WAN: OPEN AND ADVANCED LARGE-SCALE VIDEO GENERATIVE MODELS
无限长度视频生成:滑窗机制让视频生成突破长度上限,且显存/算力不会线性增长。高效注意力机制:仅对滑窗范围内token做attention,大幅节省内存和计算资源。无缝连续性:token缓存+重新引入机制保证长时序视频“无断帧、无闪烁”,时序感极强。Streamer极大提升了DiT类模型在流式、长内容、实时视频生成上的可用性,为AIGC落地带来新可能。本研究提出了基础性视频生成模型 Wan,并在多个
摘要
本报告介绍了Wan——一个全面且开放的视频基础模型套件,旨在推动视频生成的前沿发展。Wan基于主流的扩散-Transformer范式,通过一系列创新(包括我们新提出的时空变分自编码器(VAE)、可扩展的预训练策略、大规模数据整理和自动化评测指标)在生成能力上取得了重大突破。这些贡献共同提升了模型的性能和多样性。
Wan有四大核心特性:
-
领先的性能:Wan的14B参数模型在包含数十亿图像和视频的大规模数据集上训练,验证了视频生成中模型规模和数据规模的扩展规律。在多项内部和外部基准测试中,Wan持续超越现有开源模型和最先进的商用解决方案,显示出明显的性能优势。
-
全面性:Wan提供了1.3B和14B两个参数规模的模型,分别兼顾效率和效果。模型支持多种下游应用,包括图像转视频、指令引导的视频编辑和个性化视频生成,共覆盖八大任务。同时,Wan是首个能够生成中英文视觉文本的模型,极大提升了其实用价值。
-
消费级高效:1.3B模型在资源效率上表现出色,仅需8.19 GB显存,即可适配多种消费级GPU。其性能甚至超越更大参数量的开源模型,在文本生成视频任务上展现了非凡的高效性。
-
开放性:Wan全系列模型及源码均已开源,旨在推动视频生成社区的发展,极大拓展行业创作空间,并为学术界提供高质量的视频基础模型。
此外,我们对Wan的各个方面进行了广泛的实验分析,并给出了详细的结果与洞察。我们相信这些发现和结论将显著推动视频生成技术的发展。全部代码与模型可在 https://github.com/Wan-Video/Wan2.1 获取。
引言
自OpenAI发布Sora(2024)以来,视频生成技术受到了业界和学术界的高度关注,推动了该领域的快速进步。能够生成媲美专业制作内容的视频模型的出现,大大提升了内容创作的效率,同时降低了视频制作的成本。视频生成技术的迅速发展同样也得益于开源社区的蓬勃发展。像HunyuanVideo(Kong等,2024)、Mochi(GenmoTeam,2024)和CogVideoX(Yang等,2025b)等知名项目都将其视频基础模型的代码和权重公开,从而逐渐缩小了开源模型与商用模型之间的差距。
然而,需要正视的是,这些优秀开源模型与最新闭源模型之间仍存在明显差距,主要体现在三个方面:
-
性能不足:商用模型的开发进度远快于开源模型,导致性能上有明显的优势。
-
能力有限:大多数基础模型仅限于一般的文本生成视频(T2V)任务,而视频创作的需求是多样化的,基础T2V模型难以满足这些复杂需求。
-
效率不高:尽管部分开源模型性能和规模可观,但对算力要求过高,普通创作团队难以承受,限制了其可访问性和实用性。
这些挑战共同限制了开源社区的持续创新和发展。
为应对上述挑战,本文提出并公开了一系列高性能的基础视频生成模型——Wan,旨在为该领域树立新的标杆。Wan的核心设计灵感来源于Diffusion Transformer(DiT)(Peebles & Xie, 2023)与Flow Matching(Lipman等,2022)相结合的架构,这一框架在文本生成图像(T2I)和文本生成视频(T2V)任务中通过大规模扩展展现出了显著的性能提升。在此架构下,模型采用交叉注意力机制嵌入文本条件,并对模型设计进行了细致优化,以保证算力效率和文本可控性。为进一步提升模型对复杂动态的捕捉能力,Wan还引入了完整的时空注意力机制。
经过大规模实验验证,Wan模型参数规模达到了140亿(14B)。训练数据包含了数十亿图像和视频,总计大约数万亿token。如此大规模的训练促进了模型能力的涌现,使其在多个维度(如运动幅度与质量、视觉文本生成、镜头控制、指令遵循和风格多样性)上表现出色。
在此基础上,我们进一步扩展了Wan的下游能力,支持图像转视频(I2V)、指令引导的视频编辑(V2V)、零样本个性化定制、实时视频生成、音频生成等多项关键应用。为了降低推理成本,我们还推出了1.3B和14B两个版本的模型,均支持480p分辨率,极大提升了推理效率。值得一提的是,1.3B模型仅需8.19GB显存,即可在许多消费级GPU上运行,且性能优于许多更大参数量的开源模型。
此外,我们将公开整个训练流程,包括大规模数据构建流程、视频VAE、训练策略、加速技术及自动化评测算法,以助力社区开发更具特色的基础视频模型。我们还将提供详尽的设计细节与实验结果,分享在资源密集型大模型训练过程中观察到的现象、关键发现及结论。我们相信,这些贡献将对加速视频生成技术的发展起到关键作用。
相关工作
在生成建模(generative modeling)技术进步的推动下,大规模视频模型领域发生了显著演变,尤其是在基于扩散(diffusion)的框架方面。我们的回顾主要聚焦于两大类:闭源模型和开源社区的贡献。
闭源模型
闭源模型主要由大型科技公司开发,旨在高质量、专业级视频生成,因为它们投入了大量资源。我们按时间顺序整理了过去一年发布的重要模型:
-
2024年2月,OpenAI推出了Sora(OpenAI, 2024),标志着AI生成内容的重大飞跃。
-
2024年6月,快手发布了Kling(Kuaishou, 2024.06),LUMA AI推出了Luma 1.0(LumaLabs, 2024.06),二者均向公众开放测试,具备强大视频生成能力。
-
同期,Runway发布了Gen-3(Runway, 2024.06),在前作Gen-2(2023)基础上进一步提升了视频创作水准。
-
2024年7月,深势AI(Shengshu AI)发布了基于自研U-ViT架构的Vidu(Bao等, 2024)。
-
2024年9月,Kling和Luma都升级到1.5版;MiniMax发布了Hailuo Video(MiniMax, 2024.09),带来了令人惊艳的视觉效果。
-
2024年10月,Pika Labs推出Pika 1.5(PikaLabs, 2024.10),允许用户自定义视频的视觉和物理属性;Meta则推出了Movie Gen(Polyak等),并详细披露了其训练和应用。
-
2024年12月,Kling更新到1.6版,谷歌则发布了Veo 2(DeepMind, 2024.12),其物理和人类运动理解能力进一步提升。
这些进展凸显了全球视频生成领域的激烈竞争。在此背景下,我们的开源Wan模型在多项内部和外部基准测试中表现出与上述商用模型媲美甚至超越的能力,并在多个属性上处于领先地位。
开源模型
另一方面,开源社区不仅推动了整体视频生成模型的发展,还深入探索了关键组件。基于扩散的视频生成模型通常基于Stable Diffusion(Rombach等, 2022)架构,主要包括三个核心模块:
-
自动编码器(autoencoder):将原始视频映射到紧凑的潜在空间;
-
文本编码器(text encoder):提取文本嵌入;
-
通过扩散模型优化的神经网络:学习视频潜在分布。
在网络结构方面,最初用于图像生成的U-Net(Ronneberger等, 2015)通过引入时间维度被应用到视频生成。VDM(Ho等, 2022)将2D U-Net扩展为3D版本;还有一类方法(Zhou等, 2022;Wang等, 2023a;Guo等, 2024b)通过将1D时间注意力与2D空间注意力模块结合,以减少计算成本。
值得注意的是,**Diffusion Transformers(DiT, Peebles & Xie, 2023)**完全基于Transformer结构,在视觉生成任务中优于U-Net(Chen等, 2023a)。这种结构也被引入视频模型(Ma等, 2024),常见有两种变体:原始DiT使用交叉注意力对文本嵌入,MM-DiT(GenmoTeam, 2024;Kong等, 2024)则将文本嵌入与视觉嵌入拼接进行全注意力处理。
自动编码器方面,早期采用标准VAE(Kingma, 2013),近期的VQ-VAE(Van Den Oord等, 2017)和VQGAN(Esser等, 2021)则改进了重建和压缩效果。LTX-Video(HaCohen等, 2024)则对VAE解码器做了创新,将最后去噪步骤和高频细节生成结合在一起。
文本编码器同样至关重要,目前主流视频生成模型主要使用T5系列(Raffel等, 2020),经常结合CLIP(Radford等, 2021)。如HunyuanVideo(Kong等, 2024)则用多模态大语言模型替代T5,实现更强的文本与视觉对齐。
通过结合这些关键模块和高效的扩散优化技术(Ho等, 2020;Song & Ermon, 2019;Lipman等, 2022),涌现出了众多有前景的开源视频生成模型(GenmoTeam, 2024;Kong等, 2024;HaCohen等, 2024;Zheng等, 2024;Lin等, 2024;Jin等, 2024;Yang等, 2025b)。在Wan中,我们对每个关键模块都进行了精心设计和选择,以保证高质量视频合成。我们还提供了详细的设计信息和消融实验,为未来视频生成模型的设计提供借鉴。
此外,大量研究聚焦于视频生成的下游任务,例如重绘(repainting)、编辑、可控生成和参考帧生成等,通常通过adapter或ControlNet结构实现用户自定义条件。我们也基于Wan开发了多种下游应用,表现优异。
数据处理流程
高质量的数据对于大规模生成模型的训练至关重要,而自动化的数据构建流程极大提升了训练效率。在构建我们的数据集时,我们坚持了三大核心原则:高质量、高多样性和大规模。遵循这些原则,我们精心筛选出由数十亿视频和图像组成的数据集。本节详细介绍了Wan所采用的数据构建流程。
预训练数据
我们从内部有版权的数据源和公开可获取的数据中筛选和去重,构建了候选数据集。在预训练阶段,我们的目标是从这批规模庞大但较为杂乱的数据中,选出高质量且多样性丰富的数据以便高效训练。在整个数据挖掘流程中,我们设计了一个四步数据清洗流程,重点关注基础维度、视觉质量和运动质量。随后,还将介绍构建视觉文本数据的处理流程。
基础维度(Fundamental dimensions)
基础维度的数据筛选框架侧重于源视频和图片的内在属性,从而能高效初步过滤掉所有不适合的数据。我们采用多维度的过滤方法,涵盖以下关键方面:
-
文本检测:通过轻量级OCR检测器,统计文本覆盖率,有效剔除包含过多文字的图片和视频,保证视觉清晰度。
-
美学评价:利用广泛使用的LAION-5B美学分类器,对图像做初步质量评估,快速滤除低质量数据。
-
NSFW评分:通过内部安全评估模型,对所有训练数据计算NSFW分数,系统性筛除不适内容。
-
水印与Logo检测:检测视频或图片中是否包含水印和logo,并在训练时进行裁剪。
-
黑边检测:利用启发式检测方法,自动裁剪无关黑边,保证内容聚焦。
-
过曝检测:用训练好的专家分类器评估并滤除色调异常的数据,确保训练集的视觉质量最优。
-
合成图片检测:实验证明即使少量(<10%)合成图片也会显著降低模型性能,因此我们训练了专家分类器专门剔除这类“污染”图片。
-
模糊检测:使用内部模型对训练素材分配模糊分数,系统性去除视觉不清晰内容。
-
时长与分辨率:对视频设置时长(须超过4秒)与分辨率门槛,不同训练阶段有不同标准,过滤低质量样本。
通过这些高效预处理策略,我们成功淘汰了约50%的初始数据集。保留的高质量数据将进入下一步更高级的语义驱动选择阶段进行进一步优化。
视觉质量(Visual quality)
这一步主要是从候选数据集中选择满足预训练标准、且质量较高的数据。要求这些数据视觉效果好、整体分布应贴近自然数据。在此过程中分为两步:
-
聚类(Clustering):先将所有数据按特征聚成100个小群,每个群单独处理。好处是能防止长尾分布下某些稀有但重要的数据被整体淘汰,保持原始数据多样性和完整性。每个群体都会按比例选取一部分数据进入下一步。
-
打分(Scoring):为每个视频或图像分配一个质量分数,便于后续各阶段筛选。具体做法是:每个聚类中抽样一定量数据进行人工打分(1分为最差,5分为最好),然后用人工标注的数据训练专家评估模型,最后该模型给全量数据赋分。
运动质量(Motion quality)
运动质量评估的目标,是挑选出自然、完整且具有显著运动的视频,同时避免静态或抖动的视频内容。我们将视频数据的运动质量分为六个等级:
-
最优运动(Optimal motion):此级别的视频具有最佳特征,如显著的运动布局、视角、幅度,以及流畅、干净的运动画面。
-
中等质量运动(Medium-quality motion):这类视频有明显的动作,但可能存在一些小问题,如多主体或部分遮挡。这类数据保证了运动的多样性,有助于模型更好地理解时空关系,适合用于预训练。
-
静态视频(Static Videos):主要包括访谈、聊天类的视频,虽然运动信息很少,但画质高。因此,需要单独识别出来,降低采样比例,防止影响整体运动建模。
-
摄像机主导运动(Camera-driven Motion):如航拍等以镜头移动为主、主体运动较少的视频。这类内容和静态图片类似,在采样时会大幅降低优先级。
-
低质量运动(Low-quality Motion):此类视频往往包含过多主体、严重遮挡或主体不清晰(如拥挤街景等),对训练效率和运动生成质量有负面影响,因此被排除。
-
抖动镜头画面(Shaky camera footage):如业余视频中明显的抖动,常伴随运动模糊和前景/背景难以区分,这类视频会被系统性地剔除。
视觉文本数据(Visual text data)
此外,我们还引入了一种创新的数据处理方法,以增强Wan在视觉文本生成方面的能力。该方法分为两个分支,分别提升文本渲染的准确性和和谐美观:
-
一方面,我们合成了数亿张带有中文字符的图片,这些字符被渲染在纯白背景上,增强模型对字符形状的学习能力。
-
另一方面,我们从海量真实数据中收集大量含文本的图片,通过多种OCR模型准确识别图片和视频中的中英文文本,再将提取出的文本输入到多模态大语言模型Qwen2-VL中。Qwen2-VL会根据图片内容和文本生成自然描述,确保描述中尽可能包含准确的文本信息。
通过上述流程,我们收集了大量真实的图文对。将合成数据和真实数据共同用于预训练,使得模型在生成视频中文字时,能精准还原罕见词汇的字形,且文本极具真实感,Wan在视觉文本生成方面表现出显著优势。
后训练处理
后训练的核心目标,是通过高质量数据进一步提升生成视频的视觉逼真度和运动动态表现。在该阶段,我们针对静态数据和动态数据采用了不同的处理策略:图片数据主要优化视觉质量,视频数据则重点提升运动质量。
图片处理(Image processing)
从高分图片数据池中,我们进行了进一步筛选,挑选出在质量、构图和细节等方面表现最优的样本。具体包括两种方式构建精编数据集:
-
专家模型筛选(expert-based collection):利用专家模型预测的分数,选取排名前20%的图片。对这部分数据,还考虑风格和类别,保证数据分布多样性。
-
人工收集(manual collection):人工从不同类别和数据源中收集顶级图片,并补充数据集中缺失的概念,从而增强模型的泛化能力。
通过上述方法,我们总共收集了数百万张精编高质量图片。
视频处理(Video processing)
