【LLM】MOE混合专家大模型综述(重要模块&原理)
定义expert类:由线性层和激活函数构成- 定义MOE类:- self.num_experts:专家的数量,也就是上面提到的“并列线性层”的个数,训练后的每个专家的权重都是不同的,代表它们所掌握的“知识”是不同的。- self.top_k:每个输入token激活的专家数量。- self.expert_capacity:代表计算每组token时,每个专家能被选择的最多次数。- self.gate:
note
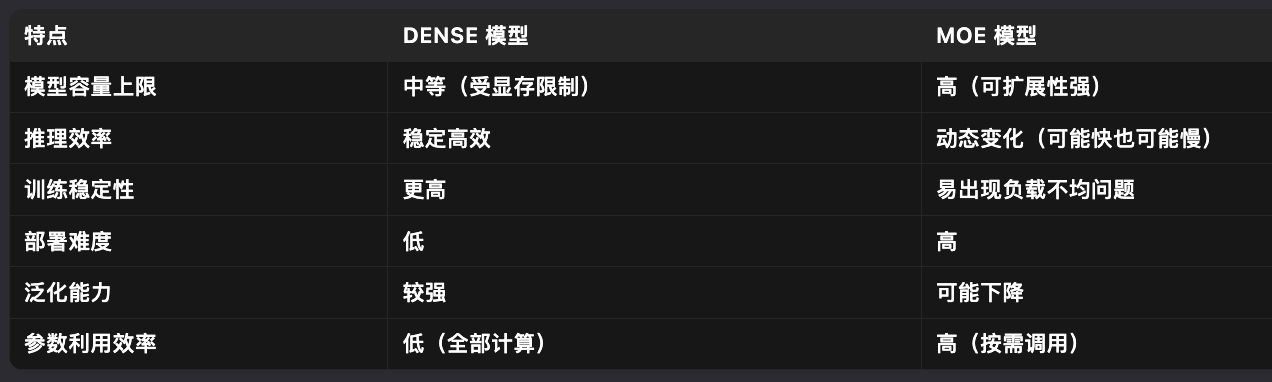
- MoE模型与dense模型和核心区别在于FFN层,将dense模型的FFN层切分成多个小FFN(每一个小FFN称之为一个专家, routed-expert)。相比于Dense模型中所有token都会过一个相同的MLP层,MoE模型中每个token会在多个小专家中会选择top-k个专家,专家输出的结果再合成一个,计算量相比之前降低了很多
- Moe负载均衡问题体现在两层面:
- expert 的负载均衡,主要体现在训练阶段的loss设计上;
- GPU 的计算均衡,主要体现在推理阶段 EP 的使用上
- 解决负载不均衡的方法有2种:设置专家容量、增加负载均衡loss
- 当前的 MoE 架构就是一个用显存换训练时长/推理延迟的架构
- MoE 目前的架构基本集中在于将原先 GPT 每层的 FFN 复制多份作为 n 个 expert,并增加一个 router,用来计算每个 token 对应到哪个 FFN(一般采用每个 token 固定指派 n 个 expert 的方案),也就是类似 Mixtral 7x8B 的结构。
- 之后 deepspeed 和 qwen 都陆续采用了更细的 granularity,也就是在不改变参数数量的情况下,将单个 FFN 变窄,FFN 数量变多,以及采用了 shared expert+,也就是所有 token 都会共享一部分 FFN 的方案。
- MoE模型存在的问题:专家并行引入了计算和通信等待。当模型规模较大时,需要切分专家到不同设备形成并行(EP),这就引入额外All-to-All通信。与此同时,MoE层绝大部分EP通信与计算存在时序依赖关系,一般的串行执行模式会导致大量计算单元空闲,等待通信。
文章目录
一、相关综述和MOE介绍
Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., & Huang, J. (2024).
A Survey on Mixture of Experts.
arXiv preprint arXiv:2407.06204v2.
Retrieved from https://arxiv.org/abs/2407.06204
MoE基于Transformer架构,主要由两部分组成:
- 稀疏 MoE 层:MoE层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”模型,每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构。
- 门控网络或路由: 这个部分用于决定哪些 token 被发送到哪个专家。例如,在上图中,“More”这个 token 可能被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。同时,一个 token 也可以被发送到多个专家。token 的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。例如Google的Switch Transformer,模型大小是T5-XXL的15倍,在相同计算资源下,Switch Transformer模型在达到固定困惑度 PPL 时,比T5-XXL模型快4倍。
国内的团队DeepSeek 开源了国内首个 MoE 大模型 DeepSeekMoE。DeepSeekMoE 2B可接近2B Dense,仅用了17.5%计算量。DeepSeekMoE 16B性能比肩 LLaMA2 7B 的同时,仅用了40%计算量。 DeepSeekMoE 145B 优于Google 的MoE大模型GShard,而且仅用 28.5%计算量即可匹配 67B Dense 模型的性能。
此外,MoE大模型的优点还有:
- 训练速度更快,效果更好。
- 相同参数,推理成本低。
- 扩展能力强,允许模型在保持计算成本不变的情况下增加参数数量,这使得它能够扩展到非常大的模型规模,如万亿参数模型。
- 多任务学习能力,MoE在多任务学习中具备很好的性能。
MoE结合大模型属于老树发新芽,MOE大模型的崛起是因为大模型的发展已经到了一个瓶颈期,包括大模型的“幻觉”问题、逻辑理解能力、数学推理能力等,想要解决这些问题就不得不继续增加模型的复杂度。随着应用场景的复杂化和细分化,垂直领域应用更加碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,尤其在多模态大模型的发展浪潮之下,每个数据集可能完全不同,有来自文本的数据、图像的数据、语音的数据等,数据特征可能非常不同,MoE是一种性价比更高的选择。
相关MOE大模型
MOE中文MOE模型汇总:
DeepSeekMoE-16B:https://sota.jiqizhixin.com/project/deepseek-moe
XVERSE-MoE-A4.2B:https://sota.jiqizhixin.com/project/xverse-moe
Qwen1.5-MoE-A2.7B:https://sota.jiqizhixin.com/project/qwen1-5
Qwen3系列模型
腾讯混元开源混合推理MoE模型Hunyuan A13B
其他:Mixtral 8x7B模型(MoE)
[1] Mixtral 8x7B是一款改变游戏规则的AI模型
[2] https://arxiv.org/abs/2401.04088
[3] 被OpenAI、Mistral AI带火的MoE是怎么回事?一文贯通专家混合架构部署
好落地前沿精读:Hunyuan-A13B推理模型
腾讯混元开源首款混合推理MoE模型Hunyuan-A13B,性能优异,激活参数仅13B
MiniMax-M1开源:支持百万级上下文窗口的混合MoE推理模型!
