Voice Agent 介绍与实现方案
虽然目前能够直接接受视频输入的 LLM 还没有被广泛的应用,稳定性和可用性也有待提供,但是接受图像作为输入的 LLM 很多已经表现出非常出色的分析能力,不仅能够描述图像内容以及转录图像中出现的文本,有些还能统计画面的对象、识别边界框以及更好地理解图像中对象之间的关系。然而,抛开模型服务引入的延迟,在 Voice Agent 场景下,客户端和 Agent 服务程序还需进行媒体数据(音频,甚至视频)的
360智汇云 AI 多模态交互产品,支持客户灵活接入 多家厂商/自部署 大模型服务,实现 AI 与用户之间的实时音视频交互,构建高度契合业务场景的多模态智能体验。产品融合了智汇云自研及第三方 RTC 能力,保障低延迟、高质量的传输效果,带来自然流畅的沉浸式交互体验,同时提供覆盖全端的 SDK,便于快速接入或私有化部署。
本文将系统性地介绍该产品背后的核心技术方案 —— Voice Agent 的基础架构与关键实现路径。
01
Voice Agent 简单介绍
1.1 定义
Voice Agent 是一种融合了语音处理与大语言模型推理能力的智能体,能够实现实时、自然、类人化的语音交互体验。与传统的语音助手不同,现代 Voice Agent 不仅能“听懂”用户的语言,还能基于上下文进行深度理解与推理,并给出符合语境的自然语言回应。这种融合语音识别(ASR)、大语言模型(LLM)与语音合成(TTS)的智能系统,正逐步改变人机交互的方式,成为推动 AI 多模态交互技术发展的关键力量。
1.2 应用场景
-
智能语音助手:用户通过语音与智能助手互动,例如设置提醒、查询天气、搜索信息等。
-
AI客户服务:用户向AI客服咨询问题或提交请求,AI以自然的语音与用户进行实时对话,回答问题或引导操作。
-
AI在线教育:学生通过语音向AI提问,AI以真人感的语音进行详细解答或外语学习,AI根据发音、语法和语调进行实时纠正和反馈。
-
智能医疗场景:医生使用语音与AI沟通查询病例或医疗知识,AI以语音反馈并同步显示相关文字信息。
-
智能硬件:用户通过语音与物联网设备交互,如控制灯光、温度、玩具问答或播放音乐,AI以自然语音提供反馈。
-
AI陪伴与情感支持:用户通过语音与AI进行陪伴式对话,分享情绪或寻求心理支持。
02
Voice Agent 基本原理
2.1 工作流程
360智汇云 AI 多模态交互产品同时支持语音、文本和图像的输入与输出,充分发挥多模态优势。
输入:系统接受用户的语音输入, 甚至是视频输入,比如用户的问题或请求(含语音、文字或图片)
输出:生成语音回应,甚至是音视频同步的答复,比如一个有形象、会说话的虚拟数字人