在视频处理阶段,我们采用与图片类似的策略,收集高质量视频。具体做法为:
-
首先,利用视觉质量分类器从候选数据集中筛选出顶级视频;
-
然后,再用运动质量分类器,分别选出数百万个简单运动视频和数百万个复杂运动视频。
-
所有视频的选择都注重类别均衡和高度多样性。
-
同时,我们从包括科技、动物、艺术、人类、交通工具等在内的12个主要类别中进行数据选取,以提升模型在常见类别下的生成能力。
密集视频标注
虽然我们的数据集中,许多图片和视频都包含了原网页的文本描述,但这些描述往往过于简略,难以准确传达丰富的视觉内容。DALL-E 3(Betker等,2023)的研究表明:如果用高度细致的生成型视觉描述(dense caption)来训练视觉生成模型,模型对指令的跟随能力会大幅提升。因此,我们开发了内部的标注模型,为每一张图片和每一个视频生成密集标注(dense captions)。为了训练这个标注模型,我们结合了开源视觉-语言数据集和自建采集的数据集。
开源数据集
我们收集了广泛使用的图像和视频的视觉-语言数据集,包括各种标注数据集以及关注视觉内容(如动作、计数、OCR等)的视觉问答数据集(visual Q&A datasets)。在某些场景下,我们还要求caption模型根据用户指令生成特定风格或内容的caption,因此我们还采集了纯文本的指令数据,以增强模型的指令跟随能力。
自建数据集
我们自建数据集,覆盖多个任务,以提升模型在特定领域的能力:
-
名人、地标和影视角色识别
-
为了让模型能识别名人、地标和电影角色,我们收集了成千上万身份的数据。首先,利用大语言模型(LLMs)收集人物/地标/角色名称,然后用类似CLIP的模型在图文数据库中检索对应图片。经过多模型测试,发现TEAM(Xie等,2022)在识别个体(尤其是中国名人)方面表现优异。为了进一步降噪,我们还做了关键词匹配,只有TEAM模型检索到且描述匹配关键词的图片才被保留。
-
-
目标计数
-
为了提升模型的视觉计数能力,我们通过检索带有如“一、二、三”等数字描述的图片,构建了计数数据集。这些数字为图片提供了粗略注释。之后用LLM从文本中提取(类别,数量)对,最终用Grounding DINO检测实际图像中的数量。只有文本描述和Grounding DINO结果一致的图片才被保留。
-
-
OCR
-
为了提升模型的文本描述能力,我们构建了带OCR信息的图像标注数据集。先用现成OCR检测器提取图片文本,再用caption模型结合OCR结果生成图片描述。目前仅支持中英文。
-
-
镜头角度与运动
-
我们发现当前多模态大模型(MLLMs)在预测镜头角度和运动(包括GPT-4o、Google Gemini Pro等SOTA模型)方面表现有限。为此,我们手工标注了一批视频的镜头角度与运动。这套数据既可直接用于最终训练阶段,也可用于训练专家模型,对更多数据进行自动标注。该数据集提升了模型对运动和角度描述的准确性,增强了生成模型的镜头运动可控性。
-
-
细粒度类别识别
-
为了增强模型对如动物、植物、车辆等细分类别的识别能力,我们构建了包含数百万相关类别图片的数据集。
-
-
关系理解
-
通过收集专注于空间关系(如左、右、上、下)的数据集(多来源于现有目标检测数据),提升模型空间关系理解能力。
-
-
再标注(Re-caption)
-
标注模型一个重要能力是将已有标签或简短说明扩展为密集描述。为此,我们整理了一个再标注数据集,指导模型根据图片内容将简要标签扩展成详细描述。
-
-
编辑指令标注
-
收集描述两张图片间差异或变换的数据集,这类标注对图像编辑任务有较高价值。
-
-
组图描述
-
构建了一个组图描述数据集,每个标注先描述组图的共性特征,再分别用相似语言描述各个图片。
-
-
人工密集标注
-
收集了人工标注的图片和视频密集描述,这些是我们质量最高的标注数据,用于模型训练的最终阶段。
-
模型设计
架构(Architecture)
我们的标注模型采用类似 LLaVA(Liu等, 2023c)的架构。具体做法是:
-
使用 ViT(视觉Transformer)编码器提取图像和视频帧的视觉特征(embedding)。
-
这些视觉特征通过一个两层感知机投影后,输入到 Qwen 大语言模型(QwenTeam, 2024)中。
对于图像输入,借鉴了 LLaVA 的“动态高分辨率”机制。一张图片最多可以被分割成七个patch,每个patch自适应池化为12×12的特征网格,从而降低计算量。
对于视频输入,我们以每秒采样3帧,最多不超过129帧。为了进一步减小计算量,采用“慢-快编码策略”(slow-fast encoding):每隔4帧保留原始分辨率,其余帧则将embedding做全局平均池化。长视频基准实验表明,这一机制能在有限视觉token下提升模型理解力(如在VideoMME基准上无字幕时性能从67.6%提升至69.1%)。
训练(Training)
借鉴最新SOTA方法,训练过程分为三阶段:
-
第一阶段,ViT和LLM参数冻结,仅训练多层感知机(MLP),让视觉特征对齐到LLM输入空间,学习率为1e-3。
-
第二阶段,全部参数参与训练,LLM和MLP的学习率为1e-5,ViT为1e-6。
-
第三阶段,用一小批高质量数据做端到端训练,进一步提升模型表现,学习率同第二阶段。
评估
自动评估对于标注模型的开发非常关键,有助于发现不同版本模型的优劣。我们借鉴CAPability(Liu等, 2025b),开发了一套自动化的标注评估流程。
在视频生成领域,我们关注十个核心视觉维度:
-
动作(action)
-
摄像机角度(camera angle)
-
摄像机运动(camera motion)
-
物体类别(object category)
-
物体颜色(object color)
-
物体计数(object counting)
-
OCR文本
-
场景(scene)
-
风格(style)
-
事件(event)
每个维度都随机抽取1000个视频及其模型生成的标注,同时用Google Gemini 1.5 Pro为这些数据生成密集标注。最后,按照CAPability方法,分别对每个维度计算F1指标,评估我们和Gemini的结果。
评估显示:
-
我们的标注在视频事件、摄像机角度、摄像机运动、风格和物体颜色等维度优于Gemini;
-
Gemini在动作、OCR、场景、物体类别和物体计数方面表现更好。
模型设计和加速
时空变分编码器(Spatio-Temporal Variational Auto encoder)
变分自编码器(VAE,Wu等,2024;Blattmann等,2023;OpenAI,2024)在从高维视觉数据(尤其是视频)中学习紧凑的潜在表示方面发挥着关键作用,这有助于实现生成模型(如扩散模型)的高效和可扩展训练。
然而,针对视频生成任务设计高效的VAE面临多重挑战:
-
空间和时间维度耦合:视频本身同时具有空间和时间两个维度,因此VAE需要能捕捉复杂的时空依赖关系。
-
高维度带来的资源消耗:视频数据维度极高(多帧+高分辨率像素),这大幅提升了内存占用和计算开销,导致VAE难以扩展到长视频序列。
-
时间因果性约束:为了生成真实且连贯的视频,必须确保“时间因果性”(即未来帧不能影响过去帧),而实现这一点会使模型结构更加复杂。
为了解决上述难题,我们提出了一种新颖的三维因果VAE架构(Wan-VAE),专为视频生成任务设计。我们结合了多种策略(Wu等,2024)来提升时空压缩效率、减少内存占用,并确保时间因果性。通过这些改进,Wan-VAE不仅更加高效和易扩展,也更适合与基于扩散的生成模型(如DiT)集成。
接下来,我们将介绍Wan-VAE的网络结构、训练细节、高效推理方式以及实验对比结果。
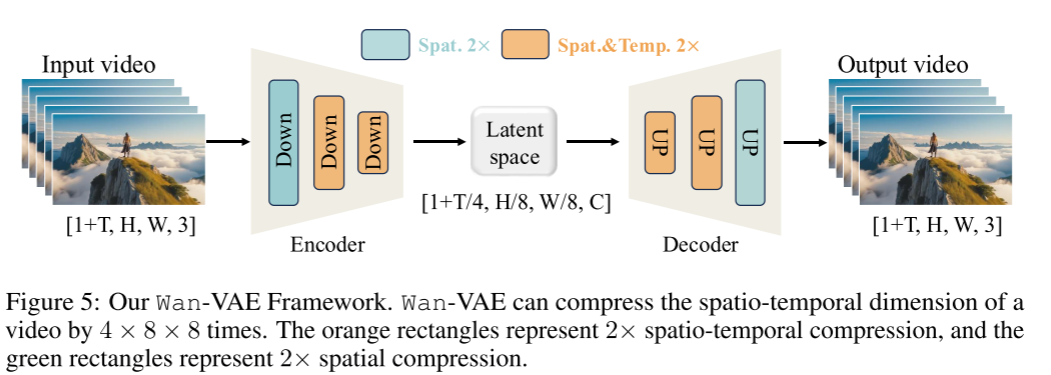
模型设计
为了在高维像素空间与低维潜在空间之间实现双向映射,我们设计了一个三维因果VAE(如图5所示)。给定输入视频 V ∈ R<sup>(1+T)×H×W×3</sup>,Wan-VAE 会将其时空维度压缩到 [1 + T/4, H/8, W/8],同时将通道数C扩展到16。具体来说,第一帧只做空间压缩,以便更好地处理图像数据(参考 MagViT-v2, Yu等, 2023)。
在架构设计方面,我们用RMSNorm层(Zhang & Sennrich, 2019)替换了所有GroupNorm层(Wu & He, 2018),以保证时间因果性。这一改变还使得可以引入特征缓存机制(见4.1.3节),大幅提升推理效率。此外,在空间上采样层中输入特征通道数减半,使得推理阶段的显存占用减少了约33%。
通过精细调节基础通道数,Wan-VAE最终模型参数量仅为127M,模型非常紧凑,有效降低了编码时的时间和内存消耗,对后续扩散Transformer模型训练大有裨益。
训练
Wan-VAE的训练分为三步:
-
图像VAE预训练:首先,构建一个结构相同的二维图像VAE,在图像数据上进行训练。
-
“膨胀”成3D视频VAE: 将训练好的2D图像VAE“膨胀”为3D因果Wan-VAE,为后续视频建模提供空间压缩的先验。相比于直接从零开始训练视频VAE,这大大加快了训练速度。在此阶段,Wan-VAE使用低分辨率(128×128)、帧数较少(5帧)的视频进行训练,以加快收敛。
训练损失包括:L1重建损失、KL损失和LPIPS感知损失,它们分别由系数3、3e-6和3加权。最后,我们对具有不同分辨率和帧数的高质量视频的模型进行微调,整合GAN损失。
高效推理
为了高效支持对任意长度视频的编码与解码(Yang等, 2025a;Yao等, 2021),我们在Wan-VAE的因果卷积模块中实现了特征缓存机制(feature cache mechanism)。
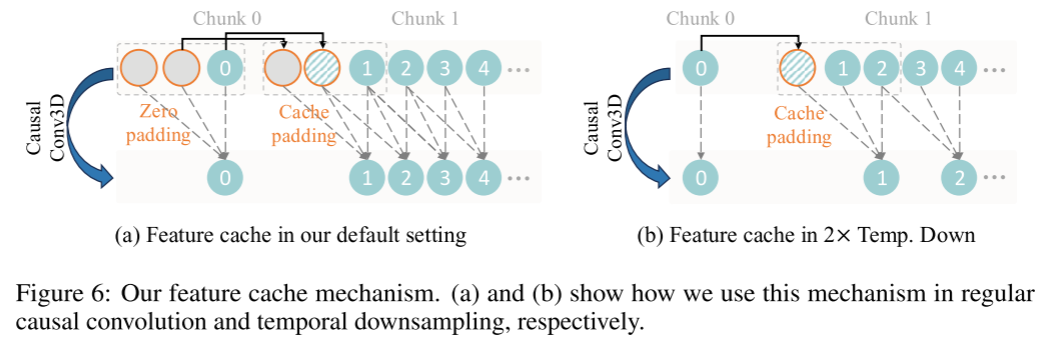
具体来说,视频序列帧的数量遵循1 + T的输入格式,因此我们将视频划分为1 + T/4个小段(chunk),与潜在特征的数量一致。在处理输入视频序列时,模型采用“分段策略”:每次编码和解码仅处理一个小段,对应一个潜在特征。根据时间压缩比,每个处理块最多包含4帧,这样可以有效防止内存溢出。
为确保上下文片段(chunk)之间的时间连续性,模型会战略性地缓存前一段的帧级特征。这些缓存特征会被系统性地集成到后续片段的因果卷积计算中。具体流程如图6所示,分为两种典型场景:
-
场景a(默认设置):因果卷积不改变帧数(卷积核大小为3),需要缓存历史的两个特征帧。对于第一个片段,采用零填充两个虚拟帧来初始化缓存。后续片段则重复利用上一片段最后两帧作为缓存,并丢弃更早的历史数据。
-
场景b(2倍时序下采样):即stride=2时,下采样后缓存管理不同。此时,仅对非初始片段进行单帧缓存填充,以确保维度一致。这样可以保证输出序列长度严格符合下采样比例,同时维护分段间的因果关系。
这种特征缓存机制不仅优化了内存利用,还保持了分段间特征的连贯性,从而实现了对无限长视频的稳定高效推理。
评估
定量结果(Quantitative results)
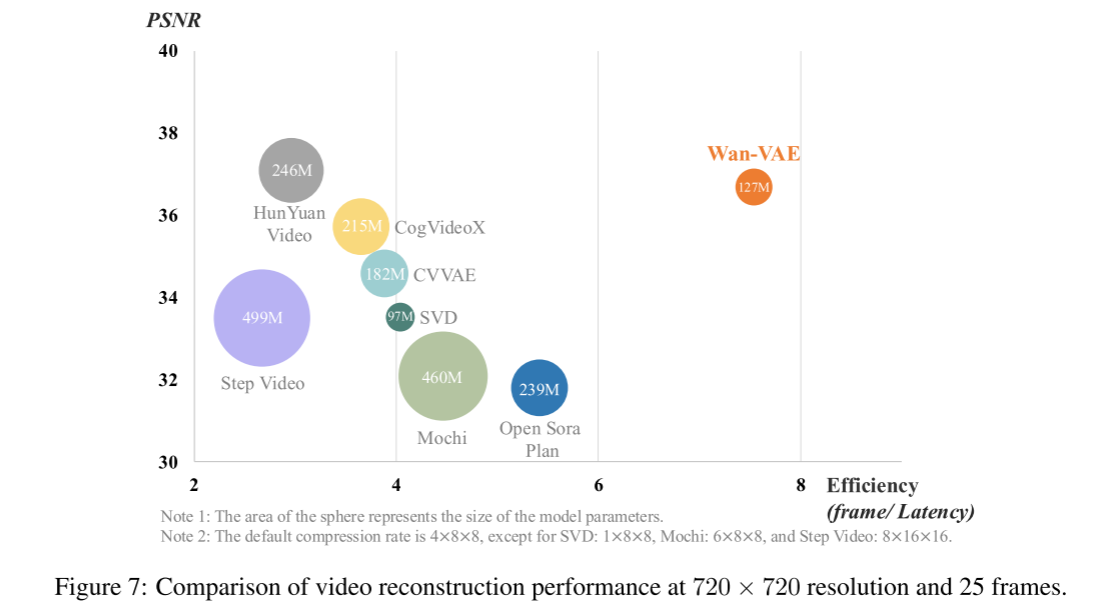
本研究通过分析峰值信噪比(PSNR)和处理效率(单位延迟每秒处理帧数,frame per second latency),对多种主流SOTA视频VAE模型(Kong等, 2024;Yang等, 2025b)进行了全面性能评测。为了公平对比,大部分模型(Kong等, 2024;Yang等, 2025b)采用与本方法相同的压缩率和潜在特征维度,即压缩率为4 × 8 × 8,潜在维度为16。Open Sora Plan(Lab & etc., 2024)压缩率与我们一致,潜在维度为4;SVD(Blattmann等, 2023)压缩率为1 × 8 × 8,潜在维度为4;Step Video(Ma等, 2025)为8 × 16 × 16,潜在维度为64;Mochi(GenmoTeam, 2024)为6 × 8 × 8,潜在维度为12。
评测在200个视频上进行,这些视频均为25帧,分辨率为720 × 720。图7中,圆圈大小与模型参数量正相关。
实验结果显示,Wan-VAE在视频质量(PSNR)和处理效率两项指标上均表现出极强竞争力,兼具高视频质量和高处理效率。值得注意的是,在相同硬件环境下,我们的VAE重建速度比现有SOTA方法(如HunYuan Video)快2.5倍。由于模型体积小和特征缓存机制,这一速度优势在更高分辨率下会更加突出。
这种进步为视频重建任务和视频生成训练提供了高效解决方案。这些结果不仅验证了所提模型设计的有效性,也为VAE技术未来发展提供了有价值的参考。
定性结果(Qualitative results)
为验证方法在多样场景下的视频重建表现,图8给出了在纹理、面部、文本和高速运动场景下的可视化效果。与现有VAE模型相比,Wan-VAE在这些场景中均表现出更优效果。例如:
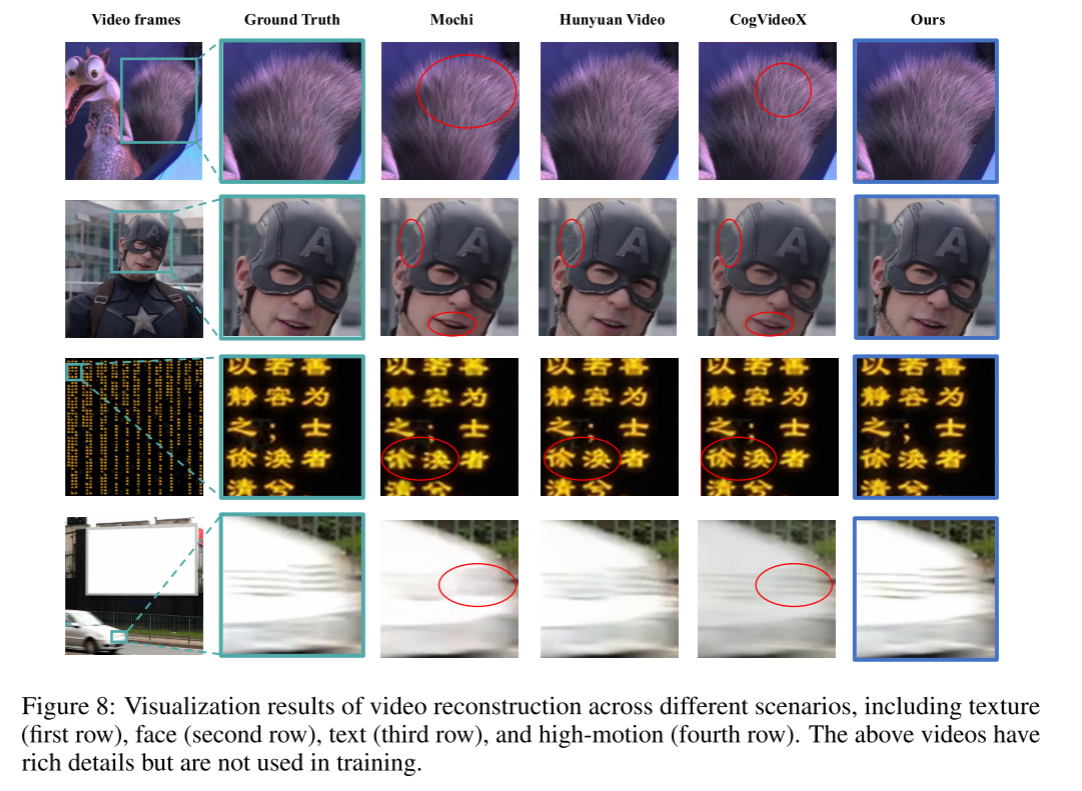
-
纹理场景(第一行):Wan-VAE能更准确捕捉细节,如头发的纹理与方向;
-
面部场景(第二行):Wan-VAE在保留面部特征的同时,减少了嘴唇区域的模糊与失真;
-
文本场景(第三行):Wan-VAE能清晰还原文本内容,有效减缓字符失真和丢失问题;
-
高速运动场景(第四行):Wan-VAE保持了视频帧的运动清晰度。
这些结果说明,Wan-VAE在处理多种复杂场景时具有显著优势。
模型训练
本节将详细介绍我们基础视频模型的架构设计,尤其聚焦于文本生成视频(text-to-video, T2V)任务,同时给出预训练和后训练阶段的细节。
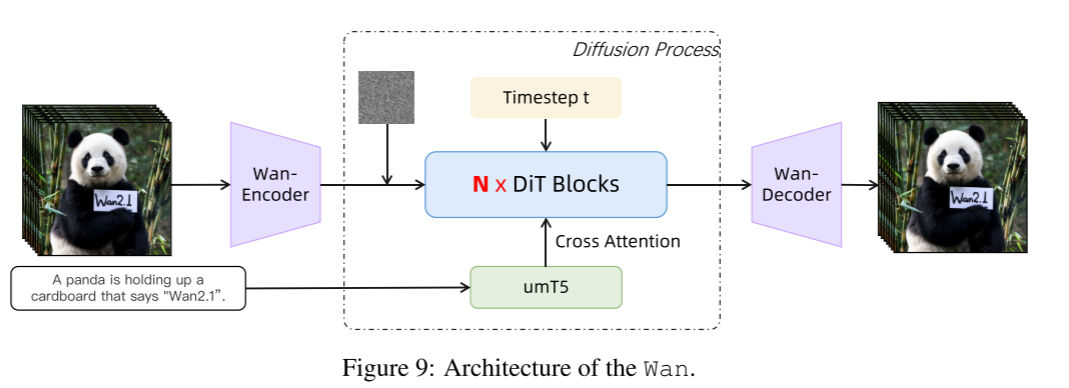
如图9所示,Wan模型的架构基于当前主流的DiT(Diffusion Transformer,Peebles & Xie, 2023)结构,通常包括三个主要组成部分:
-
Wan-VAE:用于对视频数据进行潜在空间编码。
-
扩散Transformer(Diffusion Transformer):实现生成建模和时空内容合成。
-
文本编码器(Text Encoder):对输入文本进行嵌入,作为条件控制生成过程。
对于给定的视频 V ∈ R^(1+T)×H×W×3,Wan-VAE的编码器会将其从像素空间映射到潜在空间 x ∈ R^(1+T/4)×H/8×W/8,随后输入到扩散Transformer进行后续处理和生成。
视频diffusion Transformer
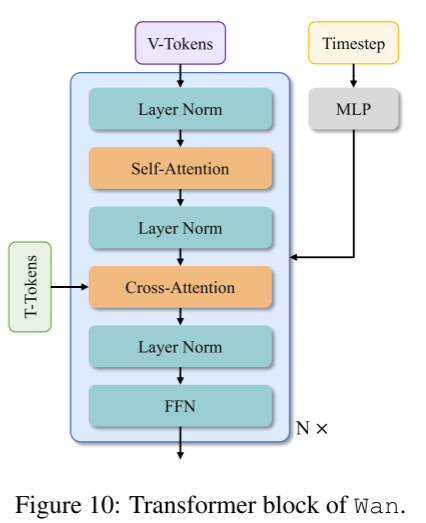
扩散Transformer(Diffusion Transformer)
扩散Transformer主要由三个部分组成:patchify模块、Transformer块 和 unpatchify模块。每个Transformer块的核心在于如何高效建模时空上下文关系,并在此基础上嵌入文本条件和时间步信息。
-
patchify模块
-
使用一个3D卷积,卷积核大小为(1, 2, 2),然后做flatten操作,将输入x转换成形状为 (B, L, D) 的特征序列。
-
B:batch size
-
L = (1 + T/4) × H/16 × W/16 (即时空降采样后的序列长度)
-
D:潜在特征维度
-
-
-
跨注意力机制(cross-attention)
-
如图10所示,模型通过跨注意力嵌入输入文本条件,这样即使在长上下文场景下也能很好地理解和跟随指令。
-
同时,使用带有Linear层和SiLU激活的MLP,对输入的时间步嵌入进行处理,预测6个调制参数(modulation parameters)。
-
这个MLP在所有Transformer块中共享,但每个块学习不同的偏置(bias)。实验表明,这样设计可以减少约25%参数量,并在相同参数规模下显著提升性能。
