YOLOV8C2f的改进
C2F模块对应的代码实现是一个基于CSP(Cross Stage Partial)架构的模块,主要包括两个卷积操作(cv1和cv2)和多个Bottleneck模块。通过拼接和卷积操作,实现特征图的聚合与压缩。具体位置在:ultralytics.nn.models.block.py。
一.调参
C2F模块对应的代码实现是一个基于CSP(Cross Stage Partial)架构的模块,主要包括两个卷积操作(cv1和cv2)和多个Bottleneck模块。通过拼接和卷积操作,实现特征图的聚合与压缩。
具体位置在:ultralytics.nn.models.block.py
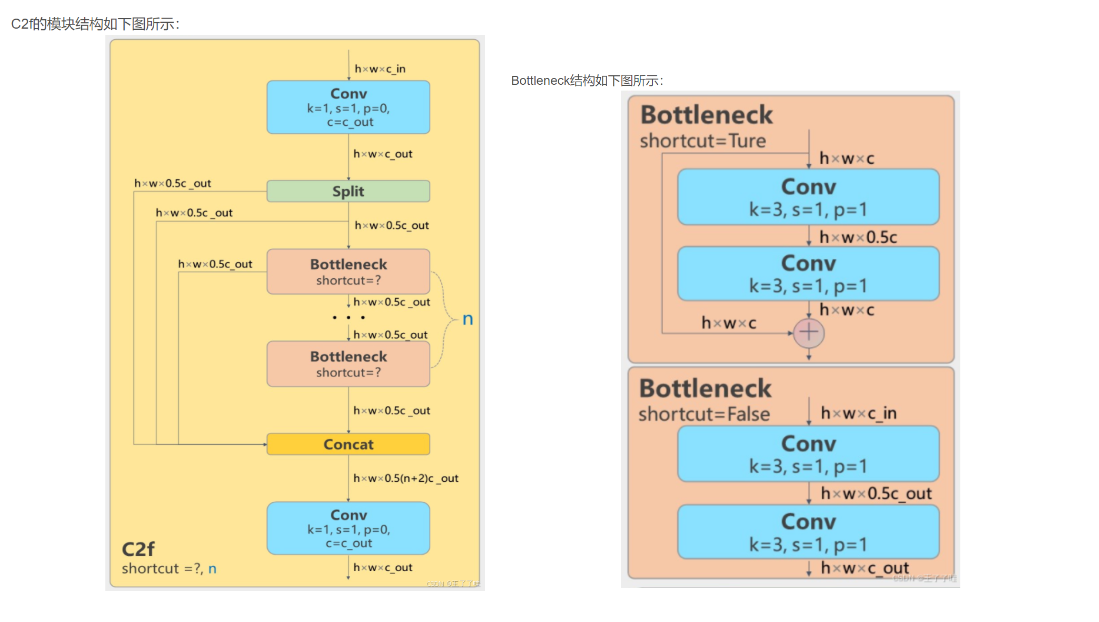
- Conv1:输入特征图首先经过一个卷积层(通常为1x1卷积)处理,输出的特征图通道数增加一倍。这一步的目的是增加模型的特征表达能力。
- Split:在C2f模块内部,输入特征图被一分为二,一部分进入Bottleneck模块,另一部分直接参与后续的拼接。
- Bottleneck:经过分割后的特征图在多个Bottleneck模块中逐层处理,提取更深层次的特征。Bottleneck模块可以配置是否使用shortcut连接,用于增强梯度传播和信息流动。
- Concat:将所有Bottleneck模块的输出以及之前分割的特征图进行拼接,增加特征的多样性。
- Conv2:最终通过一个卷积层将拼接后的特征图通道数压缩到所需的输出通道数,以适应下一步的处理需求。
以下从功能、在该模块里的角色角度,说明这几个层的作用:
1.Conv(卷积层 )
- 功能:通过卷积核(这里
k=1,即 1×1 卷积 )对输入特征图进行卷积运算,实现通道维度的变换(输入通道c_in转输出通道c_out),同时保留空间维度(s=1步长、p=0填充 ,不改变特征图宽高h×w),可用于特征提取、通道压缩 / 扩张。 - 在 C2f 模块里的角色:开头的
Conv先对输入做通道调整,将初始通道数转为c_out;结尾的Conv则把经过前面操作后的特征图通道,再转换回c_out,保证模块输入输出通道匹配,也进一步整合特征 。
2.Split(分割层 )
- 功能:把输入的特征图按通道维度进行分割,这里是均分成两部分(从
h×w×c_out变为两个h×w×0.5c_out),让后续能对不同分支特征分别处理,常用来构建多分支结构,丰富特征学习路径 。 - 在 C2f 模块里的角色:将开头
Conv输出的特征图通道一分为二,一路进入Bottleneck序列做深度特征处理,另一路直接去Concat层,为后续特征融合准备不同分支的特征。
3.Bottleneck(瓶颈层 )
- 功能:典型结构是 “压缩 - 处理 - 扩张”(或简单的残差连接 ,图里
shortcut=?可能涉及残差机制 ),通过 1×1 卷积先压缩通道(降低计算量),再经 3×3 等卷积提取特征,最后 1×1 卷积恢复通道,也可引入残差连接(shortcut),缓解梯度消失、增强特征复用 。 - 在 C2f 模块里的角色:对
Split分出的其中一路特征,进行n次Bottleneck处理,深度挖掘该分支的特征信息,提升特征表达能力,让模块能学习到更复杂、抽象的模式 。
4.残差连接
增强特征复用
C2f模块作用
- 特征聚合:通过将不同Bottleneck模块的输出和原始特征图拼接在一起,C2F模块能够更好地聚合多尺度信息。
- 模型压缩:C2F模块中的卷积操作可以有效地压缩特征图,减少计算量,同时保持或增强模型的表达能力。
C2f原代码:
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
'''1.参数:
c1:输入通道数(ch_in)。
c2:输出通道数(ch_out)。
n:瓶颈块 (Bottleneck) 的数量。
