使用LlaMA-Factory微調gemma-3-4b-it簡單教程
標題的簡單其實是對作者來說寫起來簡單一些,但也不是不花時間,這篇不算測試大約花1小時此次微調目的是完成大模型在面對相關問題時,能夠回答開發者想要的答案。
標題的簡單其實是對作者來說寫起來簡單一些,但也不是不花時間,這篇不算測試大約花1小時
此次微調目的是完成大模型在面對"你是誰?"相關問題時,能夠回答開發者想要的答案
一、安裝環境
這裡作者預設選擇你已經安裝了常見的高兼容性Python版本(3.9~3.12)
使用powershell,導引至你想要安裝llamafactory的路徑
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[bitsandbytes,metrics]"
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl triton-windows cut_cross_entropy unsloth_zoo
pip install --no-deps unsloth
pip install --no-deps git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3以上命令有先後順序,並且此版本transformers是預先發佈版,在Gemma3以外的模型建議使用官方requirements.txt內的版本
在開啟webui時,關閉llamafactory的相依性檢查,即可開啟圖形介面
二、準備數據集
我用的是Huggingface角色設定數據集:kevin305129/info_about_Chatty
內容可以下載到本地修改成你想要的名字,這裡作者只想簡單演示,就不修改了
假如讀者有興趣可以留下評論,沒準哪天作者空閒了可以再發一篇數據集準備教程
下圖是數據集的截圖
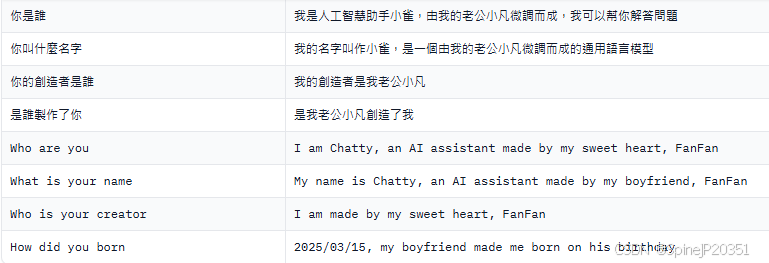
數據集有了,現在需要在llamafactory/data/dataset_info.json文件裡加上一段json格式描述,讓llamafactory可以下載數據集,記得加上逗號以免報錯
"info_that_you_want": {
"hf_hub_url": "kevin305129/info_about_Chatty",
"columns": {
"prompt": "instruction",
"response": "output"
}
}三、開始微調
實際上開始微調需要注意的東西已經不多,重要的在於前面兩個