-
文本编码器(Text Encoder)
Wan模型采用umT5(Chung等, 2023)作为文本编码器。通过大量实验发现,umT5具有以下优势:
-
强大的多语言编码能力:能够同时理解中英文以及视觉文本输入。
-
写作能力更强:在同等条件下,umT5在内容组织上优于其他单向注意力机制的大模型。
-
收敛速度快:相同参数规模下,umT5的收敛更迅速。
因此,最终选择umT5作为文本嵌入器。
预训练
我们采用flow matching 框架(Lipman等, 2022; Esser等, 2024)对图像和视频领域建模,实现统一的去噪扩散过程。预训练阶段,首先在低分辨率图像上训练,然后通过多阶段的图像-视频联合优化,逐步提升数据分辨率与时间跨度,实现图像与视频模态的融合训练。
训练目标
flow matching 提供了一个理论严谨的框架,用于在扩散模型中学习连续时间的生成过程。它避免了传统的“逐步速度预测”,可通过常微分方程(ODE)实现稳定训练,并且与最大似然目标等价。
训练流程如下:
-
对于给定的图像或视频潜在变量x₁、随机噪声x₀ ~ N(0, I)、以及从logit-normal分布采样的时间步t∈[0,1],构造中间潜变量xₜ,作为训练输入。
-
按照Rectified Flows(RFs, Esser等, 2024),xₜ是x₀与x₁的线性插值:
xₜ = t * x₁ + (1 - t) * x₀ -
真正的速度(ground truth velocity)为:
vₜ = dxₜ/dt = x₁ - x₀ -
模型的任务是预测该速度,损失函数为模型输出与vₜ的均方误差(MSE):
L = E_{x₀,x₁,cₜₓₜ,t} [||u(xₜ, cₜₓₜ, t; θ) - vₜ||²]其中,cₜₓₜ是umT5文本编码后的512-token序列,θ为模型参数,u(xₜ, cₜₓₜ, t; θ)为模型预测的速度。
图像预训练
实验分析表明,直接用高分辨率图片和长视频序列联合训练有两大难点:
-
序列长度过长(如1280×720视频通常81帧)会大幅降低训练吞吐量。在固定GPU资源下,数据利用率低,模型收敛变慢。
-
显存消耗巨大,导致batch size被迫减小,进而引发梯度方差剧增、训练不稳定。
为解决这些问题,14B模型的训练首先以低分辨率(256px)文本-图像对做预训练,强制模型实现跨模态语义-文本对齐和几何结构学习,然后再逐步引入高分辨率视频模态。
图像-视频联合训练
在大规模256px文本-图像预训练后,采用分阶段分辨率提升的课程式训练,逐步联合优化图像和视频数据。具体三阶段:
-
阶段一:用256px分辨率的图片和192px分辨率、5秒(16帧/秒)的视频片段做联合训练。
-
阶段二:分辨率提升到480px(图片和视频均为480px,5秒),保持视频时长不变。
-
阶段三:图片和视频都升级到720px分辨率,视频片段仍为5秒。
预训练配置
-
精度:采用bf16混合精度高效训练
-
优化器:AdamW(weight decay=1e-3)
-
学习率:初始1e-4,当FID和CLIP Score评价指标遇到plateau(无提升)时自动减小。
后训练
在后训练阶段,我们保持与预训练阶段相同的模型结构和优化器配置,直接用预训练得到的权重进行初始化。随后,在480px和720px分辨率下,利用第3.2节介绍的后训练视频数据集,进行联合训练优化。
模型缩放和训练效率
工作负载分析
在Wan模型中,文本编码器和VAE编码器带来的计算开销远低于DiT(Diffusion Transformer)主模型。DiT模型在训练期间占据了85%以上的总体计算量。
对于DiT模型,其主要的计算开销可用以下表达式表示:
L(αbsh² + βbs²h),其中:
-
L:DiT层数
-
b:微批次(micro batch size)
-
s:序列长度(token数)
-
h:隐藏层维度
-
α:线性层的计算系数
-
β:注意力层的计算系数
-
对于Wan采用的非因果注意力机制(non-causal attention),前向计算时β=4,反向传播时β=8。
-
与普通大模型(LLM)相比,Wan处理的序列长度经常高达几十万甚至百万级。因为注意力机制的计算量随着token数量呈二次增长,而线性层仅线性增长,所以注意力机制逐渐成为训练瓶颈。当序列长度达到100万时,注意力计算能占到端到端训练时间的95%。
训练时,只优化DiT主模型参数,文本编码器和VAE编码器均冻结,因此GPU显存主要集中用于DiT训练。DiT的GPU显存使用量可表达为γLbsh,其中γ与DiT层的实现有关。由于视频token、输入提示、时间步等都会作为模型输入,γ的值通常比普通LLM更大(普通LLM的γ约为34,DiT模型可超过60)。
举例:序列长度100万,微batch=1,14B参数规模的DiT模型,激活值所需总GPU显存可超过8TB!
总结:
Wan模型的主要计算瓶颈在注意力机制。
-
计算量随序列长度二次增长
-
显存消耗仅随序列长度线性增长
这为后续的优化(如稀疏注意力、分布式训练等)提供了重要参考。
并行化策略
Wan模型主要由三个模块组成:VAE、文本编码器和DiT。
按照4.1.3节介绍的缓存机制优化,VAE模块几乎不占用GPU显存,可以直接采用数据并行(DP, Data Parallelism)。
而文本编码器需要超过20GB显存,因此需用**模型权重切分(参数分片)来节省后续DiT模块的显存空间。为此,我们采用数据并行(DP)+ 完全分片数据并行(FSDP, Fully Sharded Data Parallel)**的组合策略。
DiT模块的模型参数、梯度和优化器状态超出单卡容量,在1M token、batch=1时,激活值存储可达8TB。且DiT占据绝大部分计算工作量。因此我们重点为DiT模块开发高效的分布式训练方案。
DiT并行策略
-
DiT模型本身参数量适中,但为了优化计算与通信重叠、放大数据并行规模,我们优选FSDP作为参数分片方案。
-
DiT块的输入形状为 [b, s, h](b是并行数据批次,s是序列长度,h是隐藏维度),因此需要考虑s和h两个维度的切分策略。
-
s维度的切分称为上下文并行(CP, Context Parallelism),典型方法有Ulysses和Ring Attention。h维度切分则主要依赖Megatron的张量并行(TP, Tensor Parallelism)+ 序列并行(SP, Sequence Parallelism),通过权重切分对隐藏单元分片。
-
因为CP的通信开销小于TP+SP,我们建议采用CP来加速批级计算,并降低每张卡的激活显存。
我们设计了二维(2D)CP,结合了Ulysses和Ring Attention的优点(类似USP方案),外层采用Ring Attention,内层用Ulysses,既减少了Ulysses跨机通信慢的问题,也解决了Ring Attention切分后块太大的问题,实现内外层通信与计算最大重叠。
在序列长度为256K,2台机器16块GPU的场景下,2D CP将通信开销由Ulysses的10%+降到1%以下。
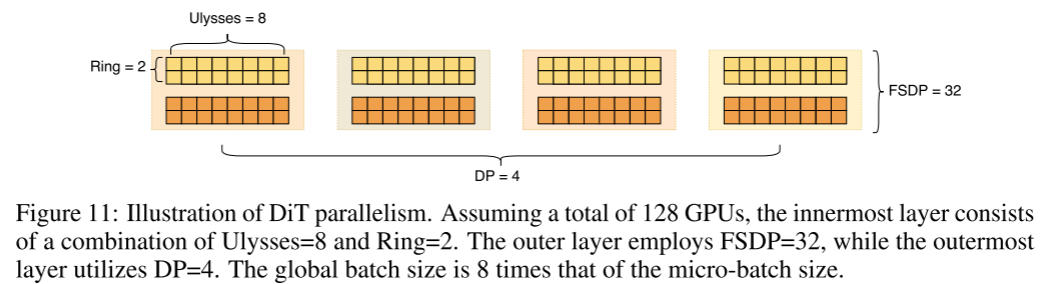
FSDP组与CP组的关系:
FSDP组和CP组在FSDP组内部有交集,DP规模等于FSDP规模/CP规模。在满足显存和单批次延迟要求后,用DP做扩展。
例如,128卡配置下,CP规模为16(Ulysses=8,Ring Attention=2),FSDP=32(批量=2b),DP=4(全局批量=8b)。分布式方案见图11。
不同模块的分布式策略切换
-
训练时,不同模块共用同一批硬件资源。
-
VAE与Text Encoder采用DP;DiT模块采用DP+CP。
-
当VAE与Text Encoder输出要送入DiT时,必须切换分布式策略以避免资源浪费。
-
CP要求CP组内设备读同一批数据。但如果VAE和Text Encoder也都读取相同数据,则造成冗余计算。
-
优化方案:CP组内设备先分别读取不同数据,再在CP前遍历CP组,顺序广播各自读取的数据,确保CP内部输入一致。这样,VAE和Text Encoder的每轮迭代时间比例降为1/CP,有效提升整体训练性能。
内存优化
如前所述,Wan模型的计算开销随序列长度 s 的平方增长,而GPU内存消耗仅随 s 线性增长。这意味着在长序列场景下,计算时间最终会超过通过PCIe总线转存激活(activation)的数据传输时间。具体来说,转存一个DiT层激活到CPU的PCIe传输时间,可以与1至3个DiT层的计算过程重叠。相比于梯度检查点(GC, Chen等, 2016),允许与计算重叠的激活转存(activation offloading, Rhu等, 2016),可以在不影响端到端性能的情况下,显著降低GPU内存使用。因此,我们优先采用激活转存技术来降低显存占用。
考虑到在长序列场景下,CPU内存同样容易耗尽,我们进一步结合激活转存与梯度检查点策略。具体做法是:优先对那些GPU显存占用与计算量比值较高的层采用梯度检查点,平衡各类内存资源压力。
集群可靠性
我们利用阿里云的智能调度、慢节点检测和自愈机制,确保训练集群的高稳定性。硬件故障在作业启动阶段就能被识别,确保只有健康节点被分配给训练任务。训练过程中,任何出现故障的节点会被迅速隔离和修复,任务会自动重启,训练可无缝恢复。通过高效编排,Wan集群在保证可靠性的同时也兼顾了高性能,保障了整体系统的稳定运行。
推理
推理优化的主要目标是最小化视频生成的延迟。与训练不同,推理阶段需要多次采样(通常约50步),因此我们采用量化(quantization)、分布式计算等技术,减少每一步的耗时。此外,还利用前后采样步中注意力机制的相似性,进一步降低整体计算负载。同时,在无分类器引导(CFG, classifier-free guidance, Ho & Salimans, 2022)下,充分利用推理过程的内部相似性,进一步减少计算量。
并行策略
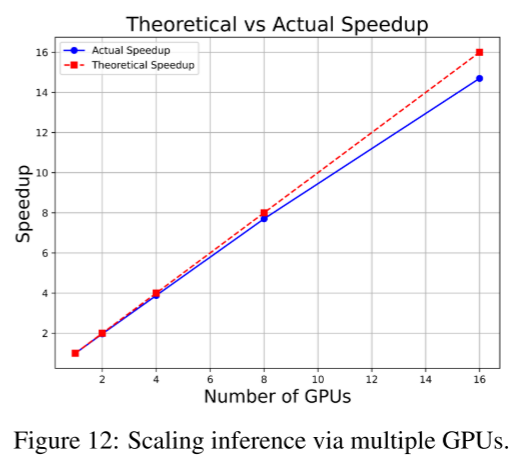
正如4.3.2节所述,为加速单个视频的生成(特别是在多GPU环境下),我们采用上下文并行(Context Parallel, CP)。
对于Wan 14B这样的大模型,为了突破GPU显存限制,还采用了模型切分(Model Sharding)。
-
模型切分(FSDP):
鉴于推理阶段序列长度很长,完全分片数据并行(FSDP)比张量并行(TP)通信开销更小,还可实现计算与通信重叠。因此,推理阶段同样采用FSDP做模型切分,与训练阶段策略保持一致。 -
上下文并行(2D Context Parallelism):
推理阶段同样采用二维上下文并行:外层为Ring Attention,内层为Ulysses,具体方案与训练一致。
这样,DiT在Wan 14B模型上实现了近乎线性加速(即GPU数提升,推理速度成正比提升),如图12所示。
扩散缓存
我们对Wan模型的推理过程进行了深入分析,发现如下特征:
-
注意力相似性:在同一个DiT(Diffusion Transformer)块内,不同采样步的注意力输出高度相似。
-
CFG相似性:在采样的后期阶段,带条件(conditional)和无条件(unconditional)DiT输出也表现出明显的相似性。
这些结论在近期的研究(如DiTFastAttn, Yuan等, 2024b,FasterCache, Lv等, 2024)中也得到了强调。我们利用这些特性,为Wan模型设计并实现了扩散缓存(diffusion cache),以降低推理阶段的计算负担。
具体实现方式:
-
注意力缓存:对于注意力模块,每隔几步执行一次attention前向计算,并将结果缓存下来,其余步复用缓存结果。
-
CFG缓存:对于无条件分支,每隔几步做一次DiT前向推理,其余步复用条件分支的结果。此外,为防止细节损失,还引入类似FasterCache的残差补偿机制。
我们在验证集上自动选择合适的缓存步数,确保缓存操作对模型性能无损。
在Wan 14B文本生成视频模型上应用扩散缓存后,推理性能提升了1.62倍。
量化
FP8 GEMM(矩阵乘法)
我们发现,在采样步骤中,所有GEMM(通用矩阵乘法)操作采用FP8精度,并对权重做每张量(per-tensor)量化,对激活做每token(per-token)量化,几乎不会带来性能损失。因此,我们对DiT模块所有GEMM操作都应用FP8量化。
FP8 GEMM的性能是BF16 GEMM的两倍,使DiT模块推理速度提升了1.13倍。
8位FlashAttention
虽然FlashAttention3(Shah等, 2025)原生FP8版本有极高性能,但我们实验发现其在视频生成中的质量下降明显。而SageAttention(Zhang等, 2024)采用int8+fp16混合精度以减少精度损失,但并未对NVIDIA Hopper架构GPU特别优化。报告发布时,SageAttention已通过后续优化提升了Hopper兼容性,未来我们会尝试整合这些新特性。
我们对FA3-FP8实现做了多项数值稳定性与性能优化。
精度优化
-
混合8位量化(Mixed 8-Bit Optimization):FA3原生用FP8(E4M3)处理所有输入(Q, K, V),我们参考数据分布和SageAttention经验,采用混合量化:
-
Int8 用于 S=QK<sup>T</sup>
-
FP8 用于 O=PV
-
-
FP 32累积用于跨块减少。本机FP 8 WGMMA实现采用14位累加器,因此在长序列处理期间容易溢出。为了解决这一限制,我们的方法利用FP 8 WGMMA来减少块内PV,同时通过具有Float 32寄存器的CUDA核心实现跨块累积,这是一种受DeepSeek-V3启发的策略(Liu et al.,2024 a)FP 8 GEMM方法。
性能优化
-
Float32累加与intra-warpgroup流水线融合:FlashAttention3用intra-warpgroup流水线并行WGMMA、softmax和缩放。为防止Float32 PV跨块累加带来的性能损耗,我们将Float32累加与rescale操作融合,实现极致并行。
-
块大小调优:因为Float32累加带来额外寄存器压力,我们调整block size,避免寄存器溢出,提升利用率。
优化后,我们的8位FlashAttention在NVIDIA H20 GPU上实现了95% MFU(最大硬件利用率)。
因此,8位FlashAttention将推理效率提升了1.27倍以上。
Prompt对齐
提示词对齐的目的是提升模型推理效果,让用户输入的prompt(提示词)与训练阶段采用的caption格式和风格保持一致。我们采用了两大核心策略:
-
多样化caption增强:为每个视频配备多种风格、长度的caption,提升数据多样性。
-
用户prompt重写:用大语言模型(LLM)对用户prompt进行改写,使其分布更贴合训练阶段的caption分布。
多样化caption增强
为适应不同用户输入风格,每张图片或每段视频都配备了多种caption,包括不同长度(如长、中、短)和不同风格(如正式、口语化、诗意等)。这样能有效覆盖用户可能输入的各种prompt形式,让模型学会不同风格、不同抽象层次下“文本到视频”的多样映射关系。
用户prompt重写
尽管训练集caption多样且较长,但真实用户往往更倾向于输入几词短语或简洁句子,导致分布不匹配,影响生成效果。为此,我们引入LLM对用户输入进行“对齐式重写”,核心目标是让用户输入分布与训练caption分布一致,从而提升模型推理和生成质量。