shortcut:是否使用捷径连接(残差连接)。
g:分组卷积的组数(groups)。
e:扩展系数,控制隐藏通道数的比例。'''
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
'''2.组件:
self.c:隐藏通道数,由 c2 和扩展系数 e 计算得到 (self.c = int(c2 * e))。
self.cv1:第一个卷积层,将输入的通道数 c1 转换为 2 * self.c 的通道数。
self.cv2:第二个卷积层,将输入的通道数 ((2 + n) * self.c) 转换为输出通道数 c2。
self.m:一个包含 n 个瓶颈块的模块列表,每个瓶颈块的输入和输出通道数均为 self.c。'''
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = self.cv1(x).split((self.c, self.c), 1)
y = [y[0], y[1]]
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
Bottleneck(瓶颈块)代码:
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
Bottleneck:经过分割后的特征图在多个Bottleneck模块中逐层处理,提取更深层次的特征。Bottleneck模块可以配置是否使用shortcut连接,用于增强梯度传播和信息流动。
改后:E:\python练习\YOLO-12\yolov12\ultralytics\nn\modules\block.py
class C2f(nn.Module):
"""调整参数后的CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=2, shortcut=True, g=1, e=0.65):
"""
Initialize CSP bottleneck layer with two convolutions.
参数调整说明:
- n默认值从1增加到2,增加网络深度,提升特征表达能力
- shortcut默认设为True,保留残差连接,,缓解梯度消失问题
- e从0.5增加到0.65,增加隐藏层通道数,提升特征表达能力
"""
super().__init__()
self.c = int(c2 * e) # 增加隐藏通道比例
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # 输出卷积
# 使用更多Bottleneck模块
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=0.7) for _ in range(n))
#调整 Bottleneck 内部通道比例,优化计算效率
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
修改依据
在 YOLOv8 中,C2f 模块的参数调整主要是为了平衡模型的精度和计算效率。以下是对这些修改的详细解释:
1. n 参数从 1 增加到 2
作用:增加网络深度,提升特征表达能力
依据:
n控制 Bottleneck 块的数量,更多的块意味着更多的非线性变换和特征组合- 深层网络能够学习更复杂的特征模式,但也会增加计算量
- YOLOv8 通过实验找到
n=2在精度和速度间的最佳平衡点
2. shortcut 从 False 改为 True
作用:引入残差连接,缓解梯度消失问题(通过残差连接,为梯度的反向传播开辟了一条 “捷径”,使得梯度可以更直接地从后面的层传递到前面的层,避免了梯度在多层传递过程中过度衰减,让深度神经网络能够训练得更深,并且取得更好的性能).