360智汇云 AI 多模态交互产品对主流 STT/LLM/TTS 模型做了全方位的覆盖支持,方便用户无缝集成、灵活替换,促进个性化和复杂的 AI 响应,增强整体对话体验。
核心组件:

常见的基本步骤:
-
用户设备上的麦克风捕捉语音信号,并对其进行编码,然后通过网络发送至云端运行的 Voice Agent 程序。
-
接收到的语音被 ASR 转写为文本,为 LLM 生成输入内容。
-
转写后的文本会被整理成完整的上下文提示(prompt),然后由 LLM 进行推理处理。
-
模型生成的结果通常会经过 Voice Agent 程序的逻辑处理,进行过滤或转换。
-
处理后的文本被送入 TTS,生成对应的语音输出。
-
生成的语音再被发送回用户端,完成一个回合的语音交互。
2.2 实现方式
360智汇云 AI 多模态交互产品同时支持 三段式级联方式 与 端到端方式,助力打造卓越的音视频交互体验。

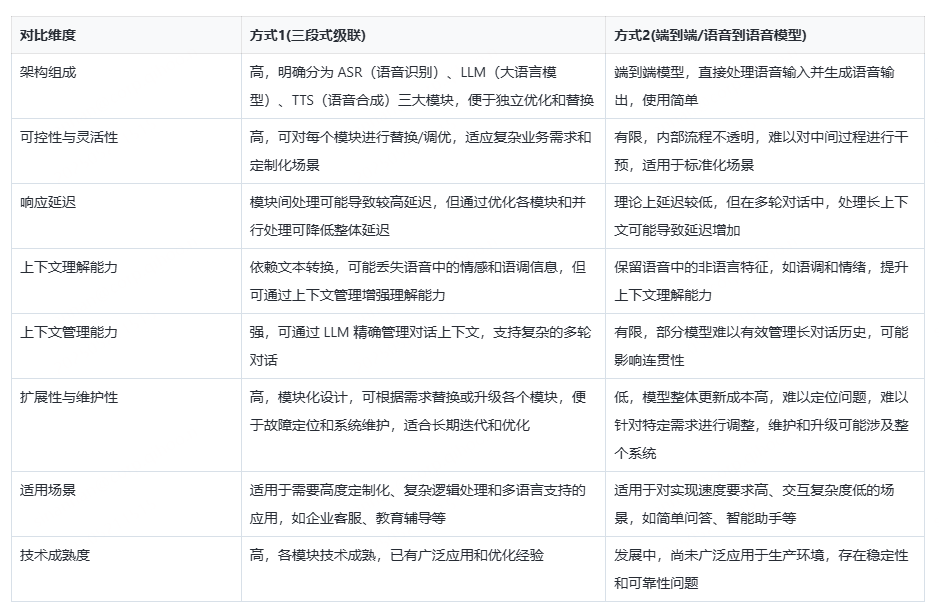
综合来看,目前三段式级联的实现方式在控制性、可维护性和适应复杂场景方面具有明显优势,尤其适合需要精细调控和高度定制化的应用。尽管端到端模型在响应速度和交互自然性方面会更具天然优势,但在处理复杂对话、上下文保持和系统稳定性方面仍面临挑战。因此,在当前技术发展阶段,前者更适合作为构建生产级别 Voice Agent 的基础架构。本文也将侧重于三段式级联方式开展进一步探讨。
03
Voice Agent实现面临的挑战
3.1 延迟
基于文本问答形式的对话 Agent 应用技术已经非常成熟并得到广泛应用,而构建 Voice Agent 在大多数方面在工程上也是类似的。但是最大的区别是延迟,因为纯文本对话更多的时候只需要考虑 LLM 引入的延迟,而语音对话还面临着 ASR、TTS 和媒体数据传输带来的延迟。
我们搜集了国内外主流模型服务厂商提供的公网API请求在流式响应中的首包延迟:
-
ASR/STT:100-500ms(英文),200-500ms(中文)
-
LLM(首token延迟:='time to first token'): 200-500ms
-
TTS(首byte延迟:='time to first byte'): 100-500ms(英文),200-500ms(中文)
-
中文场景下,模型服务带来的延迟区间:600ms - 1.5s
然而,抛开模型服务引入的延迟,在 Voice Agent 场景下,客户端和 Agent 服务程序还需进行媒体数据(音频,甚至视频)的交换,延迟可能还会增加,甚至超过一秒半,用户几乎肯定会察觉到。那么,我们如何才能接近与自然人类对话相符的低延迟下限呢?