-
重写流程:
-
LLM在不改变原意的基础上,给prompt补充细节,增强生成画面的完整性与观感。
-
重写的prompt需包含自然动作属性,根据主体类别补充合适动作,使生成视频中的运动更加流畅自然。
-
建议重写prompt的结构与后训练caption一致:先描述视频风格,再给出内容摘要,最后进行详细描述,实现高质量caption分布对齐。
-
我们在自有基准测试集上评估了LLM辅助的prompt重写效果(部分结果见Tab. 1)。结果表明,具备强指令理解与生成能力的LLM可生成更适合视频生成的prompt,从而提升生成质量。为平衡推理速度与表现,我们采用Qwen2.5-Plus作为改写模型。
Benchmarks
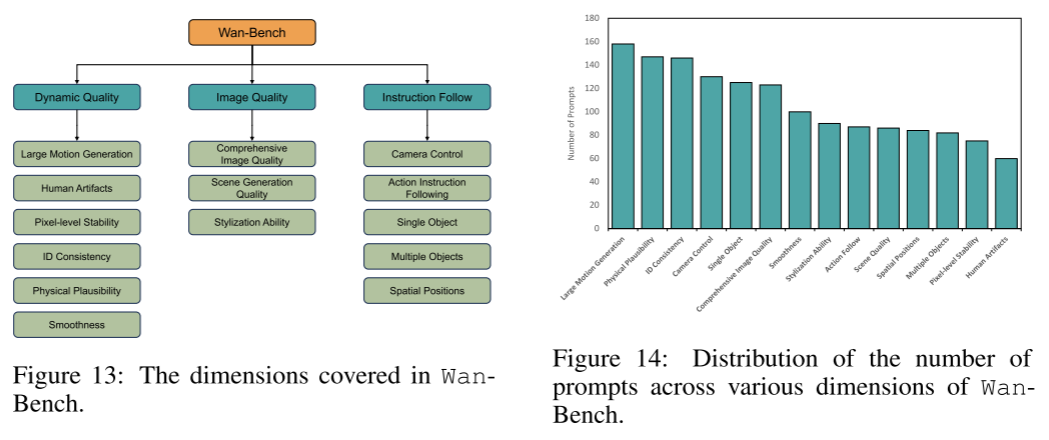
现有视频生成评价指标,如Fréchet Video Distance (FVD, Unterthiner等, 2018) 和 Fréchet Inception Distance (FID, Heusel等, 2017),与人类主观感知存在较大偏差。为此,我们提出了一套自动化、综合且与人类主观对齐的评测体系——Wan-Bench,用于评价视频生成模型。
Wan-Bench包含三大核心维度:动态质量、图像质量、指令遵循性,共设有14项细粒度评价指标。每个维度下我们都设计了专门的评分算法,简单任务采用传统检测器,复杂任务则利用多模态大模型(MLLM)。
动态质量(Dynamic quality)
衡量模型在非静态场景下的运动生成质量与稳定性,包含以下子指标:
-
大幅运动生成(Large motion generation)
为测量模型运动生成能力上限,设计鼓励大运动的prompt,用RAFT (Teed & Deng, 2021) 计算生成视频的光流,并以归一化光流幅值评估运动得分。 -
人造伪影检测(Human artifacts)
现有方法难以检测AI生成内容的伪影。我们用YOLOv3 (Redmon & Farhadi, 2018) 在2万张人工标注AI图像上训练,识别伪影位置。得分综合预测概率、框位置及持续时长。 -
物理合理性与运动流畅性(Physical plausibility & smoothness)
-
物理合理性:设计与物理相关的prompt(如弹跳、物体交互、水流等),用Qwen2-VL(Bai等, 2023)等视频问答大模型,检测如物体穿模、异常碰撞、违背重力等现象。
-
流畅性:用复杂运动prompt,Qwen2-VL自动识别运动中的伪影,评价运动流畅程度。
-
-
像素级稳定性(Pixel-level stability)
检查视频中是否频繁出现噪点。用光流识别静态区域,对比这些区域帧间像素差。若稳定,差值应较小。 -
ID一致性(ID consistency)
包括“人物一致性”、“动物一致性”、“物体一致性”,分别对应不同的prompt集合。用帧级DINO特征(Caron等, 2021)计算帧间相似度,作为一致性分数。
图像质量(Image quality)
图像质量评测维度主要用于衡量生成视频的视觉质量和审美感受。
1. 综合图像质量(Comprehensive image quality)
-
真实性(清晰度、无伪影)
用MANIQA (Yang等, 2022) 检测模糊和伪影,精准衡量清晰度。 -
审美分数
使用LAION美学打分器(LAION-AI, 2022)和MUSIQ (Ke等, 2021) 两大模型,分别对画面进行美学评估。 -
最终分数
以上三者(MANIQA、LAION-AI、MUSIQ)的结果取平均,作为最终图像质量分数。
2. 场景生成质量(Scene generation quality)
-
帧间场景一致性
连续帧用CLIP相似度(Radford等, 2021)衡量,确保时间上的连贯性。 -
场景-文本对齐
每一帧与其对应文本caption做CLIP相似度,检验语义准确性。 -
质量综合分
两项指标加权平均,得出场景生成分数。
3. 风格化能力(Stylization)
-
用Qwen2-VL大模型,通过帧级问答评估视频的艺术风格生成能力。
指令遵循性(Instruction following)
该维度用于评估模型理解和执行文本指令的能力,主要包括:
1. 单目标、多目标与空间位置
-
利用Qwen2-VL大模型预测视频中的目标类别、数量和空间关系。
-
指标为“与prompt描述准确对应的帧的平均占比”,即生成视频中有多少帧准确还原了用户指令。
2. 摄像机控制(Camera control)
-
评测5种常用摄影机运动:平移、升降、拉近/拉远、航拍和跟拍。
-
针对平移、升降、拉近/拉远这三类,利用RAFT(光流分析)识别运动方式是否符合prompt要求。
-
对于更复杂的航拍和跟拍镜头,采用Qwen2-VL通过视频问答自动判别镜头运动类型。
3. 动作指令遵循(Action instruction following)
-
将运动分为人类(如跑步)、动物(如爬行)、物体(如飞行)三类。
-
对于这些需要先验知识的运动类别,给Qwen2-VL输入关键帧,问答判断动作是否与文本匹配、动作是否完整、是否有运动伪影等,从多维度综合评估文本与视频的一致性。
人工反馈引导的加权策略(Human feedback guided weighting strategy)
-
不同评价维度对用户体验影响不同,不宜简单平均。我们通过人工反馈数据赋予每个维度不同权重。
-
具体做法:收集5000多组不同模型生成的视频“对比打分”,让用户基于同一文本指令标注偏好,并给出分数。
然后计算各评价维度与人工打分的Pearson相关系数,以此作为权重,融入最终综合得分。
评估
指标和结果
基线模型与评价指标
截至目前,市场上存在多种主流竞品,包括商业模型(如Kling、Hailuo、Sora、Runway、Vidu)以及开源模型(如Mochi、CogVideoX、Hunyuan)。本节将Wan模型与已通过权威基准测试、获得较好用户反馈的商用和开源模型进行对比。
定量结果(Quantitative results)
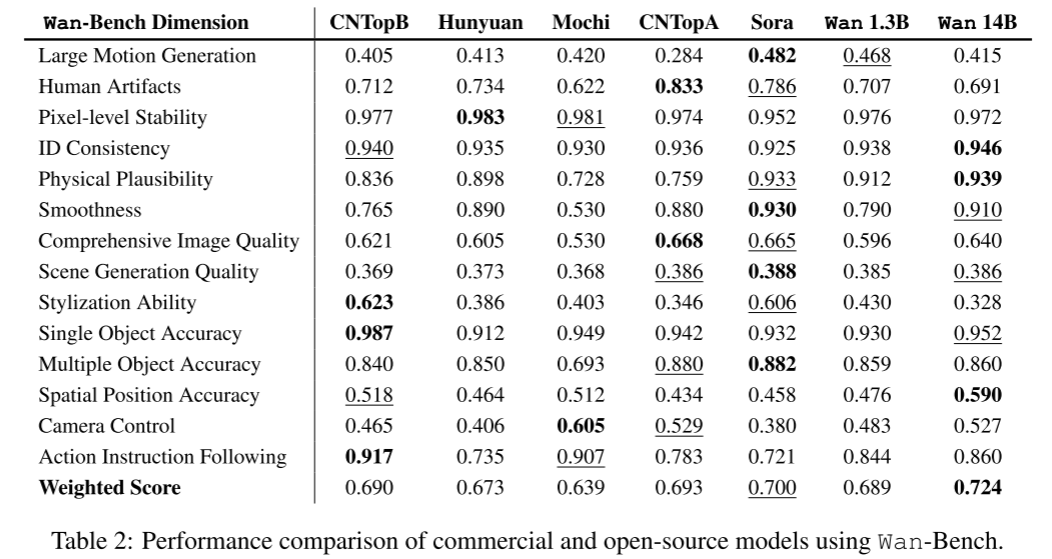
我们为每个候选模型采集了1035个样本,全部使用Wan-Bench中的prompts进行标准化测试,并按Wan-Bench三大核心指标(动态质量、图像质量、指令遵循性)进行公平打分。最终得分结合用户偏好(见4.6节)做加权排名。结果显示(见表2),Wan模型全面超越现有商用与开源模型。
定性结果(Qualitative results)
如图15所示,Wan可直接从文本描述生成多样化、高质量的视频。其擅长合成包含大幅度复杂运动的动态场景,以及高度物理交互的情境。同时,Wan支持丰富的艺术风格、能稳定生成电影级画面,还具备强大的中英文多语言视觉文本生成能力,能在动画中自然融合中英文字,呈现出“电影字幕级”效果。