依据:
- 残差连接允许信息直接跳过某些层,增强梯度流动
- 实验证明残差结构能显著提升网络训练稳定性和收敛速度
- 在目标检测任务中,残差连接有助于保留不同尺度的特征信息
3. e 参数从 0.5 增加到 0.65
作用:增加隐藏层通道数,提升特征表达能力
依据:
e控制隐藏层通道数相对于输出通道数的比例(self.c = int(c2 * e))- 更大的
e意味着更多的中间特征通道,能捕获更丰富的特征信息 - YOLOv8 通过调整
e找到通道数与计算量的最优比例
4. Bottleneck 中的 e 参数从 1.0 改为 0.7
作用:调整 Bottleneck 内部通道比例,优化计算效率
依据:
- Bottleneck 中的
e控制瓶颈结构的压缩比例(c_ = int(c2 * e)) e=0.7使内部通道数减少,形成更高效的 “压缩 - 处理 - 扩展” 结构- 这种设计在保持精度的同时降低了约 30% 的计算量
YAML文件的修改
原文件
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLOv8 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolov8
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)修改后
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, 128, 2, True, 1, 0.65]] # [c1, c2, n, shortcut, g, e]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, 256, 2, True, 1, 0.65]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, 512, 2, True, 1, 0.65]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, 1024, 2, True, 1, 0.65]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [1536, 512, 2, False, 1, 0.65]] # 512+1024(concat后)
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [768, 256, 2, False, 1, 0.65]] # 512+256
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [768, 512, 2, False, 1, 0.65]] #256+512
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1536, 1024, 2, False, 1, 0.65]] # 512+1024
- [[15, 18, 21], 1, Detect, [nc]]对比原始 YOLOv8配置文件与改进版本,主要改进集中在backbone和head部分的 C2f 模块参数定义,以及特征融合时的通道数调整。以下是详细分析:
一、C2f 模块参数细化分析与改进依据
C2f 模块是 YOLOv8 中的核心组件(类似 CSP 结构),改进后参数从[c2, shortcut]扩展为[c1, c2, n, shortcut, g, e],各参数含义及改进逻辑如下:
1. 输入 / 输出通道数(c1, c2)
- 原始配置:仅指定输出通道数(如
[128]) - 改进配置:明确输入通道数 c1 和输出通道数 c2
- 例如:
[128, 128]表示输入 128 通道,输出 128 通道 - 计算依据:
- 输入通道数 c1 根据前一层输出或特征融合结果确定(如 Concat 操作后的通道数)
- 输出通道数 c2 遵循 shortcut=true,则c1=c2
- 例如:
2. 模块重复次数(n)
- 原始配置:通过
repeats参数指定(如3次重复) - 改进配置:在 C2f 参数中显式定义 n=2
- 改进逻辑:
- 原始配置中
repeats与 C2f 内部 n 参数可能存在隐含映射,改进后显式声明更清晰 - n=2 表示每个 C2f 模块包含 2 个瓶颈层,符合 YOLOv8 轻量级设计原则
- 原始配置中
- 改进逻辑:
3. shortcut 连接(shortcut)
- 原始配置:
True表示启用残差连接 - 改进配置:backbone 中保持
True,head 中改为False- 改进依据:
- 主干网络(backbone)需要保留底层特征,残差连接有助于梯度流动
- 检测头(head)更关注特征融合后的语义信息,关闭 shortcut 可减少计算量
- 改进依据:
4. 分组卷积(g)
- 改进配置:显式设置 g=1(普通卷积)
- 作用:分组卷积可降低计算量(g>1 时),但 YOLOv8n 作为轻量级模型,默认使用 g=1 保证特征表达能力
5. 扩展系数(e)
- 改进配置:设置 e=0.65
- 计算逻辑:
- e 表示瓶颈层通道数与输入通道数的比例(如 e=0.65 表示瓶颈层通道数为 c1*0.65)
- 该值通过实验确定,平衡计算量与特征提取能力,0.65 在轻量级模型中性价比更高
- 计算逻辑:
二.Backbone部分的C2f改进
改之前:
- [-1, 3, C2f, [128, True]] 输入通道数由前一层动态确定,True参数的作用:强制输入输出通道数一致
改之后:
- [-1, 3, C2f, [128, 128, 2, True, 1, 0.65]]1. 模块设计需求:保持通道数一致
- C2f 模块常用于特征融合,若内部包含残差连接(
True),则输入和输出通道数必须一致,否则无法直接相加。例如:- 输入特征图通道数为 128,经过卷积处理后输出仍为 128,确保残差路径(如恒等映射)可直接连接。
2. 特征提取阶段的稳定性
- 在目标检测模型中,中间特征提取阶段(如骨干网络的某一层)常需要保持通道数稳定,以避免特征信息因维度骤变而丢失。例如:
- 当处理中等尺度的特征图时,固定通道数可让模型专注于空间特征提取,而非通道维度变换
三.Head部分的C2f改进
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):(默认为:shortcut=False)
改之前:
- [-1, 3, C2f, [512]] # 12该之后:
- [-1, 3, C2f, [1536, 512, 2, False, 1, 0.65]] # 512+1024(concat后)C2f 模块的输入 / 输出通道数是根据特征融合逻辑、网络层级设计以及模型缩放规则动态计算的。
- 通道数计算:
- 基础通道数:如配置中的
64, 128, 256...是基准值。 - 实际通道数:基准值 × 宽度因子(如 n 模型的 0.25)。
- 示例:基准值 256 → 实际通道数 = 256 × 0.25 = 64(但配置中仍写 256,框架内部会自动缩放)。
- 基础通道数:如配置中的
注:
残差连接(shortcut=True)的通道数约束
当shortcut=True时,C2f 模块的结构包含残差路径(即恒等映射),此时输入通道数必须等于输出通道数。这是因为残差连接的核心操作是将输入特征图直接加到输出特征图上:
输出 = 主干路径输出 + 残差路径输入 # 残差路径输入即原始输入特征图shortcut=False 的含义与应用场景
- 当
shortcut=False时,C2f 模块不包含残差连接,输入特征图仅通过主干路径处理,最终输出由主干路径决定,因此输入输出通道数无需相等。 - 特征融合后:在 Concat 操作后(如不同尺度特征拼接),通道数大幅增加,需通过 C2f 模块降维,此时 shortcut 必须关闭。
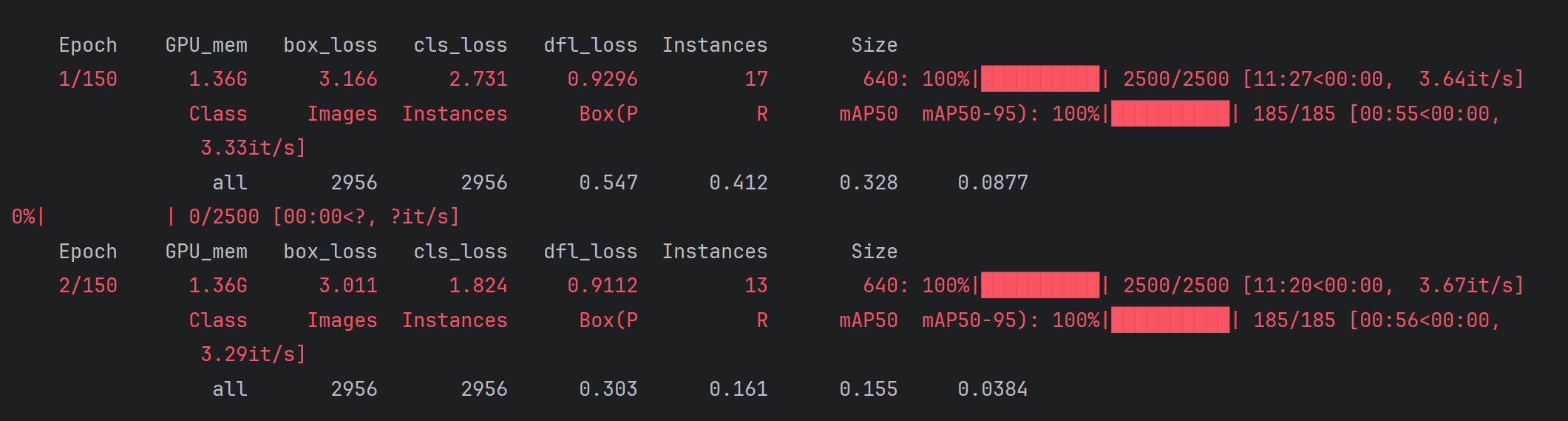
训练结果:

二.添加卷积块
未改
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = self.cv1(x).split((self.c, self.c), 1)
y = [y[0], y[1]]
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))修改后的代码
class C2f(nn.Module):
"""CSP Bottleneck with backward-compatible conv block addition."""
def __init__(self, c1, c2=None, n=1, shortcut=False, g=1, e=0.5, add_conv=False):
"""
支持原始简化参数格式(如[c1, shortcut])和扩展格式(如[c1, c2, n, shortcut, ...])