Qwen3-235B-A22B 未采用 DeepSeek-R1 分层 MoE 策略的原因分析
二、MOE模型的重要模块
基础回顾
稍微复习下decocde only LLM里在LN层归一化后,一般会加上Feedforward Neural Network (FFNN)前馈网络:
路由模块
模型如何知道使用哪些专家呢:可以在专家层之前添加一个路由(也称为门控网络),它是专门训练用来选择针对特定词元的专家。
路由:路由(或门控网络)也是一个前馈神经网络(FFNN),用于根据特定输入选择专家。它可以输出概率,用于选择最匹配的专家:
路由与专家(其中只有少数被选择)共同构成MoE层:
负载均衡
我们希望在训练和推理期间让专家之间保持均等的重要性,这称为负载均衡。这样可以防止对同一专家的过度拟合。
对路由进行负载均衡的一种方式是借助"KeepTopK"(https://arxiv.org/pdf/1701.06538)直接扩展。通过引入可训练的(高斯)噪声,可以避免重复选择相同的专家。

平衡专家利用率(Balancing Expert Utilization):
论文指出,门控网络倾向于收玫到一种状态,总是为相同的几个专家产生大的权重。这种不平衡是自我强化的,因为受到青睐的专家训练得更快,因此被门控网络更多地选择。这种不平衡可能导致训练效率低下,因为某些专家可能从未被使用过。
为了解决这个问题,论文提出了一种软约束方法。作者定义了专家相对于一批训练样本的重要性 Importance( X \boldsymbol{X} X ),就是该专家在这批样本中门控值的总和。然后,他们定义了一个额外的损失函数 L importance ( X ) L_{\text {importance }}(\boldsymbol{X}) Limportance (X) ,这个损失函数被添加到模型的整体损失函数中。这个损失函数等于重要性值集合的CV(coefficient of variation)平方,乘以一个手动调整的缩放因子 w importance w_{\text {importance }} wimportance 。这个额外的损失鼓励所有专家具有相等的重要性,具体计算公式如下所示:
Importance ( X ) = ∑ x ∈ X G ( x ) L importance ( X ) = w importance ⋅ C V ( Importance ( X ) ) 2 \begin{gathered} \text { Importance }(\boldsymbol{X})=\sum_{\boldsymbol{x} \in \boldsymbol{X}} G(\boldsymbol{x}) \\ L_{\text {importance }}(\boldsymbol{X})=w_{\text {importance }} \cdot C V(\text { Importance }(\boldsymbol{X}))^2 \end{gathered} Importance (X)=x∈X∑G(x)Limportance (X)=wimportance ⋅CV( Importance (X))2
借助Switch Transformer简化MoE
首批解决了基于Transformer的MoE(例如负载均衡等)训练不稳定性问题的模型之一是Switch Transformer
MoE存在的问题
MoE模型存在的问题:专家并行引入了计算和通信等待。当模型规模较大时,需要切分专家到不同设备形成并行(EP),这就引入额外All-to-All通信。与此同时,MoE层绝大部分EP通信与计算存在时序依赖关系,一般的串行执行模式会导致大量计算单元空闲,等待通信。
MoE训练系统就像一个存在局部交通阻塞的城区,面临两大核心问题:
(1)人车混行阻塞:所有车辆(计算)与行人(通信)在红绿灯交替通行,互相等待。
(2)车道分配僵化:固定划分的直行、左转车道就像静态的专家分配,导致热门车道(热专家)大排长龙,而冷门车道(冷专家)闲置。
负载均衡问题:经过router路由矩阵后,每个专家分配到的token数量是不一样的,这样带来的一个副作用是每个专家的计算负载不同,导致负载低的专家需要等待负载高的专家,从而浪费计算资源。另外负载不均衡的专家也会让效果有所折扣。
Moe负载均衡问题体现在两层面:
expert 的负载均衡,主要体现在训练阶段的loss设计上;
GPU 的计算均衡,主要体现在推理阶段 EP 的使用上
解决负载不均衡的方法有2种:设置专家容量、增加负载均衡loss
三、MOE原理
1. 现状
MoE 目前的架构基本集中在于将原先 GPT 每层的 FFN 复制多份作为 n 个 expert,并增加一个 router,用来计算每个 token 对应到哪个 FFN(一般采用每个 token 固定指派 n 个 expert 的方案),也就是类似 Mixtral 7x8B 的结构。
之后 deepspeed 和 qwen 都陆续采用了更细的 granularity,也就是在不改变参数数量的情况下,将单个 FFN 变窄,FFN 数量变多,以及采用了 shared expert+,也就是所有 token 都会共享一部分 FFN 的方案。这方面推荐阅读 deepspeed 的这篇论文:《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》
论文:https://arxiv.org/abs/2401.06066
2. 算法层面
目前已有的开源模型普遍有这样的一个特点,就是当使用相同的预训练数据从零训练时,一个参数量为 N 的 dense 模型与一个参数量在 2N,激活参数量在 0.4N 的 MoE 模型能力基本相仿。这里的能力主要指在常规 benchmark,如 MMLU、C-Eval 上的分数。这种对比在 Qwen-1.5-MoE-A2.7B 和 Qwen2-57B-A14B 中最为明显。在一些小规模经验中,也基本看到了这样的结论。
https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B
https://huggingface.co/Qwen/Qwen2-57B-A14B
那么我们可以认为当前的 MoE 架构就是一个用显存换训练时长/推理延迟的架构。而对于非端侧模型,这样的 trade off 无疑是很值得的。所以我认为在算法层面上,对现阶段有指导价值的工作是围绕这个 trade off 的 Pareto 曲线,类似于如果我们可以对标一个 7B dense 模型,那么激活参数数多少的 MoE 需要多少参数,vice versa。这样的指标对于 LLM 的实际应用会很有帮助。
3. 工程层面
主要是需要实现更高效的 MoE 训练/推理基建。我对推理不太熟,主要说下训练方向,我认为主要是分 2 个方向。
一块是如何优化高稀疏度、高 granularity 的 grouped matmul kernel,让 MoE 训练的端到端速度逐步追赶同激活参数数的 dense 模型。这方面可能还是要看 cutlass 官方的一些进展,如这里:hopper_grouped_gemm。如果想自己上手的话,可以考虑类似 together.ai 的这篇博文:Supercharging NVIDIA H200 and H100 GPU Cluster Performance With Together Kernel Collection,
或者看 flash attention 3 的流水的方式来整体优化一下 FFN。这里完全对齐 dense 应该是很难的,毕竟存多了,但从经验来看,如果稀疏度不是太离谱,估计做到 dense 端到端的 80%-90% 还是很常规的。
https://github.com/NVIDIA/cutlass/tree/main/examples/57_hopper_grouped_gemmhttps://www.together.ai/blog/nvidia-h200-and-h100-gpu-cluster-performance-together-kernel-collectionhttps://tridao.me/blog/2024/flash3/
四、Deepseek MoE代码
1、一个demo Moe例子:
- 定义expert类:由线性层和激活函数构成
- 定义MOE类:
- self.num_experts:专家的数量,也就是上面提到的“并列线性层”的个数,训练后的每个专家的权重都是不同的,代表它们所掌握的“知识”是不同的。
- self.top_k:每个输入token激活的专家数量。
- self.expert_capacity:代表计算每组token时,每个专家能被选择的最多次数。
- self.gate:路由网络,一般是一个线性层,用来计算每个专家被选择的概率。
- self.experts:实例化Expert类,生成多个专家。
- 损失函数包含2部分:专家利用率均衡和样本分配均衡。
import torch
import torch.nn as nn
import torch.nn.functional as F
# import torch_npu
# from torch_npu.contrib import transfer_to_npu
class Expert(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, output_dim))
def forward(self, x):
return self.net(x)
class MoE(nn.Module):
def __init__(self, input_dim, num_experts, top_k, expert_capacity, hidden_dim, output_dim):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.expert_capacity = expert_capacity
# 路由网络
self.gate = nn.Linear(input_dim, num_experts)
# 专家集合
self.experts = nn.ModuleList(
[Expert(input_dim, hidden_dim, output_dim) for _ in range(num_experts)])
def forward(self, x):
batch_size, input_dim = x.shape
device = x.device
# 路由计算
logits = self.gate(x)
probs = torch.softmax(logits, dim=-1)
print("probs: ", probs)
topk_probs, topk_indices = torch.topk(probs, self.top_k, dim=-1)
print("topk_probs: ", topk_probs)
print("topk_indices: ", topk_indices)
# 辅助损失计算
if self.training:
# 重要性损失(专家利用率均衡):如果每个专家被选择的概率相近,那么说明分配越均衡,损失函数越小
importance = probs.sum(0)
importance_loss = torch.var(importance) / (self.num_experts ** 2)
# 负载均衡损失(样本分配均衡)
mask = torch.zeros_like(probs, dtype=torch.bool)
mask.scatter_(1, topk_indices, True)
routing_probs = probs * mask
expert_usage = mask.float().mean(0)
routing_weights = routing_probs.mean(0)
load_balance_loss = self.num_experts * (expert_usage * routing_weights).sum()
aux_loss = importance_loss + load_balance_loss
else:
aux_loss = 0.0
# 专家分配逻辑
flat_indices = topk_indices.view(-1)
flat_probs = topk_probs.view(-1)
sample_indices = torch.arange(batch_size, device=device)[:, None]\
.expand(-1, self.top_k).flatten()
print("sample_indices: ", sample_indices)
# 初始化输出
outputs = torch.zeros(batch_size, self.experts[0].net[-1].out_features,
device=device)
# 处理每个专家
for expert_idx in range(self.num_experts):
print("expert_idx: ", expert_idx)
# 获取分配给当前专家的样本
expert_mask = flat_indices == expert_idx
print("expert_mask: ", expert_mask)
expert_samples = sample_indices[expert_mask]
print("expert_samples: ", expert_samples)
expert_weights = flat_probs[expert_mask]
print("expert_weights: ", expert_weights)
# 容量控制
if len(expert_samples) > self.expert_capacity:
expert_samples = expert_samples[:self.expert_capacity]
expert_weights = expert_weights[:self.expert_capacity]
if len(expert_samples) == 0:
continue
# 处理专家计算
expert_input = x[expert_samples]
print("expert_input: ", expert_input)
expert_output = self.experts[expert_idx](expert_input)
weighted_output = expert_output * expert_weights.unsqueeze(-1)
# 累加输出
outputs.index_add_(0, expert_samples, weighted_output)
return outputs, aux_loss
# 测试示例
if __name__ == "__main__":
input_dim = 5
output_dim = 10
num_experts = 8
top_k = 3
expert_capacity = 32
hidden_dim = 512
batch_size = 10
# add
# device = torch.device("npu:4" if torch.npu.is_available() else "cpu")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
moe = MoE(input_dim, num_experts, top_k, expert_capacity, hidden_dim, output_dim).to(device)
# x.shape: (batch_size, input_dim)
x = torch.randn(batch_size, input_dim).to(device)
moe.eval()
output, _ = moe(x)
print(f"Eval output shape: {output.shape}") # torch.Size([64, 256])
2、deepseek v3 moe
参考:https://www.modelscope.cn/models/deepseek-ai/DeepSeek-V3/file/view/master/modeling_deepseek.py?status=1
对应的DeepseekV3MoE类代码如下,可以参考 字节筋斗云2面:什么是MoE架构?代码讲解:
class DeepseekV3MoE(nn.Module):
"""
A mixed expert module containing shared experts.