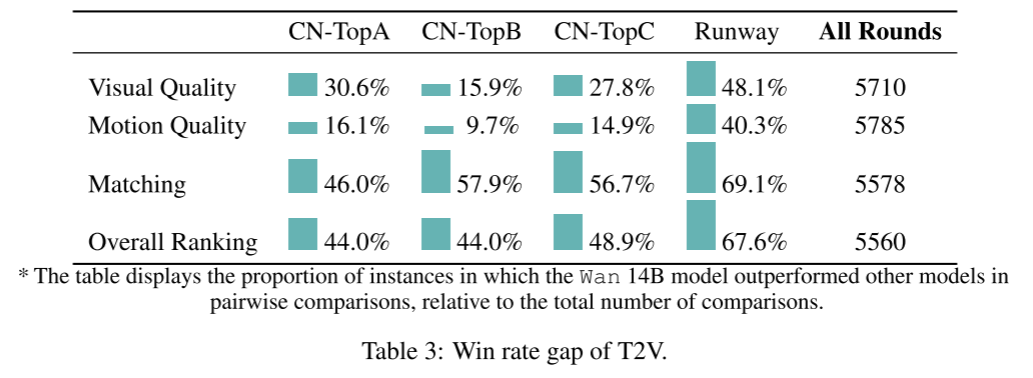
人工评价(Human evaluation)
我们设计了700多个评测任务,由20余人对每个模型从对齐性、图像质量、动态质量、整体质量4个维度进行人工标注和综合评价。表3显示,Wan 14B模型在所有视觉质量维度上均持续领先,展现出卓越的T2V(文本生成视频)能力。
公共榜单表现(Wan in public leaderboard)
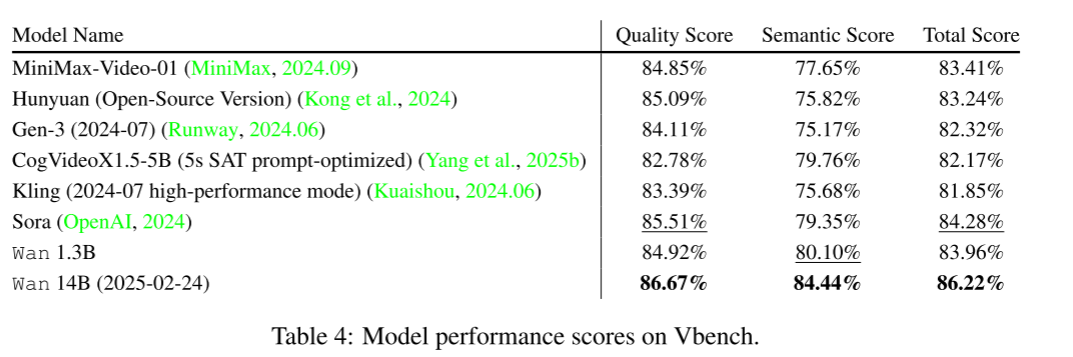
Wan在被广泛采用的视频生成评测基准VBench(Huang等, 2023)上也实现了SOTA(最优)表现。VBench共包含16个人类主观对齐的细分指标,覆盖审美、运动流畅性、语义一致性等。
Wan 14B和Wan 1.3B两个版本的榜单分数(见表4):
-
Wan 14B总分86.22%,视觉质量86.67%,语义一致性84.44%,大幅超越Sora(OpenAI)、Hailuo(MiniMax)等顶级竞品。
-
Wan 1.3B也极具竞争力,得分83.96%,超过了商用HunyuanVideo、Kling 1.0及开源CogVideoX1.5-5B等。
消融实验
我们对模型设计中的关键模块进行了消融实验,以分析各部分对整体性能的贡献。为提升实验效率,主要在1.3B版本上进行。
关于自适应归一化层的消融实验
在DiT(Diffusion Transformer)中,自适应归一化层(adaLN, Perez等, 2018)带来大量的参数开销。我们探究:是增加adaLN参数量,还是增加网络层数更有效?
为调整参数量,参照PixArt(Chen等, 2023a),我们对adaLN是否共享进行了消融实验:
-
非共享(non-shared):每个attention块的scale和shift参数由各自独立的MLP预测(输入为时间嵌入),参数量大。
-
共享(shared):只在第一个块预测一组全局scale/shift参数,所有块共享,大幅减少参数量(即PixArt里的AdaLN-single)。
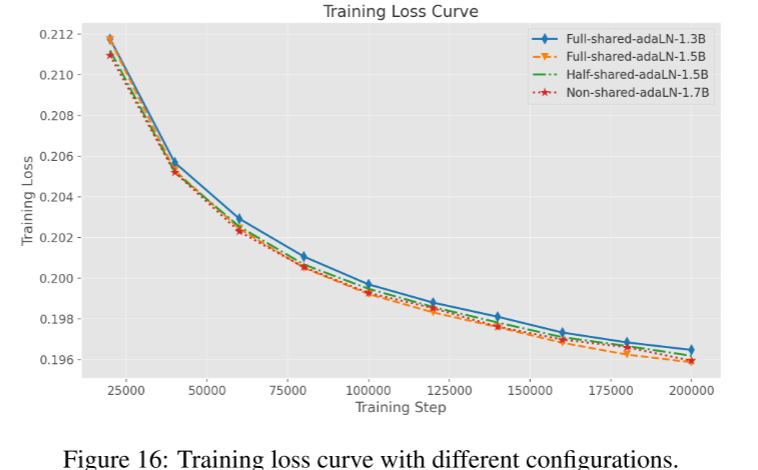
我们评估了4种配置:
-
Full-shared-adaLN-1.3B:全部30个注意力块共享同一套adaLN参数(即原始模型,参数最少)。
-
Half-shared-adaLN-1.5B:前15个块共享,后15个块独立,参数量为1.5B。
-
Full-shared-adaLN-1.5B(扩展版):全部共享,但把模型深度从30层加到35层,参数仍为1.5B。
-
Non-shared-AdaLN-1.7B:所有块的adaLN均不共享,深度仍为30层,参数增至1.7B。
其他参数均不变,从零训练模型200,000步,做text-to-image任务,全局batch为1536。比较指标为生成图像与真实图像在latent space的L2损失,损失越小表明收敛越好。
主要发现
-
Full-shared-adaLN-1.3B(最省参数)损失略高,但可接受。
-
Half-shared-adaLN-1.5B与Full-shared-adaLN-1.5B(参数量相同)相比,全共享+加深模型的Full-shared-adaLN-1.5B损失最低,即深度优先更有效。
-
Non-shared-AdaLN-1.7B(参数最多)反而效果并不如Full-shared-adaLN-1.5B。
-
结论:增加模型深度比单纯增大adaLN参数量更有用,全共享adaLN可大幅减小参数同时保持性能。
因此,最终模型采用完全共享的adaLN设计,实现了在显著减少参数量的情况下仍保持高性能。
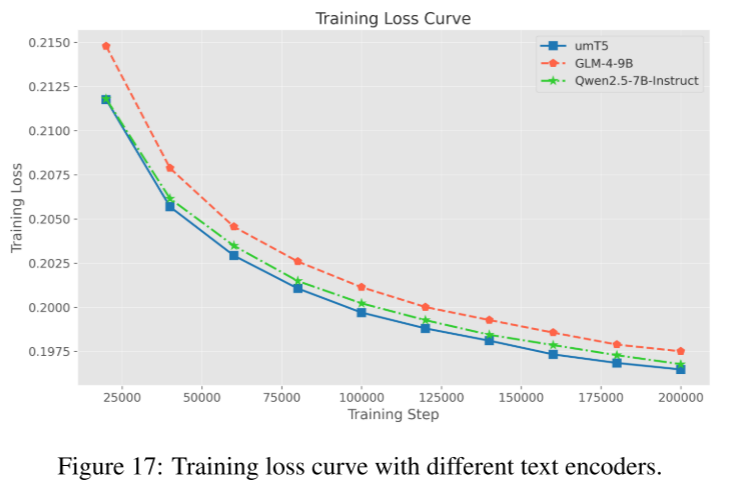
文本编码器消融实验
我们选取了三种可处理双语(中英文)输入的文本编码器进行对比:
-
umT5(Chung等, 2023,5.3B参数):T5系列在视频生成领域非常常见。
-
Qwen2.5-7B-Instruct(QwenTeam, 2024):在10B以下LLM中语言理解能力很强。
-
GLM-4-9B(TeamGLM等, 2024):同样以语言理解能力见长。
实验中其余设置保持不变,对三者分别进行text-to-image任务训练(全局batch=1536),其中Qwen2.5和GLM-4的文本特征取自倒数第二层。
训练过程以训练损失作为比较指标,见Fig. 17。
主要发现
-
与其他强大的LLM型编码器相比,umT5的文本特征表现更优(训练损失最低)。
-
Hunyuan-Video(Kong等, 2024)指出,decoder-only LLM(如Qwen、GLM)采用单向注意力,而umT5采用双向注意力,这对扩散模型尤其有利。
-
仿照HunyuanVideo策略,我们为Qwen2.5和GLM都加入了“双向token-refiner适配层”,但实际训练损失和生成效果依然是umT5最优。
-
进一步与多模态大模型Qwen-VL-7B-Instruct(Bai等, 2023)比较,发现用Qwen-VL倒数第二层特征生成效果接近umT5,但模型参数更大。

