【GitHub项目推荐--Easy Dataset:LLM微调数据集创建的强大工具】
是一个专门为大型语言模型(LLM)创建微调数据集的强大工具。它提供了一个直观的界面,用于上传领域特定文件、智能分割内容、生成问题,并生成高质量的模型微调训练数据。🔗 GitHub地址🚀 核心价值:LLM微调 · 数据集创建 · 智能处理 · 多格式支持 · 开源免费项目背景:微调需求:解决LLM微调数据集创建困难的问题自动化处理:自动化数据集创建流程多格式支持:支持

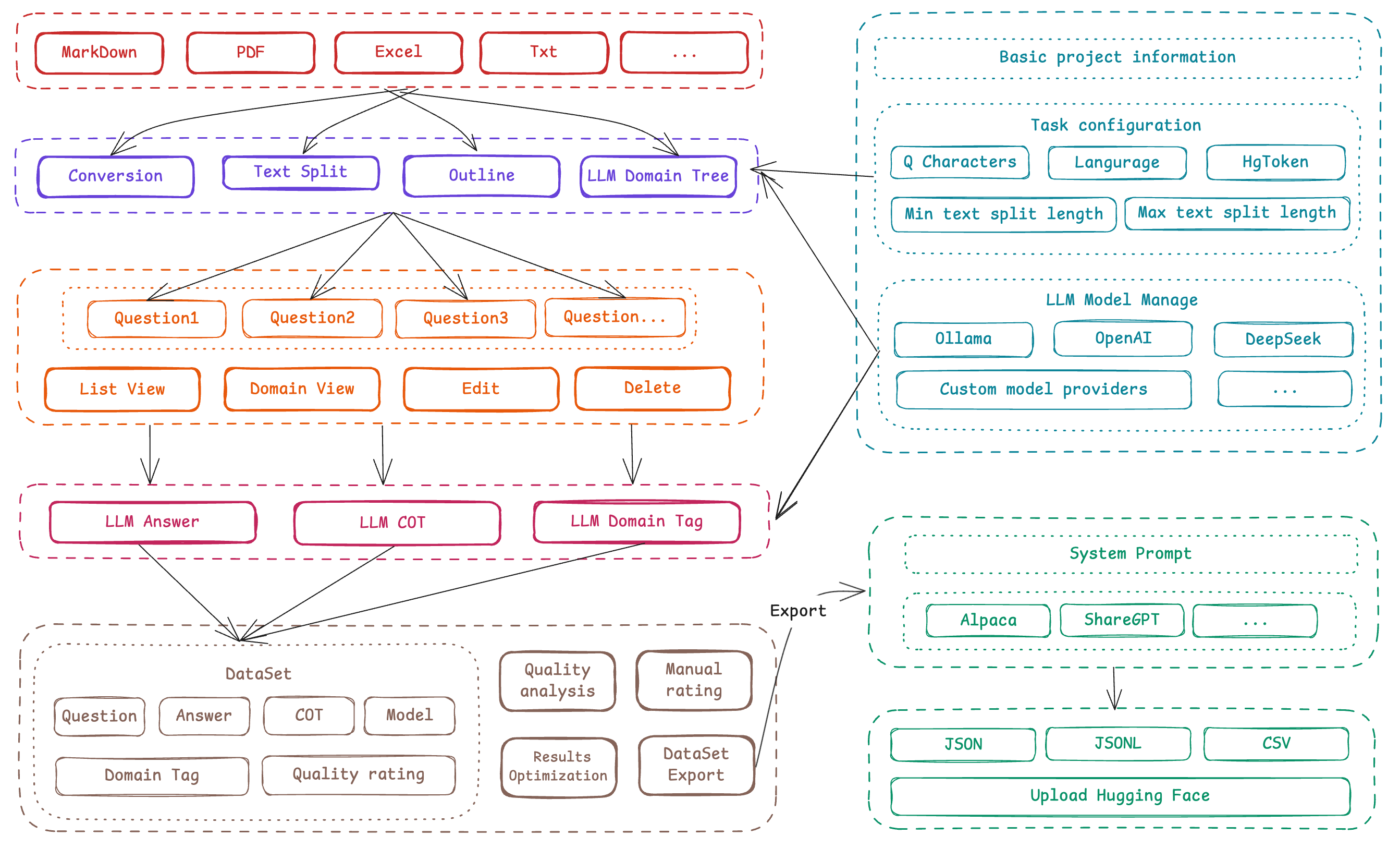
简介
Easy Dataset 是一个专门为大型语言模型(LLM)创建微调数据集的强大工具。它提供了一个直观的界面,用于上传领域特定文件、智能分割内容、生成问题,并生成高质量的模型微调训练数据。
🔗 GitHub地址:
https://github.com/ConardLi/easy-dataset
🚀 核心价值:
LLM微调 · 数据集创建 · 智能处理 · 多格式支持 · 开源免费
项目背景:
-
微调需求:解决LLM微调数据集创建困难的问题
-
自动化处理:自动化数据集创建流程
-
多格式支持:支持多种文档格式处理
-
智能生成:智能问题生成和答案生成
-
开源生态:开源社区驱动的工具生态
项目特色:
-
📚 文档处理:智能处理多种文档格式
-
❓ 问题生成:自动生成相关问题
-
🏷️ 标签管理:智能领域标签构建
-
📊 数据集构建:高质量数据集构建
-
🆓 完全开源:代码完全开源免费
技术亮点:
-
智能分割:智能文本分割算法
-
LLM集成:集成多种LLM API
-
可视化编辑:可视化编辑界面
-
多格式导出:多种导出格式支持
-
扩展架构:模块化扩展架构
主要功能
1. 核心功能体系
Easy Dataset提供了一套完整的LLM微调数据集创建解决方案,涵盖文档处理、文本分割、问题生成、答案生成、数据集构建等多个方面。
文档处理功能:
格式支持:
- PDF文档: PDF文件解析和处理
- Markdown: Markdown格式支持
- Word文档: DOCX文件处理
- 文本文件: 纯文本文件处理
- 其他格式: 多种文档格式支持
文档解析:
- 内容提取: 文档内容智能提取
- 结构分析: 文档结构分析
- 元数据提取: 文档元数据提取
- 格式转换: 格式转换处理
- 质量检查: 文档质量检查
批量处理:
- 批量上传: 多文件批量上传
- 并行处理: 并行文档处理
- 进度跟踪: 处理进度跟踪
- 错误处理: 错误处理和恢复
- 结果验证: 处理结果验证文本分割功能:
分割算法:
- 智能分割: 智能文本分割算法
- 语义分割: 基于语义的分割
- 结构分割: 基于结构的分割
- 自定义分割: 自定义分割规则
- 多算法支持: 多种分割算法
分割控制:
- 粒度控制: 分割粒度控制
- 重叠设置: 段落重叠设置
- 边界检测: 语义边界检测
- 质量优化: 分割质量优化
- 可视化调整: 可视化分割调整
分割管理:
- 分割预览: 分割结果预览
- 手动调整: 手动分割调整
- 批量处理: 批量分割处理
- 版本管理: 分割版本管理
- 导出功能: 分割结果导出问题生成功能:
生成方式:
- 自动生成: 自动问题生成
- 语义相关: 语义相关问题
- 上下文感知: 上下文感知生成
- 多样性控制: 问题多样性控制
- 质量保证: 生成质量保证
问题类型:
- 事实性问题: 事实性信息问题