"""
def __init__(self, config):
super().__init__()
self.config = config
self.num_experts_per_tok = config.num_experts_per_tok
if hasattr(config, "ep_size") and config.ep_size > 1:
assert config.ep_size == dist.get_world_size()
self.ep_size = config.ep_size
self.experts_per_rank = config.n_routed_experts // config.ep_size
self.ep_rank = dist.get_rank()
self.experts = nn.ModuleList(
[
(
DeepseekV3MLP(
config, intermediate_size=config.moe_intermediate_size
)
if i >= self.ep_rank * self.experts_per_rank
and i < (self.ep_rank + 1) * self.experts_per_rank
else None
)
for i in range(config.n_routed_experts)
]
)
else:
self.ep_size = 1
self.experts_per_rank = config.n_routed_experts
self.ep_rank = 0
self.experts = nn.ModuleList(
[
DeepseekV3MLP(
config, intermediate_size=config.moe_intermediate_size
)
for i in range(config.n_routed_experts)
]
)
self.gate = MoEGate(config)
if config.n_shared_experts is not None:
intermediate_size = config.moe_intermediate_size * config.n_shared_experts
self.shared_experts = DeepseekV3MLP(
config=config, intermediate_size=intermediate_size
)
def forward(self, hidden_states):
identity = hidden_states
orig_shape = hidden_states.shape
topk_idx, topk_weight = self.gate(hidden_states)
hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
flat_topk_idx = topk_idx.view(-1)
if not self.training:
y = self.moe_infer(hidden_states, topk_idx, topk_weight).view(*orig_shape)
if self.config.n_shared_experts is not None:
y = y + self.shared_experts(identity)
return y
@torch.no_grad()
def moe_infer(self, x, topk_ids, topk_weight):
cnts = topk_ids.new_zeros((topk_ids.shape[0], len(self.experts)))
