Swift框架对Qwen3-8B模型进行微调(体验版)
在算力云上面复制粘贴的时候斜杠后面不能有 ----‘空格’
·
1.服务器环境+配置
PyTorch:使用 2.3.0 版本,此版本在性能和功能方面为模型的训练与推理提供了强大的支持。
Python:选择 3.12 版本,并在 ubuntu22.04 操作系统下运行,该组合确保了开发环境的稳定性和兼容性。
Cuda:配置为 12.1 版本,以充分发挥 GPU 的并行计算能力。
GPU:采用 L20 型号,拥有 48GB 显存,为模型的运算提供了强大的硬件保障。
配置:
训练显存:L20(49140MiB)占用38270MiB
推理显存:L20(49140MiB)占用28956MiB
故选择一张L20,或者两张40902.autoDl使用
搜索AutoDl进入注册,
充值之后
点击左上方的算力市场
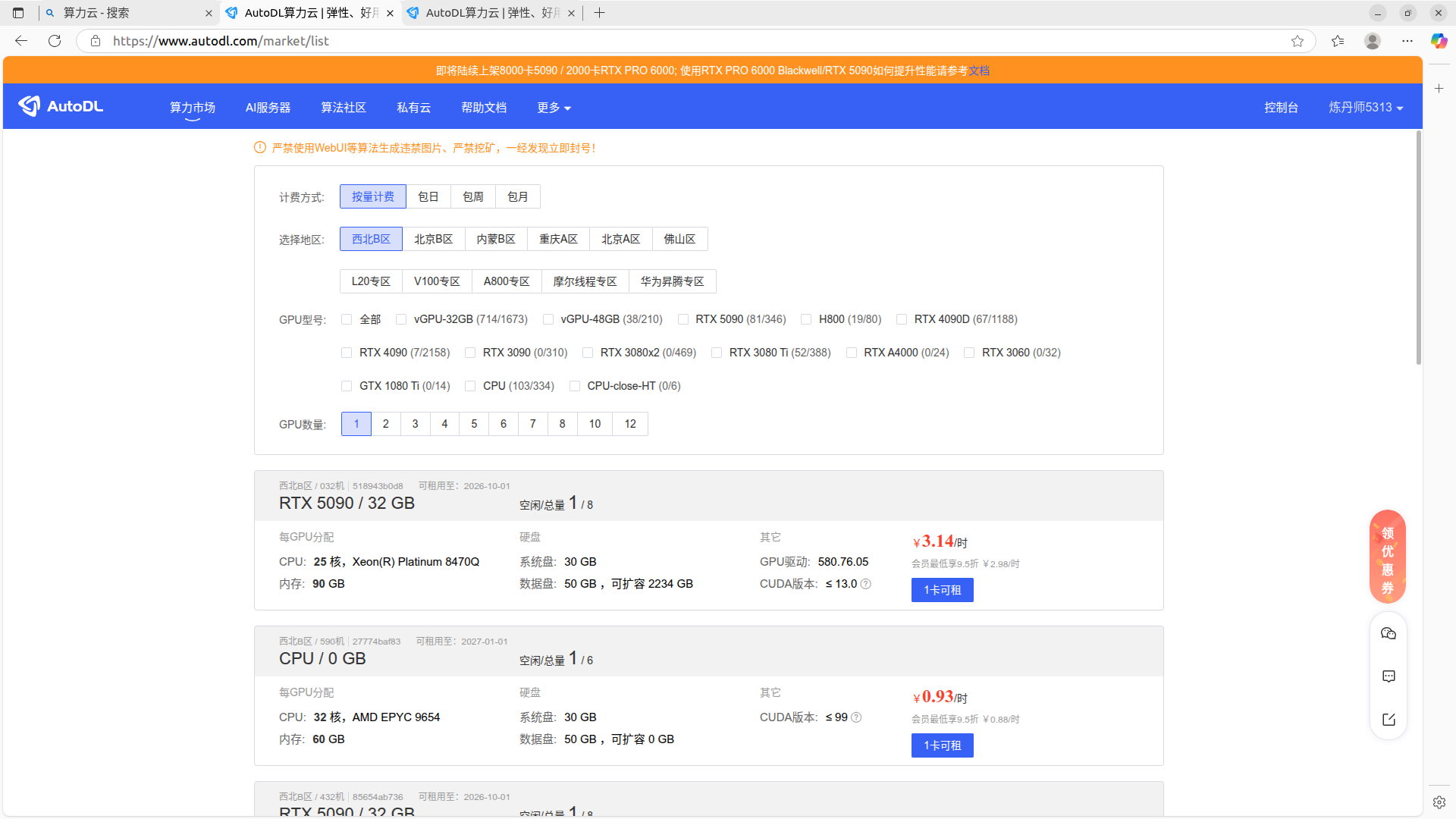
根据地区选择服务器,点击可租用
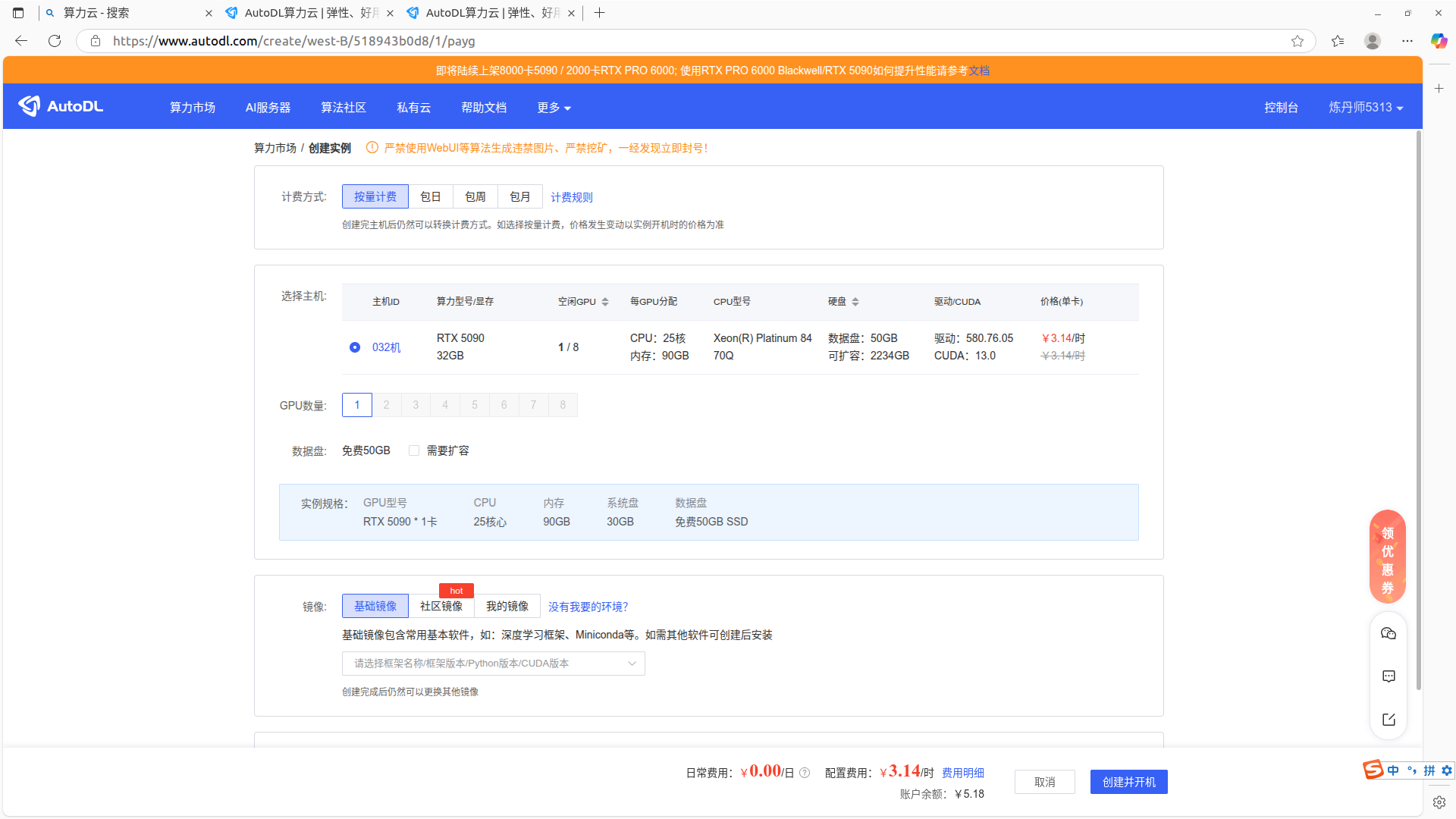
点击镜像选择12.4版本
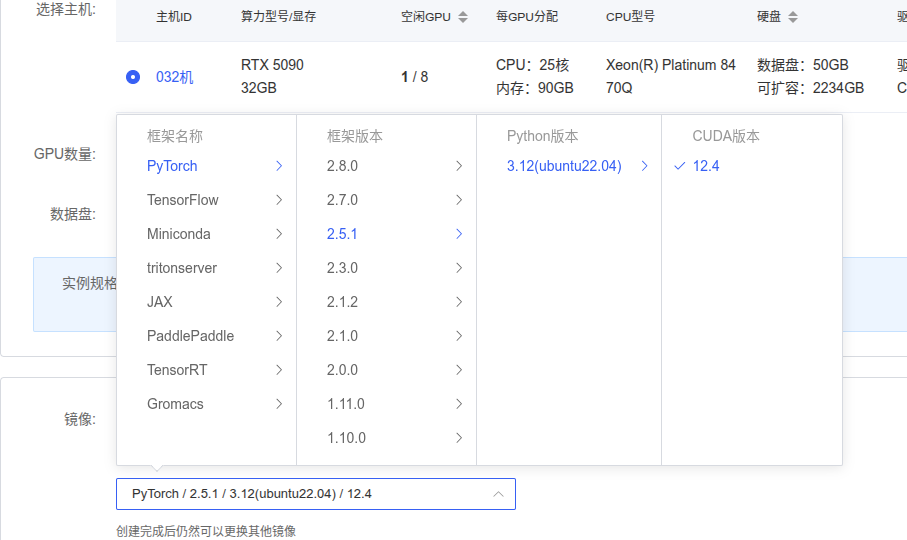
点击创建并开机,他会自动跳转控制台,如果没有跳转,点击控制台
点击容器实例
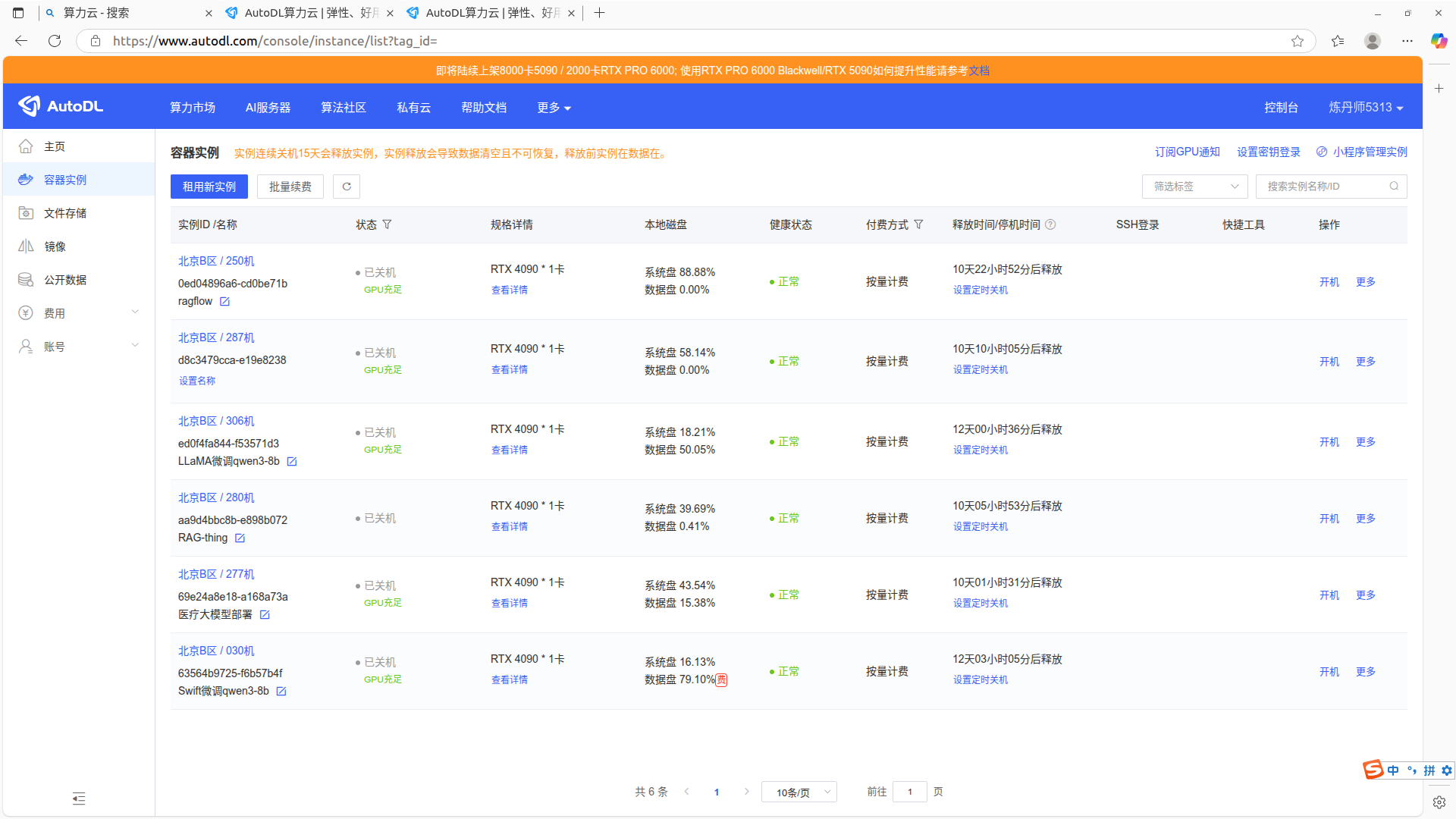
先点击更多选择无卡模式开机
点击jupyterLab,进入选择终端控制台
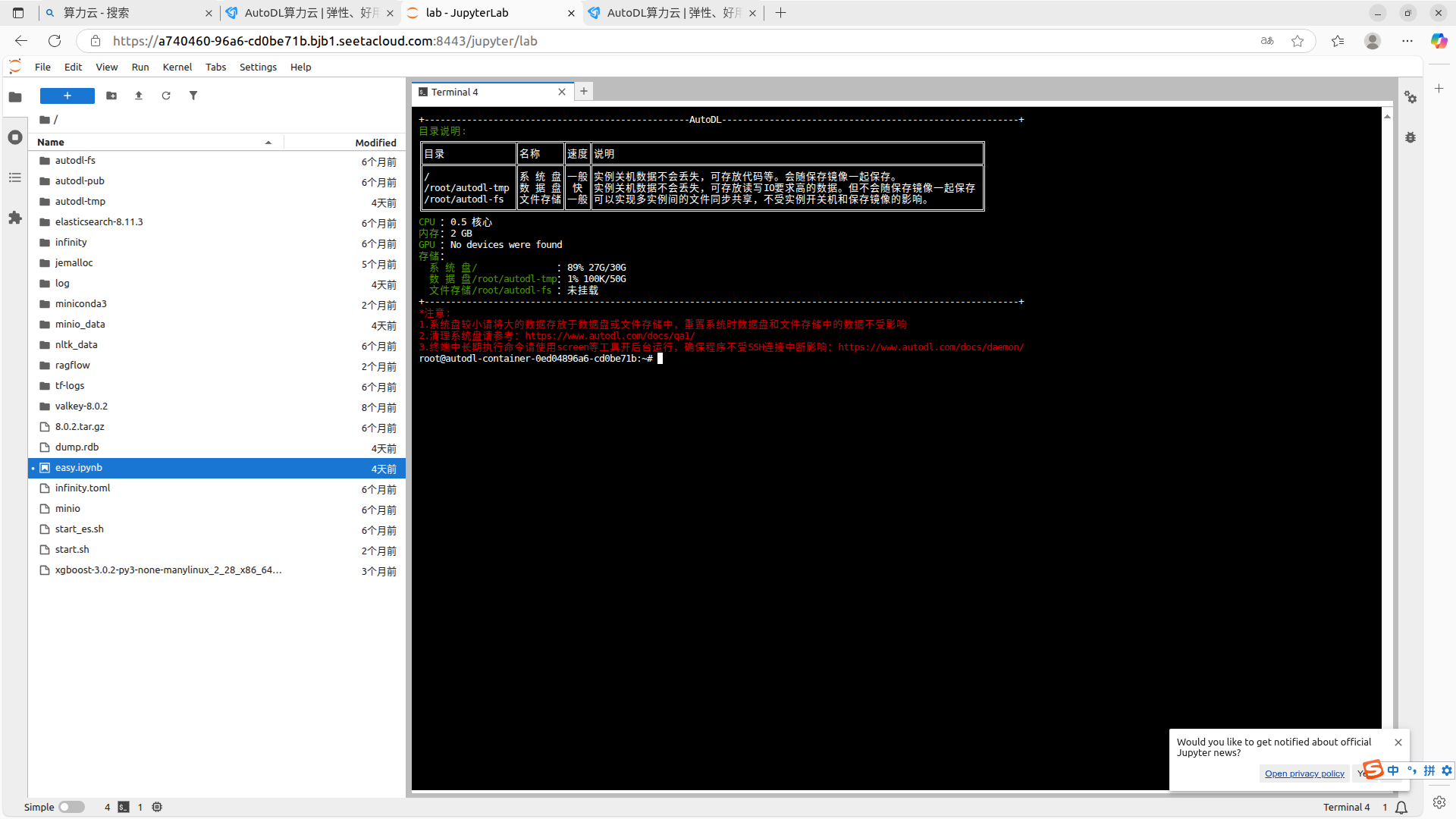
2.创建环境+拉取swift+下载模型
1.环境配置