3.2 音频处理
Voice Agent 应用一个很大优势在于能够解放用户的双手,达到让用户动动嘴就能获取信息,因此音频的相关处理是开发者无法绕开的环节,可能涉及以下相关问题:
-
回声干扰:用户扬声器的输出可能被麦克风再次拾取形成回声,严重干扰语音识别,并造成对话逻辑混乱。
-
背景噪声:用户可能处于嘈杂环境中,如咖啡店、地铁或办公区,这些不可控的背景声音会显著影响语音清晰度,导致识别错误频发。
-
音量变化:用户说话音量存在个体差异,甚至在一次通话中也可能因距离变化、情绪波动而变化,语音信号的强弱难以控制。
-
轮次检测:用户开始说话、是否正在说话以及停止说话的状态难以确认,无法保障流畅的交互节奏。
04
Voice agent 实现方案
4.1 网络传输协议/方式的选择
4.1.1 传输层协议对比:TCP vs UDP
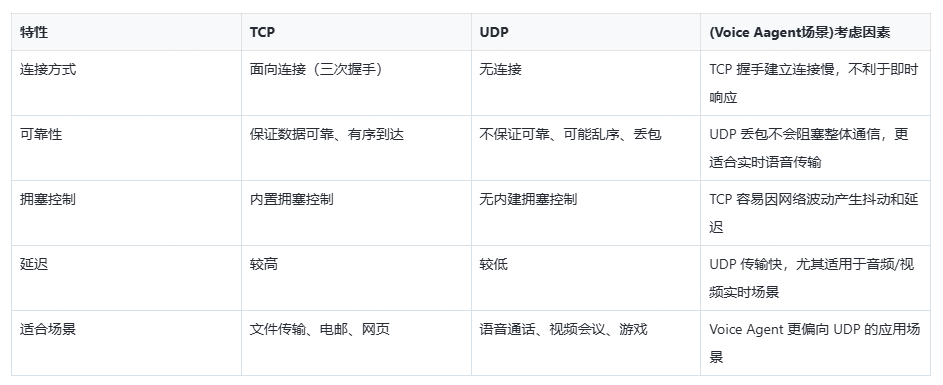
Voice Agent 是对「延迟」高度敏感的场景:
-
TCP 的“可靠传输”反而会拖慢交互效率,比如音视频包的队首阻塞,最终可能会导致音频播放时出现断断续续或者卡顿,这是一种糟糕的用户体验,不适用于实时语音通信,
-
UDP 优先考虑低延迟而非可靠性,能够跳过丢包重传与拥塞控制的开销,与 TCP 不同,UDP 会立即将数据包交给 Agent,尽管在网络情况糟糕的情况下可能存在不可靠的传输,但 Agent 实际上可以选择在这种情况下做什么允许更流畅的实时体验。
4.1.2 应用层通信协议对比:HTTP vs WebSocket vs WebRTC
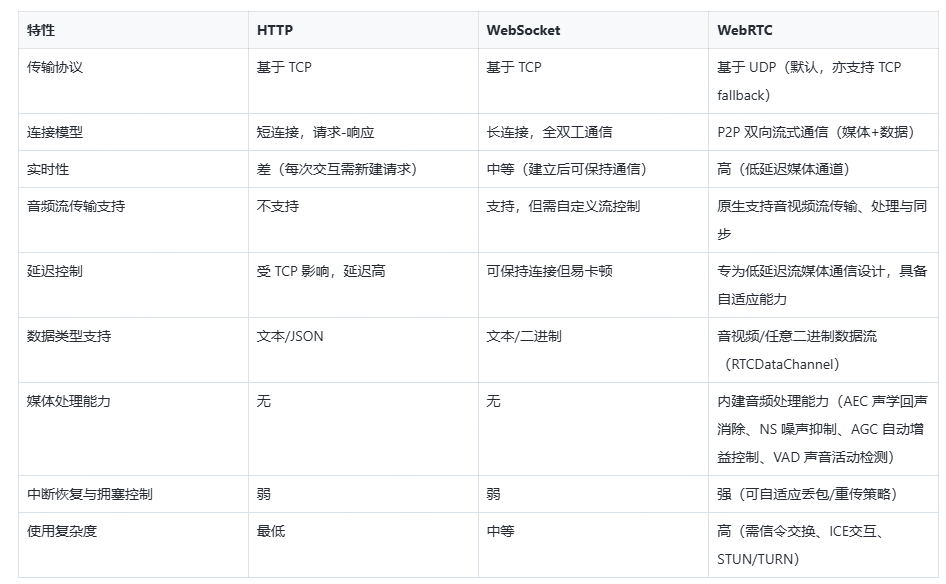
4.1.3 结论:为何 WebRTC 更适合 Voice Agent
基于上述对比,我们可以重新梳理 Voice Agent 的关键需求如下:
超低延迟响应能力:用于实现接近人类自然对话节奏;支持实时音频流传输:ASR、TTS 通常以流式方式处理数据,要求边传边转边播;具备网络适应能力:面对抖动、丢包的互联网环境时,仍能保持较好的语音质量;内建音频增强模块:如回声消除、噪声抑制、自动增益控制等,简化客户端开发;双向语音传输(full-duplex):支持打断、插话等更自然的对话行为。WebRTC 正是为实时媒体通信场景量身打造的协议栈,在传输层选择了 UDP,在应用层集成了丰富的音视频能力,并且为延迟敏感型应用提供了出色的网络适配策略。因此,它是实现 Voice Agent 实时互动体验的首选通信传输方式。
360智汇云 AI 多模态交互产品,融合了智汇云自研及第三方 RTC 能力,同时提供覆盖全端的 SDK,极简接入 RTC 流程,及一站式服务,方便客户更快、更便捷的接入,开发和运营成本极低。
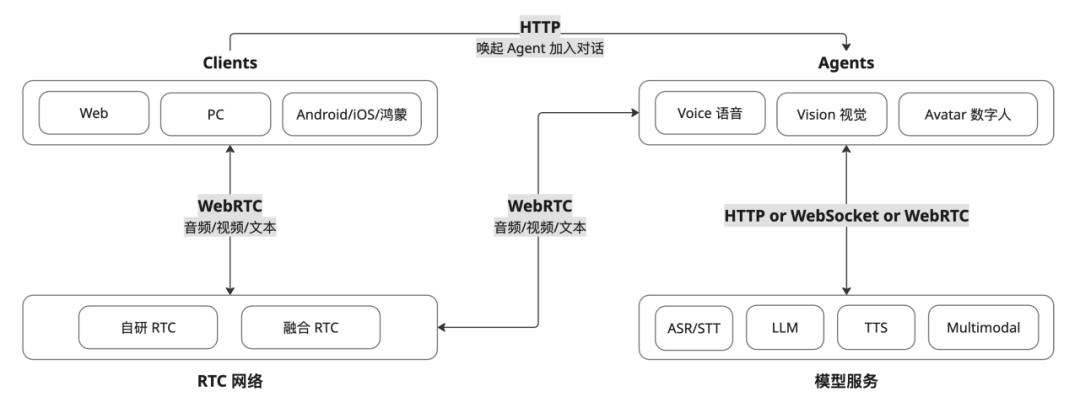
4.2 Voice Agent 实现架构
360智汇云使用基于工作流的架构来构建 Voice Agent 与 AI 进行实时交互。让我们看看 Voice Agent 在实践中是如何工作的,然后分解其中的关键细节。