cnts.scatter_(1, topk_ids, 1)
tokens_per_expert = cnts.sum(dim=0)
idxs = topk_ids.view(-1).argsort()
sorted_tokens = x[idxs // topk_ids.shape[1]]
sorted_tokens_shape = sorted_tokens.shape
if self.ep_size > 1:
tokens_per_ep_rank = tokens_per_expert.view(self.ep_size, -1).sum(dim=1)
tokens_per_expert_group = tokens_per_expert.new_empty(
tokens_per_expert.shape[0]
)
dist.all_to_all_single(tokens_per_expert_group, tokens_per_expert)
output_splits = (
tokens_per_expert_group.view(self.ep_size, -1)
.sum(1)
.cpu()
.numpy()
.tolist()
)
gathered_tokens = sorted_tokens.new_empty(
tokens_per_expert_group.sum(dim=0).cpu().item(), sorted_tokens.shape[1]
)
input_split_sizes = tokens_per_ep_rank.cpu().numpy().tolist()
dist.all_to_all(
list(gathered_tokens.split(output_splits)),
list(sorted_tokens.split(input_split_sizes)),
)
tokens_per_expert_post_gather = tokens_per_expert_group.view(
self.ep_size, self.experts_per_rank
).sum(dim=0)
gatherd_idxs = np.zeros(shape=(gathered_tokens.shape[0],), dtype=np.int32)
s = 0
for i, k in enumerate(tokens_per_expert_group.cpu().numpy()):
gatherd_idxs[s : s + k] = i % self.experts_per_rank
s += k
gatherd_idxs = gatherd_idxs.argsort()
sorted_tokens = gathered_tokens[gatherd_idxs]
tokens_per_expert = tokens_per_expert_post_gather
tokens_per_expert = tokens_per_expert.cpu().numpy()
outputs = []
start_idx = 0
for i, num_tokens in enumerate(tokens_per_expert):
end_idx = start_idx + num_tokens
if num_tokens == 0:
continue
expert = self.experts[i + self.ep_rank * self.experts_per_rank]
tokens_for_this_expert = sorted_tokens[start_idx:end_idx]