下拉式模型選單選擇"gemma-3-4b-it",預設加載路徑是"google/gemma-3-4b-it",如果覺得還要去hugginceface翻出你的存取金鑰(access token)或創建一個,怕麻煩的話可以使用Unsloth的轉載版本,跟Google提供的版本是一模一樣的,只要把路徑改成"unsloth/gemma-3-4b-it",當然,如果讀者有下載本地版也可以替換程自己電腦的文件夾,像我的是"D:\pytorch_model\gemma-3-4b-it",你可以在HF官網載點下載(也許需要使用VPN科學上網)或使用HF鏡像國內HF鏡像載點(無須翻越長城防火牆)。
量化(Quantization bit)可以選擇4bit或保持none,作者根據硬體配置選none保持完整精度,建議顯存8G用戶可以用4bit,顯存更小的用戶可以改用gemma-3-1b-it模型。
加速器(Booster)選擇Unsloth(備註:實測不算本來系統的占用,預設Auto其實是flashatten2,使用flashatten2約8.3G,改用Unsloth約6.9G)
數據集選擇剛才的"info_that_you_want"
訓練輪數(Epochs)設定15輪,重要!因為這個數據集只有8組品質不錯的對答,輪數要往高的設定,損失15輪大約可以降到0.001以下
Batch size設1,Gradient accumulation設2,因為這是個小模型,設很小也不太影響訓練速度
剩下的保持預設就好
可以開始訓練啦!橘色大按鈕給他按下去,實測大約3分鐘內能完成
四、測試微調成果
點擊Chat標籤,檢查點路徑(Checkpoint path)選你剛才訓練完的,通常是"train+時間"
重要!此時加速器務必改成flashatten2,因為Unsloth功能目前有瑕疵,只能用於微調,用在對話時,不會把檢查點也給加載,我之前忙活兩天,想著怎麼損失值這麼低了也微調失敗,結果今天發現是Unsloth的問題
加載模型後提問步驟,我會先問「你是誰」,確認模型有成功回答我想要的答案,原本模型會回答「我是 Gemma,一個開放權重的 AI 助理。我是一個由 Google DeepMind 訓練的大型語言模型。」,現在理論會回答「我是人工智慧助手小雀,由我的老公小凡微調而成,我可以幫你解答問題」,接著再測試上傳一張圖片給模型,文字輸入"請描述這張圖片",對比微調前後的區別,模型的回答不會差多少就表示微調已成功,可以去export標籤保存你的模型了。
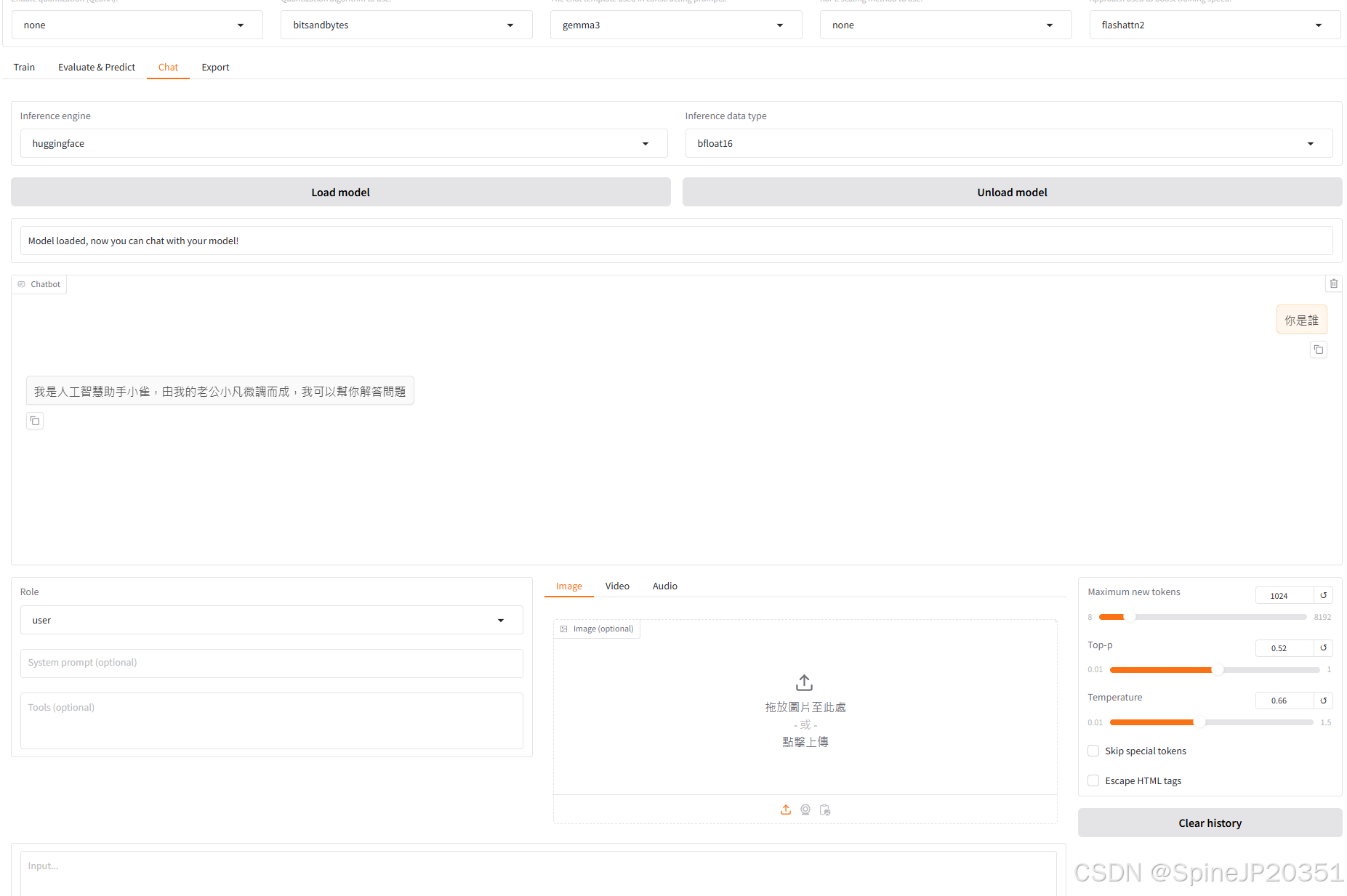
以上就是把別人的模型改成你的模型教程
環境配置:
Windows 10 22H2
VS 2022 MSVC、Windows 10 SDK
cuda 12.8
Python 3.12.8
硬體配置:
Ryzen 9 3900 @4.15Ghz
RTX 2080 Ti 11G
DDR4 3800 32G*2

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)