# 设置全局pip镜像源(适用于所有平台)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip install --upgrade pip
# 设置conda环境目录和包缓存目录
mkdir -p /root/autodl-tmp/conda/envs
conda config --add envs_dirs /root/autodl-tmp/conda/envs
mkdir -p /root/autodl-tmp/conda/pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
# 验证配置
cat /root/.condarc
# 创建环境
conda create -n swift python==3.12 -y
# 初始化
conda init
# 激活环境
conda activate swift
# 安装 modelscope 库,为模型的下载、管理等操作提供便利
pip install modelscope
# 学术加速
source /etc/network_turbo
# 下载Qwen3-8B
modelscope download --model Qwen/Qwen3-8B --local_dir /root/autodl-tmp/Qwen/Qwen3-8B2.下载模型
# 再开一个终端 激活环境
# 学术加速
source /etc/network_turbo
conda activate swift
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .3.数据格式
标准格式:
{"messages": [{"role": "system", "content": "<system>"}, {"role": "user", "content": "<query1>"}, {"role": "assistant", "content": "<response1>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
示例:
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "告诉我明天的天气"}, {"role": "assistant", "content": "明天天气晴朗"}]}
{"messages": [{"role": "system", "content": "你是个有用无害的数学计算器"}, {"role": "user", "content": "1+1等于几"}, {"role": "assistant", "content": "等于2"}, {"role": "user", "content": "再加1呢"}, {"role": "assistant", "content": "等于3"}]}数据集
链接: https://pan.baidu.com/s/1cJHxlrt--U7aKzzuSOk9eg?pwd=5a6n 提取码: 5a6n
--来自百度网盘超级会员v2的分享
4.训练命令
训练的时候关闭无卡模式,直接点击GPU开机
注意!!!!在算力云上面复制粘贴的时候斜杠后面不能有 ----‘空格’