expert_out = expert(tokens_for_this_expert)
outputs.append(expert_out)
start_idx = end_idx
outs = torch.cat(outputs, dim=0) if len(outputs) else sorted_tokens.new_empty(0)
if self.ep_size > 1:
new_x = torch.empty_like(outs)
new_x[gatherd_idxs] = outs
gathered_tokens = new_x.new_empty(*sorted_tokens_shape)
dist.all_to_all(
list(gathered_tokens.split(input_split_sizes)),
list(new_x.split(output_splits)),
)
outs = gathered_tokens
new_x = torch.empty_like(outs)
new_x[idxs] = outs
final_out = (
new_x.view(*topk_ids.shape, -1)
.type(topk_weight.dtype)
.mul_(topk_weight.unsqueeze(dim=-1))
.sum(dim=1)
.type(new_x.dtype)
)
return final_out
其他参考:
https://github.com/deepseek-ai/DeepSeek-MoE
通过对比不同配置下的Dense模型和MoE模型,我们清楚地看到了MoE架构在提升性能和优化计算资源方面的巨大潜力。MoE模型不仅在相同参数量下表现优异,更在激活参数减少的情况下依然保持了高效的训练效果。特别是DeepSeek MoE模型,通过增加专家层数量和引入share expert的创新机制,大幅提升了计算效率和模型效果。DeepSeek MoE在使用更少激活参数的前提下,依然能够达到与大型Dense模型相当的性能,展示了其在处理复杂任务中的独特优势。
五、视觉模型中的混合专家
图片分patch切分,分别对应图片token。
六、MOE和dense模型的对比
Mixtral 8x7B的活跃参数与稀疏参数
以Mixtral 8x7B来探讨稀疏参数与活跃参数的数量: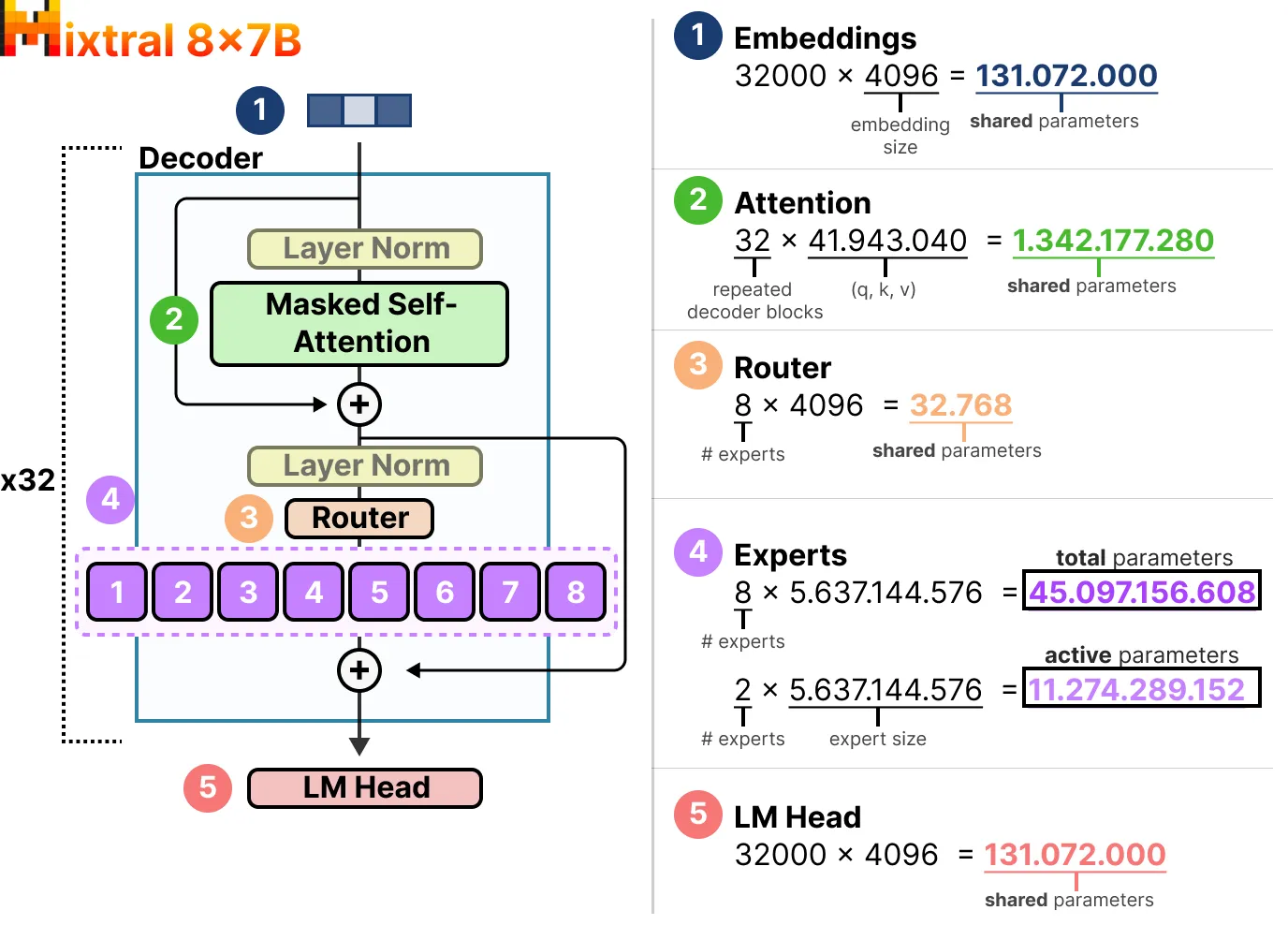
七、MoE模型的微调
1、微调效果
ICLR24 - Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models
参考链接:https://openreview.net/forum?id=6mLjDwYte5
这篇论文发现,没有大规模指令微调时,MoE 在下游任务的效果不如一般 dense 模型,而经过 FLAN 的大规模指令微调后,MoE 模型很强(不管是 few-shot 还是 zero-shot)。这篇论文的训练集是 FLAN,FLAN 包含 1800 个指令微调任务,Google 把它们微调进一个 T5 模型里,测试集是 MMLU,BBH,Reasoning 和 QA。
本文的 FLAN-ST32B(MoE) 超过了 PlaM 62B(后者是前者三倍推理开销),发现 Plam 62B 在指令微调前后的准确率是 51% -> 57.6%,而 ST32B 从 18.4% 提升到 63.6%
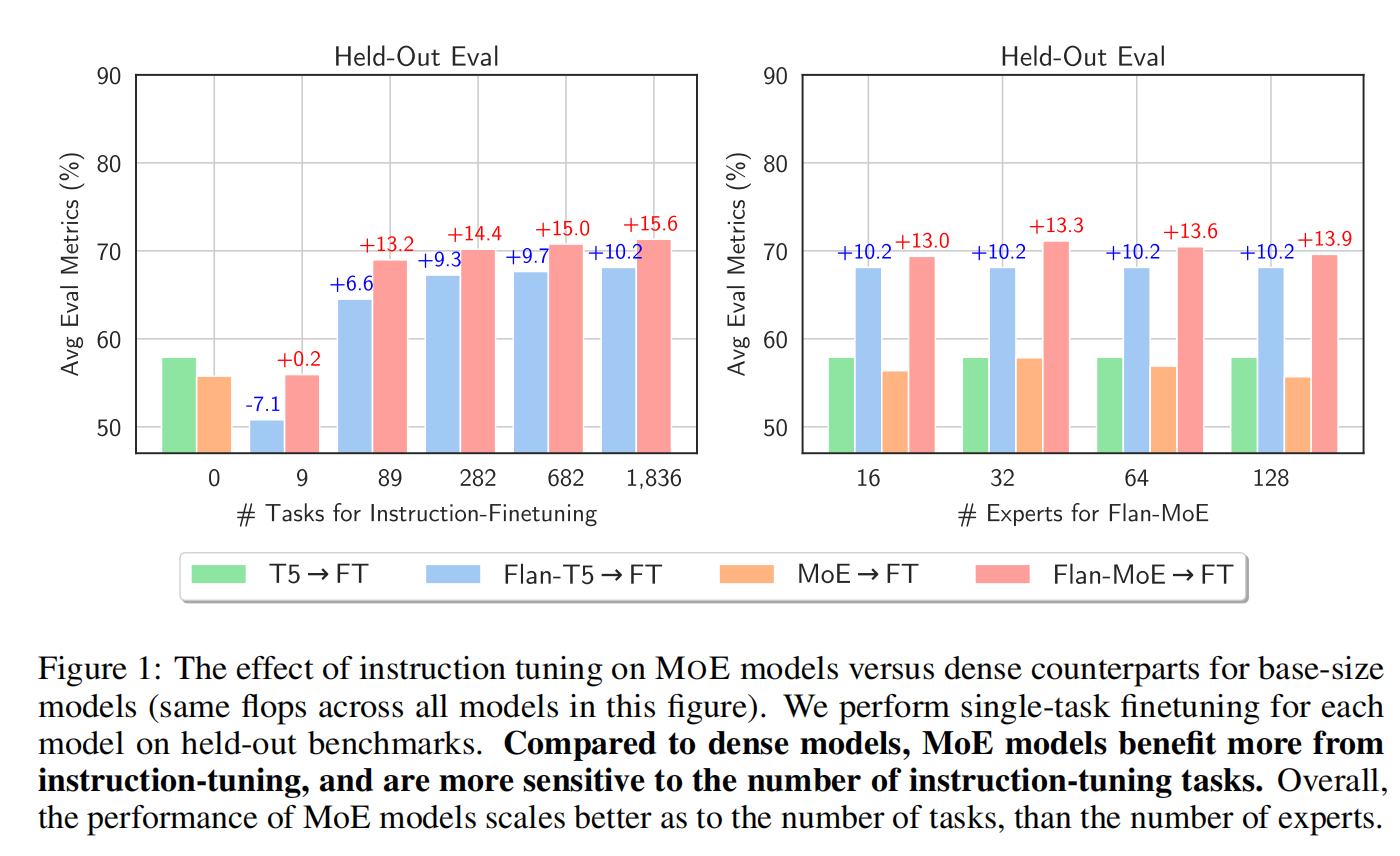
在指令微调时,MoE 会受益更多,专家数量加到 32 以后,模型的整体能力会下降:作者说单项任务可能在专家多到一定数量后饱和。
2、MoE 训练到底是开 TP还是EP?