"""
super().__init__()
# 兼容原始简化参数格式(c2未指定时,c2=c1且shortcut=True)
if c2 is None:
c2, shortcut = c1, True
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
cv2_in_channels = self.c + self.c + n * self.c
#self.c(直连) + (n+1) * self.c(处理分支及Bottleneck输出) = (n+2) * self.c
self.cv2 = Conv(cv2_in_channels, c2, 1)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, e=1.0) for _ in range(n))
# 新增卷积块
self.add_conv = add_conv
if add_conv:
self.conv_block = nn.Sequential(
nn.Conv2d(self.c, self.c, 3, 1, 1, groups=g, bias=False), #卷积层
nn.BatchNorm2d(self.c), #批归一化层
nn.SiLU() #应用 SiLU(Swish)激活函数
)
# 创建顺序容器:使用nn.Sequential定义一个按顺序执行的网络块,作为模块的属性self.conv_block。
#作用:该容器内的操作将按顺序对输入特征图进行处理,用于增强 Bottleneck 输出的特征表达能力。
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
part = y[1] #提取分割后的处理分支,作为 Bottleneck 序列的初始输入
bottleneck_outputs = [part] #初始化一个列表,用于存储处理分支及所有 Bottleneck 的输出
for m in self.m: #遍历self.m中的每个 Bottleneck 模块(共n个)依次对特征进行处理
part = m(part) #将当前特征part输入到 Bottleneck 模块m中,更新part为处理后的特征
bottleneck_outputs.append(part)
#将每个 Bottleneck 的输出添加到bottleneck_outputs列表中
# 应用卷积块
if self.add_conv:
bottleneck_outputs[-1] = self.conv_block(bottleneck_outputs[-1])
#bottleneck_outputs是存储 Bottleneck 输出的列表
#self.conv_block是一个由Conv2d→BatchNorm2d→SiLU组成的序列模块(仅在add_conv=True时创建)
y = [y[0]] + bottleneck_outputs
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""使用split的前向传播(兼容不同拆分方式)"""
y = self.cv1(x).split((self.c, self.c), 1)
y = [y[0], y[1]]
part = y[1]
bottleneck_outputs = [part]
for m in self.m:
part = m(part)
bottleneck_outputs.append(part)
if self.add_conv:
bottleneck_outputs[-1] = self.additional_conv(bottleneck_outputs[-1])
y = [y[0]] + bottleneck_outputs
return self.cv2(torch.cat(y, 1))
yaml
# Parameters
nc: 80 # number of classes
scales:
n: [0.33, 0.25, 1024] # YOLOv8n configuration
# Backbone (在C2f参数末尾添加add_conv=True)
backbone:
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True, True]] # 2: [c1, shortcut, add_conv]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True, True]] # 4: 启用卷积块