4.2.1 图解 Voice Agent 工作流程
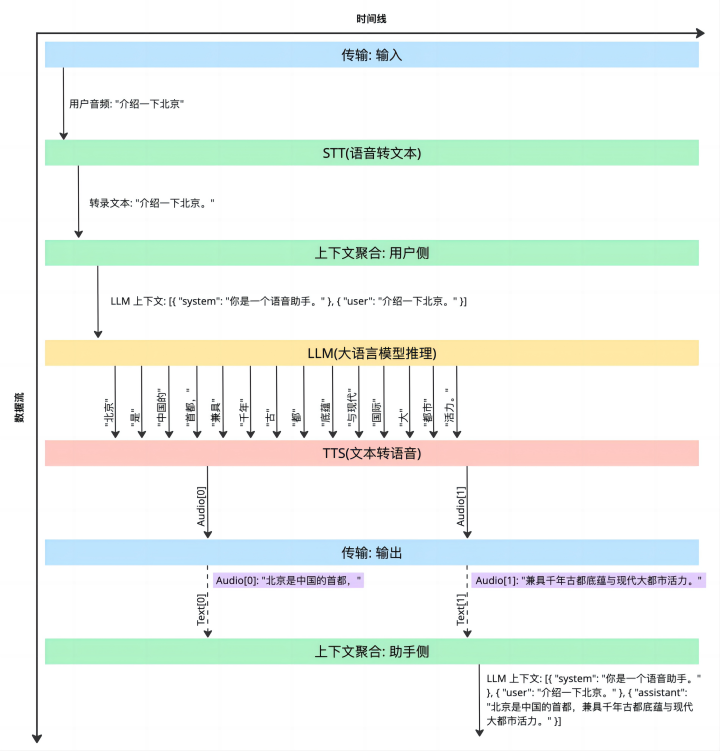
这张图直观展示了 Voice Agent 系统如何从用户语音输入到语音输出进行完整闭环处理的过程,覆盖了从语音识别(ASR/STT)到大语言模型推理(LLM)再到语音合成(TTS)的整个流式语音交互流程。
我们从上到下、从左到右(即时间线和数据流)来一步步分析:
1. 传输: 输入
-
用户说话:"介绍一下北京。"
-
这段原始语音通过实时传输方式(如 WebRTC)从终端设备传入系统。
2. STT(语音转文本)
-
将用户语音转录为文本:"介绍一下北京。"
-
这个节点即 ASR(Automatic Speech Recognition),在Voice Agent 中承担“听懂用户说了什么”的任务。
3.上下文聚合: 用户侧
-
构建用于 LLM 推理的上下文:
[ { "system": "你是一个语音助手。" }, { "user": "介绍一下北京。" }]-
该节点整合当前对话状态和历史语境,作为 prompt 提交给 LLM。
4.LLM(大语言模型推理)
-
接收到语音转文本后的用户输入与上下文后,LLM 开始推理响应。
-
此过程是流式生成(Streaming Generation)的逐 token 文本片段,如:
"北京" "是" "中国的" "首都," "兼具" "千年" "古" "都" "底蕴" "与现代" "国际" "大" "都市" "活力。"-
每个 token 生成完后立即发送给 TTS 组件,开始语音合成,避免等待整个句子生成完毕,从而显著降低整体响应延迟。
5. TTS(文本转语音)
-
接收到来自 LLM 组件的文本片段后,TTS 模块开始进行流式语音合成,例如:
"北京是中国的首都,"被合成为 Audio[0]
"兼具千年古都底蕴与现代大都市活力。",被合成为 Audio[1]
-
由于语音合成也是流式,响应可以快速开始播放。
6. 传输: 输出
-
合成后的音频(Audio[0], Audio[1])通过网络传回用户客户端。
-
输出过程中支持同步传送对应文本片段(Text[0], Text[1]),用于实时字幕、辅助 UI 展示等。
7. 上下文聚合: 助手侧
-
在本轮对话结束后,Agent 会更新对话上下文,用于后续轮次:
[ { "system": "你是一个语音助手。" }, { "user": "介绍一下北京。" } { "assistant": "北京是中国的首都,兼具千年古都底蕴与现代大都市活力。" }]-
这保证了下一轮交互具备完整语境。
上述流程无需等待每一步的完整响应,而是处理最小数据单元,这些数据在管道中流动,展现了一个 Voice Agent 系统的五大关键特性:
低延迟响应:通过实时采集、实时传输,以及ASR、LLM 和 TTS 的流式处理,边说边转录,边生成边处理边播放。状态上下文感知:每轮对话被持续累积管理,增强连续性。双向语音流:支持语音输入与语音输出的闭环处理。模块解耦:STT → LLM → TTS 是清晰的模块链条,方便灵活替换。输出并发:语音和文本输出并行发送,适用于可视化界面增强体验。4.2.2 Voice Agent 架构概述
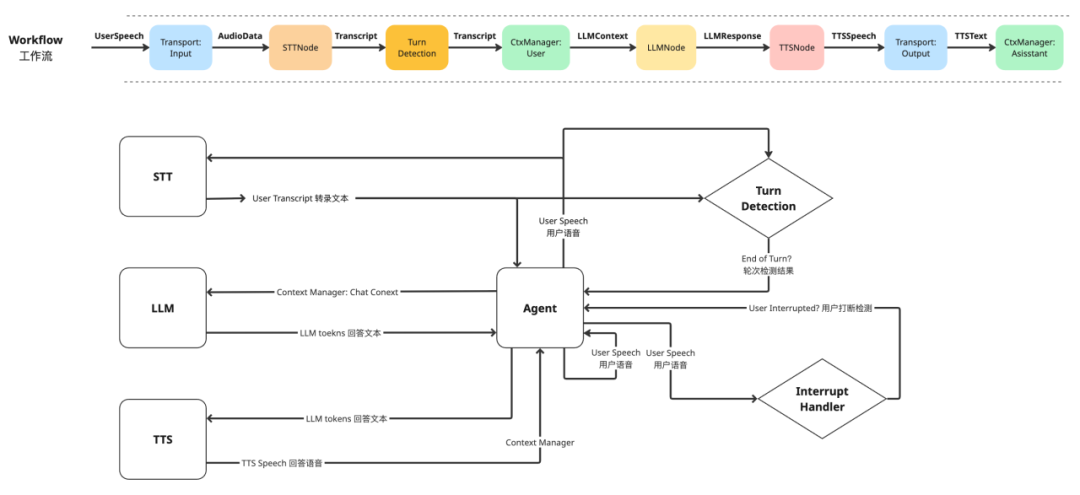
1、基础概念
Voice Agent 内部由三个关键组件组成:
数据 Data
数据是在 Voice Agent 程序中移动的最小单元,包括但不仅限于:
-
来自麦克风的音频数据,
RawAudioData -
ASR 转录文本数据,
STTTranscriptData -
LLM 响应数据,
LLMResponseData -
TTS 生成的音频数据,
TTSSpeechData -
图像或视频数据,
ImageDataVideoData -
控制信号和系统消息,
InterruptSignal(打断信号)UserSpeaking(用户正在说话状态)
数据可以双向流动:
-
向下:正常处理流程
-
向上:用于错误和控制信号
节点 Node
每个节点承担一定的工作任务,如:
-
接收数据作为输入
-
处理特定类型的数据
-
传递该节点不处理的数据
-
生成新的数据作为输出
节点可以定义任意工作内容,但对于实时多模态 AI 应用,通常需要有:
-
ASR节点,接收原始音频输入数据并生成转录文本数据
-
LLM节点,接收上下文数据并生成响应文本数据,甚至响应图片数据等
-
TTS节点,接收文本数据并生成原始音频输出数据
-
传输节点,如WebRTC,用于接收现实世界麦克风传入的声音,以及传递至用户扬声器的声音
工作流 Workflow
工作流将所有节点连接到一起,为数据在应用程序中流动创建路径,以一个基本工作流为例:

2、轮次检测 Turn Detection
轮次检测是指确定用户何时说话结束并期望 LLM 做出响应。实际上,人与人之间在进行对话时,我们本能的也一直在进行着轮次检测,比如听对方把话说完再发言,又或者对方没说完就进行打断,就算是人类也不能总是做到准确。因此,人与 Agent之间的轮次检测更是一个难题,没有完美的解决方案,但我们可以探讨一些常用的方法。
VAD(Voice Activity Detection) 声音活动检测
目前,在 Voice Agent 系统中,最常见的方法是基于“长时间静音”来判断用户的发言是否结束。然而,仅靠音量变化来检测静音常常会产生误判,尤其是在存在背景噪音或用户说话停顿时。
为了解决这一问题,Voice Agent 通常会集成一个轻量级的语音活动检测(VAD)模型,用于更精确地识别用户发言的起止。整个流程如下:
当用户的音频流输入系统时,它首先被发送到 VAD 模块,而不是直接传给 ASR(自动语音识别)。VAD 模块会对音频进行实时分析,它本质上是一个小型的二元分类神经网络,用于判断当前音频片段中是否包含人声。