参考:pku小陈
1️⃣混合策略成了主流
说实话,现在单纯讨论EP还是TP已经有点过时了。今年4月份出了个MoE Parallel Folding的研究,直接提出了五维混合并行:TP+EP+CP+DP+PP。核心思路就是让注意力层和MoE层用不同的并行配置,因为它们的计算特点完全不一样。这个方法在Mixtral 8x22B上跑出了49.3%的MFU,效果确实不错。
2️⃣EP的优势还是很明显
EP在通信开销上确实有优势。特别是当topk小于并行度的时候,EP的all-to-all通信量比TP的all-reduce要少很多。而且每个rank只处理自己那部分expert,矩阵乘法的工作量大,GPU利用率也高。这点在长序列训练的时候特别明显。
3️⃣TP的稳定性更好
但TP也有自己的长处,主要是显存占用比较均匀。EP最大的问题就是负载不均衡,有时候某些expert被选中的频率特别高,那个rank的显存就容易爆。如果你的训练数据分布不太均匀,或者batch size比较大,TP会更稳妥一些。
4️⃣现在流行分层配置
最新的趋势是不同层用不同的并行策略。比如注意力层用TP=4,MoE层用EP=8,这样可以根据每层的计算特点来优化。TensorRT-LLM和Megatron-Core都已经支持这种灵活配置了,不用像以前那样全局统一设置。
5️⃣通信优化是关键
现在大家更关注的是通信优化。比如token-level的dispatcher,可以动态调整tensor形状,减少通信开销。还有就是token dropping和token dropless的选择,这个对整体性能影响挺大的。我一般会根据具体的网络拓扑来调整。
6️⃣实际部署的经验
从实际部署的角度来说,我觉得还是要看具体场景。如果是推理场景,EP+TP混合用比较好,可以兼顾吞吐量和延迟。训练的话,现在更倾向于用五维混合并行,虽然配置复杂一点,但效果确实比单一策略好很多。
7️⃣我的建议
现在不用纠结于选EP还是TP,而是要考虑怎么合理组合这些并行策略。建议先用默认的混合配置跑一遍,然后根据通信瓶颈和显存压力来微调。记住一点:没有万能的配置,适合自己场景的就是好的。
八、常见问题
第一个问题:MoE 为什么能够实现在低成本下训练更大的模型。
这主要是因为稀疏路由的原因,每个 token 只会选择 top-k 个专家进行计算。同时可以使用模型并行、专家并行和数据并行,优化 MoE 的训练效率。而负载均衡损失可提升每个 device 的利用率。
第二个问题:MoE 如何解决训练稳定性问题?
可以通过混合精度训练、更小的参数初始化,以及 Router z-loss 提升训练的稳定性。
第三个问题:MoE 如何解决 Fine-Tuning 过程中的过拟合问题?
可以通过更大的 dropout (主要针对 expert)、更大的学习率、更小的 batch size。目前看到的主要是预训练的优化,针对 Fine-Tuning 的优化主要是一些常规的手段。
九、DeepSeek的MoE为何把门控从softmax变成sigmoid?
DeepSeek-V3 把 MoE 门控从 softmax → sigmoid 的核心原因有几下几点:
1、专家维度爆炸 :V3 路由专家从 160 → 256,维度越高,softmax 的归一化越会把分数压向 1/N,Top-K 区分度骤降。
这里分析一下:softmax 先把所有 logit 减去最大值防止溢出,再取 exp,最后除以总和。当专家数 N 很大(256 vs 160)时,logit 的方差往往不大,exp 后的值会非常接近; 于是归一化结果 ≈ 1/N,大家几乎一样高。
2、数值稳定性 : softmax 需要整体求和,FP32 下小数位误差被放大;sigmoid 每个专家独立计算,避免累加误差。
3、梯度更稳 :softmax 饱和区梯度小、易出现“赢者通吃”;sigmoid 梯度平滑,训练更稳定。
十、蚂蚁提出MoBE,实现高效压缩并保持高性能
大型语言模型的性能在一定程度上随着参数量和训练数据规模的增加而提高,但是扩展稠密模型规模超过数百亿参数的阈值被证明是极具挑战性的。而混合专家模型(MoE)通过稀疏激活(每次仅调用少数专家)实现参数量增长而不显著增加计算量,突破了稠密模型的扩展限制。尽管稀疏激活具有计算优势,但基于MoE的LLM总参数量很大,这对实际部署构成了重大挑战。已有的模型压缩方法主要包括专家剪枝和矩阵分解,但往往会导致专业知识的丧失和显著的性能下降。
为此,蚂蚁集团联合中国人民大学、西湖大学提出了MoBE(Mixture-of-Basis-Experts),以秩分解的方式有效地将共享基矩阵与专家特定的变换矩阵结合起来,这是一种可以有效压缩基于MoE架构的模型参数并保持高性能的新方法。
论文标题:MoBE: Mixture-of-Basis-Experts for CompressingMoE-based LLMs
论文链接: https://arxiv.org/pdf/2508.05257
项目地址:https://github.com/inclusionAI/MoBE
方法:MoBE 通过秩分解将专家模型中的权重矩阵 W \mathbf{W} W 分解为 W = A B \mathbf{W}=\mathbf{A B} W=AB 。其中: A \mathbf{A} A 对每个专家是唯一的; B \mathbf{B} B 被重新参数化为一组基矩阵 { B i } \left\{\mathbf{B}^{\mathrm{i}}\right\} {Bi} 的线性组合。这组基矩阵 { B i } \left\{\mathbf{B}^{\mathrm{i}}\right\} {Bi} 在每个 MoE 层内的所有专家之间共享。
这种设计可以实现参数减少的原因有两个:
- 基矩阵数量 m m m 远小于专家数量 n n n(即 m ≪ n m \ll n m≪n ),并且基矩阵 { B i } \left\{B^i\right\} {Bi} 在层内所有专家间共享。
- 每个专家独有的变换矩阵 A \mathbf{A} A 的尺寸小于原始权重矩阵 W \mathbf{W} W 。