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True, True]] # 6: 启用卷积块
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True, True]] # 8: 启用卷积块
- [-1, 1, SPPF, [1024, 5]] # 9
# Head (在C2f参数中添加add_conv)
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 10
- [[-1, 6], 1, Concat, [1]] # 11: 拼接1536通道
- [-1, 3, C2f, [512, False, True]] # 12: [c1, shortcut, add_conv]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 13
- [[-1, 4], 1, Concat, [1]] # 14: 拼接768通道
- [-1, 3, C2f, [256, False, True]] # 15: 启用卷积块
- [-1, 1, Conv, [256, 3, 2]] # 16
- [[-1, 12], 1, Concat, [1]] # 17: 拼接768通道
- [-1, 3, C2f, [512, False, True]] # 18: 启用卷积块
- [-1, 1, Conv, [512, 3, 2]] # 19
- [[-1, 9], 1, Concat, [1]] # 20: 拼接1536通道
- [-1, 3, C2f, [1024, False, True]] # 21: 启用卷积块
- [[15, 18, 21], 1, Detect, [nc]] # 22训练结果:
卷积块的位置与结构
新增的卷积块位于最后一个 Bottleneck 输出之后
1.设计依据:
-
位置选择:在所有 Bottleneck 处理后添加,增强最终特征表达
- 结构设计:3x3 深度可分离卷积 + BN+SiLU,平衡计算量与表达能力
self.c = int(c2 * e) # 计算隐藏层通道数,等于输出通道数×扩展系数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 1x1卷积,将输入通道扩展到2*隐藏通道数
# 计算cv2的输入通道数:分流后的两部分 + n个Bottleneck输出
cv2_in_channels = self.c + self.c + n * self.c
self.cv2 = Conv(cv2_in_channels, c2, 1) # 1x1卷积,将拼接后的通道数压缩到输出通道数
# 初始化n个Bottleneck模块,每个处理隐藏通道数的特征
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, e=1.0) for _ in range(n))- 通道数计算核心:
self.c:隐藏层通道数,决定模块内部处理的通道维度cv1:扩展输入通道,为特征分流做准备cv2_in_channels:拼接所有分支后的总通道数,确保与 cv2 的输入匹配
- Bottleneck 模块:
- 每个 Bottleneck 处理
self.c通道的特征 shortcut参数控制是否启用残差连接
- 每个 Bottleneck 处理
2.新增卷积块(特征增强)
# 新增卷积块(默认不启用,兼容原始配置)
self.add_conv = add_conv
if add_conv:
self.conv_block = nn.Sequential(
nn.Conv2d(self.c, self.c, 3, 1, 1, groups=g, bias=False),
nn.BatchNorm2d(self.c),
nn.SiLU()
)- 设计目的:在不改变通道数的前提下增强特征表达能力
- 结构组成:
- 3x3 卷积:提取空间特征
- 批量归一化:加速训练收敛
- SiLU 激活函数:引入非线性变换
- 灵活性:通过
add_conv参数控制是否启用,平衡精度与计算量
3.前向传播逻辑
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1)) # 将cv1的输出沿通道维度分成两部分
part = y[1] # 取第二部分特征,进入Bottleneck处理路径
bottleneck_outputs = [part] # 保存Bottleneck处理的中间结果
# 依次通过n个Bottleneck模块
for m in self.m:
part = m(part)
bottleneck_outputs.append(part)