结论
-
umT5是当前最佳文本编码器选择,即使与专门适配的LLM或多模态大模型相比,也能兼顾性能与效率。
自动编码器

除了我们自研的VAE(变分自编码器)外,还设计了一个变体VAE-D,其区别是将重建损失(reconstruction loss)替换为扩散损失(diffusion loss)。我们分别用预训练的VAE和VAE-D进行text-to-image(文本生成图像)任务,训练15万步直至收敛。在第10万和15万步分别计算了FID分数(Fréchet Inception Distance,用于衡量生成图像与真实图像的距离,越低越好)。
结果如表5所示,VAE模型的FID分数始终低于VAE-D,说明在本任务和设定下,传统的重建损失更加有效。
扩展的应用
图像生成视频(I2V)
图像到视频(I2V,Image-to-Video)生成任务,指的是从静态输入图像出发,结合文本提示,合成出具有动态效果的视频序列。这种方法通过将生成结果锚定在指定的起始帧上,极大提升了视频生成的可控性,因此在学术界和工业界均备受关注。
现有方法(如I2VGen-XL、SVD、CogVideo等)通常是在T2V(文本生成视频)框架基础上,将“条件潜在表示”(来自输入图像)和噪声潜在变量在通道维度拼接,实现从图像出发的视频生成。
Wan-I2V模型也采用了类似策略,充分利用基础T2V模型中积累的先验知识,从而实现高质量的I2V生成效果。
模型设计
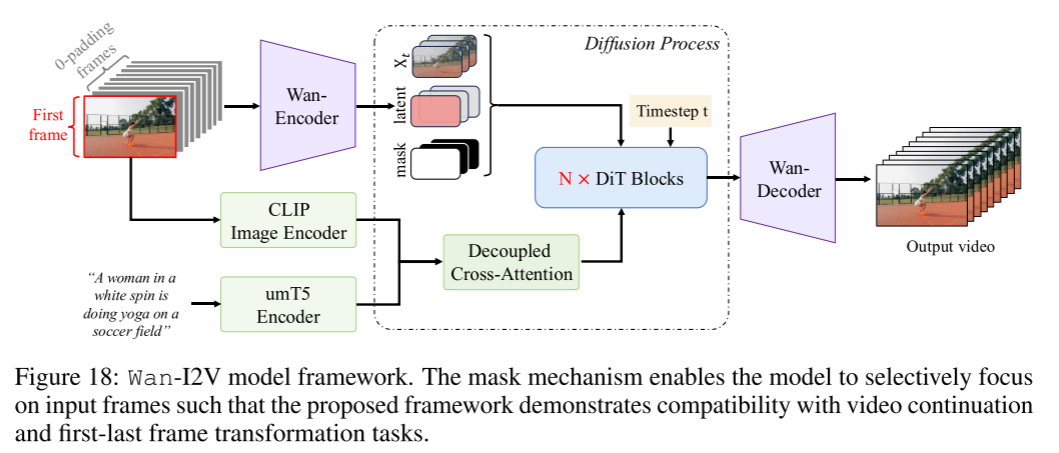
我们在视频合成过程中引入了一张条件图片,作为第一帧,用以控制视频生成的起点。具体方法如下:
-
条件帧与遮罩机制

-
通道拼接与模型输入

-
全局上下文信息
-
CLIP特征融合:用CLIP的图像编码器提取输入图像的特征,经三层MLP投影,得到全局上下文,作为解耦交叉注意力注入到DiT模型中,增强生成的全局一致性。
-
-
扩展与多任务训练
-
该机制可泛化至首-尾帧变换、视频续写等可控视频生成任务。
-
通过显式mask机制,模型能精准区分哪些帧是条件输入,哪些需要生成。
-
训练阶段,采用“多任务联合训练+单任务精调”策略:先用image-to-video、视频续写、首尾帧变换、随机插帧等任务做统一预训练,使模型掌握“mask理解能力”;再分别针对各单项任务做精细化微调。
-
数据集
在多任务联合训练阶段,I2V(图像生成视频)使用与T2V(文本生成视频)相同的训练集,使模型具备“以参考图像生成运动视频”的基础能力。精调阶段,则针对不同任务特点,构建专门的任务数据集。
图像生成视频(I2V)数据集
-
早期实验发现,训练集中首帧和视频内容差异越大,模型越难学到稳定的图像驱动视频生成能力。
-
因此,应选取首帧与后续视频内容高度相似的数据用于训练。
-
实现方法:用SigLIP(Zhai等, 2023)提取首帧与其余帧的特征,计算首帧与剩余帧平均特征的余弦相似度,只保留相似度高于阈值的视频。
视频续写(Video continuation)数据集
-
同样,训练用的连续性更强的视频有助于提升模型续写能力。
-
具体做法:分别提取视频首1.5秒和末3.5秒的SigLIP特征,计算二者的余弦相似度,根据分数筛选高一致性视频用于训练。
首尾帧变换(First-last frame transformation)数据集
-
不同于I2V任务,社区对首尾帧平滑过渡(如“图片变形过渡动画”)更感兴趣。
-
所以训练集需提升首尾帧变化较大的样本比例,让模型更好学会首帧到末帧平滑衔接和变化。
评估
I2V模型(包括首尾帧变换和视频续写任务)的训练分为两个阶段:
第一阶段:预训练
-
采用与T2V任务相同的数据集,帧数稍多。
-
此阶段不引入图像编码器分支,其动机是保证模型在视觉生成过程中能强对齐文本输入,保持对语义细节的敏感性。
-
预训练稳定后,模型已具备I2V生成、视频续写等多种能力,说明预训练为时空理解打下了坚实基础。
实证观察与问题
-
实际发现:仅靠帧级信息,无法在特定任务(如I2V、视频续写、首尾帧变换)取得最佳效果。
-
换句话说,预训练模型虽为基于帧的视频生成提供了基础,但在条件帧极少的情况下,模型仍难以捕获足够的上下文和语义,导致时序一致性欠佳。
第二阶段:监督微调(SFT)
-
针对上述问题,在SFT阶段引入图像编码器(如CLIP),通过解耦交叉注意力机制提取全局上下文特征(参考Ye等, 2023; Guo等, 2024a),增强模型的全局理解能力。
-
分别在480p和720p两个分辨率下,用不同checkpoint做I2V、视频续写、首尾帧变换等多任务训练。
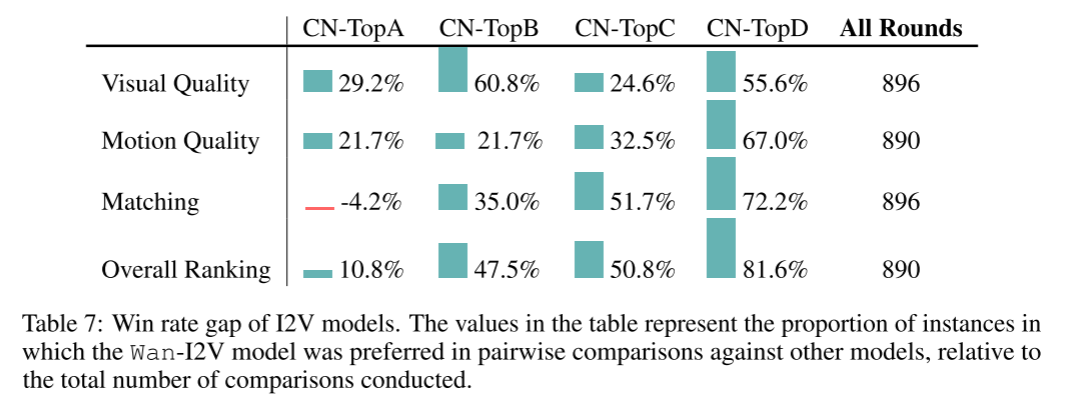
评测方式与结果
-
类比T2V模型的人类评价流程,对I2V模型也与业界最优技术做全方位对比,重点考察视觉质量、运动质量、文本匹配度等。
-
结果(表7)显示,Wan I2V模型在各项指标均表现优异。
-
图19、20给出了Wan I2V模型的更多可视化样例,直观展现了静态图片到高质量动画视频的强大表现。