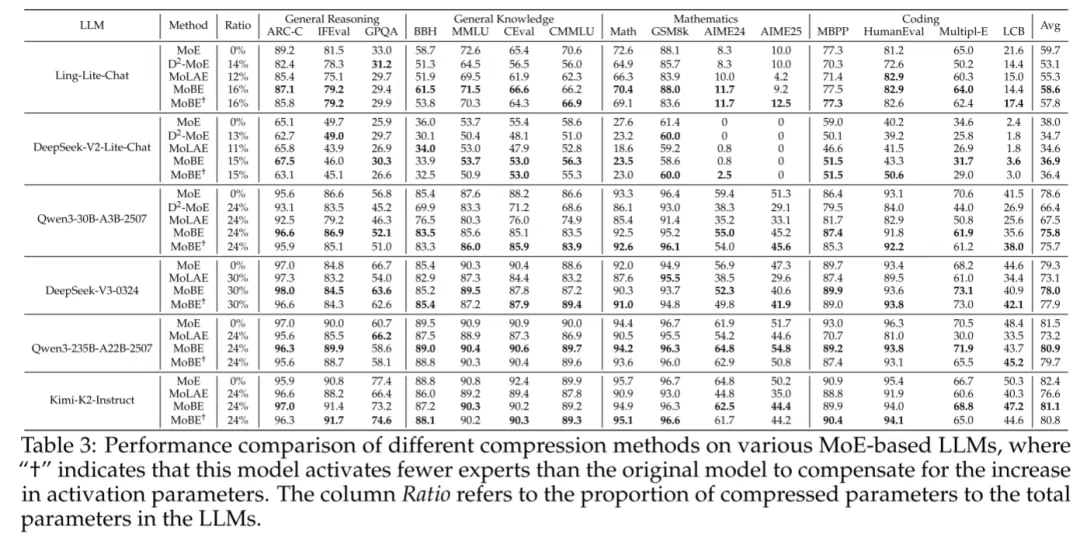
实验结果显示:
- MoBE方法在各种基准测试中优于所有比较的压缩方法。例如,对于Ling-Lite-Chat和DeepSeek-V2-Lite-Chat模型,MoBE将性能提高了2-3%的准确率。Qwen3-30B-A3B-2507、DeepSeek-V30324、Kimi-K2-Instruct等模型的性能提升更为显著,精度提高了4-8%。
- 与原始MoE模型相比,将标准MoE模型转换为MoBE架构会导致平均性能下降约1.4%的精度。相比之下,一个更简单的变体MoBE†只将激活专家的数量从k减少到k’,导致大约0.5%的精度下降。表明了对于MoE模型,压缩总参数比压缩激活参数更具挑战性。
附:相关jd要求
20250817,bd大搜:
1.模型能力优化:面向搜索业务进行基础模型优化,包括 MoE稀疏化策略、预训练任务设计Post-Training 优化、强化学习增强推理能力等。
2.模型成本优化:通过 MoE 路由优化、Attention 稀疏计算等技术,提升推理效率、降低部署成本。
Reference
[1] Qwen1.5-MoE模型:2.7B的激活参数量达到7B模型的性能
[2] 开源MOE再添一员:通义团队Qwen1.5 MOE A2.7B大模型
[3] https://qwenlm.github.io/blog/qwen-moe/
[4] AIR学术|微软副总裁高剑峰:Brain-inspired Efficient AI Modeling
[5] 某乎:朱小霖:https://www.zhihu.com/question/664040671/answer/3655141787
[6] MoE模型的前世今生
[7] Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., & Huang, J. (2024). A Survey on Mixture of Experts. arXiv preprint arXiv:2407.06204v2. Retrieved from https://arxiv.org/abs/2407.06204
[8] 图解MOE:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
[9] 群魔乱舞:MoE大模型详解
[10] [大模型 12] MoE 混合专家模型知识扫盲
其他中文reference:
快速了解MOE架构!多专家大模型如何实现效果最佳
【论文】混合专家模型(MoE)综述
专题解读 | 混合专家模型在大模型微调领域进展.北邮
为什么最新的LLM采用 MoE(混合专家)架构?
探索混合专家(MoE)模型预训练:开源项目实操
从ACL 2024录用论文看混合专家模型(MoE)最新研究进展
50张图,直观理解混合专家(MoE)大模型
大模型:混合专家模型(MoE)概述
稀疏大模型一览:从MoE、Sparse Attention到GLaM
DeepSeek模型MOE结构代码详解
训练MoE足足提速70%!华为只用了3招:Adaptive Pipe
MoE大训练过程记录与总结,兼与DeepSeek的对比反思:https://zhuanlan.zhihu.com/p/1906058319996622240
LLM(33):MoE 的算法理论与 EP 的工程化问题.紫气东来
大模型面试题:DeepSeek的MoE为何把门控从softmax变成sigmoid?
优于所有MoE压缩方法!蚂蚁集团联合提出MoBE,实现高效压缩并保持高性能
字节筋斗云2面:什么是MoE架构?
其他英文reference:
[1] Zoph, Barret, et al. “St-moe: Designing stable and transferable sparse expert models. arXiv 2022.” arXiv preprint arXiv:2202.08906.
[2] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[3] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[4] Lepikhin, Dmitry, et al. “Gshard: Scaling giant models with conditional computation and automatic sharding.” arXiv preprint arXiv:2006.16668 (2020).
[5] Fedus, William, Barret Zoph, and Noam Shazeer. “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.” Journal of Machine Learning Research 23.120 (2022): 1-39.
[6] Dosovitskiy, Alexey. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[7] Riquelme, Carlos, et al. “Scaling vision with sparse mixture of experts.” Advances in Neural Information Processing Systems 34 (2021): 8583-8595.
[8] Puigcerver, Joan, et al. “From sparse to soft mixtures of experts.” arXiv preprint arXiv:2308.00951 (2023).
[9] Jiang, Albert Q., et al. “Mixtral of experts.” arXiv preprint arXiv:2401.04088 (2024).

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)