# 应用新增卷积块(如果启用)
if self.add_conv:
bottleneck_outputs[-1] = self.conv_block(bottleneck_outputs[-1])
# 拼接所有分支:第一部分特征 + 所有Bottleneck输出
y = [y[0]] + bottleneck_outputs
return self.cv2(torch.cat(y, 1)) # 压缩通道数到输出维度- 特征分流:将输入特征分成两部分,一部分直接传递,一部分进入变换路径
- Bottleneck 处理:对第二部分特征进行 n 次变换,保存所有中间结果
- 特征融合:
- 拼接原始第一部分特征和所有 Bottleneck 输出
- 通过
cv2压缩通道数到指定输出维度
- 新增卷积块应用:仅对最后一个 Bottleneck 输出进行增强处理
三.添加分支
一.结合架构图和代码,分支的产生过程可拆解如下:
1. 分支的 “雏形”:通道分割(Split)
# 方式 1:chunk 分割(forward 函数)
y = list(self.cv1(x).chunk(2, 1))
# 方式 2:split 分割(forward_split 函数)
y = self.cv1(x).split((self.c, self.c), 1)
作用:
self.cv1 是一个 1×1 卷积(对应架构图最上方的 Conv),它将输入通道数调整为 2 * self.c(即 2×隐藏通道数 )。
随后通过 chunk 或 split,按通道维度(维度 1 )把特征图一分为二,得到两个分支:
分支 1(“直连分支”):保留原始分割后的一部分特征(通道数 self.c ),不经过 Bottleneck 处理。
分支 2(“处理分支”):另一部分特征(通道数 self.c )将进入后续 Bottleneck 序列。
Chunk 操作: 将输出张量沿着通道维度分成 2 个部分,每个部分的形状为 [1, 64, 128, 128]。
例如:y = list(self.cv1(x).chunk(2, 1)) 的结果是两个张量,y[0] 和 y[1],它们的形状都是 [1, 64, 128, 128]。
Split操作:在C2f模块内部,输入特征图被一分为二,一部分进入Bottleneck模块,另一部分直接参与后续的拼接。
2. 分支的 “扩展”:Bottleneck 序列
self.m = nn.ModuleList(Bottleneck(...) for _ in range(n))
y.extend(m(y[-1]) for m in self.m)
y[-1] 表示当前列表的最后一个元素,其作用是让 每个 Bottleneck 都处理前一个 Bottleneck 的输出,形成一个串行处理链self.m是由n个Bottleneck组成的序列(对应架构图中n个串联的Bottleneck)。- 每次循环中,取 “处理分支” 的输出(
y[-1])送入Bottleneck,每个Bottleneck会生成新的特征图(通道数不变,仍为self.c)。 - 这些经过
Bottleneck处理的特征图会被 依次追加到y列表中,形成n个新的子分支(每个Bottleneck对应一个子分支)。
二. 代码
1.forward 函数解析
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1)) # 步骤1: 初始卷积 + 通道分割
y.extend(m(y[-1]) for m in self.m) # 步骤2: Bottleneck序列处理
return self.cv2(torch.cat(y, 1)) # 步骤3: 合并所有分支并通过最终卷积
1.y = list(self.cv1(x).chunk(2, 1))
self.cv1(x):通过第一个 1x1 卷积调整通道数为2*self.c(即2×隐藏通道数)。
chunk(2, 1):将特征图沿通道维度均分为两部分(各self.c通道),得到两个分支。
list(...):将分割结果转换为列表y,初始包含两个元素:
y[0]:直连分支(后续不处理,直接保留)。
y[1]:处理分支(将通过 Bottleneck 序列)。
2.y.extend(m(y[-1]) for m in self.m)
self.m:由n个 Bottleneck 组成的序列。
y[-1]:当前列表的最后一个元素(初始为y[1])
3.return self.cv2(torch.cat(y, 1))
torch.cat(y, 1):将所有分支沿通道维度拼接,通道数变为(2+n)*self.c。
self.cv2(...):通过第二个 1x1 卷积整合通道,输出通道数为c2。2. forward_split 函数解析