统一视频编辑
基于文本生成图像(T2I)和文本生成视频(T2V)的基础大模型,为多种下游应用拓展打下了坚实基础,如重绘(repainting)、编辑(editing)、可控生成(controllable generation)、定制生成(customized generation)、帧参考生成(frame reference generation)、高效生成(efficient generation)、ID参考视频合成等。
为提升灵活性、降低多模型部署负担,研究者开始聚焦统一架构(unified model architecture)的开发,如ACE、OmniGen等,旨在用一套大模型兼容多种图像/视频编辑、合成、控制任务,便于打造多样化应用流程,并极大提升易用性。在视频领域,由于时间和空间上的协同变换,更适合用统一模型释放无限创意。
在我们此前的工作VACE中,提出了可控视频生成与编辑的统一框架,可同时实现参考视频生成、视频到视频编辑、带mask的视频编辑等。
本项目在Wan预训练大模型基础上,集成多模态输入(如图片、视频、编辑参考、mask等),统一输入到Video Condition Unit(VCU),支持多种格式。
VACE采用了“概念解耦策略”,能让模型自动判断哪些内容需保留、哪些需修改,编辑/参考信息各自独立,不混淆。
框架提供两种训练模式:
-
VCU输入+全模型微调:VCU为输入,直接全参数微调Wan模型,适合能力全面提升。
-
可插拔Context Adapter + Res-Tuning微调:只在主干外部加控制adapter,主模型参数不变,仅adapter参数可学习,虽然模型规模变大,但更灵活、更安全。
得益于Wan强大的视频生成能力,该统一编辑框架在定量与定性评测中均表现突出,可任意组合基础任务,支持如长视频重渲染等复杂场景。
因此,为用户驱动的视频内容创作和编辑,提供了高效、通用的解决方案,极大拓展了AI视频生成的应用边界。
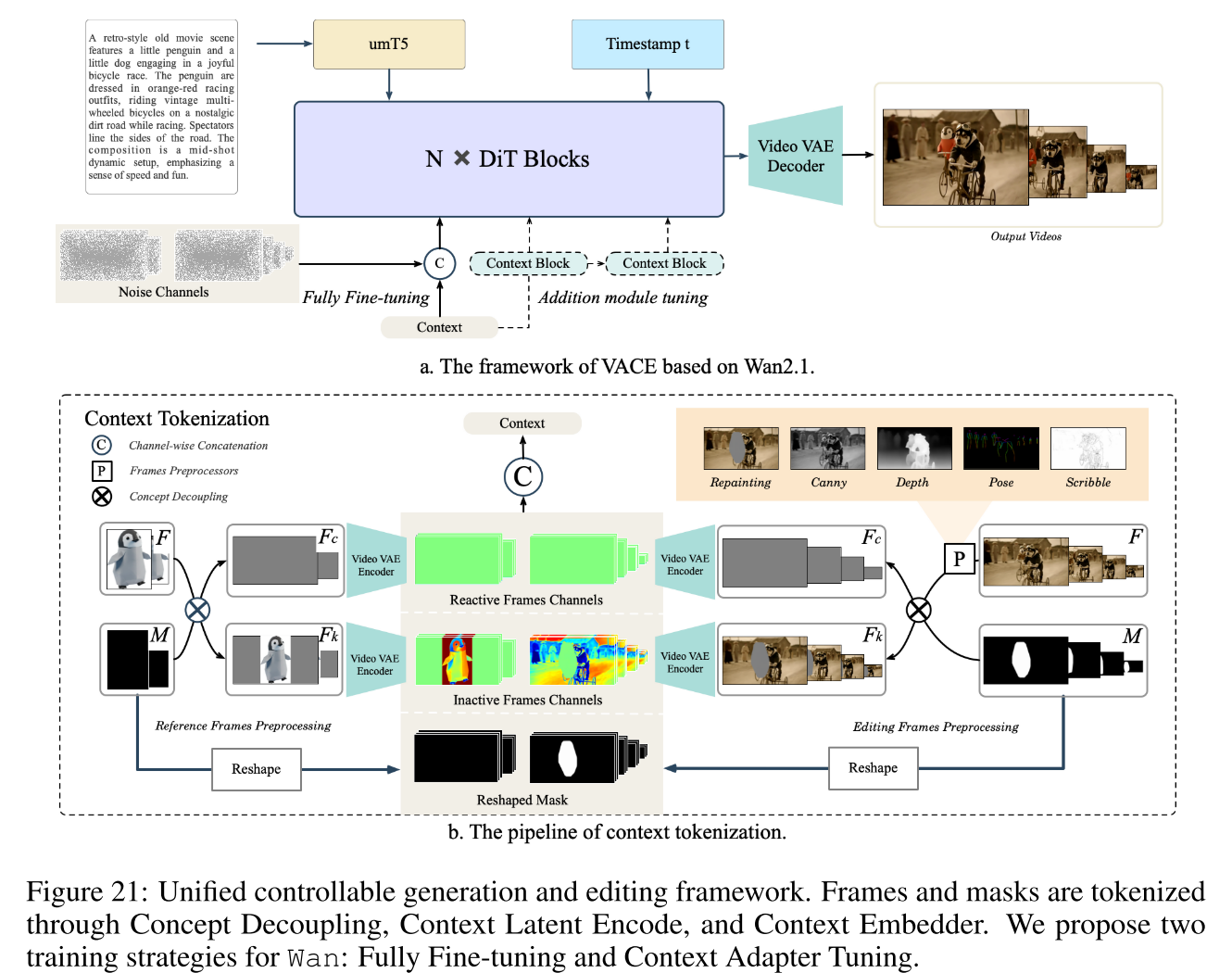
模型设计
视频条件单元(VCU, Video Condition Unit),最早在VACE中提出,是一种统一多种输入条件的输入范式。它将多样化的编辑、参考输入转换为文本输入(T)、帧序列(F)和遮罩序列(M)。
其形式化表达为:
V = [T; F; M]
-
T:文本指令(prompt)
-
F:上下文视频帧序列 {u₁, u₂, ..., uₙ}(RGB空间,归一化到[-1, 1])
-
M:mask序列 {m₁, m₂, ..., mₙ}(二值,1/0分别代表“编辑/不编辑”),F和M在时空维度(n, h, w)上完全对齐。
1. Token化与输入
-
利用Wan-VAE将输入的帧序列和mask信息编码为上下文token。
-
如Fig.21(a)所示,这些token与噪声视频token一起输入,对Wan模型进行微调。
2. Context Adapter Tuning 策略
-
支持上下文token流经Context Blocks后,重新集成回DiT主干网络,无需改动主模型权重,实现灵活编辑与扩展。
-
这样既能充分利用上下文信息,又不会影响大模型参数的稳定性。
3. 概念解耦与多模态融合
-
在token化之前,对原始帧和mask做概念解耦,即:
-
Fc = F × M:需要被编辑的像素(反应帧,mask=1区域)
-
Fk = F × (1-M):需要被保留的像素(静默帧,mask=0区域)
-
-
这样所有任务都能清晰定义“编辑/保留”区域,有利于模型区分不同任务,提高收敛速度和泛化性。
-
Fc、Fk经Wan-VAE编码,统一映射到latent空间X,保持时空一致性。
4. 图像/视频引用的处理
-
避免图片和视频混杂输入,参考图片单独编码,再在时间维拼接回主输入,解码时相应部分需剔除。
-
M遮罩直接reshape和插值,和latent对齐,最终保证上下文、遮罩、主干输入时空一致。
数据集和实现
数据构建
要训练一个全能型视频编辑/生成模型,数据的多样性和复杂性必须大幅提升。
-
针对可控视频生成和编辑任务,输入模态扩展为:目标视频、源视频、局部mask、参考帧等多种类型。
-
高效获取适用于多任务的数据,需要在保证视频质量的前提下,做实例级分析和理解。
-
具体流程:
-
切分镜头(shot slicing):将原始视频切成多个镜头片段。
-
初步过滤:根据分辨率、美学分数、运动幅度筛选优质片段。
-
目标检测与实例筛查:用RAM对第一帧做分割标注,再用Grounding DINO检测,去除目标区域过大或过小的视频。
-
实例分割传播:用SAM2实现全视频实例分割,获得每个目标的mask序列。
-
帧级有效性过滤:根据mask面积阈值计算“有效帧比例”,进一步保留高质量实例。
-
针对不同任务(如inpainting、参考帧编辑、组合任务等)制定不同的数据采样和构建策略。
-
实现细节
-
所有模型均以Wan-T2V-14B为预训练基础,支持最高720p分辨率,采用多阶段训练。
-
第一阶段:关注图像修复(inpainting)与扩展(extension),引入mask,发展时空上下文理解能力。
-
后续阶段:任务扩展到多输入参考帧,从单一到组合复杂任务。
-
最后阶段:用更高质量、时长更长的数据精调,进一步提升生成和编辑质量。
-
评测
-
Fig. 22, 23展示了Wan单一模型在多种任务上的生成结果,模型在视频质量与时序一致性上表现优异。






-
Fig. 24(a) 展示了通过不同生成能力组合带来的新应用场景,模型对这些新型任务的适应能力极强,表现出显著的扩展潜力。

-
Fig. 24(b) 还证明了VACE提出的统一可控生成与编辑框架不仅适用于视频,也同样适用于图像生成与编辑。
文本生成图像(T2I)
Wan模型不仅在视频生成领域表现出色,还通过联合图像与视频数据集的训练,实现了卓越的图像合成能力。
这种双模态联合训练策略,促进了跨模态知识迁移,使Wan在图像和视频生成两个方向都取得了优异的表现。
-
训练数据规模:模型所用图像数据集规模约为视频集的10倍,进一步强化了T2I和T2V任务间的协同效应。
-
实际效果:Wan可在多种场景下生成高质量图片,涵盖艺术风格文本图、写实肖像、创意设计以及专业产品摄影等多种类型(见Fig.25)。

视频个性化生成
视频个性化的目标是生成与用户提供的参考形象一致的视频,例如让AI视频持续保有指定人脸、角色等身份特征(参考文献:Wei等,Li等,Yuan等,2024-2025)。本节介绍了Wan模型集成的最新个性化技术,在业界表现出色,并详细阐述了模型架构、个性化数据和实验验证。
模型设计

技术挑战
-
个性化视频生成的核心难点有两个:
-
获取高保真个性身份特征;
-
将这些身份特征无缝融入视频生成流程。
-
方法设计
-
Wan-T2V基础上,首先获取个性化身份信息。
-
传统方法:
-
一类用ID特征提取器(如ArcFace)或通用视觉特征提取器(如CLIP),但ArcFace仅适合人脸识别,易受分辨率、光照、遮挡影响,且难以捕获如疤痕、贴纸等丰富视觉线索;
-
CLIP等通用提取器侧重粗语义信息,不擅长细粒度身份建模。
-
-
Wan方案:
-
完全不依赖额外特征提取器,直接在Wan-VAE的潜空间对输入人脸图像进行建模与条件控制,最大限度保留身份信息和个性细节。
-
个性特征注入方式
-
许多可行方法中,实验发现:
-
cross-attention适合融合稠密特征(如外部提取器输出)
-
self-attention更适合同空间内的信息交互,Wan采用后者。
-
-
具体做法:
-
在潜空间内,将K帧“参考人脸图像”拼接到目标视频的前面,所有帧尺寸、格式和视频一致;
-
每帧带有mask(前K帧为全1,后续帧为全0);
-
这些拼接信号作为“inpainting条件”输入扩散过程,模型学会用这K帧约束生成后续视频的身份一致性;
-
训练时,随机丢弃部分参考帧,支持“0~K帧参考”灵活个性生成;
-
推理时,将用户提供的人脸图像拼到前K帧,剩下由模型续写,确保“前K帧复现输入人脸,后续帧保持一致生成”。
-
数据集
我们从T2V基础模型的训练集,通过自动化筛选与合成,构建了大规模个性化数据集:
1. 原始数据筛选流程
-
首先用内部人脸分类器,从大约上亿(O(100)M)视频中过滤合适样本;
-
用人脸检测器对所有视频以1 FPS采样,检测每一帧的人脸数:
-
若任何一帧中检测到多于1张人脸,则丢弃该视频;
-
若有10%以上帧未检测到人脸,同样丢弃;
-
-
计算所有连续帧的人脸ArcFace相似度,过滤掉相似度低的视频(确保同一视频身份一致);
-
做人脸分割,去除背景干扰;
-
做人脸关键点检测,便于后续在训练中对齐画布(canvas alignment);
-
注意:没有过滤小人脸,因为发现这些视频往往包含全身照,对多样性有好处;
-
最终构建了大约千万级(O(10)M)个性化视频,每个视频平均配有5张分割后的人脸图片。
2. 合成多样性数据
-
为进一步提升人脸风格、姿态、光照、遮挡等多样性,我们利用Instant-ID自动生成更多人脸样本:
-
随机挑选百万级个性化视频;
-
设计100+文本prompt模板(如二次元、线稿、电影感、Minecraft风等),每次随机抽取;
-
随机选取全身姿态(pose)配合prompt作为Instant-ID输入;
-
对生成结果用ArcFace测相似度,过滤掉与目标身份不符的图片。
-
-
最终收集了百万级(O(1)M)合成数据,极大丰富了数据在风格、姿态、光照、遮挡等方面的多样性。
评估
-
定性:如Fig.27所示,左侧为输入身份图像,右侧为生成的视频结果,测试图像全部随机取自Pexels数据集。

-
定量:在未见过的测试集上,对比输入人脸与生成视频中的人脸(每秒采样一帧),计算ArcFace相似度,将所有分数取均值作为最终指标。
-
结果如Table 8,Wan个性化视频生成模型的性能媲美甚至优于主流商业/闭源中文大模型。

相机运动可控性
本模块旨在通过利用相机轨迹,使生成视频的运动和视角准确匹配指定的相机运动条件。
具体地,系统对每一帧使用外参 [R, t] ∈ R³×⁴ 和 内参 Kf ∈ R³×³。该方法主要分为两部分,如Fig.28所示:
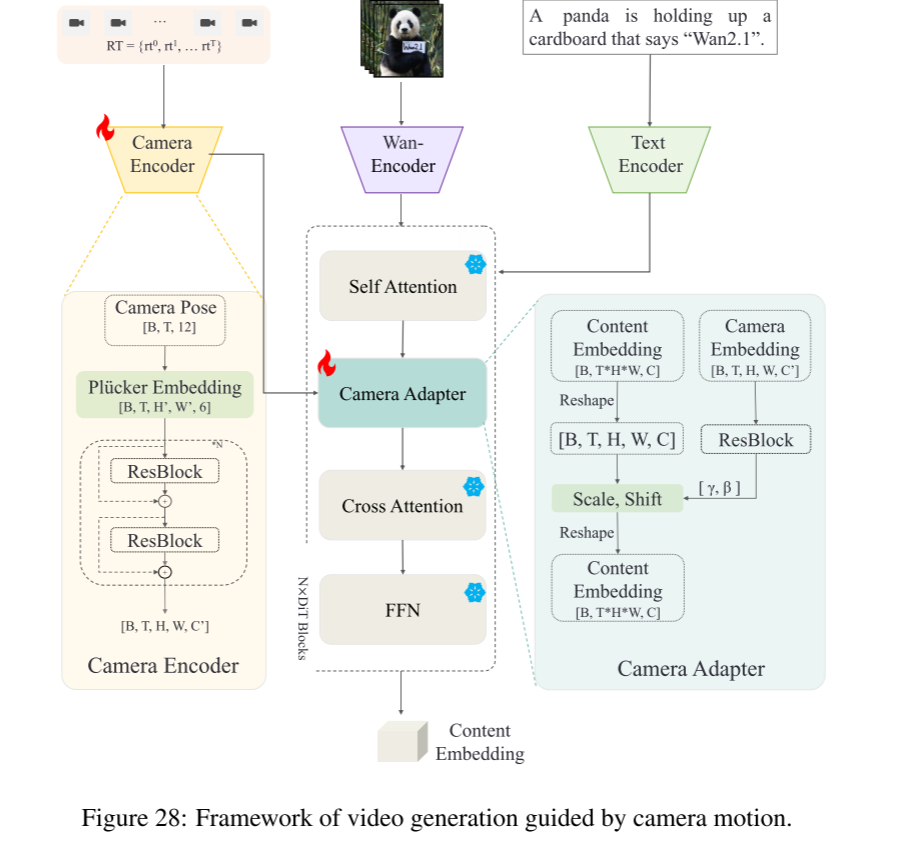
1. 相机姿态编码器(Camera pose encoder)
-
针对每一帧的每一个像素,使用Plücker坐标,将外参和内参转为细粒度的空间位置序列P ∈ R⁶×F×H×W(F为帧数,H×W为分辨率)。
-
使用PixelUnshuffle(PyTorch算子)调整P的空间分辨率(降低分辨率、增加通道),使其与视频潜特征压缩后格式一致。
-
最后,用一系列卷积模块编码P,输出多层次的相机运动特征,特征层数与DiT模块一致。
2. 相机姿态适配器(Camera pose adapter)
-
为将相机运动特征注入视频潜特征,采用自适应归一化层(adaptive normalization)。
-
具体方法:用两层零初始化的卷积,将输入的相机运动特征序列转换为缩放因子 γi 和偏置 βi。
-
γi和βi通过线性投影注入到每一层DiT主干网络中,公式为:
fi = (γi + 1) * fi-1 + βi
其中fi是第i层的视频潜特征。 -
这样可以有效控制视频的运动与相机轨迹高度一致。
3. 训练数据
-
利用先进的VGG-SfM算法自动从大量运动丰富的视频中提取相机轨迹,获得约一千段带精确运动标签的视频片段。
-
在T2V主框架下用Adam优化器训练相机控制模块。
4. 效果
-
Fig.29展示了在指定相机运动指导下生成的多样视频结果,证明方法可精细控制虚拟相机视角和运动效果。

实时视频生成
目前主流的视频生成方法,即使在高端硬件上也常常需要消耗大量算力和数分钟时间,才能生成几秒钟的视频片段。虽然生成画质显著提升,但“生成速度慢”已成为实际应用和创意设计中的主要瓶颈。
-
应用场景痛点:
-
在需要快速迭代、实时调整的领域,如互动娱乐、虚拟现实、视频制作,缓慢的生成速度会极大限制创作自由和内容优化效率。
-
动态环境下(如直播、游戏等)对实时反馈需求更高,AI生成延迟会严重影响用户沉浸感与互动体验。
-
-
Wan的目标:
-
通过优化设计,实现实时级别的视频生成,提升生成技术的性能和落地可用性,拓宽AIGC在快节奏互动场景中的应用空间。
-
如Fig.30、31所示,Wan已能支持实时长视频流生成等新应用。
-
接下来,论文将介绍如何基于Wan模型实现这一目标。