CUDA_VISIBLE_DEVICES=0 \ # 指定使用第0号GPU(多GPU可写0,1,单卡无需修改)
swift sft \ # 调用Swift框架执行「有监督微调(SFT)」,SFT是用标注数据训练模型的核心方式
--model /root/autodl-tmp/Qwen/Qwen3-8B \ # 指定Qwen3-8B原模型的本地文件夹路径,需替换为你实际的模型存放路径
--train_type lora \ # 选择微调方式为LoRA(低秩适配),仅训练少量新增参数,大幅节省显存(单卡即可跑Qwen3-8B)
--dataset /root/autodl-tmp/turning_data.json \ # 指定训练数据集路径(JSON格式,含标注的对话/指令数据),需替换为你自己的数据集路径
--torch_dtype bfloat16 \ # 设定计算精度为bfloat16(半精度),比全精度(float32)节省50%显存,且不影响训练效果
--num_train_epochs 5 \ # 设定训练总轮数为5(即完整遍历数据集5次),轮数太少模型学不充分,太多易过拟合
--per_device_train_batch_size 1 \ # 单GPU的训练批次大小为1(每次输入1条数据),Qwen3-8B显存有限,设大易崩
--per_device_eval_batch_size 1 \ # 单GPU的验证批次大小为1(若有验证集,用于评估模型效果)
--learning_rate 1e-4 \ # 设定学习率为0.0001(LoRA微调常用值,太快易学错,太慢训练效率低)
--lora_rank 8 \ # LoRA的「秩」参数,控制新增参数规模(8是平衡效果与显存的常用值,值越大参数越多)