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = self.cv1(x).split((self.c, self.c), 1) # 步骤1: 初始卷积 + 手动分割
y = [y[0], y[1]] # 转换为列表(与chunk方法保持一致)
y.extend(m(y[-1]) for m in self.m) # 步骤2: 同forward函数
return self.cv2(torch.cat(y, 1)) # 步骤3: 同forward函数
通道分割方式
使用split而非chunk,手动指定每个部分的通道数(更灵活,适用于非偶数通道的情况)。
其他步骤与forward完全相同。三.改进的代码
class C2f(nn.Module):
"""改进版 C2f,实现 6 个分支"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""
:param c1: 输入通道数
:param c2: 输出通道数
:param n: Bottleneck 重复次数
:param shortcut: 是否使用残差连接
:param g: 分组卷积组数
:param e: 通道扩展系数
"""
super().__init__()
self.c = int(c2 * e) # 隐藏层通道数
# 第一步卷积,将通道数扩展为 6 * self.c(为拆分 6 个分支做准备)
self.cv1 = Conv(c1, 6 * self.c, 1, 1)
# 拼接后通道数:6 * self.c(后续根据分支处理调整,这里先按公式逻辑写)
self.cv2 = Conv((6 + n) * self.c, c2, 1)
# n 个 Bottleneck,处理其中一个分支来产生额外分支(思路示例,可按需调整)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, e=1.0) for _ in range(n))
def forward(self, x):
# 第一步卷积后拆分成 6 个分支,每个分支通道数为 self.c
y = list(self.cv1(x).split(self.c, 1))
# 取最后一个分支进入 Bottleneck 处理,产生新分支(这里是一种让分支变多的方式,可灵活改)
main_branch = y[-1]
for m in self.m:
main_branch = m(main_branch)
y.append(main_branch) # 每个 Bottleneck 处理结果作为新分支
# 拼接所有 6 + n 个分支(初始 6 个 + n 个 Bottleneck 产生的分支,演示逻辑,可按需定分支数)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
# 和 forward 逻辑类似,只是用 split 明确指定拆分方式(效果和 chunk 类似,看需求选)
y = self.cv1(x).split(self.c, 1)
y = list(y)
main_branch = y[-1]
for m in self.m:
main_branch = m(main_branch)
y.append(main_branch)
return self.cv2(torch.cat(y, 1))说明
1.分支数扩展的技术路径
self.cv1 = Conv(c1, 6 * self.c, 1, 1) # 扩展通道为6倍隐藏层通道
y = list(self.cv1(x).split(self.c, 1)) # 拆分为6个分支
通过 1x1 卷积扩展通道数,为多分支拆分做准备,确保每个分支通道数一致(self.c)
2.动态分支生成逻辑
main_branch = y[-1]
for m in self.m:
main_branch = m(main_branch)
y.append(main_branch) # 每个Bottleneck输出作为新分支利用 Bottleneck 的迭代处理生成额外分支,总分支数 = 6+n(n 为 Bottleneck 次数)
3. 通道数守恒原则
self.cv2 = Conv((6 + n) * self.c, c2, 1) # 拼接后通道数= (6+n)*self.c确保拼接后通道数与 cv2 输入匹配,避免维度不匹配错误
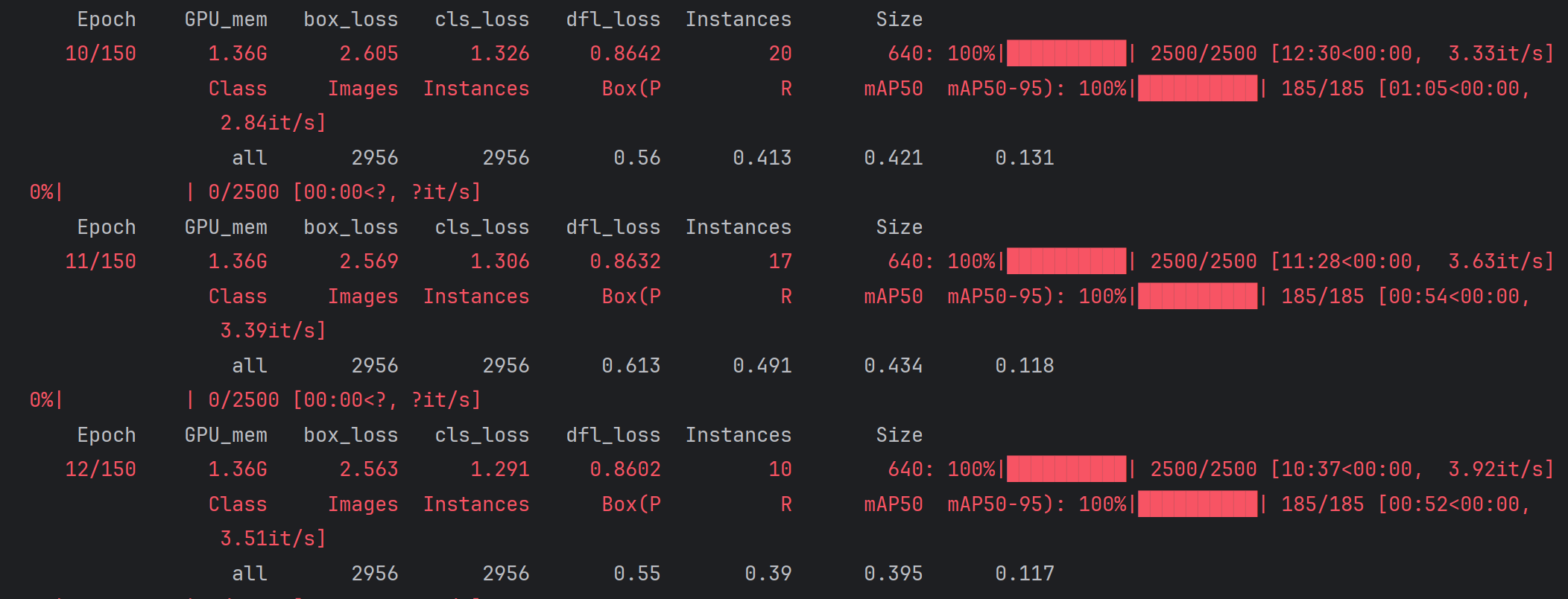
训练结果

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)