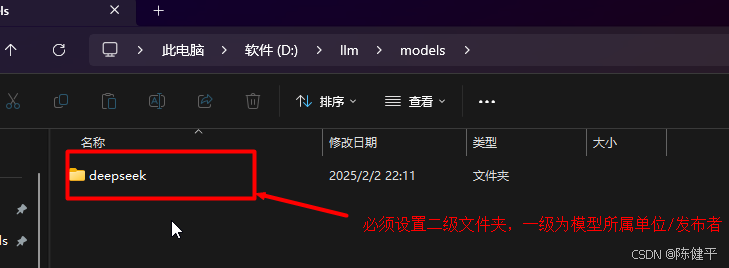
在models文件夹下必须设置二级文件夹如deepseek->deepseep-r1
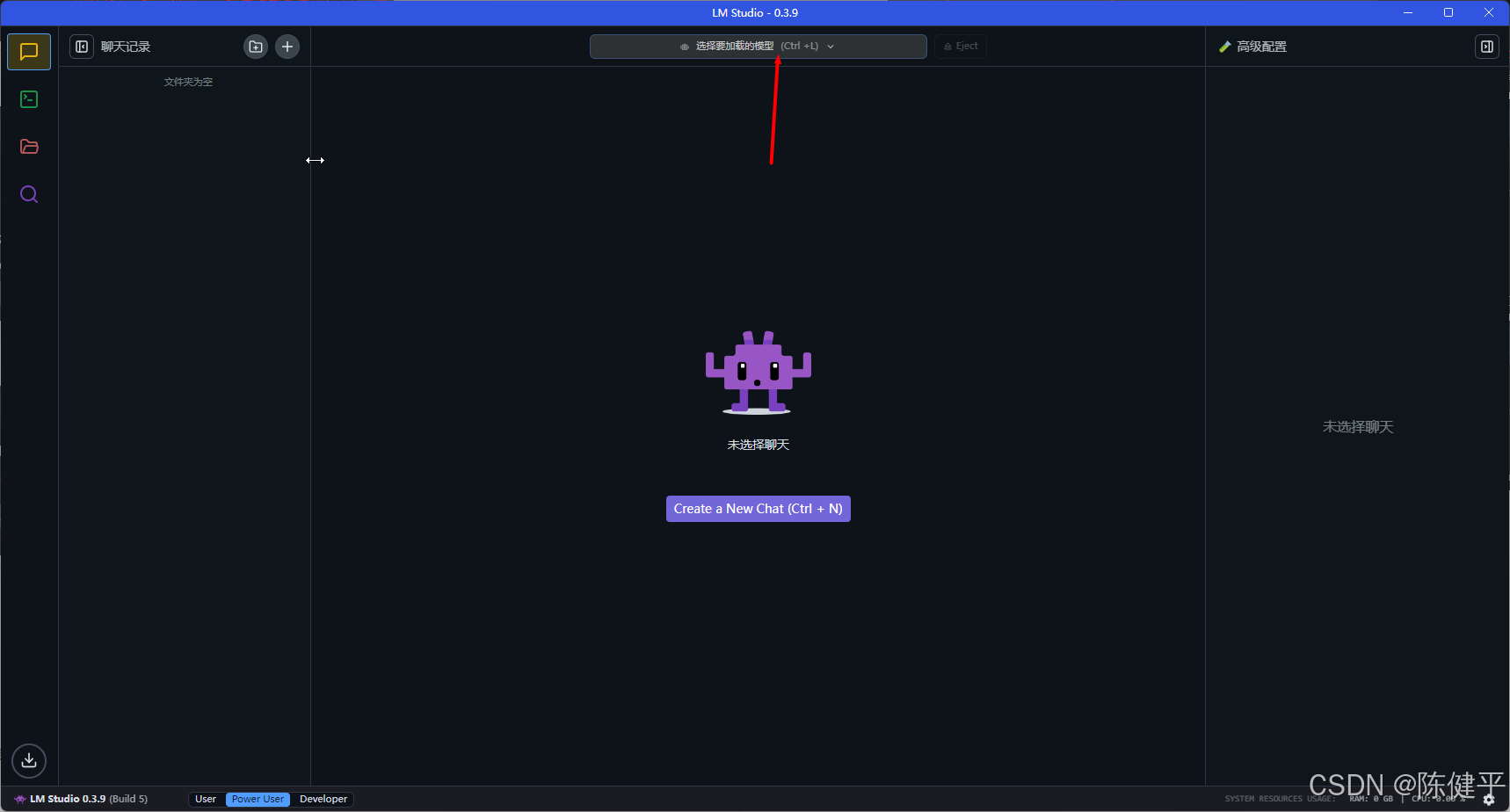
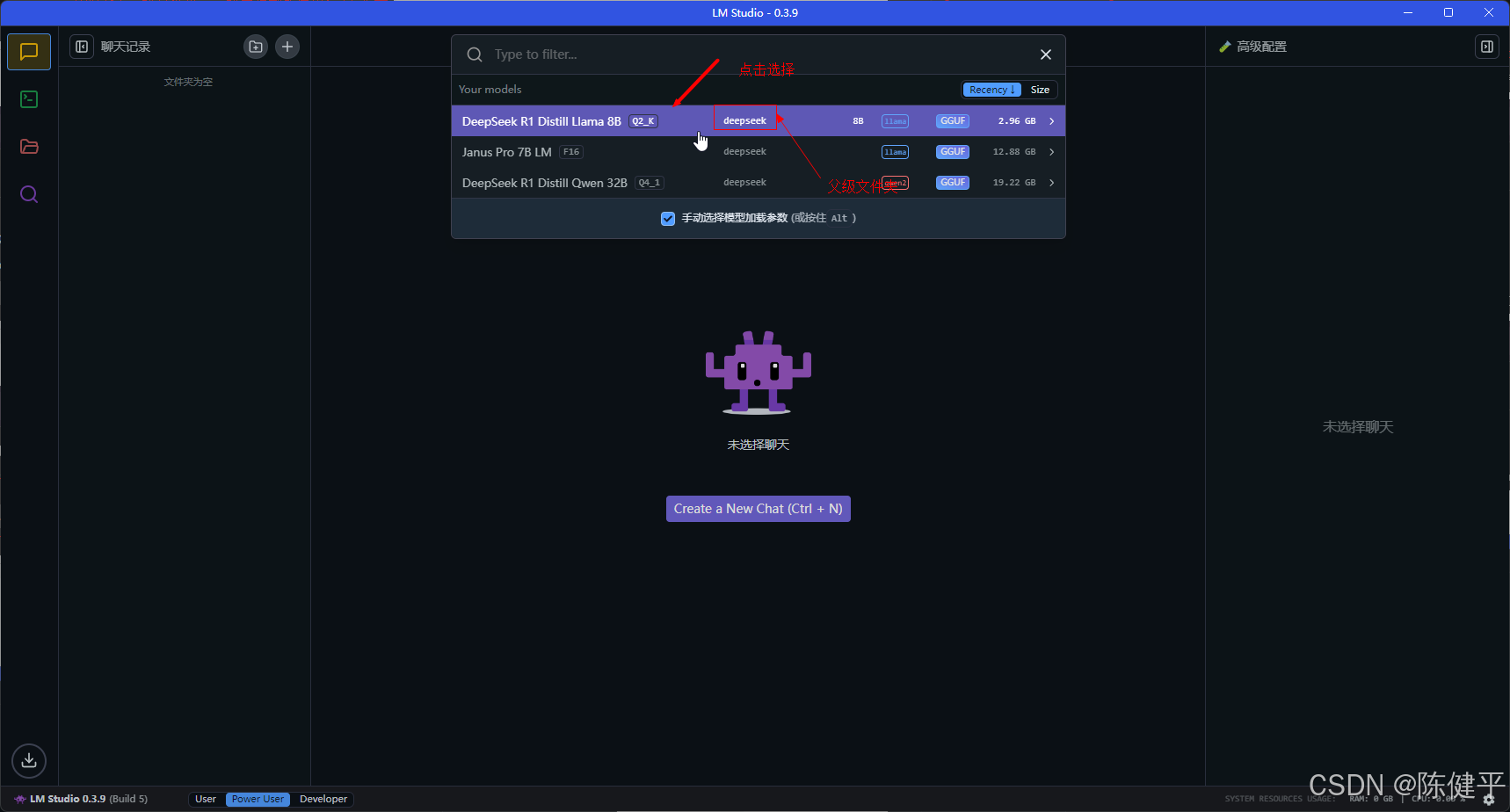