- 理解性问题: 理解性问题
- 推理问题: 推理性问题
- 应用问题: 应用性问题
- 创造性问题: 创造性问题
问题管理:
- 问题编辑: 问题编辑和优化
- 问题筛选: 问题筛选和过滤
- 问题组织: 问题组织管理
- 质量控制: 问题质量控制
- 批量处理: 批量问题处理答案生成功能:
生成集成:
- LLM API: 集成LLM API生成
- 多模型支持: 支持多种LLM
- 参数配置: 生成参数配置
- 质量优化: 生成质量优化
- 成本控制: 生成成本控制
答案类型:
- 直接答案: 直接回答问题
- 推理过程: 包含推理过程
- 详细解释: 详细解释答案
- 多角度回答: 多角度回答
- 创造性回答: 创造性回答
答案管理:
- 答案编辑: 答案编辑优化
- 质量评估: 答案质量评估
- 一致性检查: 答案一致性
- 批量生成: 批量答案生成
- 版本控制: 答案版本管理数据集构建功能:
数据结构:
- 样本组织: 数据样本组织
- 格式标准: 标准数据格式
- 元数据: 丰富元数据
- 质量标签: 质量标签标注
- 统计信息: 数据集统计信息
质量控制:
- 质量检查: 数据质量检查
- 一致性验证: 一致性验证
- 完整性检查: 完整性检查
- 多样性评估: 多样性评估
- 偏差检测: 偏差检测和纠正
版本管理:
- 版本控制: 数据集版本控制
- 变更跟踪: 变更历史跟踪
- 回溯能力: 数据回溯能力
- 比较功能: 版本比较功能
- 导出管理: 导出版本管理2. 高级功能
标签管理系统:
标签生成:
- 自动生成: 自动标签生成
- 语义分析: 语义分析标签
- 层次结构: 层次标签结构
- 领域特定: 领域特定标签
- 自定义标签: 自定义标签支持
标签管理:
- 标签编辑: 标签编辑管理
- 标签组织: 标签组织整理
- 标签搜索: 标签搜索功能
- 标签过滤: 标签过滤筛选
- 标签统计: 标签统计分析
标签应用:
- 数据标注: 数据样本标注
- 检索支持: 基于标签检索
- 组织管理: 数据组织管理
- 分析支持: 数据分析支持
- 导出支持: 标签导出功能导出功能:
导出格式:
- Alpaca格式: Alpaca兼容格式
- ShareGPT格式: ShareGPT格式
- JSON格式: 标准JSON格式
- JSONL格式: JSON行格式
- 自定义格式: 自定义格式支持
导出配置:
- 内容选择: 导出内容选择
- 格式设置: 输出格式设置
- 质量过滤: 质量过滤设置
- 批量导出: 批量导出支持
- 进度跟踪: 导出进度跟踪
导出优化:
- 压缩支持: 数据压缩支持
- 分块导出: 大数据分块导出
- 元数据包含: 元数据包含选项
- 质量报告: 导出质量报告
- 验证信息: 导出验证信息API集成功能:
API支持:
- OpenAI格式: OpenAI兼容API
- 多模型支持: 多种LLM支持
- 自定义API: 自定义API集成
- 本地模型: 本地模型支持
- 参数配置: API参数配置
集成管理:
- 连接管理: API连接管理
- 密钥管理: API密钥管理
- 用量监控: API用量监控
- 成本控制: 使用成本控制
- 性能优化: 集成性能优化
高级功能:
- 批量调用: 批量API调用
- 异步处理: 异步处理支持
- 错误重试: 错误重试机制
- 缓存策略: 智能缓存策略
- 回退机制: 故障回退机制安装与配置
1. 环境准备
系统要求:
硬件要求:
- 内存: 8GB+ RAM (推荐16GB)