--lora_alpha 32 \ # LoRA的缩放因子,通常设为lora_rank的4倍(保证参数更新幅度稳定,避免训练震荡)
--target_modules all-linear \ # 指定对模型所有「线性层」应用LoRA微调,覆盖核心计算层,最大化微调效果
--gradient_accumulation_steps 16 \ # 梯度累积步数为16,等效将批次大小放大16倍(缓解显存不足,同时提升训练稳定性)
--eval_steps 50 \ # 每训练50步(step)执行一次验证,监控模型在验证集上的表现,避免过拟合
--save_steps 50 \ # 每训练50步保存一次模型 checkpoint(快照),防止训练中断后前功尽弃
--save_total_limit 5 \ # 最多保留5个最新的模型 checkpoint,避免占用过多磁盘空间
--logging_steps 5 \ # 每训练5步记录一次日志(如损失值、学习率),方便实时查看训练进度
--max_length 2048 \ # 设定输入文本的最大长度(2048个token),超过会截断,平衡显存占用与数据完整性
--output_dir /root/autodl-tmp/output \ # 指定训练结果保存路径,含微调后的LoRA权重、日志、配置文件,需替换为你想保存的路径
--system 'You are a helpful assistant.' \ # 设定模型的「系统提示」,定义模型角色(如“你是一个有帮助的助手”)
--warmup_ratio 0.05 \ # 学习率预热比例为5%,前5%的训练步数中学习率从0逐渐涨到目标值,避免初始学习率过大导致模型不稳定
--dataloader_num_workers 4 \ # 设定数据加载的进程数为4,加速数据预处理(通常设为CPU核心数的1-2倍)
--model_author swift \ # 自定义模型作者标识(仅备注用,不影响训练)
--model_name swift-robot # 自定义微调后模型的名称(仅备注用,方便区分不同训练任务)5.推理(有卡模式)
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters /root/autodl-tmp/output/v1-20250508-084203/checkpoint-200 \ # 修改参数名称---执行命令时要删除注释
--stream true \
--temperature 0 \
--max_new_tokens 20486.模型融合
swift export \
--model /root/autodl-tmp/Qwen/Qwen3-8B \
--adapters /root/autodl-tmp/output/v0-20250509-145906/checkpoint-543 \ # 修改参数名称---执行命令时要删除注释
--output_dir /root/autodl-tmp/fusion_model \
--merge_lora true \
--safe_serialization true

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)