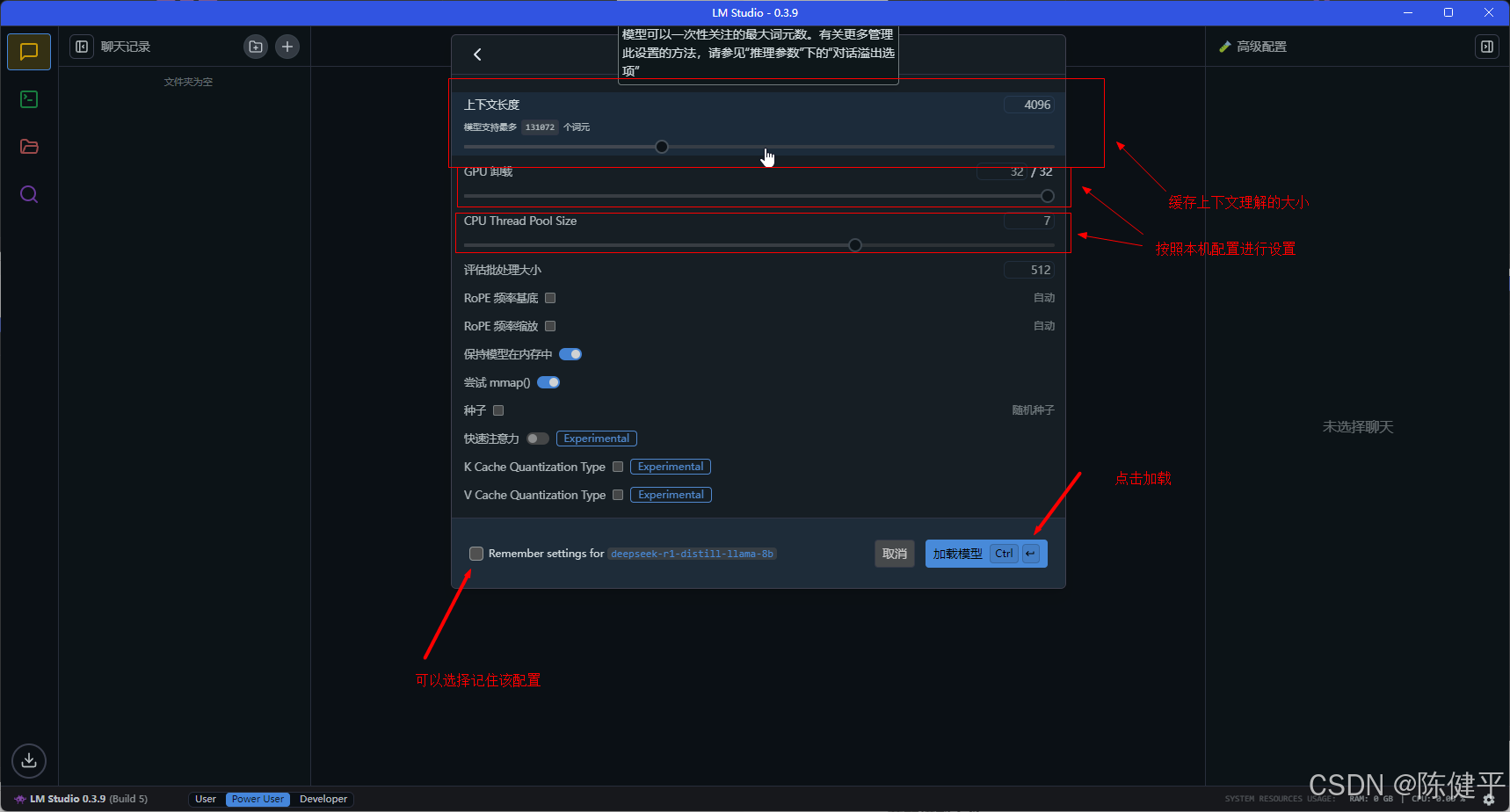
5.加载模型
6.使用模型对话
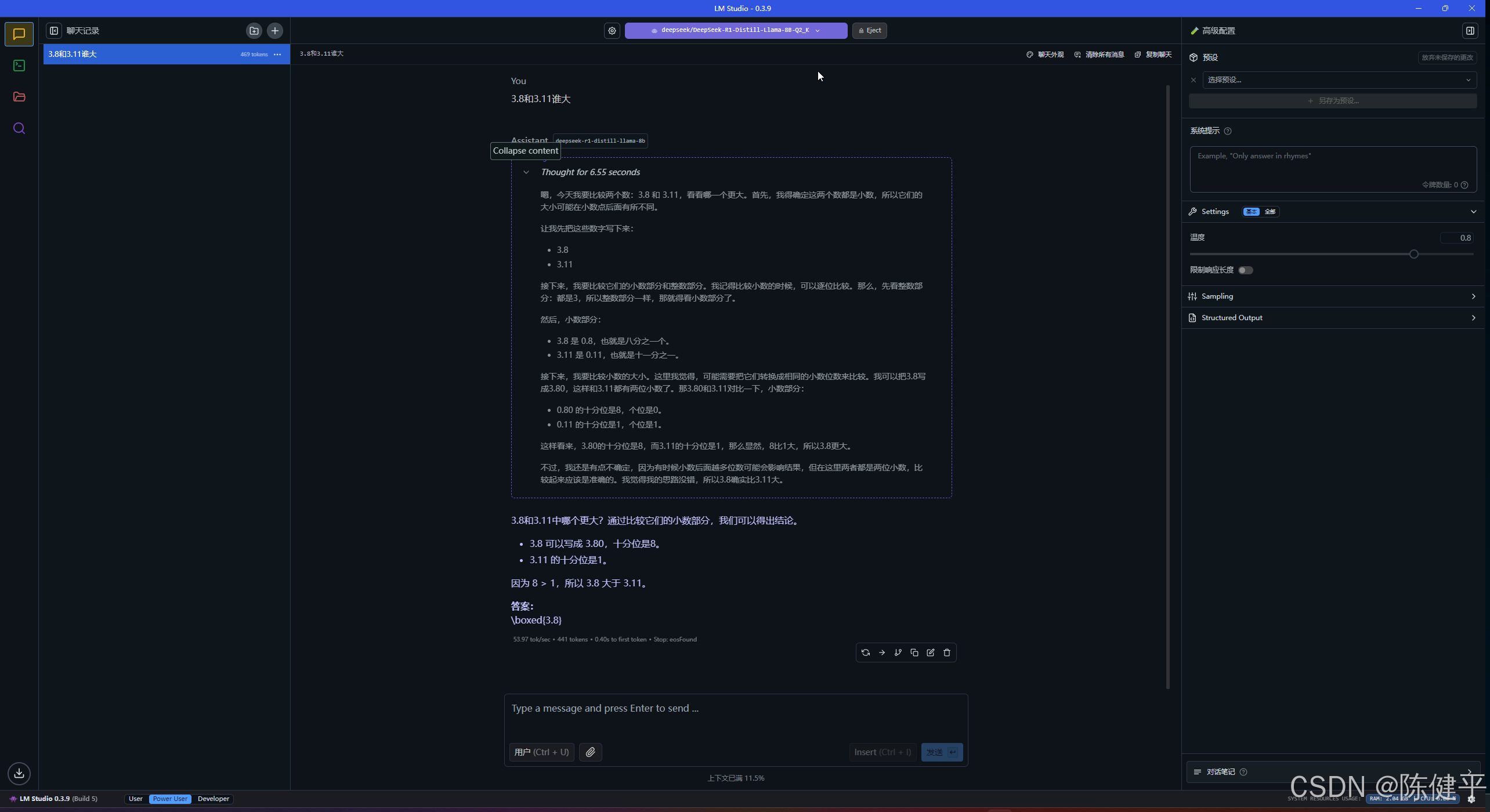
创建对话,AI智商经典对话3.8和3.11谁大,6秒生成