- 存储: 10GB+ 可用空间
- CPU: 多核处理器
- 网络: 稳定网络连接
软件要求:
- 操作系统: Windows, macOS, Linux
- Node.js: 18+ 版本
- npm: 最新版本
- Docker: 容器支持(可选)
- 数据库: SQLite(内置)
API要求:
- LLM API: OpenAI兼容API访问
- 网络访问: 外部API访问权限2. 安装步骤
NPM安装:
# 克隆仓库
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
# 安装依赖
npm install
# 构建项目
npm run build
# 启动服务
npm run start
# 访问应用
# http://localhost:1717Docker安装:
# 使用Docker Compose
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
# 修改docker-compose.yml配置
# 根据需求修改端口和卷映射
# 启动服务
docker-compose up -d
# 访问应用
# http://localhost:1717桌面应用:
桌面版本:
- Windows: 下载Setup.exe安装
- macOS: 下载MacOS应用
- Linux: 下载AppImage文件
安装步骤:
1. 下载对应平台安装包
2. 运行安装程序
3. 启动应用程序
4. 开始使用3. 配置说明
环境配置:
# 环境配置示例
PORT=1717
NODE_ENV=production
# 数据库配置
DATABASE_URL=file:./local-db/dev.db
DATABASE_PATH=./local-db
# API配置
OPENAI_API_KEY=your-api-key
API_BASE_URL=https://api.openai.com/v1
API_MODEL=gpt-3.5-turbo
# 性能配置
MAX_FILE_SIZE=10485760
MAX_CONCURRENT=5
REQUEST_TIMEOUT=30000
# 功能配置
ENABLE_EXPERIMENTAL=true
LOG_LEVEL=info
CACHE_ENABLED=true项目配置:
project:
name: "my-dataset-project"
version: "1.0.0"
description: "Custom dataset creation project"
processing:
chunk_size: 1000
chunk_overlap: 200
min_chunk_size: 100
max_chunk_size: 2000
generation:
question_template: "default"
answer_template: "detailed"
temperature: 0.7
max_tokens: 1000
quality:
min_quality_score: 0.8
max_attempts: 3
validation_strictness: "medium"
export:
default_format: "alpaca"
file_format: "jsonl"
include_metadata: true
compress_output: falseAPI配置:
api:
providers:
- name: "openai"
base_url: "https://api.openai.com/v1"
api_key: "${OPENAI_API_KEY}"
models: ["gpt-3.5-turbo", "gpt-4"]
enabled: true
- name: "azure"
base_url: "https://your-resource.openai.azure.com/openai/deployments"
api_key: "${AZURE_API_KEY}"
api_version: "2023-05-15"
models: ["gpt-35-turbo", "gpt-4"]
enabled: false
- name: "local"
base_url: "http://localhost:8080/v1"
api_key: "local-key"
models: ["local-model"]
enabled: false
defaults:
default_provider: "openai"
default_model: "gpt-3.5-turbo"
timeout: 30000
retries: 3
fallback: true使用指南
1. 基本工作流
使用Easy Dataset的基本流程包括:项目创建 → 文档上传 → 文本分割 → 问题生成 → 答案生成 → 数据集构建 → 导出使用。整个过程设计为简单高效。
2. 基本使用
项目创建:
1. 项目设置:
- 项目命名: 创建项目名称
- 描述添加: 添加项目描述
- API配置: 配置LLM API
- 参数设置: 设置处理参数
- 模板选择: 选择处理模板
2. 文档准备:
- 文件收集: 收集领域文档
- 格式检查: 检查文档格式
- 质量评估: 评估文档质量
- 预处理: 必要预处理
- 批量准备: 批量文档准备
3. 流程规划:
- 处理流程: 规划处理流程
- 质量要求: 设定质量要求
- 规模估计: 估计数据集规模
- 资源分配: 分配计算资源
- 时间规划: 时间计划制定文档处理:
1. 文档上传:
- 单个上传: 单个文档上传
- 批量上传: 批量文档上传
- 格式支持: 多种格式支持
- 进度跟踪: 上传进度跟踪
- 错误处理: 上传错误处理
2. 文本分割:
- 自动分割: 自动文本分割
- 参数调整: 分割参数调整
- 可视化检查: 可视化检查分割
- 手动调整: 手动分割调整
- 质量评估: 分割质量评估
3. 内容优化:
- 内容清理: 清理无关内容
- 格式统一: 统一文本格式
- 质量筛选: 质量筛选内容
- 重复去除: 去除重复内容
- 组织整理: 内容组织整理数据集构建:
1. 问题生成:
- 自动生成: 自动问题生成
- 质量检查: 问题质量检查
- 多样性保证: 保证问题多样性
- 相关性验证: 相关性验证
- 批量处理: 批量问题生成
2. 答案生成:
- API调用: 调用LLM生成答案
- 质量监控: 生成质量监控
- 一致性检查: 答案一致性
- 错误处理: 生成错误处理
- 批量生成: 批量答案生成
3. 数据集组装:
- 样本构建: 构建数据样本
- 质量评估: 样本质量评估
- 标签添加: 添加语义标签
- 组织管理: 数据集组织
- 版本管理: 版本控制管理3. 高级用法
质量控制:
质量监控:
- 自动评估: 自动质量评估
- 人工审核: 人工质量审核