方法
为实现实时视频生成流水线,我们基于已预训练好的Wan大模型进行改造。这一设计有两大优势:
-
更快收敛与更高稳定性:预训练模型本身已经学到大量视觉和时序知识,为后续优化提供了坚实起点;
-
继承运动与动态知识:模型已掌握连续动作与运动规律,这对于生成流畅自然的长视频尤为关键,可直接迁移到实时生成任务中。
因此,我们选用预训练的Wan模型作为实时流水线的基础。
Wan的原始设计
-
Wan原本是用来生成固定长度视频片段(通常为5~10秒)。
要实现实时无限流式生成,需两大核心改造:
1. 流式生成机制(Streaming pipeline adaptation)
-
传统静态流程:一次性输出固定长度的全部视频token。
-
流式改造后:模型“边生成边输出”,维护一个“去噪队列”(denoising queue):
-
每当生成出一帧(或一组token),就将队列最旧的token“出队”,并在队尾添加新token;
-
这样可以连续、无限地生成视频帧,实现“无长度限制”的流式输出。
-
2. 实时加速优化(Real-time acceleration)
-
除了流式机制,还需大幅提升推理速度,确保生成速度≥播放速度,才能满足实时应用需求。
流式视频生成
传统的扩散Transformer(DiT)模型即便配合强力的时空压缩(如VAE),也很难生成超过几秒的长视频。主要瓶颈在于:时序过长时,注意力机制对算力和显存的需求呈指数级上升。
为突破这一限制,Wan引入了名为Streamer的新方法:
Streamer核心思想:滑动时间窗
-
假设时序依赖仅存在于有限的窗口内,即每一帧只需关注前后有限数量的帧即可。这样可以显著降低计算与内存消耗,同时保证视频内容连贯、自然。
-
具体机制:
-
将所有视频token维护在一个队列(queue)里;
-
每次只对窗口内的token做去噪(denoise)处理,窗口外的不计算attention;
-
每完成一轮固定步数的去噪,队列左端(最早)token出队并缓存,右端插入新的高斯噪声token,保持窗口长度不变;
-
不断滑动窗口,就可以无限制地生成连贯视频帧。
-
这样做就实现了长/无限时长视频的连续流式生成,同时有效缓解显存和算力压力。
训练和推理
-
微调方式:Streamer基于预训练的DiT模型进行微调。
-
训练流程:
-
每次采样2w个视频token(w为滑动窗口长度,通常等于扩散求解步数T)。
-
前w个token用于模型“热身”(warming up),不参与损失计算;
-
损失函数仅对最后w个token计算,确保模型专注于窗口内连续视频帧的生成质量。
-
-
推理(生成)时:
-
同样采用热身策略:前w帧不输出,从第w+1帧开始正式作为生成视频输出。
-
确保生成连续性
为了保证滑动窗口之间生成内容的平滑衔接,Streamer 会将已缓存的 token(即上一窗口已经生成好的帧),以噪声等级为 0 的形式重新引入到 token 队列。这样,前一窗口生成的帧就能参与后续窗口的去噪过程,实现窗口间的时序连续与无缝衔接,避免出现画面断裂或“跳帧”现象。
方法总结与创新价值
-
无限长度视频生成:滑窗机制让视频生成突破长度上限,且显存/算力不会线性增长。
-
高效注意力机制:仅对滑窗范围内token做attention,大幅节省内存和计算资源。
-
无缝连续性:token缓存+重新引入机制保证长时序视频“无断帧、无闪烁”,时序感极强。
Streamer极大提升了DiT类模型在流式、长内容、实时视频生成上的可用性,为AIGC落地带来新可能。
一致性模型蒸馏
在将 DiT 模型成功扩展为 Streamer(可实现无限长度视频流式生成)后,下一个关键难题是如何实现模拟世界的实时渲染。Streamer 虽然通过滑动时间窗高效管理时序依赖,实现了长视频的生成,但扩散模型本身的推理速度仍然是实时落地的瓶颈。
为了解决这一问题,论文提出将 Streamer 与“Consistency Models(CM,一致性模型)”结合,极大加速扩散推理。
具体做法是引入 Latent Consistency Model(LCM)及其视频版 VideoLCM,这两者能将原本冗长的扩散+无分类引导过程,蒸馏为极高效的4步一致性生成,大大减少采样步数,同时维持时序一致性和流式生成能力。
-
结合要点:
-
LCM/VideoLCM被训练成保留Streamer的滑窗去噪机制,确保时序依赖管理不被破坏。
-
训练时,精心优化以平衡速度与画质。
-
结果:推理速度提升10-20倍,模型可达8-16帧每秒(FPS),可真正用于实时应用(如交互仿真、直播级视频生成、虚拟环境动态内容AIGC等)。
-
这样,Streamer的“无限生成+时序连续”与LCM的“极致推理加速”形成互补,真正打通了高质量视频AIGC的实时化路径。
这也让扩散模型首次具备流式、交互式、沉浸式实时媒体创作能力。
消费级设备部署:量化优化
即便达到实时生成速度,模型的算力和内存需求(哪怕是4090级别高端GPU)依然对消费级设备落地形成障碍。
-
为此,Wan引入量化优化:
-
int8量化(适用于注意力层和线性头),将权重和激活都转换为8位整数,大幅降低内存消耗,同时画质影响可控。但int8量化主要节省内存,对生成速度提升有限。
-
TensorRT量化(针对整个模型),则可极大提升推理速度,使得在单张4090上达到8FPS的实时性能,真正可用于消费级落地。
不过,TensorRT量化会带来小幅网络误差,表现为:画面细节或一致性偶有轻微下降、个别视频会有闪烁或时序不稳等现象。
-
-
权衡:int8和TensorRT量化结合,既保障效率与落地性,也基本保证画质。通过参数调优和TensorRT内置的错误检测机制,可以将负面影响控制在可接受范围内,实现“高效且实用”的消费级AIGC体验。
音频生成
本工作的音频生成主要目标,是为视频片段生成同步的音轨,即采用“视频转音频(V2A)”的生成框架。生成的音轨包括环境音效和背景音乐,明确排除了语音和人声元素。
与常规的文本生成音频(text-to-audio)模型不同(如 Liu 等,2023b/2024c),视频转音频模型要求生成的环境音效在时间上要与视觉内容严格对齐;而背景音乐则需准确体现视频的情感色彩和场景氛围,如同真人视频后期配乐一样自然契合。
此外,为了提升用户对音效设计的可控性,Wan 框架支持视频+文本联合条件生成,用户可以指定屏幕内或屏幕外的音效,以及定义背景音乐的风格和有无,从而实现更精细、可定制的多模态视听生成。
模型设计
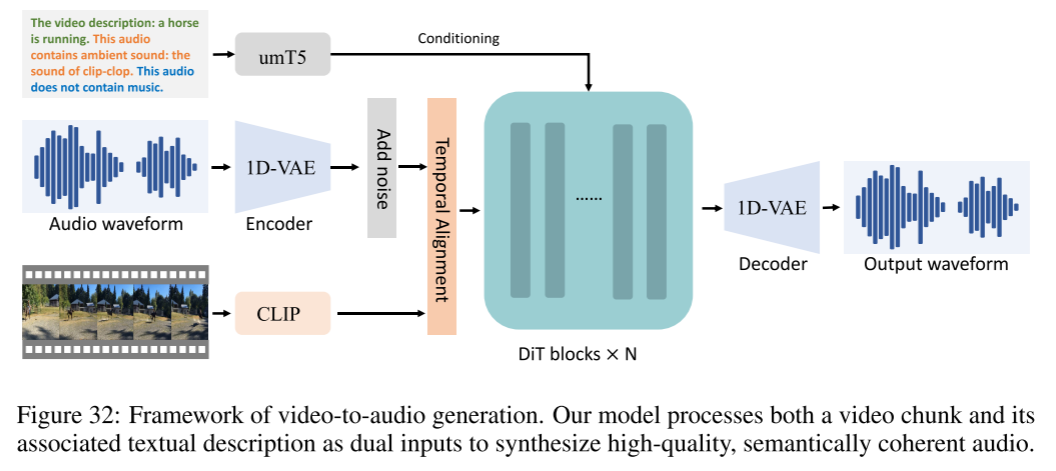
与视频生成框架一致,Wan 的视频转音频(V2A)模型也基于**扩散Transformer(DiT)架构,并采用流匹配(flow-matching)**方案来建模音频领域的去噪扩散过程。V2A详细流程如图32所示。
音频自编码器(Audio Autoencoder)
传统的音频压缩方法通常先将原始波形转为mel谱,再用基于图像的变分自编码器(VAE)编码为 Ha × Wa × Ca 的特征(参考 Liu等, 2023b/2024c)。但在扩散Transformer结构中,通常需要把这些特征分块后重塑为 (Ha·Wa)×Ca 的张量,这一“分patch+reshape”过程容易破坏音视频同步的时间对齐关系,成为配准难点。
为此,Wan 训练了直接作用于原始波形的 1D-VAE,自编码器输出尺寸为 Ta × Ca(Ta为时间轴长度),从而显式保留时序信息,保证音视频精准同步。
视频与文本编码器(Video and Text Encoder)
为实现音频与视觉序列的帧级同步,模型通过多模态特征融合建立时序一致性:
-
首先用CLIP提取逐帧视觉特征,通过复制(rate adaptation)方式将视觉特征对齐到音频采样率(参考Polyak等),再用线性投影映射到DiT潜空间,与音频特征逐元素相加实现多模态融合。
-
文本理解采用冻结参数的umT5大模型,具备多语言跨模态能力。
数据
V2A训练集来源于视频生成数据,经过过滤去除无音轨和含人声的视频,得到约“千小时”高质量音视频。为强化多模态表征,训练集每条样本都配有三类caption:
-
密集视频描述
-
环境音效描述
-
背景音乐分析(风格、节奏、旋律、乐器)
其中音乐/环境音的caption由Qwen2-audio自动生成。
实现细节
-
Wan V2A模型支持最长12秒的高保真立体声生成,采样率44.1kHz;
-
文本特征(umT5-XXL)为4096维,视觉特征(CLIP)每帧1024维,音视频特征均映射到DiT的1536维统一潜空间;
-
时序对齐时,输入视频被下采样为48帧(对应12秒),保证音视频帧级同步;
-
每批处理序列长度为256。
-
训练时引入随机掩码机制:以一定概率随机丢弃环境音或音乐caption,迫使模型学会通过视觉内容自主生成音效与配乐,同时具备文本可控能力。
评估
我们在图33中提供了音频生成的定性评估,其中我们将我们的方法与最近发布的开源方法MMAudio(Cheng等人,2024年)的报告。由于MMAudio代表了与我们的方法最相似和最具竞争力的基准,在音频生成任务中表现出了令人印象深刻的性能,因此这种比较分析特别有意义。这些视频是由我们的文本到视频模型生成的,持续时间为5秒。
我们的V2A模型在音频生成的几个关键方面都表现出了上级的性能,这一点可以从比较结果中得到证明。具体地说,该模型表现出增强的长期一致性,在“倒咖啡”场景(图33中的第一种情况)中尤其明显。在第二种“键入”的情况下,与MMAudio产生的噪声结果相比,我们的方法产生的音频输出明显更清晰。此外,我们的方法在合成有节奏的声音模式方面表现出色,如“行走”、“拳击”和“夹击”示例(图33中的最后三种情况)中所示,在这些示例中,它实现了更自然和连贯的音频生成。
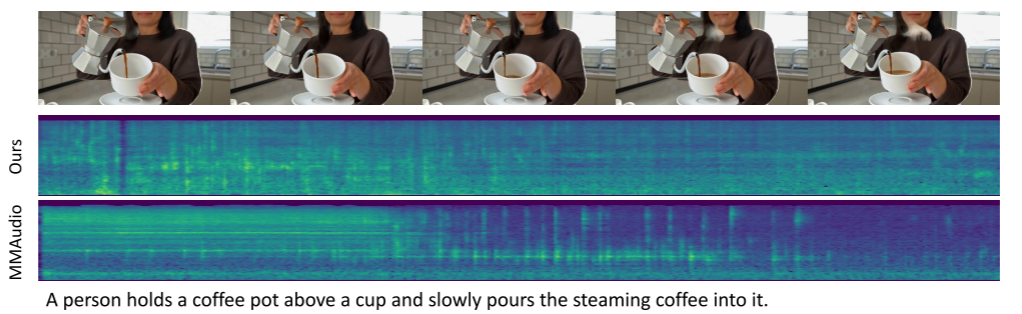

我们的方法在产生人类声音方面表现出局限性,包括但不限于笑声、哭声和讲话。这一限制主要归因于我们的数据准备过程,在该过程中,与语音相关的声音数据被故意从训练数据集中排除。MMAudio模型能够产生随机的类似语音的声音,这是因为它在训练语料库中保留了语音相关的数据。在我们未来的工作中,我们计划整合语音生成功能来解决这一限制。
局限性和总结
局限性
本研究提出了基础性视频生成模型 Wan,并在多个基准测试上取得了显著进展,尤其在大幅度运动(如体育、舞蹈)和指令跟随能力方面表现突出。但仍存在如下局限:
-
大运动场景下的细节丢失
Wan 及当前视频生成领域整体都面临一个难题——在剧烈运动(如快速移动、剧烈转场等)时难以保留细粒度视觉细节。需要继续提升此类场景下的保真度。 -
高算力消耗
大模型推理成本很高,例如,Wan 14B 在单张高端GPU上生成一次视频约需30分钟,若无进一步优化,难以普及到大众。效率与可扩展性仍需重点攻关。 -
领域专业性不足
作为“通用”视频生成基础模型,Wan 致力于提升整体能力,但在某些特定垂直领域(如教育、医疗)表现可能不够理想。后续将继续开放模型、推动社区参与,以实现更强的专业化和本地化适配。
总结
在本报告中,作者正式公开发布 Wan,该模型为视频生成设立了新的业界基线。报告系统梳理了 Wan-VAE 和 DiT(扩散Transformer)架构、训练方法、数据处理流程、评测体系与实证结果等,推动了视频生成领域的技术进步。
此外,报告还深入探讨了 Wan 在下游场景的广泛应用(如图像转视频、视频编辑、个性化视频生成等),展示了模型的多样化和实用性。值得注意的是,除了开源14B大模型,团队还积极探索小模型(1.3B),在保证生成质量的前提下大幅提升了效率与可用性,使内容创作更加“亲民”。
展望未来,Wan 团队将继续扩大数据与模型规模,攻克视频生成领域的关键难题,为学术界和产业界提供更加强大且通用的视频生成工具,推动创新与普及。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)