一旦 VAD 判断当前从“检测到语音”切换为“未检测到语音”,系统会启动一个可配置的静音计时器(通常以毫秒为单位)。如果这段静音持续超过设定阈值,系统就认为用户已经完成了发言,并触发后续处理逻辑(如发送音频到 ASR 进行识别)。如果在计时器触发之前 VAD 再次检测到语音,计时器会被重置。这种机制比简单基于音量阈值的方法更加稳健,有效减少误触发。
常见的 VAD 模型通常有如下参数配置, 以最常用的开源 Silero VAD 模型为例(该模型在 CPU 上运行高效,支持多种语言,适用于 8kHz 和 16kHz 音频,并且作为 wasm 包可用于网页浏览器。在实时单声道音频流上运行通常只需不到典型虚拟机 CPU 核心的 1/8 时间):
-
threshold(语音概率阈值): 决定模型判断语音/静音的灵敏度。值越高,模型越“保守”;可根据误检/漏检情况灵活调整。 -
min_speech_duration_ms(最小语音持续时间): 去除太短的非人声杂音。设得太小容易误判背景噪音为人声,设得太大会漏掉一些较短的人声。 -
max_speech_duration_s(最大语音持续时间): 限制连续语音片段的最长时长,避免出现一个巨大段落不被切分,影响后续处理。 -
min_silence_duration_ms(最小静音持续时间): 定义认为用户“说完”的最短静音时长。值越小,响应越快;值越大,容错越强。 -
speech_pad_ms(语音填充时长): 在语音片段前后添加的缓冲时间,避免切掉说话开头或结尾。
通过合理配置和集成 VAD,Voice Agent 可以在保持响应速度的同时,更准确地判断用户是否说完,从而实现更加自然和流畅的语音交互体验。
Semantic Turn Detection 语义轮次检测
利用 VAD 基于语音中的停顿来检测轮次的明显问题是,有时人们会停顿但并未说完话。个人的说话风格各不相同。人们在某些类型的对话中停顿更多,而在其他类型中则较少。设置较长的停顿间隔会导致对话显得生硬——这是一种非常糟糕的用户体验。但如果停顿间隔太短,语音代理会频繁打断用户——这同样是糟糕的用户体验。
常见的方式是引入一个可以实时运行的小型语义轮次检测模型,将该模型与 VAD 模型结合使用或替代使用。用户的输入语音被 STT 转为文本并发送回 Agent, 在 Agent 的工作流中,可以将转录文本数据数据传递到到语义轮次检测节点,它可以接收用户的语音以及对话中最近的3或4个之前回合的转录内容,输出一个预测结果,判断它通过用户所说内容是否认为用户已经说完。
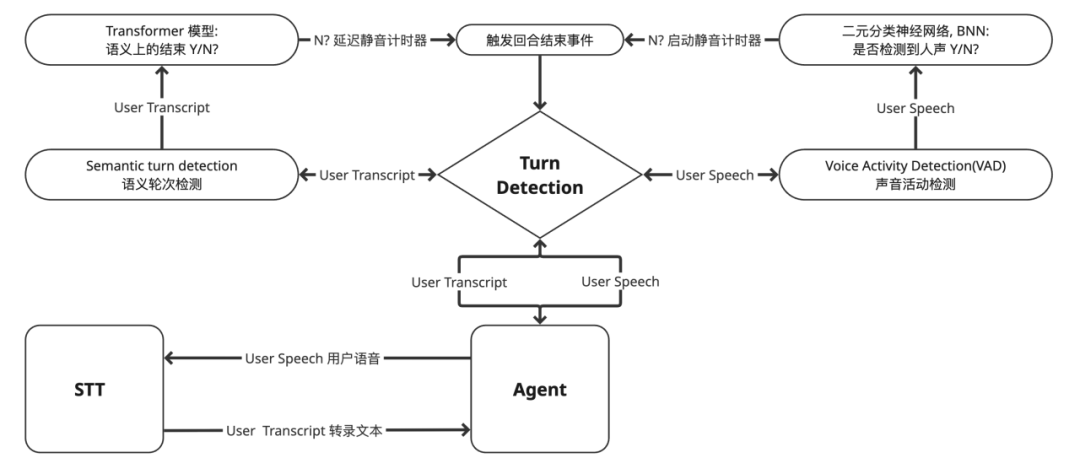
3、打断处理 Interrupt Handler
VAD 不仅用于语音端检测,它还用于处理中断。为了模拟两个人类进行对话的动态性,我们需要能够处理用户中断 Agent 发言的情况。Voice Agent 正在说话时,可能由于多种原因发生中断,比如:LLM 可能说的太多了,或者用户改变了想法,甚至用户可能想要纠正自己提问的问题。在 Agent 的内部,我们结合 VAD 判断是否有人声存在以及语义处理的的结果来作为是否中断的信号。
