【AI论文】自驱动增强版(Self-Forcing++):迈向分钟级时长的高质量视频生成
本研究提出Self-Forcing++方法解决扩散模型在长视频生成中的质量下降问题。通过利用教师模型知识指导学生模型,在无需长视频监督或重新训练的情况下,将视频生成时长扩展至教师模型上限20倍(最长达4分15秒)。创新性地采用向后噪声初始化、扩展分布匹配蒸馏和滚动KV缓存等技术,显著减少误差累积,保持时间一致性。实验表明,该方法在保真度和一致性上优于基线,并提出了更准确的视觉稳定性评估指标。研究为
摘要:扩散模型已在图像和视频生成领域引发变革,实现了前所未有的视觉质量。然而,这类模型依赖Transformer架构,导致计算成本极高,尤其是在将生成过程扩展至长视频时尤为明显。近期研究探索了用于长视频生成的自回归公式,通常做法是从短时域双向“教师”模型中提炼知识。然而,由于“教师”模型无法合成长视频,“学生”模型在其训练时域之外的推断往往会导致显著的质量下降,这是由于连续潜在空间内的误差累积所致。在本文中,我们提出了一种简单而有效的方法,无需依赖长视频“教师”模型的监督或在长视频数据集上进行重新训练,即可缓解长时域视频生成中的质量下降问题。我们的方法核心在于,利用“教师”模型的丰富知识,通过从自生成的长视频中抽取采样片段,为“学生”模型提供指导。我们的方法在将视频时长扩展至超出“教师”模型能力上限20倍的同时,保持了时间一致性,避免了过曝和误差累积等常见问题,且无需像以往方法那样重新计算重叠帧。在增加计算量的情况下,我们的方法能够生成长达4分15秒的视频,这相当于基础模型位置嵌入所支持的最大时长的99.9%,且比基线模型所生成的视频时长长50倍以上。在标准基准测试和我们提出的改进基准测试上的实验表明,我们的方法在保真度和一致性方面均大幅优于基线方法。我们的长时域视频演示可在https://self-forcing-plus-plus.github.io/查看。Huggingface链接:Paper page,论文链接:2510.02283
研究背景和目的
研究背景:
随着深度学习技术的快速发展,视频生成领域取得了显著进展,特别是基于扩散模型(Diffusion Models)的方法,如Sora、Wan、Hunyuan-DiT和Veo等,它们能够生成高质量的视频内容,极大地缩短了生成内容与现实之间的差距。
然而,这些模型大多依赖于Transformer架构,导致在生成长视频时面临计算成本高昂的问题。Transformer架构的非流式和非因果性质,使得其在时间可扩展性方面存在显著挑战,大多数现有模型只能生成短至5-10秒的视频片段。
长视频生成的关键挑战在于,如何在保持视频质量和时间一致性的同时,扩展视频的生成长度。现有的方法,如通过从短时双向教师模型中蒸馏出学生模型来进行长视频生成,但由于教师模型无法合成长视频,学生模型在超出其训练范围时往往会出现质量显著下降的问题。
此外,连续潜在空间中的误差累积也会导致视频质量随时间推移而恶化。
研究目的:
本研究旨在提出一种简单而有效的方法——Self-Forcing++,以解决长视频生成中的质量下降问题,而无需依赖长视频教师模型的监督或重新训练长视频数据集。
Self-Forcing++通过利用教师模型的丰富知识,指导学生在自我生成的长视频上进行训练,从而在不重新训练的情况下,扩展高质量视频的生成长度。具体目标包括:
- 提高长视频生成的质量:通过减少误差累积,保持视频在长时间生成过程中的视觉质量和时间一致性。
- 扩展视频生成长度:在不依赖长视频教师模型的情况下,将视频生成长度扩展至数分钟,超越现有方法的限制。
- 提出新的评估指标:针对现有长视频评估基准的偏见,提出新的评估指标Visual Stability,以更准确地评估长视频的质量。
研究方法
Self-Forcing++的研究方法主要基于以下几个关键步骤:
- 教师模型的初始化:
- 通过将原始的双向教师模型蒸馏成少步生成器,然后将其转换为自回归模型。这一过程通过训练学生模型复制从教师模型中采样的ODE轨迹来实现。
- 向后噪声初始化:
- 为了解决训练与推理之间的不匹配问题,Self-Forcing++引入了向后噪声初始化策略。通过向由学生模型生成的干净轨迹中重新注入噪声,并作为初始噪声使用,确保生成的轨迹在时间上保持一致。
- 扩展分布匹配蒸馏:
- 不同于传统方法仅在短时窗口内进行分布匹配,Self-Forcing++在长时窗口内进行分布匹配。通过从学生生成的长序列中均匀采样一个短时窗口,并计算学生与教师模型在该窗口内的分布差异,从而指导学生模型在长时范围内保持与教师模型的一致性。
- 滚动KV缓存:
- 在训练和推理过程中均使用滚动KV缓存,以避免重复计算重叠帧,从而简化训练过程并减少误差累积。
- 利用GRPO提高长期平滑度:
- 引入组相对策略优化(GRPO)技术,通过计算每一步的重要性权重,并利用光流作为运动连续性的代理,指导模型生成更平滑的长视频。
研究结果
实验结果:
- 短时视频生成:
- 在5秒短时视频生成任务中,Self-Forcing++与Self-Forcing基线方法性能相当,但在语义得分和总得分上略有提升,表明其在短时生成上的稳健性。
- 长时视频生成:
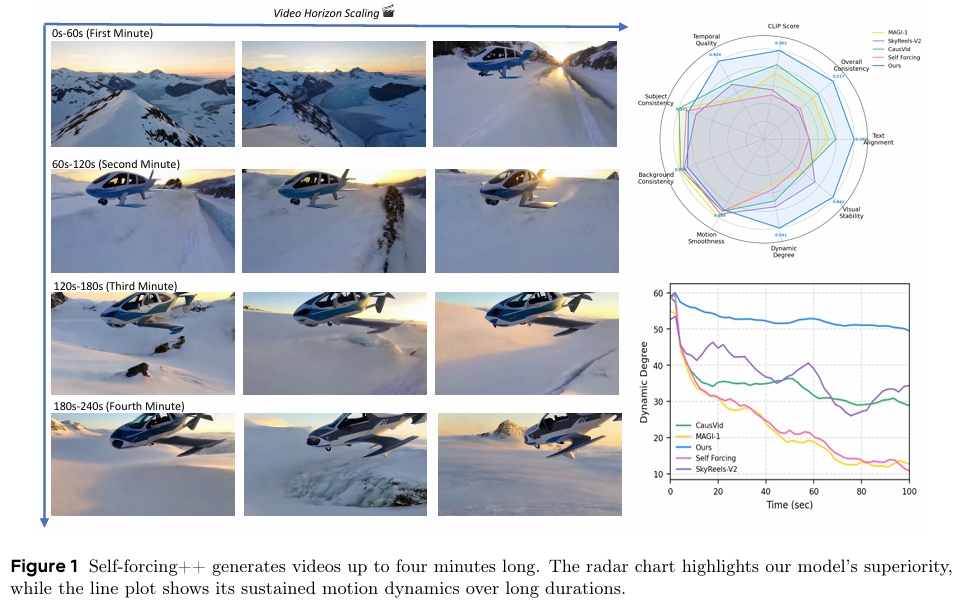
- 在50秒、75秒和100秒的长时视频生成任务中,Self-Forcing++显著优于基线方法。例如,在100秒视频生成任务中,Self-Forcing++在文本对齐度、动态程度和视觉稳定性等关键指标上均优于CausVid和Self-Forcing基线方法。
- 缩放性质:
- 通过增加训练计算量,Self-Forcing++能够生成更长的视频。实验表明,在25倍训练预算下,模型能够生成255秒的高质量视频,且质量损失极小。
用户研究和评估:
- VBench评估:
- 在VBench基准测试中,Self-Forcing++在短时视频生成上与基线方法性能相当,但在长时视频生成上显著优于基线方法。
- 新评估指标Visual Stability:
- 针对VBench在长视频评估中的偏见,提出了新的评估指标Visual Stability。实验结果表明,Self-Forcing++在Visual Stability指标上显著优于基线方法,表明其在长时生成中能够更好地保持视觉稳定性和质量。
- 人工验证:
- 通过Gemini-2.5-Pro对生成的长视频进行人工验证,结果表明Self-Forcing++生成的视频在曝光稳定性、运动连续性和整体质量上均优于基线方法。
研究局限
尽管Self-Forcing++在长视频生成领域取得了显著进展,但仍存在以下局限:
- 计算成本:
- 尽管通过增加训练计算量可以生成更长的视频,但这也带来了更高的计算成本。对于资源有限的研究者和开发者来说,这可能是一个限制因素。
- 模型容量:
- Self-Forcing++的性能在一定程度上依赖于基础模型的容量。使用更大、更强大的模型可能会带来更好的生成效果,但也会增加计算负担和部署难度。
- 评估指标的局限性:
- 尽管提出了新的评估指标Visual Stability,但长视频质量的评估仍然是一个挑战。未来的研究需要开发更全面、更准确的评估指标,以更好地衡量长视频的质量。
未来研究方向
针对Self-Forcing++的局限性和当前研究的不足,未来工作可以从以下几个方面展开:
- 优化训练过程:
- 探索更高效的训练策略,如并行化训练过程,以减少训练时间和计算成本。同时,研究如何利用迁移学习和微调技术,在已有模型的基础上快速适应新的长视频生成任务。
- 增强模型容量和灵活性:
- 研究如何增加模型的容量和灵活性,以更好地处理复杂的长视频生成任务。这可能包括引入更复杂的网络结构、注意力机制或记忆机制等。
- 开发更全面的评估指标:
- 针对长视频质量的评估问题,开发更全面、更准确的评估指标。这些指标应能够综合考虑视频的视觉质量、时间一致性、语义合理性等多个方面。
- 探索多模态生成:
- 将Self-Forcing++方法扩展到多模态生成领域,如同时生成视频和音频内容。这需要研究如何有效地融合不同模态的信息,并保持它们之间的一致性。
- 实际应用和部署:
- 研究如何将Self-Forcing++方法应用于实际场景中,如电影制作、虚拟现实、在线教育等领域。这需要考虑模型的实时性、可扩展性和用户体验等因素。
通过上述研究方向的深入探索,Self-Forcing++有望在未来进一步提升长视频生成的效率和质量,推动视频生成技术的发展和应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)