- 质量指标: 定义质量指标
- 阈值设置: 质量阈值设置
- 实时监控: 实时质量监控
质量改进:
- 问题修复: 质量问题修复
- 迭代优化: 迭代改进优化
- 反馈学习: 质量反馈学习
- 模板优化: 生成模板优化
- 参数调整: 生成参数调整
质量保证:
- 验证流程: 建立验证流程
- 标准制定: 质量标准制定
- 文档记录: 质量文档记录
- 报告生成: 质量报告生成
- 持续改进: 持续质量改进批量处理:
大规模处理:
- 批量上传: 大规模文档上传
- 并行处理: 并行处理优化
- 资源管理: 计算资源管理
- 进度监控: 批量进度监控
- 错误恢复: 错误恢复机制
效率优化:
- 缓存策略: 智能缓存策略
- 预处理优化: 预处理优化
- API优化: API调用优化
- 内存优化: 内存使用优化
- 性能监控: 性能监控优化
自动化流程:
- 工作流自动化: 自动化工作流
- 调度管理: 任务调度管理
- 自动重试: 自动重试机制
- 通知系统: 处理状态通知
- 日志记录: 详细日志记录自定义扩展:
模板定制:
- 问题模板: 自定义问题模板
- 答案模板: 自定义答案模板
- 提示工程: 提示词工程定制
- 格式模板: 输出格式模板
- 样式定制: 界面样式定制
功能扩展:
- 插件开发: 开发功能插件
- API扩展: 扩展API支持
- 格式支持: 新格式支持
- 算法扩展: 新算法集成
- 集成扩展: 外部集成扩展
开发支持:
- SDK提供: 开发SDK支持
- 文档完善: 开发文档完善
- 示例代码: 丰富示例代码
- 测试工具: 开发测试工具
- 调试支持: 调试工具支持应用场景实例
案例1:企业知识库微调
场景:企业内部知识库LLM微调
解决方案:使用Easy Dataset创建企业知识微调数据集。
实施方法:
-
文档收集:收集企业文档和知识库
-
知识提取:提取和分割知识内容
-
问题生成:生成相关业务问题
-
答案创建:创建准确业务答案
-
微调训练:用于LLM微调训练
企业价值:
-
知识利用:充分利用企业知识
-
问答能力:提升业务问答能力
-
成本节约:降低数据准备成本
-
质量保证:保证数据质量
-
快速部署:快速部署应用
案例2:教育内容创建
场景:教育机构教学材料创建
解决方案:使用Easy Dataset创建教育问答数据集。
实施方法:
-
教材处理:处理教科书和教学材料
-
知识点提取:提取关键知识点
-
学习问题:生成学习相关问题
-
教学答案:创建教学答案
-
学习应用:用于学习助手开发
教育价值:
-
教学资源:丰富教学资源
-
个性化学习:支持个性化学习
-
教师支持:教师教学支持
-
学习效果:提升学习效果
-
教育公平:促进教育公平
案例3:客服系统增强
场景:客服系统智能增强
解决方案:使用Easy Dataset创建客服问答数据集。
实施方法:
-
客服记录:收集客服对话记录
-
问题整理:整理常见问题
-
答案优化:优化标准答案
-
数据集构建:构建客服数据集
-
系统增强:增强客服系统
客服价值:
-
效率提升:提升客服效率
-
质量一致:保证回答质量
-
成本降低:降低客服成本
-
用户体验:改善用户体验
-
规模扩展:支持规模扩展
案例4:专业领域应用
场景:专业领域LLM应用
解决方案:使用Easy Dataset创建专业领域数据集。
实施方法:
-
专业文档:收集专业领域文档
-
术语处理:处理专业术语
-
专业问答:生成专业问题
-
专家答案:创建专家级答案
-