当发生中断时,Voice Agent 工作流后续的每个节点的任务都会被清空。如果当时 LLM 正在进行推理,则会停止。如果有任何 TTS 推理出音频,也会停止。
4、上下文管理 Conext Manager
在 Voice Agent 的工作流中,上下文管理也扮演着至关重要的角色。它不仅关系到系统是否能够理解用户的真实意图,还直接影响对话的连贯性、响应的准确性以及整体用户体验。
LLM 是无状态的,必须靠上下文“喂给记忆”
大多数 Voice Agent 背后的 LLM 本身并没有记忆。每次生成回复时,模型并不知道之前发生了什么——除非你显式地把整个对话历史重新发送进去。这意味着 Voice Agent 在每一轮对话中,必须维护并发送:
-
用户和 Agent 的历史发言
-
可能调用过的函数及其结果(例如 API 请求)
-
当前的系统指令或提示(system prompt)
-
任何必要的工具定义(functions/tools)
完整上下文 vs 精简上下文
虽然发送完整历史可以让模型更“了解整个对话”,但这会带来明显的代价:
• 响应时间更长(延迟更高)
• 成本增加(Token 使用量变多)
• 回答偏题/逻辑混乱(上下文太长可能导致 LLM 注意力分散)
因此,Voice Agent 还应当支持选取、压缩、或总结上下文。例如,当对话变长,Agent 可以只保留关键内容、删减重复信息,甚至使用摘要方式传递过去的内容,从而减少负担,同时保留对话核心。
5、整体架构呈现
6、全链路延迟表现
阶段macOS 麦克风输入 40msopus 音频编码 20msWebRTC 传输 30ms数据包处理 2msjitter buffer 40msopus 音频解码 1msasr转录+轮次检测 300msllm ttfb 250ms文本聚合 10mstts ttfb 250msopus 音频编码 20ms数据包处理 2msWebRTC传输 30msjitter buffer 40msopus 音频解码 1msmacOS 扬声器输出 15ms总耗时 1051ms ~= 1s4.3 迈向多模态 Voice Agent -> Multi-modal Agent
随着 LLM 的发展,越来越多的 LLM 现在除了文本外,还能处理和生成音频、图像和视频。所以,越来越多的 Voice Agent 应用开始赋予 Agent 能够“看见”的能力,比如用户可以将屏幕画面共享给 Agent 并让其执行一些相应的任务。虽然目前能够直接接受视频输入的 LLM 还没有被广泛的应用,稳定性和可用性也有待提供,但是接受图像作为输入的 LLM 很多已经表现出非常出色的分析能力,不仅能够描述图像内容以及转录图像中出现的文本,有些还能统计画面的对象、识别边界框以及更好地理解图像中对象之间的关系。