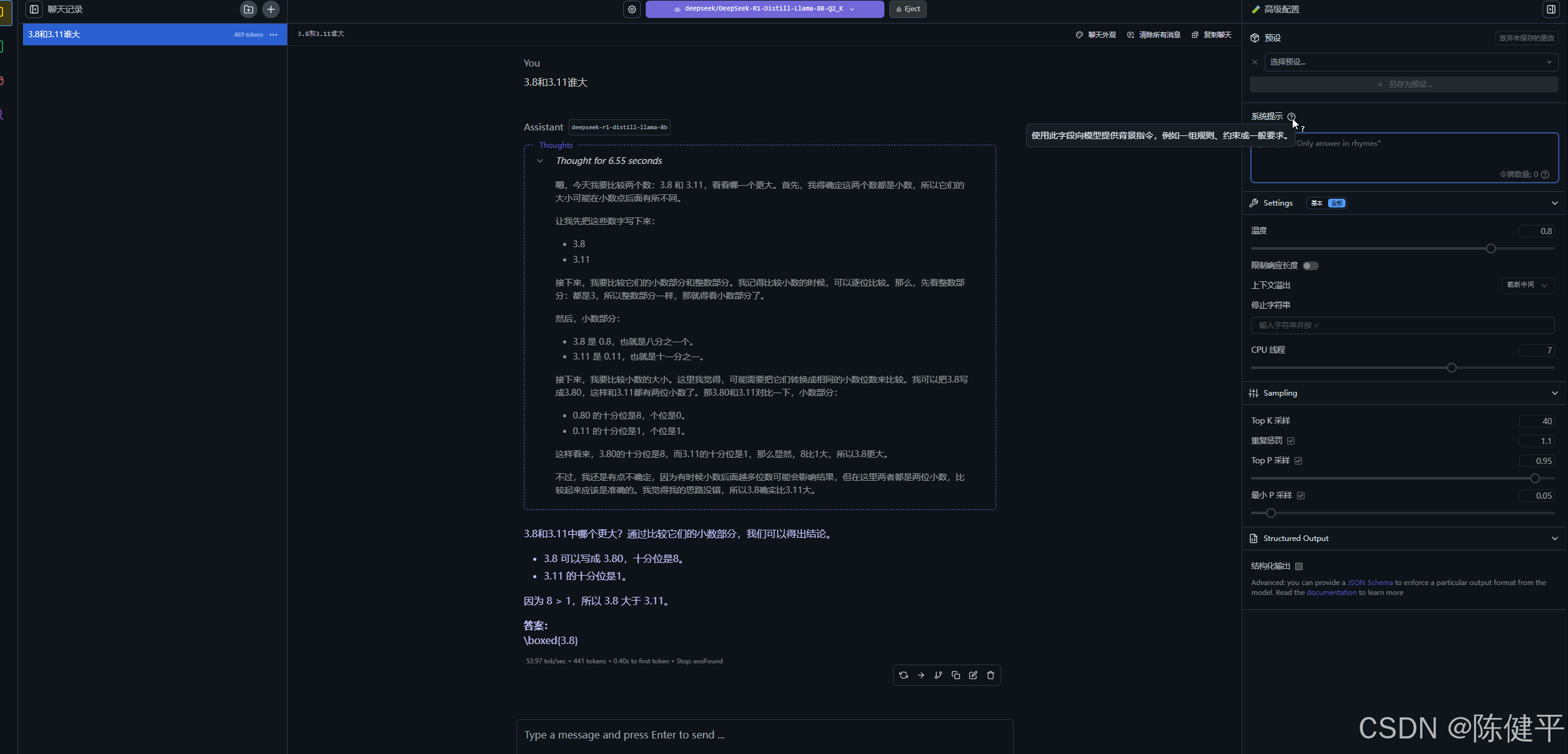
右侧可以设置AI的角色和回答问题的强度,按照自己需求进行设置
总结
模型下载链接
通过网盘分享的文件:DeepSeek-R1-Distill-Llama-8B-Q2_K.gguf
链接: https://pan.baidu.com/s/1rJkaKY_d7IpDZzBIgKOlYQ?pwd=rseb
通过网盘分享的文件:DeepSeek-R1-Distill-Qwen-32B-Q4_1.gguf
链接: https://pan.baidu.com/s/1yleGkkDTnJxAnKJuzoVAQQ?pwd=2z8d
🔔 CSDN专栏:AI人工智能实战专栏
🔔 如果本文对您有帮助,请点击下方⭐️Star支持!
🔔 关注博主,获取更多AI实战教程!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 39
39 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)