领域应用:专业领域应用
专业价值:
-
专业知识:专业知识数字化
-
专家能力:复制专家能力
-
准确性:保证专业准确性
-
可及性专业知识可及性
-
创新支持:支持专业创新
案例5:多语言支持
场景:多语言LLM应用支持
解决方案:使用Easy Dataset创建多语言数据集。
实施方法:
-
多语言文档:收集多语言文档
-
语言处理:多语言内容处理
-
翻译支持:翻译和本地化
-
多语言生成:多语言问答生成
-
跨语言应用:跨语言应用支持
多语言价值:
-
语言覆盖:多语言支持
-
文化适应:文化适应性
-
全球应用:全球应用支持
-
本地化:本地化内容
-
多样性:语言多样性
总结
Easy Dataset作为一个创新的LLM微调数据集创建工具,通过其强大的文档处理、智能问题生成、高质量答案生成和灵活导出能力,为LLM微调提供了完整的解决方案。
核心优势:
-
📚 智能处理:智能文档处理和分割
-
❓ 问题生成:自动相关问题生成
-
✅ 质量保证:高质量数据保证
-
🚀 高效创建:高效数据集创建
-
🆓 完全开源:代码完全开源免费
适用场景:
-
企业知识库微调
-
教育内容创建
-
客服系统增强
-
专业领域应用
-
多语言支持
立即开始使用:
# 快速开始
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
npm install
npm run start
# 访问 http://localhost:1717资源链接:
-
📚 项目地址:GitHub仓库
-
📖 技术文档:详细技术文档
-
💬 社区支持:GitHub讨论区
-
🎥 演示示例:在线演示示例
-
🔧 配置参考:配置选项参考
通过Easy Dataset,您可以:
-
数据创建:轻松创建微调数据集
-
质量保证:保证数据集质量
-
效率提升:大幅提升创建效率
-
成本降低:降低数据准备成本
-
创新实现:实现创新应用
无论您是开发者、研究人员、企业用户还是教育工作者,Easy Dataset都能为您提供强大、易用且免费的数据集创建解决方案!
特别提示:
-
🔍 API配置:正确配置API密钥
-
📖 文档阅读:详细阅读技术文档
-
🤝 社区参与:积极参与社区贡献
-
🔧 配置优化:根据需求优化配置
-
⚠️ 质量监控:注意数据质量监控
通过Easy Dataset,共同推动LLM微调技术的发展!
未来发展:
-
🚀 更多功能:持续添加新功能
-
🤖 质量提升:进一步提升数据质量
-
🌍 多语言:更多语言支持扩展
-
📊 性能优化:进一步性能优化
-
🔧 生态建设:开发者生态建设
加入社区:
参与方式:
- GitHub Issues: 问题反馈和功能建议
- 文档贡献: 技术文档改进贡献
- 代码贡献: 代码改进和功能添加
- 示例贡献: 示例和教程贡献
- 插件开发: 插件和工具开发
社区价值:
- 技术交流和学习
- 问题解答和支持
- 功能建议和讨论
- 项目贡献和认可
- 职业发展机会通过Easy Dataset,共同构建更好的LLM微调未来!
许可证:
AGPL 3.0许可证
免费用于学术和商业用途致谢:
特别感谢:
- 核心团队: 项目研发团队
- 贡献者: 代码贡献者
- 用户社区: 用户反馈和支持
- 合作伙伴: 技术合作伙伴
- 开源项目: 依赖的开源项目通过Easy Dataset,体验数据集创建的无限可能!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)