因此,利用仅接收图像输入的 LLM 同样也能够让 Voice Agent 和用户进行“视频”通话,一个通用的方式是从用户实时输入的视频中(摄像头/屏幕共享等)实时提取单个帧并将这些帧作为图像嵌入到上下文中。
目前,对于多模态 Agent 的场景来说,最大挑战无疑是音频和图像数据会占用大量的 tokens,而 token 数量的增加很可能直接导致系统响应延迟的显著上升。这是多模态系统在实际应用中难以回避的技术瓶颈。
尤其在一些需要高实时性的应用场景中,比如多轮对话系统,工程上需要同时处理大量图像的同时,还要控制对话的延迟,这成为一个极具挑战性的任务。为了实现较低的对话延迟,开发者通常需要尽量精简上下文信息,或者依赖于特定厂商提供的缓存 API 来提升处理效率。举例来说,一小时的视频内容可能对应接近一百万个 tokens。即便某些大型模型具备处理百万级上下文的能力,在每一轮多轮对话中都加载如此庞大的信息,其计算开销和响应延迟也难以承受。
面对这种困境,目前有两种常见的解决方案:
-
内容摘要:将视频、音频等多模态信息进行文本摘要,仅保留摘要内容用于上下文,从而大幅压缩 token 数量。
-
嵌入检索(Embedding + RAG):通过预先生成的特征向量进行检索,再结合类似 RAG(Retrieval-Augmented Generation)的机制,在需要时动态查找相关信息。
这些方法可以有效利用 LLM 在内容提取和函数调用驱动检索方面的能力,从而减轻上下文负担。
05
总结
我们同时支持三段式级联架构(ASR-LLM-TTS)或端到端模型架构与WebRTC 实时传输技术结合,成功将端到端交互延迟控制在约1秒水平,接近自然人类对话体验。并在 Voice Agent 的工作流程设计充分考虑了延迟优化、音频处理、轮次检测和上下文管理等关键环节,努力为用户提供流畅自然的 AI 对话体验。随着多模态大模型技术的快速发展,我们已经将 Voice Agent 推向更全面的多模态 Agent 演进,不仅能"听"和"说",还能"看"和"理解"视觉信息。未来,我们将持续优化模型集成能力,优化各项流程指标,为各行业客户提供更智能、更自然的 AI 交互解决方案,推动人机交互迈向新的高度。
360智汇云 AI 多模态交互产品将持续致力于降低技术门槛,帮助企业快速构建和部署自己的智能交互应用,释放 AI 多模态交互的潜力,共同开创人机协作的美好未来。
DEMO 在线体验:
PC端请点击:
https://webrtc.zyun.360.cn/agent_talk/page/(请复制链接后在电脑端打开)
移动端可扫码:

AI多模态交互产品体验:
https://zyun.360.cn/product/aimi
更多技术干货,
请关注“360智汇云开发者”👇
360智汇云官网:https://zyun.360.cn(复制在浏览器中打开)
更多好用又便宜的云产品,欢迎试用体验~
添加工作人员企业微信👇,get更快审核通道+试用包哦~


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)